SES School, Studie en Onderwijs
Wiskunde in de brugklas, Frans voor het examen of een studie Personeel en Arbeid? Moeilijke formulieren van DUO? Iets weten over studiefinanciering of studentenverenigingen? Dit is het forum voor leerkrachten, scholieren en studenten, van brugklas tot uni



Mensen, ik vul data in in STATA.
Heb nu twee variabelen gemaakt, maar als ik vervolgens "summarize" in tik dan geeft STATA aan dat er voor beide variabelen 0 observaties zijn terwijl ze er toch echt staan. Bijvoorbeeld de variabele "Year" aangemaakt en vervolgens staat daaronder (in de data editor) 1950 t/m 2010.
Dit is de eerste keer dat ik zelf data in het programma gooi. Wat kan ik verkeerd doen? Hulp is zeer welkom.
Heb nu twee variabelen gemaakt, maar als ik vervolgens "summarize" in tik dan geeft STATA aan dat er voor beide variabelen 0 observaties zijn terwijl ze er toch echt staan. Bijvoorbeeld de variabele "Year" aangemaakt en vervolgens staat daaronder (in de data editor) 1950 t/m 2010.
Dit is de eerste keer dat ik zelf data in het programma gooi. Wat kan ik verkeerd doen? Hulp is zeer welkom.
Ik gebruik geen STATA dus het is een wilde gok, maar zijn de variabelen nog hoofdlettergevoelig misschien? En is het type variabele juist? (Dat je niet stiekem string hebt terwijl het integer moet zijn.)quote:Op zaterdag 9 april 2016 15:15 schreef Kaas- het volgende:
Mensen, ik vul data in in STATA.
Heb nu twee variabelen gemaakt, maar als ik vervolgens "summarize" in tik dan geeft STATA aan dat er voor beide variabelen 0 observaties zijn terwijl ze er toch echt staan. Bijvoorbeeld de variabele "Year" aangemaakt en vervolgens staat daaronder (in de data editor) 1950 t/m 2010.
Dit is de eerste keer dat ik zelf data in het programma gooi. Wat kan ik verkeerd doen? Hulp is zeer welkom.
Ook ik ken srata niet, maar heb wel eens gehad dat de vorm van de data in de kolommen verkeerd ingesteld was een p die manier gaf de software dan aan dat er geen observaties waren...quote:
Mensen, ik vul data in in STATA.
Heb nu twee variabelen gemaakt, maar als ik vervolgens "summarize" in tik dan geeft STATA aan dat er voor beide variabelen 0 observaties zijn terwijl ze er toch echt staan. Bijvoorbeeld de variabele "Year" aangemaakt en vervolgens staat daaronder (in de data editor) 1950 t/m 2010.
Dit is de eerste keer dat ik zelf data in het programma gooi. Wat kan ik verkeerd doen? Hulp is zeer welkom.
Whatever...
Ik heb een vraag omtrent een schaal (SPSS).
Ik onderzoek de relatie tussen Facebookgebruik, zelfbeeld en eetgedrag. Nu onderzoek ik eetgedrag met behulp van de Eating Attitudes Test 26 (EAT-26). Deze bestaat uit drie delen:
(A) Gewicht en lengte (waar ik BMI van heb gemaakt),
(B) 26 vragen
(C) 4 gedragsvragen variërend van (nooit, 1x per maand of minder, 2-3x per maand, 1x per week, 2-6x per week en 1x per dag of meer) en 2 extra (heftige) vragen waar alleen (ja of nee) kan worden beantwoord.
De scoring voor die 26 vragen heb ik al verwerkt via Transform - Recode zodat ik op een totaal van 20 of meer kom wat problematisch eetgedrag blijkt. Dit staat op: http://www.eat-26.com/scoring.php. Maar er staat verder geen score bij de overige delen, behalve dan kruisjes bij wat problematisch gedrag is. Hoe kan ik (A) BMI en (C) de vragen waarbij een andere score wordt gehanteerd, dan samenvoegen met de 26 vragen? Ik moet toch uiteindelijk op een schaal komen, namelijk eetgedrag.
Mijn dank zal groot zijn.
Ik onderzoek de relatie tussen Facebookgebruik, zelfbeeld en eetgedrag. Nu onderzoek ik eetgedrag met behulp van de Eating Attitudes Test 26 (EAT-26). Deze bestaat uit drie delen:
(A) Gewicht en lengte (waar ik BMI van heb gemaakt),
(B) 26 vragen
(C) 4 gedragsvragen variërend van (nooit, 1x per maand of minder, 2-3x per maand, 1x per week, 2-6x per week en 1x per dag of meer) en 2 extra (heftige) vragen waar alleen (ja of nee) kan worden beantwoord.
De scoring voor die 26 vragen heb ik al verwerkt via Transform - Recode zodat ik op een totaal van 20 of meer kom wat problematisch eetgedrag blijkt. Dit staat op: http://www.eat-26.com/scoring.php. Maar er staat verder geen score bij de overige delen, behalve dan kruisjes bij wat problematisch gedrag is. Hoe kan ik (A) BMI en (C) de vragen waarbij een andere score wordt gehanteerd, dan samenvoegen met de 26 vragen? Ik moet toch uiteindelijk op een schaal komen, namelijk eetgedrag.
Mijn dank zal groot zijn.
Kun je vraag C niet als robustnesscheck inbouwen. Dus je doet eerst je onderzoek op basis van B. Dan doe je het nogmaals met C. Of ik zou BMI als moderator beschouwen. Ik denk namelijk niet dat een BMI alles zegt over problematisch eetgedrag. Een skinny bitch kan toch net zo goed een problematische eter zijn.quote:
Ik heb een vraag omtrent een schaal (SPSS).
Ik onderzoek de relatie tussen Facebookgebruik, zelfbeeld en eetgedrag. Nu onderzoek ik eetgedrag met behulp van de Eating Attitudes Test 26 (EAT-26). Deze bestaat uit drie delen:
(A) Gewicht en lengte (waar ik BMI van heb gemaakt),
(B) 26 vragen
(C) 4 gedragsvragen variërend van (nooit, 1x per maand of minder, 2-3x per maand, 1x per week, 2-6x per week en 1x per dag of meer) en 2 extra (heftige) vragen waar alleen (ja of nee) kan worden beantwoord.
De scoring voor die 26 vragen heb ik al verwerkt via Transform - Recode zodat ik op een totaal van 20 of meer kom wat problematisch eetgedrag blijkt. Dit staat op: http://www.eat-26.com/scoring.php. Maar er staat verder geen score bij de overige delen, behalve dan kruisjes bij wat problematisch gedrag is. Hoe kan ik (A) BMI en (C) de vragen waarbij een andere score wordt gehanteerd, dan samenvoegen met de 26 vragen? Ik moet toch uiteindelijk op een schaal komen, namelijk eetgedrag.
Mijn dank zal groot zijn.
[ Bericht 8% gewijzigd door #ANONIEM op 10-04-2016 14:54:40 ]
Probeer de volgende dingen/commando's:quote:
Mensen, ik vul data in in STATA.
Heb nu twee variabelen gemaakt, maar als ik vervolgens "summarize" in tik dan geeft STATA aan dat er voor beide variabelen 0 observaties zijn terwijl ze er toch echt staan. Bijvoorbeeld de variabele "Year" aangemaakt en vervolgens staat daaronder (in de data editor) 1950 t/m 2010.
Dit is de eerste keer dat ik zelf data in het programma gooi. Wat kan ik verkeerd doen? Hulp is zeer welkom.
-count.
-inspect [variabele namen]
Zoals hierboven ook al gezegd wordt, kijk of je geen hoofdletters hebt gebruikt en of het wel numerieke variabelen zijn. Alle commando's zijn hoofdlettergevoelig.
Kopieer de data naar excel en importeer het dan als nieuwe dataset.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Mijn kennis van statistiek is uitermate belabberd, maar toch durf ik wat vraagtekens bij het volgende experiment te zetten. Gaarne jullie input.
Men doet 22 operaties op patienten, en na die operatie voert men een meting met een speciaal instrument uit op de wond. Die meting wordt na een week herhaald, en na een maand na de operatie, twee maanden na de operatie, drie maanden na de operatie en vier maanden na de operatie. Tijdens ieder meetpunt kijkt de dokter mee, en geeft een oordeel over de kwaliteit van de wond. Of de wond netjes geheeld is ("good"), of dat er een lelijk litteken is ("moderate"), of dat er complicaties zijn ("poor").
Op basis van die metingen worden ROC curves gemaakt. Wat men namelijk wil weten, is of de metingen met dat speciale instrument in een vroeg stadium kunnen voorspellen of er later complicaties zullen zijn.
Die ROC curves blijken erg onbetrouwbaar te zijn voor data die direct na de operatie is verzameld, of die een week na de operatie is verzameld.
