SES School, Studie en Onderwijs
Wiskunde in de brugklas, Frans voor het examen of een studie Personeel en Arbeid? Moeilijke formulieren van DUO? Iets weten over studiefinanciering of studentenverenigingen? Dit is het forum voor leerkrachten, scholieren en studenten, van brugklas tot uni



Thanks. Dat verhielp het probleem inderdaad.quote:Op vrijdag 21 juli 2017 17:44 schreef Z het volgende:
De boel even opnieuw opstarten wellicht? Ik weet niks van SAS maar met Macro's weet je soms niet welke er hoe in het geheugen staat.
Hallo!
Ik hoop dat jullie mij kunnen helpen! Ik heb data van mijn onderzoek maar ik twijfel over statistische test die ik moet gebruiken.
Ik heb 1 groep deelnemers (sporters) gevolgd in de tijd. De tijd kan ik indelen in 2 perioden: training en vakantie.
Deze groep heb ik in de studieperiode 8 x een vragenlijst toegestuurd en uiteindelijk heb ik van iedere deelnemer data van 6 of 7 complete vragenlijsten. Uit iedere vragenlijst heb ik data gekregen voor 6 subscales (het zijn 6 gemoeds/gevoelstoestanden, zoals vermoeidheid, blijdschap/energie, boosheid, etc).
Ik heb dus 6 afhankelijke variabelen (de subscales).
En ik heb ze meerdere malen gemeten binnen mijn proefpersonen. Ik heb niet van iedere deelnemer evenveel datapunten in de 'training' en 'vakantie' periode.
Ik wil weten of de subscales significant anders zijn in de verschillende periode en welke dat dan zijn.
Als ik mijn data plot kan ik al zien dat er duidelijk verschil is, maar ik wil het met cijfers kunnen onderbouwen.
Nu heb ik drie opties bedacht:
• 1. Ik kan van iedere deelnemer per periode een gemiddelde nemen van de gemeten scores per periode (omdat het dus meerdere metingen zijn binnen 1 persoon) en deze per subscale vergelijken in paired samples t-tests.
Alleen raak ik hier geen 'data' kwijt?
• 2. Ik kan een MANOVA uitvoeren op de alle metingen (niet gemiddeld) omdat ik meerdere dependent variables heb (6 subscales), en twee onafhankelijke factoren 'Periode' en 'participant'?
• 3. Ik dacht ook aan een repeated measurement ANOVA omdat ik meerdere metingen heb uitgevoerd binnen dezelfde participant. 'Subscale' zet ik dan als within-subject factor. 'Periode' is een Between-subject Factor, en 'Participant' ook.
Iemand een suggestie welke van mijn opties ik het beste kan kiezen?
Ik hoop dat jullie mij kunnen helpen! Ik heb data van mijn onderzoek maar ik twijfel over statistische test die ik moet gebruiken.
Ik heb 1 groep deelnemers (sporters) gevolgd in de tijd. De tijd kan ik indelen in 2 perioden: training en vakantie.
Deze groep heb ik in de studieperiode 8 x een vragenlijst toegestuurd en uiteindelijk heb ik van iedere deelnemer data van 6 of 7 complete vragenlijsten. Uit iedere vragenlijst heb ik data gekregen voor 6 subscales (het zijn 6 gemoeds/gevoelstoestanden, zoals vermoeidheid, blijdschap/energie, boosheid, etc).
Ik heb dus 6 afhankelijke variabelen (de subscales).
En ik heb ze meerdere malen gemeten binnen mijn proefpersonen. Ik heb niet van iedere deelnemer evenveel datapunten in de 'training' en 'vakantie' periode.
Ik wil weten of de subscales significant anders zijn in de verschillende periode en welke dat dan zijn.
Als ik mijn data plot kan ik al zien dat er duidelijk verschil is, maar ik wil het met cijfers kunnen onderbouwen.
Nu heb ik drie opties bedacht:
• 1. Ik kan van iedere deelnemer per periode een gemiddelde nemen van de gemeten scores per periode (omdat het dus meerdere metingen zijn binnen 1 persoon) en deze per subscale vergelijken in paired samples t-tests.
Alleen raak ik hier geen 'data' kwijt?
• 2. Ik kan een MANOVA uitvoeren op de alle metingen (niet gemiddeld) omdat ik meerdere dependent variables heb (6 subscales), en twee onafhankelijke factoren 'Periode' en 'participant'?
• 3. Ik dacht ook aan een repeated measurement ANOVA omdat ik meerdere metingen heb uitgevoerd binnen dezelfde participant. 'Subscale' zet ik dan als within-subject factor. 'Periode' is een Between-subject Factor, en 'Participant' ook.
Iemand een suggestie welke van mijn opties ik het beste kan kiezen?
Optie 1 valt af omdat je een aanname schendt, namelijk die van onafhankelijke waarnemingen. Dat geldt ook voor optie 2. Repeated measures anova houdt hier wel rekening mee, dus dat lijkt me de voorkeur hebben.quote:Op woensdag 26 juli 2017 16:13 schreef Sonyanijntje het volgende:
Hallo!
Ik hoop dat jullie mij kunnen helpen! Ik heb data van mijn onderzoek maar ik twijfel over statistische test die ik moet gebruiken.
[...]
Iemand een suggestie welke van mijn opties ik het beste kan kiezen?
Ik weet echter niet of je problemen krijgt met missing data, dat zou nog wel eens kunnen. Het mooiste alternatief zou multi-level regressie zijn, die techniek is veel flexibeler, maar dat is next level shit
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Ik heb een sas-macro maar er gaat iets niet helemaal naar behoren
Ik wil dus verschillende acties uitvoeren voor de jaren voor 2003 en de jaren 2003 tot en met 2007.
Bij het runnen van de macro voor de jaren 2003-2007 gaat alles naar behoren, alleen bij het runnen van de jaren voor 2003 krijg ik een error:
Daaruit blijkt dat de macro op de data van de jaren kleiner dan 2003 ook de actie voor de jaren 2003-2007 uitvoert. Ik zie alleen niet waar de fout in mijn script zit
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | %combineddata(y); Mergeddata&y; merge a b; run; %if &y<2003 %then %do; data test&y; merge mergeddata&y d; by db32; run; %end; %if 2003 le &y le 2007 %then %do; data test&y; merge mergeddata&y f; by db45; run; %end; |
Ik wil dus verschillende acties uitvoeren voor de jaren voor 2003 en de jaren 2003 tot en met 2007.
Bij het runnen van de macro voor de jaren 2003-2007 gaat alles naar behoren, alleen bij het runnen van de jaren voor 2003 krijg ik een error:
Daaruit blijkt dat de macro op de data van de jaren kleiner dan 2003 ook de actie voor de jaren 2003-2007 uitvoert. Ik zie alleen niet waar de fout in mijn script zit
Kun je ze niet los van elkaar runnen en die van voor 2003 net zo schrijven als 2003-2007?quote:
Ik heb een sas-macro maar er gaat iets niet helemaal naar behoren
[ code verwijderd ]
Ik wil dus verschillende acties uitvoeren voor de jaren voor 2003 en de jaren 2003 tot en met 2007.
Bij het runnen van de macro voor de jaren 2003-2007 gaat alles naar behoren, alleen bij het runnen van de jaren voor 2003 krijg ik een error:
Daaruit blijkt dat de macro op de data van de jaren kleiner dan 2003 ook de actie voor de jaren 2003-2007 uitvoert. Ik zie alleen niet waar de fout in mijn script zit
Ik heb hem herschrevenquote:
[..]
Kun je ze niet los van elkaar runnen en die van voor 2003 net zo schrijven als 2003-2007?
Ik heb de volgende regel herschreven:quote:
[..]
