COR Corona COVID-19 forum
Alles over het corona / COVID-19 virus.



Precies, en het dus publiceren tot 2 cijfers achter de komma, omdat (zijn woorden) 'dat beter onderscheidend is'.
Hij moet gewoon zeggen wat ze weten, dat de R tussen x en y zit, en boven, onder of rond de 1 zit.
Hij moet gewoon zeggen wat ze weten, dat de R tussen x en y zit, en boven, onder of rond de 1 zit.
Omdat je meer data hebt en dus preciezer kunt schatten? Het andere alternatief is te wachten tot je vrijwel alle data hebt en pas na maanden kunt rapporteren.quote:Op woensdag 17 maart 2021 12:24 schreef George_of_the_Jungle het volgende:
[..]
Dat zou kunnen ja, maar waarom achteraf het reproductiegetal in de data voor het dashboard aanpassen?
Ik snap dit niet. De R wordt gewoon voor iedere dag geschat. Niet iedere dag gerapporteerd, nee.quote:En ze houden een reproductie tijd van 4 dagen aan, maar ze updaten de geschatte R twee keer per week, dus eigenlijk update je je schatting voordat de vorige echt effect had. Ik zie ook niet zo het nut ervan in om 2 keer per week zo'n schatting te updaten.
Zo zie ik dat niet.quote:Dat wekt, alweer, het vermoeden dat men een precies beeld heeft dan de R (terwijl dat niet zo is)
Met alle respect, het gaat nog niet eens om 0,01% van de bevolking die a) dit soort marginale wijzigingen opvalt; en b) hier ook nog aanstoot aan zou nemen.quote:door het telkens te veranderen knaagt het aan het vertrouwen bij mensen (zie dit topic bijv), en door telkens een veranderende geschatte R gooi je olie op het vuur voor mensen die maatregelen graag aangepast zien.
Je kunt moeilijk vooraf al bepalen wat het reproductiegetal is. En voor het naar voren kijken hebben ze dus de modelleringsunit die scenario's schetst.quote:En het zijn ook nog een schattingen achteraf, terwijl ze vaak gebruikt worden om vooruit beleid te bepalen.
Sorry, maar dit is gewoon onzin. Hoe vaak je het ook blijft roepen.quote:
Maar Jaap moet daarin duidelijk zijn, gewoon zeggen: Sorry we hebben eigenlijk helemaal niet zo een goed beeld wat dit getal is,
We gaan het eind maart zien, het model voorspeelde 1500 IC gevallen met de huidige beperkingen, voorlopig zitten we op 568 dus dan zouden er 1000 bij moeten komen in 13 dagen, laten we wel afspreken dat als dit niet gebeurt dat we dan maar stoppen met het model?quote:
[..]
Sorry, maar dit is gewoon onzin. Hoe vaak je het ook blijft roepen.
🕰️₿🕰️₿🕰️₿🕰️₿🕰️₿🕰️ TikTok next Block
Prima joh.quote:
[..]
We gaan het eind maart zien, het model voorspeelde 1500 IC gevallen met de huidige beperkingen, voorlopig zitten we op 568 dus dan zouden er 1000 bij moeten komen in 13 dagen, laten we wel afspreken dat als dit niet gebeurt dat we dan maar stoppen met het model?
Als men zegt: "De R 1.14", dan wekt dat toch het idee dat men heel precies weet wat de R is? Als men 4 dagen later zegt: "Nu is de R 0.98", dan denkt men dus dat de R in 4 dagen flink gekelderd is, maar in feite zitten een of beide schattingen er (flink) naast. Als men zegt "De R zit tussen de 0.9 en 1.2", en 4 dagen later zegt men hetzelfde, dan is dat hoogstwaarschijnlijk in beide gevallen correct, en het is een meer accurate weergave van wat men eigenlijk weet.quote:
[..]
Omdat je meer data hebt en dus preciezer kunt schatten? Het andere alternatief is te wachten tot je vrijwel alle data hebt en pas na maanden kunt rapporteren.
[..]
Ik snap dit niet. De R wordt gewoon voor iedere dag geschat. Niet iedere dag gerapporteerd, nee.
[..]
Zo zie ik dat niet.
[..]
Met alle respect, het gaat nog niet eens om 0,01% van de bevolking die a) dit soort marginale wijzigingen opvalt; en b) hier ook nog aanstoot aan zou nemen.
[..]
Je kunt moeilijk vooraf al bepalen wat het reproductiegetal is. En voor het naar voren kijken hebben ze dus de modelleringsunit die scenario's schetst.
Het is niet zo dat men er aanstoot aan neemt, het is meer dat het ogenschijnlijk kwispelturige gedrag van het RIVM, OMT en overheid, gebaseerd op dit soort steeds weer wisselende cijfers van het RIVM leidt tot ondermijning van het vertrouwen in de overheid en de maatregelen die genomen worden.
Een correctere schatting van de R leidt hoogstwaarschijnlijk tot een geschatte R met een ruimere onzekerheid eromheen. Dat ligt gewoon aan het feit dat het heel moeilijk is om de R te schatten. Dat een methode een precise schatting produceert, wilt nog niet zeggen dat die schatting goed is.
Ze schatten inderdaad de R ook elke dag, wat ook niet echt slim is imo. In weekende wordt er minder getest, op basis van hun methode zou de R van zaterdag en zondag bijvoorbeeld altijd lager zijn dan die van een vrijdag. Dat is gewoon geen goede weergave van water werkelijk gebeurd, en dat is wat de gerapporteerde R zou moeten weergeven.
Waarom een schatting achteraf corrigeren als er toch niks meer mee gedaan wordt? Je wilt zo'n achteraf aangepaste schatting zeker niet gebruiken om te kijken hoe goed je schatting op dat moment was, en het wordt ook niet meer gebruikt voor beleid, het vertroebelt alleen je beeld wanneer je gaat kijken naar uitgevoerd beleid op een bepaald moment. Dan wil je ook de schatting van de R op dat moment hebben, en niet een R die achteraf nog eens is aangepast omdat er achteraf meer data beschikbaar is gekomen.