Maar na 1 maand blijkt dat in 6 van de 9 gevallen dat het apparaat een rood sein gaf, er tussen maand 1 en 4 idd. een complicatie is opgetreden. In 1 van de 13 gevallen dat het apparaat aangaf dat alles ok was, is er in die periode ook een complicatie opgetreden.
Kun je op basis van zo weinig metingen uberhaupt ROC curves maken, en zo ja, hoe betrouwbaar is zo'n curve dan?
[ Bericht 1% gewijzigd door Lyrebird op 04-05-2016 15:18:43 ]
Men doet 22 operaties op patienten, en na die operatie voert men een meting met een speciaal instrument uit op de wond. Die meting wordt na een week herhaald, en na een maand na de operatie, twee maanden na de operatie, drie maanden na de operatie en vier maanden na de operatie. Tijdens ieder meetpunt kijkt de dokter mee, en geeft een oordeel over de kwaliteit van de wond. Of de wond netjes geheeld is ("good"), of dat er een lelijk litteken is ("moderate"), of dat er complicaties zijn ("poor").
Op basis van die metingen worden ROC curves gemaakt. Wat men namelijk wil weten, is of de metingen met dat speciale instrument in een vroeg stadium kunnen voorspellen of er later complicaties zullen zijn.
Die ROC curves blijken erg onbetrouwbaar te zijn voor data die direct na de operatie is verzameld, of die een week na de operatie is verzameld.
Maar na 1 maand blijkt dat in 6 van de 9 gevallen dat het apparaat een rood sein gaf, er tussen maand 1 en 4 idd. een complicatie is opgetreden. In 1 van de 13 gevallen dat het apparaat aangaf dat alles ok was, is er in die periode ook een complicatie opgetreden.
Kun je op basis van zo weinig metingen uberhaupt ROC curves maken, en zo ja, hoe betrouwbaar is zo'n curve dan?
[ Bericht 1% gewijzigd door Lyrebird op 04-05-2016 15:18:43 ]
Good intentions and tender feelings may do credit to those who possess them, but they often lead to ineffective — or positively destructive — policies ... Kevin D. Williamson
Hallo mensen!
Ik hoop dat iemand hier mij kan helpen met mijn vraag.
Ik doe een onderzoekje met een dataset waarin respondenten uit vier landen zitten.
Er is een variabele die ik heb bewerkt, en uiteindelijk omgezet naar een dichotome variabele. Dit heb ik per land gedaan, omdat de oorspronkelijke categorieen in de verschillende landen niet met elkaar te vergelijken waren.
Ik heb nu dus vier dichotome variabelen, per land. Elke respondent komt dus ook maar één keer voor in al deze vier variabelen.
Nu wil ik er eigenlijk weer één variabele van maken. Iedereen heeft nu eenzelfde score (1 of 0), dus ik denk dat dit wel mogelijk is.
Maar hoe moet ik dit doen?
Ik werk trouwens met SPSS Syntax, dus als iemand er ook nog eens een syntax code voor zou weten zou ik helemaal gelukkig zijn....
Ik hoop dat iemand hier mij kan helpen met mijn vraag.
Ik doe een onderzoekje met een dataset waarin respondenten uit vier landen zitten.
Er is een variabele die ik heb bewerkt, en uiteindelijk omgezet naar een dichotome variabele. Dit heb ik per land gedaan, omdat de oorspronkelijke categorieen in de verschillende landen niet met elkaar te vergelijken waren.
Ik heb nu dus vier dichotome variabelen, per land. Elke respondent komt dus ook maar één keer voor in al deze vier variabelen.
Nu wil ik er eigenlijk weer één variabele van maken. Iedereen heeft nu eenzelfde score (1 of 0), dus ik denk dat dit wel mogelijk is.
Maar hoe moet ik dit doen?
Ik werk trouwens met SPSS Syntax, dus als iemand er ook nog eens een syntax code voor zou weten zou ik helemaal gelukkig zijn....
Regenboog, regenboog
gelukkig ben je krom,
anders heette je regenstreep,
en dat klinkt toch wel zo stom
gelukkig ben je krom,
anders heette je regenstreep,
en dat klinkt toch wel zo stom
recode naar 1-2 op de dv van het land, geef ze 0 op de dv's die ze niet hebben en tel dan de 4 kolommen op voor de overkoepelende dv?quote:
Hallo mensen!
Ik hoop dat iemand hier mij kan helpen met mijn vraag.
Ik doe een onderzoekje met een dataset waarin respondenten uit vier landen zitten.
Er is een variabele die ik heb bewerkt, en uiteindelijk omgezet naar een dichotome variabele. Dit heb ik per land gedaan, omdat de oorspronkelijke categorieen in de verschillende landen niet met elkaar te vergelijken waren.
Ik heb nu dus vier dichotome variabelen, per land. Elke respondent komt dus ook maar één keer voor in al deze vier variabelen.
Nu wil ik er eigenlijk weer één variabele van maken. Iedereen heeft nu eenzelfde score (1 of 0), dus ik denk dat dit wel mogelijk is.
Maar hoe moet ik dit doen?
Ik werk trouwens met SPSS Syntax, dus als iemand er ook nog eens een syntax code voor zou weten zou ik helemaal gelukkig zijn....
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Mijn statistiekkennis is nogal weggezakt, dus vandaar de volgende vraag:
Ik wil het effect van de verandering van een variabele onderzoeken. Ik heb in principe twee tijdsperiodes: zeg maar bijvoorbeeld oktober - december 2011 - 2013 (dus 3 tijdsperiodes) en 2012 en 2013 helemaal (dus 2 tijdsperiodes). Je moet dit onderzoek zien als een experiment.
Tussentijds is (dit is een voorbeeldje) 3x het loon gestegen. Stel ik zou willen onderzoeken of dit effect heeft op de arbeidsproductiviteit, hoe pak ik dit dan aan? Voor een panel analysis is de tijdsperiode te kort. Hoe kan ik het beste het effect van deze variabele over de tijd onderzoeken? En als ik wil weten of er verschil is tussen mannen en vrouwen?
Bedankt!
Ik wil het effect van de verandering van een variabele onderzoeken. Ik heb in principe twee tijdsperiodes: zeg maar bijvoorbeeld oktober - december 2011 - 2013 (dus 3 tijdsperiodes) en 2012 en 2013 helemaal (dus 2 tijdsperiodes). Je moet dit onderzoek zien als een experiment.
Tussentijds is (dit is een voorbeeldje) 3x het loon gestegen. Stel ik zou willen onderzoeken of dit effect heeft op de arbeidsproductiviteit, hoe pak ik dit dan aan? Voor een panel analysis is de tijdsperiode te kort. Hoe kan ik het beste het effect van deze variabele over de tijd onderzoeken? En als ik wil weten of er verschil is tussen mannen en vrouwen?
Bedankt!
Begrijp ik het goed dat je hoogstens 3 periodes hebt met verschillende lonen?quote:
Mijn statistiekkennis is nogal weggezakt, dus vandaar de volgende vraag:
Ik wil het effect van de verandering van een variabele onderzoeken. Ik heb in principe twee tijdsperiodes: zeg maar bijvoorbeeld oktober - december 2011 - 2013 (dus 3 tijdsperiodes) en 2012 en 2013 helemaal (dus 2 tijdsperiodes). Je moet dit onderzoek zien als een experiment.
Tussentijds is (dit is een voorbeeldje) 3x het loon gestegen. Stel ik zou willen onderzoeken of dit effect heeft op de arbeidsproductiviteit, hoe pak ik dit dan aan? Voor een panel analysis is de tijdsperiode te kort. Hoe kan ik het beste het effect van deze variabele over de tijd onderzoeken? En als ik wil weten of er verschil is tussen mannen en vrouwen?
Bedankt!
[ Bericht 0% gewijzigd door #ANONIEM op 17-05-2016 15:54:31 ]
Oh sorry, dat was ik vergeten te vermelden. Ik heb rond de 1300 bruikbare observaties (totaal circa 1600).
Heb je al gewoon een regressie gedraaid met als moderator geslacht?quote:
Oh sorry, dat was ik vergeten te vermelden. Ik heb rond de 1300 bruikbare observaties (totaal circa 1600).
Nee, ik heb nog niets uitgevoerd. Voor het scriptievoorstel moet ik de methode beschrijven, dus ik probeer erachter te komen welke statistische analyse ik precies moet uitvoeren.
Drukke dag gehad dus misschien zeg ik domme dingen, MCH zal dat dan wel laten weten.
Fixed effects? Elk persoon telt dan 2x als observatie met de verschillen tussen 2011-2012 en 2012-2013 als input. Al kan je dan niet dingen als geslacht doen omdat deze niet veranderen.
