SES School, Studie en Onderwijs
Wiskunde in de brugklas, Frans voor het examen of een studie Personeel en Arbeid? Moeilijke formulieren van DUO? Iets weten over studiefinanciering of studentenverenigingen? Dit is het forum voor leerkrachten, scholieren en studenten, van brugklas tot uni



Post hier weer al je vragen, passies, trauma's en andere dingen die je uit je slaap houden met betrekking tot de wiskunde.
Van MBO tot WO, hier is het topic waar je een antwoord kunt krijgen op je vragen. Vragen over stochastiek in het algemeen en stochastische processen & analyse in het bijzonder worden door sommigen extra op prijs gesteld!
Opmaak:
• met de [tex]-tag kun je Latexcode in je post opnemen om formules er mooier uit te laten zien (uitleg).
Links:
• http://integrals.wolfram.com/index.jsp: site van Wolfram, makers van Mathematica, om online symbolische integratie uit te voeren.
• http://mathworld.wolfram.com/: site van Wolfram met een berg korte wiki-achtige artikelen over wiskundige concepten en onderwerpen, incl. search.
• http://functions.wolfram.com/: site van Wolfram met een berg identiteiten, gerangschikt per soort functie.
• http://scholar.google.com/: Google scholar, zoek naar trefwoorden specifiek in (wetenschappelijke) artikelen. Vaak worden er meerdere versies van hetzelfde artikel gevonden, waarvan één of meer van de website van een journaal en (dus) niet vrij toegankelijk, maar vaak ook een versie die wel vrij van de website van de auteur te halen is.
• http://www.wolframalpha.com Meest geavanceerde rekenmachine van het internet. Handig voor het berekenen van integralen, afgeleides, etc...
OP
Handig:
Riparius heeft ooit een PDF geschreven over goniometrische identiteiten. Deze kun je hier downloaden:
www.mediafire.com/view/?2b214qltc7m3v0d
Van MBO tot WO, hier is het topic waar je een antwoord kunt krijgen op je vragen. Vragen over stochastiek in het algemeen en stochastische processen & analyse in het bijzonder worden door sommigen extra op prijs gesteld!
Opmaak:
• met de [tex]-tag kun je Latexcode in je post opnemen om formules er mooier uit te laten zien (uitleg).
Links:
• http://integrals.wolfram.com/index.jsp: site van Wolfram, makers van Mathematica, om online symbolische integratie uit te voeren.
• http://mathworld.wolfram.com/: site van Wolfram met een berg korte wiki-achtige artikelen over wiskundige concepten en onderwerpen, incl. search.
• http://functions.wolfram.com/: site van Wolfram met een berg identiteiten, gerangschikt per soort functie.
• http://scholar.google.com/: Google scholar, zoek naar trefwoorden specifiek in (wetenschappelijke) artikelen. Vaak worden er meerdere versies van hetzelfde artikel gevonden, waarvan één of meer van de website van een journaal en (dus) niet vrij toegankelijk, maar vaak ook een versie die wel vrij van de website van de auteur te halen is.
• http://www.wolframalpha.com Meest geavanceerde rekenmachine van het internet. Handig voor het berekenen van integralen, afgeleides, etc...
OP
Handig:
Riparius heeft ooit een PDF geschreven over goniometrische identiteiten. Deze kun je hier downloaden:
www.mediafire.com/view/?2b214qltc7m3v0d
Bewijs eerst, rechtstreeks met de definitie van de Fermatgetallen, dat je voor elke (gehele) n ≥ 1 hebtquote:Op woensdag 7 maart 2018 21:07 schreef _--_ het volgende:
Nu even terug. Wat kan je bewijzen wat betreft Fermatgetallen. (en een beetje op mijn niveau)
Hint: maak gebruik van het merkwaardig product a² − b² = (a + b)(a − b).
Gebruik identiteit (1) vervolgens om te bewijzen dat je voor elke (gehele) n ≥ 1 hebt
Hint: geef een bewijs met volledige inductie. Dit houdt in dat je aantoont
(a) dat (2) juist is voor n = 1, en
(b) dat (2) juist is voor n = k + 1 áls (2) juist is voor een zekere n = k.
Uit (a) en (b) samen volgt dan dat (2) juist is voor elke gehele n ≥ 1.
Heb je (2) bewezen, dan is het triviaal om via een bewijs uit het ongerijmde (een reductio ad absurdum) aan te tonen dat elk tweetal (verschillende) Fermatgetallen onderling ondeelbaar is.
Kies twee gehele getallen m en n zodanig dat 0 ≤ m < n en veronderstel dat Fm en Fn beide deelbaar zijn door een geheel getal a > 1. Dan is a dus een factor van Fn maar ook van het gedurig product van F0 t/m Fn−1 omdat dit product immers Fm bevat als factor (want: m is kleiner dan n). Maar dan moet het verschil van Fn en het gedurig product van F0 t/m Fn−1 ook deelbaar zijn door a. Echter, uit (2) volgt dat dit verschil gelijk is aan 2, zodat a dan een deler van 2 moet zijn. En omdat we a > 1 hebben verondersteld volgt dan dat a = 2 zou moeten zijn. Maar dit is onmogelijk omdat Fermatgetallen oneven zijn en dus niet 2 als deler kunnen hebben. De aanname dat twee Fermatgetallen Fm en Fn een deler a > 1 gemeen hebben voert dus tot een tegenstrijdigheid, zodat deze aanname onjuist moet zijn. Ergo, elk tweetal Fermatgetallen is onderling ondeelbaar.

Dankjewel voor je uitwerking. Om eerlijk te zijn heb ik hier op dit moment niets aan omdat ik zulke formuleringen nog niet heb gehad op school.quote:Op donderdag 8 maart 2018 04:37 schreef Riparius het volgende:
[..]
