SES School, Studie en Onderwijs
Wiskunde in de brugklas, Frans voor het examen of een studie Personeel en Arbeid? Moeilijke formulieren van DUO? Iets weten over studiefinanciering of studentenverenigingen? Dit is het forum voor leerkrachten, scholieren en studenten, van brugklas tot uni



Iemand heeft de vorige dicht laten gaan zonder een nieuwe te openen.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Nou, kreeg net mail en heb toch een (omgerekend) 9 ofzo voor een opdracht óver SPSS/Quants.
Jolijt, ik schijn het een beetje te begrijpen!
Jolijt, ik schijn het een beetje te begrijpen!
Ja doei.

Al bijna een week zonder dat er iemand een SPSS vraag heeft, FOK! gaat vooruit.quote:Op donderdag 10 april 2014 16:35 schreef oompaloompa het volgende:
Iemand heeft de vorige dicht laten gaan zonder een nieuwe te openen.
Netjes!quote:
Nou, kreeg net mail en heb toch een (omgerekend) 9 ofzo voor een opdracht óver SPSS/Quants.
Jolijt, ik schijn het een beetje te begrijpen!

nicequote:
Nee, kritisch/analytisch paper over een onderzoek dat gebruik maakt van quants/spss.
Ik zat te denken, is het misschien nuttig om in plaats van de SPSS thread er de statistiekthread van te maken? Het gaat regelmatig over algemene statistiek vragen en soms ook over andere programmas als excel / R / etc.
De laatste post was een vraag, maar als je niet de moeite neemt een nieuwe thread te openen neem ik niet de moeite hem te beantwoordenquote:
[..]
Al bijna een week zonder dat er iemand een SPSS vraag heeft, FOK! gaat vooruit.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Goed plan. Misschien iets als "Statistiek en SPSS topic" van maken? Aangezien er anders misschien mensen zijn die denken dat hun SPSS vraag er niet thuis hoort en er weer een wildgroei aan SPSS topics komt.quote:
[..]
nice
Ik zat te denken, is het misschien nuttig om in plaats van de SPSS thread er de statistiekthread van te maken? Het gaat regelmatig over algemene statistiek vragen en soms ook over andere programmas als excel / R / etc.
Terecht.quote:De laatste post was een vraag, maar als je niet de moeite neemt een nieuwe thread te openen neem ik niet de moeite hem te beantwoorden
Als je een sample met waarnemingen x1, x2, ... , xn hebt, dan is x(1) de kleinste waarneming van je sample en x(n) de grootste.quote:
Mocht je sample dus x1 = 4, x2 = 8, x3 = 2 zijn, dan heb je x(1) = 2, x(2) = 4, x(3) = 8.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Zover was ik al ja! Maar bijvoorbeeld zo'n vraag:quote:
[..]
Als je een sample met waarnemingen x1, x2, ... , xn hebt, dan is x(1) de kleinste waarneming van je sample en x(n) de grootste.
Mocht je sample dus x1 = 4, x2 = 8, x3 = 2 zijn, dan heb je x(1) = 2, x(2) = 4, x(3) = 8.
Consider a random sample
1) Prove the density of the minimum
2) Consider two estimators of
(Tentamen Probability Distributions van afgelopen dinsdag)
En, had jij nou ook Multivariate van gisteren gemaakt? Zo ja, wat vond jij van die toets?
Stomme vraag, maar wat betekent die x in de notatie van de distributie? Ik heb alleen nog maar uniforme distributies gezien genoteerd als U(begin, einde).
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Je hebt een kansdichtheid functie. En een functie moet altijd input en output hebben, al lijkt deze overbodig.quote:
Stomme vraag, maar wat betekent die x in de notatie van de distributie? Ik heb alleen nog maar uniforme distributies gezien genoteerd als U(begin, einde).
Als statistiek nitwit een vraag.
Stel... ik heb 3.349 tekstuele beoordelingen, ik wil gaan bepalen wat voor soort beoordelingen het meest voorkomen en daar actie op ondernemen. Omdat het doorlezen van 3.500 blokken tekst belachelijk veel werk is, ga ik met een steekproef werken. Een online hulpmiddel leert mij het volgende: met een 4% foutmarge en 95% betrouwbaarheid heb ik een steekproef nodig van 510.
Vervolgens random 510 beoordelingen genomen, allemaal gelezen en netjes gecategoriseerd. 236 van de beoordelingen bleken echter onvoldoende ingevuld/verkeerd gelabeld/andere vorm van onbruikbaar. Ik ga dus mijn plan baseren op 510-236 = 274 beoordelingen.
Dat lijkt ineens erg weinig. Dus vraag ik me af: zijn die 274 dan wel representatief?
Ene mannetje op mijn schouder zegt: nee, te weinig. Andere mannetje op andere schouder zegt: ja, maar als blijkbaar uit jouw steekproef 236 van de 510 onbruikbaar zijn en je hebt random getrokken, dan betekent dat ongeveer 3.349 / 510 * 236 = 1.550 van álle beoordelingen onbruikbaar zijn. Dus die 274 zijn verder representatief voor de hele populatie....
Heeft dat tweede mannetje gelijk? Mijn gut feeling zegt van wel, maar ik kan het buiten bovenstaande benadering niet onderbouwen.
Stel... ik heb 3.349 tekstuele beoordelingen, ik wil gaan bepalen wat voor soort beoordelingen het meest voorkomen en daar actie op ondernemen. Omdat het doorlezen van 3.500 blokken tekst belachelijk veel werk is, ga ik met een steekproef werken. Een online hulpmiddel leert mij het volgende: met een 4% foutmarge en 95% betrouwbaarheid heb ik een steekproef nodig van 510.
Vervolgens random 510 beoordelingen genomen, allemaal gelezen en netjes gecategoriseerd. 236 van de beoordelingen bleken echter onvoldoende ingevuld/verkeerd gelabeld/andere vorm van onbruikbaar. Ik ga dus mijn plan baseren op 510-236 = 274 beoordelingen.
Dat lijkt ineens erg weinig. Dus vraag ik me af: zijn die 274 dan wel representatief?
Ene mannetje op mijn schouder zegt: nee, te weinig. Andere mannetje op andere schouder zegt: ja, maar als blijkbaar uit jouw steekproef 236 van de 510 onbruikbaar zijn en je hebt random getrokken, dan betekent dat ongeveer 3.349 / 510 * 236 = 1.550 van álle beoordelingen onbruikbaar zijn. Dus die 274 zijn verder representatief voor de hele populatie....
Heeft dat tweede mannetje gelijk? Mijn gut feeling zegt van wel, maar ik kan het buiten bovenstaande benadering niet onderbouwen.
Da gao nie nou!
Dit ligt ver buiten mijn kennisgebied, maar het lijkt me af te hangen van de vraag die je wilt beantwoorden.quote:
Als statistiek nitwit een vraag.
Stel... ik heb 3.349 tekstuele beoordelingen, ik wil gaan bepalen wat voor soort beoordelingen het meest voorkomen en daar actie op ondernemen. Omdat het doorlezen van 3.500 blokken tekst belachelijk veel werk is, ga ik met een steekproef werken. Een online hulpmiddel leert mij het volgende: met een 4% foutmarge en 95% betrouwbaarheid heb ik een steekproef nodig van 510.
Vervolgens random 510 beoordelingen genomen, allemaal gelezen en netjes gecategoriseerd. 236 van de beoordelingen bleken echter onvoldoende ingevuld/verkeerd gelabeld/andere vorm van onbruikbaar. Ik ga dus mijn plan baseren op 510-236 = 274 beoordelingen.
Dat lijkt ineens erg weinig. Dus vraag ik me af: zijn die 274 dan wel representatief?
Ene mannetje op mijn schouder zegt: nee, te weinig. Andere mannetje op andere schouder zegt: ja, maar als blijkbaar uit jouw steekproef 236 van de 510 onbruikbaar zijn en je hebt random getrokken, dan betekent dat ongeveer 3.349 / 510 * 236 = 1.550 van álle beoordelingen onbruikbaar zijn. Dus die 274 zijn verder representatief voor de hele populatie....
Heeft dat tweede mannetje gelijk? Mijn gut feeling zegt van wel, maar ik kan het buiten bovenstaande benadering niet onderbouwen.
Als je conclusies wilt maken puur op basis van bruikbare beoordelingen uit de populatie zou ik je berekening in het begin nogmaals uitvoeren maar nu met een basissample van 3349-1550 = 1799 en dan die uitkomst als aantal bruikbare beoordelingen nemen.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Thnx voor je reactie. Het vervelende is dat ik vooraf niet weet welke 1.550 het zijn. Daarvoor moet ik ze allemaal doorlezen. En dat is nu juist de reden dat ik met een steekproef wil werken. Om je een idee te geven, de 3.349 beoordelen samen bevatten ruim 290.000 woorden, dus ongeveer 580 pagina's.quote:
[..]
Dit ligt ver buiten mijn kennisgebied, maar het lijkt me af te hangen van de vraag die je wilt beantwoorden.
Als je conclusies wilt maken puur op basis van bruikbare beoordelingen uit de populatie zou ik je berekening in het begin nogmaals uitvoeren maar nu met een basissample van 3349-1550 = 1799 en dan die uitkomst als aantal bruikbare beoordelingen nemen.
Da gao nie nou!
Dat valt me stiekem nog mee eigenlijk.quote:
[..]
Thnx voor je reactie. Het vervelende is dat ik vooraf niet weet welke 1.550 het zijn. Daarvoor moet ik ze allemaal doorlezen. En dat is nu juist de reden dat ik met een steekproef wil werken. Om je een idee te geven, de 3.349 beoordelen samen bevatten ruim 290.000 woorden, dus ongeveer 580 pagina's.
Ik ben ongeveer anderhalve minuut gemiddeld met een beoordeling bezig om deze te categoriseren. Dat is 84 uur in totaal. Zoveel tijd heb ik bij lange na nietquote:
[..]
Dat valt me stiekem nog mee eigenlijk.Geen mogelijkheid om ze allemaal even door te nemen? Nog geen 100 woorden per beoordeling. (Ik weet niet hoelang het duurt om 1 beoordeling door te spitten op de voor jou belangrijke data.)
Da gao nie nou!
Nog maar 76 uur aangezien je er al ruim 500 hebt gedaan.quote:
[..]
Ik ben ongeveer anderhalve minuut gemiddeld met een beoordeling bezig om deze te categoriseren. Dat is 84 uur in totaal. Zoveel tijd heb ik bij lange na niet
Ik snap dat het veel is ja. Is het voor een scriptie? Stellen ze eisen aan het resultaat? Het mooiste is om alles mee te nemen, aangezien het relevante data is en je blijkbaar de dataset toch al ter beschikking hebt. Maar het hangt een beetje af van het doel van je onderzoek hoe belangrijk dit precies is.
Het is voor een scriptie inderdaad. Ze zijn akkoord met een steekproef, maar dan wel netjes uitgevoerdquote:
[..]
Nog maar 76 uur aangezien je er al ruim 500 hebt gedaan.
Ik snap dat het veel is ja. Is het voor een scriptie? Stellen ze eisen aan het resultaat? Het mooiste is om alles mee te nemen, aangezien het relevante data is en je blijkbaar de dataset toch al ter beschikking hebt. Maar het hangt een beetje af van het doel van je onderzoek hoe belangrijk dit precies is.
Het gaat om klachten van klanten. Waar ik voor moet zorgen is dat ik uit die teksten handige categorieën maak, vervolgens ga kijken hoeveel klachten per categorie voorkomen en daarmee bepalen welke categorie de meeste prio moet krijgen om het totaal met een X percentage te kunnen reduceren.
Lijkt me dus niet dat ik daar 100% voor nodig heb...
Da gao nie nou!
Hi,
Ik heb een (denk ik) hele simpele vraag over SPSS.
Ik heb een variabele 'totaal aantal woorden advertentie' en een variabele 'totaal aantal Engelse woorden advertentie'.
Een derde variabele 'percentage Engels advertentie' wil ik graag automatisch laten invullen door de eerste twee variabelen te combineren.
Is dat mogelijk in SPSS en zo ja, welke test gebruik ik hiervoor?
Alvast bedankt!
Ik heb een (denk ik) hele simpele vraag over SPSS.
Ik heb een variabele 'totaal aantal woorden advertentie' en een variabele 'totaal aantal Engelse woorden advertentie'.
Een derde variabele 'percentage Engels advertentie' wil ik graag automatisch laten invullen door de eerste twee variabelen te combineren.
Is dat mogelijk in SPSS en zo ja, welke test gebruik ik hiervoor?
Alvast bedankt!
I like you more than pizza, and I really like pizza.
| 1 2 | compute percentage=(var_engels)/(var_totaal)*100. execute. |
Of, als je niet via syntax werkt (niet echt aan te raden): Transform -> Compute variable
Target variable: percentage
Numeric expression: (var_engels)/(var_totaal)*100
Bedankt! Dit was m:)quote:
[ code verwijderd ]
Of, als je niet via syntax werkt (niet echt aan te raden): Transform -> Compute variable
Target variable: percentage
Numeric expression: (var_engels)/(var_totaal)*100
I like you more than pizza, and I really like pizza.
Even ter controle een vraagje, omdat de uitkomsten zo makkelijk lijken.
Ik heb een aantal deelvragen om te beantwoorden dmv SPSS, dit zijn:
1.1. Hoeveel Engelse woorden bevatten de advertenties gemiddeld?
1.2. Hoeveel procent van de woorden in de advertentie is Engels?
Ik heb deze vragen beantwoord nav deze output:
Vraag 1.1.
Ik had een variabele 'aantal Engelse woorden in de advertentie' en een variabele 'totaal aantal woorden advertentie'
Ik heb alleen de eerste variabele gebruikt:
Descriptive Statistics
N = 55
Minimum = 5
Maximum = 128
Mean = 24,31
Antwoord: 24 woorden
Vraag 1.2.
Descriptive Statistics
N = 55
Minimum = 7
Maximum = 100
Mean = 38,19
Std. Deviation = 24,852
Heb hier geantwoord: 38,2%.
Ik weet niet of het klopt, omdat het vrij simpel lijkt (en dan ga ik twijfelen XD)
Ik heb een aantal deelvragen om te beantwoorden dmv SPSS, dit zijn:
1.1. Hoeveel Engelse woorden bevatten de advertenties gemiddeld?
1.2. Hoeveel procent van de woorden in de advertentie is Engels?
Ik heb deze vragen beantwoord nav deze output:
Vraag 1.1.
Ik had een variabele 'aantal Engelse woorden in de advertentie' en een variabele 'totaal aantal woorden advertentie'
Ik heb alleen de eerste variabele gebruikt:
Descriptive Statistics
N = 55
Minimum = 5
Maximum = 128
Mean = 24,31
Antwoord: 24 woorden
Vraag 1.2.
Descriptive Statistics
N = 55
Minimum = 7
Maximum = 100
Mean = 38,19
Std. Deviation = 24,852
Heb hier geantwoord: 38,2%.
Ik weet niet of het klopt, omdat het vrij simpel lijkt (en dan ga ik twijfelen XD)
I like you more than pizza, and I really like pizza.
En dan heb ik nog een (hopelijk laatste) vraagje. Ik moet de samenhang bepalen:
Hangt het aantal Engelse woorden samen met het gebruikte schrift
(westers schrift of niet-westers schrift)?
Aantal EN woorden is een ratio variabele en gebruikte schrift is een nominale variabele.
Moet ik die ratio variabele eerst hercoderen?
Hangt het aantal Engelse woorden samen met het gebruikte schrift
(westers schrift of niet-westers schrift)?
Aantal EN woorden is een ratio variabele en gebruikte schrift is een nominale variabele.
Moet ik die ratio variabele eerst hercoderen?
I like you more than pizza, and I really like pizza.
Je antwoord op vraag 1.1 lijkt me correct.
De vraag 1.2 is niet zo heel duidelijk, ze vragen naar 'de advertentie'. Als jij denkt dat de vraagsteller 'wat is het gemiddelde percentage Engelse woorden in alle advertenties' bedoelt, dan klopt je antwoord.
De vraag 1.2 is niet zo heel duidelijk, ze vragen naar 'de advertentie'. Als jij denkt dat de vraagsteller 'wat is het gemiddelde percentage Engelse woorden in alle advertenties' bedoelt, dan klopt je antwoord.
Dat ligt volledig aan wat voor statistische toets je wilt doen.quote:
En dan heb ik nog een (hopelijk laatste) vraagje. Ik moet de samenhang bepalen:
Hangt het aantal Engelse woorden samen met het gebruikte schrift
(westers schrift of niet-westers schrift)?
Aantal EN woorden is een ratio variabele en gebruikte schrift is een nominale variabele.
Moet ik die ratio variabele eerst hercoderen?
Bedankt voor je hulp. Dat maakt niet heel veel uit voor mij, wil graag de samenhang kunnen vinden. Ik wil graag weten welke toets ik moet doen, omdat ik een verkeerde output krijg als ik nu crosstabs doe met deze twee variabelen. (Dat lijkt me ook logisch, maar ik kom er verder niet meer uit..)
I like you more than pizza, and I really like pizza.
Je vragen zijn wel heel simpel, je kunt deze antwoorden makkelijk ergens vinden. Niet dat ik je niet wil helpen natuurlijkquote:
Bedankt voor je hulp. Dat maakt niet heel veel uit voor mij, wil graag de samenhang kunnen vinden. Ik wil graag weten welke toets ik moet doen, omdat ik een verkeerde output krijg als ik nu crosstabs doe met deze twee variabelen. (Dat lijkt me ook logisch, maar ik kom er verder niet meer uit..)
Mocht je wel crosstabs willen gebruiken, dan moet je uiteraard dat percentage Engelse woorden in categorieën ophakken. Hoe dat technisch moet is niet zo moeilijk (Transform > Recode into different variables), welk afkappunt je moet kiezen is lastiger. Wellicht is het nuttig om eerst via Explore eens te kijken hoe je data eruit zien.
[ Bericht 3% gewijzigd door dotKoen op 24-04-2014 19:02:11 ]
Haha, ik weet het, sorry :$
Het is alleen dat ik de afgelopen dagen alleen maar bezig ben geweest met SPSS en nu lijken de simpelste tests opeens rocket science.
Heel erg bedankt voor je hulp!
Het is alleen dat ik de afgelopen dagen alleen maar bezig ben geweest met SPSS en nu lijken de simpelste tests opeens rocket science.
Heel erg bedankt voor je hulp!
I like you more than pizza, and I really like pizza.
Wie kan me helpen?
Ik wil in general linear model een analyse doen met één afhankelijke variabele (dv; ordinaal), twee onafhankelijke variabelen (iv 1 en iv2; beide nominaal) en een controlevariabele (cv; ordinaal). De controlevariabele moet ik invoeren als:
glm dv by iv1 iv2 with cv
/design iv1 iv2 iv1*iv2 iv1*cv iv2*cv iv1*iv2*cv
En uiteraard nog wat andere commando's in de syntax
Als ik dit doe, krijg ik een prachtige anova-tabel met de effecten van al de gespecificeerde designs. Nu wil ik uiteraard beter naar die effecten kijken en uitvinden welke celvergelijkingen significant zijn en welke niet. Normaal gesproken (= zonder zo'n controlevariabele) doe ik dat met de emmeans-functie. Als ik dat nu doe, dan wordt de controlevariabele gebruikt als covariaat en dat wil ik niet. Ik wil alleen dat de controlevariabele een deel van de errorvariantie vermindert, zonder de gemiddelden te vergelijken alsof de groepen gelijk scoren op de covariaat.
Als ik de controlevariabele invoer als "by"-factor, dan gebruikt glm de variabele alsof ik een 3e iv heb en dat is ook niet de bedoeling (uitbreiding van het design dus).
Hoe kan ik de anova-toetsen nader inspecteren met een controlevariabele?
Ik wil in general linear model een analyse doen met één afhankelijke variabele (dv; ordinaal), twee onafhankelijke variabelen (iv 1 en iv2; beide nominaal) en een controlevariabele (cv; ordinaal). De controlevariabele moet ik invoeren als:
glm dv by iv1 iv2 with cv
/design iv1 iv2 iv1*iv2 iv1*cv iv2*cv iv1*iv2*cv
En uiteraard nog wat andere commando's in de syntax
Als ik dit doe, krijg ik een prachtige anova-tabel met de effecten van al de gespecificeerde designs. Nu wil ik uiteraard beter naar die effecten kijken en uitvinden welke celvergelijkingen significant zijn en welke niet. Normaal gesproken (= zonder zo'n controlevariabele) doe ik dat met de emmeans-functie. Als ik dat nu doe, dan wordt de controlevariabele gebruikt als covariaat en dat wil ik niet. Ik wil alleen dat de controlevariabele een deel van de errorvariantie vermindert, zonder de gemiddelden te vergelijken alsof de groepen gelijk scoren op de covariaat.
Als ik de controlevariabele invoer als "by"-factor, dan gebruikt glm de variabele alsof ik een 3e iv heb en dat is ook niet de bedoeling (uitbreiding van het design dus).
Hoe kan ik de anova-toetsen nader inspecteren met een controlevariabele?