Heb je ook personen die geen opslag kregen? Dan Difference in differeces? Groepen 2011-2012 en 2012-2013,maak een dummy (periode) waarbij het eerst jaar 0 is en het tweede 1, maak een dummy voor opslag of niet tussen periode 0 en 1. Zet dit allemaal onder elkaar, dus elke persoon twee keer. Doe de regressie op output = periode, opslag, periode*opslag, (ln)salaris (en andere variabelen die je hebt). De interactie is waar je dan naar kijkt. Is die significant en positief dan heeft het krijgen van een opslag een positie effect op de output van de komende periode.
___
Maar wellicht is er een reden waarom mensen opslag krijgen, bijvoorbeeld omdat ze de periode ervoor heel erg productief waren? Dan zou je bijvoorbeeld de productiviteit van de periode ervoor als lag kunnen toevoegen.
[ Bericht 9% gewijzigd door Zith op 17-05-2016 19:41:10 ]
Fixed effects? Elk persoon telt dan 2x als observatie met de verschillen tussen 2011-2012 en 2012-2013 als input. Al kan je dan niet dingen als geslacht doen omdat deze niet veranderen.
Heb je ook personen die geen opslag kregen? Dan Difference in differeces? Groepen 2011-2012 en 2012-2013,maak een dummy (periode) waarbij het eerst jaar 0 is en het tweede 1, maak een dummy voor opslag of niet tussen periode 0 en 1. Zet dit allemaal onder elkaar, dus elke persoon twee keer. Doe de regressie op output = periode, opslag, periode*opslag, (ln)salaris (en andere variabelen die je hebt). De interactie is waar je dan naar kijkt. Is die significant en positief dan heeft het krijgen van een opslag een positie effect op de output van de komende periode.
___
Maar wellicht is er een reden waarom mensen opslag krijgen, bijvoorbeeld omdat ze de periode ervoor heel erg productief waren? Dan zou je bijvoorbeeld de productiviteit van de periode ervoor als lag kunnen toevoegen.
[ Bericht 9% gewijzigd door Zith op 17-05-2016 19:41:10 ]
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Hi,
Ik ben momenteel bezig met analyse van robuustheid resultaten. Nu wil ik outliers eruit filteren/ervoor controllen, maar zie ik door de bomen het bos niet meer.
Ik heb daarom een aantal vragen
1. Wat is het verschil tussen outliers en influential factors, en waar kan ik me beter op focussen?
2. Mahalanobis concentreert zich alleen op multivariate outliers. Moet ik nog iets doen met dependent variable?
3. Winsorizen: er wordt vaak gesproken over winsorizen op 5% level aan beide kanten. Moet dit worden gedaan voor zowel X als Y variabele?
4. Welke outlier detection/removal technique gebruiken jullie altijd. Ik zie bijv ook nog: Leverage, Cook's, Trimming, Hat's, Likelihood, etc.
5. Hoe zit het met outliers van indicator variables/dummies. Bijv Mahalanobis haalt 1 hele variabele weg die 4x voorkomt. Is dit wel juist? Of moet ik alleen outliers checken op niet-dummies?
Thanks in advance!
Ik ben momenteel bezig met analyse van robuustheid resultaten. Nu wil ik outliers eruit filteren/ervoor controllen, maar zie ik door de bomen het bos niet meer.
Ik heb daarom een aantal vragen
1. Wat is het verschil tussen outliers en influential factors, en waar kan ik me beter op focussen?
2. Mahalanobis concentreert zich alleen op multivariate outliers. Moet ik nog iets doen met dependent variable?
3. Winsorizen: er wordt vaak gesproken over winsorizen op 5% level aan beide kanten. Moet dit worden gedaan voor zowel X als Y variabele?
4. Welke outlier detection/removal technique gebruiken jullie altijd. Ik zie bijv ook nog: Leverage, Cook's, Trimming, Hat's, Likelihood, etc.
5. Hoe zit het met outliers van indicator variables/dummies. Bijv Mahalanobis haalt 1 hele variabele weg die 4x voorkomt. Is dit wel juist? Of moet ik alleen outliers checken op niet-dummies?
Thanks in advance!
Omdat het geen psychologisch onderzoek is, maar waargebeurde financial events. Dan kan ikk niet zeggen: oh die is me wat te hoog, dan negeer/corrigeer ik die.quote:
Hoezo ga je na je uitkomsten en tijdens je robustness checks pas kijken naar je outliers?
Is dit voor een scriptie oid of moet het echt een paper worden uiteindelijk? In dat tweede geval zou ik, als het niet al te laat is, eerst je plan opstellen, dit vastleggen en dan pas naar de data kijken. Nu loop je het risico (on)bewust je uitkomsten te beinvloeden.quote:
[..]
Omdat het geen psychologisch onderzoek is, maar waargebeurde financial events. Dan kan ikk niet zeggen: oh die is me wat te hoog, dan negeer/corrigeer ik die.
Wat je moet gebruiken ligt heel erg aan het type data en kan ik weinig over zeggen op basis van de beperkte informatie.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik beinvloed niet.quote:
[..]
Is dit voor een scriptie oid of moet het echt een paper worden uiteindelijk? In dat tweede geval zou ik, als het niet al te laat is, eerst je plan opstellen, dit vastleggen en dan pas naar de data kijken. Nu loop je het risico (on)bewust je uitkomsten te beinvloeden.
Wat je moet gebruiken ligt heel erg aan het type data en kan ik weinig over zeggen op basis van de beperkte informatie.
Cook's Distance <1 voor alle observations
Winsorizing 5% geeft tevens geen verandering in results.
Wat had je gedaan als het wel een verschil zou maken?quote:
[..]
Ik beinvloed niet.
Cook's Distance <1 voor alle observations
Winsorizing 5% geeft tevens geen verandering in results.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ook gerapporteerd. Mn initiele event window geeft ook insignificantie.quote:
[..]
Wat had je gedaan als het wel een verschil zou maken?
Mn p-value neemt wel af van <0.05 naar <0.10 na winsorizen, de ander blijft constant.
Ja dan moet je nu dus beslissen wat je hoofdconclusie is / wat de beste methode is (met of zonder winsor) terwijl je al weet wat dat voor je uitkomsten doet...quote:
[..]
Ook gerapporteerd. Mn initiele event window geeft ook insignificantie.
Mn p-value neemt wel af van <0.05 naar <0.10 na winsorizen, de ander blijft constant.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik zie geen enkele reden om vooraf te winsorizen. Waarom zou je dat doen?quote:
[..]
Ja dan moet je nu dus beslissen wat je hoofdconclusie is / wat de beste methode is (met of zonder winsor) terwijl je al weet wat dat voor je uitkomsten doet...
Niet van te voren doen, van te voren bepalen of je het gaat doen of niet.quote:
[..]
Ik zie geen enkele reden om vooraf te winsorizen. Waarom zou je dat doen?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik heb een vraag omtrent Stata.
Ik heb een data base met verschillende regios en verschillende jaren.
Ik heb een model waar de GDP wordt beinvloed door Investments, Labor force, Unemployment, Educatie, Internet variabelen (internet penetratie) en populatie density.
Dit is een panel set analyse en ik moet uitzoeken wat het effect is van de internet variabelen.
Echter weet ik niet wat de juiste stappen zijn die ik moet ondernemen.
Graag zou ik beginnen alle variabelen naar growth variabelen te zetten. Echter kom ik er gewoon niet uit icm data panel set.
Als iemand hier goed is in STATA contacteer mij dan alsjeblieft.
Ik heb een data base met verschillende regios en verschillende jaren.
Ik heb een model waar de GDP wordt beinvloed door Investments, Labor force, Unemployment, Educatie, Internet variabelen (internet penetratie) en populatie density.
Dit is een panel set analyse en ik moet uitzoeken wat het effect is van de internet variabelen.
Echter weet ik niet wat de juiste stappen zijn die ik moet ondernemen.
Graag zou ik beginnen alle variabelen naar growth variabelen te zetten. Echter kom ik er gewoon niet uit icm data panel set.
Als iemand hier goed is in STATA contacteer mij dan alsjeblieft.

Dit is nou niet echt een specifieke vraag over STATA. Denk dat je in plaats van op "stata", moet gaan googlen op "statistiek".quote:
Ik heb een vraag omtrent Stata.
Ik heb een data base met verschillende regios en verschillende jaren.
Ik heb een model waar de GDP wordt beinvloed door Investments, Labor force, Unemployment, Educatie, Internet variabelen (internet penetratie) en populatie density.
Dit is een panel set analyse en ik moet uitzoeken wat het effect is van de internet variabelen.
Echter weet ik niet wat de juiste stappen zijn die ik moet ondernemen.
Graag zou ik beginnen alle variabelen naar growth variabelen te zetten. Echter kom ik er gewoon niet uit icm data panel set.