Bewijs eerst, rechtstreeks met de definitie van de Fermatgetallen, dat je voor elke (gehele) n ≥ 1 hebt
Hint: maak gebruik van het merkwaardig product a² − b² = (a + b)(a − b).
Gebruik identiteit (1) vervolgens om te bewijzen dat je voor elke (gehele) n ≥ 1 hebt
Hint: geef een bewijs met volledige inductie. Dit houdt in dat je aantoont
(a) dat (2) juist is voor n = 1, en
(b) dat (2) juist is voor n = k + 1 áls (2) juist is voor een zekere n = k.
Uit (a) en (b) samen volgt dan dat (2) juist is voor elke gehele n ≥ 1.
Heb je (2) bewezen, dan is het triviaal om via een bewijs uit het ongerijmde (een reductio ad absurdum) aan te tonen dat elk tweetal (verschillende) Fermatgetallen onderling ondeelbaar is.
Kies twee gehele getallen m en n zodanig dat 0 ≤ m < n en veronderstel dat Fm en Fn beide deelbaar zijn door een geheel getal a > 1. Dan is a dus een factor van Fn maar ook van het gedurig product van F0 t/m Fn−1 omdat dit product immers Fm bevat als factor (want: m is kleiner dan n). Maar dan moet het verschil van Fn en het gedurig product van F0 t/m Fn−1 ook deelbaar zijn door a. Echter, uit (2) volgt dat dit verschil gelijk is aan 2, zodat a dan een deler van 2 moet zijn. En omdat we a > 1 hebben verondersteld volgt dan dat a = 2 zou moeten zijn. Maar dit is onmogelijk omdat Fermatgetallen oneven zijn en dus niet 2 als deler kunnen hebben. De aanname dat twee Fermatgetallen Fm en Fn een deler a > 1 gemeen hebben voert dus tot een tegenstrijdigheid, zodat deze aanname onjuist moet zijn. Ergo, elk tweetal Fermatgetallen is onderling ondeelbaar.
Crack the following and we will get back to you: !1!llssod000;;
Dit zou je echt wel moeten kunnen met de gegeven aanwijzingen. Voor het bewijs van (1) heb je alleen rekenregels nodig voor machten zoalsquote:
[..]
Dankjewel voor je uitwerking. Om eerlijk te zijn heb ik hier op dit moment niets aan omdat ik zulke formuleringen nog niet heb gehad op school.
en
die je inmiddels hoort te kennen, en het merkwaardig product
Het bewijs van (2) is wat lastiger, niet zozeer vanwege de gedachtegang achter een bewijs met inductie maar wel om dit correct op te schrijven.
Ik ga je even op weg helpen met de concrete vraag die je hier stelde, namelijk om te laten zien dat Fn nooit een deler kan zijn van Fn+1. Het idee is om eerst een recursieve betrekking op te stellen waarbij we Fn+1 uitdrukken in Fn. Daaruit zouden we dan moeten kunnen aflezen dat Fn+1 geen geheel veelvoud kan zijn van Fn, zodat deling van Fn+1 door Fn geen geheel getal op kan leveren.
Welnu, volgens de definitie van de Fermatgetallen hebben we voor elke gehele n ≥ 0
en als we hier n in beide leden van deze betrekking vervangen door n + 1 hebben we zo dus ook
Nu heb je, als we bovenstaande rekenregels voor machten gebruiken
en daarmee dus ook
Nu moeten we gaan proberen de uitdrukking in het rechterlid van deze betrekking te relateren aan Fn, want we wilden immers Fn+1 uitdrukken in Fn. Dit kan op verschillende manieren, maar het is hier wellicht het gemakkelijkst als we eerst 2 aftrekken van beide leden, want dan krijgen we
Waarom doe ik dit? Wel, je ziet dat we Fn+1 − 2 kunnen schrijven als een verschil van twee kwadraten. Dat is mooi, want een verschil van de kwadraten van twee grootheden kun je altijd herschrijven als het product van de som en het verschil van die grootheden. Dat is, zoals hierboven al is opgemerkt, één van de merkwaardige producten (identiteiten) die vaak van pas komen bij algebraïsche herleidingen en die je dus van buiten moet kennen (ze zijn het merken waard, dat wilde vroeger zeggen dat ze de moeite waard zijn om te onthouden, vandaar de naam). Maken we nu gebruik van a² − b² = (a + b)(a − b) dan krijgen we
Kortom, we hebben dus
en daarmee hebben we een betrekking gevonden tussen Fn+1 en Fn. Maar we wilden eigenlijk niet Fn+1 − 2 maar Fn+1 zelf uitdrukken in Fn. Daarom tellen we nu bij beide leden weer 2 op en zo vinden we dus
Delen we tenslotte beide leden door Fn, dan hebben we
En kijk, nu zien we direct dat deling van Fn+1 door Fn geen geheel getal op kan leveren. Weliswaar is (Fn − 2) een geheel getal, maar omdat Fn ≥ 3 voor elke n ≥ 0 is 2/Fn een echte breuk, dat wil zeggen een breuk waarvan de waarde tussen 0 en 1 ligt. De uitkomst van de deling van Fn+1 door Fn is dus geen geheel getal, oftewel Fn is geen deler van Fn+1, QED.
Bedankt voor de verheldering. Ik snapte dit tekentje nietquote:
[..]
Dit zou je echt wel moeten kunnen met de gegeven aanwijzingen. Voor het bewijs van (1) heb je alleen rekenregels nodig voor machten zoals
en
die je inmiddels hoort te kennen, en het merkwaardig product
Het bewijs van (2) is wat lastiger, niet zozeer vanwege de gedachtegang achter een bewijs met inductie maar wel om dit correct op te schrijven.
Ik ga je even op weg helpen met de concrete vraag die je hier stelde, namelijk om te laten zien dat Fn nooit een deler kan zijn van Fn+1. Het idee is om eerst een recursieve betrekking op te stellen waarbij we Fn+1 uitdrukken in Fn. Daaruit zouden we dan moeten kunnen aflezen dat Fn+1 geen geheel veelvoud kan zijn van Fn, zodat deling van Fn+1 door Fn geen geheel getal op kan leveren.