Het reproductiegetal is niet statisch, hè. Op 15 december ging de lockdown in, dus zo vreemd is dat het toch niet dat deze daags voor de lockdown hoger was dan daarna?quote:
Als men zegt: "De R 1.14", dan wekt dat toch het idee dat men heel precies weet wat de R is? Als men 4 dagen later zegt: "Nu is de R 0.98", dan denkt men dus dat de R in 4 dagen flink gekelderd is, maar in feite zitten een of beide schattingen er (flink) naast.
Sorry dat ik het zeg, maar dit soort uitspraken doen mij vermoeden dat je geen enkel idee hebt hoe een reproductiegetal berekend wordt en hoe je kunt corrigeren voor de zaken die je nu noemt.quote:
Ze schatten inderdaad de R ook elke dag, wat ook niet echt slim is imo. In weekende wordt er minder getest, op basis van hun methode zou de R van zaterdag en zondag bijvoorbeeld altijd lager zijn dan die van een vrijdag. Dat is gewoon geen goede weergave van water werkelijk gebeurd, en dat is wat de gerapporteerde R zou moeten weergeven.
... Manmanmanmanmanmanmanman.quote:
[..]
Het reproductiegetal is niet statisch, hè. Op 15 december ging de lockdown in, dus zo vreemd is dat het toch niet dat deze daags voor de lockdown hoger was dan daarna?
[..]
Sorry dat ik het zeg, maar dit soort uitspraken doen mij vermoeden dat je geen enkel idee hebt hoe een reproductiegetal berekend wordt en hoe je kunt corrigeren voor de zaken die je nu noemt.
"Het enkele feit dat de gewasbeschermingsmiddelen zijn toegelaten, geeft in ieder geval geen garantie op het ontbreken van met name een uitgesteld schadelijk effect op de gezondheid van mensen."
Ik was inderdaad even vergeten dat je wel ongefundeerde kritiek op het RIVM mocht hebben, maar niet op FOK!kers.
Ik werkte al lang voor de pandemie regelmatig met het detecteren en schatten van toename en afname in populatie groottes en dichtheden. Dat was dan wel met dieren, maar de onderliggen principes zijn niet veel anders.quote:
[..]
Het reproductiegetal is niet statisch, hè. Op 15 december ging de lockdown in, dus zo vreemd is dat het toch niet dat deze daags voor de lockdown hoger was dan daarna?
[..]
Sorry dat ik het zeg, maar dit soort uitspraken doen mij vermoeden dat je geen enkel idee hebt hoe een reproductiegetal berekend wordt en hoe je kunt corrigeren voor de zaken die je nu noemt.
Dus, of ik leg het niet erg goed uit, of jij snapt het niet zo goed. Laten we het voor de goede orde maar op het eerste houden dan.
Tja, dat zal vast, maar een uitspraak als "op basis van hun methode zou de R van zaterdag en zondag bijvoorbeeld altijd lager zijn dan die van een vrijdag" getuigt niet bepaald van inzicht in de methodiek achter de berekening.quote:
[..]
Ik werkte al lang voor de pandemie regelmatig met het detecteren en schatten van toename en afname in populatie groottes en dichtheden. Dat was dan wel met dieren, maar de onderliggen principes zijn niet veel anders.
Dus, of ik leg het niet erg goed uit, of jij snapt het niet zo goed. Laten we het voor de goede orde maar op het eerste houden dan.
Het reproductiegetal van de afgelopen weekenden:
Vrijdagen: 0.99, 1.14, 1.04 en 1.04 (5, 12, 19 en 26 februari).
Zaterdagen: 1.02, 1.16, 1.04 en 1.04 (6, 13, 20 en 27 februari).
Zondagen: 1.03, 1.15, 1.00 en 1.05 (7, 14, 21 en 28 februari).
Kortom, hoezo zouden zaterdagen en zondagen lager moeten zijn?
Hier mijn poging het reproductiegetal laagdrempelig te reproduceren:
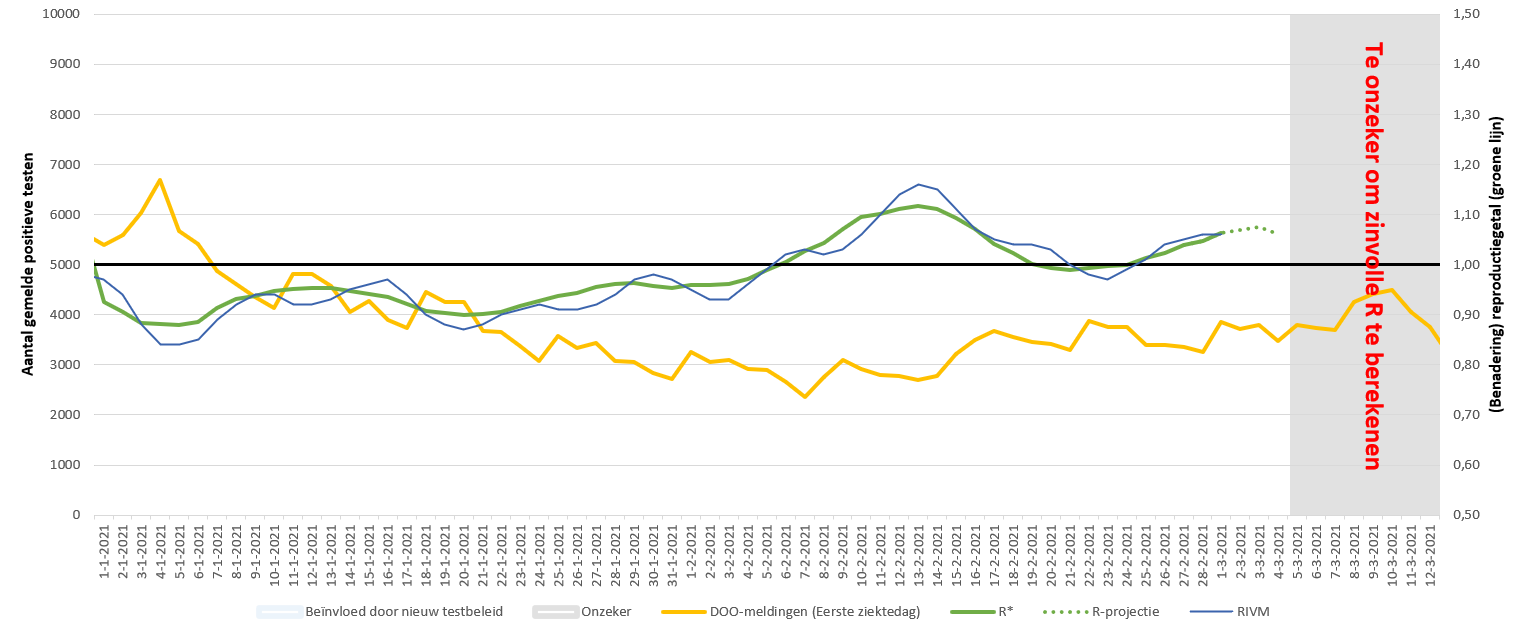
Doordat ik een lopend gemiddelde neem heb je iets minder fluctuaties, maar het punt is: ook ik heb geen last van de dagelijkse verschillen. Omdat mijn methode daar niet van afhankelijk is. Net als de methode die het RIVM niet gevoelig is voor de dagelijkse fluctuaties zoals jij ze beschrijft.