Kun je ze niet los van elkaar runnen en die van voor 2003 net zo schrijven als 2003-2007?
| 1 | %if 2003 le &y le 2007 %then %do; |
| 1 | %if 2003 le &y AND &y le 2007 %then %do; |
Ik weet niet of je dit bedoelde, maar iig bedankt voor het meedenken
tussendoor even een kansloze excel vraag, excuus.
Hoe krijg ik van die up/down pijltjes in een cel om een nummer te verhogen/verlagen? ipv 683 handmatig veranderen in 684 het door middel van een klik op een pijltje verhogen?
Hoe krijg ik van die up/down pijltjes in een cel om een nummer te verhogen/verlagen? ipv 683 handmatig veranderen in 684 het door middel van een klik op een pijltje verhogen?
'If you really think that the environment is less important than the economy try holding your breath while you count your money'
Hallo allen,
Ik heb hier een R code en ik vraag mij dus af wat er bedoeld wordt met:
- x1, x2 en x3...
- var
Ik heb hier een R code en ik vraag mij dus af wat er bedoeld wordt met:
- x1, x2 en x3...
- var
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | makelms <- function(){ # Store the coefficient of linear models with different independent variables cf <- c(coef(lm(Fertility ~ Agriculture, swiss))[2], coef(lm(Fertility ~ Agriculture + Catholic,swiss))[2], coef(lm(Fertility ~ Agriculture + Catholic + Education,swiss))[2], coef(lm(Fertility ~ Agriculture + Catholic + Education + Examination,swiss))[2], coef(lm(Fertility ~ Agriculture + Catholic + Education + Examination +Infant.Mortality, swiss))[2]) print(cf) } # Regressor generation process 1. rgp1 <- function(){ print("Processing. Please wait.") # number of samples per simulation n <- 100 # number of simulations nosim <- 1000 # set seed for reproducability set.seed(4321) # Point A: x1 <- rnorm(n) x2 <- rnorm(n) x3 <- rnorm(n) # Point B: betas <- sapply(1 : nosim, function(i)makelms(x1, x2, x3)) round(apply(betas, 1, var), 5) } # Regressor generation process 2. rgp2 <- function(){ print("Processing. Please wait.") # number of samples per simulation n <- 100 # number of simulations nosim <- 1000 # set seed for reproducability set.seed(4321) # Point C: x1 <- rnorm(n) x2 <- x1/sqrt(2) + rnorm(n) /sqrt(2) x3 <- x1 * 0.95 + rnorm(n) * sqrt(1 - 0.95^2) # Point D: betas <- sapply(1 : nosim, function(i)makelms(x1, x2, x3)) round(apply(betas, 1, var), 5) } betas |
Na wat data manipulatie heb ik een dataset gekregen die ik in R wil gebruiken om wat plotjes te maken etc.
(Dit is niet het origineel, maar copy daarvan is niet mogelijk aangezien ik op een beveiligde server werk)
Echter wil ik dit script omschrijven in een function waarin ik voor 2000 elk willekeurig jaartal in zou moeten kunnen vullen. Dit lukt echter maar gedeeltelijk, want de functie kan prima elke keer 2000 veranderen in het gewenste jaartal maar kan dit niet doen voor de tekst die tussen "" staat, zoals onderandere de bestandsnaam van de sas-dataset. Is dit in het geheel niet mogelijk of is zijn er mogelijkheden om dit voor elkaar te krijgen?
| 1 2 3 | dataset2000<-read_sas("dataset2000.sas7dbat") plot(dataset2000, x,y) etc.... |
Echter wil ik dit script omschrijven in een function waarin ik voor 2000 elk willekeurig jaartal in zou moeten kunnen vullen. Dit lukt echter maar gedeeltelijk, want de functie kan prima elke keer 2000 veranderen in het gewenste jaartal maar kan dit niet doen voor de tekst die tussen "" staat, zoals onderandere de bestandsnaam van de sas-dataset. Is dit in het geheel niet mogelijk of is zijn er mogelijkheden om dit voor elkaar te krijgen?
quote:
Moet kunnen. "Putting all the data frames in a list and looping over that list with lapply".
Bedankt voor de hulp, maar dit gaat specifiek over de dataset. Maar ik wil ook dat de functie de titel van de grafiek aanpast etc., maar aangezien die tussen "" staat, doet de functie daar niets mee.quote:
ehh, paste0("dataset", n, ".sas7dbat") ?
Populatie a: 500.000 samples, mean = 19, stdv = 10
Populatie b: 500 samples, mean = 23, stdv = 11
Populaties zijn niet normaal verdeeld.
Wat voor een test kan ik het beste gebruiken om aan te tonen of populatie b binnen/buiten populatie a valt?
[ Bericht 9% gewijzigd door Lyrebird op 30-08-2017 17:19:38 ]
Populatie b: 500 samples, mean = 23, stdv = 11
Populaties zijn niet normaal verdeeld.
Wat voor een test kan ik het beste gebruiken om aan te tonen of populatie b binnen/buiten populatie a valt?
[ Bericht 9% gewijzigd door Lyrebird op 30-08-2017 17:19:38 ]
Good intentions and tender feelings may do credit to those who possess them, but they often lead to ineffective — or positively destructive — policies ... Kevin D. Williamson
Mann-whitneytoets.quote:Op woensdag 30 augustus 2017 16:49 schreef Lyrebird het volgende:
Populatie a: 500.000 samples, mean = 19, stdv = 10
Populatie b: 500 samples, mean = 23, stdv = 11
Populaties zijn niet normaal verdeeld.
Wat voor een test kan ik het beste gebruiken om aan te tonen of populatie b binnen/buiten populatie a valt?
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Graag uw hulp.
Ik heb van opeenvolgende jaren een populatie gevolgt waarvan een proportie positief scored op een test (dichotoom: positief of negatief).
Graag wil ik een trend analyse doen om aan te tonen dat de proportie positieve testen toeneemt in de tijd. De gescreende individuen in de populatie die worden getest verschillen per jaar.
Welke methode is hier geschikt voor? Ik denk dat ik met logistic regression een heel eind kom.
[ Bericht 4% gewijzigd door No-P op 21-09-2017 21:44:17 ]
Ik heb van opeenvolgende jaren een populatie gevolgt waarvan een proportie positief scored op een test (dichotoom: positief of negatief).
Graag wil ik een trend analyse doen om aan te tonen dat de proportie positieve testen toeneemt in de tijd. De gescreende individuen in de populatie die worden getest verschillen per jaar.
Welke methode is hier geschikt voor? Ik denk dat ik met logistic regression een heel eind kom.
[ Bericht 4% gewijzigd door No-P op 21-09-2017 21:44:17 ]
Sei wachsam,
Fall nicht auf sie rein! Paß auf, daß du deine Freiheit nutzt,
Die Freiheit nutzt sich ab, wenn du sie nicht nutzt!
Fall nicht auf sie rein! Paß auf, daß du deine Freiheit nutzt,
Die Freiheit nutzt sich ab, wenn du sie nicht nutzt!
Nee, want je schendt de assumptie van onafhankelijke waarnemingen, wanneer er sprake is van meerdere metingen per persoon. Een waarneming is dan niet meer onafhankelijk want het is immers afhankelijk van de persoon.quote:
Graag uw hulp.
Ik heb van opeenvolgende jaren een populatie gevolgt waarvan een proportie positief scored op een test (dichotoom: positief of negatief).
Graag wil ik een trend analyse doen om aan te tonen dat de proportie positieve testen toeneemt in de tijd. De gescreende individuen in de populatie die worden getest verschillen per jaar.
Welke methode is hier geschikt voor? Ik denk dat ik met logistic regression een heel eind kom.
Multi level logistic regression corrigeert hiervoor, dus dat zou ik je aanraden.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Meer statistiek/onderzoek maar het heeft een wiskunde component en het is niet de moeite om een apart topic te openen.