Als iemand hier goed is in STATA contacteer mij dan alsjeblieft.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Dankjewel voor je meedenken!quote:
[..]
recode naar 1-2 op de dv van het land, geef ze 0 op de dv's die ze niet hebben en tel dan de 4 kolommen op voor de overkoepelende dv?
Ik heb uiteindelijk één van de variabele gekopieerd, en deze met behulp van een serie if-jes gehercodeerd.
Erg omslachtig, maar uiteindelijk is het goed gekomen
Regenboog, regenboog
gelukkig ben je krom,
anders heette je regenstreep,
en dat klinkt toch wel zo stom
gelukkig ben je krom,
anders heette je regenstreep,
en dat klinkt toch wel zo stom
Ik neem aan dat dit voor je bachelor scriptie is? (Gezien het scriptie topic.) Aangezien je geen enkel idee lijkt te hebben wat je moet doen lijkt het me handig als je je statistiekboeken raadpleegt, aangezien mensen hier best willen helpen, maar niet alles gaan voorkauwen.quote:
Ik heb een vraag omtrent Stata.
Ik heb een data base met verschillende regios en verschillende jaren.
Ik heb een model waar de GDP wordt beinvloed door Investments, Labor force, Unemployment, Educatie, Internet variabelen (internet penetratie) en populatie density.
Dit is een panel set analyse en ik moet uitzoeken wat het effect is van de internet variabelen.
Echter weet ik niet wat de juiste stappen zijn die ik moet ondernemen.
Graag zou ik beginnen alle variabelen naar growth variabelen te zetten. Echter kom ik er gewoon niet uit icm data panel set.
Als iemand hier goed is in STATA contacteer mij dan alsjeblieft.
Goedemiddag. Ik ben bezig mijn resultaten in te voeren in SPSS. Ik heb het boek Handleiding SPSS voor mij liggen maar heb een vraag.
Mijn enquête bestaat uit 30 vragen. Bij een aantal vragen kan het voorkomen dat je door het geven van een antwoord de eerstvolgende vragen overslaat (omdat je daar door het antwoord niet meer voor in aanmerking komt) en verder gaat bij bijv. 5 vragen verder op. Dan kom je dus met een vijftal vragen te zitten die blanco blijven. Hoe voer ik dit in in SPSS?
Moet ik het desbetreffende vakje voor de 'overgeslagen' vragen in de Data View helemaal leeg laten?
Ik zal het verduidelijken met een eenvoudig voorbeeld, stel:
Vraag 1: Naam
Vraag 2: Antwoord
Vraag 3: Krijg je zakgeld (Ja, ga naar vraag 4 - Nee, ga naar vraag 5)
Vraag 4: Hoeveel zakgeld krijg je?
Vraag 5: Waar geef je je zakgeld aan uit?
Dus, iemand vult bij vraag 3 'Nee' in en gaat dus naar vraag 5 en slaat vraag 4 over. Wat vul ik in SPSS in als 'antwoord' bij vraag 4 voor deze respondent?
[ Bericht 26% gewijzigd door carebaer op 21-05-2016 17:43:49 ]
Mijn enquête bestaat uit 30 vragen. Bij een aantal vragen kan het voorkomen dat je door het geven van een antwoord de eerstvolgende vragen overslaat (omdat je daar door het antwoord niet meer voor in aanmerking komt) en verder gaat bij bijv. 5 vragen verder op. Dan kom je dus met een vijftal vragen te zitten die blanco blijven. Hoe voer ik dit in in SPSS?
Moet ik het desbetreffende vakje voor de 'overgeslagen' vragen in de Data View helemaal leeg laten?
Ik zal het verduidelijken met een eenvoudig voorbeeld, stel:
Vraag 1: Naam
Vraag 2: Antwoord
Vraag 3: Krijg je zakgeld (Ja, ga naar vraag 4 - Nee, ga naar vraag 5)
Vraag 4: Hoeveel zakgeld krijg je?
Vraag 5: Waar geef je je zakgeld aan uit?
Dus, iemand vult bij vraag 3 'Nee' in en gaat dus naar vraag 5 en slaat vraag 4 over. Wat vul ik in SPSS in als 'antwoord' bij vraag 4 voor deze respondent?
[ Bericht 26% gewijzigd door carebaer op 21-05-2016 17:43:49 ]
?quote:
Goedemiddag. Ik ben bezig mijn resultaten in te voeren in SPSS. Ik heb het boek Handleiding SPSS voor mij liggen maar heb een vraag.
Mijn enquête bestaat uit 30 vragen. Bij een aantal vragen kan het voorkomen dat je door het geven van een antwoord de eerstvolgende vragen overslaat (omdat je daar door het antwoord niet meer voor in aanmerking komt) en verder gaat bij bijv. 5 vragen verder op. Dan kom je dus met een vijftal vragen te zitten die blanco blijven. Hoe voer ik dit in in SPSS?
Moet ik het desbetreffende vakje voor de 'overgeslagen' vragen in de Data View helemaal leeg laten?
Ik zal het verduidelijken met een eenvoudig voorbeeld, stel:
Vraag 1: Naam
Vraag 2: Antwoord
Vraag 3: Krijg je zakgeld (Ja, ga naar vraag 4 - Nee, ga naar vraag 5)
Vraag 4: Hoeveel zakgeld krijg je?
Vraag 5: Waar geef je je zakgeld aan uit?
Dus, iemand vult bij vraag 3 'Nee' in en gaat dus naar vraag 5 en slaat vraag 4 over. Wat vul ik in SPSS in als 'antwoord' bij vraag 4 voor deze respondent?

Super, precies wat ik bedoelde. Kan dus n.v.t. gebruiken!quote:
Inmiddels heb ik alle gegevens/variabelen ingevuld. Stuit ik weer op een probleem.
Ik heb op den duur een vraag waar mensen een bedrag moeten invullen, en ik heb deze gezet op ratio-niveau. Maar het kan ook voorkomen dat de vraag n.v.t. is op iemand.
Hoe kan ik er voor zorgen dat er een 'code' n.v.t. komt te staan bij iemand die de vraag niet hoeft in te vullen, maar wel een getal voor de mensen die een bedrag invullen?
Ik heb op den duur een vraag waar mensen een bedrag moeten invullen, en ik heb deze gezet op ratio-niveau. Maar het kan ook voorkomen dat de vraag n.v.t. is op iemand.
Hoe kan ik er voor zorgen dat er een 'code' n.v.t. komt te staan bij iemand die de vraag niet hoeft in te vullen, maar wel een getal voor de mensen die een bedrag invullen?
Ik zou ze gewoon leeglaten eigenlijk. Dan kun je een missing value instellen voor de mensen die die vraag onterecht hebben leeggelaten (in de variable view).quote:
Inmiddels heb ik alle gegevens/variabelen ingevuld. Stuit ik weer op een probleem.
Ik heb op den duur een vraag waar mensen een bedrag moeten invullen, en ik heb deze gezet op ratio-niveau. Maar het kan ook voorkomen dat de vraag n.v.t. is op iemand.
Hoe kan ik er voor zorgen dat er een 'code' n.v.t. komt te staan bij iemand die de vraag niet hoeft in te vullen, maar wel een getal voor de mensen die een bedrag invullen?
Oke. Is het onmogelijk om nominale + ratio antwoorden te combineren in één vraag?quote:
[..]
Ik zou ze gewoon leeglaten eigenlijk. Dan kun je een missing value instellen voor de mensen die die vraag onterecht hebben leeggelaten (in de variable view).
SPSS zal een variabele altijd als één soort variabele zien en in die zin kun je nominaal en ratio niet combineren. Je kunt wel bij ratio een extra code/label aanmaken dat bijvoorbeeld 99 niet van toepassing betekent, maar de vraag is een beetje wat je er aan hebt. Als je de cel leeglaat kun je gewoon de analyses doen met de beschikbare data en als je NVT invult moet je die toch weer uitsluiten van je analyse later. Daarnaast kun je het percentage NVT gewoon berekenen met het antwoord op de vraag die de NVT als gevolg heeft.quote:
[..]
Oke. Is het onmogelijk om nominale + ratio antwoorden te combineren in één vraag?
Ik snap het. Zou je me kunnen vertellen waar ik die uitzondering toevoeg? Als leek met SPSS vind ik het toch wel handig om in het overzicht van de data die extra nvt toe te voegenquote:
[..]
SPSS zal een variabele altijd als één soort variabele zien en in die zin kun je nominaal en ratio niet combineren. Je kunt wel bij ratio een extra code/label aanmaken dat bijvoorbeeld 99 niet van toepassing betekent, maar de vraag is een beetje wat je er aan hebt. Als je de cel leeglaat kun je gewoon de analyses doen met de beschikbare data en als je NVT invult moet je die toch weer uitsluiten van je analyse later. Daarnaast kun je het percentage NVT gewoon berekenen met het antwoord op de vraag die de NVT als gevolg heeft.