Ik heb ook een vraag, want ik loop nogal vast bij een bepaalde analyse.
Voor m'n onderzoek heb ik een pre-test uitgevoerd waarbij respondenten hun oordeel moesten geven over gesprekstechnieken die voorkomen in vijf verschillende video's. In de dataset heb ik nu dus voor elk van de vijf video's beoordelingen van negen verschillende gesprekstechnieken. Bijvoorbeeld: V1_T1 (waarde/beoordeling voor video 1, techniek 1), V1_T2 (waarde/beoordeling voor video 1, techniek 2) etc.
Nu wil ik graag een analyse uitvoeren waarbij ik de video kan selecteren die over het algemeen het hoogst scoort op de verschillende categorieën. Dus: Welke video scoort overall het hoogst?
Wat is hiervoor de beste methode? Alvast ontzettend bedankt!
Voor m'n onderzoek heb ik een pre-test uitgevoerd waarbij respondenten hun oordeel moesten geven over gesprekstechnieken die voorkomen in vijf verschillende video's. In de dataset heb ik nu dus voor elk van de vijf video's beoordelingen van negen verschillende gesprekstechnieken. Bijvoorbeeld: V1_T1 (waarde/beoordeling voor video 1, techniek 1), V1_T2 (waarde/beoordeling voor video 1, techniek 2) etc.
Nu wil ik graag een analyse uitvoeren waarbij ik de video kan selecteren die over het algemeen het hoogst scoort op de verschillende categorieën. Dus: Welke video scoort overall het hoogst?
Wat is hiervoor de beste methode? Alvast ontzettend bedankt!
:)
Als ik het goed begrijp moet je dus eerst een variabele V1_totaal maken? Hoe je die moet maken is afhankelijk van wat voor score het is. Zijn al die technieken op dezelfde manier gescoord en even belangrijk? Dan kun je ze optellen en delen (recode into different variable), zou ik zeggen.
Geruik Compute Variable om een totaalscore per video te maken. Daarna kun je bijvoorbeeld via Descriptives het gemiddelde daarvan berekenen. De video met de hoogste gemiddelde totaalscore is "de beste."quote:Op maandag 28 april 2014 10:34 schreef TWP het volgende:
Ik heb ook een vraag, want ik loop nogal vast bij een bepaalde analyse.
Voor m'n onderzoek heb ik een pre-test uitgevoerd waarbij respondenten hun oordeel moesten geven over gesprekstechnieken die voorkomen in vijf verschillende video's. In de dataset heb ik nu dus voor elk van de vijf video's beoordelingen van negen verschillende gesprekstechnieken. Bijvoorbeeld: V1_T1 (waarde/beoordeling voor video 1, techniek 1), V1_T2 (waarde/beoordeling voor video 1, techniek 2) etc.
Nu wil ik graag een analyse uitvoeren waarbij ik de video kan selecteren die over het algemeen het hoogst scoort op de verschillende categorieën. Dus: Welke video scoort overall het hoogst?
Wat is hiervoor de beste methode? Alvast ontzettend bedankt!
quote:
Als ik het goed begrijp moet je dus eerst een variabele V1_totaal maken? Hoe je die moet maken is afhankelijk van wat voor score het is. Zijn al die technieken op dezelfde manier gescoord en even belangrijk? Dan kun je ze optellen en delen (recode into different variable), zou ik zeggen.
Bedankt voor de snelle reactie.quote:Op maandag 28 april 2014 11:03 schreef Operc het volgende:
[..]
Geruik Compute Variable om een totaalscore per video te maken. Daarna kun je bijvoorbeeld via Descriptives het gemiddelde daarvan berekenen. De video met de hoogste gemiddelde totaalscore is "de beste."
Ik heb inderdaad een gemiddelde score berekend van de video's. Alle categorieën waren inderdaad even belangrijk en geschaald van 1 t/m 5.
Is het werkelijk zo simpel? Ik zat echt veel te moeilijk te denken dan
:)
Als je alle videos op dezelfde manier hebt laten beoordelen wel, dus ook in dezelfde richting (dat 1 laag is en 5 hoog etc.)quote:
[..]
[..]
Bedankt voor de snelle reactie.
Ik heb inderdaad een gemiddelde score berekend van de video's. Alle categorieën waren inderdaad even belangrijk en geschaald van 1 t/m 5.
Is het werkelijk zo simpel? Ik zat echt veel te moeilijk te denken danGa het meteen even uitproberen.
Ik zou graag achter iedere case in SPSS de regressiecoëfficiënt van een onafhankelijke variabele op een afhankelijke variabele printen, en dit per subgroep. Handmatig is niet te doen aangezien ik een zeer groot aantal subgroepen heb.
Kan dit op enigerlei wijze dmv bijv. deze syntax?
AGGREGATE
OUTFILE=* MODE=ADDVARIABLES OVERWRITE=YES
/BREAK= SUBGROEP
/SCHATTER= ????.
Kan dit op enigerlei wijze dmv bijv. deze syntax?
AGGREGATE
OUTFILE=* MODE=ADDVARIABLES OVERWRITE=YES
/BREAK= SUBGROEP
/SCHATTER= ????.
Event er verduidelijking: Ik kan de resultaten wel op m'n scherm krijgen dmv de volgende syntax
sort cases by SUBGROEP.
split file by SUBGROEP.
regression
/dep AFHANKELIJK
/method = enter ONAFHANKELIJK.
split file off.
De vraag is nu hoe ik de coefficienten uit de afzondelijke regressies aanroep en achter mijn afzonderlijke cases geprint krijg.
sort cases by SUBGROEP.
split file by SUBGROEP.
regression
/dep AFHANKELIJK
/method = enter ONAFHANKELIJK.
split file off.
De vraag is nu hoe ik de coefficienten uit de afzondelijke regressies aanroep en achter mijn afzonderlijke cases geprint krijg.
Ik heb een vraag over de ANOVA icm Homogeneity of variance test.
Ik wil nagaan of de gemiddelde leeftijd van de deelnemers in drie condities niet significant van elkaar verschilt (dit is een controlecheck voorafgaand aan de resultaten van het hoofdonderzoek waarin ik effecten meet).
De verschillen blijken niet significant (F (2, 101) = 1.328; p = .270.)
De Levene geeft wel een significante waarde, namelijk .009
De verhouding van de grootste en kleinste standaarddeviatie is groter dan 2: (SD = 10.485 en SD = 13.660)
Wat kan ik hieruit concluderen? Is er nog een post-hoc test die ik kan doen, of is het geen groot probleem dat de variantie niet in elke groep gelijk is?
Alvast bedankt!
Ik wil nagaan of de gemiddelde leeftijd van de deelnemers in drie condities niet significant van elkaar verschilt (dit is een controlecheck voorafgaand aan de resultaten van het hoofdonderzoek waarin ik effecten meet).
De verschillen blijken niet significant (F (2, 101) = 1.328; p = .270.)
De Levene geeft wel een significante waarde, namelijk .009
De verhouding van de grootste en kleinste standaarddeviatie is groter dan 2: (SD = 10.485 en SD = 13.660)
Wat kan ik hieruit concluderen? Is er nog een post-hoc test die ik kan doen, of is het geen groot probleem dat de variantie niet in elke groep gelijk is?
Alvast bedankt!
I like you more than pizza, and I really like pizza.
Dat ligt er aan waarom je in de eerste plaats die toets uitgevoerd hebt. Als je denkt dat er een relatie bestaat tussen leeftijd en je afhankelijke variabele kun je er het beste voor controleren. Als het gewoon een toets was om te kijken of randomisatie een beetje fatsoenlijk was zou ik het gewoon negeren.quote:
Ik heb een vraag over de ANOVA icm Homogeneity of variance test.
Ik wil nagaan of de gemiddelde leeftijd van de deelnemers in drie condities niet significant van elkaar verschilt (dit is een controlecheck voorafgaand aan de resultaten van het hoofdonderzoek waarin ik effecten meet).
De verschillen blijken niet significant (F (2, 101) = 1.328; p = .270.)
De Levene geeft wel een significante waarde, namelijk .009
De verhouding van de grootste en kleinste standaarddeviatie is groter dan 2: (SD = 10.485 en SD = 13.660)
Wat kan ik hieruit concluderen? Is er nog een post-hoc test die ik kan doen, of is het geen groot probleem dat de variantie niet in elke groep gelijk is?
Alvast bedankt!
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Bedankt!quote:
[..]
Dat ligt er aan waarom je in de eerste plaats die toets uitgevoerd hebt. Als je denkt dat er een relatie bestaat tussen leeftijd en je afhankelijke variabele kun je er het beste voor controleren. Als het gewoon een toets was om te kijken of randomisatie een beetje fatsoenlijk was zou ik het gewoon negeren.
I like you more than pizza, and I really like pizza.
Ik zit weer vast met een analyse in SPSS
Ik heb een aantal teksten geanalyseerd op het type schrift en het aandeel van het Engels.
Ik heb drie variabelen:
- totaal aantal woorden in de tekst (ratio)
- totaal aantal Engelse woorden in de tekst (ratio)
- Of de tekst in westers schrift of een mix van westers en niet-westers schrift is opgesteld (nominaal)
Ik moet berekenen hoeveel Engels woorden er gemiddeld voorkomen in de tekst met de mix van westers en niet-westers schrift (dit heb ik gedaan) en hoeveel % van de totale tekst deze Engelse woorden uitmaken. << die laatste kom ik niet uit...
Ik moet volgens mij alle 3 de variabelen gebruiken, maar kom er niet uit hoe ik nou het juiste percentage krijg..
Kan iemand mij helpen?
Ik heb een aantal teksten geanalyseerd op het type schrift en het aandeel van het Engels.
Ik heb drie variabelen:
- totaal aantal woorden in de tekst (ratio)
- totaal aantal Engelse woorden in de tekst (ratio)
- Of de tekst in westers schrift of een mix van westers en niet-westers schrift is opgesteld (nominaal)
Ik moet berekenen hoeveel Engels woorden er gemiddeld voorkomen in de tekst met de mix van westers en niet-westers schrift (dit heb ik gedaan) en hoeveel % van de totale tekst deze Engelse woorden uitmaken. << die laatste kom ik niet uit...
Ik moet volgens mij alle 3 de variabelen gebruiken, maar kom er niet uit hoe ik nou het juiste percentage krijg..
Kan iemand mij helpen?
I like you more than pizza, and I really like pizza.
Je kunt een nieuwe variabele maken, die het percentage engelse t.o.v. Totaal aantal woorden aangeeft (via compute). Vervolgens kun je een split file doen op schrift en dan via descriptives gemiddelden opvragen. Als je de gemiddelden met elkaar moet vergelijken, dan kun je een anova uitvoeren (maar niet met spkit file!).
Bedankt voor je reactie! Ik begrijp niet helemaal wat je bedoelt met 'split file op schrift', sorry. Ik had al wel een variabele 'Percentage Engels in teksten'.quote:
Je kunt een nieuwe variabele maken, die het percentage engelse t.o.v. Totaal aantal woorden aangeeft (via compute). Vervolgens kun je een split file doen op schrift en dan via descriptives gemiddelden opvragen. Als je de gemiddelden met elkaar moet vergelijken, dan kun je een anova uitvoeren (maar niet met spkit file!).
Ik heb nu twee gemiddelden gevonden: De teksten waarin zowel westers als niet-westers schrift voorkwam bleken gemiddeld 22.35 Engelse woorden te bevatten (SD = 14.529). Het gemiddeld totaal aantal woorden in deze teksten was 77.61 (SD = 44.095).
Maar welke variabelen moet ik nu voor de anova gebruiken? Want de gemiddelde waarden zijn geen aparte variabelen.
Ik hoop dat ik niet te vaag ben. Alvast bedankt.
I like you more than pizza, and I really like pizza.
Ik heb de anova uitgevoerd en de variabelen 'percentage Engels' en 'gebruikt schrift' gebruikt.quote:
[..]
Bedankt voor je reactie! Ik begrijp niet helemaal wat je bedoelt met 'split file op schrift', sorry. Ik had al wel een variabele 'Percentage Engels in teksten'.
Ik heb nu twee gemiddelden gevonden: De teksten waarin zowel westers als niet-westers schrift voorkwam bleken gemiddeld 22.35 Engelse woorden te bevatten (SD = 14.529). Het gemiddeld totaal aantal woorden in deze teksten was 77.61 (SD = 44.095).
Maar welke variabelen moet ik nu voor de anova gebruiken? Want de gemiddelde waarden zijn geen aparte variabelen.
Ik hoop dat ik niet te vaag ben. Alvast bedankt.
Ik zie wel een gemiddelde score in de descriptives tabel. Mag ik deze gewoon overnemen? de p-waarde is wel significant, of heeft dit niks te maken met de score?
I like you more than pizza, and I really like pizza.
is dat niet gewoon hoeveelheid engelse woorden / totale aantal woorden? Of mis ik nu iets?quote:
Ik zit weer vast met een analyse in SPSS
Ik heb een aantal teksten geanalyseerd op het type schrift en het aandeel van het Engels.
Ik heb drie variabelen:
- totaal aantal woorden in de tekst (ratio)
- totaal aantal Engelse woorden in de tekst (ratio)
- Of de tekst in westers schrift of een mix van westers en niet-westers schrift is opgesteld (nominaal)
Ik moet berekenen hoeveel Engels woorden er gemiddeld voorkomen in de tekst met de mix van westers en niet-westers schrift (dit heb ik gedaan) en hoeveel % van de totale tekst deze Engelse woorden uitmaken. << die laatste kom ik niet uit...
Ik moet volgens mij alle 3 de variabelen gebruiken, maar kom er niet uit hoe ik nou het juiste percentage krijg..
Kan iemand mij helpen?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Thanks, Ik ben er uit, was idd super simpel maar zat me weer blind te staren op te ingewikkelde oplossingenquote:
[..]
is dat niet gewoon hoeveelheid engelse woorden / totale aantal woorden? Of mis ik nu iets?
I like you more than pizza, and I really like pizza.
Mensen!
(Ik weet, 1st post, maar daar komt verandering in).
Ik ben bezig met m'n afstudeerscriptie en zit op dit moment helemaal vast met SPSS analyse.
Ik doe onderzoek naar relatie tussen irritatie binnen een reclame en naamsbekendheid.
Er zijn 2 vragenlijsten rondgegaan. De eerste om de irritatie te meten en de 2e om de naamsbekendheid te meten.
Dit was vooral met likert scale.
Het probleem is nu om de hypotheses te testen..
Er is gebruik gemaakt van 2 irritante reclames (vanish & zalando) en 2 niet-irritante reclames (kia en crystal clear)
Heb dus 4 onafhankelijke groepen (reclames) binnen een onafhankelijke variabele (Soort reclame)
Ik wil nu het volgende bewijzen:
Een test laat zien dat de irritante reclame meer irritatie opleverde dan de niet-irritante reclame.
Onafhankelijk: Soort Reclame. Afhankelijk: Ervaren irritatie.
Een reclame die irritatie bevat zorgt voor een hogere naamsbekendheid dan een niet-irritante reclame.
Onafhankelijk: Irritatie Afhankelijk: Naamsbekendheid (recall)
Er is mij gezegd dat ik gebruik moet maken van een ANOVA, maar dan kom ik bij het probleem, hoe ik een irritante reclame vergelijk met een niet-irritante reclame en hoe ik dan de onafhankelijke variabele invoer?
Als iemand weet hoe dit werkt, dank is groot!!
(Ik weet, 1st post, maar daar komt verandering in).
Ik ben bezig met m'n afstudeerscriptie en zit op dit moment helemaal vast met SPSS analyse.
Ik doe onderzoek naar relatie tussen irritatie binnen een reclame en naamsbekendheid.
Er zijn 2 vragenlijsten rondgegaan. De eerste om de irritatie te meten en de 2e om de naamsbekendheid te meten.
Dit was vooral met likert scale.
Het probleem is nu om de hypotheses te testen..
Er is gebruik gemaakt van 2 irritante reclames (vanish & zalando) en 2 niet-irritante reclames (kia en crystal clear)
Heb dus 4 onafhankelijke groepen (reclames) binnen een onafhankelijke variabele (Soort reclame)
Ik wil nu het volgende bewijzen:
Een test laat zien dat de irritante reclame meer irritatie opleverde dan de niet-irritante reclame.
Onafhankelijk: Soort Reclame. Afhankelijk: Ervaren irritatie.
Een reclame die irritatie bevat zorgt voor een hogere naamsbekendheid dan een niet-irritante reclame.
Onafhankelijk: Irritatie Afhankelijk: Naamsbekendheid (recall)
Er is mij gezegd dat ik gebruik moet maken van een ANOVA, maar dan kom ik bij het probleem, hoe ik een irritante reclame vergelijk met een niet-irritante reclame en hoe ik dan de onafhankelijke variabele invoer?
Als iemand weet hoe dit werkt, dank is groot!!
--
Je kan het een beetje vergelijken met deze vraag, maar dan moet ik in plaats van 2 reclames, 4 reclames analyseren, 2 irritante en 2 niet -irritante.
Hoi!
Voor mijn masterscriptie ben ik bezig met het verwerken van de resultaten in SPSS (jippi, not).
Nu loop ik echt helemaal vast!
Ik heb een vragenlijst gehouden met likert-schaal vragen. Deze heb ik allemaal ingevoerd in SPSS, no problem. Nu heb ik de verschillende variabelen die samen één item vormen samengevoegd, eerst heb ik een Cronbach's Alpha uitgevoerd om te kijken of dit kon, no problem.
Mijn vragenlijst bestond uit 2 afbeeldingen. Nu wil ik de uitkomsten voor deze twee afbeeldingen met elkaar vergelijken. Hoe doe ik dit?
De data van de twee afbeeldingen staat wel in één SPSS bestand.
Ik dacht aan een ANOVA, maar welke gegevens moet ik dan waar invoeren?
Moet ik voor de afbeeldingen ook variabelen aanmaken? Hoe doe ik dan zonder dat SPSS er niet mee kan rekenen (had ik net namelijk).
Ik heb het idee dat ik een variabele mis ofzo, maar zou niet weten welke en hoe ik deze dan in moet voeren.
Wie kan mij helpen? Ik word er onderhand een beetje wanhopig van!
Hoi!
Voor mijn masterscriptie ben ik bezig met het verwerken van de resultaten in SPSS (jippi, not).
Nu loop ik echt helemaal vast!
Ik heb een vragenlijst gehouden met likert-schaal vragen. Deze heb ik allemaal ingevoerd in SPSS, no problem. Nu heb ik de verschillende variabelen die samen één item vormen samengevoegd, eerst heb ik een Cronbach's Alpha uitgevoerd om te kijken of dit kon, no problem.
Mijn vragenlijst bestond uit 2 afbeeldingen. Nu wil ik de uitkomsten voor deze twee afbeeldingen met elkaar vergelijken. Hoe doe ik dit?
De data van de twee afbeeldingen staat wel in één SPSS bestand.
Ik dacht aan een ANOVA, maar welke gegevens moet ik dan waar invoeren?
Moet ik voor de afbeeldingen ook variabelen aanmaken? Hoe doe ik dan zonder dat SPSS er niet mee kan rekenen (had ik net namelijk).
Ik heb het idee dat ik een variabele mis ofzo, maar zou niet weten welke en hoe ik deze dan in moet voeren.
Wie kan mij helpen? Ik word er onderhand een beetje wanhopig van!
--
Samengevat: Je wil eerst controleren of de irritante reclames inderdaad irritanter waren dan de niet-irritante reclames en daarna analyseren of deze een grotere naamsbekendheid creëren. Klopt die samenvatting?quote:
Mensen!
(Ik weet, 1st post, maar daar komt verandering in).
Ik ben bezig met m'n afstudeerscriptie en zit op dit moment helemaal vast met SPSS analyse.
Ik doe onderzoek naar relatie tussen irritatie binnen een reclame en naamsbekendheid.
Er zijn 2 vragenlijsten rondgegaan. De eerste om de irritatie te meten en de 2e om de naamsbekendheid te meten.
Dit was vooral met likert scale.
Het probleem is nu om de hypotheses te testen..
Er is gebruik gemaakt van 2 irritante reclames (vanish & zalando) en 2 niet-irritante reclames (kia en crystal clear)
Heb dus 4 onafhankelijke groepen (reclames) binnen een onafhankelijke variabele (Soort reclame)
Ik wil nu het volgende bewijzen:
Een test laat zien dat de irritante reclame meer irritatie opleverde dan de niet-irritante reclame.
Onafhankelijk: Soort Reclame. Afhankelijk: Ervaren irritatie.
Een reclame die irritatie bevat zorgt voor een hogere naamsbekendheid dan een niet-irritante reclame.
Onafhankelijk: Irritatie Afhankelijk: Naamsbekendheid (recall)
Er is mij gezegd dat ik gebruik moet maken van een ANOVA, maar dan kom ik bij het probleem, hoe ik een irritante reclame vergelijk met een niet-irritante reclame en hoe ik dan de onafhankelijke variabele invoer?
Als iemand weet hoe dit werkt, dank is groot!!
Eerste stap is om te controleren of alle items op je vragenlijst hetzelfde meten (volgens je volgende post is dat zo). Daarna kun je totaalscores maken als je wil per reclame. Je kunt vervolgens óf de irritante reclames samenvoegen en de niet-irritante reclames toevoegen en een t-test uitvoeren. Of je kunt een ANOVA doen met 4 groepen (de reclames). Je afhankelijke variabele is dan irritatiefactor, je onafhankelijke variabele is dan de reclame.
Daarna kun je eenzelfde ANOVA (of t-test) doen met naamsbekendheid als afhankelijke variabele in plaats van de irritatiefactor.
Even uit interesse: Gaat het om een hbo of wo scriptie en welke studie doe je?
WO, Business Economics.
Heb de variabelen samengevoegd en doormiddel van gepairde t-tests kom ik nu al erg ver
Wanneer ik een ANOVA zou doen..
Hoe kan ik SPSS dan onafhankelijke variabele soort reclame invoeren...?
Alvast bedankt, en tnx voor je antwoord
Heb de variabelen samengevoegd en doormiddel van gepairde t-tests kom ik nu al erg ver
Wanneer ik een ANOVA zou doen..
Hoe kan ik SPSS dan onafhankelijke variabele soort reclame invoeren...?
Alvast bedankt, en tnx voor je antwoord
--
Variabele aanmaken en die de waardes 1-4 geven waarbij je elke waarde een label geeft van een reclame.quote:
WO, Business Economics.
Heb de variabelen samengevoegd en doormiddel van gepairde t-tests kom ik nu al erg ver
Wanneer ik een ANOVA zou doen..
Hoe kan ik SPSS dan onafhankelijke variabele soort reclame invoeren...?
Alvast bedankt, en tnx voor je antwoord
Ja, maar alle respondenten zien de 4 reclames hé, dan lukt het me niet om reclame 1 te koppelen aan irritatie 1. Daarom lijkt het me veel idealiter om gebruik te maken van de paired t test
--
Hoezo niet? Reclame is gewoon een within-subjects-factor toch? Of heb je irritatie niet per reclame gemeten?quote:
Ja, maar alle respondenten zien de 4 reclames hé, dan lukt het me niet om reclame 1 te koppelen aan irritatie 1. Daarom lijkt het me veel idealiter om gebruik te maken van de paired t test
En je hebt een ANOVA nodig om alle 4 de condities tegelijk te analyseren, dat gaat niet met een t-toets.
Ik heb de irritatie per reclame gemeten, toen mbv compute variable ervaren irritatie irritante reclame gemaakt en een met ervaren irritatie niet-irritante reclame.
Mbv t-toets dat irritante reclame meer irritatie oplevert dan een niet-irritante reclame.
Bewustzijn irritante reclames samengevoegd + bewustzijn niet-irritante reclames samengevoegd.
T-toets
Bewustzijn irritante reclames hoger dan niet-irritant.
Mij is verteld dat het ook op deze manier kon?
Zou je misschien kunnen uitleggen hoe ik dan reclame dan in SPSS kan invoeren ?
Mbv t-toets dat irritante reclame meer irritatie oplevert dan een niet-irritante reclame.
Bewustzijn irritante reclames samengevoegd + bewustzijn niet-irritante reclames samengevoegd.
T-toets
Bewustzijn irritante reclames hoger dan niet-irritant.
Mij is verteld dat het ook op deze manier kon?
Zou je misschien kunnen uitleggen hoe ik dan reclame dan in SPSS kan invoeren ?
--
En dan hoe jij in variable view het eruit zou laten zien?
Super dat je reageert trouwens
Ik ga ervanuit dat ik het op deze manier met irritante reclames en niet irritante reclames en t nog op een juiste manier doe..
Super dat je reageert trouwens
Ik ga ervanuit dat ik het op deze manier met irritante reclames en niet irritante reclames en t nog op een juiste manier doe..
--
Zo kan het ook, alleen lijkt het wat onlogisch voor je vraag of de irritante reclames daadwerkelijk irritant zijn. Ik ken je data niet, maar stel de niet irritante reclames scoren 2 en 2 op de irritatieschaal. En de irritante reclames scoren 2 en 7. Dan is je gemiddelde niet-irritante reclame 2 en je gemiddelde irritante reclame 4,5, waardoor de irritante reclames irritanter lijken te zijn (kromme zin maar je snapt het vast.) Maar eigenlijk is er maar 1 reclame irritanter dan de andere 3. Dus voor het controleren of de reclames daadwerkelijk irritant/niet-irritant zijn, kun je beter 4 groepen overhouden. Omdat het een within-subject-factor is, kom je uit bij een repeated-measures-ANOVA. Als je de irritatiescores van de 4 reclames hebt kom je er wel. over die RM-ANOVA kun je vast genoeg vinden in je statistiek boeken/internet.quote:
Ik heb de irritatie per reclame gemeten, toen mbv compute variable ervaren irritatie irritante reclame gemaakt en een met ervaren irritatie niet-irritante reclame.
Mbv t-toets dat irritante reclame meer irritatie oplevert dan een niet-irritante reclame.
Bewustzijn irritante reclames samengevoegd + bewustzijn niet-irritante reclames samengevoegd.
T-toets
Bewustzijn irritante reclames hoger dan niet-irritant.
Mij is verteld dat het ook op deze manier kon?
Zou je misschien kunnen uitleggen hoe ik dan reclame dan in SPSS kan invoeren ?
Top, dankjewel! Ik ga er eens achteraan, ben tenminste al 1000 x verder door middel van t-test voor het feedback moment, dan zonder deze antwoorden., had geen flauw idee waar te beginnen.
--
Ik moet een interactie tussen een gestandaardiseerde continue variabele en een categorische variabele interpreteren. De interactie is significant, maar de levels van de categorische variabele binnen de continue variabele (op zowel z=-1 als z=+1) verschillen niet. Het is een disordinale interactie (bij z=-1 omgekeerd patroon t.o.v. z=+1).
Hoe interpreteer ik deze interactie dan met behulp van toetsen? Als ik een plot maak, zie ik duidelijk dat de regressielijnen kruisen. De interactietoets is ook significant. Maar ik moet ook uitleggen welke "cellen" (ik noem het cellen, omdat we van de continue variabele een punt hebben gekozen) van elkaar verschillen. Hoe krijg ik de toetsen die dat laten zien?
Hoe interpreteer ik deze interactie dan met behulp van toetsen? Als ik een plot maak, zie ik duidelijk dat de regressielijnen kruisen. De interactietoets is ook significant. Maar ik moet ook uitleggen welke "cellen" (ik noem het cellen, omdat we van de continue variabele een punt hebben gekozen) van elkaar verschillen. Hoe krijg ik de toetsen die dat laten zien?
Vorig jaar heb ik mijn HBO afgerond en ben op dit moment bezig met een schakeljaar om volgend jaar te starten met de Master Business Administration. In dit schakeljaar moet je ook een klein onderzoek houden. Daarbij is het de bedoeling dat je SPSS gebruikt om de resultaten te interpreteren, door mijn HBO achtergrond heb ik daar helaas weinig ervaring in. Daarom heb ik een korte vraag:
Ik ben aan het onderzoeken of de afstand, gemeten in kilometers, invloed heeft op de resultaten van een alliantie. De volgende variabele heb ik:
Dependent: Performance (1. Objective not accomplished, 2. partially accomplished and 3, met) -> ordinaal
Independent: Geographical distance (1. Low distance, 2. Moderate distance, 3. High distance) -> nominaal
Daarnaast heb ik twee control variables; Subsidie en aantal partners in de alliantie -> beide zijn scale.
Ik heb een drietal hypotheses om te analysere of er een zogenaamde U-shape is:
1)een lage geografische afstand heeft een negatieve invloed op de performance;
2) een optimale geografische afstand heeft een positieve invloed op de performance;
3) een grote geografische afstand heeft een negatieve invloed op de performance.
Kan iemand mij helpen met een aanzet te geven welke test het best te gebruik is in SPSS? Graag via de makkelijkste weg.
Hartelijk dank!
Ik ben aan het onderzoeken of de afstand, gemeten in kilometers, invloed heeft op de resultaten van een alliantie. De volgende variabele heb ik:
Dependent: Performance (1. Objective not accomplished, 2. partially accomplished and 3, met) -> ordinaal
Independent: Geographical distance (1. Low distance, 2. Moderate distance, 3. High distance) -> nominaal
Daarnaast heb ik twee control variables; Subsidie en aantal partners in de alliantie -> beide zijn scale.
Ik heb een drietal hypotheses om te analysere of er een zogenaamde U-shape is:
1)een lage geografische afstand heeft een negatieve invloed op de performance;
2) een optimale geografische afstand heeft een positieve invloed op de performance;
3) een grote geografische afstand heeft een negatieve invloed op de performance.
Kan iemand mij helpen met een aanzet te geven welke test het best te gebruik is in SPSS? Graag via de makkelijkste weg.
Hartelijk dank!
Ik heb voor mijn masteronderzoek (geneeskunde, EUR) een dataset in SPSS met behandelgegevens van patiënten. Per patiënt heb ik meerdere regels met behandelinformatie, waarbij alle 'baseline' informatie steeds hetzelfde is.
Kan ik de regels die bij één patiënt horen koppelen, zodat SPSS al die regels als één case ziet?
Kan ik de regels die bij één patiënt horen koppelen, zodat SPSS al die regels als één case ziet?
Restructure cases into variables in de Restucture Data Wizard (Data > Restructure). Of via syntax
| 1 | CASESTOVARS |
Beste heren/dames,
Om te beginnen volg ik een opleiding die niets te maken heeft met Wiskunde (Bedrijfskundige Informatica). Ik ben bezig met mijn afstudeerscriptie. Hier behandel ik een probleemgroepinteractietabel. Ik dien aan te geven (op procentuele wijze) dat het oplossen van een x aantal problemen van de ene probleemgroep,tegelijkertijd een x-aantal problemen oplost van een andere probleemgroep.
Ik dien dit uit te rekenen met een berekening, en ik heb werkelijk geen idee hoe ik dit moet aanpakken. Ik zou jullie eeuwig dankbaar zijn als jullie mij hierbij kunnen helpen, omdat dit mijn laatste onderdeel is wat ik nog moet uitvogelen!
Ik zal het nog even aantonen met een voorbeeldje:
Er zijn 2 probleemgroepen:
Probleemgroep A:
Probleem 1
Probleem 2
Probleem 3
Probleemgroep B:
Probleem 4
Probleem 5
Probleem 6
Ik wil dus aangeven dat het onderlinge verband tussen probleemgroep A en B is, dat bijvoorbeeld het oplossen van probleem 2 tegelijkertijd probleem 5 en 6 van probleemgroep B oplost. Dit wil ik procentueel aantonen.
Hoe dien ik dit aan te geven met een berekening? En hoe heet deze berekening, is er een benoeming voor deze methode? Ik dien namelijk literair te onderbouwen hoe ik aan de berekening kom.. Ik heb even diep in mijn geheugen gegraven, in het kader van dit voorbeeldje ben ik op 1/3e x 2/3e gekomen, vraag me niet hoe ik daarop kom..
ik kan jullie alleen maar eeuwig dankbaar zijn. Ik hoop echt dat jullie mij zsm kunnen helpen!
Om te beginnen volg ik een opleiding die niets te maken heeft met Wiskunde (Bedrijfskundige Informatica). Ik ben bezig met mijn afstudeerscriptie. Hier behandel ik een probleemgroepinteractietabel. Ik dien aan te geven (op procentuele wijze) dat het oplossen van een x aantal problemen van de ene probleemgroep,tegelijkertijd een x-aantal problemen oplost van een andere probleemgroep.
Ik dien dit uit te rekenen met een berekening, en ik heb werkelijk geen idee hoe ik dit moet aanpakken. Ik zou jullie eeuwig dankbaar zijn als jullie mij hierbij kunnen helpen, omdat dit mijn laatste onderdeel is wat ik nog moet uitvogelen!
Ik zal het nog even aantonen met een voorbeeldje:
Er zijn 2 probleemgroepen:
Probleemgroep A:
Probleem 1
Probleem 2
Probleem 3
Probleemgroep B:
Probleem 4
Probleem 5
Probleem 6
Ik wil dus aangeven dat het onderlinge verband tussen probleemgroep A en B is, dat bijvoorbeeld het oplossen van probleem 2 tegelijkertijd probleem 5 en 6 van probleemgroep B oplost. Dit wil ik procentueel aantonen.
Hoe dien ik dit aan te geven met een berekening? En hoe heet deze berekening, is er een benoeming voor deze methode? Ik dien namelijk literair te onderbouwen hoe ik aan de berekening kom.. Ik heb even diep in mijn geheugen gegraven, in het kader van dit voorbeeldje ben ik op 1/3e x 2/3e gekomen, vraag me niet hoe ik daarop kom..
ik kan jullie alleen maar eeuwig dankbaar zijn. Ik hoop echt dat jullie mij zsm kunnen helpen!
Dag,
Ik heb een vraag over welke analyse ik moet gebruiken bij SPSS.
Ikzelf kom er niet uit.
Ik wil kijken of er een verband bestaat tussen de leeftijd + ervaring en aan de andere kant de leerstijl van de verpleegkundige.
Een kort overzicht van mijn data:
Onafhankelijke variabelen:
- Leeftijd
- Ervaring in de zorg
Afhankelijke variabelen:
Voor elke respondent heb ik een score op elke vijf leerstijlen, dus vijf scores in totaal.
Bijv:
33 op leren door nieuwe zaken toe te voegen
80 op leren door de theorie
55 op leren door doen
30 op leren door reflectie
60 op leren door sociale interactie
Graag zou ik hier een regressieanalyse over willen doen, maar ik weet niet hoe dat moet met meerdere afhankelijke variabelen/waarden.
Ik heb een vraag over welke analyse ik moet gebruiken bij SPSS.
Ikzelf kom er niet uit.
Ik wil kijken of er een verband bestaat tussen de leeftijd + ervaring en aan de andere kant de leerstijl van de verpleegkundige.
Een kort overzicht van mijn data:
Onafhankelijke variabelen:
- Leeftijd
- Ervaring in de zorg
Afhankelijke variabelen:
Voor elke respondent heb ik een score op elke vijf leerstijlen, dus vijf scores in totaal.
Bijv:
33 op leren door nieuwe zaken toe te voegen
80 op leren door de theorie
55 op leren door doen
30 op leren door reflectie
60 op leren door sociale interactie
Graag zou ik hier een regressieanalyse over willen doen, maar ik weet niet hoe dat moet met meerdere afhankelijke variabelen/waarden.
Ik ben momenteel bezig met een onderzoek naar de link tussen crowdfunding en innovativiteit.
Mijn hypothese is dat projecten die innovatiever zijn succesvoller zullen zijn.
Ik heb de scores voor innovativiteit van 100 projecten; van 1=niet innovatief tot 5=zeer innovatief, dit is dus een ordinale schaal.
Het succes is ook op ordinale wijze gemeten met 1=niet succesvol tot 10=succesvol.
Daarnaast heb ik ook veel data die als controle variabelen gebruikt kunnen worden. Deze controle varriabelen zijn rente, looptijd lening en risico en zijn op scale niveau gemeten.
Ik wil met behulp van een regressie bekijken wat de invloed van innovativiteit op succes is, gecontroleerd voor de 3 controlevariabelen. (Het is eventueel ook een optie om van innovativiteit een dichotome score te maken van; 1=niet innovatief 2=innovatief)
Hoe voer ik deze ordinale lineaire regressie uit?
Ik heb al gekeken bij regression--ordinal--- en heb succes(dependent), innovativeness(factor) en risk, rente and looptijd(coovariaat) meegenomen.
Is dit de juiste keuze? En hoe kan dan zien wat de invloed van de controle variabelen is? En hoe kan ik het effect van innovativiteit op succes zien gecontroleerd voor de 3 controle variabelen?
Mijn hypothese is dat projecten die innovatiever zijn succesvoller zullen zijn.
Ik heb de scores voor innovativiteit van 100 projecten; van 1=niet innovatief tot 5=zeer innovatief, dit is dus een ordinale schaal.
Het succes is ook op ordinale wijze gemeten met 1=niet succesvol tot 10=succesvol.
Daarnaast heb ik ook veel data die als controle variabelen gebruikt kunnen worden. Deze controle varriabelen zijn rente, looptijd lening en risico en zijn op scale niveau gemeten.
Ik wil met behulp van een regressie bekijken wat de invloed van innovativiteit op succes is, gecontroleerd voor de 3 controlevariabelen. (Het is eventueel ook een optie om van innovativiteit een dichotome score te maken van; 1=niet innovatief 2=innovatief)
Hoe voer ik deze ordinale lineaire regressie uit?
Ik heb al gekeken bij regression--ordinal--- en heb succes(dependent), innovativeness(factor) en risk, rente and looptijd(coovariaat) meegenomen.
Is dit de juiste keuze? En hoe kan dan zien wat de invloed van de controle variabelen is? En hoe kan ik het effect van innovativiteit op succes zien gecontroleerd voor de 3 controle variabelen?
Beste Fokkers,
Ik werk aan mijn master thesis (marketing management) en zit met de volgende situatie en kom er niet helemaal uit. Wellicht heeft iemand een idee?
Ik heb 3 groepen die allen een verschillende combinatie van advertenties hebben gezien. Als dependent variable heb ik click-through intention (een 7 scale van hoe aannemelijk het is dat de respondent op de afsluitende/online advertentie geklikt heeft).
De groepen zien er als volgt uit:
Groep 1: Eerst radio advertentie zonder humor vervolgens een online advertentie
Groep 2: Eerst radio advertentie met humor vervolgens een online advertentie
Groep 3: eerst online advertentie en vervolgens weer een online advertentie.
Mijn hypotheses:
H1: Groep 1 heeft een hogere click-through intention dan Groep 3
H2: Groep 2 heeft een hogere click-through intention dan Groep 1.
Ik heb dus geen full factorial design omdat mijn moderator alleen van toepassing is op Groep 1 en Groep 2. Zelf zat ik te denken aan een Indepentent sample T test en dan gewoon groep 1 met groep 3 vergelijken en groep 2 met groep 1 vergelijken.
Mijn begeleider suggereert dat er een andere/betere test is om de analyse te doen. Wat zouden jullie doen?
Alvast hartelijk dank voor de moeite!
Ik werk aan mijn master thesis (marketing management) en zit met de volgende situatie en kom er niet helemaal uit. Wellicht heeft iemand een idee?
Ik heb 3 groepen die allen een verschillende combinatie van advertenties hebben gezien. Als dependent variable heb ik click-through intention (een 7 scale van hoe aannemelijk het is dat de respondent op de afsluitende/online advertentie geklikt heeft).
De groepen zien er als volgt uit:
Groep 1: Eerst radio advertentie zonder humor vervolgens een online advertentie
Groep 2: Eerst radio advertentie met humor vervolgens een online advertentie
Groep 3: eerst online advertentie en vervolgens weer een online advertentie.
Mijn hypotheses:
H1: Groep 1 heeft een hogere click-through intention dan Groep 3
H2: Groep 2 heeft een hogere click-through intention dan Groep 1.
Ik heb dus geen full factorial design omdat mijn moderator alleen van toepassing is op Groep 1 en Groep 2. Zelf zat ik te denken aan een Indepentent sample T test en dan gewoon groep 1 met groep 3 vergelijken en groep 2 met groep 1 vergelijken.
Mijn begeleider suggereert dat er een andere/betere test is om de analyse te doen. Wat zouden jullie doen?
Alvast hartelijk dank voor de moeite!
Kun je het niet gewoon als continue variabele gebruiken? Als je N hoog genoeg is en de data genoeg spreiding laat zien kun je volgens mij gewoon beiden als continue gebruiken en dat maakt het een heel stuk gemakkelijker.quote:
Ik ben momenteel bezig met een onderzoek naar de link tussen crowdfunding en innovativiteit.
Mijn hypothese is dat projecten die innovatiever zijn succesvoller zullen zijn.
Ik heb de scores voor innovativiteit van 100 projecten; van 1=niet innovatief tot 5=zeer innovatief, dit is dus een ordinale schaal.
Het succes is ook op ordinale wijze gemeten met 1=niet succesvol tot 10=succesvol.
Daarnaast heb ik ook veel data die als controle variabelen gebruikt kunnen worden. Deze controle varriabelen zijn rente, looptijd lening en risico en zijn op scale niveau gemeten.
Ik wil met behulp van een regressie bekijken wat de invloed van innovativiteit op succes is, gecontroleerd voor de 3 controlevariabelen. (Het is eventueel ook een optie om van innovativiteit een dichotome score te maken van; 1=niet innovatief 2=innovatief)
Hoe voer ik deze ordinale lineaire regressie uit?
Ik heb al gekeken bij regression--ordinal--- en heb succes(dependent), innovativeness(factor) en risk, rente and looptijd(coovariaat) meegenomen.
Is dit de juiste keuze? En hoe kan dan zien wat de invloed van de controle variabelen is? En hoe kan ik het effect van innovativiteit op succes zien gecontroleerd voor de 3 controle variabelen?
Je spreekt over een moderator maar die zie ik niet genoemd worden. Als je twee losse t-toetsen gebruikt, gebruik je niet je volledige data. Het beste is (m.i.) om een anova te doen met 2 planned contrasten: groep 1 t.o.v. groep 3, en groep 2 tov groep 1.quote:
Beste Fokkers,
Ik werk aan mijn master thesis (marketing management) en zit met de volgende situatie en kom er niet helemaal uit. Wellicht heeft iemand een idee?
Ik heb 3 groepen die allen een verschillende combinatie van advertenties hebben gezien. Als dependent variable heb ik click-through intention (een 7 scale van hoe aannemelijk het is dat de respondent op de afsluitende/online advertentie geklikt heeft).
De groepen zien er als volgt uit:
Groep 1: Eerst radio advertentie zonder humor vervolgens een online advertentie
Groep 2: Eerst radio advertentie met humor vervolgens een online advertentie
Groep 3: eerst online advertentie en vervolgens weer een online advertentie.
Mijn hypotheses:
H1: Groep 1 heeft een hogere click-through intention dan Groep 3
H2: Groep 2 heeft een hogere click-through intention dan Groep 1.
Ik heb dus geen full factorial design omdat mijn moderator alleen van toepassing is op Groep 1 en Groep 2. Zelf zat ik te denken aan een Indepentent sample T test en dan gewoon groep 1 met groep 3 vergelijken en groep 2 met groep 1 vergelijken.
Mijn begeleider suggereert dat er een andere/betere test is om de analyse te doen. Wat zouden jullie doen?
Alvast hartelijk dank voor de moeite!
Dat gezegd hebbende, de data zullen niet heel anders zijn als je mijn manier gebruikt.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Dank voor je reactie! Mijn opzet was als volgt:quote:Je spreekt over een moderator maar die zie ik niet genoemd worden. Als je twee losse t-toetsen gebruikt, gebruik je niet je volledige data. Het beste is (m.i.) om een anova te doen met 2 planned contrasten: groep 1 t.o.v. groep 3, en groep 2 tov groep 1.
Dat gezegd hebbende, de data zullen niet heel anders zijn als je mijn manier gebruikt.
Dependent variable is click-through intention (7 punts schaal).
Independent variable is "synergy between radio en online advertising" met 2 levels: ja of nee. Ja = eerst radio advertentie en dan online advertentie en Nee= twee keer online advertentie.
Nu verwacht ik dat radio-online beter werkt dan online-online. En ik verwacht dat radio-online extra goed werkt als de radio advertentie humor bevat.
In mijn ogen is mijn moderator dus "wel of geen humor in de radio advertentie". Is dit eigenlijk wel een echte moderator? En met welke test maak ik wél gebruik van mijn volledige data?
Bedankt. Dat is inderdaad een optie. Ik ga even kijken of het normaal verdeeld is.quote:
[..]
Kun je het niet gewoon als continue variabele gebruiken? Als je N hoog genoeg is en de data genoeg spreiding laat zien kun je volgens mij gewoon beiden als continue gebruiken en dat maakt het een heel stuk gemakkelijker.
[..]
Je spreekt over een moderator maar die zie ik niet genoemd worden. Als je twee losse t-toetsen gebruikt, gebruik je niet je volledige data. Het beste is (m.i.) om een anova te doen met 2 planned contrasten: groep 1 t.o.v. groep 3, en groep 2 tov groep 1.
Dat gezegd hebbende, de data zullen niet heel anders zijn als je mijn manier gebruikt.
Ik zou het geen moderator noemen omdat je met deze optie niet weet of dat het gewoon een (main) effect van humor is, of dat er echt iets speciaals is qua humor op de radio.quote:
[..]
Dank voor je reactie! Mijn opzet was als volgt:
Dependent variable is click-through intention (7 punts schaal).
Independent variable is "synergy between radio en online advertising" met 2 levels: ja of nee. Ja = eerst radio advertentie en dan online advertentie en Nee= twee keer online advertentie.
Nu verwacht ik dat radio-online beter werkt dan online-online. En ik verwacht dat radio-online extra goed werkt als de radio advertentie humor bevat.
In mijn ogen is mijn moderator dus "wel of geen humor in de radio advertentie". Is dit eigenlijk wel een echte moderator? En met welke test maak ik wél gebruik van mijn volledige data?
Je kunt de test doen door middel van planned contrasten in een anova.
als online-online conditie 1 is
radio (geen humor) online = conditie 2
radio (humor) online = 3
dan doe je de volgende twee contrasten:
1
-1
0
hierbij kijk je of conditie 2 significant van 1 verschilt
en
0
1
-1
hierbij kijk je of conditie 3 significant van conditie 2 verschilt
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Deze vraag is vast al heel vaak gesteld,
dus ik ga even het topic doorlezen.........
Hoe zat dat ook al weer met thesistools, excel bestand & SPSS
Volgens mij kon ik dit vorig jaar nog prima invoeren en nu heb ik echt geen idee wat ik moet doen
-edit-
er komt al wat boven drijven! gelukkig
[ Bericht 9% gewijzigd door Probability op 19-05-2014 19:27:41 ]
dus ik ga even het topic doorlezen.........
Hoe zat dat ook al weer met thesistools, excel bestand & SPSS
Volgens mij kon ik dit vorig jaar nog prima invoeren en nu heb ik echt geen idee wat ik moet doen
-edit-
er komt al wat boven drijven! gelukkig
[ Bericht 9% gewijzigd door Probability op 19-05-2014 19:27:41 ]
Worry is a misuse of imagination
en met behulp van wat tutorials mijn vragen in spss ingevoerd (na wat moeite!)quote:
Deze vraag is vast al heel vaak gesteld,
dus ik ga even het topic doorlezen.........
Hoe zat dat ook al weer met thesistools, excel bestand & SPSS
Volgens mij kon ik dit vorig jaar nog prima invoeren en nu heb ik echt geen idee wat ik moet doen
-edit-
er komt al wat boven drijven! gelukkig
kon ik de antwoorden van de online enquete er zo inplakken
volgens mij begrijp ik het wel aardig
Worry is a misuse of imagination
Iemand hier die suggesties heeft voor een basis boek/tutorial voor statistische toetsen met R?
En zijn er verschillende R programma's? (Zo ja, adviezen over welke het beste werkt?)
En zijn er verschillende R programma's? (Zo ja, adviezen over welke het beste werkt?)
Een directe suggestie voor een goed boek heb ik niet, ik heb zelf het vooral door oefening en voorbeelden op internet geleerd. Er zijn niet verschillende R programma's (wel verschillende versies, maar in principe neem je gewoon de nieuwste). Ik raad je wel aan om een IDE te nemen, waarbij de makkelijkste waarschijnlijk Rstudio is. Een andere mogelijkheid is een plugin in Eclipse. Zo'n IDE maakt het leven een stuk makkelijker met debuggen en programmeren.quote:
Iemand hier die suggesties heeft voor een basis boek/tutorial voor statistische toetsen met R?
En zijn er verschillende R programma's? (Zo ja, adviezen over welke het beste werkt?)
Er zijn wel heel veel paketten die je kan installeren buiten de basis-R, maar dat installeren gaat vrij eenvoudig.
Enkele handige sites:
http://www.statmethods.net/ (vrij goed beginnersoverzicht van verschillende mogelijkheden, waaronder statistische tests en plotmogelijkheden. Ook nog handig voor de meer ervarener gebruiker als naslag.)
http://www.cookbook-r.com/ (bijna hetzelfde, plots zijn hier meer gefocused op het pakket ggplot2)
http://www.ats.ucla.edu/stat/r/whatstat/whatstat.htm (concreet overzichtje met statistische tests in R, weet niet of het volledig is).
You don't need a weatherman to know which way the wind blows.
---------------------------------------------------------------------------------------------------------------------------------------------
Album top 100 2024
---------------------------------------------------------------------------------------------------------------------------------------------
Album top 100 2024
Die IDE's bedoelde ik inderdaad, kon even niet op de naam komen.quote:
[..]
Een directe suggestie voor een goed boek heb ik niet, ik heb zelf het vooral door oefening en voorbeelden op internet geleerd. Er zijn niet verschillende R programma's (wel verschillende versies, maar in principe neem je gewoon de nieuwste). Ik raad je wel aan om een IDE te nemen, waarbij de makkelijkste waarschijnlijk Rstudio is. Een andere mogelijkheid is een plugin in Eclipse. Zo'n IDE maakt het leven een stuk makkelijker met debuggen en programmeren.
Er zijn wel heel veel paketten die je kan installeren buiten de basis-R, maar dat installeren gaat vrij eenvoudig.
Enkele handige sites:
http://www.statmethods.net/ (vrij goed beginnersoverzicht van verschillende mogelijkheden, waaronder statistische tests en plotmogelijkheden. Ook nog handig voor de meer ervarener gebruiker als naslag.)
http://www.cookbook-r.com/ (bijna hetzelfde, plots zijn hier meer gefocused op het pakket ggplot2)
http://www.ats.ucla.edu/stat/r/whatstat/whatstat.htm (concreet overzichtje met statistische tests in R, weet niet of het volledig is).
Bedankt voor de links, ik zal ze eens napluizen.
Eén van mijn independent variables in mijn regressie geeft een probability weer.
Ik neem aan dat ik deze variable niet 'zo maar' in een OLS-regressie (Stata) kan zetten?
Hoe kan ik dat het beste oplossen? Een logaritme van maken?
Ik neem aan dat ik deze variable niet 'zo maar' in een OLS-regressie (Stata) kan zetten?
Hoe kan ik dat het beste oplossen? Een logaritme van maken?
Beste mensen,
Ik ben bezig met een onderzoek. Het onderzoek gaat over het vergelijken van vragenlijsten. In verschillende vragenlijst worden manipulatie doorgevoerd met betrekking tot bijvoorbeeld aanspreekvorm en likert schalen. Door deze manipulaties zijn er vier verschillende versies van de vragenlijst.
Het is de bedoeling dat deze vier verschillende versies met elkaar worden vergeleken. Er dient dus een zekere significantietoets te worden uitgevoerd om te kijken of de verschillen tussen deze vragnelijsten significant zijn. Mijn vraag is nu welke toets kan ik hiervoor toepassen.
Even een kleine samenvatting: Ik ben dus op zoek naar een test met behulp van SPSS die vier vragenlijsten kan vergelijken, en dat ik zo kan zien of er per vraag sprake is van significante verschillen.
Iemand enig idee? Alvast bedankt!
Ik ben bezig met een onderzoek. Het onderzoek gaat over het vergelijken van vragenlijsten. In verschillende vragenlijst worden manipulatie doorgevoerd met betrekking tot bijvoorbeeld aanspreekvorm en likert schalen. Door deze manipulaties zijn er vier verschillende versies van de vragenlijst.
Het is de bedoeling dat deze vier verschillende versies met elkaar worden vergeleken. Er dient dus een zekere significantietoets te worden uitgevoerd om te kijken of de verschillen tussen deze vragnelijsten significant zijn. Mijn vraag is nu welke toets kan ik hiervoor toepassen.
Even een kleine samenvatting: Ik ben dus op zoek naar een test met behulp van SPSS die vier vragenlijsten kan vergelijken, en dat ik zo kan zien of er per vraag sprake is van significante verschillen.
Iemand enig idee? Alvast bedankt!
Iets meer uitleg is nodig. Zijn het vier onafhankelijke condities of is het een 2x2 design? Zijn de rvagen aan elkaar gerelateerd of onafhankelijk? Etc.quote:
Beste mensen,
Ik ben bezig met een onderzoek. Het onderzoek gaat over het vergelijken van vragenlijsten. In verschillende vragenlijst worden manipulatie doorgevoerd met betrekking tot bijvoorbeeld aanspreekvorm en likert schalen. Door deze manipulaties zijn er vier verschillende versies van de vragenlijst.
Het is de bedoeling dat deze vier verschillende versies met elkaar worden vergeleken. Er dient dus een zekere significantietoets te worden uitgevoerd om te kijken of de verschillen tussen deze vragnelijsten significant zijn. Mijn vraag is nu welke toets kan ik hiervoor toepassen.
Even een kleine samenvatting: Ik ben dus op zoek naar een test met behulp van SPSS die vier vragenlijsten kan vergelijken, en dat ik zo kan zien of er per vraag sprake is van significante verschillen.
Iemand enig idee? Alvast bedankt!
Algemene antwoord: anova
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Hoi allemaal,
ik heb een onderzoek waarbij ik vijf versies heb van mijn testmateriaal. Eentje als neutrale versie, de anderen hebben op vier plaatsen een verschillende manipulatie gehad, die dus allemaal een keer op verschillende plekken voorkomen, in de vier andere versies. Dus als 1 t/m 5 de verschillende manipulaties zijn, is het zoiets:
Versie 1: 1-1-1-1
Versie 2: 2-3-4-5
Versie 3: 3-4-5-2
Versie 4: 4-5-2-3
Versie 5: 5-2-3-4
Nu wil ik dus van de manipulaties weten of zij 'iets' uitmaken, met betrekking tot de neutrale conditie (1). Hoe de fuck moet dat? Ik studeer echt al eeuwen en het is denk ik zeven jaar geleden dat ik voor het laatst SPSS open had. Dus elke hulp is welkom.
Ik denk overigens dat het in de buurt van de Independant Samples T-Test komt, maar dan kan ik geen vijf verschillende manipulaties testen. Zie dit voorbeeld: http://www.spsshandboek.nl/independent_samples_t-test.html
ik heb een onderzoek waarbij ik vijf versies heb van mijn testmateriaal. Eentje als neutrale versie, de anderen hebben op vier plaatsen een verschillende manipulatie gehad, die dus allemaal een keer op verschillende plekken voorkomen, in de vier andere versies. Dus als 1 t/m 5 de verschillende manipulaties zijn, is het zoiets:
Versie 1: 1-1-1-1
Versie 2: 2-3-4-5
Versie 3: 3-4-5-2
Versie 4: 4-5-2-3
Versie 5: 5-2-3-4
Nu wil ik dus van de manipulaties weten of zij 'iets' uitmaken, met betrekking tot de neutrale conditie (1). Hoe de fuck moet dat?
Ik denk overigens dat het in de buurt van de Independant Samples T-Test komt, maar dan kan ik geen vijf verschillende manipulaties testen. Zie dit voorbeeld: http://www.spsshandboek.nl/independent_samples_t-test.html
Kan dat niet door middel van het selecteren van diverse cases. Kijk anders even in deze handleiding, ik weet niet of je er wat aan hebt. Had het net ook al geplaatst bij een andere oproep op dit forum:quote:
Hoi allemaal,
ik heb een onderzoek waarbij ik vijf versies heb van mijn testmateriaal. Eentje als neutrale versie, de anderen hebben op vier plaatsen een verschillende manipulatie gehad, die dus allemaal een keer op verschillende plekken voorkomen, in de vier andere versies. Dus als 1 t/m 5 de verschillende manipulaties zijn, is het zoiets:
Versie 1: 1-1-1-1
Versie 2: 2-3-4-5
Versie 3: 3-4-5-2
Versie 4: 4-5-2-3
Versie 5: 5-2-3-4
Nu wil ik dus van de manipulaties weten of zij 'iets' uitmaken, met betrekking tot de neutrale conditie (1). Hoe de fuck moet dat?
Ik denk overigens dat het in de buurt van de Independant Samples T-Test komt, maar dan kan ik geen vijf verschillende manipulaties testen. Zie dit voorbeeld: http://www.spsshandboek.nl/independent_samples_t-test.html
http://pc-en-internet.inf(...)ken-handleiding.html
Anders is er toch wel een docent op een Hogeschool die je hiermee kan helpen?
Iets meer informatie zou handig zijn.quote:
Hoi allemaal,
ik heb een onderzoek waarbij ik vijf versies heb van mijn testmateriaal. Eentje als neutrale versie, de anderen hebben op vier plaatsen een verschillende manipulatie gehad, die dus allemaal een keer op verschillende plekken voorkomen, in de vier andere versies. Dus als 1 t/m 5 de verschillende manipulaties zijn, is het zoiets:
Versie 1: 1-1-1-1
Versie 2: 2-3-4-5
Versie 3: 3-4-5-2
Versie 4: 4-5-2-3
Versie 5: 5-2-3-4
Nu wil ik dus van de manipulaties weten of zij 'iets' uitmaken, met betrekking tot de neutrale conditie (1). Hoe de fuck moet dat?
Ik denk overigens dat het in de buurt van de Independant Samples T-Test komt, maar dan kan ik geen vijf verschillende manipulaties testen. Zie dit voorbeeld: http://www.spsshandboek.nl/independent_samples_t-test.html
1. Wat en hoe vaak meet je je afhankelijke variabele? Is dat na alle 4 de manipulaties of na elke manipulatie?
2. Is je versie 1-5 tabel een voorbeeld of is het een realistische weergave? (volgt manipulatie 3 altijd na manipulatie 2, of kan de combinatie ook 4253 zijn bijvoorbeeld?)
3. wil je van elke variabele apart weten of deze invloed heeft of eerder of 2435(in welke volgorde dan ook) invloed heeft ten opzichte van 1111?