Ik zit met het probleem dat ik niet weet of ik een t-test moet doen of een regressie. In het verleden heb ik het allemaal gehad maar het is weg gezakt.
In het kort het onderzoek:
Op dag 1 wordt gevraagd naar de mening over A. (Via een likert schaal).
Op dag 2 wordt onder een compleet andere groep mensen gevraagd naar de mening over B.
Het is trouwens onbekend of de variatie van beiden gelijk zijn.
Nu is de vraag moet ik dit onderzoeken met een double tail independent two sample T test of Welchers T test. Of dat ik het beter kan doen met een regressie (least squares).
Zo ja welke moet ik kiezen en vooral waarom. Mijn gevoel en volgens wiki zegt de T test echter kom ik niet echt achter de voordelen van een T-test over een regressie.
[ Bericht 1% gewijzigd door icecreamfarmer_NL op 13-10-2017 21:28:48 ]
Ik zit met het probleem dat ik niet weet of ik een t-test moet doen of een regressie. In het verleden heb ik het allemaal gehad maar het is weg gezakt.
In het kort het onderzoek:
Op dag 1 wordt gevraagd naar de mening over A. (Via een likert schaal).
Op dag 2 wordt onder een compleet andere groep mensen gevraagd naar de mening over B.
Het is trouwens onbekend of de variatie van beiden gelijk zijn.
Nu is de vraag moet ik dit onderzoeken met een double tail independent two sample T test of Welchers T test. Of dat ik het beter kan doen met een regressie (least squares).
Zo ja welke moet ik kiezen en vooral waarom. Mijn gevoel en volgens wiki zegt de T test echter kom ik niet echt achter de voordelen van een T-test over een regressie.
[ Bericht 1% gewijzigd door icecreamfarmer_NL op 13-10-2017 21:28:48 ]
1/10 Van de rappers dankt zijn bestaan in Amerika aan de Nederlanders die zijn voorouders met een cruiseschip uit hun hongerige landen ophaalde om te werken op prachtige plantages.
"Oorlog is de overtreffende trap van concurrentie."
"Oorlog is de overtreffende trap van concurrentie."
Wat wil je uberhaupt onderzoeken?quote:
Meer statistiek/onderzoek maar het heeft een wiskunde component en het is niet de moeite om een apart topic te openen.
Ik zit met het probleem dat ik niet weet of ik een t-test moet doen of een regressie. In het verleden heb ik het allemaal gehad maar het is weg gezakt.
In het kort het onderzoek:
Op dag 1 wordt gevraagd naar de mening over A. (Via een likert schaal).
Op dag 2 wordt onder een compleet andere groep mensen gevraagd naar de mening over B.
Het is trouwens onbekend of de variatie van beiden gelijk zijn.
Nu is de vraag moet ik dit onderzoeken met een double tail independent two sample T test of Welchers T test. Of dat ik het beter kan doen met een regressie (least squares).
Zo ja welke moet ik kiezen en vooral waarom. Mijn gevoel en volgens wiki zegt de T test echter kom ik niet echt achter de voordelen van een T-test over een regressie.
Ik hoop heel erg dat iemand mij kan helpen hiermee.
Ik heb de volgende onderzoeksopzet:
Er werd getest wat het effect van beweging is op je witte bloedcellen. Hiervoor hebben we 7 mannen vier verschillende protocollen laten fietsen (A t/m D). Iedereen heeft elk protocol gerandomiseerd gefietst, met één of twee weken er tussen. In totaal zijn er op vier tijdstippen monsters genomen: t1= voor het fietsen,t2, t3 en t4 na het fietsen op vaste tijdstippen.
Data ziet er per protocol dus als volgt uit:
t1 t2 t3 t4
1 5% 6% 4% 5%
2
3
4
5
6
7
N.B. Er zit veel biologische variatie tussen de proefpersonen
Wat ik wil weten zijn twee dingen
1. zit er verschil tussen t1 van protocol A en protocol B ( en C en D).
2. Zit er binnen het protocol verschil tussen t1, t2, t3 en t4
Voor de tweede vraag heb ik een one way repeated measures anova gedaan. Omdat het om herhaalde metingen gaat op dezelfde persoon in de tijd. Post hoc = bonferroni
Maar uit de eerste vraag kom ik niet zo goed. Ik ging er niet van uit dat dit herhaalde metingen zijn en wilde een two-way anova doen om wel te blocken voor de biologische variatie, maar bij het uitvoeren er van (in GraphPad Prism) raakte ik wat in de war bij de 'multiple comparisons' en bedacht ik mij dat het niet klopt, want je kan een persoon niet als factor zien als je wilt zien wat het verschil is, maar ook kan je niet werken met een gemiddelde van de complete groep (t1 protocol a) vanwege de variatie.
Zou je hier ook een one-way ANOVA met herhaalde metingen op los kunnen laten?
Niet alle data is normaal verdeeld, denk dat dat (Deels) komt door het geringe aantal. Bij het uitvoeren van de test ga ik er wel altijd van uit dat de sphericty niet wordt gehaald en wordt er een Geisser-Green nogwat correctie uitgevoerd.
Klopt het een beetje wat ik doe?
Ik heb de volgende onderzoeksopzet:
Er werd getest wat het effect van beweging is op je witte bloedcellen. Hiervoor hebben we 7 mannen vier verschillende protocollen laten fietsen (A t/m D). Iedereen heeft elk protocol gerandomiseerd gefietst, met één of twee weken er tussen. In totaal zijn er op vier tijdstippen monsters genomen: t1= voor het fietsen,t2, t3 en t4 na het fietsen op vaste tijdstippen.
Data ziet er per protocol dus als volgt uit:
t1 t2 t3 t4
1 5% 6% 4% 5%
2
3
4
5
6
7
N.B. Er zit veel biologische variatie tussen de proefpersonen
Wat ik wil weten zijn twee dingen
1. zit er verschil tussen t1 van protocol A en protocol B ( en C en D).
2. Zit er binnen het protocol verschil tussen t1, t2, t3 en t4
Voor de tweede vraag heb ik een one way repeated measures anova gedaan. Omdat het om herhaalde metingen gaat op dezelfde persoon in de tijd. Post hoc = bonferroni
Maar uit de eerste vraag kom ik niet zo goed. Ik ging er niet van uit dat dit herhaalde metingen zijn en wilde een two-way anova doen om wel te blocken voor de biologische variatie, maar bij het uitvoeren er van (in GraphPad Prism) raakte ik wat in de war bij de 'multiple comparisons' en bedacht ik mij dat het niet klopt, want je kan een persoon niet als factor zien als je wilt zien wat het verschil is, maar ook kan je niet werken met een gemiddelde van de complete groep (t1 protocol a) vanwege de variatie.
Zou je hier ook een one-way ANOVA met herhaalde metingen op los kunnen laten?
Niet alle data is normaal verdeeld, denk dat dat (Deels) komt door het geringe aantal. Bij het uitvoeren van de test ga ik er wel altijd van uit dat de sphericty niet wordt gehaald en wordt er een Geisser-Green nogwat correctie uitgevoerd.
Klopt het een beetje wat ik doe?
Ik heb een vraagje over het gebruik van SAS MACRO's . Ik heb hier zelf nooit eerder mee moeten werken, echter moet ik dit nu voor mijn thesis wel doen. Ik heb nu een syntax voor een macro gekregen die ik kan gebruiken. Het gaat hierbij om het maken van restricted cubic splines. Echter snap ik dus niet hoe ik deze macro moet runnen. Ik heb het idee dat ik iets heel simpels verkeerd doe.. Ik gebruik de RCS_Reg van loïc Desquilet, mocht het verhelderend werken.
Kan iemand mij simpel uitleggen wat je moet doen om het goed te laten runnen? In de spoiler staat een deel van de syntax.
Kan iemand mij simpel uitleggen wat je moet doen om het goed te laten runnen? In de spoiler staat een deel van de syntax.
SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.
[ Bericht 57% gewijzigd door peperkoekmannetje op 30-10-2017 14:16:42 (toevoeging) ]
Hallo allemaal,
Graag zou ik de volgende data willen analyseren.
Verschil in resultaat (in percentage) na 4 weken en 1 jaar gescoord door dezelfde groep: wilcoxon signed rank test?
Verschil in resultaat in percentage na 4 weken (en 1 jaar) gescoord door 2 verschillende groepen
welke analyses kan ik hier het beste voor gebruiken in spes en waarom
Graag zou ik de volgende data willen analyseren.
Verschil in resultaat (in percentage) na 4 weken en 1 jaar gescoord door dezelfde groep: wilcoxon signed rank test?
Verschil in resultaat in percentage na 4 weken (en 1 jaar) gescoord door 2 verschillende groepen
welke analyses kan ik hier het beste voor gebruiken in spes en waarom
Hallo,<br />Ik wil graag het volgende analyseren
Vraagje, ik heb een categorial variable: emailopen (email geopend: ja of nee) en een variable met de frequentie van de ja's en nee's. Moet ik dan een chi square goodness of fit test doen?
Ik ben bezig met een statistiek opdracht, maar ik kom er niet helemaal uit welke formule ik nu moet gebruiken:
X heeft een effect op Y, maar verwacht wordt dat dit een inverted U-shape is, door moderator Z.
Nu zit ik met het volgende, zet ik de kwadraat op de X of op de Z? X is trouwens een binary variable.
Op internet lees ik verschillende dingen, ook omdat de meeste sites uitgaan van gewoon in een inverted U, zonder de moderator.
Ik dacht zelf dat ik hem op de Z moest zetten...
X heeft een effect op Y, maar verwacht wordt dat dit een inverted U-shape is, door moderator Z.
Nu zit ik met het volgende, zet ik de kwadraat op de X of op de Z? X is trouwens een binary variable.
Op internet lees ik verschillende dingen, ook omdat de meeste sites uitgaan van gewoon in een inverted U, zonder de moderator.
Ik dacht zelf dat ik hem op de Z moest zetten...

Hi Fok!kers,
Ik zit met een vraag mbt Betrouwbaarheidsinterval bij beperkt eindige populatie en hoe ik dat in mijn rekenmachine moet verwerken. De gegevens staan in de spoilers, het betrouwbaarheidspercentage is 95%, dus een z-waarde van 1,96.
Ik voer dit in (6-1,96*3/wortel300)*(wortel 1000-300/1000-1)
Can somebody help me
Ik zit met een vraag mbt Betrouwbaarheidsinterval bij beperkt eindige populatie en hoe ik dat in mijn rekenmachine moet verwerken. De gegevens staan in de spoilers, het betrouwbaarheidspercentage is 95%, dus een z-waarde van 1,96.
Ik voer dit in (6-1,96*3/wortel300)*(wortel 1000-300/1000-1)
Can somebody help me
SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.Man is de baas, vrouw kent haar plaats.
Beetje googlen, pagina 2: http://canmedia.mcgrawhil(...)bow02371_OLC_7_9.pdfquote:
Bijna goed dus, je hebt te maken met de sample standaarddeviatie en niet die van de populatie.
Thanks voor jouw responsequote:
[..]
Beetje googlen, pagina 2: http://canmedia.mcgrawhil(...)bow02371_OLC_7_9.pdf
Bijna goed dus, je hebt te maken met de sample standaarddeviatie en niet die van de populatie.
Kun jij voordoen hoe je hem in de rekenmachine zet? Ik zit ergens te kutten met zo'n haakje, dus ik krijg voortdurend afwijkende uitkomsten.
Man is de baas, vrouw kent haar plaats.
Oh sorry geen idee, ik weet slechts een beetje af van de meest standaard betrouwbaarheidsintervallen vanwege het premastervak dat ik volg. Het enige dat ik op een rekenmachine kan, is het gemiddelde en de standaardafwijking berekenenquote:Op vrijdag 5 januari 2018 01:23 schreef phpmystyle het volgende:
[..]
Thanks voor jouw response
Kun jij voordoen hoe je hem in de rekenmachine zet? Ik zit ergens te kutten met zo'n haakje, dus ik krijg voortdurend afwijkende uitkomsten.

Ik heb een dataset met x en y coördinaten. Nu wil ik die coördinaten 45o roteren. Ik kom daar niet echt uit in r. Ik vind wel dit maar dat werkt niet omdat het een ander grafiektype is. Ik kom er niet echt uit. Iemand een idee? Het hoeft niet per se in r te gebeuren.
Aldus.
wil je nou een dataset roteren of een plot? EN hoe roteren, rond 0,0? Datapaartjes [x,y] kun je natuurlijk altijd roteren door ze te vermenigvuldigen met een 2D rotatie matrixquote:
Ik heb een dataset met x en y coördinaten. Nu wil ik die coördinaten 45o roteren. Ik kom daar niet echt uit in r. Ik vind wel dit maar dat werkt niet omdat het een ander grafiektype is. Ik kom er niet echt uit. Iemand een idee? Het hoeft niet per se in r te gebeuren.
Verschillende opties, of die matrix die door ralfie genoemd wordt. Of omzetten naar polaire coordinaten en dan er gewoon 45 bij optellen en terugzetten naar x y.quote:
Ik heb een dataset met x en y coördinaten. Nu wil ik die coördinaten 45o roteren. Ik kom daar niet echt uit in r. Ik vind wel dit maar dat werkt niet omdat het een ander grafiektype is. Ik kom er niet echt uit. Iemand een idee? Het hoeft niet per se in r te gebeuren.
Ps. heb je een paar r functies in dm gestuurd.
[ Bericht 1% gewijzigd door Bosbeetle op 10-01-2018 09:32:48 ]
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Altijd goedquote:Op woensdag 10 januari 2018 12:05 schreef Z het volgende:
Dank! Ik heb uiteindelijk voor een andere onelegante oplossing gekozen.
Voor de geintresseerden hier de twee methodes in R... wel oppassen dat dit rond 0,0 roteert en dat is niet altijd wenselijk
polaire coordinaten strategie
r <-sqrt(x^2+y^2)
phi <- atan2(x,y)
new_x <- r*sin(phi+angle)
new_y <- r*cos(phi+angle)
matrix strategie
conversionmatrix <- matrix(c(cos(angle),sin(angle),-sin(angle),cos(angle)), ncol=2, nrow=2)
xy <- cbind(x,y)%*%conversionmatrix
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Wat ik niet helemaal snap is dat de gemiddelden (zo sterk) veranderen na vermenigvuldiging.
Waarschijnlijk doe ik iets niet helemaal goed.
| 1 2 3 4 5 6 7 8 9 10 | d <- as.data.frame(matrix(rnorm(16000, 3, .25), ncol=2)) angle <- 45 conversionmatrix <- matrix(c(cos(angle),sin(angle),-sin(angle),cos(angle)), ncol=2, nrow=2) xy <- as.data.frame(cbind(d$V1,d$V2)%*%conversionmatrix) mean(d$V1) #3 mean(d$V2) #3 mean(xy$V1) #4.129064 mean(xy$V2) #-0.9749411 |
Waarschijnlijk doe ik iets niet helemaal goed.
Aldus.

Hoi! Ik heb speciaal een account aangemaakt omdat ik wanhopig op zoek ben naar hulp bij SPSS. Heeel erg bedankt als iemand me hierbij kan helpen.
Ik moet onderzoek doen naar herhaald slachtofferschap van criminaliteit. Ik wil kijken of personen die eerder slachtoffer zijn geworden van criminaliteit vaker slachtoffer worden dan anderen. Ik heb hierbij onder andere deze variabelen: (1) ooit slachtoffer geweest (2) aantal keer slachtoffer geweest. Bij de tweede variabele kunnen er 6 antwoorden zijn gegeven 0 = geen slachtoffer, 1 = 1 keer etc.
