SES School, Studie en Onderwijs
Wiskunde in de brugklas, Frans voor het examen of een studie Personeel en Arbeid? Moeilijke formulieren van DUO? Iets weten over studiefinanciering of studentenverenigingen? Dit is het forum voor leerkrachten, scholieren en studenten, van brugklas tot uni



Goedemorgen,
Ik heb een voorbeeldvraag plus uitwerking ervan, die over de de tekentoets (sign test) gaat, maar hierover heb ik een vraag.
Dit levert 14+, 5- en één 0.
X: aantal plussen
H0: p=0,5 (er is geen verschil)
H1: p>0,5 (de herkansing is beter gemaakt)
X ~ Bin(19, 0,5)
P(X ≥ 14) = 1 – P(X ≤ 13) = 0,0318
''Dat is kleiner dan 0,05. we verwerpen de nulhypothese en nemen de alternatieve hypothese aan. De herkansing is beter gemaakt dan de toets.''
Wat ik mij dus afvraag:
-Hoe had ik het moeten aanpakken als de tekentoets tweezijdig was geweest en wat is de intuïtie erachter van de aanpak?
-Hoe had ik het moeten aanpakken als de alternatieve hypothese p < 0,5 was geweest en wat is de intuïtie erachter van de aanpak?
Ik heb een voorbeeldvraag plus uitwerking ervan, die over de de tekentoets (sign test) gaat, maar hierover heb ik een vraag.

Dit levert 14+, 5- en één 0.
X: aantal plussen
H0: p=0,5 (er is geen verschil)
H1: p>0,5 (de herkansing is beter gemaakt)
X ~ Bin(19, 0,5)
P(X ≥ 14) = 1 – P(X ≤ 13) = 0,0318
''Dat is kleiner dan 0,05. we verwerpen de nulhypothese en nemen de alternatieve hypothese aan. De herkansing is beter gemaakt dan de toets.''
Wat ik mij dus afvraag:
-Hoe had ik het moeten aanpakken als de tekentoets tweezijdig was geweest en wat is de intuïtie erachter van de aanpak?
-Hoe had ik het moeten aanpakken als de alternatieve hypothese p < 0,5 was geweest en wat is de intuïtie erachter van de aanpak?
Ik ben momenteel weer bezig met de data van mijn masteronderzoek, dat ik 1 jaar en een paar maanden geleden heb afgerond, om er een manuscript van te maken om te submitten.
Daarbij kwam ik tegen dat ik voor een bepaalde analyse partiële correlatie heb gebruikt. Een collega van me vroeg me gisteren waarom ik daarvoor gekozen heb i.p.v. (multivariate) lineaire regressie.
Ik besefte me dat daar een theoretische basis aan ten grondslag ligt, maar het is voor mij even te lang geleden om dat weer voor de geest te halen.
Mijn vraag is dan ook: wat zijn de verschillen tussen partiële correlatie en (multivariate) lineaire regessie?
Daarbij kwam ik tegen dat ik voor een bepaalde analyse partiële correlatie heb gebruikt. Een collega van me vroeg me gisteren waarom ik daarvoor gekozen heb i.p.v. (multivariate) lineaire regressie.
Ik besefte me dat daar een theoretische basis aan ten grondslag ligt, maar het is voor mij even te lang geleden om dat weer voor de geest te halen.
Mijn vraag is dan ook: wat zijn de verschillen tussen partiële correlatie en (multivariate) lineaire regessie?
Volgens mij is het in essentie hetzelfde
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ja dat dacht ik dus ook alquote:Op donderdag 12 november 2015 18:21 schreef oompaloompa het volgende:
Volgens mij is het in essentie hetzelfde
Voor zover ik het weet, maar ik ben niet 100% zeker dus als je het echt wilt claimen zou ik het dubbelchecken, is de test hetzelfde, dus je p-waardes etc. zullen hetzelfde zijn, maar is de uitput iets anders. Iets van de B-s in de regressie zijn tov de hele variantie en de correlaties alleen tov de variantie tussen x1 en x2 of zo...quote:
[..]
Ja dat dacht ik dus ook almaar omdat het me weer zo expliciet gevraagd werd begon ik te twijfelen
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Je had gelijk. De statistics professor zei ook model 7. Ik kan alleen Hayes (nog) niet gebruiken aangezien mijn mediator en dv een curvilineair effect is en schijnbaar slikt Hayes dat niet. Dus daar moet ik nog wat op vinden.quote:
[..]