Je kiest voor NVT een waarde uit die niet in die variabele voorkomt als 'echte' waarde. Dus stel dat je ratio variabele scores heeft tussen 0 en 10, dan kun je vanaf 11 een willekeurige waarde kiezen. Die waarde vul je in bij de cellen die NVT zijn in die variabele. Vervolgens kun je in Variable View in het kopje Values aangeven wat elke waarde betekent. Dus stel 11 is NVT, dan kun je dat daar invullen en toevoegen.quote:
[..]
Ik snap het. Zou je me kunnen vertellen waar ik die uitzondering toevoeg? Als leek met SPSS vind ik het toch wel handig om in het overzicht van de data die extra nvt toe te voegen
Als je dan in je Data View NVT wil zien in plaats van 11, klik je op het icoontje met '1' en 'A' met een pijl ertussen, dan zie je de labels die je aan de values hebt gegeven in plaats van de getalletjes. (En je kunt er wel mee blijven rekenen.)
Ah het werkt net als bij nominaal en ordinaal zie ik inderdaad, je kan het gewoon toeveogen. Thanks!quote:
[..]
Je kiest voor NVT een waarde uit die niet in die variabele voorkomt als 'echte' waarde. Dus stel dat je ratio variabele scores heeft tussen 0 en 10, dan kun je vanaf 11 een willekeurige waarde kiezen. Die waarde vul je in bij de cellen die NVT zijn in die variabele. Vervolgens kun je in Variable View in het kopje Values aangeven wat elke waarde betekent. Dus stel 11 is NVT, dan kun je dat daar invullen en toevoegen.
Als je dan in je Data View NVT wil zien in plaats van 11, klik je op het icoontje met '1' en 'A' met een pijl ertussen, dan zie je de labels die je aan de values hebt gegeven in plaats van de getalletjes. (En je kunt er wel mee blijven rekenen.)
Eindelijk kan ik mijn data is kruistabellen gaan analyseren en in mijn rapport zetten. Nu kom ik weer een probleem tegen. Wat is SPSS toch een fijn programma... 
Als ik een kruistabel kopieer en in word plak, valt het rechterdeel van de tabel buiten de breedte van het word bestand. Ik kan 'm ook niet verkleinen. Hoe zorg ik er voor dat het tabel schaalt met word zodat hij volledig leesbaar is?
Ik heb het zowel geprobeerd met kopiëren plakken als met exporteren naar word. Beide manieren zorgen voor dezelfde problemen. Sterker nog: zodra ik het exporteer naar word worden de tabellen in tweeën gesplitst in sommige gevallen.
Als ik een kruistabel kopieer en in word plak, valt het rechterdeel van de tabel buiten de breedte van het word bestand. Ik kan 'm ook niet verkleinen. Hoe zorg ik er voor dat het tabel schaalt met word zodat hij volledig leesbaar is?
Ik heb het zowel geprobeerd met kopiëren plakken als met exporteren naar word. Beide manieren zorgen voor dezelfde problemen. Sterker nog: zodra ik het exporteer naar word worden de tabellen in tweeën gesplitst in sommige gevallen.
Ah helaas. Ik heb vannacht de deadline voor concept en hierna heb ik nog 2 weken voor definitief. Dan heb ik aan tijd om alles netjes te maken, maar voor nu wil ik de tabellen zo snel mogelijk naar word hebben. Dan eerst maar even met printscreen denk ik..quote:
Maak je eigen tabel. SPSS output in je scriptie.
Dus even exporteren naar excel.
Edit: Ik vind het toch wel vreemd dat SPSS of Word het niet zo maken dat dit makkelijk te kopiëren en te plakken is, sinds efficiëntie in onze samenleving zo belangrijk is
Stiekem is SPSS echt een bizar slecht programma, alleen omdat het zo wordt aangeleerd valt het niet zo op.quote:
[..]
Ah helaas. Ik heb vannacht de deadline voor concept en hierna heb ik nog 2 weken voor definitief. Dan heb ik aan tijd om alles netjes te maken, maar voor nu wil ik de tabellen zo snel mogelijk naar word hebben. Dan eerst maar even met printscreen denk ik..
Edit: Ik vind het toch wel vreemd dat SPSS of Word het niet zo maken dat dit makkelijk te kopiëren en te plakken is, sinds efficiëntie in onze samenleving zo belangrijk is
Doe ik. Bedankt voor je hulp en vlotte reactie!quote:
Focus je nu maar op de deadline. Dan maak je het voor de finale versie allemaal mooi.

Eens, ik probeer ook zoveel mogelijk in R te doen. Maar vandaag ben ik weer zielsgelukkig met SPSS en de fantastische restructure-functie.quote:
[..]
Stiekem is SPSS echt een bizar slecht programma,
[...]
Aldus.
Wat doet dat ook alweer?quote:Op maandag 23 mei 2016 17:05 schreef Z het volgende:
[..]
Eens, ik probeer ook zoveel mogelijk in R te doen. Maar vandaag ben ik weer zielsgelukkig met SPSS en de fantastische restructure-functie.
Er zijn meerdere opties. Je kan van cases variabelen en van variabelen cases. Databestanden herstructureren dus.quote:
Aldus.
Ahzo, ja dat gaat makkelijker in SPSS dan R ja.quote:
[..]
Er zijn meerdere opties. Je kan van cases variabelen en van variabelen cases. Databestanden herstructureren dus.

Ik heb ook een vraag omdat ik vastloop met mn master thesis.
Voor mijn (uiteindelijk 3-way) ANOVA heb ik een independent variable (type of assortment) die bestaat uit 2 nominale variabelen (evidently equivalent en non equivalent). Deze variabele is echter niet gecodeerd in SPSS omdat iedere participant vragen heeft beantwoord over beide types of assortment.
Met een andere independent variable behoren participanten wel gewoon tot één van de twee nominale groepen (whether they have a broad or narrow scope of attention) en kan ik wel gewoon een ANOVA uitvoeren.
Hoe moet ik nu verder? Moet ik een dummy variable creëren? En op basis van welke data? Ik kreeg als tip dat ik misschien een nieuwe dataset moest creëren en dan de data van het ene assortiment onder dat van het andere assortiment te plakken. Maar hoe zou dit er dan uit komen te zien?
Ik hoop dat het een beetje duidelijk is
Voor mijn (uiteindelijk 3-way) ANOVA heb ik een independent variable (type of assortment) die bestaat uit 2 nominale variabelen (evidently equivalent en non equivalent). Deze variabele is echter niet gecodeerd in SPSS omdat iedere participant vragen heeft beantwoord over beide types of assortment.
Met een andere independent variable behoren participanten wel gewoon tot één van de twee nominale groepen (whether they have a broad or narrow scope of attention) en kan ik wel gewoon een ANOVA uitvoeren.
Hoe moet ik nu verder? Moet ik een dummy variable creëren? En op basis van welke data? Ik kreeg als tip dat ik misschien een nieuwe dataset moest creëren en dan de data van het ene assortiment onder dat van het andere assortiment te plakken. Maar hoe zou dit er dan uit komen te zien?
Ik hoop dat het een beetje duidelijk is
Kun je dit eens uitleggen. Je hebt een variabele die bestaat uit twee variabelen?quote:Op woensdag 25 mei 2016 15:20 schreef PlukvdP. het volgende:
Voor mijn (uiteindelijk 3-way) ANOVA heb ik een independent variable (type of assortment) die bestaat uit 2 nominale variabelen (evidently equivalent en non equivalent). Deze variabele is echter niet gecodeerd in SPSS omdat iedere participant vragen heeft beantwoord over beide types of assortment.
Excuses, ik bedoel dat die variabele bestaat uit 2 groepen.quote:
[..]
Kun je dit eens uitleggen. Je hebt een variabele die bestaat uit twee variabelen?
mijn variabele is dus 'type of assortment' en mijn groups zijn 'evidently equivalent' en 'non equivalent' .quote:Assumption #2: Your three independent variables should each consist of two or more categorical, independent groups. Example independent variables that meet this criterion include gender (two groups: male or female), ethnicity (three groups: Caucasian, African American and Hispanic), profession (five groups: surgeon, doctor, nurse, dentist, therapist), and so forth.
Dus eigenlijk heb je maar twee independent variabelen: type of assortment (evidently equi en non equi) en attention (broad or narrow)?quote:
[..]
Excuses, ik bedoel dat die variabele bestaat uit 2 groepen.
[..]
mijn variabele is dus 'type of assortment' en mijn groups zijn 'evidently equivalent' en 'non equivalent' .
Plus nog een derde, motivational orientation. die ook weer bestaat uit 2 groups.quote:
[..]
Dus eigenlijk heb je maar twee independent variabelen: type of assortment (evidently equi en non equi) en attention (broad or narrow)?