Kan iemand mij vertellen hoe ik er nu achter kan komen of eerdere slachtoffers significant vaker slachtoffer worden van criminaliteit dan personen die hier nog nooit slachtoffer van zijn geworden? Moet ik hiervoor de Independent Samples t-test of Chi Kwadraat toets gebruiken? Wat moet ik precies invullen?
Alvast heeeel erg bedankt voor jullie hulp!
[ Bericht 1% gewijzigd door Alaianaya op 20-03-2018 00:03:42 ]
Ik moet onderzoek doen naar herhaald slachtofferschap van criminaliteit. Ik wil kijken of personen die eerder slachtoffer zijn geworden van criminaliteit vaker slachtoffer worden dan anderen. Ik heb hierbij onder andere deze variabelen: (1) ooit slachtoffer geweest (2) aantal keer slachtoffer geweest. Bij de tweede variabele kunnen er 6 antwoorden zijn gegeven 0 = geen slachtoffer, 1 = 1 keer etc.
Kan iemand mij vertellen hoe ik er nu achter kan komen of eerdere slachtoffers significant vaker slachtoffer worden van criminaliteit dan personen die hier nog nooit slachtoffer van zijn geworden? Moet ik hiervoor de Independent Samples t-test of Chi Kwadraat toets gebruiken? Wat moet ik precies invullen?
Alvast heeeel erg bedankt voor jullie hulp!
[ Bericht 1% gewijzigd door Alaianaya op 20-03-2018 00:03:42 ]
Independent Samples t-test lijkt me prima. Dan ga ik ervan uit dat de 'tweede variabele' een logisch schaaltje is en je er dus een gemiddelde van kan berekenen.
Aldus.
Bedankt! Kun je me misschien nog vertellen hoe ik dit precies doe?quote:
Independent Samples t-test lijkt me prima. Dan ga ik ervan uit dat de 'tweede variabele' een logisch schaaltje is en je er dus een gemiddelde van kan berekenen.
Het is echt jaren geleden voor mij, weet echt nog maar heel weinig.

Zoek dat maar lekker zelf uitquote:
[..]
Bedankt! Kun je me misschien nog vertellen hoe ik dit precies doe?
Het is echt jaren geleden voor mij, weet echt nog maar heel weinig.
Aldus.
Daar ben ik dus al 2,5 dag mee bezig, vandaar dat ik het hier vraag. Maar nogmaals, thanks voor je hulp.quote:
En check 't boek van Andy Field, al dan niet gratis te vinden op de al dan niet bekende websites.quote:
[..]
Daar ben ik dus al 2,5 dag mee bezig, vandaar dat ik het hier vraag. Maar nogmaals, thanks voor je hulp.
Wat overigens echt een eindbaas is (zie zijn twitter account)
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Misschien een noobvraag, maar ik download zojuist een bestand in SPSS. Een deel van de vragen van de survey bevat meerkeuzevragen, A-B-C. In data view staat er onder deze vragen dus een 1, 2 of een 3. Dit klopt bij alle vragen, echter bij een van de vragen met drie antwoordmogelijkheden staat er bij iedere respondent 4, 5 of 6. Iemand een idee hoe dit komt en hoe dit op te lossen?
hmm dat is wel een goede.... dit was een snel ingetypte die code die ik je toen gestuurd heb is beter getest.quote:
Wat ik niet helemaal snap is dat de gemiddelden (zo sterk) veranderen na vermenigvuldiging.
[ code verwijderd ]
Waarschijnlijk doe ik iets niet helemaal goed.
denk trouwens dat je daar de angle in radialen moet invullen... maar dat verklaart de gemiddelden nog niet.
En ik denk dat die dotproduct niet goed gaat over twee kolommen....
ah gevonden wat ik al gezegd had
Even gekeken en het komt dus omdat je punten gecentreerd liggen op 3,3 en je roteert rond 0,0 je draait niet om het midden van de punten heen dus komen ze in een ander kwadrant te liggen en krijgen een heel ander gemiddelde.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 | d <- as.data.frame(matrix(rnorm(16000, 3, .25), ncol=2)) angle <- (45/180)*PI conversionmatrix <- matrix(c(cos(angle),sin(angle),-sin(angle),cos(angle)), ncol=2, nrow=2) xy <- as.data.frame(cbind(d$V1-3,d$V2-3)%*%conversionmatrix) xy <- xy+3 mean(d$V1) #2.999956 mean(d$V2) #2.99881 mean(xy$V1) #2.998964 mean(xy$V2) #2.999412 |
[ Bericht 7% gewijzigd door Bosbeetle op 10-04-2018 11:07:31 ]
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna

ik ben al weer vergeten hoe ik dit opgelost heb.quote:
[..]
hmm dat is wel een goede.... dit was een snel ingetypte die code die ik je toen gestuurd heb is beter getest.
denk trouwens dat je daar de angle in radialen moet invullen... maar dat verklaart de gemiddelden nog niet.
En ik denk dat die dotproduct niet goed gaat over twee kolommen....
ah gevonden wat ik al gezegd had
Even gekeken en het komt dus omdat je punten gecentreerd liggen op 3,3 en je roteert rond 0,0 je draait niet om het midden van de punten heen dus komen ze in een ander kwadrant te liggen en krijgen een heel ander gemiddelde.
[ code verwijderd ]
Aldus.
Iemand hier ervaring met de PROCESS-methode van Hayes? Ik heb een specifieke vraag over model 4. Mijn mediator bestaat uit twee persoonlijkheidskenmerken. Ieder persoonlijkheidskenmerk wordt gemeten door middel van vier items met een five-point Likert Scale (helemaal oneens t/m helemaal eens). Dit zijn er dus acht in totaal. In SPSS is dus een variabele met deze acht items erin gemaakt. Maar ik heb ook losse variabelen met gemiddelden per persoonlijkheidsstijl gemaakt (om te vergelijken tussen mannen en vrouwen). Nu wil ik nog een analyse doen door middel van PROCESS. Welke variabele moet ik dan als mediator invoeren? De twee mean variables die samen de mediator vormen of de variabele die simpelweg uit de items bestaat?
Je kan in dit model maar 1 mediator per keer testen dus ik zou je model twee keer laten draaien.quote:
Iemand hier ervaring met de PROCESS-methode van Hayes? Ik heb een specifieke vraag over model 4. Mijn mediator bestaat uit twee persoonlijkheidskenmerken. Ieder persoonlijkheidskenmerk wordt gemeten door middel van vier items met een five-point Likert Scale (helemaal oneens t/m helemaal eens). Dit zijn er dus acht in totaal. In SPSS is dus een variabele met deze acht items erin gemaakt. Maar ik heb ook losse variabelen met gemiddelden per persoonlijkheidsstijl gemaakt (om te vergelijken tussen mannen en vrouwen). Nu wil ik nog een analyse doen door middel van PROCESS. Welke variabele moet ik dan als mediator invoeren? De twee mean variables die samen de mediator vormen of de variabele die simpelweg uit de items bestaat?
Dus twee keer draaien met beide keren een mean variable? En kom ik dan niet in de problemen met het rapporteren van de resultaten, aangezien het om één mediator gaat?quote:
[..]
Je kan in dit model maar 1 mediator per keer testen dus ik zou je model twee keer laten draaien.
Bedankt voor je antwoord in ieder geval!
Je kan ook drie keer doen, 1x geheel, 1x man, 1x vrouw.quote:
[..]
Dus twee keer draaien met beide keren een mean variable? En kom ik dan niet in de problemen met het rapporteren van de resultaten, aangezien het om één mediator gaat?
Bedankt voor je antwoord in ieder geval!
Hoe noem je een variable in SPSS die zowel goede als foute antwoorden bevat (bijvoorbeeld een kennisvraag)?