Welnu, volgens de definitie van de Fermatgetallen hebben we voor elke gehele n ≥ 0
en als we hier n in beide leden van deze betrekking vervangen door n + 1 hebben we zo dus ook
Nu heb je, als we bovenstaande rekenregels voor machten gebruiken
en daarmee dus ook
Nu moeten we gaan proberen de uitdrukking in het rechterlid van deze betrekking te relateren aan Fn, want we wilden immers Fn+1 uitdrukken in Fn. Dit kan op verschillende manieren, maar het is hier wellicht het gemakkelijkst als we eerst 2 aftrekken van beide leden, want dan krijgen we
Waarom doe ik dit? Wel, je ziet dat we Fn+1 − 2 kunnen schrijven als een verschil van twee kwadraten. Dat is mooi, want een verschil van de kwadraten van twee grootheden kun je altijd herschrijven als het product van de som en het verschil van die grootheden. Dat is, zoals hierboven al is opgemerkt, één van de merkwaardige producten (identiteiten) die vaak van pas komen bij algebraïsche herleidingen en die je dus van buiten moet kennen (ze zijn het merken waard, dat wilde vroeger zeggen dat ze de moeite waard zijn om te onthouden, vandaar de naam). Maken we nu gebruik van a² − b² = (a + b)(a − b) dan krijgen we
Kortom, we hebben dus
en daarmee hebben we een betrekking gevonden tussen Fn+1 en Fn. Maar we wilden eigenlijk niet Fn+1 − 2 maar Fn+1 zelf uitdrukken in Fn. Daarom tellen we nu bij beide leden weer 2 op en zo vinden we dus
Delen we tenslotte beide leden door Fn, dan hebben we
En kijk, nu zien we direct dat deling van Fn+1 door Fn geen geheel getal op kan leveren. Weliswaar is (Fn − 2) een geheel getal, maar omdat Fn ≥ 3 voor elke n ≥ 0 is 2/Fn een echte breuk, dat wil zeggen een breuk waarvan de waarde tussen 0 en 1 ligt. De uitkomst van de deling van Fn+1 door Fn is dus geen geheel getal, oftewel Fn is geen deler van Fn+1, QED.
Crack the following and we will get back to you: !1!llssod000;;
Je hebt Grieks, dus dat teken zou je moeten herkennen. Het is de hoofdletter Π die wordt gebruikt om een (gedurig) product aan te geven. De kleine letter i is hier een index die loopt van 0 t/m n−1. Zo kan men het product (vermenigvuldiging) van de getallen F0 t/m Fn−1 heel compact noteren. Op dezelfde manier wordt ook de hoofdletter Σ gebruikt om de som (optelling) van een aantal getallen compact te noteren.quote:
[..]
Bedankt voor de verheldering. Ik snapte dit tekentje niet [ afbeelding ]. Hierdoor raakte ik in de war. Nu is het duidelijker.
Kort vraagje: Klopt het dat als 2 verschillende personen op dezelfde tijdstip aan komen op een bepaald punt. wat de tussenliggende snelheid ook is, de gemiddelde snelheid altijd even groot is?
Crack the following and we will get back to you: !1!llssod000;;
Dat hangt er maar net vanaf of ze dezelfde afstand hebben afgelegd en of ze tegelijk vertrokken zijn, natuurlijk.quote:
Kort vraagje: Klopt het dat als 2 verschillende personen op dezelfde tijdstip aan komen op een bepaald punt. wat de tussenliggende snelheid ook is, de gemiddelde snelheid altijd even groot is?
Opinion is the medium between knowledge and ignorance (Plato)
Ja dat bedoel ik ook. Sorry. zelfde afstand en tegelijk vertrokken.quote:
[..]
Dat hangt er maar net vanaf of ze dezelfde afstand hebben afgelegd en of ze tegelijk vertrokken zijn, natuurlijk.
Crack the following and we will get back to you: !1!llssod000;;
Tja, dan is de gemiddelde snelheid wel hetzelfde natuurlijk, dat lijkt me triviaal. Snelheid = afstand/tijd, en zowel tijd als afstand zijn gelijk.quote:
[..]
Ja dat bedoel ik ook. Sorry. zelfde afstand en tegelijk vertrokken.
Opinion is the medium between knowledge and ignorance (Plato)
quote:
[..]
Tja, dan is de gemiddelde snelheid wel hetzelfde natuurlijk, dat lijkt me triviaal. Snelheid = afstand/tijd, en zowel tijd als afstand zijn gelijk.
Crack the following and we will get back to you: !1!llssod000;;
Dat wist je zelf ook wel, want als dat niet zo was zou trajectcontrole onmogelijk zijn. Iets om over na te denken: trajectcontrole maakt gebruik van de middelwaardestelling.quote:
Ik vroeg voor de zekerheid.quote:
[..]
Dat wist je zelf ook wel, want als dat niet zo was zou trajectcontrole onmogelijk zijn. Iets om over na te denken: trajectcontrole maakt gebruik van de middelwaardestelling.
Crack the following and we will get back to you: !1!llssod000;;
Veel interessanter is de vraag waarom jij dacht dat de gemiddelde snelheid wel eens niet hetzelfde kon zijn? Je vraag deed me trouwens ook denken aan deze opgave.quote:
Wat nou als 2 personen 300 meter afleggen.quote:
[..]
Veel interessanter is de vraag waarom jij dacht dat de gemiddelde snelheid wel eens niet hetzelfde kon zijn? Je vraag deed me trouwens ook denken aan deze opgave.
Persoon A legt de eerste 299 meter af in ∞ km/u daarna wacht hij tot persoon B met een normale snelheid (10 km/u) bij hem is.
Als ze daarna tegelijk finishen is de gemiddelde snelheid dan nog gelijk?