Alleen van die variabele type of assortment snap ik dus niet hoe ik hem mee moet nemen in de ANOVA omdat alle respondenten dus vragen hebben beantwoord over beide groepen. De andere 2 variabelen hebben dat niet, alle respondenten vallen hierbij netjes in 1 van de 2 categorieën.
Dus je hebt dit probleem?quote:
[..]
Plus nog een derde, motivational orientation. die ook weer bestaat uit 2 groups.
Alleen van die variabele type of assortment snap ik dus niet hoe ik hem mee moet nemen in de ANOVA omdat alle respondenten dus vragen hebben beantwoord over beide groepen. De andere 2 variabelen hebben dat niet, alle respondenten vallen hierbij netjes in 1 van de 2 categorieën.
Assumption #3: You should have independence of observations, which means that there is no relationship between the observations in each group or between the groups themselves. For example, there must be different participants in each group with no participant being in more than one group. This is more of a study design issue than something you would test for, but it is an important assumption of the three-way ANOVA. If your study fails this assumption, you will need to use another statistical test instead of the three-way ANOVA (e.g., a repeated measures design). If you are unsure whether your study meets this assumption, you can use our Statistical Test Selector, which is part of our enhanced guides.
Ik stel trouwens voor dat iedereen voortaan z'n conceptuele model hier ook post. Dat maakt vragen beantwoorden vaak wat makkelijker. 
Stargazer.quote:
Maak je eigen tabel. SPSS output in je scriptie.
Dus even exporteren naar excel.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ik lees het nu. Maar die tip/hint die ik van mijn begeleider kreeg dan? Een nieuwe dataset creëren? Is er iemand die hier iets meer over weet? Het zou toch echt met een three-way ANOVA moeten kunnen blijkbaar.quote:
[..]
Dus je hebt dit probleem?
Assumption #3: You should have independence of observations, which means that there is no relationship between the observations in each group or between the groups themselves. For example, there must be different participants in each group with no participant being in more than one group. This is more of a study design issue than something you would test for, but it is an important assumption of the three-way ANOVA. If your study fails this assumption, you will need to use another statistical test instead of the three-way ANOVA (e.g., a repeated measures design). If you are unsure whether your study meets this assumption, you can use our Statistical Test Selector, which is part of our enhanced guides.
Heb je nou een fout gemaakt in je questionnaire? Mensen konden het assortiment tegelijk evidently equivalent en non equivalent vinden?quote:
[..]
Ik lees het nu. Maar die tip/hint die ik van mijn begeleider kreeg dan? Een nieuwe dataset creëren? Is er iemand die hier iets meer over weet? Het zou toch echt met een three-way ANOVA moeten kunnen blijkbaar.
Het enige wat ik kan bedenken is dat je een variabele aanmaakt met 0 als ze beide 0 hebben, 1 als 1 van de opties, 2 de andere optie en 3 als ze beide opties hebben aangekruist.

Dat is een package voor R die je output omzet naar LaTeX-code. Werkt fantastisch.quote:
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.

newmatrix <- t(matrix). Moet je je dataset wel even als matrix lezen.quote:
[..]
Ahzo, ja dat gaat makkelijker in SPSS dan R ja.(Zou zo 123 even niet weten hoe dat in R moet.)
Als ik het goed begrijp, is het probleem dat de variabele "type of assortment" ongestructureerd is, omdat deze bestaat uit de antwoorden op een open vraag? Dat betekent dat je deze zal moeten coderen. Open je dataset in Excel, stel codes op voor de verschillende antwoordcategorieën en codeer vervolgens alle antwoorden die je hebt gekregen in een nieuwe, lege kolom. Zeker voor een scriptie zal dat moeten volstaan.quote:
[..]
Ik lees het nu. Maar die tip/hint die ik van mijn begeleider kreeg dan? Een nieuwe dataset creëren? Is er iemand die hier iets meer over weet? Het zou toch echt met een three-way ANOVA moeten kunnen blijkbaar.
Het zijn geen open vragen. Voor deze variabele heb ik voor beide groepen (beide assortimenten dus) een figuur met hierop verschillende producten. Van deze producten moet men er 1 uitkiezen. En dat dan voor beide assortimenten. Het product dat je omcirkelt is dan de 'location of product' (mijn dependent variable). Ik wil dus onderzoeken of er een verschil zit tussen de 2 verschillende assortimenten en de location of products die mensen kiezen.quote:Op donderdag 26 mei 2016 06:24 schreef Reya het volgende:
[..]
Als ik het goed begrijp, is het probleem dat de variabele "type of assortment" ongestructureerd is, omdat deze bestaat uit de antwoorden op een open vraag? Dat betekent dat je deze zal moeten coderen. Open je dataset in Excel, stel codes op voor de verschillende antwoordcategorieën en codeer vervolgens alle antwoorden die je hebt gekregen in een nieuwe, lege kolom. Zeker voor een scriptie zal dat moeten volstaan.
Maar iedere respondent heeft dus voor beide assortimenten een product omcirkelt, waardoor ik nu niet kan zeggen: respondent 1 valt voor de variabele type of assortment in groep 1 of 2. Dit kan wel bij "normale" variabelen in een ANOVA.
Dan moet je een nieuwe variabele creëren die controleert of keuze bij assortiment A en keuze bij assortiment B gelijk dan wel ongelijk is. Zowel in R als in SPSS vergt dit een klein beetje syntax.quote:
[..]
Het zijn geen open vragen. Voor deze variabele heb ik voor beide groepen (beide assortimenten dus) een figuur met hierop verschillende producten. Van deze producten moet men er 1 uitkiezen. En dat dan voor beide assortimenten. Het product dat je omcirkelt is dan de 'location of product' (mijn dependent variable). Ik wil dus onderzoeken of er een verschil zit tussen de 2 verschillende assortimenten en de location of products die mensen kiezen.
Maar iedere respondent heeft dus voor beide assortimenten een product omcirkelt, waardoor ik nu niet kan zeggen: respondent 1 valt voor de variabele type of assortment in groep 1 of 2. Dit kan wel bij "normale" variabelen in een ANOVA.
Gewoon handmatig gaat denk ik sneller met zo´n studentenenquete.quote:
[..]
Dan moet je een nieuwe variabele creëren die controleert of keuze bij assortiment A en keuze bij assortiment B gelijk dan wel ongelijk is. Zowel in R als in SPSS vergt dit een klein beetje syntax.

Leer ze nou niet het verkeerde aan. Syntax is altijd beter.quote:
[..]
Gewoon handmatig gaat denk ik sneller met zo´n studentenenquete.
Aldus.
Ik heb een sterk vermoeden dat de vraagsteller weinig syntaxen of uberhaupt statistiek nodig heeft in z'n verdere beroepsleven.quote:Op donderdag 26 mei 2016 12:58 schreef Z het volgende:
[..]
Leer ze nou niet het verkeerde aan. Syntax is altijd beter.
Studeert PlukvdP Marketing in Groningen? 
[ Bericht 0% gewijzigd door #ANONIEM op 26-05-2016 13:16:49 ]
[ Bericht 0% gewijzigd door #ANONIEM op 26-05-2016 13:16:49 ]
Nog bedankt voor de eerdere reactie.
Ik heb inmiddels een model kunnen maken.
Ik gebruik panel data over een 3 jarige periode en 30 regio's. Ik heb GDP en GDP growth als dependent variables. Bij GDP klinkt alles vrij logisch, de variabelen die effect zouden moeten hebben zijn significant. Echter bij GDP growth is het een compleet ander verhaal. Ik ben vrij zeker van m'n GDP growth variabelen, dat zij de juiste waardes hebben. Ik heb dit zowel handmatig uitgerekend als via m'n software (STATA). Echter zijn de independent variables en control variables compleet onlogisch. Variables die een positief effect zouden moeten hebben, bijvoorbeeld het growth percentage van employment, unemployment (negatief), investeringen, import en export increase, nemen negatieve waardes aan! Verder zijn zij vrijwel allemaal negatief.
Ik snap er niks van, ik heb zowel een normale regressie gedaan, als een fixed en random effect regressie.
Heeft iemand dit wel eens meegemaakt? Dat de resultaten van de regressie totaal onverwacht zijn... Waar zou dit aan kunnen liggen?
Ik heb inmiddels een model kunnen maken.
Ik gebruik panel data over een 3 jarige periode en 30 regio's. Ik heb GDP en GDP growth als dependent variables. Bij GDP klinkt alles vrij logisch, de variabelen die effect zouden moeten hebben zijn significant. Echter bij GDP growth is het een compleet ander verhaal. Ik ben vrij zeker van m'n GDP growth variabelen, dat zij de juiste waardes hebben. Ik heb dit zowel handmatig uitgerekend als via m'n software (STATA). Echter zijn de independent variables en control variables compleet onlogisch. Variables die een positief effect zouden moeten hebben, bijvoorbeeld het growth percentage van employment, unemployment (negatief), investeringen, import en export increase, nemen negatieve waardes aan! Verder zijn zij vrijwel allemaal negatief.