Ik heb de volgende data:
manipulatievariabele (2 experimentele, 1 controle), man/vrouw, reactietijd en hulp (ja of nee)
Het is zijn allemaal van losse personen (between subjects dus)
Nu wil ik weten of de reactietijd en/of hulpgedrag significant verschillen in de verschillende condities en wellicht ook nog of er man/vrouw verschillen zijn.
Heb zelf al verschillende ANOVAs uitgevoerd, maar wil eigenlijk experimentele conditie vergelijken met de controle (los van elkaar). Moet ik hiervoor dummy variabelen aanmaken oid? Of welke analyses moet ik draaien, ik snap het niet meer
manipulatievariabele (2 experimentele, 1 controle), man/vrouw, reactietijd en hulp (ja of nee)
Het is zijn allemaal van losse personen (between subjects dus)
Nu wil ik weten of de reactietijd en/of hulpgedrag significant verschillen in de verschillende condities en wellicht ook nog of er man/vrouw verschillen zijn.
Heb zelf al verschillende ANOVAs uitgevoerd, maar wil eigenlijk experimentele conditie vergelijken met de controle (los van elkaar). Moet ik hiervoor dummy variabelen aanmaken oid? Of welke analyses moet ik draaien, ik snap het niet meer
Ik moet met SPSS de een percentage van 2 variabelen bepalen.
Ik heb 1 variabele totale slaap en een andere variabele dromend over een range van verschillende diersoorten.
Nu moet ik dus het percentage dromend van totale slaap analyseren, maar geen idee hoe dit het beste te doen.
de vraag is letterlijk dit.
[quote]
Definieer ten slotte als variabele het percentage dat droomslaap uitmaakt van de totale slaap
[\]
Ik heb 1 variabele totale slaap en een andere variabele dromend over een range van verschillende diersoorten.
Nu moet ik dus het percentage dromend van totale slaap analyseren, maar geen idee hoe dit het beste te doen.
de vraag is letterlijk dit.
[quote]
Definieer ten slotte als variabele het percentage dat droomslaap uitmaakt van de totale slaap
[\]
Laaiend enthousiast kwam hij uit de brandende kerncentrale en keek stralen om zich heen!
Compute variable, percentage = droomslaap/totale slaap? Daarna kun je via descriptives nog het gemiddelde percentage opvragen van de hele groep.quote:
Ik moet met SPSS de een percentage van 2 variabelen bepalen.
Ik heb 1 variabele totale slaap en een andere variabele dromend over een range van verschillende diersoorten.
Nu moet ik dus het percentage dromend van totale slaap analyseren, maar geen idee hoe dit het beste te doen.
de vraag is letterlijk dit.
[quote]
Definieer ten slotte als variabele het percentage dat droomslaap uitmaakt van de totale slaap
[\]
Dus je hebt een 2(man/vrouw)*3(exp1/exp2/controle) between-subjects design met 2 afhankelijke variabelen(reactietijd/hulp)?quote:Op donderdag 5 juni 2014 00:10 schreef Andyy het volgende:
Ik heb de volgende data:
manipulatievariabele (2 experimentele, 1 controle), man/vrouw, reactietijd en hulp (ja of nee)
Het is zijn allemaal van losse personen (between subjects dus)
Nu wil ik weten of de reactietijd en/of hulpgedrag significant verschillen in de verschillende condities en wellicht ook nog of er man/vrouw verschillen zijn.
Heb zelf al verschillende ANOVAs uitgevoerd, maar wil eigenlijk experimentele conditie vergelijken met de controle (los van elkaar). Moet ik hiervoor dummy variabelen aanmaken oid? Of welke analyses moet ik draaien, ik snap het niet meer
Dan zou je in SPSS dus de volgende variabelen hebben:
Groep (met waarde 1, 2 of 3 (exp1/exp2/controle als labels))
Geslacht (met waarde 1 of 2 (man/vrouw als labels))
Reactietijd (in ms)
Hulp (met waarde 1 of 2 (ja/nee als labels))
Dan kun je toch gewoon een ANOVA doen met Groep als onafhankelijke variabele? Je zou eventueel ook 2 t-toetsen kunnen doen, waarbij je exp1 vergelijkt met controle en exp2 vergelijkt met controle.
Dit begrijp ik niet helemaal, ben redelijk beginneling met SPSS dus wat meer hulp is welkom.quote:
[..]
Compute variable, percentage = droomslaap/totale slaap? Daarna kun je via descriptives nog het gemiddelde percentage opvragen van de hele groep.
Als ik via compute variable voor de = Percentage invoer en daarna droomslaap/totale slaap krijg ik geen uitkomst.
Laaiend enthousiast kwam hij uit de brandende kerncentrale en keek stralen om zich heen!
Klik op compute variable, bij Target Variable typ je de naam van de nieuwe variabele in. Bij Numeric Expression, komt de formule te staan. Dubbelklik in de lijst links op de variabele DroomSlaap (afhankelijk van hoe je die hebt genoemd heet die dus anders.) Daarna klik je in het rekenmachientjesstukje op "/" en daarna klik je in de linker lijst dubbel op de variabele totale slaap. Vervolgens klik je op "*" in het rekenmachientje en typ je daarna 100. Daarna klik je op OK en dan komt je variabele met het percentage droomslaap ten opzichte van de totale slaap in je data venster te staan.quote:
[..]
Dit begrijp ik niet helemaal, ben redelijk beginneling met SPSS dus wat meer hulp is welkom.
Als ik via compute variable voor de = Percentage invoer en daarna droomslaap/totale slaap krijg ik geen uitkomst.
SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.
quote:
[..]
Klik op compute variable, bij Target Variable typ je de naam van de nieuwe variabele in. Bij Numeric Expression, komt de formule te staan. Dubbelklik in de lijst links op de variabele DroomSlaap (afhankelijk van hoe je die hebt genoemd heet die dus anders.) Daarna klik je in het rekenmachientjesstukje op "/" en daarna klik je in de linker lijst dubbel op de variabele totale slaap. Vervolgens klik je op "*" in het rekenmachientje en typ je daarna 100. Daarna klik je op OK en dan komt je variabele met het percentage droomslaap ten opzichte van de totale slaap in je data venster te staan.Bedankt, had niet meteen door dat er een nieuwe variabele gemaakt werdSPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.
Hiermee kan ik wel weer verderLaaiend enthousiast kwam hij uit de brandende kerncentrale en keek stralen om zich heen!
Nu zit ik met een volgend probleem waar ik mij even geen raad mee weet.
Kies een maat voor botdichtheid en relateer die aan het cumulatief rookgedrag (pyr), weer voor beide leden van de tweeling. (Grafisch en via regressie en voer de verschillende controles uit op de normaliteit.)
ik heb een dataset met gegevens over tweelingen en levensstijlen en botdichtheid
De verschillende maten voor botdichtheid worden aangegeven met respectievelijk LSx (Lumbar spine (g/cm**2)) FNx (Femoral neck (g/cm**2)) en FSx(Femoral shaft (g/cm**2)) dit is dus de meetlocatie van de botdichtheid aangegeven met een afkorting en een x waarbij de x een 1 of 2 kan zijn afhankelijk van bij welke tweeling de meting is gedaan.
Pyr staat voor pakjes gerookt per jaar (hoeft niet te betekenen dat ze nog roken)
Ik heb dus geen idee hoe ik die aan elkaar moet relateren, als ik er een lijngrafiek van maak krijg ik enkel hele vreemde grafieken en een boxplot lijkt me ook niet de beste oplossing.
Kies een maat voor botdichtheid en relateer die aan het cumulatief rookgedrag (pyr), weer voor beide leden van de tweeling. (Grafisch en via regressie en voer de verschillende controles uit op de normaliteit.)
ik heb een dataset met gegevens over tweelingen en levensstijlen en botdichtheid
De verschillende maten voor botdichtheid worden aangegeven met respectievelijk LSx (Lumbar spine (g/cm**2)) FNx (Femoral neck (g/cm**2)) en FSx(Femoral shaft (g/cm**2)) dit is dus de meetlocatie van de botdichtheid aangegeven met een afkorting en een x waarbij de x een 1 of 2 kan zijn afhankelijk van bij welke tweeling de meting is gedaan.
Pyr staat voor pakjes gerookt per jaar (hoeft niet te betekenen dat ze nog roken)
Ik heb dus geen idee hoe ik die aan elkaar moet relateren, als ik er een lijngrafiek van maak krijg ik enkel hele vreemde grafieken en een boxplot lijkt me ook niet de beste oplossing.
Laaiend enthousiast kwam hij uit de brandende kerncentrale en keek stralen om zich heen!
Beste mensen heeft er iemand enige ervaring met excel VBA?
Voor mijn project moet ik het stemproces(optellen van de stemmen in correcte hoeveelheden bij elke partij) genereren.
Nu heb ik om kleins te beginnen het volgende geprobeerd, maar mijn Excel loopt elke keer vast omdat ik denk dat deze code iets oneindig doet?
In excel mogen geen formules gebruikt worden alleen vaste waardes, als test heb ik er ook 2 neergezet.
Wat ik wil bereiken is dat het gegeven aantal stemmen wordt verdeeld over de partijen in dit voorbeeldje 2 partijen en 50stemmen, Partij1 = 23 stemmen part2 = 22 stemmen. En dat wanneer part1 vol zit hij door gaat naar 2. Het max stemmen van een partij staat in excel dus. Uiteindelijk moeten de uitkomsten in excel komen naast de van te voren ingevoerde cijfers.
Wie kan mij hiermee helpen?
De code is als volgt:
Sub st31()
Dim stemmen, aftel, stemmenpart1, stemmenpart2 As LongPtr
Dim tekst1, tekst2 As String
stemmen = 50
stemmenpart1 = 0
stemmenpart2 = 0
aftel = 1
Do
Loop While stemmen >= 0
stemmen = stemmen - aftel
Do While stemmenpart1 <= Worksheets("st").Cells(3, 2)
stemmenpart1 = stemmenpart1 + aftel
Loop
If stemmenpart1 = True Then
tekst1 = stemmenpart1
End If
Do While stemmenpart1 = Worksheets("st").Cells(3, 2)
stemmenpart2 = stemmenpart2 + aftel
Loop
If stemmenpart2 = True Then
tekst2 = stemmenpart2
End If
Worksheets("st").Cells(3, 3) = tekst1
Worksheets("st").Cells(3, 4) = tekst2
End Sub
Voor mijn project moet ik het stemproces(optellen van de stemmen in correcte hoeveelheden bij elke partij) genereren.
Nu heb ik om kleins te beginnen het volgende geprobeerd, maar mijn Excel loopt elke keer vast omdat ik denk dat deze code iets oneindig doet?
In excel mogen geen formules gebruikt worden alleen vaste waardes, als test heb ik er ook 2 neergezet.
Wat ik wil bereiken is dat het gegeven aantal stemmen wordt verdeeld over de partijen in dit voorbeeldje 2 partijen en 50stemmen, Partij1 = 23 stemmen part2 = 22 stemmen. En dat wanneer part1 vol zit hij door gaat naar 2. Het max stemmen van een partij staat in excel dus. Uiteindelijk moeten de uitkomsten in excel komen naast de van te voren ingevoerde cijfers.
Wie kan mij hiermee helpen?
De code is als volgt:
Sub st31()
Dim stemmen, aftel, stemmenpart1, stemmenpart2 As LongPtr
Dim tekst1, tekst2 As String
stemmen = 50
stemmenpart1 = 0
stemmenpart2 = 0
aftel = 1
Do
Loop While stemmen >= 0
stemmen = stemmen - aftel
Do While stemmenpart1 <= Worksheets("st").Cells(3, 2)
stemmenpart1 = stemmenpart1 + aftel
Loop
If stemmenpart1 = True Then
tekst1 = stemmenpart1
End If
Do While stemmenpart1 = Worksheets("st").Cells(3, 2)
stemmenpart2 = stemmenpart2 + aftel
Loop
If stemmenpart2 = True Then
tekst2 = stemmenpart2
End If
Worksheets("st").Cells(3, 3) = tekst1
Worksheets("st").Cells(3, 4) = tekst2
End Sub
Scatterplot, en dan evt. een lijn erdoor laten plotten, in spss komt dan ook de regressievergelijking erbij te staan.quote:
Nu zit ik met een volgend probleem waar ik mij even geen raad mee weet.
Kies een maat voor botdichtheid en relateer die aan het cumulatief rookgedrag (pyr), weer voor beide leden van de tweeling. (Grafisch en via regressie en voer de verschillende controles uit op de normaliteit.)
ik heb een dataset met gegevens over tweelingen en levensstijlen en botdichtheid
De verschillende maten voor botdichtheid worden aangegeven met respectievelijk LSx (Lumbar spine (g/cm**2)) FNx (Femoral neck (g/cm**2)) en FSx(Femoral shaft (g/cm**2)) dit is dus de meetlocatie van de botdichtheid aangegeven met een afkorting en een x waarbij de x een 1 of 2 kan zijn afhankelijk van bij welke tweeling de meting is gedaan.
Pyr staat voor pakjes gerookt per jaar (hoeft niet te betekenen dat ze nog roken)
Ik heb dus geen idee hoe ik die aan elkaar moet relateren, als ik er een lijngrafiek van maak krijg ik enkel hele vreemde grafieken en een boxplot lijkt me ook niet de beste oplossing.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>

Het lijkt me dat "Loop While stemmen >= 0" inderdaad een oneindige loop is. Daar moet iets als "and stemmen < 51" bij. En volgens mij wordt er dan nog niet helemaal juist geteld maar dat merk je vanzelf wel.quote:
Beste mensen heeft er iemand enige ervaring met excel VBA?
Voor mijn project moet ik het stemproces(optellen van de stemmen in correcte hoeveelheden bij elke partij) genereren.
Nu heb ik om kleins te beginnen het volgende geprobeerd, maar mijn Excel loopt elke keer vast omdat ik denk dat deze code iets oneindig doet?
In excel mogen geen formules gebruikt worden alleen vaste waardes, als test heb ik er ook 2 neergezet.
Wat ik wil bereiken is dat het gegeven aantal stemmen wordt verdeeld over de partijen in dit voorbeeldje 2 partijen en 50stemmen, Partij1 = 23 stemmen part2 = 22 stemmen. En dat wanneer part1 vol zit hij door gaat naar 2. Het max stemmen van een partij staat in excel dus. Uiteindelijk moeten de uitkomsten in excel komen naast de van te voren ingevoerde cijfers.
Wie kan mij hiermee helpen?
De code is als volgt:
Sub st31()
Dim stemmen, aftel, stemmenpart1, stemmenpart2 As LongPtr
Dim tekst1, tekst2 As String
stemmen = 50
stemmenpart1 = 0
stemmenpart2 = 0
aftel = 1
Do
Loop While stemmen >= 0
stemmen = stemmen - aftel
Do While stemmenpart1 <= Worksheets("st").Cells(3, 2)
stemmenpart1 = stemmenpart1 + aftel
Loop
If stemmenpart1 = True Then
tekst1 = stemmenpart1
End If
Do While stemmenpart1 = Worksheets("st").Cells(3, 2)
stemmenpart2 = stemmenpart2 + aftel
Loop
If stemmenpart2 = True Then
tekst2 = stemmenpart2
End If
Worksheets("st").Cells(3, 3) = tekst1
Worksheets("st").Cells(3, 4) = tekst2
End Sub
Aldus.
Lieve FOK!kers, ik heb over een maandje mijn toelatingsexamen voor mijn Sociologie master aan de VU. Ik kom van het hbo af en heb dus niet/nauwelijks statistiek of wiskunde gehad. Ben al druk aan het oefenen, maar hebben jullie nog tips, tricks of linkjes naar goede samenvattingen of oefenmogelijkheden?
Welke onderwerpen zijn het meest belangrijk bij wiskunde ihkv statistiek?
Welke onderwerpen zijn het meest belangrijk bij wiskunde ihkv statistiek?
Als bij een multiple logistische regressie een interactieterm (onafhankelijke variabele1*onafhankelijke variabele2) niet significant is, dan kan ik deze interactieterm weglaten uit mijn analyse toch om het effect van deze onafhankelijke variabelen an sich te bepalen?
Situatie is namelijk als volgt: onafhankelijke variabelen 1 en 2 zijn beiden significant in mijn logistische regressiemodel, maar als ik een interactieterm introduceer met deze variabelen, is deze interactieterm niet significant, maar worden ook de variabelen individueel niet significant.
Volgens mij kan ik mijn interactieterm dan weglaten en de significante variabelen als zodanig rapporteren.
Situatie is namelijk als volgt: onafhankelijke variabelen 1 en 2 zijn beiden significant in mijn logistische regressiemodel, maar als ik een interactieterm introduceer met deze variabelen, is deze interactieterm niet significant, maar worden ook de variabelen individueel niet significant.
Volgens mij kan ik mijn interactieterm dan weglaten en de significante variabelen als zodanig rapporteren.
Nee, tell me more?quote:
Ik heb alleen mijn multipele logistische regressie herhaald met alle originele onafhankelijke variabelen plus de interactieterm. Toen was de interactieterm niet significant, maar de twee onafhankelijke variabelen die eerst wel significant waren, ook niet meer.
Met een F-test test je of je variabelen samen significant zijn, om het in hypethesissen te verwoorden:
F test: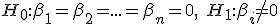 voor een
voor een ![i \in [1,n] \cap \mathbb{N}](https://forum.fok.nl/lib/mimetex.cgi?i%20%5Cin%20%5B1%2Cn%5D%20%5Ccap%20%5Cmathbb%7BN%7D)
T-test: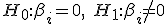
F test:
T-test:
Beste SPSS helden,
Op dit moment ben ik bezig met mijn afstudeeronderzoek en heb een vraag over een SPSS analyse.
Ik doe een onderzoek naar welke behoeften mensen hebben op een webshop en in de fysieke winkel, bijvoorbeeld, in welke mate hebben consumenten behoefte aan reviews op een webshop, of het product aanraken in de winkel etc.
Ook vraag ik in de enquête in welke mate zij de winkel/webshop beoordelen op deze punten.
Zo heb ik 2 vragen gemeten op basis van een 5 punt likert schaal:
- In welke mate vindt u de volgende functies belangrijk op een webshop? --> reviews en beoordelingen
- Hoe beoordeelt u de Euro Funcenter webshop op deze functies? --> reviews en beoordelingen
Op deze manier kan ik zien wat mensen belangrijk vinden en waar er verbeterpunten liggen, of niet.
Weet iemand een mooie duidelijke manier om naast elkaar dit aan te tonen in SPSS? ik kom er zelf niet zo goed uit namelijk. Dus bijvoorbeeld:
100 mensen vinden reviews en beoordelingen zeer belangrijk
80 mensen vinden de reviews en beoordelingen op de webshop matig.
enzovoort.
Ik hoop dat jullie me kunnen helpen!
Op dit moment ben ik bezig met mijn afstudeeronderzoek en heb een vraag over een SPSS analyse.
Ik doe een onderzoek naar welke behoeften mensen hebben op een webshop en in de fysieke winkel, bijvoorbeeld, in welke mate hebben consumenten behoefte aan reviews op een webshop, of het product aanraken in de winkel etc.
Ook vraag ik in de enquête in welke mate zij de winkel/webshop beoordelen op deze punten.
Zo heb ik 2 vragen gemeten op basis van een 5 punt likert schaal:
- In welke mate vindt u de volgende functies belangrijk op een webshop? --> reviews en beoordelingen
- Hoe beoordeelt u de Euro Funcenter webshop op deze functies? --> reviews en beoordelingen
Op deze manier kan ik zien wat mensen belangrijk vinden en waar er verbeterpunten liggen, of niet.
Weet iemand een mooie duidelijke manier om naast elkaar dit aan te tonen in SPSS? ik kom er zelf niet zo goed uit namelijk. Dus bijvoorbeeld:
100 mensen vinden reviews en beoordelingen zeer belangrijk
80 mensen vinden de reviews en beoordelingen op de webshop matig.
enzovoort.
Ik hoop dat jullie me kunnen helpen!
Analyze -> descriptive statistics -> frequenciesquote:
Beste SPSS helden,
Op dit moment ben ik bezig met mijn afstudeeronderzoek en heb een vraag over een SPSS analyse.
Ik doe een onderzoek naar welke behoeften mensen hebben op een webshop en in de fysieke winkel, bijvoorbeeld, in welke mate hebben consumenten behoefte aan reviews op een webshop, of het product aanraken in de winkel etc.
Ook vraag ik in de enquête in welke mate zij de winkel/webshop beoordelen op deze punten.
Zo heb ik 2 vragen gemeten op basis van een 5 punt likert schaal:
- In welke mate vindt u de volgende functies belangrijk op een webshop? --> reviews en beoordelingen
- Hoe beoordeelt u de Euro Funcenter webshop op deze functies? --> reviews en beoordelingen
Op deze manier kan ik zien wat mensen belangrijk vinden en waar er verbeterpunten liggen, of niet.
Weet iemand een mooie duidelijke manier om naast elkaar dit aan te tonen in SPSS? ik kom er zelf niet zo goed uit namelijk. Dus bijvoorbeeld:
100 mensen vinden reviews en beoordelingen zeer belangrijk
80 mensen vinden de reviews en beoordelingen op de webshop matig.
enzovoort.
Ik hoop dat jullie me kunnen helpen!
Als je zorgt dat je in je variabelen scherm de labels van de values hebt aangepast naar de benamingen die je noemt kun je op deze manier een tabel krijgen met de aantallen die je zoekt.
Als je eerst nog op Charts klikt (voor je op OK klikt) dan kun je nog kiezen uit wat grafiekjes.
Klopt! Deze manier had ik eerst ook. Alleen ik dacht, misschien is er een mooiere manier om dit naast elkaar weer te geven. Zodat je in een snelle oogopslag kan zien bv: 80% vind reviews 'zeer belangrijk', maar 70% beoordeeld bedrijf xx op dit punt 'matig'. Dan weet je dat hier verbeterpunten liggen.quote:
[..]
Analyze -> descriptive statistics -> frequencies
Als je zorgt dat je in je variabelen scherm de labels van de values hebt aangepast naar de benamingen die je noemt kun je op deze manier een tabel krijgen met de aantallen die je zoekt.
Als je eerst nog op Charts klikt (voor je op OK klikt) dan kun je nog kiezen uit wat grafiekjes.
ik weet niet of dit mogelijk is, of is het verstandiger om het gewoon simpel te houden
In ieder geval bedankt voor je tip alvast!
Ah op die manier. Dan zou ik op basis van de frequency tabellen de data in Excel plaatsen en op die manier grafieken maken. Het zal vast ook kunnen in SPSS, maar ik ben niet zo thuis in de Chartbuilder.quote:
[..]
Klopt! Deze manier had ik eerst ook. Alleen ik dacht, misschien is er een mooiere manier om dit naast elkaar weer te geven. Zodat je in een snelle oogopslag kan zien bv: 80% vind reviews 'zeer belangrijk', maar 70% beoordeeld bedrijf xx op dit punt 'matig'. Dan weet je dat hier verbeterpunten liggen.
ik weet niet of dit mogelijk is, of is het verstandiger om het gewoon simpel te houden
In ieder geval bedankt voor je tip alvast!
Ik ben bijna klaar met het afronden van mijn masterscriptie, maar hik al enige weken tegen hetzelfde probleem aan.
Wat ik heb: iedere respondent kreeg 3 namen onder ogen te zien, OF alle 3 in het Engels OF alle 3 in het Nederlands. Respondenten zelf verschilden qua nationaliteit: het waren Nederlanders of Belgen. Per voorgelegde naam gaven zij hun mening, die vervolgens zijn gecodeerd naar 0 = negatief, 1 = neutraal en 2 = positief. In totaal heb ik 155 (respondenten) x 3 (voorgelegde namen) = 465 meningen.
Wat ik wil: iets zinnigs kunnen zeggen over eventuele verschillen in aantallen. Ik wil in eerste instantie het aantal negatieve, neutrale en positieve meningen vergelijken tussen de Engelse en de Nederlandse versie. Kijken of deze verschillen in totale aantal en in aantal negatieve, neutrale of positieve meningen. Tenslotte zou ik ook nog willen kijken in hoeverre de meningen verschillen als het aankomt op nationaliteit; dus verschilt het totale aantal meningen en het aantal negatieve, neutrale en positieve meningen tussen Belgen en Nederlanders.
Kan iemand mij hiermee helpen?
UPDATE: Ter verduidelijking onderstaande uitkomst van een chi-kwadraat. Kan ik hier nu iets zeggen over dat de totale aantallen significant verschillen. Of ook welke onderling verschillen?
[ Bericht 11% gewijzigd door Jiveje op 08-07-2014 12:16:57 ]
Wat ik heb: iedere respondent kreeg 3 namen onder ogen te zien, OF alle 3 in het Engels OF alle 3 in het Nederlands. Respondenten zelf verschilden qua nationaliteit: het waren Nederlanders of Belgen. Per voorgelegde naam gaven zij hun mening, die vervolgens zijn gecodeerd naar 0 = negatief, 1 = neutraal en 2 = positief. In totaal heb ik 155 (respondenten) x 3 (voorgelegde namen) = 465 meningen.
Wat ik wil: iets zinnigs kunnen zeggen over eventuele verschillen in aantallen. Ik wil in eerste instantie het aantal negatieve, neutrale en positieve meningen vergelijken tussen de Engelse en de Nederlandse versie. Kijken of deze verschillen in totale aantal en in aantal negatieve, neutrale of positieve meningen. Tenslotte zou ik ook nog willen kijken in hoeverre de meningen verschillen als het aankomt op nationaliteit; dus verschilt het totale aantal meningen en het aantal negatieve, neutrale en positieve meningen tussen Belgen en Nederlanders.
Kan iemand mij hiermee helpen?
UPDATE: Ter verduidelijking onderstaande uitkomst van een chi-kwadraat. Kan ik hier nu iets zeggen over dat de totale aantallen significant verschillen. Of ook welke onderling verschillen?