Bij wijze van spreken. Als je dagelijks een R gaat berekenen en daarbij de cijfers van nu en 4 dagen later neemt, dan krijg je dezelfde golf beweging die je ook doordeweeks ziet, en waarom men vooral ook kijkt naar 7-daagse gemiddeldes. Ik had de cijfers niet bij de hand, maar het ging er vooral om dat je daarmee de ruis van het wekelijkse patroon mogelijk door laat werken in de berekening van je R.quote:
[..]
Tja, dat zal vast, maar een uitspraak als "op basis van hun methode zou de R van zaterdag en zondag bijvoorbeeld altijd lager zijn dan die van een vrijdag" getuigt niet bepaald van inzicht in de methodiek achter de berekening.
Het reproductiegetal van de afgelopen weekenden:
Vrijdagen: 0.99, 1.14, 1.04 en 1.04 (5, 12, 19 en 26 februari).
Zaterdagen: 1.02, 1.16, 1.04 en 1.04 (6, 13, 20 en 27 februari).
Zondagen: 1.03, 1.15, 1.00 en 1.05 (7, 14, 21 en 28 februari).
Kortom, hoezo zouden zaterdagen en zondagen lager moeten zijn?
Hier mijn poging het reproductiegetal laagdrempelig te reproduceren:
[ afbeelding ]
Doordat ik een lopend gemiddelde neem heb je iets minder fluctuaties, maar het punt is: ook ik heb geen last van de dagelijkse verschillen. Omdat mijn methode daar niet van afhankelijk is. Net als de methode die het RIVM niet gevoelig is voor de dagelijkse fluctuaties zoals jij ze beschrijft.
En een R die 4% daalt van 20 op 21 februari, dat kan eigenlijk niet, dat is een heel groot verschil in populatiegroei, dan is je data niet goed, en dat laat duidelijk zien dat de onzekerheid rond de schattingen veel groter dient te zijn.
Zoals het RIVM hun methode beschrijft als zei een korte beschrijving van hun methode geven, zijn ze daar dus wel van afhankelijk. En een sprong van 4% (en een van 3%) op een dag laat ook zien dat hun methode schijnbaar gevoelig is voor dagelijkse veranderingen.
Het heeft ook helemaal geen zin om dagelijks een R te schatten:
1) De onzekerheid rond je schattingen is dermate groot (of zou dat moeten zijn) dat de schatting van de volgende dag altijd in de onzekerheid zal vallen.
2) De R zal van dag op dag niet dramatisch veranderen
3) Maatregelen worden niet dagelijks aangepast
Je kunt wel een model bouwen dat voor elke dag een schatting produceert, maar dat wilt niet zeggen dat dat een beter model zal zijn wat bijvoorbeeld elke week of elke twee weken een schatting produceert. En dan, precies wat jij ook doet, met gegevens werkt gemiddeld over een X-aantal dagen om erratic data te dempen (denk effecten van weekenden, feestdagen, sluiten testcentra vanwege ijzel/storm etc). Zo'n methode zou leiden tot meer accurate schattingen, je zou duidelijker effecten van maatregelen in een R kunnen zien (nu is het altijd: Het lijkt wel te dalen, maar we weten niet of het door de maatregelen komt, want x, y, z. Wacht gewoon tot je weet dat x, y en z geen rol meer spelen), en uiteindelijk zal daarmee meer support gekregen worden.
Een schatting is slechts zo goed als de onzekerheid van de schatting aangeeft, niet in hoeveel decimalen de schatting wordt gedaan, of hoe vaak een schatting wordt gedaan. En die onzekerheid bij het RIVM lijkt niet goed te worden berekend want die is te nauw (te zien aan dat de onzekerheid breedte van schattingen slechts enkele dagen later elkaar soms niet eens overlappen, terwijl er geen nieuwe maatregelen zijn), en ze zijn elke keer symmetrisch, wat niet logisch is.
Ik heb net even die paper proberen te lezen van Wielinga: https://royalsocietypublishing.org/doi/pdf/10.1098/rspb.2006.3754
Dit is kennelijk de wetenschappelijke versie van hoe ze het reproductiegetal meten, ik ben echter geen wetenschapper en snap nooit zo goed hoe ik die formules moet lezen (ik ben autodidact dus ken die noteringen niet).