Crack the following and we will get back to you: !1!llssod000;;
∞ is geen welbepaalde grootheid, dus kun je niet meer spreken over (gemiddelde) snelheden. Dit is dus geen tegenvoorbeeld.quote:
[..]
Wat nou als 2 personen 300 meter afleggen.
Persoon A legt de eerste 299 meter af in ∞ km/u daarna wacht hij tot persoon B met een normale snelheid (10 km/u) bij hem is.
Als ze daarna tegelijk finishen is de gemiddelde snelheid dan nog gelijk?
lichtsnelheid?quote:
[..]
∞ is geen welbepaalde grootheid, dus kun je niet meer spreken over (gemiddelde) snelheden. Dit is dus geen tegenvoorbeeld.
Crack the following and we will get back to you: !1!llssod000;;
Dan klopt het wel. Uiteindelijk hebben A en B even lang gedaan over hetzelfde traject, en dus zijn hun gemiddelde snelheden over dit traject gelijk.quote:

Hoe bereken je een helling op een bepaald punt exact met je ti-84? Ik weet wel hoe je het met algebra doet hoor. Maar je moet ook snappen hoe je het met een GR doet. Ik weet wel dat het iets met tabel is.
Crack the following and we will get back to you: !1!llssod000;;
Calc->dy/dxquote:Op zondag 8 april 2018 21:38 schreef _--_ het volgende:
Hoe bereken je een helling op een bepaald punt exact met je ti-84? Ik weet wel hoe je het met algebra doet hoor. Maar je moet ook snappen hoe je het met een GR doet. Ik weet wel dat het iets met tabel is.
Vragen over rekenmachines zijn niet echt vragen voor het wiskunde topic, en ik heb ook niet zo'n ding, maar om je even op weg te helpen: de helling op een bepaald punt van de grafiek van een functie is de waarde van de afgeleide functie op dat punt.quote:
Hoe bereken je een helling op een bepaald punt exact met je ti-84? Ik weet wel hoe je het met algebra doet hoor. Maar je moet ook snappen hoe je het met een GR doet. Ik weet wel dat het iets met tabel is.
Dus, als je een (differentieerbare) functie f hebt en een grafiek met als vergelijking y = f(x), dan is voor x = a de helling in het punt (a; f(a)) op de grafiek gelijk aan f'(a).
Zoek even in de handleiding hoe je de waarde van een afgeleide functie bepaalt met je rekenmachine.
Ik heb een aantal vragen voor de intelligente Fokkers hier:
Ik was de paper "Unveiling What Is Written in the Stars: Analyzing Explicit, Implicit, and Discourse Paterns of Sentiment in Social Media" over text mining aan het bestuderen en toen stuitte ik op de volgende formules:
Ik zal beginnen met wat achtergrond informatie. De onderzoekers willen hier door middel van kwantificeren van expliciete sentimentele uitdrukkingen (woorden) onderzoeken of het onderscheid maken tussen erg positieve/negatieve expressieve uitdrukkingen en minder expressieve positieve/negatieve uitdrukkingen beter de verschillen in de 1-5 sterren recensies op Amazon kan verklaren dan normale valentie gradaties (positief/neutraal/negatief sentiment).
Mijn vraag gaat niet zo zeer over de statistiek die hierbij komt kijken, maar meer over de formules hierboven. Ik namelijk nog nooit een sommatie op deze manier uitgedrukt zien worden. Ik neem aan dat het een dubbele sommatie is? Maar als iemand hier meer duidelijkheid over kan geven zou dat erg fijn zijn.
Deze vier formules gaan over het kwantificeren van de expressieve woorden naar een desbetreffende score per review. Ze laten hier alleen de formules zien voor de positieve scores. Er zijn ook 4 zelfde soort formules voor de negatieve expressies.
De variabelen beteken het volgende:
Ik was de paper "Unveiling What Is Written in the Stars: Analyzing Explicit, Implicit, and Discourse Paterns of Sentiment in Social Media" over text mining aan het bestuderen en toen stuitte ik op de volgende formules:

Ik zal beginnen met wat achtergrond informatie. De onderzoekers willen hier door middel van kwantificeren van expliciete sentimentele uitdrukkingen (woorden) onderzoeken of het onderscheid maken tussen erg positieve/negatieve expressieve uitdrukkingen en minder expressieve positieve/negatieve uitdrukkingen beter de verschillen in de 1-5 sterren recensies op Amazon kan verklaren dan normale valentie gradaties (positief/neutraal/negatief sentiment).
Mijn vraag gaat niet zo zeer over de statistiek die hierbij komt kijken, maar meer over de formules hierboven. Ik namelijk nog nooit een sommatie op deze manier uitgedrukt zien worden. Ik neem aan dat het een dubbele sommatie is? Maar als iemand hier meer duidelijkheid over kan geven zou dat erg fijn zijn.
Deze vier formules gaan over het kwantificeren van de expressieve woorden naar een desbetreffende score per review. Ze laten hier alleen de formules zien voor de positieve scores. Er zijn ook 4 zelfde soort formules voor de negatieve expressies.
De variabelen beteken het volgende:
SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.Mijn eerste echte vraag: Begrijp ik goed dat ze de som nemen van de waarde tussen de haken over alle zinnen 0-n in review i en vervolgens de som nemen van deze waarden over alle reviews 0-m? In dat geval, waarom zijn de buitenste indexen boven en onder de sigma niet i voor de reviews en de binnenste indexen niet j voor de zinnen? Nu lijkt het alsof ze doorelkaar staan en er geen hiërarchie wordt aangegeven welke sommatie eerst uitgevoerd dient te worden. Plus, als je de score van elke review wil weten (aangegeven door de index i bij de variabelen aan de linker zijde van de formule) waarom neem je dan de som van alle reviews? In dat geval zijn het aantal zinnen in elke review het enige wat de scores van elkaar onderscheidt. Wat ook niet echt de bedoeling is lijkt me.