[ Bericht 11% gewijzigd door Jiveje op 08-07-2014 12:16:57 ]
Als ik een Mann-Whitney U test doe met een geïmputeerde dataset, krijg ik wel netjes de P-waarden voor mijn originele data en elke imputatiestap (10), maar ik krijg geen P-waarden voor mijn 'pooled' dataset. Terwijl ik wel ranks krijg voor de pooled data.
Waarom krijg ik hiervoor geen p-waarde en hoe kan ik ervoor zorgen dat ik die wel krijg?
Als ik een two-sample t-test doe, krijg ik wel een p-waarde voor de pooled data, maar dat is natuurlijk niet helemaal netjes, omdat ik niet parametrisch mag testen.
Waarom krijg ik hiervoor geen p-waarde en hoe kan ik ervoor zorgen dat ik die wel krijg?
Als ik een two-sample t-test doe, krijg ik wel een p-waarde voor de pooled data, maar dat is natuurlijk niet helemaal netjes, omdat ik niet parametrisch mag testen.
Een chi-square test alleen of er verschillen zijn, maar niet waar die verschillen zitten.quote:
Ik ben bijna klaar met het afronden van mijn masterscriptie, maar hik al enige weken tegen hetzelfde probleem aan.
Wat ik heb: iedere respondent kreeg 3 namen onder ogen te zien, OF alle 3 in het Engels OF alle 3 in het Nederlands. Respondenten zelf verschilden qua nationaliteit: het waren Nederlanders of Belgen. Per voorgelegde naam gaven zij hun mening, die vervolgens zijn gecodeerd naar 0 = negatief, 1 = neutraal en 2 = positief. In totaal heb ik 155 (respondenten) x 3 (voorgelegde namen) = 465 meningen.
Wat ik wil: iets zinnigs kunnen zeggen over eventuele verschillen in aantallen. Ik wil in eerste instantie het aantal negatieve, neutrale en positieve meningen vergelijken tussen de Engelse en de Nederlandse versie. Kijken of deze verschillen in totale aantal en in aantal negatieve, neutrale of positieve meningen. Tenslotte zou ik ook nog willen kijken in hoeverre de meningen verschillen als het aankomt op nationaliteit; dus verschilt het totale aantal meningen en het aantal negatieve, neutrale en positieve meningen tussen Belgen en Nederlanders.
Kan iemand mij hiermee helpen?
UPDATE: Ter verduidelijking onderstaande uitkomst van een chi-kwadraat. Kan ik hier nu iets zeggen over dat de totale aantallen significant verschillen. Of ook welke onderling verschillen?
[ afbeelding ]
Het gemakkelijkste is om een chi-square uit te voeren voor elk los contrast.
Dus contrast 1: positief vs de rest
Contrast 2: negatief vs de rest
en eventueel (ligt aan je hypothese) neutraal vs de rest.
Wat bedoel je met de pooled data? Kun je de output posten?quote:
Als ik een Mann-Whitney U test doe met een geïmputeerde dataset, krijg ik wel netjes de P-waarden voor mijn originele data en elke imputatiestap (10), maar ik krijg geen P-waarden voor mijn 'pooled' dataset. Terwijl ik wel ranks krijg voor de pooled data.
Waarom krijg ik hiervoor geen p-waarde en hoe kan ik ervoor zorgen dat ik die wel krijg?
Als ik een two-sample t-test doe, krijg ik wel een p-waarde voor de pooled data, maar dat is natuurlijk niet helemaal netjes, omdat ik niet parametrisch mag testen.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Het gaat in dit geval om een Wilcoxon signed ranks test, maar hetzelfde probleem doet zich eigenlijk voor bij alle non-parametrische testen:
Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.


Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.
Whoops sorry, verkeerde knopjequote:
Het gaat in dit geval om een Wilcoxon signed ranks test, maar hetzelfde probleem doet zich eigenlijk voor bij alle non-parametrische testen:
Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.
Ik ben er iets meer ingedoken, en Wilkinson is voor dependent samples (dus elke case wordt 2x gemeten, bv voor en na interventie), ik denk dus niet dat dat de juiste test voor je is.quote:
Het gaat in dit geval om een Wilcoxon signed ranks test, maar hetzelfde probleem doet zich eigenlijk voor bij alle non-parametrische testen:
[ afbeelding ]
[ afbeelding ]
Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.
Welke test wel zou moeten werken is de Mann Whitney. Ik heb zelf net wat data gesimuleerd en dan werkt het gewoon. Misschien heb je je dataset niet goed opgezet? (of misschien begrijp ik verkeerd wat je wilt doen
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik weet dat een Wilcoxon een test is voor dependent samples. Ik heb op dezelfde data zowel een Wilcoxon signed ranks test als een Mann-Whitney U test gedaan, om de within and between groups differences te testen. Daar ging m'n vraag ook niet over.quote:
[..]
Ik ben er iets meer ingedoken, en Wilkinson is voor dependent samples (dus elke case wordt 2x gemeten, bv voor en na interventie), ik denk dus niet dat dat de juiste test voor je is.
Welke test wel zou moeten werken is de Mann Whitney. Ik heb zelf net wat data gesimuleerd en dan werkt het gewoon. Misschien heb je je dataset niet goed opgezet? (of misschien begrijp ik verkeerd wat je wilt doen
Ik wil weten waarom ik geen testuitslagen krijg voor m'n gepoolde data na imputatie. Ik heb namelijk een p-waarde voor de originele data (voordat er geïmputeerd is voor missing data) en ik wil dus een p-waarde voor m'n dataset na imputatie, dit is de 'pooled data'. Hiervoor krijg ik dus wel descriptives en ranks, maar geen p-waarde.
Nu begin ik het te begrijpen, helaas geen goed nieuws, dat kan niet in SPSS. Je kunt kijken of je een macro er voor kunt vinden.quote:
[..]
Ik weet dat een Wilcoxon een test is voor dependent samples. Ik heb op dezelfde data zowel een Wilcoxon signed ranks test als een Mann-Whitney U test gedaan, om de within and between groups differences te testen. Daar ging m'n vraag ook niet over.
Ik wil weten waarom ik geen testuitslagen krijg voor m'n gepoolde data na imputatie. Ik heb namelijk een p-waarde voor de originele data (voordat er geïmputeerd is voor missing data) en ik wil dus een p-waarde voor m'n dataset na imputatie, dit is de 'pooled data'. Hiervoor krijg ik dus wel descriptives en ranks, maar geen p-waarde.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
quote:
[..]
Nu begin ik het te begrijpen, helaas geen goed nieuws, dat kan niet in SPSS. Je kunt kijken of je een macro er voor kunt vinden.
nou je ik weet het ook niet zeker ik heb nog nooit met imputed data gewerkt, internet zegt allen dat het niet kan. Hier kun je misschien meer vinden: http://jeremyjaytaylor.sq(...)discuss/post/1436944quote:
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Bij partiële correlatie heb ik gevonden dat Y significant negatief gecorreleerd is met X, gecorrigeerd voor W en Z. Om dit visueel weer te geven, gebruik ik een lineaire regressie met Y als dependent variable en X, W en Z als independent variables. Ik laat alle partial plots weergeven.
Echter, X heeft in mijn dataset een range van 38-1120, maar in mijn partial plot krijg ik ook punten in de puntenwolk met een negatieve X-waarde. Als ik mijn X-as wil aanpassen in de chart editor, geeft 'ie aan dat de range in de data loopt van -39 tot 43.
Als ik toch de minimum X-as op 0 zet, is het visuele effect van mijn correlatie weg.
Hoe komt het dat ik een heel andere range van mijn X krijg, en hoe los ik dit op?
Echter, X heeft in mijn dataset een range van 38-1120, maar in mijn partial plot krijg ik ook punten in de puntenwolk met een negatieve X-waarde. Als ik mijn X-as wil aanpassen in de chart editor, geeft 'ie aan dat de range in de data loopt van -39 tot 43.
Als ik toch de minimum X-as op 0 zet, is het visuele effect van mijn correlatie weg.
Hoe komt het dat ik een heel andere range van mijn X krijg, en hoe los ik dit op?
Kun je even screenshotje posten van regressieresultaten en de plotjes?quote:
Bij partiële correlatie heb ik gevonden dat Y significant negatief gecorreleerd is met X, gecorrigeerd voor W en Z. Om dit visueel weer te geven, gebruik ik een lineaire regressie met Y als dependent variable en X, W en Z als independent variables. Ik laat alle partial plots weergeven.
Echter, X heeft in mijn dataset een range van 38-1120, maar in mijn partial plot krijg ik ook punten in de puntenwolk met een negatieve X-waarde. Als ik mijn X-as wil aanpassen in de chart editor, geeft 'ie aan dat de range in de data loopt van -39 tot 43.
Als ik toch de minimum X-as op 0 zet, is het visuele effect van mijn correlatie weg.
Hoe komt het dat ik een heel andere range van mijn X krijg, en hoe los ik dit op?
Ik vermoed overigens dat het komt omdat je x-as niet variabele X weergeeft maar de residuals van X en als dat zo is hoef je dat natuurlijk niet op te lossen
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-



Zo te zien komt dat doordat alleen de partial effecten van beide variabelen geplot zijn (zoals eigenlijk ook hoort). Ik denk dat het mogelijk is om de residuals op te slaan in je dataset dan zou je zelf een plotje IQ vs residuals DV kunnen maken.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Met andere woorden, je kan niet IQ vs DV maken, gecorrigeerd voor een aantal variabelen. Dan moet je dus altijd de residuals plotten?quote:
Zo te zien komt dat doordat alleen de partial effecten van beide variabelen geplot zijn (zoals eigenlijk ook hoort). Ik denk dat het mogelijk is om de residuals op te slaan in je dataset dan zou je zelf een plotje IQ vs residuals DV kunnen maken.
Ola senors en senoritas. Op deze mooie zomerse dag ben ik eens bezig gegaan met SPSS voor mijn masterscriptie, en ik loop eigenlijk al gelijk vast..
Ik wil mijn respondenten selecteren op twee variabelen; doe je X op school of buiten school? Deze twee variabelen lopen van 1 t/m 4 (1 = nooit, 2 = 1 of 2 keer, 3 = +- 1x per week en 4 = meerdere keren per week).
Ik wil mijn respondenten selecteren op dat zij zowel op variabele één als op twee, 2 of hoger geantwoord hebben. Dus ik vul bij select cases in: Var1 = 2 | 3 | 4 & Var2 = 2 | 3 | 4 En vervolgens vertelt SPSS me dat "The sequence of operators found is invalid. Check the expression for ommited or extra operands, operators, and parentheses. Maar ik kan dus echt niet verzinnen wat ik anders zou moeten doen; nergens staat een extra spatie oid. En als ik >1 i.p.v. 2 | 3 | 4 invul krijg ik precies hetzelfde... Wie o wie kan mij helpen?
Ik wil mijn respondenten selecteren op twee variabelen; doe je X op school of buiten school? Deze twee variabelen lopen van 1 t/m 4 (1 = nooit, 2 = 1 of 2 keer, 3 = +- 1x per week en 4 = meerdere keren per week).
Ik wil mijn respondenten selecteren op dat zij zowel op variabele één als op twee, 2 of hoger geantwoord hebben. Dus ik vul bij select cases in: Var1 = 2 | 3 | 4 & Var2 = 2 | 3 | 4 En vervolgens vertelt SPSS me dat "The sequence of operators found is invalid. Check the expression for ommited or extra operands, operators, and parentheses. Maar ik kan dus echt niet verzinnen wat ik anders zou moeten doen; nergens staat een extra spatie oid. En als ik >1 i.p.v. 2 | 3 | 4 invul krijg ik precies hetzelfde... Wie o wie kan mij helpen?
SPSS snapt "Var1 = 2 | 3 | 4" niet.
Dat moet iets zijn als:
(Var1 = 2 | Var1 = 3 | Var1 = 4) & (...)
Dat moet iets zijn als:
(Var1 = 2 | Var1 = 3 | Var1 = 4) & (...)
Aldus.
Kun je wel maar 1 van de twee variabelen selecteren zoals je wil, of komt er dan ook een foutmelding?quote:
Ola senors en senoritas. Op deze mooie zomerse dag ben ik eens bezig gegaan met SPSS voor mijn masterscriptie, en ik loop eigenlijk al gelijk vast..
Ik wil mijn respondenten selecteren op twee variabelen; doe je X op school of buiten school? Deze twee variabelen lopen van 1 t/m 4 (1 = nooit, 2 = 1 of 2 keer, 3 = +- 1x per week en 4 = meerdere keren per week).
Ik wil mijn respondenten selecteren op dat zij zowel op variabele één als op twee, 2 of hoger geantwoord hebben. Dus ik vul bij select cases in: Var1 = 2 | 3 | 4 & Var2 = 2 | 3 | 4 En vervolgens vertelt SPSS me dat "The sequence of operators found is invalid. Check the expression for ommited or extra operands, operators, and parentheses. Maar ik kan dus echt niet verzinnen wat ik anders zou moeten doen; nergens staat een extra spatie oid. En als ik >1 i.p.v. 2 | 3 | 4 invul krijg ik precies hetzelfde... Wie o wie kan mij helpen?
Ga ik even proberen, thanksquote:Op dinsdag 5 augustus 2014 15:24 schreef Z het volgende:
SPSS snapt "Var1 = 2 | 3 | 4" niet.
Dat moet iets zijn als:
(Var1 = 2 | Var1 = 3 | Var1 = 4) & (...)
Eentje lukt wel gewoon inderdaad.quote:
[..]
Kun je wel maar 1 van de twee variabelen selecteren zoals je wil, of komt er dan ook een foutmelding?
quote:
SPSS snapt "Var1 = 2 | 3 | 4" niet.
Dat moet iets zijn als:
(Var1 = 2 | Var1 = 3 | Var1 = 4) & (...)
Alleen moest & in mijn geval | worden, maar dat is mijn eigen fout
Even geprobeerd, als je ook data hebt met veel mogelijkheden: VAR1>1 AND VAR2>1 zou ook moeten werken.quote:
[..]Je bent geweldig
Alleen moest & in mijn geval | worden, maar dat is mijn eigen fout
| 1 2 3 4 5 6 7 8 | DATASET ACTIVATE DataSet0. USE ALL. COMPUTE filter_$=(VAR00001>1 AND VAR00002>1). VARIABLE LABELS filter_$ 'VAR00001>1 AND VAR00002>1 (FILTER)'. VALUE LABELS filter_$ 0 'Not Selected' 1 'Selected'. FORMATS filter_$ (f1.0). FILTER BY filter_$. EXECUTE. |
Die had ik ook geprobeerd inderdaad, maar die pakte hij ook niet bij de tweede variabele.quote:
[..]
Even geprobeerd, als je ook data hebt met veel mogelijkheden: VAR1>1 AND VAR2>1 zou ook moeten werken.
[ code verwijderd ]
Oh ja, daar kan ik me vaag iets van herinneren inderdaad. Het is al weer een tijdje geleden dat ik met SPSS heb gewerkt, dus ik moet er echt weer even inkomen.quote:
En als het verschillende waarden moeten zijn ANY(var1,3,6,8)
Super bedankt voor de snelle reacties allemaal!
Beste Fok-buddies(  ),
),
Ik ben voor mijn afstudeeronderzoek gestrand bij de regressie-analyse. Mijn onderzoeksvraag is:
Welke factoren zijn van invloed op de merkmeerwaarde?
Merkmeerwaarde bestaat uit 5 onafhankelijke variabelen (gehaald uit de theorie), namelijk:
• Merkidentiteit
• Merkbetekenis
• Merkrespons
• Merkrelatie
• Content
Deze 5 variabelen heb ik in mijn survey verwerkt in 42 vragen die allen te beantwoorden zijn op basis van een 5-puntsschaal. Vervolgens heb ik een Cronbach's Alpha toegepast op alle factoren en vervolgens de vragen in een schaal geplaatst. Nu rest dus alleen nog een Regressie-analyse om er achter te komen in hoeverre de vijf factoren van invloed zijn op de merkmeerwaarde. ... En zodat ik te weten kom welke factor het meeste van invloed is, zodat ik daar mijn aanbevelingen op kan baseren.
Echter krijg ik bij het uitdraaien van de Regressie-analyse de volgende warning:
"For the final model with dependent variable Merkmeerwaarde, influence statistics can not be computed because the fit is perfect."
Ik begrijp dat dit komt omdat de afhankelijke variabele (Merkmeerwaarde) bestaat uit de 5 onafhankelijke variabelen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content).
Mijn vraag: Hoe kan ik dit oplossen, zodat ik alsnog iets kan zeggen over de invloed van de 5 (afzonderlijke) onafhankelijke variabelen op de afhankelijke variabele? (Welke variabele heeft de meeste invloed / is de sterkste predictor?)
|
|
Ik heb zeg maar 0 les gehad in SPSS en er wordt dan ook niet verwacht dat ik een uitgebreide, wiskundige analyse in mijn scriptie verwerk. Hoe simpeler, hoe beter!
Ik moet uiteraard wel een antwoord kunnen geven op mijn onderzoeksvraag. Ik hoop dat hier iemand een oplossing heeft. In elk geval alvast bedankt!
Ik ben voor mijn afstudeeronderzoek gestrand bij de regressie-analyse. Mijn onderzoeksvraag is:
Welke factoren zijn van invloed op de merkmeerwaarde?
Merkmeerwaarde bestaat uit 5 onafhankelijke variabelen (gehaald uit de theorie), namelijk:
• Merkidentiteit
• Merkbetekenis
• Merkrespons
• Merkrelatie
• Content
Deze 5 variabelen heb ik in mijn survey verwerkt in 42 vragen die allen te beantwoorden zijn op basis van een 5-puntsschaal. Vervolgens heb ik een Cronbach's Alpha toegepast op alle factoren en vervolgens de vragen in een schaal geplaatst. Nu rest dus alleen nog een Regressie-analyse om er achter te komen in hoeverre de vijf factoren van invloed zijn op de merkmeerwaarde. ... En zodat ik te weten kom welke factor het meeste van invloed is, zodat ik daar mijn aanbevelingen op kan baseren.
Echter krijg ik bij het uitdraaien van de Regressie-analyse de volgende warning:
"For the final model with dependent variable Merkmeerwaarde, influence statistics can not be computed because the fit is perfect."
Ik begrijp dat dit komt omdat de afhankelijke variabele (Merkmeerwaarde) bestaat uit de 5 onafhankelijke variabelen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content).
Mijn vraag: Hoe kan ik dit oplossen, zodat ik alsnog iets kan zeggen over de invloed van de 5 (afzonderlijke) onafhankelijke variabelen op de afhankelijke variabele? (Welke variabele heeft de meeste invloed / is de sterkste predictor?)
|
|
Ik heb zeg maar 0 les gehad in SPSS en er wordt dan ook niet verwacht dat ik een uitgebreide, wiskundige analyse in mijn scriptie verwerk. Hoe simpeler, hoe beter!
Ik moet uiteraard wel een antwoord kunnen geven op mijn onderzoeksvraag. Ik hoop dat hier iemand een oplossing heeft. In elk geval alvast bedankt!
Heb je ze wel allemaal apart in je regressie analyse gedaan, dus een voor een ipv allemaal tegelijk?quote:
Beste Fok-buddies(
Ik ben voor mijn afstudeeronderzoek gestrand bij de regressie-analyse. Mijn onderzoeksvraag is:
Welke factoren zijn van invloed op de merkmeerwaarde?
Merkmeerwaarde bestaat uit 5 onafhankelijke variabelen (gehaald uit de theorie), namelijk:
• Merkidentiteit
• Merkbetekenis
• Merkrespons
• Merkrelatie
• Content
Deze 5 variabelen heb ik in mijn survey verwerkt in 42 vragen die allen te beantwoorden zijn op basis van een 5-puntsschaal. Vervolgens heb ik een Cronbach's Alpha toegepast op alle factoren en vervolgens de vragen in een schaal geplaatst. Nu rest dus alleen nog een Regressie-analyse om er achter te komen in hoeverre de vijf factoren van invloed zijn op de merkmeerwaarde. ... En zodat ik te weten kom welke factor het meeste van invloed is, zodat ik daar mijn aanbevelingen op kan baseren.
Echter krijg ik bij het uitdraaien van de Regressie-analyse de volgende warning:
"For the final model with dependent variable Merkmeerwaarde, influence statistics can not be computed because the fit is perfect."
Ik begrijp dat dit komt omdat de afhankelijke variabele (Merkmeerwaarde) bestaat uit de 5 onafhankelijke variabelen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content).
Mijn vraag: Hoe kan ik dit oplossen, zodat ik alsnog iets kan zeggen over de invloed van de 5 (afzonderlijke) onafhankelijke variabelen op de afhankelijke variabele? (Welke variabele heeft de meeste invloed / is de sterkste predictor?)
|
|
Ik heb zeg maar 0 les gehad in SPSS en er wordt dan ook niet verwacht dat ik een uitgebreide, wiskundige analyse in mijn scriptie verwerk. Hoe simpeler, hoe beter!
Ik moet uiteraard wel een antwoord kunnen geven op mijn onderzoeksvraag. Ik hoop dat hier iemand een oplossing heeft. In elk geval alvast bedankt!
Edit: Ik ben er al uit en de vraag was iets te herkenbaar, dus hij is weer weg
[ Bericht 75% gewijzigd door fh101 op 05-08-2014 19:26:28 ]
[ Bericht 75% gewijzigd door fh101 op 05-08-2014 19:26:28 ]
Ja, dat heb ik gedaan maar zodra ik de vijfde dan toevoeg krijg ik de foutmelding. Dat komt waarschijnlijk omdat de 5 onafhankelijke variabelen samen de afhankelijke variabele vormen..quote:
[..]
Heb je ze wel allemaal apart in je regressie analyse gedaan, dus een voor een ipv allemaal tegelijk?
Dat klopt. Dit heet colinneariteit.quote:
[..]
Ja, dat heb ik gedaan maar zodra ik de vijfde dan toevoeg krijg ik de foutmelding. Dat komt waarschijnlijk omdat de 5 onafhankelijke variabelen samen de afhankelijke variabele vormen..
Overigens zegt Cronbachs alfa niets over onderliggende factoren, maar alleen iets over betrouwbaarheid van een schaal (mits je steekproef groot genoeg is, anders is het een slechte schatter maar dat geldt eigenlijk altijd bij statistiek).
Wat je hier wil doen is een zinloze exercitie, omdat je afhankelijke variabele bestaat uit de onafhankelijke variabelen. Dit zegt uiteindelijk dus niets nuttigs.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Cronbachs Alfa is inderdaad om de betrouwbaarheid van de schalen te meten, daar heb ik het ook voor gebruiktquote:
[..]
Dat klopt. Dit heet colinneariteit.
Overigens zegt Cronbachs alfa niets over onderliggende factoren, maar alleen iets over betrouwbaarheid van een schaal (mits je steekproef groot genoeg is, anders is het een slechte schatter maar dat geldt eigenlijk altijd bij statistiek).
Wat je hier wil doen is een zinloze exercitie, omdat je afhankelijke variabele bestaat uit de onafhankelijke variabelen. Dit zegt uiteindelijk dus niets nuttigs.
Hmm, is er geen andere methode om alsnog de gewenste gegevens uitgedraaid te krijgen?
Beste Fokkers, (Dubbelpost, mn topic hierover mag dan wel weg)
Google kan me niet helpen, jullie misschien.
Ik heb in excel nogal wat data gekregen (17.000 respondenten). Nu heb ik dat in excel allemaal wat leesbaarder gemaakt en vervolgens geëxporteerd naar SPSS.
In SPSS is (bijna) alles heel mooi. Alleen 1 variabele heeft als type "string" met een nominal measure maar die moet "numeric" met een linear measure zijn. Als ik dat verander in the variable view vervallen opeens een groot aantal responsen.
Hoe kan ik deze variabele wel veranderen in numeriek zodat ik er wel statistische testen mee kan doen.
Let op: alle data die ingevuld is bij de variabele is al numeriek (1-100). Alleen de instellingen kloppen dus niet.
Ik kijk uit naar reacties!
Google kan me niet helpen, jullie misschien.
Ik heb in excel nogal wat data gekregen (17.000 respondenten). Nu heb ik dat in excel allemaal wat leesbaarder gemaakt en vervolgens geëxporteerd naar SPSS.
In SPSS is (bijna) alles heel mooi. Alleen 1 variabele heeft als type "string" met een nominal measure maar die moet "numeric" met een linear measure zijn. Als ik dat verander in the variable view vervallen opeens een groot aantal responsen.
Hoe kan ik deze variabele wel veranderen in numeriek zodat ik er wel statistische testen mee kan doen.
Let op: alle data die ingevuld is bij de variabele is al numeriek (1-100). Alleen de instellingen kloppen dus niet.
Ik kijk uit naar reacties!
Je vraag is heel erg raar. Je hebt 42 vragen die allemaal voor 1/42 meetellen in een schaal. Nu wil je een regressie doen om te kijken hoeveel die vragen meetellen, wat dus per definitie 1/42 is per vraag.quote:
[..]
Cronbachs Alfa is inderdaad om de betrouwbaarheid van de schalen te meten, daar heb ik het ook voor gebruikt
Hmm, is er geen andere methode om alsnog de gewenste gegevens uitgedraaid te krijgen?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Komt het toevalllig omdat de antwoorden met punten als decimalen gegeven zijn in excell maar spss met commas werkt oid? Dat is bij mij meestal het probleem. De responses die vervallen, vervallen meestal omdat spss ze niet omgezet krijgt in een nummer, daar zou het probleem dus moeten liggen. Misschien dat er spaties in staat of iets anders?quote:
Beste Fokkers, (Dubbelpost, mn topic hierover mag dan wel weg)
Google kan me niet helpen, jullie misschien.
Ik heb in excel nogal wat data gekregen (17.000 respondenten). Nu heb ik dat in excel allemaal wat leesbaarder gemaakt en vervolgens geëxporteerd naar SPSS.
In SPSS is (bijna) alles heel mooi. Alleen 1 variabele heeft als type "string" met een nominal measure maar die moet "numeric" met een linear measure zijn. Als ik dat verander in the variable view vervallen opeens een groot aantal responsen.
Hoe kan ik deze variabele wel veranderen in numeriek zodat ik er wel statistische testen mee kan doen.
Let op: alle data die ingevuld is bij de variabele is al numeriek (1-100). Alleen de instellingen kloppen dus niet.
Ik kijk uit naar reacties!
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
quote:quote:
0s.gif Op woensdag 6 augustus 2014 17:04 schreef Wallcrawler-GP het volgende:
Beste Fokkers, (Dubbelpost, mn topic hierover mag dan wel weg)
Google kan me niet helpen, jullie misschien.
Ik heb in excel nogal wat data gekregen (17.000 respondenten). Nu heb ik dat in excel allemaal wat leesbaarder gemaakt en vervolgens geëxporteerd naar SPSS.
In SPSS is (bijna) alles heel mooi. Alleen 1 variabele heeft als type "string" met een nominal measure maar die moet "numeric" met een linear measure zijn. Als ik dat verander in the variable view vervallen opeens een groot aantal responsen.
Hoe kan ik deze variabele wel veranderen in numeriek zodat ik er wel statistische testen mee kan doen.
Let op: alle data die ingevuld is bij de variabele is al numeriek (1-100). Alleen de instellingen kloppen dus niet.
Ik kijk uit naar reacties!
Super bedankt! Met zoeken en vervangen de punten voor komma's vervangen en daarna kon ik de variabele wel numeriek maken:)quote:Komt het toevalllig omdat de antwoorden met punten als decimalen gegeven zijn in excell maar spss met commas werkt oid? Dat is bij mij meestal het probleem. De responses die vervallen, vervallen meestal omdat spss ze niet omgezet krijgt in een nummer, daar zou het probleem dus moeten liggen. Misschien dat er spaties in staat of iets anders?
Wel gek want in excel (het originele bestand) stonden alle variabelen gelijk. Allemaal met komma. Alleen voor deze ene variabele maakt spss er een punt van. Maar geen punt, het is opgelost. Bedankt Oompaloompa!
Volgens mij heb ik het fout uitgelegd dan. Ik heb inderdaad 42 vragen, die zijn opgedeeld in 5 schalen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content). Nu wil ik een regressie-analyse inzetten om erachter te komen in hoeverre elke schaal van invloed is op de afhankelijke variabele (merkmeerwaarde) en welke schaal het meest van invloed is.quote:
[..]
Je vraag is heel erg raar. Je hebt 42 vragen die allemaal voor 1/42 meetellen in een schaal. Nu wil je een regressie doen om te kijken hoeveel die vragen meetellen, wat dus per definitie 1/42 is per vraag.
Maar omdat de 5 schalen samen de afhankelijke variabele vormen, geeft SPSS de foutmelding "the fit is perfect". Vandaar mijn vraag of ik op een andere manier kan aantonen in hoeverre de 5 schalen van invloed zijn
Hopelijk is het zo wat duidelijker
Begrijp ik het goed dat elk van die subschalen gemeten wordt met ongeveer 8 van de 42 vragen en dat het alle 42 vragen samen merkmeerwaarde meten?quote:
[..]
Volgens mij heb ik het fout uitgelegd dan. Ik heb inderdaad 42 vragen, die zijn opgedeeld in 5 schalen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content). Nu wil ik een regressie-analyse inzetten om erachter te komen in hoeverre elke schaal van invloed is op de afhankelijke variabele (merkmeerwaarde) en welke schaal het meest van invloed is.
Maar omdat de 5 schalen samen de afhankelijke variabele vormen, geeft SPSS de foutmelding "the fit is perfect". Vandaar mijn vraag of ik op een andere manier kan aantonen in hoeverre de 5 schalen van invloed zijn
Hopelijk is het zo wat duidelijker
Ik heb al een tijd geen regressie-analyse meer gedaan, maar meet je daarmee niet doorgaans de invloed van andere factoren op de afhankelijke variabele? (Factoren zoals leeftijd, salarisschaal etc.)quote:
[..]
Volgens mij heb ik het fout uitgelegd dan. Ik heb inderdaad 42 vragen, die zijn opgedeeld in 5 schalen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content). Nu wil ik een regressie-analyse inzetten om erachter te komen in hoeverre elke schaal van invloed is op de afhankelijke variabele (merkmeerwaarde) en welke schaal het meest van invloed is.
Maar omdat de 5 schalen samen de afhankelijke variabele vormen, geeft SPSS de foutmelding "the fit is perfect". Vandaar mijn vraag of ik op een andere manier kan aantonen in hoeverre de 5 schalen van invloed zijn
Hopelijk is het zo wat duidelijker
Je wil nu analyseren hoe een deel van de afhankelijke variabele deel is van de afhankelijke variabele (zo lijkt het in ieder geval.)
Volgens mij bedoelt hij dat ja.quote:
[..]
Begrijp ik het goed dat elk van die subschalen gemeten wordt met ongeveer 8 van de 42 vragen en dat het alle 42 vragen samen merkmeerwaarde meten?
Moet je niet kijken naar hoeveel elk van de scores op de subschalen de variatie op de totale schaal verklaart? Kom je dan niet bij een ANOVA uit? Daar heb ik eigenlijk geen verstand van, moet ik bekennen.
Ik wil erachter komen in hoeverre de 5 schalen van invloed zijn en welke schaal het meest van invloed is (gezien vanuit de consument).quote:
[..]
Ik heb al een tijd geen regressie-analyse meer gedaan, maar meet je daarmee niet doorgaans de invloed van andere factoren op de afhankelijke variabele? (Factoren zoals leeftijd, salarisschaal etc.)
Je wil nu analyseren hoe een deel van de afhankelijke variabele deel is van de afhankelijke variabele (zo lijkt het in ieder geval.)
Dat weet je al: ~8/42quote:
[..]
Ik wil erachter komen in hoeverre de 5 schalen van invloed zijn
Dit lijkt meer op de vraag die je moet stellen inderdaad.quote:en welke schaal het meest van invloed is (gezien vanuit de consument).
Als ik daarmee kan aantonen welke schaal de respondenten van de survey het belangrijkste vinden en welke de grootste invloed heeft op de totale schaal, dan lijkt me dat zeker een oplossing.quote:
Moet je niet kijken naar hoeveel elk van de scores op de subschalen de variatie op de totale schaal verklaart? Kom je dan niet bij een ANOVA uit? Daar heb ik eigenlijk geen verstand van, moet ik bekennen.
Iemand die dit kan bevestigen?
Maar als bij de eerste schaal alle respondenten bij de 8 vragen "zeer eens" hebben ingevuld, en bij de tweede schaal alle respondenten "zeer oneens" zijn, dan is dat niet dezelfde mate van invloed op de totale schaal?quote:
[..]
Dat weet je al: ~8/42
[..]
Dit lijkt meer op de vraag die je moet stellen inderdaad.
In feite kom ik al een heel eind als ik kan aantonen welke schaal het meest van invloed is. Wat is een gebruikelijke methode om dit te doen?
(sorry als ik sommige termen in de war haal of als ik het niet meteen helemaal begrijp. Zoals gezegd: 0 les gehad in SPSS, dus amper verstand ervan
Welke kant de score op gaat hoort niet de mate van invloed te bepalen. Hoe bereken je die totale schaal? Alle scores van de Likerts bij elkaar opgeteld? De score op de subschalen omgerekend naar percentages en die bij elkaar opgeteld?quote:
[..]
Maar als bij de eerste schaal alle respondenten bij de 8 vragen "zeer eens" hebben ingevuld, en bij de tweede schaal alle respondenten "zeer oneens" zijn, dan is dat niet dezelfde mate van invloed op de totale schaal?
quote:
[..]
Welke kant de score op gaat hoort niet de mate van invloed te bepalen. Hoe bereken je die totale schaal? Alle scores van de Likerts bij elkaar opgeteld? De score op de subschalen omgerekend naar percentages en die bij elkaar opgeteld?
De totale schaal is inderdaad de som van de 5 schalen.quote:
[..]
Welke kant de score op gaat hoort niet de mate van invloed te bepalen. Hoe bereken je die totale schaal? Alle scores van de Likerts bij elkaar opgeteld? De score op de subschalen omgerekend naar percentages en die bij elkaar opgeteld?
Ik heb een Cronbach's alfa uitgevoerd en vervolgens de schalen ingedeeld. Toen wilde ik beginnen met de regressie-analyse, maar kwam ik al snel uit op het probleem.
Ik kan je mijn Output bestand wel even sturen, misschien zie je dan hoe ik het het gedaan. Want ik vind het best lastig uitleggen met mijn beperkte kennis van SPSS
Np, ik heb dit helaas zelf ook veel te vaak meegemaaktquote:
[..]
[..]
Super bedankt! Met zoeken en vervangen de punten voor komma's vervangen en daarna kon ik de variabele wel numeriek maken:)
Wel gek want in excel (het originele bestand) stonden alle variabelen gelijk. Allemaal met komma. Alleen voor deze ene variabele maakt spss er een punt van. Maar geen punt, het is opgelost. Bedankt Oompaloompa!
Maar merkwaarde bestaat toch uit die 5 schalen?quote:
[..]
Volgens mij heb ik het fout uitgelegd dan. Ik heb inderdaad 42 vragen, die zijn opgedeeld in 5 schalen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content). Nu wil ik een regressie-analyse inzetten om erachter te komen in hoeverre elke schaal van invloed is op de afhankelijke variabele (merkmeerwaarde) en welke schaal het meest van invloed is.
Maar omdat de 5 schalen samen de afhankelijke variabele vormen, geeft SPSS de foutmelding "the fit is perfect". Vandaar mijn vraag of ik op een andere manier kan aantonen in hoeverre de 5 schalen van invloed zijn
Hopelijk is het zo wat duidelijker
Dus je hebt 42 vragen die 5 scchalen vormen. Laten we even voor het gemak 8 vragen per schaal nemen. Daarna bestaat je afhankelijke uit de som van de 5 schalen. Dat betekent dus dat elke vraag voor 1/40 invloed op merkwaarde heeft (of elke schaal 20%). Je vraag klopt niet, en daarom geeft SPSS errors. Je beslist namelijk eerst zelf hoeveel invloed elke schaal op merkwaarde heeft omdat je het concept merkwaarde definieert als een combinatie van de schalen.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Okay, bedankt voor je reactie!quote:
[..]
Np, ik heb dit helaas zelf ook veel te vaak meegemaakt
[..]
Maar merkwaarde bestaat toch uit die 5 schalen?
Dus je hebt 42 vragen die 5 scchalen vormen. Laten we even voor het gemak 8 vragen per schaal nemen. Daarna bestaat je afhankelijke uit de som van de 5 schalen. Dat betekent dus dat elke vraag voor 1/40 invloed op merkwaarde heeft (of elke schaal 20%). Je vraag klopt niet, en daarom geeft SPSS errors. Je beslist namelijk eerst zelf hoeveel invloed elke schaal op merkwaarde heeft omdat je het concept merkwaarde definieert als een combinatie van de schalen.
Hoe moet ik het nu oplossen om met mijn verkregen data uit het surveyonderzoek alsnog iets over de merkmeerwaarde te kunnen zeggen?
Hmm dat wordt moeilijk aangezien je merkwaarde hebt gedefinieerd als de combinatie van die schalen. Je zou wel bv kunnen kijken hoe de subschalen onderling verband met elkaar houden en of demografische gegevens bv geslacht / leeftijd invloed hebben. Maar als je wilt weten hoe de schalen samenhangen met merkwaarde had je merkwaarde op een andere, independent, manier moeten meten.quote:
[..]
Okay, bedankt voor je reactie!
Hoe moet ik het nu oplossen om met mijn verkregen data uit het surveyonderzoek alsnog iets over de merkmeerwaarde te kunnen zeggen?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
En een stap terugnemen en de schalen op een andere manier indelen is geen optie?quote:
[..]
Hmm dat wordt moeilijk aangezien je merkwaarde hebt gedefinieerd als de combinatie van die schalen. Je zou wel bv kunnen kijken hoe de subschalen onderling verband met elkaar houden en of demografische gegevens bv geslacht / leeftijd invloed hebben. Maar als je wilt weten hoe de schalen samenhangen met merkwaarde had je merkwaarde op een andere, independent, manier moeten meten.
Onderling verband met de verschillende schalen is niet persé wat ik zoek namelijk. Ik wil weten welk aspect van merkmeerwaarde de respondenten het belangrijkst vinden, zodat de organisatie zich daar op kan focussen. En als ik de resultaten bekijk, dan zie ik dat de meest positieve antwoorden zijn ingevuld bij de schaal content. Hoe laat ik dit zien door middel van een test?
Is er geen andere toets (Mann-Whitney U Test / Pearson R / Anova ??) die ik hiervoor kan inzetten?
Want als het niet lukt via SPSS, dan lijkt het me beter om gewoon de survey resultaten te analyseren en zelf grafieken te maken over hoe positief (of negatief) de respondenten de vragen uit de verschillende vragen hebben beantwoord.
Ik heb voor mijn scriptie onderzoek gedaan naar de volgorde van persoonlijk voornaamwoorden in het Nieuwgrieks door middel van het afnemen van een enquête. Ik heb 5 algemene vragen gesteld om te bepalen of de respondenten tot de doelgroep behoren (of dat de enquête eventueel afgebroken moet worden), uit welke regio van Griekenland de respondent afkomstig is en wat het geslacht en de leeftijd van de respondent is. Vervolgens heb ik 19 zinnen voorgelegd, waarbij de respondenten op een schaal van 1 tot 4 konden kiezen (ja, waarschijnlijk wel, waarschijnlijk niet, nee) in hoeverre het mogelijk was die zinnen te horen in hun omgeving.
Uiteindelijk heeft mijn enquête 92 respondenten opgeleverd. Een voldoende aantal binnen de taalwetenschap. Met een χ2-toets heb ik vervolgens per vraag bepaald in hoeverre de verdeling over de antwoordmogelijkheden willekeurig is (verdeling 23-23-23-23). Er is geen hypothese die getoetst kan worden, omdat er slechts twee halve alinea's over geschreven zijn door twee verschillende auteurs en hun beweringen lijnrecht tegenover elkaar staan. Van de 19 zinnen hield ik er 14 over met p<0,01 2 met 0,01<p<0,05. 1 zin met 0,05<p<0,1 en 2 met p>0,1. Ik heb besloten alledrie deze zinnen buiten het onderzoek te houden.
Ik heb met een ongepaarde t-toets gekeken of er een significant verschil zat tussen mannen en vrouwen om zo deze insignificantie te kunnen verklaren, maar dat leverde niets op. Ook dit verschil was insignificant.
Met de mediaan heb ik vervolgens bepaald of een zin wel of niet aangenomen kan worden als acceptabel. Mediaan 1-2 is acceptabel en mediaan 3-4 is niet acceptabel. Uiteindelijk blijkt dat beide volgorden met meerdere zinnen acceptabel zijn. Van de 19 zinnen kon ik in verband met het wegvallen van een aantal zinnen door gebrek aan significantie 6 paren vormen. Bij het bekijken van de gemiddelden zag ik dat er toch wat verschillen in het gemiddelde zaten die op een voorkeur voor de ene of de andere volgorde zouden kunnen wijzen.
Hoe kan ik bepalen of er tussen twee onafhankelijke (?) variabelen met dezelfde schaalverdeling van 1 tot 4 een significant verschil bestaat? Ik had in eerste instantie gedacht aan een gepaarde t-toets, maar volgens mij is deze alleen voor afhankelijke variabelen of heb ik dat mis?
Alle statistiek die ik heb gebruikt tot nu toe, heb ik in de afgelopen 3 a 4 dagen bijgespijkerd, na N&T op het VWO met biologie (gelukkig snapte ik dus wel de χ2-toets) heb ik besloten een talenstudie te gaan doen. Ik heb dus alleen Wiskunde B gedaan en nooit iets met statistiek te maken gehad. Ik maak gebruik van SPSS, dus als jullie hier rekening mee zouden willen houden in jullie tips, zou dat fijn zijn!
Uiteindelijk heeft mijn enquête 92 respondenten opgeleverd. Een voldoende aantal binnen de taalwetenschap. Met een χ2-toets heb ik vervolgens per vraag bepaald in hoeverre de verdeling over de antwoordmogelijkheden willekeurig is (verdeling 23-23-23-23). Er is geen hypothese die getoetst kan worden, omdat er slechts twee halve alinea's over geschreven zijn door twee verschillende auteurs en hun beweringen lijnrecht tegenover elkaar staan. Van de 19 zinnen hield ik er 14 over met p<0,01 2 met 0,01<p<0,05. 1 zin met 0,05<p<0,1 en 2 met p>0,1. Ik heb besloten alledrie deze zinnen buiten het onderzoek te houden.
Ik heb met een ongepaarde t-toets gekeken of er een significant verschil zat tussen mannen en vrouwen om zo deze insignificantie te kunnen verklaren, maar dat leverde niets op. Ook dit verschil was insignificant.
Met de mediaan heb ik vervolgens bepaald of een zin wel of niet aangenomen kan worden als acceptabel. Mediaan 1-2 is acceptabel en mediaan 3-4 is niet acceptabel. Uiteindelijk blijkt dat beide volgorden met meerdere zinnen acceptabel zijn. Van de 19 zinnen kon ik in verband met het wegvallen van een aantal zinnen door gebrek aan significantie 6 paren vormen. Bij het bekijken van de gemiddelden zag ik dat er toch wat verschillen in het gemiddelde zaten die op een voorkeur voor de ene of de andere volgorde zouden kunnen wijzen.
Hoe kan ik bepalen of er tussen twee onafhankelijke (?) variabelen met dezelfde schaalverdeling van 1 tot 4 een significant verschil bestaat? Ik had in eerste instantie gedacht aan een gepaarde t-toets, maar volgens mij is deze alleen voor afhankelijke variabelen of heb ik dat mis?
Alle statistiek die ik heb gebruikt tot nu toe, heb ik in de afgelopen 3 a 4 dagen bijgespijkerd, na N&T op het VWO met biologie (gelukkig snapte ik dus wel de χ2-toets) heb ik besloten een talenstudie te gaan doen. Ik heb dus alleen Wiskunde B gedaan en nooit iets met statistiek te maken gehad. Ik maak gebruik van SPSS, dus als jullie hier rekening mee zouden willen houden in jullie tips, zou dat fijn zijn!
Ik denk dat het grootste punt is dat je enkel afhankelijke variabelen hebt. Doordat de vijf schalen samen de afhankelijke variabelen vormen, zijn ze zelf ook afhankelijke variabelen. Als je merkwaarde ook nog op een andere manier kunt meten, dan kun je de relatie tussen de vijf schalen in je vragenlijst en merkwaarde meten. Als je dat niet hebt is de vraag of je een of meerdere onafhankelijke variabelen hebt in je data waar je iets mee kunt.quote:
[..]
En een stap terugnemen en de schalen op een andere manier indelen is geen optie?
Onderling verband met de verschillende schalen is niet persé wat ik zoek namelijk. Ik wil weten welk aspect van merkmeerwaarde de respondenten het belangrijkst vinden, zodat de organisatie zich daar op kan focussen. En als ik de resultaten bekijk, dan zie ik dat de meest positieve antwoorden zijn ingevuld bij de schaal content. Hoe laat ik dit zien door middel van een test?
Is er geen andere toets (Mann-Whitney U Test / Pearson R / Anova ??) die ik hiervoor kan inzetten?
Want als het niet lukt via SPSS, dan lijkt het me beter om gewoon de survey resultaten te analyseren en zelf grafieken te maken over hoe positief (of negatief) de respondenten de vragen uit de verschillende vragen hebben beantwoord.
Een ander punt is: Wat zegt een hogere score op een bepaalde subschaal? Aangezien je de subschalen optelt zorgt een hogere score op een subschaal voor een hogere merkwaarde, maar dat betekent niet dat de invloed alleen maar groot is als de score hoog is. Een subschaal waar laag op wordt gescoord kan ook een grote invloed hebben.
Wat heb je precies gemeten in je schalen? Zijn dat algemene vragen: "Voor mij is tevredenheid belangrijk." of specifieke vragen: "Ik ben heel erg tevreden met merk X." In dat laatste geval kun je aanbevelingen doen op basis van de data met betrekking tot het merk. Bijvoorbeeld "Deelnemers waren erg tevreden over de kwaliteit van het merk, maar niet tevreden over de prijs. Als jullie de merkwaarde willen vergroten is het dus verstanding om nog eens naar de prijs te kijken in plaats van te focussen op de kwaliteit."
(Overigens zijn mijn voorbeelden totaal uit de lucht gegrepen aangezien ik je onderzoek niet echt ken, maar misschien kun je er iets mee.)
Je probleem is geen probleem van de toets maar, no offense, van een verkeerd opgezet onderzoek. De vraag die je wilt beantwoorden kun je niet beantwoorden met de data die je verzameld hebt.quote:
[..]
En een stap terugnemen en de schalen op een andere manier indelen is geen optie?
Onderling verband met de verschillende schalen is niet persé wat ik zoek namelijk. Ik wil weten welk aspect van merkmeerwaarde de respondenten het belangrijkst vinden, zodat de organisatie zich daar op kan focussen. En als ik de resultaten bekijk, dan zie ik dat de meest positieve antwoorden zijn ingevuld bij de schaal content. Hoe laat ik dit zien door middel van een test?
Is er geen andere toets (Mann-Whitney U Test / Pearson R / Anova ??) die ik hiervoor kan inzetten?
Want als het niet lukt via SPSS, dan lijkt het me beter om gewoon de survey resultaten te analyseren en zelf grafieken te maken over hoe positief (of negatief) de respondenten de vragen uit de verschillende vragen hebben beantwoord.
Ik snap niet zo goed wat je hier doet. Waarom zouden die antwoorden gelijk verdeeld moeten zijn? Waarom haal je de gelijk verdeelde zinner er uit?quote:
Ik heb voor mijn scriptie onderzoek gedaan naar de volgorde van persoonlijk voornaamwoorden in het Nieuwgrieks door middel van het afnemen van een enquête. Ik heb 5 algemene vragen gesteld om te bepalen of de respondenten tot de doelgroep behoren (of dat de enquête eventueel afgebroken moet worden), uit welke regio van Griekenland de respondent afkomstig is en wat het geslacht en de leeftijd van de respondent is. Vervolgens heb ik 19 zinnen voorgelegd, waarbij de respondenten op een schaal van 1 tot 4 konden kiezen (ja, waarschijnlijk wel, waarschijnlijk niet, nee) in hoeverre het mogelijk was die zinnen te horen in hun omgeving.
Uiteindelijk heeft mijn enquête 92 respondenten opgeleverd. Een voldoende aantal binnen de taalwetenschap. Met een χ2-toets heb ik vervolgens per vraag bepaald in hoeverre de verdeling over de antwoordmogelijkheden willekeurig is (verdeling 23-23-23-23).
Er is geen hypothese die getoetst kan worden, omdat er slechts twee halve alinea's over geschreven zijn door twee verschillende auteurs en hun beweringen lijnrecht tegenover elkaar staan. Van de 19 zinnen hield ik er 14 over met p<0,01 2 met 0,01<p<0,05. 1 zin met 0,05<p<0,1 en 2 met p>0,1. Ik heb besloten alledrie deze zinnen buiten het onderzoek te houden.
Welke insignificantie? In snap nog steeds niet helemaal de bedoeling van de chi-square toets maar 3/19 n.s. is niet vreemd en hoeft ook niet verklaard te worden, het is statistisch vrij logisch dat niet altijd alles significant verschilt zelfs wanneer er in de wekelijkheid wel zo'n verband is.quote:Ik heb met een ongepaarde t-toets gekeken of er een significant verschil zat tussen mannen en vrouwen om zo deze insignificantie te kunnen verklaren, maar dat leverde niets op. Ook dit verschil was insignificant.
De beoordeling van de zinnen is een afhankelijke variabele dus je kunt gewoon een paired t-test doen.quote:Met de mediaan heb ik vervolgens bepaald of een zin wel of niet aangenomen kan worden als acceptabel. Mediaan 1-2 is acceptabel en mediaan 3-4 is niet acceptabel. Uiteindelijk blijkt dat beide volgorden met meerdere zinnen acceptabel zijn. Van de 19 zinnen kon ik in verband met het wegvallen van een aantal zinnen door gebrek aan significantie 6 paren vormen. Bij het bekijken van de gemiddelden zag ik dat er toch wat verschillen in het gemiddelde zaten die op een voorkeur voor de ene of de andere volgorde zouden kunnen wijzen.
Hoe kan ik bepalen of er tussen twee onafhankelijke (?) variabelen met dezelfde schaalverdeling van 1 tot 4 een significant verschil bestaat? Ik had in eerste instantie gedacht aan een gepaarde t-toets, maar volgens mij is deze alleen voor afhankelijke variabelen of heb ik dat mis?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-