Kan iemand mij vertellen of in deze methode ook immuniteit word meegerekend? Ik krijg heel erg het idee dat de methode die hier beschreven staat zich focussed op het begin van een pandemie en niet op een langdurige.
Dit is kennelijk de wetenschappelijke versie van hoe ze het reproductiegetal meten, ik ben echter geen wetenschapper en snap nooit zo goed hoe ik die formules moet lezen (ik ben autodidact dus ken die noteringen niet).
Kan iemand mij vertellen of in deze methode ook immuniteit word meegerekend? Ik krijg heel erg het idee dat de methode die hier beschreven staat zich focussed op het begin van een pandemie en niet op een langdurige.
🕰️₿🕰️₿🕰️₿🕰️₿🕰️₿🕰️ TikTok next Block
In mijn vakgebied heeft men het over density dependence of carrying capacity. Een populatie kan niet eeuwig exponentieel blijven groeien in een eindige omgeving, dus op een gegeven moment neemt de groei af, puur omdat veel resources al door anderen van de populatie bezet worden.
Datzelfde zou je moeten zien als een virus zich in een populatie verspreid. Immers, vroeg in de epidemie zal elk ander mens wat een besmettelijk persoon tegenkomt vatbaar zijn om besmet te raken, maar na verloop van tijd is dat niet meer zo, dan komt een besmettelijk persoon steeds vaker iemand tegen die al immuun is, en daardoor zal de R zakken. Het idee van groepsimmuniteit.
In Wallinga & Lipsitch 2006 kijken ze vooral naar hoe de distributie van de generatie-interval de groei van een populatie beinvloedt, en dan met name in het begin van een epidemie, wanneer de 'populatie' exponentieel groeit. Men houdt er dus niet expliciet rekening mee in de paper. Maar het R package waar naar verwezen wordt, EpiEstim, heeft er wel een functie voor
Het RIVM verwijst naar beide packages (EpiEstim en R0). Voor 'code beschikbaar' linken ze naar de download pagina voor EpiEstim, en voor 'R-package beschikbaar', linken ze naar de paper die het package R0 beschrijft.
Maar het is dus niet duidelijk, althans niet voor mij, hoe ze precies de R berekenen. Het nogal makkelijk om naar een package te verwijzen, dat is in feite gewoon een bundel functies om de R te berekenen.
Het package EpiEstim heeft wel een functie 'wallinga_teunis', met de beschrijving:
Waar ook code en data van is. Alleen, in de eerder gelinkte video heeft Wallinga het over gemiddeld 4 dagen tussen ziek worden en iemand besmetten. In deze paper hebben ze het over 6.4 dagen tussen besmet worden en symptomen vertonen, dat is toch weer iets anders.
En het rivm gebruikt niet alleen maar 4 dagen, ze gebruiken een distributie rond die 4 dagen volgens mij.
Maar nu ff koken en chillen.
Datzelfde zou je moeten zien als een virus zich in een populatie verspreid. Immers, vroeg in de epidemie zal elk ander mens wat een besmettelijk persoon tegenkomt vatbaar zijn om besmet te raken, maar na verloop van tijd is dat niet meer zo, dan komt een besmettelijk persoon steeds vaker iemand tegen die al immuun is, en daardoor zal de R zakken. Het idee van groepsimmuniteit.
In Wallinga & Lipsitch 2006 kijken ze vooral naar hoe de distributie van de generatie-interval de groei van een populatie beinvloedt, en dan met name in het begin van een epidemie, wanneer de 'populatie' exponentieel groeit. Men houdt er dus niet expliciet rekening mee in de paper. Maar het R package waar naar verwezen wordt, EpiEstim, heeft er wel een functie voor
In Wallinga & Teunis 2004 wordt er ook naar het verloop over tijd gekeken, en dan wordt er wel met een 'density dependence' effect rekening gehouden, deze methode is ook opgenomen in het R0 package.quote:overall_infectivity computes the overall infectivity due to previously infected individuals.
Het RIVM verwijst naar beide packages (EpiEstim en R0). Voor 'code beschikbaar' linken ze naar de download pagina voor EpiEstim, en voor 'R-package beschikbaar', linken ze naar de paper die het package R0 beschrijft.
Maar het is dus niet duidelijk, althans niet voor mij, hoe ze precies de R berekenen. Het nogal makkelijk om naar een package te verwijzen, dat is in feite gewoon een bundel functies om de R te berekenen.
Het package EpiEstim heeft wel een functie 'wallinga_teunis', met de beschrijving:
Ben nu wel benieuwd of ze 'gewoon' die functie eigenlijk hebben gebruikt. Dan zou je wel nog moeten uitvogelen welke interval distributie ze hebben gebruikt. Op de rivm pagina hebben ze ook een link naar een studie die keek naar de incubatie periode: https://www.eurosurveillance.org/content/10.2807/1560-7917.ES.2020.25.5.2000062quote:Description
wallinga_teunisestimates the case reproduction number of an epidemic, given the incidence timeseries and the serial interval distribution
Usage
wallinga_teunis(incid,method = c("non_parametric_si", "parametric_si"),config)
Arguments
incid One of the following
• Vector (or a dataframe with a column named ’incid’) of non-negative inte-gers containing an incidence time series. If the dataframe contains a columnincid$dates, this is used for plotting.incid$datesmust contains onlydates in a row.
• An object of classincidencemethodthe
method used to estimate R, one of "non_parametric_si", "parametric_si","uncertain_si", "si_from_data" or "si_from_sample"
configa list with the following elements:
• t_start: Vector of positive integers giving the starting times of each windowover which the reproduction number will be estimated. These must be inascending order, and so that for alli,t_start[i]<=t_end[i]. t_start[1]should be strictly after the first day with non null incidence.