Mijn tweede vraag: Neg_PHi zou de score moeten geven voor de proportie van ontkende erg positieve expressies in review i. Waarom staat de Nij variabele dan voor de opsomming? Dit zou betekenen dat je eerst alle erg positieve woorden opsomt voor elke zin j en (en review i als ze het echt zo bedoelen) en dan als er in al die zinnen (van al die reviews) ook maar één ontkenning van een expressief woord staat, N = 1 en alle woorden als "ontkenningen" gezien worden en bij de score woorden opgeteld. Dit geeft dan toch precies dezelfde uitkomst als score PHi? Daarnaast zou dan de index van N totaal onlogisch zijn. Naar mijn idee moet Nij binnen de haken staan, achter de sommatie, zodat enkel de zinnen waarin zich een ontkenning bevindt worden meegeteld voor de score (al zou woorden ipv zinnen zou nog beter zijn imo).
Heeft iemand enig idee of ik compleet fout zit te denken en het niet begrepen heb? Ik kan me toch moeilijk voorstellen dat er in een peer-reviewed paper zulk soort fouten staan.
Sorry voor de lange tekst
quote:Okay even proberen inhoudelijk je vragen te beantwoorden:SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.Mijn eerste echte vraag: Begrijp ik goed dat ze de som nemen van de waarde tussen de haken over alle zinnen 0-n in review i en vervolgens de som nemen van deze waarden over alle reviews 0-m? In dat geval, waarom zijn de buitenste indexen boven en onder de sigma niet i voor de reviews en de binnenste indexen niet j voor de zinnen? Nu lijkt het alsof ze doorelkaar staan en er geen hiërarchie wordt aangegeven welke sommatie eerst uitgevoerd dient te worden. Plus, als je de score van elke review wil weten (aangegeven door de index i bij de variabelen aan de linker zijde van de formule) waarom neem je dan de som van alle reviews? In dat geval zijn het aantal zinnen in elke review het enige wat de scores van elkaar onderscheidt. Wat ook niet echt de bedoeling is lijkt me.
Mijn tweede vraag: Neg_PHi zou de score moeten geven voor de proportie van ontkende erg positieve expressies in review i. Waarom staat de Nij variabele dan voor de opsomming? Dit zou betekenen dat je eerst alle erg positieve woorden opsomt voor elke zin j en (en review i als ze het echt zo bedoelen) en dan als er in al die zinnen (van al die reviews) ook maar één ontkenning van een expressief woord staat, N = 1 en alle woorden als "ontkenningen" gezien worden en bij de score woorden opgeteld. Dit geeft dan toch precies dezelfde uitkomst als score PHi? Daarnaast zou dan de index van N totaal onlogisch zijn. Naar mijn idee moet Nij binnen de haken staan, achter de sommatie, zodat enkel de zinnen waarin zich een ontkenning bevindt worden meegeteld voor de score (al zou woorden ipv zinnen zou nog beter zijn imo).
Heeft iemand enig idee of ik compleet fout zit te denken en het niet begrepen heb? Ik kan me toch moeilijk voorstellen dat er in een peer-reviewed paper zulk soort fouten staan.
Sorry voor de lange tekst
Ja, het betreft hier een dubbele som over i,j.
Aangezien het hier eindige sommatie betreft kun je gewoon de orde van sommatie omdraaien aangezien het een commutatieve groep is. Dat wil niks meer zeggen dan A + B = B+A (bijvoorbeeld voor matrix multiplicatie is dit in het algemeen niet waar)
Je andere observatie is inderdaad vreemd. Neg_PH_i zou alleen van index i afhangen, en inderdaad de index j zou compleet uit de RHS (right hand side) moeten verdwijnen.
Heb je deze Latex formules zelf geschreven? De notatie is hoogst ongebruikelijk en ronduit verschrikkelijk lelijk te noemen. Dat houdt me ook een beetje tegen om het artikel te gaan lezen eigenlijk.
Persoonlijk sla ik altijd de reviews op Facebook over omdat de meeste mensen daar alleen maar hun klachten komen spuien en derhalve die review sectie volgens mij vaak 'biased' is.
[ Bericht 0% gewijzigd door #ANONIEM op 02-05-2018 23:17:55 ]
Bedankt voor het uitgebreide antwoord!quote:
[..]
Okay even proberen inhoudelijk je vragen te beantwoorden:
Ja, het betreft hier een dubbele som over i,j.
Aangezien het hier eindige sommatie betreft kun je gewoon de orde van sommatie omdraaien aangezien het een commutatieve groep is. Dat wil niks meer zeggen dan A + B = B+A (bijvoorbeeld voor matrix multiplicatie is dit in het algemeen niet waar)
Je andere observatie is inderdaad vreemd. Neg_PH_i zou alleen van index i afhangen, en inderdaad de index j zou compleet uit de RHS (right hand side) moeten verdwijnen.
Heb je deze Latex formules zelf geschreven? De notatie is hoogst ongebruikelijk en ronduit verschrikkelijk lelijk te noemen. Dat houdt me ook een beetje tegen om het artikel te gaan lezen eigenlijk.
Persoonlijk sla ik altijd de reviews op Facebook over omdat de meeste mensen daar alleen maar hun klachten komen spuien en derhalve die review sectie volgens mij vaak 'biased' is.
De formules staan echt zo in het artikel. Mijn tutor heeft er inmiddels ook even naar gekeken en die kwam ook tot de conclusie dat de schrijvers slordig zijn geweest met de notatie. Beetje vreemd dat dat niemand is opgevallen voordat het werd gepubliceerd.
Het gaat hier overigens niet alleen over reviews op Facebook. Ze onderzoeken eerst reviews van Amazon, Barnes & Nobles en TripAdvisor met goede resultaten en vervolgens kijken ze of deze resultaten ook worden behaald in de context van Facebook en Twitter. De resultaten zijn daar iets minder, maar het nieuwe model weet het sentiment van de schrijver nog altijd beter te benaderen dan de traditionele aanpak enkel gebaseerd op valentie (positief/neutraal/negatief).
