ONZ Onzin voor je leven!
Vrolijkheid troef in dit lieve forum vol humor.





Spel bedacht door: Pg_Up
Met dank aan bondage, voor het maken van de puntenteltool.
Aangezien ONZ nogal dood is, presenteer ik jullie Het Dodetopicspel. Je hoeft er niks voor te doen, behalve te posten en hopen dat het lang duurt voordat er een nieuwe reactie geplaatst wordt. Elke minuut dat er na jou niks gepost is is een punt. Er moeten dus minimaal 60 seconden tussen jouw post en de volgende post zitten voor een punt: 59 seconden telt nog steeds als 0 minuten en dus 0 punten. Restseconden worden niet bij elkaar opgeteld. De punten worden automatisch opgeteld. Tip: je kan beter niet meerdere keren achter elkaar posten, want je krijgt dus pas punten als er minstens een minuut tussen je post en de volgende post zit, ook al zijn beide posts van jou.
Voor elke minuut tussen de OP en de fipo krijg je ook gewoon een punt, maar voor de tijd tussen de lapo en de nieuwe OP krijg je geen punten. Zoals gebruikelijk is op FOK!, opent degene met de laatste post het nieuwe topic. Duurt dit te lang, dan kan een andere user dit doen en gaan we verder in het topic dat het snelst geopend is.
Gelieve de OP duidelijk en overzichtelijk te houden en de uitleg/regels niet te veranderen, bij voorbaat dank.
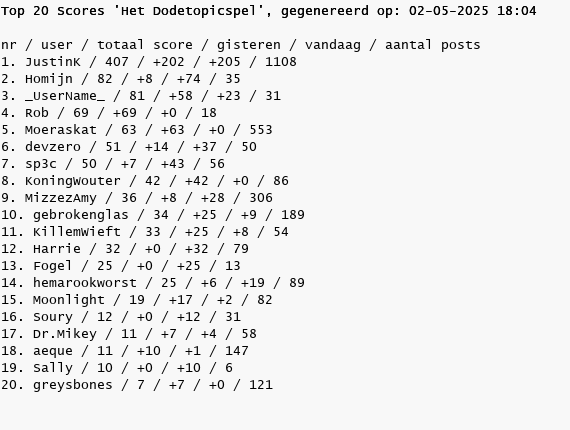
 Geldige scores worden automatisch gepost door Monitor
Geldige scores worden automatisch gepost door Monitordeze plaatjen updatet automagisch. (afblijven dus)
Oudere seizoenen
Een seizoen bestaat uit 1 maand en begint vanaf de 1ste post op de 1ste dag van de maand. Nadat een seizoen afloopt worden de scores weer op nul gezet. Dit om er voor te zorgen dat iedereen een kans heeft om tweede te worden.
Winnaars:
Seizoen 1: Haags_kwartiertje
Seizoen 2: Haags_kwartiertje
Seizoen 3: Dr.Mikey
Seizoen 4: Haags_kwartiertje
Seizoen 5: Haags_kwartiertje
Seizoen 6: Dr.Mikey

Ik voelde me echt bagger toen m'n wekker ging vannacht. Na een half uur half voor pampus te hebben gelegen maar de keuze gemaakt om weer door te slapen. Heeft me ook heel veel tijd gekost die ik anders aan huiswerk had besteed, waar ik me nu dus totaal niet op kan concentrerenquote:Op woensdag 18 april 2018 11:46 schreef haags_kwartiertje het volgende:
[..]
neusspray helpt je de nacht door vriend

oh je bent nog student.quote:Op woensdag 18 april 2018 11:48 schreef Nattekat het volgende:
[..]
Ik voelde me echt bagger toen m'n wekker ging vannacht. Na een half uur half voor pampus te hebben gelegen maar de keuze gemaakt om weer door te slapen. Heeft me ook heel veel tijd gekost die ik anders aan huiswerk had besteed, waar ik me nu dus totaal niet op kan concentreren
Zonder wrijving geen glans
Dinges.quote:
 Op
Op Als iemand dit in leken- en/of zombietaal kan uitleggen, graag
quote:In this paper we address the problem of automatically learning
to classify the sentiment of short messages/reviews by
exploiting information derived from meta-level features i.e.,
features derived primarily from the original bag-of-words
representation. We propose new meta-level features especially
designed for the sentiment analysis of short messages
such as:
among the k nearest neighbors of a given short test
document x, (ii) the distribution of distances of x to their
neighbors and (iii) the document polarity of these neighbors
given by unsupervised lexical-based methods. Our approach
is also capable of exploiting information from the neighborhood
of document x regarding (highly noisy) data obtained
from 1.6 million Twitter messages with emoticons. The set
of proposed features is capable of transforming the original
feature space into a new one, potentially smaller and more
informed. Experiments performed with a substantial number
of datasets (nineteen) demonstrate that the effectiveness
of the proposed sentiment-based meta-level features is not
only superior to the traditional bag-of-word representation
(by up to 16%) but is also superior in most cases to state-ofart
meta-level features previously proposed in the literature
for text classification tasks that do not take into account
some idiosyncrasies of sentiment analysis. Our proposal is
also largely superior to the best lexicon-based methods as
well as to supervised combinations of them. In fact, the
proposed approach is the only one to produce the best results
in all tested datasets in all scenarios.
TLDR.quote:
[..]
Dinges.
Als iemand dit in leken- en/of zombietaal kan uitleggen, graag
[..]

(i)quote:
Deksels, plan mislukt
Toch een puntje.
"It's hard to argue against cynics - they always sound smarter than optimists because they have so much evidence on their side."
 Op
Op
Neuhquote:
[..]
Jaaaaa, weer iets wat alleen ik kan
Owacht.
Pak er eens een paar meer.quote:
Deksels, plan mislukt
Toch een puntje.