• t_end: Vector of positive integers giving the ending times of each windowover which the reproduction number will be estimated. These must be inascending order, and so that for alli,t_start[i]<=t_end[i].
• method: One of "non_parametric_si" or "parametric_si" (see details).• mean_si: For method "parametric_si" ; positive real giving the mean serialinterval.
• std_si: For method "parametric_si" ; non negative real giving the standarddeviation of the serial interval.
• si_distr: For method "non_parametric_si" ; vector of probabilities givingthe discrete distribution of the serial interval, starting withsi_distr[1](probability that the serial interval is zero), which should be zero.
• n_sim: A positive integer giving the number of simulated epidemic treesused for computation of the confidence intervals of the case reproductionnumber (see details).
Details
Estimates of the case reproduction number for an epidemic over predefined time windows can beobtained, for a given discrete distribution of the serial interval, as proposed by Wallinga and Teunis(AJE, 2004). Confidence intervals are obtained by simulating a number (config$n_sim) of possibletransmission trees (only done if config$n_sim > 0).
The methods vary in the way the serial interval distribution is specified.
———————–method "non_parametric_si"———————–
The discrete distribution of the serial interval is directly specified in the argumentconfig$si_distr.
———————–method "parametric_si"———————–
The mean and standard deviation of the continuous distribution of the serial interval are given in theargumentsconfig$mean_siandconfig$std_si. The discrete distribution of the serial interval isderived automatically usingdiscr_si.
Valuea
list with components:
• R: a dataframe containing: the times of start and end of each time window considered ; theestimated mean, std, and 0.025 and 0.975 quantiles of the reproduction number for each timewindow.
• si_distr: a vector containing the discrete serial interval distribution used for estimation
• SI.Moments: a vector containing the mean and std of the discrete serial interval distribution(s)used for estimation
• I: the time series of total incidence• I_local: the time series of incidence of local cases (so thatI_local + I_imported = I)
• I_imported: the time series of incidence of imported cases (so thatI_local + I_imported =I)
• dates: a vector of dates corresponding to the incidence time serie
Waar ook code en data van is. Alleen, in de eerder gelinkte video heeft Wallinga het over gemiddeld 4 dagen tussen ziek worden en iemand besmetten. In deze paper hebben ze het over 6.4 dagen tussen besmet worden en symptomen vertonen, dat is toch weer iets anders.
En het rivm gebruikt niet alleen maar 4 dagen, ze gebruiken een distributie rond die 4 dagen volgens mij.
Maar nu ff koken en chillen.
Er zijn veel subtiliteiten bij het berekenen van een R-waarde. Wallinga kent deze wel, veel amateurepidemiologen (ook al kunnen ze erg goed met getallen omgaan) zullen wel het een en ander missen.
De R-waarde is makkelijk te interpreteren en te communiceren. Het is een erg nuttig getal als je effecten van maatregelen binnen modellen wil doorrekenen, en als je een epidemie analyseert aan de hand van genetische data (of heel effectieve contact tracing). Als je het verdere verloop van een epidemie wil voorspellen kunnen andere getallen nuttiger zijn, zoals de toename van het aantal besmettingen per week etc. Wat nog al eens gebeurt is dat deze werkelijke-tijd groeisnelheid wordt omgerekend (met behulp van een of ander model) tot een R waarde en vervolgens wordt die R-waarde gebruikt om een prognose te maken voor de toekomst door vanuit die R-waarde weer een groeisnelheid in kalendertijd te berekenen. Dat is allemaal niet zo efficient. Voordeel is wel dat het allemaal niet zo veel uitmaakt welk model je gebruikt omdat wat je nodig hebt voor je prognose eigenlijk vrij direct in de data zit.
De R-waarde die berekend wordt is niet de R0 waarde. Het doel is te zeggen hoeveel mensen iemand die nu besmet wordt zal besmetten gedurende de infectieuze periode. Zolang de omgeving niet extreem verandert binnen een paar weken is dit niet erg gevoelig voor hoeveel mensen al besmet is. Als nu 20% van de bevolking niet meer vatbaar is, dan zit dat impliciet in de besmettingscijfers en dus in de R-schatting en als dat over een maand 25% is maakt dat wel iets uit maar niet al te veel. Wat wel kan uitmaken is dat er variatie is vatbaarheid (sommige mensen worden ziek bij maar een minimaal contact, terwijl anderen (mogelijk door een immuunsysteem dat al op zijn hoede is) heel moeilijk te besmetten zijn. Dit is een punt wat Gabriela Gomes en haar groep heel duidelijk maakten in wat preprints. M.i, claimden zij veel te veel en het kost veel moeite om de papers gepubliceerd te krijgen. De observatie dat variatie in vatbaarheid belangrijk is, is een belangrijke en dat is iets wat niet meegenomen wordt in de modellen die Wallinga en anderen gebruiken.
Andere dingen die belangrijk zijn: Stel dat we een ideale ziekte hebben waar mensen precies vier dagen na besmetting zelf besmettelijk worden. Daarna voor 3 dagen gemiddeld 1 persoon per dag besmetten. Dan (na totaal 7 dagen dus) vertonen ze symptomen en isoleren zich goed. Dan is de R waarde 3, de tijd tussen besmetting en vertonen van symptomen 7 dagen, maar de "gemiddelde leeftijd van een infector op het moment er iemand besmet wordt" is 5.5 dagen. Er is nog meer aan de hand, omdat de epidemie groeit is het tijdens de groeifase niet zo dat als je een willekeurige besmetting waarneemt en je kijkt naar hoe lang geleden de infectie van de "infector" plaats vond 5.5. dagen is. Dit heeft een beetje te maken met "size biasing": Als een gemiddelde vrouw in Nederland 1 dochter krijgt gedurende haar leven en ongeveer 25% van de vrouwen nul dochters, dan zul je toch geen vrouw op straat vinden waarvan de moeder nul dochters heeft.