Kickje?
Ik zit al een poosje te peinzen over een probleem wat zich afspeelt binnen de complexe functietheorie maar eigenlijk gaat over evolutievergelijkingen.
Enfin, als volgt:
Zij X een Banach ruimte en A een lineaire, begrensde operator op X. Dan weten we dat:
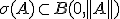
En voor alle s in de resolventen verzameling bestaat er een Laurent series ontwikkeling:
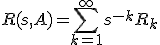
Waar Rk weer lineaire, begrensde operatoren op X zijn.
Schrijf nu sI-A = s(I-A/s) en pas een Neumann ontwikkeling toe:
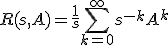
En het volgt al snel dat Rk = Ak-1
Dan volgt het echte vraagstuk:
Bereken:
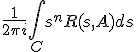 voor n = 0,1,2.. waar C een contourintegraal is (tegen de klok in) die het spectrum van A omvat.
voor n = 0,1,2.. waar C een contourintegraal is (tegen de klok in) die het spectrum van A omvat.
Nu weten we dat de resolvent geen analytische voortzetting bevat in het spectrum van A, maar complexe functietheorie vertelt ons dat we integraal kunnen evalueren door naar het residu te kijken. Nu weten we niet of het spectrum überhaupt aftelbaar is, dus nu mijn vraag, hoe gebruiken we complexe functietheorie om deze integraal te evalueren?
Merk tevens op dat de resolvent een operator is, en we dus integreren over lineaire operators op X.
Ik zit al een poosje te peinzen over een probleem wat zich afspeelt binnen de complexe functietheorie maar eigenlijk gaat over evolutievergelijkingen.
Enfin, als volgt:
Zij X een Banach ruimte en A een lineaire, begrensde operator op X. Dan weten we dat:
En voor alle s in de resolventen verzameling bestaat er een Laurent series ontwikkeling:
Waar Rk weer lineaire, begrensde operatoren op X zijn.
Schrijf nu sI-A = s(I-A/s) en pas een Neumann ontwikkeling toe:
En het volgt al snel dat Rk = Ak-1
Dan volgt het echte vraagstuk:
Bereken:
Nu weten we dat de resolvent geen analytische voortzetting bevat in het spectrum van A, maar complexe functietheorie vertelt ons dat we integraal kunnen evalueren door naar het residu te kijken. Nu weten we niet of het spectrum überhaupt aftelbaar is, dus nu mijn vraag, hoe gebruiken we complexe functietheorie om deze integraal te evalueren?
Merk tevens op dat de resolvent een operator is, en we dus integreren over lineaire operators op X.
Ik weet niet veel van Banachruimten, maar hier zal toch haast wel An uitkomen?
Zolang de straal van C maar groter is dan |A| convergeert de reeks absoluut en kun je integraal en som omwisselen. Maar dan staat het er gewoon.
[ Bericht 25% gewijzigd door thabit op 30-07-2018 21:37:33 ]
Zolang de straal van C maar groter is dan |A| convergeert de reeks absoluut en kun je integraal en som omwisselen. Maar dan staat het er gewoon.
[ Bericht 25% gewijzigd door thabit op 30-07-2018 21:37:33 ]
Want de enige term die een bijdrage levert is k = n+1 (dat levert een integrand A^n / s op) en verder zijn alle residuen 0?quote:Op maandag 30 juli 2018 15:59 schreef thabit het volgende:
Ik weet niet veel van Banachruimten, maar hier zal toch haast wel An uitkomen?
Zolang de straal van C maar groter is dan |A| convergeert de reeks absoluut en kun je integraal en som omwisselen. Maar dan staat het er gewoon.
[ Bericht 0% gewijzigd door #ANONIEM op 30-07-2018 22:32:39 ]
Ja, sk is primitiveerbaar als k niet gelijk is aan -1 en dus is de integraal over een gesloten pad gelijk aan 0.quote:Op maandag 30 juli 2018 22:31 schreef Amoeba het volgende:
[..]
Want de enige term die een bijdrage levert is k = n+1 (dat levert een integrand A^n / s op) en verder zijn alle residuen 0?

OK het probleem is dat ik bij voorbeeld 2 even nergens meer kan vinden hoe je met die exact strepen op wortel vijf keer wortel 25 uitkomt...
Boven de deelstreep is alles appeltje eitje. Er onder is het ineens hub hub barbatruc
Op donderdag 23 mei 2024 23:36 schreef DerRabbit het volgende: Ja oké, daar heb je gelijk in.
Ohww. Ik ben een blonde gans. Dat is de wortel van (1^2+2^2)maal de wortel van (3^2+4^2) natuurlijk... Mijn excuses
Op donderdag 23 mei 2024 23:36 schreef DerRabbit het volgende: Ja oké, daar heb je gelijk in.

Van rechtsboven via rechtsonder naar linksonder lees je A B C D E F G H I J K. Dit patroon is er ook als je twee vakjes meer naar links begint: dan moet er A B C D E F G staan, en dus een E op de plek van het vraagteken.
Aaah ik zie hem, thanks!quote:
Van rechtsboven via rechtsonder naar linksonder lees je A B C D E F G H I J K. Dit patroon is er ook als je twee vakjes meer naar links begint: dan moet er A B C D E F G staan, en dus een E op de plek van het vraagteken.
Nog een

Eerste getal is telkens het kwadraat van het tweede getal, 12 dus.quote:
[..]
Aaah ik zie hem, thanks!
Nog een
[ afbeelding ]
Oh jeetje, ik las het als decimalen. Thanks. : ]quote:
[..]
Eerste getal is telkens het kwadraat van het tweede getal, 12 dus.