Ik snap er niks van, ik heb zowel een normale regressie gedaan, als een fixed en random effect regressie.
Heeft iemand dit wel eens meegemaakt? Dat de resultaten van de regressie totaal onverwacht zijn... Waar zou dit aan kunnen liggen?
Dan heb je geen bewijs gevonden voor je hypothese?quote:
Heeft iemand dit wel eens meegemaakt? Dat de resultaten van de regressie totaal onverwacht zijn... Waar zou dit aan kunnen liggen?
Sign of the coefficient speelt ook een rol natuurlijk. Ga jij het maar uitleggen als b.v. advertising een negatief effect heeft op sales terwijl je logisch gezien natuurlijk een positief effect zal mogen verwachten.quote:
[..]
Dan heb je geen bewijs gevonden voor je hypothese?
Post je model / output en de VIF. Post ook een (screenshot van) correlatietabel. Er zijn verschillende redenen waarom een coefficient negatief kan worden terwijl je andersom verwacht, multicollinearity is daar een van. Aangezien je een economisch model probeert te maken waarin alles elkaar beinvloed lijkt me dat wel voor de hand liggend.
Probeer ook eens de variablen een voor een toe te voegen om te kijken hoe de coefficients veranderen in bijzijn van andere.
Probeer ook eens de variablen een voor een toe te voegen om te kijken hoe de coefficients veranderen in bijzijn van andere.
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Het is erger dan dat, de H0 wordt zo wel weerlegd, alleen niet op de manier die verwacht was.quote:
[..]
Dan heb je geen bewijs gevonden voor je hypothese?
Anyway - zo lang er geen info is over de betrouwbaarheid van het model (is er multicollinearity, endogeneity, homoscedasticity?) is het nog niet duidelijk of het model realistisch/betrouwbaar is.
Ik zou trouwens bij dit soort onderzoeken altijd beginnen met autoregressions, omdat de huidige GDP altijd zeer (95%+) afhankelijk is van de GDP t-1, t-2, , enz.. Als je niet de benodigde hoeveelheid data hebt hiervoor (veel tijdsperiodes) dan kan je GDP t-1 als lag toevoegen voor een snelle oplossing...
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!

Is dit hetzelfde?quote:
Ik zou trouwens bij dit soort onderzoeken altijd beginnen met autoregressions, omdat de huidige GDP altijd zeer (95%+) afhankelijk is van de GDP t-1, t-2, , enz.. Als je niet de benodigde hoeveelheid data hebt hiervoor (veel tijdsperiodes) dan kan je GDP t-1 als lag toevoegen voor een snelle oplossing...
Traditionally, the first-order autoregressive process (AR(1)) represented by (5.11)
has been the primary autocorrelation process considered in econometrics (Judge
et al. 1985, pp. 226–227). For annual data, the AR(1)-process is often sufficient
for models with autocorrelated disturbances (with the caveat that it may mask
other shortcomings in model specification).
Zeker in gevallen als GDP-groei zou ik ook al snel denken aan een algemeen gebrek aan statistische kracht (niet genoeg observaties) en gecorreleerde meetfouten (observaties beïnvloeden elkaar door omstandigheden).quote:
[..]
Het is erger dan dat, de H0 wordt zo wel weerlegd, alleen niet op de manier die verwacht was.
Anyway - zo lang er geen info is over de betrouwbaarheid van het model (is er multicollinearity, endogeneity, homoscedasticity?) is het nog niet duidelijk of het model realistisch/betrouwbaar is.
Ik zou trouwens bij dit soort onderzoeken altijd beginnen met autoregressions, omdat de huidige GDP altijd zeer (95%+) afhankelijk is van de GDP t-1, t-2, , enz.. Als je niet de benodigde hoeveelheid data hebt hiervoor (veel tijdsperiodes) dan kan je GDP t-1 als lag toevoegen voor een snelle oplossing...
http://imgur.com/97VD57L
Bedanktt
Dit is een model over 3 jaren met jaarlijkse data en 31 regios.
GRP = gross regional product
GRPcapgrowth = % groei in GRP capita
fixedinvesrgrowth = % groei in fixed asset investments
intusergrowth = % groei internet penetratie (internet gebruikers/populatie)
gcf = gross capital formation
higheducper = % van populatie die hoger onderwijs volgt
urbanunper = unemployment % in urban cities
grptert2 = grp tertiary/grp
popdensity = populatie density
Verder weet ik dit dit model niet optimaal is, en heb het met verschillende constructies geprobeerd maar allen geven soortgelijke resultaten.
Mijn normale non-groei model werkt wel heel goed. Maar alleen de growth werkt van geen meter. Bijvoorbeeld de R-squared van reg GRP fixedassetinvestments is 75%. Maar de R-squared van reg GRPgrowth fixedassetinvestmentsgrowth = 0.04%!
[ Bericht 64% gewijzigd door ScriptieIdee12345 op 27-05-2016 15:35:57 ]
Bedanktt
Dit is een model over 3 jaren met jaarlijkse data en 31 regios.
GRP = gross regional product
GRPcapgrowth = % groei in GRP capita
fixedinvesrgrowth = % groei in fixed asset investments
intusergrowth = % groei internet penetratie (internet gebruikers/populatie)
gcf = gross capital formation
higheducper = % van populatie die hoger onderwijs volgt
urbanunper = unemployment % in urban cities
grptert2 = grp tertiary/grp
popdensity = populatie density
Verder weet ik dit dit model niet optimaal is, en heb het met verschillende constructies geprobeerd maar allen geven soortgelijke resultaten.
Mijn normale non-groei model werkt wel heel goed. Maar alleen de growth werkt van geen meter. Bijvoorbeeld de R-squared van reg GRP fixedassetinvestments is 75%. Maar de R-squared van reg GRPgrowth fixedassetinvestmentsgrowth = 0.04%!
[ Bericht 64% gewijzigd door ScriptieIdee12345 op 27-05-2016 15:35:57 ]
Mij is verteld dat met panel data al die dingen worden verholpen door fixed en random effects, door middel van xtreg, fe en xtreg, re. Is dit onjuist?
Okay, je doet geen echte fixed effects want je zet de variablen die voor het fixed effects model zorgen niet vast
Zie http://www.jblumenstock.com/files/courses/econ174/FEModels.pdf vanaf Fixed effects regression in practice
Goed, ik zou het volgende doen:
Kies een paar variablen die je echt wil hebben en die niet echt gecorreleerd zijn (corr var1 var2 var3), werk hiermee met de volgende stappen :
-Maak dummy voor Year 2, Year 3. Probeer de reg met deze twee dummies en je gekozen v
variablen.
-Maak een dummy voor elke regio die je hebt behalve 1. Probeer de reg met de year dummies en deze dummies en je variabelen. ( stata command: tabulate regio, generate(regio) zet de regio's in dummies)
Je hebt nu een fixed effect model.
Helpt het niet?
-Maak een variable gdpgrowth_1 en maak hiervan de GDPgrowth van de vorige periode, dus voor de group uit jaar 3 neem je de gdpgrowth van jaar 2. Als je geen dgpgrowth van jaar 0 hebt, dan zul je afscheid moeten nemen van je year 1 observaties in je analyse.
-Probeer de gdpgrowth lag met de regressie + year 2 + year 3
-Probeer de gdpgrowth met de hele fixed effects model.
ADDITIONEEL:
-Type hettest na een regressie, is het resultaat significant?
-Bekijk de VIFs of multicollinearity condition index (find collin)
-Probeer eeens na een regressie command het volgende: , vce(robust) of , vce(cluster regio)
Zie http://www.jblumenstock.com/files/courses/econ174/FEModels.pdf vanaf Fixed effects regression in practice
Goed, ik zou het volgende doen:
Kies een paar variablen die je echt wil hebben en die niet echt gecorreleerd zijn (corr var1 var2 var3), werk hiermee met de volgende stappen :
-Maak dummy voor Year 2, Year 3. Probeer de reg met deze twee dummies en je gekozen v
variablen.
-Maak een dummy voor elke regio die je hebt behalve 1. Probeer de reg met de year dummies en deze dummies en je variabelen. ( stata command: tabulate regio, generate(regio) zet de regio's in dummies)
Je hebt nu een fixed effect model.
Helpt het niet?
-Maak een variable gdpgrowth_1 en maak hiervan de GDPgrowth van de vorige periode, dus voor de group uit jaar 3 neem je de gdpgrowth van jaar 2. Als je geen dgpgrowth van jaar 0 hebt, dan zul je afscheid moeten nemen van je year 1 observaties in je analyse.