Twee epidemiologen die ik vrij goed ken (en met wie ik gewerkt heb en nog steeds werk) Tom Britton en Gianpaolo Scalia-Tomba hebben hier wel een leuk artikel over geschreven: https://royalsocietypublishing.org/doi/10.1098/rsif.2018.0670
Iets waar ik graag zelf nog eens naar ga kijken (en waar al iest aan gebeurd is, maar niet veel) is, wat er gebeurt als je ook weekeffecten ga meenemen in je besmettingsmodel. De besmettingskansen zijn niet hetzelfde op zondag als op dinsdag (en niet om 12 uur in de nacht of 12 uur in de middag) Als de gemiddelde infectieuze periode maar een dag of 4 is, dan maakt dit zeker wat uit. Maar echt begrijpen hoe het precies invloed heeft weet ik niet.
De R-waarde is makkelijk te interpreteren en te communiceren. Het is een erg nuttig getal als je effecten van maatregelen binnen modellen wil doorrekenen, en als je een epidemie analyseert aan de hand van genetische data (of heel effectieve contact tracing). Als je het verdere verloop van een epidemie wil voorspellen kunnen andere getallen nuttiger zijn, zoals de toename van het aantal besmettingen per week etc. Wat nog al eens gebeurt is dat deze werkelijke-tijd groeisnelheid wordt omgerekend (met behulp van een of ander model) tot een R waarde en vervolgens wordt die R-waarde gebruikt om een prognose te maken voor de toekomst door vanuit die R-waarde weer een groeisnelheid in kalendertijd te berekenen. Dat is allemaal niet zo efficient. Voordeel is wel dat het allemaal niet zo veel uitmaakt welk model je gebruikt omdat wat je nodig hebt voor je prognose eigenlijk vrij direct in de data zit.
De R-waarde die berekend wordt is niet de R0 waarde. Het doel is te zeggen hoeveel mensen iemand die nu besmet wordt zal besmetten gedurende de infectieuze periode. Zolang de omgeving niet extreem verandert binnen een paar weken is dit niet erg gevoelig voor hoeveel mensen al besmet is. Als nu 20% van de bevolking niet meer vatbaar is, dan zit dat impliciet in de besmettingscijfers en dus in de R-schatting en als dat over een maand 25% is maakt dat wel iets uit maar niet al te veel. Wat wel kan uitmaken is dat er variatie is vatbaarheid (sommige mensen worden ziek bij maar een minimaal contact, terwijl anderen (mogelijk door een immuunsysteem dat al op zijn hoede is) heel moeilijk te besmetten zijn. Dit is een punt wat Gabriela Gomes en haar groep heel duidelijk maakten in wat preprints. M.i, claimden zij veel te veel en het kost veel moeite om de papers gepubliceerd te krijgen. De observatie dat variatie in vatbaarheid belangrijk is, is een belangrijke en dat is iets wat niet meegenomen wordt in de modellen die Wallinga en anderen gebruiken.
Andere dingen die belangrijk zijn: Stel dat we een ideale ziekte hebben waar mensen precies vier dagen na besmetting zelf besmettelijk worden. Daarna voor 3 dagen gemiddeld 1 persoon per dag besmetten. Dan (na totaal 7 dagen dus) vertonen ze symptomen en isoleren zich goed. Dan is de R waarde 3, de tijd tussen besmetting en vertonen van symptomen 7 dagen, maar de "gemiddelde leeftijd van een infector op het moment er iemand besmet wordt" is 5.5 dagen. Er is nog meer aan de hand, omdat de epidemie groeit is het tijdens de groeifase niet zo dat als je een willekeurige besmetting waarneemt en je kijkt naar hoe lang geleden de infectie van de "infector" plaats vond 5.5. dagen is. Dit heeft een beetje te maken met "size biasing": Als een gemiddelde vrouw in Nederland 1 dochter krijgt gedurende haar leven en ongeveer 25% van de vrouwen nul dochters, dan zul je toch geen vrouw op straat vinden waarvan de moeder nul dochters heeft.
Twee epidemiologen die ik vrij goed ken (en met wie ik gewerkt heb en nog steeds werk) Tom Britton en Gianpaolo Scalia-Tomba hebben hier wel een leuk artikel over geschreven: https://royalsocietypublishing.org/doi/10.1098/rsif.2018.0670
Iets waar ik graag zelf nog eens naar ga kijken (en waar al iest aan gebeurd is, maar niet veel) is, wat er gebeurt als je ook weekeffecten ga meenemen in je besmettingsmodel. De besmettingskansen zijn niet hetzelfde op zondag als op dinsdag (en niet om 12 uur in de nacht of 12 uur in de middag) Als de gemiddelde infectieuze periode maar een dag of 4 is, dan maakt dit zeker wat uit. Maar echt begrijpen hoe het precies invloed heeft weet ik niet.
edit: sorry ondermijnde een nogal technische onbegrijpelijke doch interessante discussie. Iemand een samenvatting voor data-leken?
[ Bericht 93% gewijzigd door Saboo op 23-03-2021 21:39:58 ]
[ Bericht 93% gewijzigd door Saboo op 23-03-2021 21:39:58 ]
Thanks @DrParsifal! Timing van births gedurende een jaar, of bijvoorbeeld in een broedseizoen van vogels, en hoe dat effect heeft op de kans op voortplanting, of overleving jongen, en populatie is in populatiestudies wel wat aan gedaan, en misschien dat ideeen/theorien daaruit te vertalen zijn naar dat soort week-effecten?
https://www.rijksoverheid(...)el-21-03-2021-v1.pdf
Zie dia 13 en 14 voor de meest recente resultaten uit de kiemsurveillance. De datapunten volgen de schattingen behoorlijk nauwkeurig en dus kunnen we verwachten dat de R nog iets verder zal stijgen (en dat zonder eventuele versoepelingen).