Waarom wil je dit eigenlijk doen? Deze vragen komen uit oefenexamens van de overheid in de Australische deelstaat Victoria. Het gaat om toelatingsexamens voor een viertal middelbare scholen (de zogeheten Selective Entry High Schools), en dit zijn oefenexamens die ouders hun kinderen kunnen voorleggen.quote:
[..]
Oh jeetje, ik las het als decimalen. Thanks. : ]
Ahh leuk, kunnen ze mooi trucjes leren.quote:
[..]
Waarom wil je dit eigenlijk doen? Deze vragen komen uit oefenexamens van de overheid in de Australische deelstaat Victoria. Het gaat om toelatingsexamens voor een viertal middelbare scholen (de zogeheten Selective Entry High Schools), en dit zijn oefenexamens die ouders hun kinderen kunnen voorleggen.
Op donderdag 23 mei 2024 23:36 schreef DerRabbit het volgende: Ja oké, daar heb je gelijk in.

Onderstaande grammar is ambigu omdat er twee parse trees van gemaakt kunnen worden:
Zijnde:
Dit komt volgens mij omdat er eerst voor zowel <expr> + <expr> als voor <expr> * <expr> gekozen kan worden?
Echter met onderstaande grammar:
zou dit probleem van ambiguïteit niet bestaan omdat het linker element altijd een <num> is en het rechter deel de <expression>?
Of gaat er iets mis in mijn gedachtegang? De laatste grammar heb ik geschreven a.d.h.v. een eenvoudige javascript vergelijking. En betekent dit dat de grammar onjuist is omdat er een left to right prescedence in zit waardoor de wiskundige voorrang van vermenigvuldigen en delen die wel in Javascript zitten niet gerepresenteerd wordt?
ขอแสดงความนับถือ Flip.

Zijnde:

Dit komt volgens mij omdat er eerst voor zowel <expr> + <expr> als voor <expr> * <expr> gekozen kan worden?
Echter met onderstaande grammar:

zou dit probleem van ambiguïteit niet bestaan omdat het linker element altijd een <num> is en het rechter deel de <expression>?
Of gaat er iets mis in mijn gedachtegang? De laatste grammar heb ik geschreven a.d.h.v. een eenvoudige javascript vergelijking. En betekent dit dat de grammar onjuist is omdat er een left to right prescedence in zit waardoor de wiskundige voorrang van vermenigvuldigen en delen die wel in Javascript zitten niet gerepresenteerd wordt?
ขอแสดงความนับถือ Flip.
I think that it’s extraordinarily important that we in computer science keep fun in computing
For all who deny the struggle, the triumphant overcome
Met zwijgen kruist men de duivel
For all who deny the struggle, the triumphant overcome
Met zwijgen kruist men de duivel
In de tweede grammatica wordt de expressie 2*3+4 als 2*(3+4) geparset.quote:Op zondag 21 oktober 2018 19:26 schreef FlippingCoin het volgende:
Onderstaande grammar is ambigu omdat er twee parse trees van gemaakt kunnen worden:
[ afbeelding ]
Zijnde:
[ afbeelding ]
Dit komt volgens mij omdat er eerst voor zowel <expr> + <expr> als voor <expr> * <expr> gekozen kan worden?
Echter met onderstaande grammar:
[ afbeelding ]
zou dit probleem van ambiguïteit niet bestaan omdat het linker element altijd een <num> is en het rechter deel de <expression>?
Of gaat er iets mis in mijn gedachtegang? De laatste grammar heb ik geschreven a.d.h.v. een eenvoudige javascript vergelijking. En betekent dit dat de grammar onjuist is omdat er een left to right prescedence in zit waardoor de wiskundige voorrang van vermenigvuldigen en delen die wel in Javascript zitten niet gerepresenteerd wordt?
ขอแสดงความนับถือ Flip.
Ja dus met een foutieve parse tree toch?quote:
[..]
In de tweede grammatica wordt de expressie 2*3+4 als 2*(3+4) geparset.
I think that it’s extraordinarily important that we in computer science keep fun in computing
For all who deny the struggle, the triumphant overcome
Met zwijgen kruist men de duivel
For all who deny the struggle, the triumphant overcome
Met zwijgen kruist men de duivel
Niet overeenkomstig de gebruikelijke voorrangsregels voor wiskundige operatoren nee.quote:
[..]
Ja dus met een foutieve parse tree toch?
Oke dankjewel helder.quote:
[..]
Niet overeenkomstig de gebruikelijke voorrangsregels voor wiskundige operatoren nee.
I think that it’s extraordinarily important that we in computer science keep fun in computing
For all who deny the struggle, the triumphant overcome
Met zwijgen kruist men de duivel
For all who deny the struggle, the triumphant overcome
Met zwijgen kruist men de duivel
Een klein vraagje heb ik over het algoritme van Linear Discriminant Analysis. Voor mijn scriptie moet ik dit algoritme kennen en ook kunnen uitleggen uiteindelijk. Echter, ik vind het nog zeer ingewikkeld en kan nergens ook echt een duidelijke uitleg vinden. Op youtube heb ik via dit filmpje een goede uitleg gevonden:
Voor mijn verslag probeer ik het nu algemeen uit te leggen zonder gebruik te maken van een voorbeeld. Zou iemand mij hier aub bij kunnen helpen.
Voor mijn verslag probeer ik het nu algemeen uit te leggen zonder gebruik te maken van een voorbeeld. Zou iemand mij hier aub bij kunnen helpen.
Hi, ik heb een redelijk goeie uitleg gevonden waar in 5 stappen het hele algoritme wordt uitgelegd.: https://sebastianraschka.com/Articles/2014_python_lda.htmlquote:
Een klein vraagje heb ik over het algoritme van Linear Discriminant Analysis. Voor mijn scriptie moet ik dit algoritme kennen en ook kunnen uitleggen uiteindelijk. Echter, ik vind het nog zeer ingewikkeld en kan nergens ook echt een duidelijke uitleg vinden. Op youtube heb ik via dit filmpje een goede uitleg gevonden:
Voor mijn verslag probeer ik het nu algemeen uit te leggen zonder gebruik te maken van een voorbeeld. Zou iemand mij hier aub bij kunnen helpen.