Two random variables 𝑋 and 𝑌 have a distribution described by the following simultaneous
density:
𝑓(𝑥, 𝑦) = 24𝑥y if 𝑥 > 0 , 𝑦 > 0 and 𝑥 + 𝑦 < 1
= 0 elsewhere.
𝑎. Are 𝑋𝑋 and 𝑌𝑌 independent? Motivate your answer.
Is een manier om dit aan te tonen om de marginale dichtheden te berekenen van X en Y. Vervolgens deze marginale functies keer elkaar te doen f(x) * f(y), en dan te stellen dat dit ongelijk is aan 24xy
In het boek doen ze het namelijk met een plaatje op een adere manier.
density:
𝑓(𝑥, 𝑦) = 24𝑥y if 𝑥 > 0 , 𝑦 > 0 and 𝑥 + 𝑦 < 1
= 0 elsewhere.
𝑎. Are 𝑋𝑋 and 𝑌𝑌 independent? Motivate your answer.
Is een manier om dit aan te tonen om de marginale dichtheden te berekenen van X en Y. Vervolgens deze marginale functies keer elkaar te doen f(x) * f(y), en dan te stellen dat dit ongelijk is aan 24xy
In het boek doen ze het namelijk met een plaatje op een adere manier.
Groet
Vraag over de t-test in Excel. Ik doe een opleiding die nu toevallig een stukje gedrag heeft maar ik ben a-wiskundig als de pest en heb een docent die het zelf ook niet snapt.
Ik heb onderzoek gedaan naar stress bij katten. De vraag is of een muziek apparaat de stress vermindert ja of nee. Nu heb ik dus twee uitkomsten: een gemiddelde aan aantal stressgedragingen die de katten vertoonden zonder het apparaat en daarnaast het gemiddelde aantal stressgedragingen met apparaat.
Ik heb geen SPSS op m'n laptop en de docent heeft even snel uitgelegd hoe een t-test ook in Excel kan.
Maar hoe weet je nou of je 'twee gelijke steekproeven met gelijke variantie' of 'twee gelijke steekproeven met ongelijke variantie' moet kiezen?
Ik las ergens dat je een f-test moet doen, en die komt uit op 0,2~ oftewel P > 0,05, niet significant. Maar nu weet ik nog niet of ik gelijke of ongelijke variantie moet kiezen.
Ik heb onderzoek gedaan naar stress bij katten. De vraag is of een muziek apparaat de stress vermindert ja of nee. Nu heb ik dus twee uitkomsten: een gemiddelde aan aantal stressgedragingen die de katten vertoonden zonder het apparaat en daarnaast het gemiddelde aantal stressgedragingen met apparaat.
Ik heb geen SPSS op m'n laptop en de docent heeft even snel uitgelegd hoe een t-test ook in Excel kan.
Maar hoe weet je nou of je 'twee gelijke steekproeven met gelijke variantie' of 'twee gelijke steekproeven met ongelijke variantie' moet kiezen?
Ik las ergens dat je een f-test moet doen, en die komt uit op 0,2~ oftewel P > 0,05, niet significant. Maar nu weet ik nog niet of ik gelijke of ongelijke variantie moet kiezen.
In de volgende video wordt het eenvoudig uitgelegd wanneer welke t-test te gebruiken:quote:Op zondag 17 juni 2018 15:17 schreef iSnow het volgende:
Vraag over de t-test in Excel. Ik doe een opleiding die nu toevallig een stukje gedrag heeft maar ik ben a-wiskundig als de pest en heb een docent die het zelf ook niet snapt.
Ik heb onderzoek gedaan naar stress bij katten. De vraag is of een muziek apparaat de stress vermindert ja of nee. Nu heb ik dus twee uitkomsten: een gemiddelde aan aantal stressgedragingen die de katten vertoonden zonder het apparaat en daarnaast het gemiddelde aantal stressgedragingen met apparaat.
Ik heb geen SPSS op m'n laptop en de docent heeft even snel uitgelegd hoe een t-test ook in Excel kan.
Maar hoe weet je nou of je 'twee gelijke steekproeven met gelijke variantie' of 'twee gelijke steekproeven met ongelijke variantie' moet kiezen?
Ik las ergens dat je een f-test moet doen, en die komt uit op 0,2~ oftewel P > 0,05, niet significant. Maar nu weet ik nog niet of ik gelijke of ongelijke variantie moet kiezen.
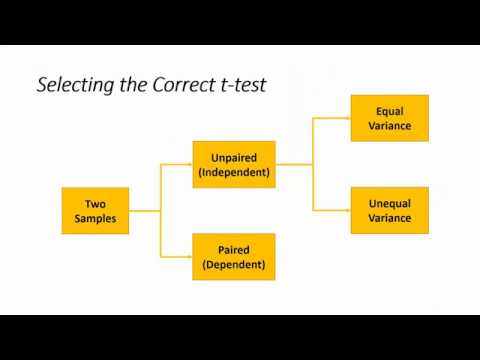
Het komt er op neer dat je variance van beide groepen door elkaar moet delen, en als dat uitkomt op 1 dan moet je voor de equal gaan, en als die waarde significant afwijkt van 1, dan moet je voor de unequal gaan.
Ik kan het op basis van de gegeven informatie niet met zekerheid zeggen, maar ik vermoed dat je voor de unequal moet gaan. (Het kan nooit geen kwaad om in zulk soort gevallen te bekijken of deze keuze ook resulteert in een significant andere uitkomst).
Dan even een beetje ongevraagd advies; ik ken veel mensen die beweerden niet wiskundig te zijn, en die kwamen zich zelf keer op keer tegen wanneer ze ook maar iets van kwantitatief onderzoek deden of probeerden te lezen. Met een beetje doorzettingsvermogen kan je jezelf veel van de meest gebruikte statistische tools eigen maken en dat is zeker als je in de toekomst voor studie of werk meer te maken krijgt met zulk soort vraagstukken onmisbaar. Dan is het zeker ook de moeite waard om wat tijd te investeren in het leren van R of Python (SPSS kan ik persoonlijk alleen maar afraden).
[ Bericht 5% gewijzigd door Mynheer007 op 17-06-2018 16:19:00 ]
Super, bedankt! Ik snapte niet helemaal dat het te maken het dat het op 1 kan uitkomen of kan afwijken van 1. De getallen liggen heel erg bij elkaar of ik nou equal of unequal kies, maar je keuze moet natuurlijk worden onderbouwd. Ik kan er in ieder geval weer mee verder.quote:
[..]
In de volgende video wordt het eenvoudig uitgelegd wanneer welke t-test te gebruiken:
Het komt er op neer dat je variance van beide groepen door elkaar moet delen, en als dat uitkomt op 1 dan moet je voor de equal gaan, en als die waarde significant afwijkt van 1, dan moet je voor de unequal gaan.
Ik kan het op basis van de gegeven informatie niet met zekerheid zeggen, maar ik vermoed dat je voor de unequal moet gaan. (Het kan nooit geen kwaad om in zulk soort gevallen te bekijken of deze keuze ook resulteert in een significant andere uitkomst).
Dan even een beetje ongevraagd advies; ik ken veel mensen die beweerden niet wiskundig te zijn, en die kwamen zich zelf keer op keer tegen wanneer ze ook maar iets van kwantitatief onderzoek deden of probeerden te lezen. Met een beetje doorzettingsvermogen kan je jezelf veel van de meest gebruikte statistische tools eigen maken en dat is zeker als je in de toekomst voor studie of werk meer te maken krijgt met zulk soort vraagstukken onmisbaar. Dan is het zeker ook de moeite waard om wat tijd te investeren in het leren van R of Python (SPSS kan ik persoonlijk alleen maar afraden).