Hallo allemaal!
Ik ben bezig met mijn onderzoek naar de kwaliteit van de Nederlandse kinderopvang en de rol die pedagogisch medewerkers (pm'ers) hierin spelen. De constructen in de vragenlijst worden zowel op een directe als een indirecte manier gemeten. Bij de indirecte manier worden telkens twee vragen gesteld (die elk een andere antwoordschaal hebben) en de score van deze items worden met elkaar vermenigvuldigd.
Bijvoorbeeld het construct "sociale norm" wordt op een indirecte manier gemeten door:
- vraag 1: "mijn collega's werken... [Niet -3 -2 -1 0 +1 +2 +3 Wel]... volgens de pedagogische visie van de instelling"
x
- vraag 2: "doen wat andere collega's ook doen is belangrijk voor mij" [Zeer oneens 1 2 3 4 5 6 7 Zeer eens].
+ vraag3 x vraag4, etc. etc.
Dus: het construct "sociale norm" = (vraag1 x vraag2) + (vraag3 x vraag4) + (etc. etc.). etc.
Nou vraag ik me af hoe ik deze items in moet voeren in mijn variable view van spss. Ik heb ze ingevoerd als ordinale variabelen en wilde daarbij de values toevoegen. Ik weet niet goed hoe ik dit aan moet pakken. Mogen de values in spss ook negatieve waarden bevatten? Of kan dit later problemen veroorzaken met bepaalde berekeningen?
En kan ik spss ook een variabele aanmaken die de totale constructscore berekent/weergeeft? Zo ja, hoe?
Ik ben bezig met mijn onderzoek naar de kwaliteit van de Nederlandse kinderopvang en de rol die pedagogisch medewerkers (pm'ers) hierin spelen. De constructen in de vragenlijst worden zowel op een directe als een indirecte manier gemeten. Bij de indirecte manier worden telkens twee vragen gesteld (die elk een andere antwoordschaal hebben) en de score van deze items worden met elkaar vermenigvuldigd.
Bijvoorbeeld het construct "sociale norm" wordt op een indirecte manier gemeten door:
- vraag 1: "mijn collega's werken... [Niet -3 -2 -1 0 +1 +2 +3 Wel]... volgens de pedagogische visie van de instelling"
x
- vraag 2: "doen wat andere collega's ook doen is belangrijk voor mij" [Zeer oneens 1 2 3 4 5 6 7 Zeer eens].
+ vraag3 x vraag4, etc. etc.
Dus: het construct "sociale norm" = (vraag1 x vraag2) + (vraag3 x vraag4) + (etc. etc.). etc.
Nou vraag ik me af hoe ik deze items in moet voeren in mijn variable view van spss. Ik heb ze ingevoerd als ordinale variabelen en wilde daarbij de values toevoegen. Ik weet niet goed hoe ik dit aan moet pakken. Mogen de values in spss ook negatieve waarden bevatten? Of kan dit later problemen veroorzaken met bepaalde berekeningen?
En kan ik spss ook een variabele aanmaken die de totale constructscore berekent/weergeeft? Zo ja, hoe?
Je kunt in spss gewoon negatieve waardes gebruiken. Als je een schaal gebruikt hoef je geen ordinale schaal aan te geven maar kun je gewoon continu/interval gebruiken.quote:Op donderdag 21 augustus 2014 01:10 schreef Natoo het volgende:
Hallo allemaal!
Ik ben bezig met mijn onderzoek naar de kwaliteit van de Nederlandse kinderopvang en de rol die pedagogisch medewerkers (pm'ers) hierin spelen. De constructen in de vragenlijst worden zowel op een directe als een indirecte manier gemeten. Bij de indirecte manier worden telkens twee vragen gesteld (die elk een andere antwoordschaal hebben) en de score van deze items worden met elkaar vermenigvuldigd.
Bijvoorbeeld het construct "sociale norm" wordt op een indirecte manier gemeten door:
- vraag 1: "mijn collega's werken... [Niet -3 -2 -1 0 +1 +2 +3 Wel]... volgens de pedagogische visie van de instelling"
x
- vraag 2: "doen wat andere collega's ook doen is belangrijk voor mij" [Zeer oneens 1 2 3 4 5 6 7 Zeer eens].
+ vraag3 x vraag4, etc. etc.
Dus: het construct "sociale norm" = (vraag1 x vraag2) + (vraag3 x vraag4) + (etc. etc.). etc.
Nou vraag ik me af hoe ik deze items in moet voeren in mijn variable view van spss. Ik heb ze ingevoerd als ordinale variabelen en wilde daarbij de values toevoegen. Ik weet niet goed hoe ik dit aan moet pakken. Mogen de values in spss ook negatieve waarden bevatten? Of kan dit later problemen veroorzaken met bepaalde berekeningen?
En kan ik spss ook een variabele aanmaken die de totale constructscore berekent/weergeeft? Zo ja, hoe?
Je kunt een variabele aanmaken die tde total score weergeeft door in compute de variabelen op te tellen of het gemiddelde te nemen (wat je wilt).
Heb je zelf bedacht om die twee variabelen te vermeningvuldigen of is dat standaard gebruik? Het is namelijk nogal vreemd om dat te doen omdat je daarmee statistische verbanden creeert waarvan je niet weet of die eigenlijk representatief zijn voor datgene dat je probeert te meten.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Dank voor je snelle reactie! Ik begrijp niet helemaal waarom het dan continu/interval (dus "scale") is. Want in principe gaat het toch om ordinale variabelen als "zeer oneens", "een beetje oneens", etc.?quote:Als je een schaal gebruikt hoef je geen ordinale schaal aan te geven maar kun je gewoon continu/interval gebruiken.
En als het een scale-variabele is, moet/kan ik dan wel gewoon values aanmaken? En zo ja, neem je dan alleen de uiteinden (dus bijvoorbeeld: "value 1 = zeer oneens" en "value 7 = zeer eens")?. Of vul ik de middelste values zelf in (bijvoorbeeld met "value 2 = oneens", "value 3 = een beetje oneens", etc.)?
Helaas hoort dit bij het type vragenlijst dat ik heb gebruikt.quote:Heb je zelf bedacht om die twee variabelen te vermeningvuldigen of is dat standaard gebruik? Het is namelijk nogal vreemd om dat te doen omdat je daarmee statistische verbanden creeert waarvan je niet weet of die eigenlijk representatief zijn voor datgene dat je probeert te meten. .
Wat je zegt klopt officieel, maar het is gebleken dat als je likert-type schalen gebruikt met 5 of meer opties (en je schaal neit extreem vreemd is) je eigenlijk geen onderschatte p-waardes krijgt met parametrische (t-test/anova) toetsen.En aangezien parametrische toetsen sterker zijn en gemakkelijker te interpreteren/vertalen naar de echte wereld zou ik die gebruiken. Er zijn best veel papers over geschreven als je een bron nodig hebt om het te beargumenterenquote:
[..]
Dank voor je snelle reactie! Ik begrijp niet helemaal waarom het dan continu/interval (dus "scale") is. Want in principe gaat het toch om ordinale variabelen als "zeer oneens", "een beetje oneens", etc.?
En als het een scale-variabele is, moet/kan ik dan wel gewoon values aanmaken? En zo ja, neem je dan alleen de uiteinden (dus bijvoorbeeld: "value 1 = zeer oneens" en "value 7 = zeer eens")?. Of vul ik de middelste values zelf in (bijvoorbeeld met "value 2 = oneens", "value 3 = een beetje oneens", etc.)?
[..]
Ik snap niet zo goed wat je daarna bedoelt met "values" dat zou hetzelfde zijn met ordinale interpretatie
Ik vind het echt een hele vreemde schaal, welke is dat? Superraar dat als je bv 0 aangeeft op vraag 1 (mijn collegas werken soms wel en soms niet volgens...) het dan niet uit zou maken of je 1 of 7 scoort op vraag 2.quote:Helaas hoort dit bij het type vragenlijst dat ik heb gebruikt.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Oja, ik begrijp het! Dankje!quote:Wat je zegt klopt officieel, maar het is gebleken dat als je likert-type schalen gebruikt met 5 of meer opties (en je schaal neit extreem vreemd is) je eigenlijk geen onderschatte p-waardes krijgt met parametrische (t-test/anova) toetsen.En aangezien parametrische toetsen sterker zijn en gemakkelijker te interpreteren/vertalen naar de echte wereld zou ik die gebruiken. Er zijn best veel papers over geschreven als je een bron nodig hebt om het te beargumenteren
Nou, ik dacht dat als je meetniveau "scale" is dat je dan eigenlijk geen values invoert.. maar dat kan dus wel? En ik begrijp niet goed hoe ik de values in moet voeren, aangezien ik alleen de uiteinden van de schaal heb.quote:Ik snap niet zo goed wat je daarna bedoelt met "values" dat zou hetzelfde zijn met ordinale interpretatie
Ja, raar is het wel! Het is de vragenlijst aangaande de Theory of Planned Behavior.. er is een manual voor ontwikkeld hoe je de vragen precies op moet stellen en hoe je ze moet scoren, en die heb ik hierbij gebruikt.quote:Ik vind het echt een hele vreemde schaal, welke is dat? Superraar dat als je bv 0 aangeeft op vraag 1 (mijn collegas werken soms wel en soms niet volgens...) het dan niet uit zou maken of je 1 of 7 scoort op vraag 2.
Hmm in mijn quote is de helft van je bericht weg. Iig die namen hoef je in spss niet aan je schaal te geven, daar kun je gewoon -3 tot +3 en 1-7 gebruiken. De anchors (helemaal wel / helemaal niet etc.) gebruik je allen in je methode-beschrijving.quote:
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Oke! Dank!!quote:Iig die namen hoef je in spss niet aan je schaal te geven, daar kun je gewoon -3 tot +3 en 1-7 gebruiken. De anchors (helemaal wel / helemaal niet etc.) gebruik je allen in je methode-beschrijving.
Laat maar 
[ Bericht 70% gewijzigd door SJK op 23-08-2014 11:21:45 ]
[ Bericht 70% gewijzigd door SJK op 23-08-2014 11:21:45 ]
Het is altijd raak met kaas van SJaaK
Hoi Jan,
Dat zijn we niet. Als je een bijles internetkunde wilt, lees de voorwaarden en regels van FOK! eens door!
Groetjes
Dat zijn we niet. Als je een bijles internetkunde wilt, lees de voorwaarden en regels van FOK! eens door!
Groetjes
Op dinsdag 25 augustus 2015 15:48 schreef Toekito het volgende:
de grootste schande van heel FOK! naast Fylax is Kano als mod.
de grootste schande van heel FOK! naast Fylax is Kano als mod.
Dag allemaal,
Ik heb een vraag over een multilevel analyse, waarvan ik hoop dat iemand me kan helpen.
Ik vergelijk twee groepen met elkaar tav van het verloop van scores over de tijd. Iedere drie maanden wordt er door de personen uit de twee groepen een vragenlijst ingevuld waar een score uit komt. De looptijd is max. een jaar, maar bij sommigen is dit korter. Niet iedereen heeft evenveel vragenlijsten ingevuld, soms is er maar 1, soms 2, soms 3 of soms 4. Mijn hypothese is dat de ene groep een vrij vlak verloop heeft (maw de score op de vragenlijsten neemt in de loop van de tijd niet af) en dat de andere groep een steiler verloop heeft (maw de score op de vragenlijsten loopt in de loop van de tijd af). Nu kwam ik op een multilevelanalyse, maar kreeg ik van mijn supervisor de vraag of de tijdsvariabele gecentreerd moet worden?! Kan iemand daar voor mij op basis van deze info iets zinnigs over zeggen? Alvast heel hartelijk dank!
Ik heb een vraag over een multilevel analyse, waarvan ik hoop dat iemand me kan helpen.
Ik vergelijk twee groepen met elkaar tav van het verloop van scores over de tijd. Iedere drie maanden wordt er door de personen uit de twee groepen een vragenlijst ingevuld waar een score uit komt. De looptijd is max. een jaar, maar bij sommigen is dit korter. Niet iedereen heeft evenveel vragenlijsten ingevuld, soms is er maar 1, soms 2, soms 3 of soms 4. Mijn hypothese is dat de ene groep een vrij vlak verloop heeft (maw de score op de vragenlijsten neemt in de loop van de tijd niet af) en dat de andere groep een steiler verloop heeft (maw de score op de vragenlijsten loopt in de loop van de tijd af). Nu kwam ik op een multilevelanalyse, maar kreeg ik van mijn supervisor de vraag of de tijdsvariabele gecentreerd moet worden?! Kan iemand daar voor mij op basis van deze info iets zinnigs over zeggen? Alvast heel hartelijk dank!
Ik kan er iets zinnigs over zeggen maar niet op basis van de gegeven infoquote:
Dag allemaal,
Ik heb een vraag over een multilevel analyse, waarvan ik hoop dat iemand me kan helpen.
Ik vergelijk twee groepen met elkaar tav van het verloop van scores over de tijd. Iedere drie maanden wordt er door de personen uit de twee groepen een vragenlijst ingevuld waar een score uit komt. De looptijd is max. een jaar, maar bij sommigen is dit korter. Niet iedereen heeft evenveel vragenlijsten ingevuld, soms is er maar 1, soms 2, soms 3 of soms 4. Mijn hypothese is dat de ene groep een vrij vlak verloop heeft (maw de score op de vragenlijsten neemt in de loop van de tijd niet af) en dat de andere groep een steiler verloop heeft (maw de score op de vragenlijsten loopt in de loop van de tijd af). Nu kwam ik op een multilevelanalyse, maar kreeg ik van mijn supervisor de vraag of de tijdsvariabele gecentreerd moet worden?! Kan iemand daar voor mij op basis van deze info iets zinnigs over zeggen? Alvast heel hartelijk dank!
Basically heb je twee opties:
niet centreren, waarbij t=0 dus t=0 blijft.
centreren waarbij de gemiddelde t 0 wordt.
afthankelijk van wat t voorstelt is het wel of niet aan te raden, aangezien het voor de statistiek niet uit maakt. (Ik ga er in deze reactie vanuit dat je tijd alleen als main-effect meeneemt, als je het als deel in een interactie gebruikt ligt het wat gecompliceerder.)
Stel je voor dat t de tijd is sinds het begin van een medicijnkuur, in dit geval is het veel logischer om tijd niet te centreren, omdat het effect van tijd ten opzichte van de gemiddelde tijd in jouw onderzoek superingewikkeld wordt om te interpreteren, het is veel logischer om het effect weer te geven in tijd sinds het begin van de kuur.
Nu wilde ik een voorbeeld geven waarin het wel logisch is om tijd te centreren maar het lukt me niet op binnen een minuut op iets te komen, nou ja punt lijkt me duidelijk toch?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Bedankt voor je reactie oompaloompa, ik gebruik wel tijd als deel van de interactie namelijk tijd x groep
Welke info kan ik nog geven zodat je daar iets over zou kunnen zeggen?
Welke info kan ik nog geven zodat je daar iets over zou kunnen zeggen?
Gebruik je dummy-coderinig voor groep? (0-1)quote:
Bedankt voor je reactie oompaloompa, ik gebruik wel tijd als deel van de interactie namelijk tijd x groep
Welke info kan ik nog geven zodat je daar iets over zou kunnen zeggen?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Dan maakt het statistisch niks uit dus zou ik gaan wat het logischt is qua interpretatiequote:
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Hallo allemaal,
Ik wil de missings in mijn dataset imputeren dus wil eerst een Little's MCAR test uitvoeren.
Ik heb begrepen dat dit alleen kan met continue variabelen. Nou vraag ik me een aantal dingen af:
• "leeftijd" of "aantal kinderen" is continu, maar dat is toch niet iets wat je laat schatten door spss?
• de meeste items (eigenlijk vrijwel alle items) bestaan uit antwoordschalen "1 = helemaal niet mee eens", etc., dus dan kan ik ze niet behandelen als continue variabelen, toch? (dan blijft er dus niks meer over om te imputeren. Ik heb een aantal 7-punts Likertschalen die ik als "scale" variabelen heb ingevoerd, dus dit is het enige wat ik zou kunnen imputeren)
• wat doe ik met de missings die ik niet kan imputeren (bijvoorbeeld omdat ze niet continu zijn)? Daar blijft dan "999" staan.. moet ik er daarna nog iets mee?
• ik heb al het één en ander geprobeerd, en uit de MCAR-test komt telkens het significantieniveau 1,000. Kan dit kloppen? (ik heb maar een kleine dataset.. 25 respondenten).
Ik hoop dat iemand mij meer duidelijkheid kan geven
Ik wil de missings in mijn dataset imputeren dus wil eerst een Little's MCAR test uitvoeren.
Ik heb begrepen dat dit alleen kan met continue variabelen. Nou vraag ik me een aantal dingen af:
• "leeftijd" of "aantal kinderen" is continu, maar dat is toch niet iets wat je laat schatten door spss?
• de meeste items (eigenlijk vrijwel alle items) bestaan uit antwoordschalen "1 = helemaal niet mee eens", etc., dus dan kan ik ze niet behandelen als continue variabelen, toch? (dan blijft er dus niks meer over om te imputeren. Ik heb een aantal 7-punts Likertschalen die ik als "scale" variabelen heb ingevoerd, dus dit is het enige wat ik zou kunnen imputeren)
• wat doe ik met de missings die ik niet kan imputeren (bijvoorbeeld omdat ze niet continu zijn)? Daar blijft dan "999" staan.. moet ik er daarna nog iets mee?
• ik heb al het één en ander geprobeerd, en uit de MCAR-test komt telkens het significantieniveau 1,000. Kan dit kloppen? (ik heb maar een kleine dataset.. 25 respondenten).
Ik hoop dat iemand mij meer duidelijkheid kan geven
Of is het dan beter om het maar gewoon zo te laten en met de oorspronkelijke dataset aan de slag te gaan? (En zo ja, moet je dan alsnog iets met die "999" of kan ik hiermee gewoon aan de slag?).
Als het niet nodig is, imputeer ik nooit data dus ik weet niet zo goed hoe het moet Maar als je de optie hebt het niet te doen, zou ik het niet doen (missings zijn volgens mij alleen een probleem bij multilevel analyses & repeated measures etc.)
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
zorg er dan trouwens wel voor dat 999 aangegeven staat als missing en niet meegenomen wordt als een score van 999! Heb ik een keer gedaan, snapte helemaal niks van m'n resultaten en duurde veel te lang voordat het kwartje viel
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Haha! Yes! Heb ik! Dank!quote:zorg er dan trouwens wel voor dat 999 aangegeven staat als missing en niet meegenomen wordt als een score van 999!
Nog een vraagje.. welke opties heb ik als m'n cronbach's alpha te laag is?
- schaal eruit laten
- schaal erin laten maar terughoudend omgaan met de resultaten?
- nog andere opties?
Ik begrijp niet zo goed waarom mijn alpha zo laag is.. ik gebruik namelijk een betrouwbaar instrument (s-EMBU), waarbij vragen worden gesteld over de eigen opvoeding.. van zowel de vader als de moeder.
De alpha's bij de vader-items zijn allemaal hoog (gemiddeld .92) maar de alpha's bij de moeder-items zijn laag (.64, .65, .70). Terwijl het om dezelfde vragen gaat..
Iemand een idee?
Oja.. ik begrijp dat ik ook losse items uit de schaal kan verwijderen. Maar ook alle alpha scores van "if item deleted" zijn nog te laag (< .70).
Dat zijn toch best aardige alpha's (voor enquêtedata). Heb je missings op je schaalvragen en kan je beredeneren waarom ze missing zijn?
Aldus.
oh, volgens mij moesten wij onze alpha's boven de .70 houden..
De respondenten met missings worden eruit gelaten dacht ik? (listwise deletion).
Ik heb echter ook alpha's van .45 en .47, maar weet dus niet goed wat ik ermee aan moet..
De respondenten met missings worden eruit gelaten dacht ik? (listwise deletion).
Ik heb echter ook alpha's van .45 en .47, maar weet dus niet goed wat ik ermee aan moet..
Vraag! We mogen dit jaar ook R gebruiken in plaats van SPSS (wordt aangeraden als men de research master overweegt), dus daar ben ik nu eens mee aan het stoeien en het gaat aardig. Ik heb een achtergrond in python en C++, dus de command line is mij in ieder geval niet vreemd en het zelf schrijven van functies ook niet, dat scheelt. Desondanks is het toch weer best wel anders. Met veel ploeteren kom ik er wel doorheen, maar nu loop ik toch echt vast.
Ik heb drie groepen, elke groep bestaat uit een reeks getallen. Groep 1 & 2 hebben 12 getallen, groep 3 heeft er 9. Ik moet nu voor elke groep een boxplot maken en die samen laten zien in één grafiek. Ik heb elke groep als volgt ingevoerd:
> group1 <- c(27, 22, 29, 21, 19, 33, 16, 20, 24, 27, 28, 19)
> group2 <- c(12, 12, 15, 9, 20, 18, 17, 14, 14, 2, 17, 19)
> group3 <- c(18, 4, 22, 15, 18, 19, 22, 12, 12)
Een boxplot maken voor één groep is geen probleem:
> boxplot(group1, main="Boxplot", ylab="group1")
Groep 1 en 2 kan ik nog samenvoegen in één grafiek (hoewel het er wat lelijk uitziet en ik er nog wat dingen aan moet tweaken dan). Dat doe ik als volgt:
> groups12 <- data.frame(group1,group2)
> boxplot(group1,group2,data=groups12, main="Boxplot", xlab="Group", ylab="Trees")
Maar als ik probeer groep 1, 2 EN 3 samen te voegen, geeft R een error omdat de argumenten een verschillend aantal rijen hebben (12 en 9). Groep 3 aanvullen met nullen is natuurlijk geen optie.
Iemand een idee?
Ik heb drie groepen, elke groep bestaat uit een reeks getallen. Groep 1 & 2 hebben 12 getallen, groep 3 heeft er 9. Ik moet nu voor elke groep een boxplot maken en die samen laten zien in één grafiek. Ik heb elke groep als volgt ingevoerd:
> group1 <- c(27, 22, 29, 21, 19, 33, 16, 20, 24, 27, 28, 19)
> group2 <- c(12, 12, 15, 9, 20, 18, 17, 14, 14, 2, 17, 19)
> group3 <- c(18, 4, 22, 15, 18, 19, 22, 12, 12)
Een boxplot maken voor één groep is geen probleem:
> boxplot(group1, main="Boxplot", ylab="group1")
Groep 1 en 2 kan ik nog samenvoegen in één grafiek (hoewel het er wat lelijk uitziet en ik er nog wat dingen aan moet tweaken dan). Dat doe ik als volgt:
> groups12 <- data.frame(group1,group2)
> boxplot(group1,group2,data=groups12, main="Boxplot", xlab="Group", ylab="Trees")
Maar als ik probeer groep 1, 2 EN 3 samen te voegen, geeft R een error omdat de argumenten een verschillend aantal rijen hebben (12 en 9). Groep 3 aanvullen met nullen is natuurlijk geen optie.
Iemand een idee?
Your opinion of me is none of my business.
De reden dat je een foutmelding krijgt is dat een dataframe er vanuit gaat dat elke variabele die je eraan toevoegt even lang is. Als je terugdenkt aan SPSS zou je voor 3 cases een lege cel hebben in "group 3" variabele. Wat R doet is dat melden (Hallo, je mist data!) maar de boxplot werkt gewoon (toen ik het probeerde wel in ieder geval.) Als je echt heel graag van die foutmelding af wil kun je in dit geval de reeks van group3 aanvullen met NA, NA, NA op het einde. Dat geeft een missing variable aan. Mochten de getallen van de verschillende variabelen echt bij specifieke cases horen (27, 12, 18 als scores van 1 proefpersoon bijvoorbeeld) dan moet je de NA codering op de juiste, missende waarde, plek invullen.quote:
Vraag! We mogen dit jaar ook R gebruiken in plaats van SPSS (wordt aangeraden als men de research master overweegt), dus daar ben ik nu eens mee aan het stoeien en het gaat aardig. Ik heb een achtergrond in python en C++, dus de command line is mij in ieder geval niet vreemd en het zelf schrijven van functies ook niet, dat scheelt. Desondanks is het toch weer best wel anders.
Ik heb drie groepen, elke groep bestaat uit een reeks getallen. Groep 1 & 2 hebben 12 getallen, groep 3 heeft er 9. Ik moet nu voor elke groep een boxplot maken en die samen laten zien in één grafiek. Ik heb elke groep als volgt ingevoerd:
> group1 <- c(27, 22, 29, 21, 19, 33, 16, 20, 24, 27, 28, 19)
> group2 <- c(12, 12, 15, 9, 20, 18, 17, 14, 14, 2, 17, 19)
> group3 <- c(18, 4, 22, 15, 18, 19, 22, 12, 12)
Een boxplot maken voor één groep is geen probleem:
> boxplot(group1, main="Boxplot", ylab="group1")
Groep 1 en 2 kan ik nog samenvoegen in één grafiek (hoewel het er wat lelijk uitziet en ik er nog wat dingen aan moet tweaken dan). Dat doe ik als volgt:
> groups12 <- data.frame(group1,group2)
> boxplot(group1,group2,data=groups12, main="Boxplot", xlab="Group", ylab="Trees")
Maar als ik probeer groep 1, 2 EN 3 samen te voegen, geeft R een error omdat de argumenten een verschillend aantal rijen hebben (12 en 9). Groep 3 aanvullen met nullen is natuurlijk geen optie.
Iemand een idee?
quote:
Oja.. ik begrijp dat ik ook losse items uit de schaal kan verwijderen. Maar ook alle alpha scores van "if item deleted" zijn nog te laag (< .70).
Wat je kunt doen (Ik weet niet of je dit al geprobeerd hebt) is te werken met de "if item deleted" waar je het over had. Je draait die analyse en leest uit de tabel af welk item alpha het meeste zou verhogen als deze weg zou worden gelaten. Die vraag haal je eruit, en dan doe je deze analyse nog een keer. de "alpha if item deleted" zal veranderen doordat je de analyse opnieuw doet na het verwijderen van een vraag, je kunt dus niet uitgaan van de getallen van de eerste keer dat je deze analyse deed.quote:
oh, volgens mij moesten wij onze alpha's boven de .70 houden..
De respondenten met missings worden eruit gelaten dacht ik? (listwise deletion).
Ik heb echter ook alpha's van .45 en .47, maar weet dus niet goed wat ik ermee aan moet..
Dit lijkt onlogisch, omdat je leert dat het belangrijk is om een construct om meerdere manieren te meten voor een hogere betrouwbaarheid. Als echter uit je analyse blijkt dat een kleiner aantal vragen een hogere betrouwbaarheid geeft, dan is het onlogisch om vragen mee te nemen die eigenlijk niet meten wat je wil meten.
Welke boxplot werkt er dan? Het samenvoegen van drie groepen werkt niet, als ik dat probeer krijg ik de melding:quote:
[..]
De reden dat je een foutmelding krijgt is dat een dataframe er vanuit gaat dat elke variabele die je eraan toevoegt even lang is. Als je terugdenkt aan SPSS zou je voor 3 cases een lege cel hebben in "group 3" variabele. Wat R doet is dat melden (Hallo, je mist data!) maar de boxplot werkt gewoon (toen ik het probeerde wel in ieder geval.) Als je echt heel graag van die foutmelding af wil kun je in dit geval de reeks van group3 aanvullen met NA, NA, NA op het einde. Dat geeft een missing variable aan. Mochten de getallen van de verschillende variabelen echt bij specifieke cases horen (27, 12, 18 als scores van 1 proefpersoon bijvoorbeeld) dan moet je de NA codering op de juiste, missende waarde, plek invullen.
"Error in data.frame(group1, group2, group3) :
arguments imply differing number of rows: 12, 9"
Dus hoe maak je die boxplot als je niet een dataset hebt om uit te trekken?
Your opinion of me is none of my business.
Goede vraag. Ik zal fout hebben gekeken gok ik.quote:
[..]
Welke boxplot werkt er dan? Het samenvoegen van drie groepen werkt niet, als ik dat probeer krijg ik de melding:
"Error in data.frame(group1, group2, group3) :
arguments imply differing number of rows: 12, 9"
Dus hoe maak je die boxplot als je niet een dataset hebt om uit te trekken?
Onderstaande code werkt in ieder geval (dan werk je met NA)
| 1 2 3 4 5 6 | group1 <- c(27, 22, 29, 21, 19, 33, 16, 20, 24, 27, 28, 19) group2 <- c(12, 12, 15, 9, 20, 18, 17, 14, 14, 2, 17, 19) group3 <- c(18, 4, 22, 15, 18, 19, 22, 12, 12, NA, NA, NA) boxplot(group1, main="Boxplot", ylab="group1") groups123 <- data.frame(group1, group2, group3) boxplot(group1,group2, group3,data=groups123, main="Boxplot", xlab="Group", ylab="Trees") |
EDIT: Je kunt ook zonder NAs boxplotten maken, alleen dan werk je zonder dataframe.
Als je group 1, 2 en 3 hebt gedfinieerd kun je deze code gebruiken:
| 1 | boxplot(group1,group2, group3,data="group1, group2, group3", main="Boxplot", xlab="Group", ylab="Trees") |
Ik heb het net gevonden!quote:
[..]
Goede vraag. Ik zal fout hebben gekeken gok ik.
Onderstaande code werkt in ieder geval (dan werk je met NA)
[ code verwijderd ]
> boxplot(group1,group2,group3)
werkt gewoon.
Your opinion of me is none of my business.
Ah, mijn edit kwam te laat.quote:
[..]
Ik heb het net gevonden!
> boxplot(group1,group2,group3)
werkt gewoon.
Dank voor de hulp in ieder geval!quote:
[..]
Ah, mijn edit kwam te laat.
Your opinion of me is none of my business.