Dat is je mediator. Model 5 test de moderator op de directe relatie waarvan jij zegt dat die niet bestaat dus dan kom je uit bij model 7.
Friettent dikke Willie, met Willie
Kun je dan geen log transformation doen van je variabelen?quote:
[..]
Je had gelijk. De statistics professor zei ook model 7. Ik kan alleen Hayes (nog) niet gebruiken aangezien mijn mediator en dv een curvilineair effect is en schijnbaar slikt Hayes dat niet. Dus daar moet ik nog wat op vinden.
Wat houdt dat precies in? Ik heb daar geen kaas van gegeten.quote:
[..]
Kun je dan geen log transformation doen van je variabelen?
Friettent dikke Willie, met Willie
Hallo allemaal,
Ik ben momenteel bezig met het analyseren van data voor mijn masterscriptie. Nu is er iets waar ik niet helemaal uit kom. Mijn plan is om een meervoudige regressie analyse uit te voeren. Hiervoor heb ik 3 controlevariabelen (leeftijd, geslacht, opleiding), 3 onafhankelijke variabelen (op interval niveau) en 1 afhankelijke variabele (ook op interval niveau). Leeftijd en opleiding zijn nu ordinale variabelen en daarom heb ik hiervan dummies gemaakt, zodat ik ze kan meenemen in de regressie. De klassen die het meest voorkomen beschouw ik als de referentie-variabele, deze dummy neem ik dus niet mee in de regressie.
Nu mijn vraag: ik heb een steekproef van 57 personen, waarvan 3 de controlevariabelen in de enquete niet hebben ingevuld. Nu vraag ik mij af hoe deze missing values worden meegenomen in de dummies. Zoals ik het nu zie corresponderen de missing values (die ik aangeef met een '9') met geen van de dummies en worden deze dus automatisch (en onjuist) gezien als behorende tot de referentie-variabele? Moet ik daarom nog een dummy aanmaken voor deze missing values?
Dan nog een andere vraag. Ik doe een hiërarchische regressie analyse omdat ik wil corrigeren voor de controlevariabelen. Dus ik doe de controlevariabelen in 1 blok, de 2 onafhankelijke variabelen van de theorie die ik wil testen in blok 2, en de laatste onafhankelijke variabele in blok 3. Maar kunnen alle dummie variabelen (dus van leeftijd en opleiding) wel samen in 1 blok worden toegevoegd?
Alvast heel erg bedankt voor het meedenken!
[ Bericht 15% gewijzigd door Bruinvis op 28-11-2015 12:45:27 ]
Ik ben momenteel bezig met het analyseren van data voor mijn masterscriptie. Nu is er iets waar ik niet helemaal uit kom. Mijn plan is om een meervoudige regressie analyse uit te voeren. Hiervoor heb ik 3 controlevariabelen (leeftijd, geslacht, opleiding), 3 onafhankelijke variabelen (op interval niveau) en 1 afhankelijke variabele (ook op interval niveau). Leeftijd en opleiding zijn nu ordinale variabelen en daarom heb ik hiervan dummies gemaakt, zodat ik ze kan meenemen in de regressie. De klassen die het meest voorkomen beschouw ik als de referentie-variabele, deze dummy neem ik dus niet mee in de regressie.
Nu mijn vraag: ik heb een steekproef van 57 personen, waarvan 3 de controlevariabelen in de enquete niet hebben ingevuld. Nu vraag ik mij af hoe deze missing values worden meegenomen in de dummies. Zoals ik het nu zie corresponderen de missing values (die ik aangeef met een '9') met geen van de dummies en worden deze dus automatisch (en onjuist) gezien als behorende tot de referentie-variabele? Moet ik daarom nog een dummy aanmaken voor deze missing values?
Dan nog een andere vraag. Ik doe een hiërarchische regressie analyse omdat ik wil corrigeren voor de controlevariabelen. Dus ik doe de controlevariabelen in 1 blok, de 2 onafhankelijke variabelen van de theorie die ik wil testen in blok 2, en de laatste onafhankelijke variabele in blok 3. Maar kunnen alle dummie variabelen (dus van leeftijd en opleiding) wel samen in 1 blok worden toegevoegd?
Alvast heel erg bedankt voor het meedenken!