En ik begrijp je advies, wiskunde is gewoon persoonlijk een heikel punt. M'n studie besteed er ook maar 1 vak aan in 4 jaar tijd, met een ingehuurde docent die de lesstof niet beheerst. Ik sta er zeker vor open om er wat over te leren, maar dat gaat me deze opleiding niet meer lukken denk ik.
Als je twee gelijke getallen door elkaar deelt, krijg je 1 als uitkomst. Daarom wordt 1 als waarde in dit geval gebruikt.quote:
[..]
Super, bedankt! Ik snapte niet helemaal dat het te maken het dat het op 1 kan uitkomen of kan afwijken van 1. De getallen liggen heel erg bij elkaar of ik nou equal of unequal kies, maar je keuze moet natuurlijk worden onderbouwd. Ik kan er in ieder geval weer mee verder.
En ik begrijp je advies, wiskunde is gewoon persoonlijk een heikel punt. M'n studie besteed er ook maar 1 vak aan in 4 jaar tijd, met een ingehuurde docent die de lesstof niet beheerst. Ik sta er zeker vor open om er wat over te leren, maar dat gaat me deze opleiding niet meer lukken denk ik.
Ik denk dat elke opleiding op wel een aantal punten te kort schiet, en daarom denk ik dat je ook moet kijken of je buiten je opleiding nog nieuwe zaken kunt leren. Op sites als udemy of coursera worden uitgebreide cursussen voor veel verschillende vakgebieden aangeboden waarmee je vaak met bijna nul voorkennis je nieuwe vaardigheden kunt ontwikkelen.
Hello! kan iemand mij misschien helpen? Het is een hele simpele vraag, maar ik kom er echt niet uit...
Ik heb een moderatie, en twee hypothesen.
Hypothese 1 is X --> Y effect
en Hypothese 2 is X + MOD --> Y
Nu zegt de docent dat ik meervoudige regressieanalyse moet doen in de volgende stappen:
1. controlevariabelen
2. hoofdeffecten (X en MOD)
3. multiplicatieve interactieterm (X * MOD)
maar in deze analyse kan ik toch helemaal niet hypothese 1 beantwoorden? Want dat moet toch gewoon met enkelvoudige regressieanalyse?
Weet iemand dit? Ik ben je eeuwig dankbaar.
Ik heb een moderatie, en twee hypothesen.
Hypothese 1 is X --> Y effect
en Hypothese 2 is X + MOD --> Y
Nu zegt de docent dat ik meervoudige regressieanalyse moet doen in de volgende stappen:
1. controlevariabelen
2. hoofdeffecten (X en MOD)
3. multiplicatieve interactieterm (X * MOD)
maar in deze analyse kan ik toch helemaal niet hypothese 1 beantwoorden? Want dat moet toch gewoon met enkelvoudige regressieanalyse?
Weet iemand dit? Ik ben je eeuwig dankbaar.
Je gooit alles in één (meervoudige) regressieanalyse, en daarmee toets je dan beide hypothesen. Dan controleer je dus voor MOD en de interactieterm (dat wil zeggen dat wanneer die variabelen constant blijven, er een effect zou kunnen zijn).quote:
Hello! kan iemand mij misschien helpen? Het is een hele simpele vraag, maar ik kom er echt niet uit...
Ik heb een moderatie, en twee hypothesen.
Hypothese 1 is X --> Y effect
en Hypothese 2 is X + MOD --> Y
Nu zegt de docent dat ik meervoudige regressieanalyse moet doen in de volgende stappen:
1. controlevariabelen
2. hoofdeffecten (X en MOD)
3. multiplicatieve interactieterm (X * MOD)
maar in deze analyse kan ik toch helemaal niet hypothese 1 beantwoorden? Want dat moet toch gewoon met enkelvoudige regressieanalyse?
Weet iemand dit? Ik ben je eeuwig dankbaar.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Beetje verwarrend om je hoofdeffect Mod te noemenquote:
[..]
Je gooit alles in één (meervoudige) regressieanalyse, en daarmee toets je dan beide hypothesen. Dan controleer je dus voor MOD en de interactieterm (dat wil zeggen dat wanneer die variabelen constant blijven, er een effect zou kunnen zijn).
Is het mogelijk om alleen met percentages te kijken of een verschil significant is?
Ik ben momenteel bezig met mijn afstudeeronderzoek over het hoge retouraantal van jeans.
Nu heb ik de volgende gegevens voor de modellen;
bootcut jeans 64,20%
boyfriend jeans 71,66%
flared jeans 68,73
regular jeans 70,84%
slim fit jeans 66,74%
skinny fit jeans 68,89%
straight jeans 67,15%
Ze streven naar een retourpercentage van 65%(dit geld voor alle modellen), dus ik dacht dat ik het ten opzichte van die 65% zou kunnen bekijken maar het is me nog niet gelukt..
Ik heb zelf nog nooit iets met spss gedaan dus ik kom er totaal niet uit. De een zegt dat ik meer waardes moet hebben en de ander zegt dat het wel mogelijk moet zijn maar weet niet hoe..
alvast bedankt!
Ik ben momenteel bezig met mijn afstudeeronderzoek over het hoge retouraantal van jeans.
Nu heb ik de volgende gegevens voor de modellen;
bootcut jeans 64,20%
boyfriend jeans 71,66%
flared jeans 68,73
regular jeans 70,84%
slim fit jeans 66,74%
skinny fit jeans 68,89%
straight jeans 67,15%
Ze streven naar een retourpercentage van 65%(dit geld voor alle modellen), dus ik dacht dat ik het ten opzichte van die 65% zou kunnen bekijken maar het is me nog niet gelukt..
Ik heb zelf nog nooit iets met spss gedaan dus ik kom er totaal niet uit. De een zegt dat ik meer waardes moet hebben en de ander zegt dat het wel mogelijk moet zijn maar weet niet hoe..
alvast bedankt!
Ik denk dat dit niet kan. Je zou wel een t-toets kunnen doen waarbij je naar een distributie kijkt van een score en dat toetst tegen een vaste waarde (one sample t-test), maar in dit geval is geen sprake van een distributie van scores over een range. Het is namelijk een percentage en dat is een vaste waarde.quote:
Is het mogelijk om alleen met percentages te kijken of een verschil significant is?
Ik ben momenteel bezig met mijn afstudeeronderzoek over het hoge retouraantal van jeans.
Nu heb ik de volgende gegevens voor de modellen;
bootcut jeans 64,20%
boyfriend jeans 71,66%
flared jeans 68,73
regular jeans 70,84%
slim fit jeans 66,74%
skinny fit jeans 68,89%
straight jeans 67,15%
Ze streven naar een retourpercentage van 65%(dit geld voor alle modellen), dus ik dacht dat ik het ten opzichte van die 65% zou kunnen bekijken maar het is me nog niet gelukt..
Ik heb zelf nog nooit iets met spss gedaan dus ik kom er totaal niet uit. De een zegt dat ik meer waardes moet hebben en de ander zegt dat het wel mogelijk moet zijn maar weet niet hoe..
alvast bedankt!
Bovendien, het is op het eerste aanzicht goed te zien welke broek het meeste afwijkt dus waarom moeilijk doen als het makkelijk kan.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Het is hier vast al eens voorbij gekomen maar ik kon het zo snel niet vinden. Voor mijn afstudeerscriptie heb ik een enquête afgenomen over het gebruik van (kennis)netwerken bij bedrijven. Een van de vragen betreft het nut van samenwerken met lokale, regionale, nationale, Duitse en overige buitenlandse partners (5-likert scale). Nu wil ik Duitse en Overige buitenlandse partners samenvoegen tot 1 variabel zodat ik 'Internationale' partners als geheel kan meten. Hoe kan ik dit het beste doen? Kan ik 'gewoon' de mean van beide variabelen gebruiken om een nieuw variabel te maken?