Weten jullie of ik hier een repeated measures anova voor kan gebruiken?
Ik heb twee groepen die allebei dezelfde conditie ondergaan. Er is een beginmeting en een eindmeting. Ik verwacht dat er daarnaast 3 variabelen zijn die een voorspeller zijn van de eindmeting.
Kan ik dit analyseren dmv repeated measures anova? Ik ben begonnen met multilevel analyses, vanwege meerdere metingen en missing data, maar dat werd te complex, dus ik zoek eigenlijk een simplere manier
Ik heb twee groepen die allebei dezelfde conditie ondergaan. Er is een beginmeting en een eindmeting. Ik verwacht dat er daarnaast 3 variabelen zijn die een voorspeller zijn van de eindmeting.
Kan ik dit analyseren dmv repeated measures anova? Ik ben begonnen met multilevel analyses, vanwege meerdere metingen en missing data, maar dat werd te complex, dus ik zoek eigenlijk een simplere manier
iets te snel verstuurd.. ik zoek dus een manier om het effect van de conditie te meten en of de 3 variabelen hierbij een voorspellende waarde hebben. Hoop dat iemand me hiermee kan helpen!
Nog even feedback over mijn vorige vraag... Volgens een docent is dit de meest algemene oplossing die ook werkt voor echte grote datasets:
data <- data.frame('x' = c(1,2,3,4,5,6,7,8,9),'group'=c(1,1,1,2,2,2,3,3,3))
('x' bevat de data zelf, en 'group' de groepslabels, net als bij SPSS) dan krijg je je boxplot direct via:
boxplot(data$x ~ data$group)
data <- data.frame('x' = c(1,2,3,4,5,6,7,8,9),'group'=c(1,1,1,2,2,2,3,3,3))
('x' bevat de data zelf, en 'group' de groepslabels, net als bij SPSS) dan krijg je je boxplot direct via:
boxplot(data$x ~ data$group)
Your opinion of me is none of my business.
Als 'x' een meting is die plaatsvindt in 3 groepen wel inderdaad. Als group 1/2/3 per proefpersoon verschillende zaken meten (bijvoorbeeld: "leeftijd", "lengte" en "schoenmaat") dan moet je de code gebruiken waar je vanmiddag mee kwam.quote:
Nog even feedback over mijn vorige vraag... Volgens een docent is dit de meest algemene oplossing die ook werkt voor echte grote datasets:
data <- data.frame('x' = c(1,2,3,4,5,6,7,8,9),'group'=c(1,1,1,2,2,2,3,3,3))
('x' bevat de data zelf, en 'group' de groepslabels, net als bij SPSS) dan krijg je je boxplot direct via:
boxplot(data$x ~ data$group)
[ Bericht 0% gewijzigd door Operc op 14-09-2014 21:06:04 ]
Ja, klopt. Maar in dit geval waren het bomen in verschillende percelen, dus allemaal dezelfde variabele.quote:
[..]
Als 'x' een meting is die plaatsvindt in 3 groepen wel inderdaad. Als group 1/2/3 per proefpersoon verschillende zaken meten (bijvoorbeeld: "leeftijd", "geslacht" en "schoenmaat") dan moet je de code gebruiken waar je vanmiddag mee kwam.
Your opinion of me is none of my business.
quote:Op zondag 14 september 2014 20:13 schreef wiedeweer het volgende:
Weten jullie of ik hier een repeated measures anova voor kan gebruiken?
Ik heb twee groepen die allebei dezelfde conditie ondergaan. Er is een beginmeting en een eindmeting. Ik verwacht dat er daarnaast 3 variabelen zijn die een voorspeller zijn van de eindmeting.
Kan ik dit analyseren dmv repeated measures anova? Ik ben begonnen met multilevel analyses, vanwege meerdere metingen en missing data, maar dat werd te complex, dus ik zoek eigenlijk een simplere manier
Het is voor mij al weer even geleden, maar ik denk dat je een (M)ANCOVA moet doen (kan in SPSS via GLM).quote:
iets te snel verstuurd.. ik zoek dus een manier om het effect van de conditie te meten en of de 3 variabelen hierbij een voorspellende waarde hebben. Hoop dat iemand me hiermee kan helpen!
Lokquote:
quote:
Ah, dan wel inderdaad,quote:
[..]
Ja, klopt. Maar in dit geval waren het bomen in verschillende percelen, dus allemaal dezelfde variabele.
Hoi!quote:
[..]
[..]
Het is voor mij al weer even geleden, maar ik denk dat je een (M)ANCOVA moet doen (kan in SPSS via GLM).
Lokquote:
[..]
Wat is precies hetgene waar je geintereseerd in bent? Als het puur de 3 IV's op eindmeting zijn (eventueel 4 met voormeting) dan kun je gewoon een regressie doen (je hebt geen between manipulatie toch? als de groepen ongeveer vergelijkbaar zijn kun je ze samen-nemen).quote:
Weten jullie of ik hier een repeated measures anova voor kan gebruiken?
Ik heb twee groepen die allebei dezelfde conditie ondergaan. Er is een beginmeting en een eindmeting. Ik verwacht dat er daarnaast 3 variabelen zijn die een voorspeller zijn van de eindmeting.
Kan ik dit analyseren dmv repeated measures anova? Ik ben begonnen met multilevel analyses, vanwege meerdere metingen en missing data, maar dat werd te complex, dus ik zoek eigenlijk een simplere manier
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Hoi! Sorry, daar ben ik weer!
Ik loop vast met het volgende:
Ik moet een gestandaardiseerde schaalscore berekenen, waarbij het totaal aantal gescoorde punten gedeeld moet worden door het aantal antwoordcategorieën*aantal beantwoorde items. En dat alles *100.
Bij het aantal beantwoorde items loop ik vast..
Hoe ik het heb gedaan:
eerst de "normale" somscore berekend (= aantal gescoorde punten).
Vervolgens:
nieuwe variabele aangemaakt en dan in de numeric expression:
"normale somscore/(3*NValid (variabele 1 + variabele 2 + variabele 3 + variabele 4)) * 100.
Ik krijg hier hele rare getallen uit.. iemand een idee?
Ik loop vast met het volgende:
Ik moet een gestandaardiseerde schaalscore berekenen, waarbij het totaal aantal gescoorde punten gedeeld moet worden door het aantal antwoordcategorieën*aantal beantwoorde items. En dat alles *100.
Bij het aantal beantwoorde items loop ik vast..
Hoe ik het heb gedaan:
eerst de "normale" somscore berekend (= aantal gescoorde punten).
Vervolgens:
nieuwe variabele aangemaakt en dan in de numeric expression:
"normale somscore/(3*NValid (variabele 1 + variabele 2 + variabele 3 + variabele 4)) * 100.
Ik krijg hier hele rare getallen uit.. iemand een idee?
waar komt die 3 vandaan?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
dat zijn het aantal antwoordcategorieën...
Maar ik heb gevonden waar het probleem zit! bij Nvalid heb ik de variabelen opgeteld.. nu heb ik er een komma staan en doet hij het wel!
Maar ik heb gevonden waar het probleem zit! bij Nvalid heb ik de variabelen opgeteld.. nu heb ik er een komma staan en doet hij het wel!
Ik twijfel nog steeds over het meetniveau.. mag ik een antwoordschaal "0=altijd, 1=vaak, 2=soms, 3=nooit" als "scale-variabele" benoemen in spss (dus als zogenaamde quasi-interval of semi-interval variabele)? of is het toch ordinal?
En een "nee=0, ja=1" antwoordschaal waarbij het ene antwoord "beter" is dan het andere.. is dat ordinal? of toch nominal?
En een "nee=0, ja=1" antwoordschaal waarbij het ene antwoord "beter" is dan het andere.. is dat ordinal? of toch nominal?
Bij de eerste zul je voorzichtig moeten zijn met je interpretatie. Vanaf 5 schaalpunten is een ordinale schaal eigenlijk vrijwel gelijk aan een interval schaal (zolang de ankers een beetje logisch zijn), met 4 punten zou ik toch wat voorzichtiger zijn, vooral omdat "soms" waarschijnlijk niet precies tussen nooit en vaak in ligt.quote:
Ik twijfel nog steeds over het meetniveau.. mag ik een antwoordschaal "0=altijd, 1=vaak, 2=soms, 3=nooit" als "scale-variabele" benoemen in spss (dus als zogenaamde quasi-interval of semi-interval variabele)? of is het toch ordinal?
En een "nee=0, ja=1" antwoordschaal waarbij het ene antwoord "beter" is dan het andere.. is dat ordinal? of toch nominal?
Tweede kun je in principe gewoon als ordinaal zien, maar hoe je het noemt zou in dat geval eigenlijk helemaal niks uit moeten maken.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Wat ik niet zo goed begrijp..
Ik heb dus 1 vragenlijst om het construct 'werktevredenheid' te meten, waarin het meetniveau van de schalen verschilt (scale en ordinaal). Daarnaast heb ik een vragenlijst die het construct 'motivatie voor het uit te voeren gedrag' meet (op scale niveau). Hoe kan ik de correlatie tussen deze twee constructen dan meten, aangezien het meetniveau verschilt?
Ik heb dus 1 vragenlijst om het construct 'werktevredenheid' te meten, waarin het meetniveau van de schalen verschilt (scale en ordinaal). Daarnaast heb ik een vragenlijst die het construct 'motivatie voor het uit te voeren gedrag' meet (op scale niveau). Hoe kan ik de correlatie tussen deze twee constructen dan meten, aangezien het meetniveau verschilt?
Zou iemand me kunnen helpen.
Voor mijn thesis onderzoek ik de invloed van economische onzekerheid (baan en inkomensonzekerheid) op o.a. stemkeuze.
Dus mijn afhankelijk variabele is een categorische (partijkeuze), en mijn onafhankelijke een metrische.
Welke analyse techniek gebruik ik hiervoor het best?
Voor mijn thesis onderzoek ik de invloed van economische onzekerheid (baan en inkomensonzekerheid) op o.a. stemkeuze.
Dus mijn afhankelijk variabele is een categorische (partijkeuze), en mijn onafhankelijke een metrische.
Welke analyse techniek gebruik ik hiervoor het best?
Ga je er van uit dat partijren totaal ongerelateerd zijn of zie je de partijen op een schaal van bv links tot rechts?quote:
Zou iemand me kunnen helpen.
Voor mijn thesis onderzoek ik de invloed van economische onzekerheid (baan en inkomensonzekerheid) op o.a. stemkeuze.
Dus mijn afhankelijk variabele is een categorische (partijkeuze), en mijn onafhankelijke een metrische.
Welke analyse techniek gebruik ik hiervoor het best?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
spss 16. Ik zoek een simpele functie maar kan hem niet vinden.
Ik heb 3 testen, die kunnen positief of negatief zijn. Daaruit wil ik een 3de variabele bepalen met spss: bij 1of meer positieve uitkomsten is deze variabele positief, anders negatief.
Ik had verwacht dat er wel een if functie in spss zou zitten. Iemand die me hiermee kan helpen?
Ik heb 3 testen, die kunnen positief of negatief zijn. Daaruit wil ik een 3de variabele bepalen met spss: bij 1of meer positieve uitkomsten is deze variabele positief, anders negatief.
Ik had verwacht dat er wel een if functie in spss zou zitten. Iemand die me hiermee kan helpen?
Sei wachsam,
Fall nicht auf sie rein! Paß auf, daß du deine Freiheit nutzt,
Die Freiheit nutzt sich ab, wenn du sie nicht nutzt!
Fall nicht auf sie rein! Paß auf, daß du deine Freiheit nutzt,
Die Freiheit nutzt sich ab, wenn du sie nicht nutzt!
"Compute variable" moet dat wel kunnen als het goed is.quote:
spss 16. Ik zoek een simpele functie maar kan hem niet vinden.
Ik heb 3 testen, die kunnen positief of negatief zijn. Daaruit wil ik een 3de variabele bepalen met spss: bij 1of meer positieve uitkomsten is deze variabele positief, anders negatief.
Ik had verwacht dat er wel een if functie in spss zou zitten. Iemand die me hiermee kan helpen?
quote:
spss 16. Ik zoek een simpele functie maar kan hem niet vinden.
Ik heb 3 testen, die kunnen positief of negatief zijn. Daaruit wil ik een 3de variabele bepalen met spss: bij 1of meer positieve uitkomsten is deze variabele positief, anders negatief.
Ik had verwacht dat er wel een if functie in spss zou zitten. Iemand die me hiermee kan helpen?
| 1 2 3 4 5 6 | Do if (test1=1 OR test2=1 OR test3=1). Compute var1=1. Else. Compute var1=0. End if. Execute. |
Ah, do if kon ik niet kiezen in de lijst functies. Morgens kijken of het lukt.
Sei wachsam,
Fall nicht auf sie rein! Paß auf, daß du deine Freiheit nutzt,
Die Freiheit nutzt sich ab, wenn du sie nicht nutzt!
Fall nicht auf sie rein! Paß auf, daß du deine Freiheit nutzt,
Die Freiheit nutzt sich ab, wenn du sie nicht nutzt!
Hoi allemaal!
Ik wil graag de correlatie berekenen tussen twee constructen.
- construct 1: werkbeleving (ordinaal, bestaande uit 27 items, verdeeld over 4 schalen)
- construct 2: opvoedingsstijl (ordinaal, bestaande uit 23 items, verdeeld over 3 schalen)
Gezien mijn kleine steekproef (N = 25), en de ordinale aard van de constructen dacht ik een Spearmans Rangordetest uit te voeren.
Echter, nou vroeg ik me af.. ik heb van alle schalen een (gestandaardiseerde) somscore berekend. Deze scores hebben dus een interval-meetniveau (als ik het goed heb). Als ik hier mijn correlatietoets mee uit ga voeren, dan gaat het toch niet meer om ordinale constructen, en moet ik een ander soort toets uitvoeren, toch? Of haal ik nou meerdere dingen door elkaar?
En daarbij vroeg ik me ook nog af: ik heb dus van alle schalen een schaalscore (somscore) berekend. Moet ik daarnaast ook nog een totale constructscore berekenen (de somscores van elk construct bij elkaar opgeteld) om een correlatietoets uit te kunnen voeren?
Mijn dank is groot!
Ik wil graag de correlatie berekenen tussen twee constructen.
- construct 1: werkbeleving (ordinaal, bestaande uit 27 items, verdeeld over 4 schalen)
- construct 2: opvoedingsstijl (ordinaal, bestaande uit 23 items, verdeeld over 3 schalen)
Gezien mijn kleine steekproef (N = 25), en de ordinale aard van de constructen dacht ik een Spearmans Rangordetest uit te voeren.
Echter, nou vroeg ik me af.. ik heb van alle schalen een (gestandaardiseerde) somscore berekend. Deze scores hebben dus een interval-meetniveau (als ik het goed heb). Als ik hier mijn correlatietoets mee uit ga voeren, dan gaat het toch niet meer om ordinale constructen, en moet ik een ander soort toets uitvoeren, toch? Of haal ik nou meerdere dingen door elkaar?
En daarbij vroeg ik me ook nog af: ik heb dus van alle schalen een schaalscore (somscore) berekend. Moet ik daarnaast ook nog een totale constructscore berekenen (de somscores van elk construct bij elkaar opgeteld) om een correlatietoets uit te kunnen voeren?
Mijn dank is groot!
Als werkbeleving categorisch is (bijv ja/nee) en opvoedingsstijl ook, dan zou je met een chi-square analyse de correlaties kunnen analyseren. Als werkbeleving en opvoedingsstijl beide continu zijn (bijv. 1,1 t/m 5) dan kan je een correlatie analyse gebruiken om de correlaties te berekenen.
voor werkbeleving en opvoedingsstijl, zou je denken dat het gaat om een continue antwoordschaal (bijv. van 1 laag tot 5 hoog). Als je dan inderdaad alle items bij elkaar optelt (bijv. 27 items) en deelt door 27, dan krijg je de gemiddelde continue scores. Het gaat inderdaad uiteindelijk om je gemiddelde scores. Zijn die continu of categorisch. Alleen categorisch kan je natuurlijk niet zomaar continu maken. je bent namelijk man = 1, of vrouw = 2. Dan zou de waarde 1,5 natuurlijk niet kunnen.
Je wilt uteindelijk 1 gemiddelde totaalschaal hebben voor werkbeleving en 1 ook 1 schaal voor opvoedingsstijl. Kan je daar iets mee?
voor werkbeleving en opvoedingsstijl, zou je denken dat het gaat om een continue antwoordschaal (bijv. van 1 laag tot 5 hoog). Als je dan inderdaad alle items bij elkaar optelt (bijv. 27 items) en deelt door 27, dan krijg je de gemiddelde continue scores. Het gaat inderdaad uiteindelijk om je gemiddelde scores. Zijn die continu of categorisch. Alleen categorisch kan je natuurlijk niet zomaar continu maken. je bent namelijk man = 1, of vrouw = 2. Dan zou de waarde 1,5 natuurlijk niet kunnen.
Je wilt uteindelijk 1 gemiddelde totaalschaal hebben voor werkbeleving en 1 ook 1 schaal voor opvoedingsstijl. Kan je daar iets mee?
There are no facts only interpretations
Spss & statistiek Goeroe - daviddeboon (at) Hotmail. com
Spss & statistiek Goeroe - daviddeboon (at) Hotmail. com
Wie heeft enig idee waar SW voor kan staan?
Ik moet voor een aantal groepen het gemiddelde, de standaardafwijking, de gestandaardiseerde skewness, gestandaardiseerde kurtosis, SW, outliers en percentage missing aangeven, maar kom er dus even niet meer uit waar SW ook alweer voor staat.
Ik moet voor een aantal groepen het gemiddelde, de standaardafwijking, de gestandaardiseerde skewness, gestandaardiseerde kurtosis, SW, outliers en percentage missing aangeven, maar kom er dus even niet meer uit waar SW ook alweer voor staat.
http://en.wikipedia.org/wiki/Shapiro–Wilk_testquote:
Wie heeft enig idee waar SW voor kan staan?
Ik moet voor een aantal groepen het gemiddelde, de standaardafwijking, de gestandaardiseerde skewness, gestandaardiseerde kurtosis, SW, outliers en percentage missing aangeven, maar kom er dus even niet meer uit waar SW ook alweer voor staat.
Die misschien?
Dank, dat zal hem inderdaad zijn!quote:
[..]
http://en.wikipedia.org/wiki/Shapiro–Wilk_test
Die misschien?
Okee, nieuwe vraag
In mijn dataset heb ik een aantal missings waardoor de eindvariabele, probleemgedrag, bij respondenten waarbij 1 of meer antwoorden ontbreken niet wordt uitgerekend. Ik weet dat er een trucje bestaat waarbij ik aan kan geven dat de eindvariabele ook met 1 (of 2, 3 etc) missing uitgerekend moet worden, waarbij de missing ingevuld wordt als het gemiddelde van alle andere variabelen. Maar hoe doe ik dat ook alweer?
Google wil me tot nu toe niet echt verder helpen..
youtube gelukkig wel:
[ Bericht 35% gewijzigd door fh101 op 09-11-2014 13:47:54 ]
In mijn dataset heb ik een aantal missings waardoor de eindvariabele, probleemgedrag, bij respondenten waarbij 1 of meer antwoorden ontbreken niet wordt uitgerekend. Ik weet dat er een trucje bestaat waarbij ik aan kan geven dat de eindvariabele ook met 1 (of 2, 3 etc) missing uitgerekend moet worden, waarbij de missing ingevuld wordt als het gemiddelde van alle andere variabelen. Maar hoe doe ik dat ook alweer?
Google wil me tot nu toe niet echt verder helpen..
youtube gelukkig wel:

[ Bericht 35% gewijzigd door fh101 op 09-11-2014 13:47:54 ]
Waarschijnlijk heel simpel maar ik zie het echt even niet meer.
De ANOVA geeft F = 150.672. Hoe komen ze van dat getaal op die kans van P>0.0005
Ik zit me rot te zoeken in de tabellen maar ik kan het niet vinden