[ Bericht 15% gewijzigd door Bruinvis op 28-11-2015 12:45:27 ]

Kun je die drie observaties er niet gewoon uit flikkeren? Scheelt een hoop gedoe.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ik weet niet uit hoeveel categorieën opleiding en leeftijd bestaan maar je moet dan wel even oppassen dat je niet in de problemen raakt met je degrees of freedom. Je hebt namelijk nogal weinig observeringen en voor elke onafhankelijke variabele heb je wel 5 waarnemingen nodig.quote:
Hallo allemaal,
Ik ben momenteel bezig met het analyseren van data voor mijn masterscriptie. Nu is er iets waar ik niet helemaal uit kom. Mijn plan is om een meervoudige regressie analyse uit te voeren. Hiervoor heb ik 3 controlevariabelen (leeftijd, geslacht, opleiding), 3 onafhankelijke variabelen (op interval niveau) en 1 afhankelijke variabele (ook op interval niveau). Leeftijd en opleiding zijn nu ordinale variabelen en daarom heb ik hiervan dummies gemaakt, zodat ik ze kan meenemen in de regressie. De klassen die het meest voorkomen beschouw ik als de referentie-variabele, deze dummy neem ik dus niet mee in de regressie.
Nu mijn vraag: ik heb een steekproef van 57 personen, waarvan 3 de controlevariabelen in de enquete niet hebben ingevuld. Nu vraag ik mij af hoe deze missing values worden meegenomen in de dummies. Zoals ik het nu zie corresponderen de missing values (die ik aangeef met een '9') met geen van de dummies en worden deze dus automatisch (en onjuist) gezien als behorende tot de referentie-variabele? Moet ik daarom nog een dummy aanmaken voor deze missing values?
Dan nog een andere vraag. Ik doe een hiërarchische regressie analyse omdat ik wil corrigeren voor de controlevariabelen. Dus ik doe de controlevariabelen in 1 blok, de 2 onafhankelijke variabelen van de theorie die ik wil testen in blok 2, en de laatste onafhankelijke variabele in blok 3. Maar kunnen alle dummie variabelen (dus van leeftijd en opleiding) wel samen in 1 blok worden toegevoegd?
Alvast heel erg bedankt voor het meedenken!
Ik heb ze er idd uitgegooid door te kiezen voor 'exclude cases listwise'. Bedankt voor je reactie!quote:Op zaterdag 28 november 2015 13:38 schreef wimjongil het volgende:
Kun je die drie observaties er niet gewoon uit flikkeren? Scheelt een hoop gedoe.
Ik heb er inderdaad vooraf niet bij stilgestaan dat ik dummy variabelen zou moeten gebruiken en dus een grotere steekproef nodig zou hebben, achteraf niet erg handig. Ik was simpelweg uitgegaan van een totaal van 6 onafhankelijke variabelen.quote:
[..]
Ik weet niet uit hoeveel categorieën opleiding en leeftijd bestaan maar je moet dan wel even oppassen dat je niet in de problemen raakt met je degrees of freedom. Je hebt namelijk nogal weinig observeringen en voor elke onafhankelijke variabele heb je wel 5 waarnemingen nodig.
De categorieën opleiding en leeftijd bestaan beide uit 4 categorieën dus ik heb daarvoor per variabele 3 dummies meegenomen in de regressie. Daarnaast heb ik dus nog 1 nominale controlevariabele (geslacht) en 3 onafhankelijke variabelen. Daarvoor zou ik dan minimaal 50 observaties nodig hebben toch?
Zou je anders aanraden leeftijd of opleiding bijvoorbeeld weg te laten uit de analyse?
Als jij in je theoretisch kader over deze variabelen geschreven hebt en ook hypotheses over hebt opgesteld dan is het zonde om dat er nu weer uit te slopen. Je kan twee dingen doen. Als je ruim in de tijd zit nog wat extra data verzamelen of verder gaan met deze data en daar bij de limitations een vermelding over schrijven.quote:
[..]
Ik heb er inderdaad vooraf niet bij stilgestaan dat ik dummy variabelen zou moeten gebruiken en dus een grotere steekproef nodig zou hebben, achteraf niet erg handig. Ik was simpelweg uitgegaan van een totaal van 6 onafhankelijke variabelen.
De categorieën opleiding en leeftijd bestaan beide uit 4 categorieën dus ik heb daarvoor per variabele 3 dummies meegenomen in de regressie. Daarnaast heb ik dus nog 1 nominale controlevariabele (geslacht) en 3 onafhankelijke variabelen. Daarvoor zou ik dan minimaal 50 observaties nodig hebben toch?
Zou je anders aanraden leeftijd of opleiding bijvoorbeeld weg te laten uit de analyse?