Zie dia 13 en 14 voor de meest recente resultaten uit de kiemsurveillance. De datapunten volgen de schattingen behoorlijk nauwkeurig en dus kunnen we verwachten dat de R nog iets verder zal stijgen (en dat zonder eventuele versoepelingen).
Nog een week, kunnen we stoppen met hun achterlijke model.quote:
🕰️₿🕰️₿🕰️₿🕰️₿🕰️₿🕰️ TikTok next Block
Er zijn ook voor epidemieen wat modellen beschikbaar (niet veel), maar die gaan ofwel uit van grote aantallen (en worden deterministisch geanalyseerd) of hebben andere sterke aannames. Dit is een van de projecten die binnenkort voor mij (of een student) op de agenda staat. En ja ik kijk dan ook zeker naar de ecologie.quote:
Thanks @:DrParsifal! Timing van births gedurende een jaar, of bijvoorbeeld in een broedseizoen van vogels, en hoe dat effect heeft op de kans op voortplanting, of overleving jongen, en populatie is in populatiestudies wel wat aan gedaan, en misschien dat ideeen/theorien daaruit te vertalen zijn naar dat soort week-effecten?
Misschien dat de comadre database ook iets is om dan te checken, dat is een database met matrix populatiemodellen van dieren (en compadre voor planten): https://compadre-db.org/Data/Comadrequote:
[..]
Er zijn ook voor epidemieen wat modellen beschikbaar (niet veel), maar die gaan ofwel uit van grote aantallen (en worden deterministisch geanalyseerd) of hebben andere sterke aannames. Dit is een van de projecten die binnenkort voor mij (of een student) op de agenda staat. En ja ik kijk dan ook zeker naar de ecologie.
Ze brengen daar veel populatiestudies bij elkaar.
Succes in ieder geval!
Dinsdag 30 maart op 16:00 houdt het RIVM een live sessie over de rekenmodellen:
https://www.rivm.nl/nieuws/live-sessie-coronavirus-uitgelegd-rekenmodellen-en-virus
https://www.rivm.nl/nieuws/live-sessie-coronavirus-uitgelegd-rekenmodellen-en-virus
625quote:
[..]
Sorry, maar dit is gewoon onzin. Hoe vaak je het ook blijft roepen.
🕰️₿🕰️₿🕰️₿🕰️₿🕰️₿🕰️ TikTok next Block
Ik bedacht me gister iets en ik heb dit eigenlijk nooit zo gerealiseerd, maar feitelijk werk het feit van immuun zijn 2 kanten op:
-Je kunt niet meer besmetten
-Je kunt niet meer besmet worden
Ik heb nu even geen zin om een rekensom te maken, maar ik schat zo in dat het een enorm verschil maakt of dat getal dan 15% is of 30% je krijgt namelijk dan een soort van exponentieeel lagere kans om het virus door te geven dan wel besmet te raken.
Jullie idee?
-Je kunt niet meer besmetten
-Je kunt niet meer besmet worden
Ik heb nu even geen zin om een rekensom te maken, maar ik schat zo in dat het een enorm verschil maakt of dat getal dan 15% is of 30% je krijgt namelijk dan een soort van exponentieeel lagere kans om het virus door te geven dan wel besmet te raken.
Jullie idee?
🕰️₿🕰️₿🕰️₿🕰️₿🕰️₿🕰️ TikTok next Block
Hier is in de wiskundige modellen wel naar gekeken. Je kunt zoeken naar "leaky vaccine". Het maakt ook echt uit of 80% bescherming door een vaccin betekent dat 80% van de gevaccineerden helemaal beschermd wordt en de overige 20% helemaal niet, of dat voor iedereen geldt dat 80% van de contacten die normaal tot besmetting zouden leiden, dat nu niet doen.quote:
Ik bedacht me gister iets en ik heb dit eigenlijk nooit zo gerealiseerd, maar feitelijk werk het feit van immuun zijn 2 kanten op:
-Je kunt niet meer besmetten
-Je kunt niet meer besmet worden
Ik heb nu even geen zin om een rekensom te maken, maar ik schat zo in dat het een enorm verschil maakt of dat getal dan 15% is of 30% je krijgt namelijk dan een soort van exponentieeel lagere kans om het virus door te geven dan wel besmet te raken.
Jullie idee?
Verder is er waarschijnlijk wel een correlatie tussen hoe goed een vaccin beschermt tegen besmet worden en hoe besmettelijk je bent als je toch besmet wordt.Dit zijn trouwens dingen die vaak niet terugkomen in modellen die gebruikt worden. Het is een van de punten waarbij modelaannames best grote invloed hebben zonder dat dat beseft wordt.
Thx!quote:
[..]
Hier is in de wiskundige modellen wel naar gekeken. Je kunt zoeken naar "leaky vaccine". Het maakt ook echt uit of 80% bescherming door een vaccin betekent dat 80% van de gevaccineerden helemaal beschermd wordt en de overige 20% helemaal niet, of dat voor iedereen geldt dat 80% van de contacten die normaal tot besmetting zouden leiden, dat nu niet doen.
Verder is er waarschijnlijk wel een correlatie tussen hoe goed een vaccin beschermt tegen besmet worden en hoe besmettelijk je bent als je toch besmet wordt.Dit zijn trouwens dingen die vaak niet terugkomen in modellen die gebruikt worden. Het is een van de punten waarbij modelaannames best grote invloed hebben zonder dat dat beseft wordt.
🕰️₿🕰️₿🕰️₿🕰️₿🕰️₿🕰️ TikTok next Block
Vond het beetje tegenvallen, het was vrij high level en eigenlijk niets nieuws gehoort.quote:
Dinsdag 30 maart op 16:00 houdt het RIVM een live sessie over de rekenmodellen:
https://www.rivm.nl/nieuws/live-sessie-coronavirus-uitgelegd-rekenmodellen-en-virus
🕰️₿🕰️₿🕰️₿🕰️₿🕰️₿🕰️ TikTok next Block
Ik zat gister om die tijd in de auto, was eigenlijk wel benieuwd. Hopelijk morgen wat tijd om het online terug te kijken, maar ik moet niet teveel verwachten zo the horen.
https://www.ad.nl/binnenl(...)an-gedacht~a473b18e/quote:
[..]