De ANOVA geeft F = 150.672. Hoe komen ze van dat getaal op die kans van P>0.0005
Ik zit me rot te zoeken in de tabellen maar ik kan het niet vinden
Als je handmatig rekent, kijk je in een F-tabel. Bijvoorbeeld deze:quote:
Waarschijnlijk heel simpel maar ik zie het echt even niet meer.
[ afbeelding ]
De ANOVA geeft F = 150.672. Hoe komen ze van dat getaal op die kans van P>0.0005
Ik zit me rot te zoeken in de tabellen maar ik kan het niet vinden
http://homepages.wmich.edu/~hillenbr/619/AnovaTable.pdf
De kritieke f-waarde is 3.20 in jouw voorbeeld (bij alfa = 5%), dus is de test significant. (Want jouw f-waarde is hoger.)
Ik heb een andere tabel (minder compleet).quote:
[..]
Als je handmatig rekent, kijk je in een F-tabel. Bijvoorbeeld deze:
http://homepages.wmich.edu/~hillenbr/619/AnovaTable.pdf
De kritieke f-waarde is 3.20 in jouw voorbeeld (bij alfa = 5%), dus is de test significant. (Want jouw f-waarde is hoger.)
Maar met jouw tabel snap ik het, thanks!
[ Bericht 3% gewijzigd door -Strawberry- op 22-11-2014 21:31:39 ]
hallo mede statistiek fanaten,
ik heb een vraag; Ik moet onderzoeken hoe Tutoring effect heeft op het eindexamen cijfer.
intelligentie, stress en Gemiddeld_schoolexamen_cijfer zijn ook in de data set ingesloten, tevens zijn sommigen studenten random aangemoedigd om deel te nemen aan tutoring, dus er is ook een encouragement effect.
wij zaten te denken aan een randomisatie met een encouragement design, als beste manier om te testen.
Alleen zou ik graag willen weten hoe je zon encouragement design precies uitvoert.
Het liefst met spss, maar met eviews is ook een optie.
graag hoor ik van jullie,
ik heb een vraag; Ik moet onderzoeken hoe Tutoring effect heeft op het eindexamen cijfer.
intelligentie, stress en Gemiddeld_schoolexamen_cijfer zijn ook in de data set ingesloten, tevens zijn sommigen studenten random aangemoedigd om deel te nemen aan tutoring, dus er is ook een encouragement effect.
wij zaten te denken aan een randomisatie met een encouragement design, als beste manier om te testen.
Alleen zou ik graag willen weten hoe je zon encouragement design precies uitvoert.
Het liefst met spss, maar met eviews is ook een optie.
graag hoor ik van jullie,
Zoek je het antwoord of hulp bij het vinden van het antwoord/begrip?quote:
hallo mede statistiek fanaten,
ik heb een vraag; Ik moet onderzoeken hoe Tutoring effect heeft op het eindexamen cijfer.
intelligentie, stress en Gemiddeld_schoolexamen_cijfer zijn ook in de data set ingesloten, tevens zijn sommigen studenten random aangemoedigd om deel te nemen aan tutoring, dus er is ook een encouragement effect.
wij zaten te denken aan een randomisatie met een encouragement design, als beste manier om te testen.
Alleen zou ik graag willen weten hoe je zon encouragement design precies uitvoert.
Het liefst met spss, maar met eviews is ook een optie.
graag hoor ik van jullie,
Indien het tweede, ik begrijp niet zo goed wat je bedoelt met een "randomisatie met een encouragement design".
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Graag gedaan.quote:
[..]
Ik heb een andere tabel (minder compleet).
Maar met jouw tabel snap ik het, thanks!
Bedoel je met random aangemoedigd dat je weet wie er zijn aangemoedigd en je dus een interventie aan het testen bent, of weet je sowieso niet wie er zijn aangemoedigd en wie niet? (De niet-wetenschappelijke betekenis van 'random' zeg maar.quote:
hallo mede statistiek fanaten,
ik heb een vraag; Ik moet onderzoeken hoe Tutoring effect heeft op het eindexamen cijfer.
intelligentie, stress en Gemiddeld_schoolexamen_cijfer zijn ook in de data set ingesloten, tevens zijn sommigen studenten random aangemoedigd om deel te nemen aan tutoring, dus er is ook een encouragement effect.
wij zaten te denken aan een randomisatie met een encouragement design, als beste manier om te testen.
Alleen zou ik graag willen weten hoe je zon encouragement design precies uitvoert.
Het liefst met spss, maar met eviews is ook een optie.
graag hoor ik van jullie,
Ik heb een aantal vragen met betrekking tot SPSS in verband met een opdracht voor school.
Alle gegevens (codeboek) staan al in SPSS, ik moet echter de volgende vragen beantwoorden.
Hoeveel vragenlijsten zijn er niet volledig ingevuld?
Hoe kun je alle ingevulde vragenlijsten selecteren?
Hoe kun je niet volledig ingevulde vragenlijsten weggooien?
Hopelijk weet een van jullie hoe dit moet.
Gr en alvast bedankt
Alle gegevens (codeboek) staan al in SPSS, ik moet echter de volgende vragen beantwoorden.
Hoeveel vragenlijsten zijn er niet volledig ingevuld?
Hoe kun je alle ingevulde vragenlijsten selecteren?
Hoe kun je niet volledig ingevulde vragenlijsten weggooien?
Hopelijk weet een van jullie hoe dit moet.
Gr en alvast bedankt
*1.666?quote:
Hoe kan ik met SPSS de antwoorden die ik kreeg op een Likert-schaal van 0-6, hercoderen naar 0-10?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Bedankt voor je reactie, ik ben aan het zoeken via welke opdracht in SPSS ik dat kan ingeven (recode,...)?
Waarom zou je het willen? Methodologisch niet heel netjes ook.
compute var_x = var_x * 1,6667.
exe.
compute var_x = var_x * 1,6667.
exe.
Aldus.
Mijn antwoorden worden nu weergegeven in scores op 6, niet echt heel overzichtelijk. Beter zou zijn om scores op 10 weer te geven.
Kort door de bocht: als je scores op 10 had willen hebben, had je er bij de dataverzameling om moeten vragen. Vooral omdat respondenten 0-10 heel anders opvatten dan 0-6. Enzoals hierboven gezegd, het aantal mogelijke waarden verandert niet.quote:
Mijn antwoorden worden nu weergegeven in scores op 6, niet echt heel overzichtelijk. Beter zou zijn om scores op 10 weer te geven.
Ja misschien is mijn vraag niet heel duidelijk, het gaat over herschalen naar een score tussen 0 en 10 of 0 en 100%, dat leest en interpreteert wat makkelijker.
Hallo iedereen,
ik heb een spss-vraagje.
Voor mijn onderzoek heb ik enquêtes uitgestuurd waarbij respondenten op verschillende items moeten antwoorden op een 7punten likert schaal (van helemaal niet akkoord (1) tot helemaal akkoord (7). Na reliability analysis heb ik de items telkens samengevoegd tot verschillende variabelen. Hiervoor heb ik het gemiddelde genomen van de waarden van de bijhorende items.
1) Eerst was mijn schaal dus duidelijk ordinaal. Door het nemen van de gemiddelden van de samengevoegde scores van telkens 5 items kom ik nu kommagetallen uit. Moet ik deze afronden naar gehele getallen, zodat 1 nog steeds 'helemaal niet akkoord' betekent, en en 4 ' neutraal ' ..., of behoud ik de kommagetallen voor mijn onderzoek en worden dit hierdoor intervalschalen?
2) Eigenlijk bevraag ik dimensies. Dat wil zeggen dat in mijn studie rond socialisatie hoge scores bijvoorbeeld betekenen dat respondenten in groep werden opgeleid, en lage scores betekenen dat respondenten individueel werden opgeleid. Nu wil ik telkens nagaan wat bijvoorbeeld de invloed is van de socialisatietactiek 'collectief' op de tevredenheid van de respondent (ook gemeten op een 7pointlikertschaal'. Zo wens ik uiteindelijk na te gaan of collectieve socialiatie (hoge score op die variabel) beter is dan individuele socialisatie (lage score op die variabele) voor de tevredenheid van de respondent.
Iemand enig idee welke stappen ik hiervoor in spss moet uitvoeren en welke analyses ik moet doen?
Sorry voor de lange post.
Alvast heel erg bedankt!
ik heb een spss-vraagje.
Voor mijn onderzoek heb ik enquêtes uitgestuurd waarbij respondenten op verschillende items moeten antwoorden op een 7punten likert schaal (van helemaal niet akkoord (1) tot helemaal akkoord (7). Na reliability analysis heb ik de items telkens samengevoegd tot verschillende variabelen. Hiervoor heb ik het gemiddelde genomen van de waarden van de bijhorende items.
1) Eerst was mijn schaal dus duidelijk ordinaal. Door het nemen van de gemiddelden van de samengevoegde scores van telkens 5 items kom ik nu kommagetallen uit. Moet ik deze afronden naar gehele getallen, zodat 1 nog steeds 'helemaal niet akkoord' betekent, en en 4 ' neutraal ' ..., of behoud ik de kommagetallen voor mijn onderzoek en worden dit hierdoor intervalschalen?
2) Eigenlijk bevraag ik dimensies. Dat wil zeggen dat in mijn studie rond socialisatie hoge scores bijvoorbeeld betekenen dat respondenten in groep werden opgeleid, en lage scores betekenen dat respondenten individueel werden opgeleid. Nu wil ik telkens nagaan wat bijvoorbeeld de invloed is van de socialisatietactiek 'collectief' op de tevredenheid van de respondent (ook gemeten op een 7pointlikertschaal'. Zo wens ik uiteindelijk na te gaan of collectieve socialiatie (hoge score op die variabel) beter is dan individuele socialisatie (lage score op die variabele) voor de tevredenheid van de respondent.
Iemand enig idee welke stappen ik hiervoor in spss moet uitvoeren en welke analyses ik moet doen?
Sorry voor de lange post.
Alvast heel erg bedankt!
Het punt is (zoals Z al aangaf) dat het maar 7 waarden blijven (0-6). Stel je rekent het om naar 0-10, dan is de score "1" bijvoorbeeld niet mogelijk, want 0 op 0-6 blijft 0 bij 0-10 en 1 bij 0-6 wordt 1.667 bij 0-10. Het lijkt daardoor dus alsof je een continue schaal hebt, terwijl het nog steeds maar 7 waardes blijven. Omrekenen naar 0-10 maakt het misschien meer intuïtief, maar de vraag is of dat dan wel weergeeft wat je aan data hebt verzameld.quote:
Ja misschien is mijn vraag niet heel duidelijk, het gaat over herschalen naar een score tussen 0 en 10 of 0 en 100%, dat leest en interpreteert wat makkelijker.
Sommige wetenschappers argumenteren dat je bij Likert-schalen uit kunt gaan van een continue variabele, als de Likert-schaal genoeg opties heeft (bij 3 opties wordt het lastiger.) Dus als je de literatuur induikt en dat kunt onderbouwen, zijn kommagetallen prima te verantwoorden. Als je de score op een schaal wilt berekenen zou ik gewoon de totaalscore pakken, maar ik weet niet of dat in jouw onderzoek toepasbaar is. Als je daarna een groepsgemiddelde berekent ligt het voor de hand om een getal met 2 cijfers achter de komma te rapporteren.quote:
Hallo iedereen,
ik heb een spss-vraagje.
Voor mijn onderzoek heb ik enquêtes uitgestuurd waarbij respondenten op verschillende items moeten antwoorden op een 7punten likert schaal (van helemaal niet akkoord (1) tot helemaal akkoord (7). Na reliability analysis heb ik de items telkens samengevoegd tot verschillende variabelen. Hiervoor heb ik het gemiddelde genomen van de waarden van de bijhorende items.
1) Eerst was mijn schaal dus duidelijk ordinaal. Door het nemen van de gemiddelden van de samengevoegde scores van telkens 5 items kom ik nu kommagetallen uit. Moet ik deze afronden naar gehele getallen, zodat 1 nog steeds 'helemaal niet akkoord' betekent, en en 4 ' neutraal ' ..., of behoud ik de kommagetallen voor mijn onderzoek en worden dit hierdoor intervalschalen?
Als ik het goed begrijp is je onafhankelijke variabele continue (van 1-7) en je afhankelijke variabele ook? In dat geval zou ik naar correlaties gaan kijken. (Algemene tip: Zoek de tabel achterin Andy Field - Discovering Statistics Using SPSS op, daar kun je meestal wel uit afleiden wat voor soort analyse past bij jouw data.)quote:2) Eigenlijk bevraag ik dimensies. Dat wil zeggen dat in mijn studie rond socialisatie hoge scores bijvoorbeeld betekenen dat respondenten in groep werden opgeleid, en lage scores betekenen dat respondenten individueel werden opgeleid. Nu wil ik telkens nagaan wat bijvoorbeeld de invloed is van de socialisatietactiek 'collectief' op de tevredenheid van de respondent (ook gemeten op een 7pointlikertschaal'. Zo wens ik uiteindelijk na te gaan of collectieve socialiatie (hoge score op die variabel) beter is dan individuele socialisatie (lage score op die variabele) voor de tevredenheid van de respondent.
Iemand enig idee welke stappen ik hiervoor in spss moet uitvoeren en welke analyses ik moet doen?
Bedankt voor de snelle reactie!
Ik ga dus inderdaad mijn variabelen als continu beschouwen.
Ik heb de tabel achterin Andy Field - discovering statistics using spss bekeken (bedankt voor de tip), en ik denk dat ik SpearmanCorrelation of Kendall's Tau zal moeten toepassen voor de correlatie na te gaan. Maar wat is hier het exacte verschil tussen? Ik weet niet wat best van toepassing is voor mijn onderzoek.
Ik denk niet dat correlaties voldoende zijn voor een thesis in onze school, dus zal ik vermoedelijk hierbij ook nog logistische regressie moeten toepassen. Is het mogelijk deze beide analyses te doen voor dezelfde gegevens?
bedankt
Ik ga dus inderdaad mijn variabelen als continu beschouwen.
Ik heb de tabel achterin Andy Field - discovering statistics using spss bekeken (bedankt voor de tip), en ik denk dat ik SpearmanCorrelation of Kendall's Tau zal moeten toepassen voor de correlatie na te gaan. Maar wat is hier het exacte verschil tussen? Ik weet niet wat best van toepassing is voor mijn onderzoek.
Ik denk niet dat correlaties voldoende zijn voor een thesis in onze school, dus zal ik vermoedelijk hierbij ook nog logistische regressie moeten toepassen. Is het mogelijk deze beide analyses te doen voor dezelfde gegevens?
bedankt
Ik ga even lekker tegen Operc in en raad je aan een regressie analyse te doen. Dat is eigenlijk niet veel meer of minder dan een iets andere vorm van correlatie, maar een stuk overzichtelijker als je wilt weten wat de invloed van A op B is (waar je vraag op neerkomt). Het geeft dus een causale interpretatie. Echter is het wel belangrijk op te merken dat je geen experimenteel onderzoek uit hebt gevoerd (als ik het goed begrijp) maar puur A en B gemeten hebt waarbij je theorie aangeeft dat je denkt dat A --> B. Het is dus wel belangrijk ergens te vermelden dat ondanks je denkt dat het causaal is en het rapporteert dat het causaal is, je niet uit kunt sluiten dat er ook een effect B --> A is.quote:
Bedankt voor de snelle reactie!
Ik ga dus inderdaad mijn variabelen als continu beschouwen.
Ik heb de tabel achterin Andy Field - discovering statistics using spss bekeken (bedankt voor de tip), en ik denk dat ik SpearmanCorrelation of Kendall's Tau zal moeten toepassen voor de correlatie na te gaan. Maar wat is hier het exacte verschil tussen? Ik weet niet wat best van toepassing is voor mijn onderzoek.
Ik denk niet dat correlaties voldoende zijn voor een thesis in onze school, dus zal ik vermoedelijk hierbij ook nog logistische regressie moeten toepassen. Is het mogelijk deze beide analyses te doen voor dezelfde gegevens?
bedankt
Andy Field zou duidelijk genoeg moeten zijn voor de regressie, maar zo niet dan kan ik (en Operc zeker ook) er bij helpen
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Goed punt.quote:
[..]
Ik ga even lekker tegen Operc in en raad je aan een regressie analyse te doen. Dat is eigenlijk niet veel meer of minder dan een iets andere vorm van correlatie, maar een stuk overzichtelijker als je wilt weten wat de invloed van A op B is (waar je vraag op neerkomt). Het geeft dus een causale interpretatie. Echter is het wel belangrijk op te merken dat je geen experimenteel onderzoek uit hebt gevoerd (als ik het goed begrijp) maar puur A en B gemeten hebt waarbij je theorie aangeeft dat je denkt dat A --> B. Het is dus wel belangrijk ergens te vermelden dat ondanks je denkt dat het causaal is en het rapporteert dat het causaal is, je niet uit kunt sluiten dat er ook een effect B --> A is.
Andy Field zou duidelijk genoeg moeten zijn voor de regressie, maar zo niet dan kan ik (en Operc zeker ook) er bij helpen
Anders even een verduidelijking van mijn onderzoek, want ik weet niet zeker of regressie mogelijk is:
Ik heb enquêtes laten invullen door stagiairs, waarbij volgende variabelen op een 7punten likertschaal werden bevraagd a.d.h.v. een 70 tal items:
- 6 socialisatiedimensies (waarbij lage scores (1) telkens verwijzen naar geïndividualiseerde en hoge scores (7) verwijzen naar geïnstitutionaliseerde tactieken.) Deze dimensies zijn 'Collective-individueel', 'formal-informal', 'sequential-random', 'fixed-variable', 'serial-disjunctive' & 'investiture-divestiture'.
Deze tactieken wijzen dus eigenlijk altijd op schalen. Iemand wordt bijvoorbeeld individueel (geindividualiseerd) of collectief (geïnstitutionaliseerd) gesocialiseerd. Daarom werd besloten deze variabelen als continu te behandelen.
- 3 variabelen die de aanpassing van stagiairs meten (namelijk Role clarity, self-efficacy en social acceptance)
- 3 socialisatie-outcomes (stagetevredenheid, organizational commitment & Intention to sollicitate)
Ondanks de Likert schaal worden alle variabelen dus als continu behandeld. Geen één van deze variabelen is echter normaal verdeeld.
Nu wens ik eigenlijk te analyseren wat het effect is van elke aparte socialisatiedimensie op de 3 socalisatie-outcomes. Ik wil m.a.w. telkens weten of bijvoorbeeld de socialisatietactiek 'collectief' (hoge scores op de dimensie collectief-individueel: 7) of 'individueel' (lage scores op de dimensie collectief-individueel: 1) de stagetevredenheid van stagiairs verhoogt, of een derde mogelijkheid, namelijk dat de socialisatietactieken op die dimensie geen invloed hebben op de stagetevredenheid.
Ten tweede wens ik te onderzoeken of de 'aanpassing van stagiairs', voorgesteld door Role clarity, self-efficacy en social acceptance, optreden als mediator tussen de socialisatietactieken en de socialisatie-outcomes.
Ik zou deze analyses grotendeels vanavond en morgen moeten doen, mijn promotor is in verlof en mijn handboek legt niet goed uit welke correlatie en regressie analyse ik moet gebruiken als er geen normale verdeling is. Weten jullie welke analyses ik precies moet uitvoeren (welk soort toets voor correlatie of regressie bv.?
Dat zou me echt uit de nood helpen! Ik ben jullie eeuwig dankbaar!
Ik heb enquêtes laten invullen door stagiairs, waarbij volgende variabelen op een 7punten likertschaal werden bevraagd a.d.h.v. een 70 tal items:
- 6 socialisatiedimensies (waarbij lage scores (1) telkens verwijzen naar geïndividualiseerde en hoge scores (7) verwijzen naar geïnstitutionaliseerde tactieken.) Deze dimensies zijn 'Collective-individueel', 'formal-informal', 'sequential-random', 'fixed-variable', 'serial-disjunctive' & 'investiture-divestiture'.
Deze tactieken wijzen dus eigenlijk altijd op schalen. Iemand wordt bijvoorbeeld individueel (geindividualiseerd) of collectief (geïnstitutionaliseerd) gesocialiseerd. Daarom werd besloten deze variabelen als continu te behandelen.
- 3 variabelen die de aanpassing van stagiairs meten (namelijk Role clarity, self-efficacy en social acceptance)
- 3 socialisatie-outcomes (stagetevredenheid, organizational commitment & Intention to sollicitate)
Ondanks de Likert schaal worden alle variabelen dus als continu behandeld. Geen één van deze variabelen is echter normaal verdeeld.
Nu wens ik eigenlijk te analyseren wat het effect is van elke aparte socialisatiedimensie op de 3 socalisatie-outcomes. Ik wil m.a.w. telkens weten of bijvoorbeeld de socialisatietactiek 'collectief' (hoge scores op de dimensie collectief-individueel: 7) of 'individueel' (lage scores op de dimensie collectief-individueel: 1) de stagetevredenheid van stagiairs verhoogt, of een derde mogelijkheid, namelijk dat de socialisatietactieken op die dimensie geen invloed hebben op de stagetevredenheid.
Ten tweede wens ik te onderzoeken of de 'aanpassing van stagiairs', voorgesteld door Role clarity, self-efficacy en social acceptance, optreden als mediator tussen de socialisatietactieken en de socialisatie-outcomes.
Ik zou deze analyses grotendeels vanavond en morgen moeten doen, mijn promotor is in verlof en mijn handboek legt niet goed uit welke correlatie en regressie analyse ik moet gebruiken als er geen normale verdeling is. Weten jullie welke analyses ik precies moet uitvoeren (welk soort toets voor correlatie of regressie bv.?
Dat zou me echt uit de nood helpen! Ik ben jullie eeuwig dankbaar!
Ik hoop dat je altijd statistiek genegeerd hebt o.i.d., want dit is niet echt een simpele opdracht om zelf even uit te zoeken zonder enige achtergrond. Vreemd dat je begeleider hier niet meer over uit heeft gelegd (of jij niet goed genoeg opgelet hebt? )
Ten eerste de correlaties tussen de IV's, ten tweede de correlaties tussen de DV's. De beste methode hangt namelijk af van of ze wel of niet correleren.
Ok, dus je hebt 6 IV's waarvan je wilt weten of ze invloed hebben op je DV'squote:
Anders even een verduidelijking van mijn onderzoek, want ik weet niet zeker of regressie mogelijk is:
Ik heb enquêtes laten invullen door stagiairs, waarbij volgende variabelen op een 7punten likertschaal werden bevraagd a.d.h.v. een 70 tal items:
- 6 socialisatiedimensies (waarbij lage scores (1) telkens verwijzen naar geïndividualiseerde en hoge scores (7) verwijzen naar geïnstitutionaliseerde tactieken.) Deze dimensies zijn 'Collective-individueel', 'formal-informal', 'sequential-random', 'fixed-variable', 'serial-disjunctive' & 'investiture-divestiture'.
Deze tactieken wijzen dus eigenlijk altijd op schalen. Iemand wordt bijvoorbeeld individueel (geindividualiseerd) of collectief (geïnstitutionaliseerd) gesocialiseerd. Daarom werd besloten deze variabelen als continu te behandelen.
Je zegt hiervan dat ze mediatoren zijn, maar dat kan niet echt met een continue IV, kun je in normale Nederlandse woorden zeggen wat precies je hypothese is voor deze constructen? (dus A leidt tot B of A leidt alleen tot B voor vrouwen, dat soort taal).quote:- 3 variabelen die de aanpassing van stagiairs meten (namelijk Role clarity, self-efficacy en social acceptance)
Dit zijn 3 losse IV'squote:- 3 socialisatie-outcomes (stagetevredenheid, organizational commitment & Intention to sollicitate)
Voordat je dit gaat doen, wil ik je vragen 2 correlatie-grafieken te posten (zal na posten uitleggen waarom).quote:Nu wens ik eigenlijk te analyseren wat het effect is van elke aparte socialisatiedimensie op de 3 socalisatie-outcomes. Ik wil m.a.w. telkens weten of bijvoorbeeld de socialisatietactiek 'collectief' (hoge scores op de dimensie collectief-individueel: 7) of 'individueel' (lage scores op de dimensie collectief-individueel: 1) de stagetevredenheid van stagiairs verhoogt, of een derde mogelijkheid, namelijk dat de socialisatietactieken op die dimensie geen invloed hebben op de stagetevredenheid.
Ten eerste de correlaties tussen de IV's, ten tweede de correlaties tussen de DV's. De beste methode hangt namelijk af van of ze wel of niet correleren.
Zie hierbovenquote:Ten tweede wens ik te onderzoeken of de 'aanpassing van stagiairs', voorgesteld door Role clarity, self-efficacy en social acceptance, optreden als mediator tussen de socialisatietactieken en de socialisatie-outcomes.
Wow, hoe hard is die deadline?quote:Ik zou deze analyses grotendeels vanavond en morgen moeten doen,
Zolang je N hoog genoeg is, is dat niet erg.quote:mijn promotor is in verlof en mijn handboek legt niet goed uit welke correlatie en regressie analyse ik moet gebruiken als er geen normale verdeling is.
Ja maar dat hangt dus van een aantal zaken af.quote:Weten jullie welke analyses ik precies moet uitvoeren (welk soort toets voor correlatie of regressie bv.?
Dat zou me echt uit de nood helpen! Ik ben jullie eeuwig dankbaar!
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Het lukt me niet om hier afbeeldingen te posten...
Jah, ik heb nog maar een 3tal weken geleden een andere begeleider gekregen en door dat ik al vast werk was afspreken niet evident
Alleszins, als je denkt dat dit niet haalbaar is, enig idee van hoe ik de analyse kan vereenvoudigen? De titel is " de impact van geïnstitutionaliseerde socialisatietactieken op de aanpassing van stagiairs: een hulpmiddel voor het bekomen van de optimale stage".
Wel is het belangrijk dat ik de socialisatietactieken per dimensie onderzoek, aangezien het belang hiervan meermaals benadrukt staat in mijn literatuurstudie..
Bij de IV's is er enkel geen significante correlatie tussen Collective en Sequential, (De dimensie 'formal' gebruik ik niet, aangezien de interne consistentie van de items te laag was.)
Bij 'de aanpassing van stagiairs' is er enkel een significante correlatie tussen Role clarity en social acceptance.
Bij de DV's zijn alle correlaties significant...
Jah, ik heb nog maar een 3tal weken geleden een andere begeleider gekregen en door dat ik al vast werk was afspreken niet evident
Alleszins, als je denkt dat dit niet haalbaar is, enig idee van hoe ik de analyse kan vereenvoudigen? De titel is " de impact van geïnstitutionaliseerde socialisatietactieken op de aanpassing van stagiairs: een hulpmiddel voor het bekomen van de optimale stage".
Wel is het belangrijk dat ik de socialisatietactieken per dimensie onderzoek, aangezien het belang hiervan meermaals benadrukt staat in mijn literatuurstudie..
Bij de IV's is er enkel geen significante correlatie tussen Collective en Sequential, (De dimensie 'formal' gebruik ik niet, aangezien de interne consistentie van de items te laag was.)
Bij 'de aanpassing van stagiairs' is er enkel een significante correlatie tussen Role clarity en social acceptance.
Bij de DV's zijn alle correlaties significant...
Wat is je N?quote:
Het lukt me niet om hier afbeeldingen te posten...
Jah, ik heb nog maar een 3tal weken geleden een andere begeleider gekregen en door dat ik al vast werk was afspreken niet evident
Alleszins, als je denkt dat dit niet haalbaar is, enig idee van hoe ik de analyse kan vereenvoudigen? De titel is " de impact van geïnstitutionaliseerde socialisatietactieken op de aanpassing van stagiairs: een hulpmiddel voor het bekomen van de optimale stage".
Wel is het belangrijk dat ik de socialisatietactieken per dimensie onderzoek, aangezien het belang hiervan meermaals benadrukt staat in mijn literatuurstudie..
Bij de IV's is er enkel geen significante correlatie tussen Collective en Sequential, (De dimensie 'formal' gebruik ik niet, aangezien de interne consistentie van de items te laag was.)
Bij 'de aanpassing van stagiairs' is er enkel een significante correlatie tussen Role clarity en social acceptance.
Bij de DV's zijn alle correlaties significant...
De correlatie-vraag was om uit te zoeken in hoeverre je vragen echt andere dingen meten. Als je bv het effect van geslacht op lengte en gewicht los meet, zul je zien dat geslacht op allebei een effect heeft, maar het effect van geslacht op gewicht kan gewoon puur een indirect van lengte op gewicht zijn (lange mensen wegen meer), daarom is het belangrijk de correlaties te bekijken om wat meer inzicht in je constructen te krijgen.
Als je Dv's samenhangen kun je er voor kiezen ze samen te voegen als dat theoretisch ergens op slaat. Wel of niet samenvoegen maar hier niet zo heel veel uit.
Voor je IV's zijn correlaties problematischer. Dit maakt het heel erg ingewikkeld om te begrijpen wat er nu precies echt aan de hand is. Even een voorbeeldje waarin het wel logisch wat er aan de hand is om te omschrijven wat ik bedoel:
Je hebt geslacht en lengte gemeten en onderzoekt ed effecten hiervan op gewicht.
Als je naar die twee dingen los kijkt zul je vinden dat:
1. geslacht groot effect heeft op gewicht
2. lengte groot effect heeft op gewicht
maar ook dat:
3. geslacht en lengte sterk correleren
Wordt het hogere gewicht dat veroorzaakt door geslacht of door lengte? Die twee kun je niet uit elkaar halen omdat ze zo erg correleren.
Als al je IVs "sterk" correleren, wordt interpretatie heel erg moeilijk.
Probeer anders even uit te zoeken met bv. imgur hoe je een plaatje post, want ik ben bang dat dat wel echt nodig zal zijn.
Als je dat hebt gevonden, post dan de volgende output:
1. corrrelatiematrix IV's
2. mulitple regressie (onder analyze), met 1 van je DV's als dependent, en per blokje 1 van je IV's toevoegend.
Daarmee zouden ik/Operc je een stuk verder moeten kunnen helpen.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Kan je onderstaande links zien?
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#0
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#1
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#2
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#3
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#4
Ik heb dus inderdaad besloten om mijn model tot volgende te reduceren:
- 5 Socialisatietactieken ( collective, sequential, fixed, serial, investiture)
- 2 var voor de aanpassing van stagiairs (Role clarity & social acceptance)
- 1 variabele voor het succes van een stage (gemiddelde van stagetevredenheid, org commitment en intention to sollicitate)
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#0
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#1
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#2
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#3
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#4
Ik heb dus inderdaad besloten om mijn model tot volgende te reduceren:
- 5 Socialisatietactieken ( collective, sequential, fixed, serial, investiture)
- 2 var voor de aanpassing van stagiairs (Role clarity & social acceptance)
- 1 variabele voor het succes van een stage (gemiddelde van stagetevredenheid, org commitment en intention to sollicitate)
Shit sorry, had niet je nieuwe post gezien (als je iemand quote krijgen ze een pop-up weet je zeker dat ze door hebben dat je hebt gereageerd).quote:
Kan je onderstaande links zien?
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#0
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#1
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#2
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#3
http://imgur.com/Rq50Jgh,vcApcTu,9HBITOO,NZABY3o,9BHUOyI#4
Ik heb dus inderdaad besloten om mijn model tot volgende te reduceren:
- 5 Socialisatietactieken ( collective, sequential, fixed, serial, investiture)
- 2 var voor de aanpassing van stagiairs (Role clarity & social acceptance)
- 1 variabele voor het succes van een stage (gemiddelde van stagetevredenheid, org commitment en intention to sollicitate)
In je regressie kun je inderdaad zien dat je een probleem hebt dat lijkt op mijn voorbeeld (met lengte, geslacht en gewicht).
In je tweede model zie je dat zowel collective als sequential significante voorspellers zijn, maar dat in je gehele model (model 5) sequential niet meer significant is, Serial, en daarna Investiture nemen als het ware het voorspellende vermogen van sequential over. Dat komt omdat die alledrie enorm sterk samenhangen.
Wat ik zou doen is OF model 5 rapporteren (staat in andy field als het goed is, of pallant nog beter als ze die in je bieb hebben), OF alleen een model met collective en investiture rapprteren.
Soewieso welke van e twee je ook kiest zul je aan moeten geven dat sequential, serial en investitute zo hoog met elkaar correleren dat je statistisch gezien niet kunt bepalen welk deel van de variantie uniek verklaard word door deze concepten individueel.
Was dat een beetje te volgen?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik kom zelf niet uit dit vraagstuk, misschien dat hier iemand het weet:
Ik heb een databestand (zie voorbeeld) waarin voor een gemeente per jaar de kenmerken van bedrijven staan die er gevestigd zijn, zoals het aantal arbeidsplaatsen. Ieder bedrijf heeft voor ieder jaar een regel, maar niet alle bedrijven hebben evenveel regels (bijv. door later starten/ failliet gaan/ verhuizen).
De bedrijven zijn aan de hand van het aantal arbeidsplaatsen ingedeeld in categorieën (in het voorbeeld zijn dit er 2). Maar nu wil ik een variabele construeren die aangeeft of een bedrijf in vergelijking met een jaar eerder (als deze er is) gestegen of gedaald is binnen deze categorieën.
Maar hoe? Ik dacht zelf in de richting van een do repeat/ loop, maar daar loop ik op vast.
voorbeeld in spoiler:
Ik heb een databestand (zie voorbeeld) waarin voor een gemeente per jaar de kenmerken van bedrijven staan die er gevestigd zijn, zoals het aantal arbeidsplaatsen. Ieder bedrijf heeft voor ieder jaar een regel, maar niet alle bedrijven hebben evenveel regels (bijv. door later starten/ failliet gaan/ verhuizen).
De bedrijven zijn aan de hand van het aantal arbeidsplaatsen ingedeeld in categorieën (in het voorbeeld zijn dit er 2). Maar nu wil ik een variabele construeren die aangeeft of een bedrijf in vergelijking met een jaar eerder (als deze er is) gestegen of gedaald is binnen deze categorieën.
Maar hoe? Ik dacht zelf in de richting van een do repeat/ loop, maar daar loop ik op vast.
voorbeeld in spoiler:
SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.Dank!
Kun je je voorbeeld aanvullen met welke output je zou willen hebben?
Bedrijf 1 is in 2013 tov 2012 naar een categorie lager gegaan (en dus gedaald in aantal werknemers), wat moet dan de output worden?
Is de dataset zoals in het voorbeeld beperkt tot maximaal een range van iets van 10 jaar? Vergelijken tussen observaties (rijen) is vaak gevaarlijk en lastig, zeker in (ik denk?) SPSS. Daarom zou ik eerst de dataset van lang naar breed formaat overzetten (alle jaren voor elk bedrijf in 1 observatie.
Dat doe je zo:
Daarna is het relatief eenvoudig.
[ Bericht 17% gewijzigd door dotKoen op 19-02-2015 19:33:56 ]
Bedrijf 1 is in 2013 tov 2012 naar een categorie lager gegaan (en dus gedaald in aantal werknemers), wat moet dan de output worden?
Is de dataset zoals in het voorbeeld beperkt tot maximaal een range van iets van 10 jaar? Vergelijken tussen observaties (rijen) is vaak gevaarlijk en lastig, zeker in (ik denk?) SPSS. Daarom zou ik eerst de dataset van lang naar breed formaat overzetten (alle jaren voor elk bedrijf in 1 observatie.
Dat doe je zo:
| 1 2 3 | CASESTOVASRS /id=nr /index = jaar. |
Daarna is het relatief eenvoudig.
[ Bericht 17% gewijzigd door dotKoen op 19-02-2015 19:33:56 ]
Volgens mij kan dat niet in SPSS als je data er zo uit ziet: hetzelfde bedrijf op meerdere rijen. Als je de data per bedrijf op 1 regel zet, elk jaar wordt dan een variabele, is het een makkie. Je kan je data herstructureren met behulp van "restructure", een fantastische SPSS functie. Te vinden in een menu (data geloof ik).
Aldus.
Hoi!
Stomme vraag misschien, maar is het mogelijk om van de variabelen die ik via "compute variable" heb aangemaakt de numerieke code terug te vinden en/of te veranderen ? Dus stel ik heb een variabele aangemaakt: "somscore" = variabele1 + variabele2 + variabele3, en ik wil er bijvoorbeeld nog een variabele extra aan toevoegen of weghalen, kan dat? Of moet ik dan weer een hele nieuwe variabele aanmaken?
Hoop dat iemand nog reageert, aangezien het forum al lange tijd niet gebruikt is
Stomme vraag misschien, maar is het mogelijk om van de variabelen die ik via "compute variable" heb aangemaakt de numerieke code terug te vinden en/of te veranderen ? Dus stel ik heb een variabele aangemaakt: "somscore" = variabele1 + variabele2 + variabele3, en ik wil er bijvoorbeeld nog een variabele extra aan toevoegen of weghalen, kan dat? Of moet ik dan weer een hele nieuwe variabele aanmaken?
Hoop dat iemand nog reageert, aangezien het forum al lange tijd niet gebruikt is
Dat ligt er aan of je meteen de recode gerunned hebt of naar syntax gepaste. Als je het naar syntax gepaste hebt is het heel gemakkelijk aan te passen, als je het meteen gerunned hebt ben ik bang dat het niet zo gemakkelijk gaat (maar ik kan het verkeerd hebben).quote:
Hoi!
Stomme vraag misschien, maar is het mogelijk om van de variabelen die ik via "compute variable" heb aangemaakt de numerieke code terug te vinden en/of te veranderen ? Dus stel ik heb een variabele aangemaakt: "somscore" = variabele1 + variabele2 + variabele3, en ik wil er bijvoorbeeld nog een variabele extra aan toevoegen of weghalen, kan dat? Of moet ik dan weer een hele nieuwe variabele aanmaken?
Hoop dat iemand nog reageert, aangezien het forum al lange tijd niet gebruikt is
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Je zou natuurlijk
kunnen doen. Wederom een argument om alles in syntax te doen.
| 1 | Compute somscore2 = somscore + var4. |
Bedankt voor jullie reacties!
Inderdaad het beste om de syntax te gebruiken.. had ik in dit geval niet gedaan. Vanaf nu wel weer
Maar dan moet ik het zelf in de code aanpassen, toch? Ben namelijk niet zo goed in syntax-taal..
Zou fijner zijn als het werkte zoals in excel.. als je een kolomwaarde aanpast dat de somscore/gem./etc. dan ook aanpast..
Inderdaad het beste om de syntax te gebruiken.. had ik in dit geval niet gedaan. Vanaf nu wel weer
Maar dan moet ik het zelf in de code aanpassen, toch? Ben namelijk niet zo goed in syntax-taal..
Zou fijner zijn als het werkte zoals in excel.. als je een kolomwaarde aanpast dat de somscore/gem./etc. dan ook aanpast..
Als je er niet zo goed in bent, kun je het ook via de menuknoppen doen en op Paste klikken in plaats van OK. Dan plakt hij de code in een syntax bestand en kun je zelf zien hoe de syntax eruit ziet.quote:
Maar dan moet ik het zelf in de code aanpassen, toch? Ben namelijk niet zo goed in syntax-taal..
Ja dat wel, maar ik bedoel als ik berekeningen aan wil passen moet ik dat in de syntax doen (in syntax-taal)..quote:Als je er niet zo goed in bent, kun je het ook via de menuknoppen doen en op Paste klikken in plaats van OK. Dan plakt hij de code in een syntax bestand en kun je zelf zien hoe de syntax eruit ziet.