Hetzelfde geldt voor een andere vraag in mijn enquête waar ik 4 variabelen wil samenvoegen die hetzelfde 'gevoel' meten (7-likert scale). Het liefst wil ik ze ordinal houden en niet dichotoom (middels bijv. median split).
Hetzelfde geldt voor een andere vraag in mijn enquête waar ik 4 variabelen wil samenvoegen die hetzelfde 'gevoel' meten (7-likert scale). Het liefst wil ik ze ordinal houden en niet dichotoom (middels bijv. median split).
quote:
Het is hier vast al eens voorbij gekomen maar ik kon het zo snel niet vinden. Voor mijn afstudeerscriptie heb ik een enquête afgenomen over het gebruik van (kennis)netwerken bij bedrijven. Een van de vragen betreft het nut van samenwerken met lokale, regionale, nationale, Duitse en overige buitenlandse partners (5-likert scale). Nu wil ik Duitse en Overige buitenlandse partners samenvoegen tot 1 variabel zodat ik 'Internationale' partners als geheel kan meten. Hoe kan ik dit het beste doen? Kan ik 'gewoon' de mean van beide variabelen gebruiken om een nieuw variabel te maken?
Hetzelfde geldt voor een andere vraag in mijn enquête waar ik 4 variabelen wil samenvoegen die hetzelfde 'gevoel' meten (7-likert scale). Het liefst wil ik ze ordinal houden en niet dichotoom (middels bijv. median split).
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.Welke van deze 2 is homogeen en welke is heterogeen? Hoe kun je dat zien/uitleggen?
Ik weet wel dat de onderste significant is en de bovenste niet, maar ik weet niet hoe ik het moet interpreteren.
Ik zou gokken dat de bovenste homogeen (gelijke varianties) is.
quote:The first section of the Independent Samples Test output box gives you the resultsSPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.Welke van deze 2 is homogeen en welke is heterogeen? Hoe kun je dat zien/uitleggen?
Ik weet wel dat de onderste significant is en de bovenste niet, maar ik weet niet hoe ik het moet interpreteren.
Ik zou gokken dat de bovenste homogeen (gelijke varianties) is.
of Levene’s test for equality of variances. This tests whether the variance (variation)
of scores for the two groups (males and females) is the same. The outcome of
this test determines which of the t-values that SPSS provides is the correct one
for you to use.
• If your Sig. value is larger than .05 (e.g. .07, .10), you should use the first
line in the table, which refers to Equal variances assumed.
• If the significance level of Levene’s test is p=.05 or less (e.g. .01, .001), this
means that the variances for the two groups (males/females) are not the same.
Therefore your data violate the assumption of equal variance. Don’t panic—
SPSS is very kind and provides you with an alternative t-value which
compensates for the fact that your variances are not the same. You should
use the information in the second line of the t-test table, which refers to Equal
variances not assumed.
uit Pallant.'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Thnxquote:
[..]
The first section of the Independent Samples Test output box gives you the results
of Levene’s test for equality of variances. This tests whether the variance (variation)
of scores for the two groups (males and females) is the same. The outcome of
this test determines which of the t-values that SPSS provides is the correct one
for you to use.
• If your Sig. value is larger than .05 (e.g. .07, .10), you should use the first
line in the table, which refers to Equal variances assumed.
• If the significance level of Levene’s test is p=.05 or less (e.g. .01, .001), this
means that the variances for the two groups (males/females) are not the same.
Therefore your data violate the assumption of equal variance. Don’t panic—
SPSS is very kind and provides you with an alternative t-value which
compensates for the fact that your variances are not the same. You should
use the information in the second line of the t-test table, which refers to Equal
variances not assumed.
uit Pallant.
Hallo,
Ik ben momenteel bezig met een analyse in SPSS.
Even kort geschetst:
- ik wil 2 verschillende generaties met elkaar vergelijken in bijvoorbeeld communicatie (schaalvariabele), familiewaarden (schaalvariabele) enz.
Hiervoor gebruik ik de independent sample t-test en het uitvoeren van deze test is ook geen probleem.
Graag zou ik ook een test kunnen uitvoeren waar ik beide generaties met elkaar vergelijk, maar waar nog eens een verschil in bedrijfsgroottes (klein, middelgroot & groot) gemaakt wordt.
Is dit mogelijk? Indien ja, hoe pak ik dit het best aan?
Alvast bedankt!
Ik ben momenteel bezig met een analyse in SPSS.
Even kort geschetst:
- ik wil 2 verschillende generaties met elkaar vergelijken in bijvoorbeeld communicatie (schaalvariabele), familiewaarden (schaalvariabele) enz.
Hiervoor gebruik ik de independent sample t-test en het uitvoeren van deze test is ook geen probleem.
Graag zou ik ook een test kunnen uitvoeren waar ik beide generaties met elkaar vergelijk, maar waar nog eens een verschil in bedrijfsgroottes (klein, middelgroot & groot) gemaakt wordt.
Is dit mogelijk? Indien ja, hoe pak ik dit het best aan?
Alvast bedankt!

Dringend hulp gezocht!
Ik heb een probleem in SPSS 24. Nadat ik al maanden hetzelfde datafile gebruik en iedere dag open, kreeg ik gister opeens de volgende foutmelding:
The document is already in use by another user or process. If you make changes to the document they may overwrite changes made by others or your changes may be overwritten by others
Kan iemand mij in Jip en Janneke taal uitleggen hoe ik dit op moet lossen?
Ik heb een probleem in SPSS 24. Nadat ik al maanden hetzelfde datafile gebruik en iedere dag open, kreeg ik gister opeens de volgende foutmelding:
The document is already in use by another user or process. If you make changes to the document they may overwrite changes made by others or your changes may be overwritten by others
Kan iemand mij in Jip en Janneke taal uitleggen hoe ik dit op moet lossen?

Kan je het bestand wel geopend krijgen? Als dat het geval is, dan kan je gewoon een kopie maken en daarmee verder gaan.Sowieso is het zaak om altijd te back-uppen op diverse locaties (zowel fysiek als in de cloud).quote:Op zondag 12 mei 2019 11:50 schreef nikkistork het volgende:
Dringend hulp gezocht!
Ik heb een probleem in SPSS 24. Nadat ik al maanden hetzelfde datafile gebruik en iedere dag open, kreeg ik gister opeens de volgende foutmelding:
The document is already in use by another user or process. If you make changes to the document they may overwrite changes made by others or your changes may be overwritten by others
Kan iemand mij in Jip en Janneke taal uitleggen hoe ik dit op moet lossen?
[ afbeelding ]
Hoi, momenteel ben ik bezig met mijn scriptie en probeer ik een regressiemodel op te stellen met meervoudige lineaire regressie. Stel dat ik er voor kies om de variabelen die niet significant zijn, alsnog mee te nemen in mijn regressiemodel. Dit omdat de praktische essentie van bepaalde variabelen zwaarder wegen dan de theoretische significantie. (In de praktijk zijn deze variabelen dusdanig belangrijk dat ze meegenomen moeten worden). Ik heb begrepen dat de coëfficiënten van het model dan niet meer te interpreteren zijn. Maar geldt dit voor alle coëfficiënten, of alleen de coëfficiënten van de variabelen die niet significant zijn? Ook als er sprake is van multicollineariteit, dit betekent dat de geschatte coëfficiënten minder betrouwbaar zijn, maar geldt dit voor alle coëfficiënten of alleen de coëfficiënten van de variabelen die multicollineariteit veroorzaken? En hoe zit het met de determinatiecoëfficiënt, kan ik deze nog steeds gebruiken om te kijken hoe goed het model is? Of wordt deze ook beïnvloed door de insignificante variabelen? Ik hoop dat iemand mij nog even kan helpen met de laatste loodjes van mijn scriptie.
Alvast bedankt!
Alvast bedankt!
| Forum Opties | |
|---|---|
| Forumhop: | |
| Hop naar: | |