Ik zit helaas niet erg ruim in de tijd nee, dus dan ga ik voor de tweede optie! Bedankt nogmaals!quote:
[..]
Als jij in je theoretisch kader over deze variabelen geschreven hebt en ook hypotheses over hebt opgesteld dan is het zonde om dat er nu weer uit te slopen. Je kan twee dingen doen. Als je ruim in de tijd zit nog wat extra data verzamelen of verder gaan met deze data en daar bij de limitations een vermelding over schrijven.
Stel we hebben een stationair time-series waarvan we het aantal units van tijd in memory willen bepalen. Kijken we naar de partial of normale autocorrelatie?
Autocorrelatie met lagged dependent variable loopt in theorie oneindig door, dus het logische antwoord is partial.quote:
Stel we hebben een stationair time-series waarvan we het aantal units van tijd in memory willen bepalen. Kijken we naar de partial of normale autocorrelatie?

Verliezen op een gegeven moment significantie though.quote:Op woensdag 9 december 2015 14:33 schreef ibrkadabra het volgende:
[..]
Autocorrelatie met lagged dependent variable loopt in theorie oneindig door, dus het logische antwoord is partial.
Is dat juist ook niet wat je wil weten uiteindelijk? Bijvoorbeeld om te voorspellen hoeveel periodes ervoor nog een goede voorspeller is van je sales.quote:Op woensdag 9 december 2015 23:15 schreef Sokz het volgende:
[..]
Verliezen op een gegeven moment significantie though.Thanks beiden!
Ja, maar dat doe je dus met de pacf. Als je een AR(1) proces hebt, heeft t-2 ook nog een invloed op je huidige waarde, maar niet direct.quote:
[..]
Is dat juist ook niet wat je wil weten uiteindelijk? Bijvoorbeeld om te voorspellen hoeveel periodes ervoor nog een goede voorspeller is van je sales.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Klopt! :p Alleen als je een coefficient van 0.97 hebt bijv. voor je 1e lag (als we een AR(1) beschouwen), dan heb je pas bij lag 100 ofzo geen significantie meer als je de ACF gebruikt.quote:
[..]
Verliezen op een gegeven moment significantie though.
Beste allen,
Ik heb een vraag mbt SPSS. Ik wil opleidingsniveau categoriseren. Ik heb in mijn enquête gevraagd naar welke opleiding iemand gevolgd heeft en deze antwoordcategorieën gebruikt: Lagere school, VMBO, MBO, HAVO, VWO, HBO/WO. Nu wil ik deze categoriseren naar laagopgeleid, middelbaar opgeleid en hoogopgeleid volgens de theorie die ik gebruik. Dit is gelukt door 'recode into different variables'. Ik heb laagopgeleid een waarde van 10, middelbaar een waarde van 11 en hoogopgeleid een waarde van 12 gegeven. Wanneer ik nu een simpele correlatie uitvoer met een andere variabele, krijg ik resultaten.
Echter, ik wil graag deze 3 groepen scheiden, waardoor ik per groep kan kijken of het correleert ja of nee. Dit doe ik door 'split file' en dan 'organize output by groups'. Helaas krijg ik nu bij de correlatie alleen maar puntjes te zien (bij Kendall's Tau; overigens ook bij de andere, maar die heb ik niet nodig). Heeft iemand enig idee wat ik fout doe? Ik kom er echt niet uit en moet maandag scriptie inleveren
[ Bericht 1% gewijzigd door fetX op 19-12-2015 13:28:10 ]
Ik heb een vraag mbt SPSS. Ik wil opleidingsniveau categoriseren. Ik heb in mijn enquête gevraagd naar welke opleiding iemand gevolgd heeft en deze antwoordcategorieën gebruikt: Lagere school, VMBO, MBO, HAVO, VWO, HBO/WO. Nu wil ik deze categoriseren naar laagopgeleid, middelbaar opgeleid en hoogopgeleid volgens de theorie die ik gebruik. Dit is gelukt door 'recode into different variables'. Ik heb laagopgeleid een waarde van 10, middelbaar een waarde van 11 en hoogopgeleid een waarde van 12 gegeven. Wanneer ik nu een simpele correlatie uitvoer met een andere variabele, krijg ik resultaten.