Even nog iets anders.. ben even helemaal in de war!
Ik heb verschillende schalen.. van sommige schalen heb ik de somscores, van anderen heb ik gemiddelden. Nou heb ik de descriptives opgevraagd van de schalen om te kijken of ze normaal verdeeld zijn etc.. maar een "mean" van een somscore-schaal betekent iets anders dan een "mean" van een gemiddelde-schaal.
Moet ik de descriptives van alle schalen op hetzelfde 'niveau' opvragen? (dus of allemaal somscores, of allemaal gemiddelden?). Of hoeft dat niet? En hoe interpreteer ik deze verschillende descriptives? De 'mean' van een gemiddelde-schaal is wat men gemiddeld scoort en de 'mean' van een somscore-schaal is wat men totaal gemiddeld scoort, Of zo?
Ik heb verschillende schalen.. van sommige schalen heb ik de somscores, van anderen heb ik gemiddelden. Nou heb ik de descriptives opgevraagd van de schalen om te kijken of ze normaal verdeeld zijn etc.. maar een "mean" van een somscore-schaal betekent iets anders dan een "mean" van een gemiddelde-schaal.
Moet ik de descriptives van alle schalen op hetzelfde 'niveau' opvragen? (dus of allemaal somscores, of allemaal gemiddelden?). Of hoeft dat niet? En hoe interpreteer ik deze verschillende descriptives? De 'mean' van een gemiddelde-schaal is wat men gemiddeld scoort en de 'mean' van een somscore-schaal is wat men totaal gemiddeld scoort, Of zo?
Ik zou pakken wat voor de lezer het logischte is (meestal is dat gemiddelde, maar stel dat het een "schaal zou zijn van 10 proefwerkvragen die allemaal 0.0-1.0 punt opleveren, dan zou een somscore logischer zijn)quote:Op zaterdag 25 april 2015 22:55 schreef Natoo het volgende:
Even nog iets anders.. ben even helemaal in de war!
Ik heb verschillende schalen.. van sommige schalen heb ik de somscores, van anderen heb ik gemiddelden. Nou heb ik de descriptives opgevraagd van de schalen om te kijken of ze normaal verdeeld zijn etc.. maar een "mean" van een somscore-schaal betekent iets anders dan een "mean" van een gemiddelde-schaal.
inderdaadquote:Moet ik de descriptives van alle schalen op hetzelfde 'niveau' opvragen? (dus of allemaal somscores, of allemaal gemiddelden?). Of hoeft dat niet? En hoe interpreteer ik deze verschillende descriptives? De 'mean' van een gemiddelde-schaal is wat men gemiddeld scoort en de 'mean' van een somscore-schaal is wat men totaal gemiddeld scoort, Of zo?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Gezien de aard van mijn onderzoek was het de bedoeling om een multipele regressie uit te gaan voeren. Ik ben allereerst begonnen met uit uitrekenen van alle descriptives, waaruit bleek dat sommige variabelen niet normaal verdeeld bleken te zijn.. wat is nu mijn vervolgstap?
Ik neem aan dat ik eerst moet beginnen met het berekenen van de correlaties tussen de variabelen (middels een Spearman Correlatie gezien de niet-normale verdelingen, maar ook een kleine steekproefgrootte (N=25))?. En kan ik het beste de Mediaan (+MAD als spreidingsmaat) weergeven ipv de gemiddelden?
En wat doe ik daarna? Normaal volg ik gewoon een stappenplan om te kijken welke toets ik uit moet voeren, maar ik loop nu allemaal tegen dingen aan waar ik nog niet eerder mee te maken heb gehad (kleine steekproef, niet-normale verdelingen, etc.)
Iemand die mij weer op weg kan helpen, wellicht?
Ik neem aan dat ik eerst moet beginnen met het berekenen van de correlaties tussen de variabelen (middels een Spearman Correlatie gezien de niet-normale verdelingen, maar ook een kleine steekproefgrootte (N=25))?. En kan ik het beste de Mediaan (+MAD als spreidingsmaat) weergeven ipv de gemiddelden?
En wat doe ik daarna? Normaal volg ik gewoon een stappenplan om te kijken welke toets ik uit moet voeren, maar ik loop nu allemaal tegen dingen aan waar ik nog niet eerder mee te maken heb gehad (kleine steekproef, niet-normale verdelingen, etc.)
Iemand die mij weer op weg kan helpen, wellicht?
Zag dat er ook iets als ipython is icm notebook dat je interactief kunt programmeren en ook delen. Je kunt ook R code e.d. implementeren. Ben er zelf niet bekend mee maar ga mij er eens in verdiepen. Gebruik R voor statistiek en Python voor de lol om programma's te schrijven.quote:
Python heeft toch ook een mooie statistiekmodule (Panda's)?
SPSS is naar mijn idee wat verouderd, beperkt en is een black box dus heb gekozen voor R. Waarom kiezen de meesten nog voor SPSS of is dit geen vrijwillige keuze? Ik heb namelijk het idee dat er een shift gaande is naar R en dergelijke. Als je toch nog met geen van beiden bekend bent lijkt mij de keuze voor R logischer. Het is ook gratis.
"Happiness is not getting more, but wanting less"
Normaal verdeelde data is in principe geen harde eis omdat er nog geen enkele verdeling is gevonden waarbij bij n>30 de gemiddelden niet normaal verdeeld waren (dat tweede is wel een "harde" eis).quote:
Gezien de aard van mijn onderzoek was het de bedoeling om een multipele regressie uit te gaan voeren. Ik ben allereerst begonnen met uit uitrekenen van alle descriptives, waaruit bleek dat sommige variabelen niet normaal verdeeld bleken te zijn.. wat is nu mijn vervolgstap?
Ik neem aan dat ik eerst moet beginnen met het berekenen van de correlaties tussen de variabelen (middels een Spearman Correlatie gezien de niet-normale verdelingen, maar ook een kleine steekproefgrootte (N=25))?. En kan ik het beste de Mediaan (+MAD als spreidingsmaat) weergeven ipv de gemiddelden?
En wat doe ik daarna? Normaal volg ik gewoon een stappenplan om te kijken welke toets ik uit moet voeren, maar ik loop nu allemaal tegen dingen aan waar ik nog niet eerder mee te maken heb gehad (kleine steekproef, niet-normale verdelingen, etc.)
Iemand die mij weer op weg kan helpen, wellicht?
Kleine steekproef is wel vrij vervelend om veel redenen
Als je data niet extreem raar verdeeld zijn, zou ik denk ik gewoon verder gaan met je geplande methodes en ergens vermelden dat je data niet normaal verdeeld waren en dat je resultaten dus iets minder betrouwbaar zijn oid.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik doe nieuwe dingen in R, en gebruik SPSS vooral nog omdat het simpel is en ik er aan gewend ben. Als ik van scratch zou moeten beginnen zou ik alles in R doen.quote:
[..]
Zag dat er ook iets als ipython is icm notebook dat je interactief kunt programmeren en ook delen. Je kunt ook R code e.d. implementeren. Ben er zelf niet bekend mee maar ga mij er eens in verdiepen. Gebruik R voor statistiek en Python voor de lol om programma's te schrijven.
SPSS is naar mijn idee wat verouderd, beperkt en is een black box dus heb gekozen voor R. Waarom kiezen de meesten nog voor SPSS of is dit geen vrijwillige keuze? Ik heb namelijk het idee dat er een shift gaande is naar R en dergelijke. Als je toch nog met geen van beiden bekend bent lijkt mij de keuze voor R logischer. Het is ook gratis.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ok, thanks. Ik heb verder nog niet op de verdere aannames voor een multipele regressie getoetst.. maar het zou me niks verbazen als ik er niet aan voldoe (ook gezien mijn kleine steekproefgrootte). Zijn er dan nog andere opties/meer robuustere methodes om regressie te toetsen?quote:Als je data niet extreem raar verdeeld zijn, zou ik denk ik gewoon verder gaan met je geplande methodes en ergens vermelden dat je data niet normaal verdeeld waren en dat je resultaten dus iets minder betrouwbaar zijn oid.
[ Bericht 13% gewijzigd door Natoo op 29-04-2015 23:49:23 ]
Hopelijk kunnen jullie mij helpen.
Voor mijn scriptie ben ik bezig met een andere techniek voor een onderzoek op de CT-scan.
Nu ben ik geen held met SPSS en heb het grootste deel wel af, maar kom er nu totaal niet meer uit.
Wat ik wil is eigenlijk dit (uit een ander, al gepubliceerd onderzoek):
Maar dan met mijn data zou het dit worden (qua opzet):
En de data die ik in SPSS heb:
Iemand enig idee hoe ik dit voor elkaar krijg?
Alvast enorm bedankt!
Voor mijn scriptie ben ik bezig met een andere techniek voor een onderzoek op de CT-scan.
Nu ben ik geen held met SPSS en heb het grootste deel wel af, maar kom er nu totaal niet meer uit.
Wat ik wil is eigenlijk dit (uit een ander, al gepubliceerd onderzoek):

Maar dan met mijn data zou het dit worden (qua opzet):

En de data die ik in SPSS heb:

Iemand enig idee hoe ik dit voor elkaar krijg?
Alvast enorm bedankt!
You can only have the sunshine after the rain..
Als je een ANOVA doet, kun je bij "Options" op "Descriptives" klikken. Dan krijg je bij je ANOVA tabel ook een tabel met de Means, SDs etc per groep en voor het totaal. Dit kun je dan doen voor elke afhankelijke variabele. (Je bent alleen geïnteresseerd in de verschillen tussen Bolus en Test en niet AFC rechts/links etc toch?)quote:
Hopelijk kunnen jullie mij helpen.
Voor mijn scriptie ben ik bezig met een andere techniek voor een onderzoek op de CT-scan.
Nu ben ik geen held met SPSS en heb het grootste deel wel af, maar kom er nu totaal niet meer uit.
Wat ik wil is eigenlijk dit (uit een ander, al gepubliceerd onderzoek):
[ afbeelding ]
Maar dan met mijn data zou het dit worden (qua opzet):
[ afbeelding ]
En de data die ik in SPSS heb:
[ afbeelding ]
Iemand enig idee hoe ik dit voor elkaar krijg?
Alvast enorm bedankt!
Ik ben even compleet gefrustreerd. Ik heb data in spss die ik niet kan analyseren omdat hij vindt dat mijn gemiddelde score een string is. Ik heb er inmiddels een aardappelhoofd van gekregen en ook in de syntax van SPSS kom ik niet verder.
compute Score = number(SC0_1).
execute.
recode SC0_1 (convert) into score2.
execute.
COMPUTE score = NUMBER(SC0_1, F8.12).
execute.
werken allemaal niet. In de 'view variable' de variabele van string naar numeric veranderen heeft tot gevolg dat alle waardes verdwijnen. Uiteindelijk heb ik de huidige laatste drie variabelen verkregen door automatic recode te gebruiken, maar de hoeveelheid informatie die daarbij verloren gaat is onacceptabel. Hij houdt dan twee decimalen over van de veertig.
Helaas moet dit per se in spss. Iemand nog een tip?
compute Score = number(SC0_1).
execute.
recode SC0_1 (convert) into score2.
execute.
COMPUTE score = NUMBER(SC0_1, F8.12).
execute.
werken allemaal niet. In de 'view variable' de variabele van string naar numeric veranderen heeft tot gevolg dat alle waardes verdwijnen. Uiteindelijk heb ik de huidige laatste drie variabelen verkregen door automatic recode te gebruiken, maar de hoeveelheid informatie die daarbij verloren gaat is onacceptabel. Hij houdt dan twee decimalen over van de veertig.
Helaas moet dit per se in spss. Iemand nog een tip?
Your opinion of me is none of my business.
Dat is altijd even klooien ja. Je kunt proberen om de kolom naar Excel te plakken, daar de juiste celstructuur te kiezen en vervolgens weer in SPSS te zetten.quote:
Ik ben even compleet gefrustreerd. Ik heb data in spss die ik niet kan analyseren omdat hij vindt dat mijn gemiddelde score een string is. Ik heb er inmiddels een aardappelhoofd van gekregen en ook in de syntax van SPSS kom ik niet verder.
compute Score = number(SC0_1).
execute.
recode SC0_1 (convert) into score2.
execute.
COMPUTE score = NUMBER(SC0_1, F8.12).
execute.
werken allemaal niet. In de 'view variable' de variabele van string naar numeric veranderen heeft tot gevolg dat alle waardes verdwijnen. Uiteindelijk heb ik de huidige laatste drie variabelen verkregen door automatic recode te gebruiken, maar de hoeveelheid informatie die daarbij verloren gaat is onacceptabel. Hij houdt dan twee decimalen over van de veertig.
Helaas moet dit per se in spss. Iemand nog een tip?
Het is gelukt! Mijn dank is grootquote:
[..]
Als je een ANOVA doet, kun je bij "Options" op "Descriptives" klikken. Dan krijg je bij je ANOVA tabel ook een tabel met de Means, SDs etc per groep en voor het totaal. Dit kun je dan doen voor elke afhankelijke variabele. (Je bent alleen geïnteresseerd in de verschillen tussen Bolus en Test en niet AFC rechts/links etc toch?)
You can only have the sunshine after the rain..
In mijn dataset had ik ook twee variabelen die string waren. Wat bleek? Dit waren variabelen waar deelnemers een getal moest intikken (leeftijd bijvoorbeeld). Nu hadden een aantal mensen per ongeluk een / erbij getypt. Nadat ik die had weg gehaald, kon ik het wel veranderen als numerieke data.quote:
Ik ben even compleet gefrustreerd. Ik heb data in spss die ik niet kan analyseren omdat hij vindt dat mijn gemiddelde score een string is. Ik heb er inmiddels een aardappelhoofd van gekregen en ook in de syntax van SPSS kom ik niet verder.
compute Score = number(SC0_1).
execute.
recode SC0_1 (convert) into score2.
execute.
COMPUTE score = NUMBER(SC0_1, F8.12).
execute.
werken allemaal niet. In de 'view variable' de variabele van string naar numeric veranderen heeft tot gevolg dat alle waardes verdwijnen. Uiteindelijk heb ik de huidige laatste drie variabelen verkregen door automatic recode te gebruiken, maar de hoeveelheid informatie die daarbij verloren gaat is onacceptabel. Hij houdt dan twee decimalen over van de veertig.
Helaas moet dit per se in spss. Iemand nog een tip?
Herb is the healing of a nation, alcohol is the destruction.
Zijn hier Excel danwel Google spreadsheet (voorkeur) helden?
Ik zoek een formule voor een close text match.
Voorbeeld:
Kolom A
Book7324
Kolom C
Book7324 eu
Ik wil dat die deze match maakt, een voorwaarde moet zijn dat er een spatie tussenzit. Dit moet met wildcards mogelijk zijn, maar ik kom er toch niet helemaal uit.
Weet iemand tevens een manier om in 1x een cel van al zijn special characters en spaties te ontdoen?
Ik zoek een formule voor een close text match.
Voorbeeld:
Kolom A
Book7324
Kolom C
Book7324 eu
Ik wil dat die deze match maakt, een voorwaarde moet zijn dat er een spatie tussenzit. Dit moet met wildcards mogelijk zijn, maar ik kom er toch niet helemaal uit.
Weet iemand tevens een manier om in 1x een cel van al zijn special characters en spaties te ontdoen?
In Excel macro's kan je de like operator gebruiken. Je kan dus een functie maken.
Google: excel macro like function
Google: excel macro like function
Aldus.
Dit gaat me iets te snel, hoe zou de formule bij bovenstaand voorbeeld eruit zien?quote:
In Excel macro's kan je de like operator gebruiken. Je kan dus een functie maken.
Google: excel macro like function
In Excel kan je macro's maken en met een macro kan je een functie maken. Macro's bieden veel meer functionaliteiten dan functies (en een functies is in wezen een macro). Hoe je precies jouw functie maakt, weet ik niet, maar je googelt dat zo bij elkaar.quote:
Aldus.
En anders met een zoekfunctie. Je kan geloof ik zoeken naar een niet exacte match. En als de overeenkomst altijd links in de cel staat en het extra deel tekst rechts (zoals in je voorbeeld), kan je het oplossen met een =rechts() functie gecombineerd met een zoekfunctie.
Aldus.
Is het nu zo dat het begin altijd klopt en de extra, niet matchende tekst, altijd achteraan staat?
Aldus.
vert.zoeken("*Book7324*";A1:A100;1;ONWAAR)quote:
De lookup op A1 (Book7324) moet de waarde in B (Book7324 eu) vinden.
of VLOOKUP in engels
Jaquote:
Is het nu zo dat het begin altijd klopt en de extra, niet matchende tekst, altijd achteraan staat?
Ben momenteel druk bezig met het analyseren van data uit mijn enquête. Het is een hoop puzzelen en ik begrijp nog niet heel veel maar vroeg me af of ik in de groede richting zit. Als het complete onzin is wat ik hier verkondig dan wil ik dat net zo graag weten!
Ben bezig met een Pearson correlatie toets(?), het gaat over het beeld wat mensen over Facebook hebben en of dit verband heeft met leeftijd.
Analyze > Correlate > Bivariate
Dan krijg ik dit resultaat:
Betekent de -.224 dat er een enigszins negatief verband is tussen de twee, dat ouderen dus een negatiever beeld hebben? Staat de ,005 voor dat dit verband geen toeval is?
Alvast bedankt
Ben bezig met een Pearson correlatie toets(?), het gaat over het beeld wat mensen over Facebook hebben en of dit verband heeft met leeftijd.
Analyze > Correlate > Bivariate
Dan krijg ik dit resultaat:

Betekent de -.224 dat er een enigszins negatief verband is tussen de twee, dat ouderen dus een negatiever beeld hebben? Staat de ,005 voor dat dit verband geen toeval is?
Alvast bedankt
Ja, het is geen sterk effect, maar volgens die tabel is er een negatieve correlatie tussen de twee variabelen. Dus als de waarde van de ene variabele stijgt, dan daalt de waarde van de andere variabele.quote:
Betekent de -.224 dat er een enigszins negatief verband is tussen de twee, dat ouderen dus een negatiever beeld hebben? Staat de ,005 voor dat dit verband geen toeval is?
Alvast bedankt
Wat betreft de p-waarde: Doorgaans houden mensen een alpha aan van 0.05 en je p-waarde is lager dan dat. Dat betekent dat je stelt dat die waarde zo klein is, dat je de nul-hypothese (geen effect) verwerpt en de alternatieve hypothese (wel een effect) aanneemt. Het verband kan dus nog steeds een toevalligheid zijn, (Die kans is er altijd, aangezien p niet nul kan zijn) maar je stelt dat die kans zo klein is, dat je redenen hebt om die conclusie te verwerpen.
Ah super, heb ik toch weer wat geleerd vandaag. Bedankt! Waarom kan de p-waarde niet 0 zijn eigenlijk? Hieronder heb ik een andere vergelijking gevonden waar ook een kleine correlatie is tussen verschillende variabelen. Voor iemand die niet midden in het onderzoek zijn de variabelen natuurlijk onmogelijk te begrijpen.quote:
[..]
Ja, het is geen sterk effect, maar volgens die tabel is er een negatieve correlatie tussen de twee variabelen. Dus als de waarde van de ene variabele stijgt, dan daalt de waarde van de andere variabele.
Wat betreft de p-waarde: Doorgaans houden mensen een alpha aan van 0.05 en je p-waarde is lager dan dat. Dat betekent dat je stelt dat die waarde zo klein is, dat je de nul-hypothese (geen effect) verwerpt en de alternatieve hypothese (wel een effect) aanneemt. Het verband kan dus nog steeds een toevalligheid zijn, (Die kans is er altijd, aangezien p niet nul kan zijn) maar je stelt dat die kans zo klein is, dat je redenen hebt om die conclusie te verwerpen.

Het gaat om de verhouding tussen Mavenisme (mensen willen voorzien van informatie) en 'combinatie persoonlijkheden' (hoe iemand zichzelf inschat als het gaat om mensen verbinden, overtuigen en informeren). Het is niet de verhouding waarin ik geïnteresseerd ben, het gaat mij daar om 'mavenisme vs content' en 'combinatie vs content' maar ben bel benieuwd wat het betekent als P daar dus 0 is, ik zie het wel vaker voorbij komen.
Domme vragen bestaan niet maar ik bied alvast mijn excuses aan in het geval dat
Een p-waarde is eigenlijk gewoon een stuk van de oppervlakte onder de grafiek van een normaalverdeling. De normaalverdeling zal aan de uiteinden asymptotisch worden naar 0. Dat betekent dat de grafiek steeds dichter bij 0 komt, maar deze nooit zal raken. Dus je p-waarde kan oneindig klein zijn, maar nooit echt 0. SPSS rekent echter met 3 cijfers achter de komma, dus elke p-waarde van kleiner dan 0.0005 (dus 0.000499...) zal naar 0 worden afgerond. Voor je conclusies maakt dat niet uit, omdat je met een alpha van 0.05 of 0.01 rekent en het alleen gaat om wel/niet significant. Er bestaat vanuit de statistiek niet zoiets als "erg significant" of "een beetje significant."quote:
[..]
Ah super, heb ik toch weer wat geleerd vandaag. Bedankt! Waarom kan de p-waarde niet 0 zijn eigenlijk? Hieronder heb ik een andere vergelijking gevonden waar ook een kleine correlatie is tussen verschillende variabelen. Voor iemand die niet midden in het onderzoek zijn de variabelen natuurlijk onmogelijk te begrijpen.
[ afbeelding ]
Het gaat om de verhouding tussen Mavenisme (mensen willen voorzien van informatie) en 'combinatie persoonlijkheden' (hoe iemand zichzelf inschat als het gaat om mensen verbinden, overtuigen en informeren. Het is niet de verhouding waarin ik geïnteresseerd ben, het gaat mij daar om 'mavenisme vs content' en 'combinatie vs content' maar ben bel benieuwd wat het betekent als P daar dus 0 is, ik zie het wel vaker voorbij komen.
Domme vragen bestaan niet maar ik bied alvast mijn excuses aan in het geval dat
EDIT: Dat de normaalverdeling asymptotisch is, is ook meteen de reden dat je met een 95%CI of 99%CI werkt en nooit met een 100%CI. 100%CI zou betekenen dat het betrouwbaarheidsinterval loopt van - oneindig tot + oneindig. Dat is niet zo informatief.
Bedankt voor de heldere uitleg!quote:
[..]
Een p-waarde is eigenlijk gewoon een stuk van de oppervlakte onder de grafiek van een normaalverdeling. De normaalverdeling zal aan de uiteinden asymptotisch worden naar 0. Dat betekent dat de grafiek steeds dichter bij 0 komt, maar deze nooit zal raken. Dus je p-waarde kan oneindig klein zijn, maar nooit echt 0. SPSS rekent echter met 3 cijfers achter de komma, dus elke p-waarde van kleiner dan 0.0005 (dus 0.000499...) zal naar 0 worden afgerond. Voor je conclusies maakt dat niet uit, omdat je met een alpha van 0.05 of 0.01 rekent en het alleen gaat om wel/niet significant. Er bestaat vanuit de statistiek niet zoiets als "erg significant" of "een beetje significant."
EDIT: Dat de normaalverdeling asymptotisch is, is ook meteen de reden dat je met een 95%CI of 99%CI werkt en nooit met een 100%CI. 100%CI zou betekenen dat het betrouwbaarheidsinterval loopt van - oneindig tot + oneindig. Dat is niet zo informatief.
Een tip waar je niet om vraagt. Plot de twee waardes ook eens tegen elkaar met een scatterplot of zoiets.
Het zou kunnen datje data niet linear met elkaar samenhangen, bv (shit dacht dat je positieve correlatie had, nou ja voor het voorbeeld is ie positief):
leeftijd -> liking facebook (1-10)
7 - 5
8 - 4
9 - 3
10 - 2
11 - 3
12 - 4
13 - 5
14 - 6
15 - 7
16 - 8
17 - 9
18 - 10
In zo'n situatie zou je wel een significante correlatie kunnen krijgen en gaat liking over het algemeen omhoog met leeftijd maar zou de claim dat hoeouder je wordt hoe positiever je beeld wordt niet kloppen.
Het zou kunnen datje data niet linear met elkaar samenhangen, bv (shit dacht dat je positieve correlatie had, nou ja voor het voorbeeld is ie positief):
leeftijd -> liking facebook (1-10)
7 - 5
8 - 4
9 - 3
10 - 2
11 - 3
12 - 4
13 - 5
14 - 6
15 - 7
16 - 8
17 - 9
18 - 10
In zo'n situatie zou je wel een significante correlatie kunnen krijgen en gaat liking over het algemeen omhoog met leeftijd maar zou de claim dat hoeouder je wordt hoe positiever je beeld wordt niet kloppen.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ben net uit het systeem gegaan. Ga morgen weer verder, dan zal ik er even naar kijken.quote:
Een tip waar je niet om vraagt. Plot de twee waardes ook eens tegen elkaar met een scatterplot of zoiets.
Het zou kunnen datje data niet linear met elkaar samenhangen, bv (shit dacht dat je positieve correlatie had, nou ja voor het voorbeeld is ie positief):
leeftijd -> liking facebook (1-10)
7 - 5
8 - 4
9 - 3
10 - 2
11 - 3
12 - 4
13 - 5
14 - 6
15 - 7
16 - 8
17 - 9
18 - 10
In zo'n situatie zou je wel een significante correlatie kunnen krijgen en gaat liking over het algemeen omhoog met leeftijd maar zou de claim dat hoeouder je wordt hoe positiever je beeld wordt niet kloppen.
Bedankt voor de tip!
Heb even geprobeerd om een scatter plot te maken maar ik denk dat ik daar niet heel veel aan heb omdat ik de exacte leeftijden niet heb gevraagd. Het is nu allemaal ingedeeld in groepen en aan verhoudingen kan je wel zien dat mensen minder positief zijn naarmate hun leeftijd stijgt maar het is niet echt duidelijk.
Ik heb wel een andere vraag nog, zoals jullie hier kunnen zien is de indeling qua leeftijd niet echt logisch. Ik had weinig respondenten in de leeftijdsklasse 46-55 en 65+. Om de data toch te kunnen analyseren heb ik twee grotere groepen gemaakt, 36-55 en 55+. Kan ik dit goed praten? Ik lever dan waarschijnlijk in op betrouwbaarheid maar als ik in een bepaalde groep maar 10 respondenten heb kan ik daar volgens mij helemaal geen uitspraak over doen.
[ Bericht 31% gewijzigd door Tobi-wan op 18-05-2015 11:52:14 ]

Ik heb wel een andere vraag nog, zoals jullie hier kunnen zien is de indeling qua leeftijd niet echt logisch. Ik had weinig respondenten in de leeftijdsklasse 46-55 en 65+. Om de data toch te kunnen analyseren heb ik twee grotere groepen gemaakt, 36-55 en 55+. Kan ik dit goed praten? Ik lever dan waarschijnlijk in op betrouwbaarheid maar als ik in een bepaalde groep maar 10 respondenten heb kan ik daar volgens mij helemaal geen uitspraak over doen.
[ Bericht 31% gewijzigd door Tobi-wan op 18-05-2015 11:52:14 ]
Kan je dan niet een oplossing met '=LINKS()' en '=VERT.ZOEKEN()' knutselen? Eventueel met een tussenkolom.quote:
Aldus.
Deze pakt die niet als die de waarde uit de cel moet halen, dus:quote:
[..]
vert.zoeken("*Book7324*";A1:A100;1;ONWAAR)
of VLOOKUP in engels
vert.zoeken("*B1*";A1:A100;1;ONWAAR)
Hoe werken wildcards in deze combinatie?
Moet hier toch nog even op terugkomen, het is toch niet helemaal duidelijk. Als de p-waarde 0.000 is in SPSS (dus niet 0 want dat kan niet), kan je de hypothese dat iets geen effect heeft verwerpen?quote:
[..]
Een p-waarde is eigenlijk gewoon een stuk van de oppervlakte onder de grafiek van een normaalverdeling. De normaalverdeling zal aan de uiteinden asymptotisch worden naar 0. Dat betekent dat de grafiek steeds dichter bij 0 komt, maar deze nooit zal raken. Dus je p-waarde kan oneindig klein zijn, maar nooit echt 0. SPSS rekent echter met 3 cijfers achter de komma, dus elke p-waarde van kleiner dan 0.0005 (dus 0.000499...) zal naar 0 worden afgerond. Voor je conclusies maakt dat niet uit, omdat je met een alpha van 0.05 of 0.01 rekent en het alleen gaat om wel/niet significant. Er bestaat vanuit de statistiek niet zoiets als "erg significant" of "een beetje significant."
EDIT: Dat de normaalverdeling asymptotisch is, is ook meteen de reden dat je met een 95%CI of 99%CI werkt en nooit met een 100%CI. 100%CI zou betekenen dat het betrouwbaarheidsinterval loopt van - oneindig tot + oneindig. Dat is niet zo informatief.

Heb even bovenstaande vergelijking gemaakt omdat het zonder onderzoek aannemelijk is dat deze gegevens met elkaar verbonden zijn. Hier geldt ook hetgeen wat je hierboven plaatste?
Of moet ik hier de scatter plot toe te passen om te zien of er echt een correlatie tussen de twee variabelen is?quote:Wat betreft de p-waarde: Doorgaans houden mensen een alpha aan van 0.05 en je p-waarde is lager dan dat. Dat betekent dat je stelt dat die waarde zo klein is, dat je de nul-hypothese (geen effect) verwerpt en de alternatieve hypothese (wel een effect) aanneemt. Het verband kan dus nog steeds een toevalligheid zijn, (Die kans is er altijd, aangezien p niet nul kan zijn) maar je stelt dat die kans zo klein is, dat je redenen hebt om die conclusie te verwerpen.
[ Bericht 1% gewijzigd door Tobi-wan op 19-05-2015 12:23:57 ]
Aangezien het om een correlatie gaat, kun je de nulhypothese dat er geen correlatie is tussen de twee variabelen verwerken. 0.000 is immers lager dan 0.05. Zeggen dat er een effect is (wat ik deed in de eerste post, excuses), zou ik achterwege laten, omdat dat zou kunnen worden gelezen als "Variabele 1 beïnvloed Variabele 2" en die conclusie kun je bij correlaties niet trekken. Er is een samenhang en je kunt beoordelen of deze positief of negatief is en sterk of zwak.quote:
[..]
Moet hier toch nog even op terugkomen, het is toch niet helemaal duidelijk. Als de p-waarde 0.000 is in SPSS (dus niet 0 want dat kan niet), kan je de hypothese dat iets geen effect heeft verwerpen?
De uitleg uit mijn vorige past en wat ik hierboven zeg gelden ook voor deze variabelen ja. Zoals je zelf zegt is dit resultaat te verwachten omdat je in beide vragen min of meer hetzelfde meet.quote:[ afbeelding ]
Heb even bovenstaande vergelijking gemaakt omdat het zonder onderzoek aannemelijk is dat deze gegevens met elkaar verbonden zijn. Hier geldt ook hetgeen wat je hierboven plaatste?
De correlatie is er, maar zoals oompaloompa al zei, het hoeft niet perse een lineair verband te zijn. De scatterplots kunnen helpen om daar wat meer inzicht in te krijgen.quote:Of moet ik hier de scatter plot toe te passen om te zien of er echt een correlatie tussen de twee variabelen is?
| Forum Opties | |
|---|---|
| Forumhop: | |
| Hop naar: | |