-Probeer de gdpgrowth lag met de regressie + year 2 + year 3
-Probeer de gdpgrowth met de hele fixed effects model.
ADDITIONEEL:
-Type hettest na een regressie, is het resultaat significant?
-Bekijk de VIFs of multicollinearity condition index (find collin)
-Probeer eeens na een regressie command het volgende: , vce(robust) of , vce(cluster regio)
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Hoi, ik heb even een kort vraagje.
Ik wil in mijn lineaire regressieanalyse (in SPSS) controleren voor een aantal (scale meetniveau) variabelen.
Doe ik dat gewoon door de controlevariabelen in het eerst block (method:enter) in te voeren, en in het tweede block mijn onafhankelijke variabele?
En waar kijk ik dan als ik de significantie, R² en F van de predictor wil weten?
Ik raak namelijk helemaal in de war. Wat zegt het als het gehele model wel significant is maar de predictor niet? Dat betekent toch dat de predictor niks toevoegt aan het model, maar dat de significante controlevariabelen daarvoor zorgen?
Ik wil vooral weten wat ik nu precies moet rapporteren.
[ Bericht 5% gewijzigd door PluisigNijntje op 28-05-2016 19:49:16 ]
Ik wil in mijn lineaire regressieanalyse (in SPSS) controleren voor een aantal (scale meetniveau) variabelen.
Doe ik dat gewoon door de controlevariabelen in het eerst block (method:enter) in te voeren, en in het tweede block mijn onafhankelijke variabele?
En waar kijk ik dan als ik de significantie, R² en F van de predictor wil weten?
Ik raak namelijk helemaal in de war. Wat zegt het als het gehele model wel significant is maar de predictor niet? Dat betekent toch dat de predictor niks toevoegt aan het model, maar dat de significante controlevariabelen daarvoor zorgen?
Ik wil vooral weten wat ik nu precies moet rapporteren.
[ Bericht 5% gewijzigd door PluisigNijntje op 28-05-2016 19:49:16 ]
Nomnomnomnomnomnomnomnomnomnom
Het
Je laatste stelling/vraag klopt. Kijk voor voorbeelden van hoe je dit rapporteert in Pallant of Field.
Het hangt er een beetje vanaf wat die controlevariabelen zijn. In de sociale wetenschappen is het gebruikelijk dat je demografische variabelen eerst erin zet. De achtergrond van die gedachte is dat deze kenmerken namelijk al aanwezig zijn. De verklaarde variantie wordt dan eerst toegeschreven aan die variabelen. Hier is natuurlijk over te discussieren. Keith heeft hier een heldere uitleg over opgenomen in Multiple Regression and Beyond.quote:
Hoi, ik heb even een kort vraagje.
Ik wil in mijn lineaire regressieanalyse (in SPSS) controleren voor een aantal (scale meetniveau) variabelen.
Doe ik dat gewoon door de controlevariabelen in het eerst block (method:enter) in te voeren, en in het tweede block mijn onafhankelijke variabele?
En waar kijk ik dan als ik de significantie, R² en F van de predictor wil weten?
Ik raak namelijk helemaal in de war. Wat zegt het als het gehele model wel significant is maar de predictor niet? Dat betekent toch dat de predictor niks toevoegt aan het model, maar dat de significante controlevariabelen daarvoor zorgen?
Ik wil vooral weten wat ik nu precies moet rapporteren.
Je laatste stelling/vraag klopt. Kijk voor voorbeelden van hoe je dit rapporteert in Pallant of Field.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Betreft de lineaire regressie analyse heb ik ook een vraag. Ik wil het effect meten van een independent variable op een dependent variable. De sample size is 205. Als ik een control variable toevoeg (gender) blijft de sample size 205. Als ik een tweede control variable toevoeg (age) veranderd de sample size naar 26. Hoe kan dit? Ik heb gezocht op google maar kan er niks over vinden.
Wie helpt mij uit de brand? Vast bedankt!
Wie helpt mij uit de brand? Vast bedankt!
quote:
[..]
Wauw, stom dat ik dit gemist heb. Hoe makkelijk kan het soms zijn. Dankjewel!
Erg bedankt voor je reactie. Op de een of andere manier lukt het nu wel.quote:
Okay, je doet geen echte fixed effects want je zet de variablen die voor het fixed effects model zorgen niet vast
Zie http://www.jblumenstock.com/files/courses/econ174/FEModels.pdf vanaf Fixed effects regression in practice
Goed, ik zou het volgende doen:
Kies een paar variablen die je echt wil hebben en die niet echt gecorreleerd zijn (corr var1 var2 var3), werk hiermee met de volgende stappen :
-Maak dummy voor Year 2, Year 3. Probeer de reg met deze twee dummies en je gekozen v
variablen.
-Maak een dummy voor elke regio die je hebt behalve 1. Probeer de reg met de year dummies en deze dummies en je variabelen. ( stata command: tabulate regio, generate(regio) zet de regio's in dummies)
Je hebt nu een fixed effect model.
Helpt het niet?
-Maak een variable gdpgrowth_1 en maak hiervan de GDPgrowth van de vorige periode, dus voor de group uit jaar 3 neem je de gdpgrowth van jaar 2. Als je geen dgpgrowth van jaar 0 hebt, dan zul je afscheid moeten nemen van je year 1 observaties in je analyse.
-Probeer de gdpgrowth lag met de regressie + year 2 + year 3
-Probeer de gdpgrowth met de hele fixed effects model.
ADDITIONEEL:
-Type hettest na een regressie, is het resultaat significant?
-Bekijk de VIFs of multicollinearity condition index (find collin)
-Probeer eeens na een regressie command het volgende: , vce(robust) of , vce(cluster regio)
Super bedankt voor je uitleg.
Hettest werkt niet hier, de andere wel maar veranderen niet heel veel aan de waardes. Echter is het model nu wel ok (lijkt zo).
Een andere vraag.
Is log(GDP) hetzelfde als GDP growth?
Ja.quote:
Een andere vraag.
Is log(GDP) hetzelfde als GDP growth?
Ik baseer mij op Google, kun je zelf ook gebruiken: Noticequote:
that if we difference log GDP, we get the growth rate of GDP.
Niet helemaal. Het is een benadering, maar wel een benadering die door iedereen als goed genoeg wordt beschouwd.quote:
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Fijn dat het helpt!quote:
[..]
Erg bedankt voor je reactie. Op de een of andere manier lukt het nu wel.
Super bedankt voor je uitleg.
Hettest werkt niet hier, de andere wel maar veranderen niet heel veel aan de waardes. Echter is het model nu wel ok (lijkt zo).
Hmm, ik zou zeggen - zoals ik de vraag begrijp - Nee.quote:Een andere vraag.
Is log(GDP) hetzelfde als GDP growth?
GDP = 300 miljard
LOG(GDP) = 11.47
Hoe je hier een GDP growth in ziet weet ik niet
Misschien bedoel je het volgende:
EDIT:quote:Trend measured in natural-log units = ~percentage growth: Because changes in the natural logarithm are (almost) equal to percentage changes in the original series, it follows that the slope of a trend line fitted to logged data is equal to the average percentage growth in the original series. http://people.duke.edu/~rnau/411log.htm#trend
Dat klopt ook; als je log(dependent variable) gebruik in regressies dan zijn de coefficienten van de independent variables ongeveer de percentage groei van de dependent, maar het wijkt meer af wijkt meer af bij hogere percentages.quote:
[..]
Niet helemaal. Het is een benadering, maar wel een benadering die door iedereen als goed genoeg wordt beschouwd.
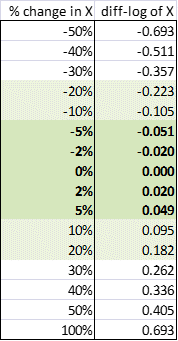
[ Bericht 4% gewijzigd door Zith op 01-06-2016 20:29:31 ]
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Ik ben bezig met een aantal logistische regressies, waaronder regressies met interactie-effecten.
Nu heb ik een beetje moeite met het uitvoeren ervan, maar ook met de interpretatie ervan.
Is er misschien iemand die morgen wat tijd over heeft om mijn regressies en interpretaties door te kijken en te voorzien van wat behulpzaam commentaar?
Mijn dank zal groot zijn
Nu heb ik een beetje moeite met het uitvoeren ervan, maar ook met de interpretatie ervan.
Is er misschien iemand die morgen wat tijd over heeft om mijn regressies en interpretaties door te kijken en te voorzien van wat behulpzaam commentaar?
Mijn dank zal groot zijn
Regenboog, regenboog
gelukkig ben je krom,
anders heette je regenstreep,
en dat klinkt toch wel zo stom
gelukkig ben je krom,
anders heette je regenstreep,
en dat klinkt toch wel zo stom