Echter, ik wil graag deze 3 groepen scheiden, waardoor ik per groep kan kijken of het correleert ja of nee. Dit doe ik door 'split file' en dan 'organize output by groups'. Helaas krijg ik nu bij de correlatie alleen maar puntjes te zien (bij Kendall's Tau; overigens ook bij de andere, maar die heb ik niet nodig). Heeft iemand enig idee wat ik fout doe? Ik kom er echt niet uit en moet maandag scriptie inleveren
[ Bericht 1% gewijzigd door fetX op 19-12-2015 13:28:10 ]
Je bent sowieso al helemaal verkeerd bezig door een correlatiemaat te berekenen over een categorische variabele. Wiskundig gezien is het nog wel mogelijk om een correlatiemaat te berekenen aangezien je 2 variabelen hebt met verschillende waarden, maar inhoudelijk gezien is het onzinnig aangezien "Opleidingsniveau" niet van intervalniveau of hoger is... snappie? Dus dat is al fout #1.quote:
Beste allen,
Ik heb een vraag mbt SPSS. Ik wil opleidingsniveau categoriseren. Ik heb in mijn enquête gevraagd naar welke opleiding iemand gevolgd heeft en deze antwoordcategorieën gebruikt: Lagere school, VMBO, MBO, HAVO, VWO, HBO/WO. Nu wil ik deze categoriseren naar laagopgeleid, middelbaar opgeleid en hoogopgeleid volgens de theorie die ik gebruik. Dit is gelukt door 'recode into different variables'. Ik heb laagopgeleid een waarde van 10, middelbaar een waarde van 11 en hoogopgeleid een waarde van 12 gegeven. Wanneer ik nu een simpele correlatie uitvoer met een andere variabele, krijg ik resultaten.
Echter, ik wil graag deze 3 groepen scheiden, waardoor ik per groep kan kijken of het correleert ja of nee. Dit doe ik door 'split file' en dan 'organize output by groups'. Helaas krijg ik nu bij de correlatie alleen maar puntjes te zien (bij Kendall's Tau; overigens ook bij de andere, maar die heb ik niet nodig). Heeft iemand enig idee wat ik fout doe? Ik kom er echt niet uit en moet maandag scriptie inleveren
Fout #2 die je maakt is dat je, na het gebruiken van split file, je wederom een correlatiemaat probeert te berekenen tussen variabele "Opleidingsniveau" en de andere variabele, maar dan per groep van opleidingsniveau. Maar, alle mensen in één split-groep hebben natuurlijk dezelfde score op Opleidingsniveau. Dus nu is het uitrekenen van een correlatiemaat behalve onzinnig, ook nog eens wiskundig onmogelijk geworden.
Overigens vind ik het ook raar dat je de categorieën aanduid met waardes (10, 11, 12). Niet echt fout, maar wel ongebruikelijk. Waarom niet (1, 2, 3) of (0, 1, 2)?
Anyway, door het indelen van de mensen op opleidingsniveau kun je het zien als groepen, en daarom zou je dan categorische toetsen op kunnen uitvoeren (Chi-kwadraat, ANOVA)
Hopelijk helpt dit een beetje?


Ik kan me zo voorstellen dat fetX een tikkie teveel in de stress zit om te reply-en. Maar netjes is het niet inderdaad.
Opleiding laag-midden-hoog kan je wel als continue variabele zien toch?
Opleiding laag-midden-hoog kan je wel als continue variabele zien toch?
Aldus.
Kan ook zijn dat hij (zij) zijn (haar) probleem zelf al op had gelost heeft ondertussen of wegens een andere reden niet meer in dit topic heeft gekeken.quote:Op maandag 21 december 2015 13:04 schreef Z het volgende:
Ik kan me zo voorstellen dat fetX een tikkie teveel in de stress zit om te reply-en. Maar netjes is het niet inderdaad.
Opleiding laag-midden-hoog kan je wel als continue variabele zien toch?
En opleidingsniveau kun je in dit geval niet zien als continue variabele. Je weet niet hoe groot de stapjes zijn tussen iedere categorie. Je weet hooguit dat er een ordening in zit, dus ordinaal meetniveau. Dit is niet genoeg om correlaties mee te berekenen.
de variabele "Aantal jaren opleiding genoten" zou daarentegen wel kunnen
Dan nog kun je even het fatsoen opbrengen om een reactie te plaatsen. Vooral als je opzichtig aan het klunzen bent.
Dan ben ik het niet met je eens, aangezien het m.i. gewoon fout is. Vooral gezien het feit dat je eerder al aangaf dat je een "laag-midden-hoog" variabele beschouwt als een continue variabele, wat ook gewoon fout is. Als je met zulke verkeerde assumpties statistiek gaat beoefenen, ga je toch echt de mist in!quote:
Je hebt een punt, maar ik vind het in sommige gevallen toch niet zo'n probleem.