Ik vroeg me alleen af; weet iemand wat wordt bedoeld met deze formule:

Als je in de inhoudsopgave op paragraaf 2.1 klikt dan kom je bij deze formule
De tex-link in de OP is dood.
Ik schrijf boeken over wetenschap en filosofie!
https://www.epsilon-uitga(...)e-tijd-materie/10996
https://www.spectrumboeke(...)k-niet-9789000386765
https://www.spectrumboeke(...)tronen-9789000395071
https://www.epsilon-uitga(...)e-tijd-materie/10996
https://www.spectrumboeke(...)k-niet-9789000386765
https://www.spectrumboeke(...)tronen-9789000395071
Wat bedoel je precies? Ik zit niet zo vaak op dit forum, maar als de formule niet te zien is, hier de link:quote:
https://ibb.co/RHS1vY1
Je kan ook op de link waar LDA wordt uitgelegd op 2.1 klikken in de inhoudsopgave
De link naar de uitleg omtrent latex-opmaak in de OP.quote:
[..]
Wat bedoel je precies? Ik zit niet zo vaak op dit forum, maar als de formule niet te zien is, hier de link:
https://ibb.co/RHS1vY1
Je kan ook op de link waar LDA wordt uitgelegd op 2.1 klikken in de inhoudsopgave
-edit: sorry, ging niet over jouw post, maar over de OP (openingspost, helemaal bovenaan).
Ik schrijf boeken over wetenschap en filosofie!
https://www.epsilon-uitga(...)e-tijd-materie/10996
https://www.spectrumboeke(...)k-niet-9789000386765
https://www.spectrumboeke(...)tronen-9789000395071
https://www.epsilon-uitga(...)e-tijd-materie/10996
https://www.spectrumboeke(...)k-niet-9789000386765
https://www.spectrumboeke(...)tronen-9789000395071
Dat is al heel lang zo, geïnteresseerden zouden in plaats daarvan deze blogs (vijf stuks) kunnen doornemen.quote:
Het echte probleem is dat de TeX parser op FOK niet meer werkt sinds de overgang van FOK naar https op 11 december 2018. Wel in oude posts, maar niet in recente posts of in nieuwe posts.
Dus, dit werkt nu niet:
Als alternatief zou je voorlopig gebruik kunnen maken van deze editor om linkjes te genereren naar gifjes van je TeX code die je dan in je berichten op kunt nemen:
Dit is echter erg omslachtig als je een bericht wil schrijven met veel TeX code. Ik heb deze bug al op 12 december j.l. gerapporteerd maar meer dan een maand later is dit nog steeds niet opgelost.

Even een hersenkrakertje.
De vraagstelling:
Zij A een matrix (n x n), Aij = {1,..,n2/2} waarbij iedere waarde precies twee keer voorkomt. Neem verder aan dat n2/2 een geheel getal is én n > 2.
Te bewijzen:
Er bestaat een set X zdd |X| = n en X bestaat uit paren (i,j) zdd dat voor iedere (i,j), (k,l) de volgende beweringen waar zijn:
i =! k
j =! l
Aij =! Akl
Maw X is een set indices zodanig dat de matrix entries niet in dezelfde kolom, niet in dezelfde rij zitten én niet dezelfde waarde delen. Een (triviaal) voorbeeld is dus de diagonaal van de matrix als die niet tweemaal dezelfde waarde bevat.
Mijn poging:
Construeer een graaf G = (V,E) op de matrix waarbij twee punten verbonden zijn als ze in dezelfde kolom of rij zitten óf dezelfde waarde delen. Ieder punt heeft dus (2n-2) of 2n-1 connecties. Merk op dat |V| = n2
Het doel is nu om te bewijzen dat V een 'independent set' bevat van tenminste n punten.. Nou weten we dat er minimaal een independent set is van grootte |V|/(d+1) waarbij d de maximale graad van een punt is, in ons geval is dat 2n-1.. Dit levert zoiets als n/2 op en dat is nog niet goed genoeg...
Iemand een beter idee?
[ Bericht 0% gewijzigd door #ANONIEM op 26-03-2019 16:39:14 ]
De vraagstelling:
Zij A een matrix (n x n), Aij = {1,..,n2/2} waarbij iedere waarde precies twee keer voorkomt. Neem verder aan dat n2/2 een geheel getal is én n > 2.
Te bewijzen:
Er bestaat een set X zdd |X| = n en X bestaat uit paren (i,j) zdd dat voor iedere (i,j), (k,l) de volgende beweringen waar zijn:
i =! k
j =! l
Aij =! Akl
Maw X is een set indices zodanig dat de matrix entries niet in dezelfde kolom, niet in dezelfde rij zitten én niet dezelfde waarde delen. Een (triviaal) voorbeeld is dus de diagonaal van de matrix als die niet tweemaal dezelfde waarde bevat.
Mijn poging:
Construeer een graaf G = (V,E) op de matrix waarbij twee punten verbonden zijn als ze in dezelfde kolom of rij zitten óf dezelfde waarde delen. Ieder punt heeft dus (2n-2) of 2n-1 connecties. Merk op dat |V| = n2
Het doel is nu om te bewijzen dat V een 'independent set' bevat van tenminste n punten.. Nou weten we dat er minimaal een independent set is van grootte |V|/(d+1) waarbij d de maximale graad van een punt is, in ons geval is dat 2n-1.. Dit levert zoiets als n/2 op en dat is nog niet goed genoeg...
Iemand een beter idee?
[ Bericht 0% gewijzigd door #ANONIEM op 26-03-2019 16:39:14 ]
|
|
| Forum Opties | |
|---|---|
| Forumhop: | |
| Hop naar: | |