Sorry, maar dit is gewoon onzin. Hoe vaak je het ook blijft roepen.
🕰️₿🕰️₿🕰️₿🕰️₿🕰️₿🕰️ TikTok next Block
Klopt. Kan je gewoon direct als percentage vanaf de R waarde aftrekken als je uit gaat van homogene populaties.quote:
Ik bedacht me gister iets en ik heb dit eigenlijk nooit zo gerealiseerd, maar feitelijk werk het feit van immuun zijn 2 kanten op:
-Je kunt niet meer besmetten
-Je kunt niet meer besmet worden
Ik heb nu even geen zin om een rekensom te maken, maar ik schat zo in dat het een enorm verschil maakt of dat getal dan 15% is of 30% je krijgt namelijk dan een soort van exponentieeel lagere kans om het virus door te geven dan wel besmet te raken.
Jullie idee?
Zijn ze net niet helemaal maar okay. De dodelijkheid en schadelijkheid nemen sneller af dan de transmissie wss omdat die twee factoren bij risicogroepen zijn geïsoleerd. Die worden als eerst gevaccineerd.
Dus de schadelijkheid van het virus zal sneller afnemen dan het aantal besmettingen.
En het idee leeft dat jongeren het meer doorgeven dan ouderen. Maar daar heb ik nooit echt bewijs voor gezien. Het klinkt enigszins plausibel maar hoeveel dat dan ook scheelt... Lijkt helemaal onduidelijk.
"Het enkele feit dat de gewasbeschermingsmiddelen zijn toegelaten, geeft in ieder geval geen garantie op het ontbreken van met name een uitgesteld schadelijk effect op de gezondheid van mensen."
quote:
[..]
Sorry, maar dit is gewoon onzin. Hoe vaak je het ook blijft roepen.
🕰️₿🕰️₿🕰️₿🕰️₿🕰️₿🕰️ TikTok next Block
Je hoeft me niet in iedere post te taggen waarin je je gebrek aan statistische kennis etaleert.
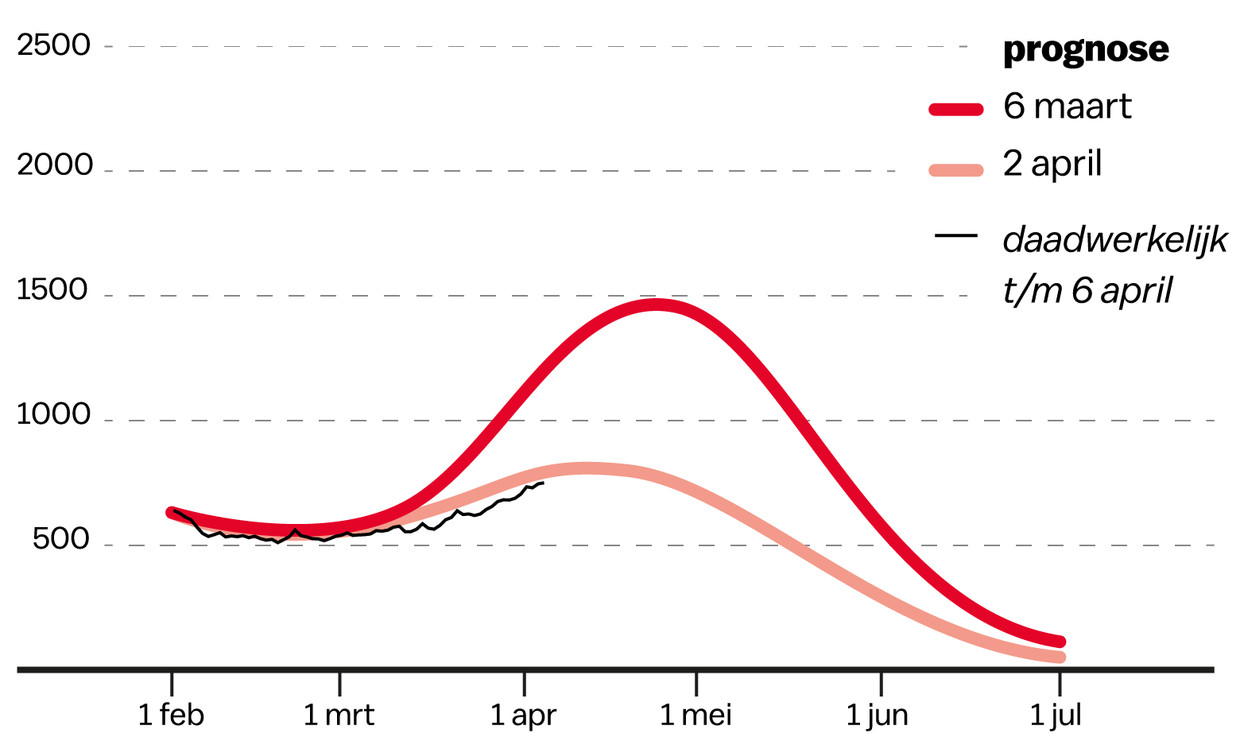
Ja, de mediane voorspelling is gewijzigd. Dat klopt.
Ja, de mediane voorspelling is gewijzigd. Dat klopt.
Prima Jaap, dit was de laatste keer.quote:
Je hoeft me niet in iedere post te taggen waarin je je gebrek aan statistische kennis etaleert.
Ja, de mediane voorspelling is gewijzigd. Dat klopt.
🕰️₿🕰️₿🕰️₿🕰️₿🕰️₿🕰️ TikTok next Block
|
|