Hi allemaal,
Na wat feedback van mijn begeleider ben ik mijn analyse (meervoudige regressieanalyse) aan het herschrijven. 1 van de punten die ze opnoemde was dat het verschil tussen de Adjusted R squares die ik heb gevonden, namelijk van .062 (model 1 met controlevariabelen) naar .805 (model 2 met vier onafhankelijke variabelen) aardig onmogelijk is. Na alles opnieuw ingevoerd te hebben kom ik op hetzelfde uit, en snap niet wat de oorzaak hiervan is.
Ik heb nu de variabelen los van elkaar in de regressieanalyse ingevoerd en ben erachter dat de hoge r square change het resultaat is van 2 onafhankelijke variabelen die best hoog met elkaar correleren (α= .645). Heeft iemand een idee wat de oorzaak van deze hoge r square change is en wat ik hieraan kan doen?
Alvast bedankt!
[ Bericht 1% gewijzigd door Bruinvis op 29-12-2015 13:09:43 ]
Na wat feedback van mijn begeleider ben ik mijn analyse (meervoudige regressieanalyse) aan het herschrijven. 1 van de punten die ze opnoemde was dat het verschil tussen de Adjusted R squares die ik heb gevonden, namelijk van .062 (model 1 met controlevariabelen) naar .805 (model 2 met vier onafhankelijke variabelen) aardig onmogelijk is. Na alles opnieuw ingevoerd te hebben kom ik op hetzelfde uit, en snap niet wat de oorzaak hiervan is.
Ik heb nu de variabelen los van elkaar in de regressieanalyse ingevoerd en ben erachter dat de hoge r square change het resultaat is van 2 onafhankelijke variabelen die best hoog met elkaar correleren (α= .645). Heeft iemand een idee wat de oorzaak van deze hoge r square change is en wat ik hieraan kan doen?
Alvast bedankt!
[ Bericht 1% gewijzigd door Bruinvis op 29-12-2015 13:09:43 ]
Klinkt inderdaad zoals Z al aangaf als het probleem van Multicollineariteit.quote:
Hi allemaal,
Na wat feedback van mijn begeleider ben ik mijn analyse (meervoudige regressieanalyse) aan het herschrijven. 1 van de punten die ze opnoemde was dat het verschil tussen de Adjusted R squares die ik heb gevonden, namelijk van .062 (model 1 met controlevariabelen) naar .805 (model 2 met vier onafhankelijke variabelen) aardig onmogelijk is. Na alles opnieuw ingevoerd te hebben kom ik op hetzelfde uit, en snap niet wat de oorzaak hiervan is.
Ik heb nu de variabelen los van elkaar in de regressieanalyse ingevoerd en ben erachter dat de hoge r square change het resultaat is van 2 onafhankelijke variabelen die best hoog met elkaar correleren (α= .645). Heeft iemand een idee wat de oorzaak van deze hoge r square change is en wat ik hieraan kan doen?
Alvast bedankt!
Kijk maar eens naar de formule van hoe de R-squared berekend wordt als je 2 voorspellende variabelen zou hebben:
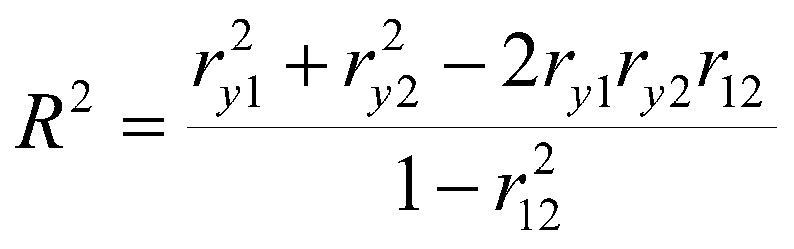
Deze formule generaliseert ook naar hogere dimensies (dus met 4 voorspellers is het hetzelfde idee). In de formule betekent de r(1,2) de correlatie tussen voorspellende variabele 1 en 2. Als deze correlatie heel klein is, of zelfs 0 (wat dus het geval is als ze onafhankelijk zijn van elkaar) vallen grote delen van de formule weg omdat deze 0 zijn. Maar als de r(1,2) groot is, dan gaat de R squared richting de 1 (en een R-squared van 1 is nooit een goed teken aangezien je data dan perfect voorspeld wordt en dat is niet de bedoeling)
Er zijn verschillende manieren om dit probleem te behandelen, afhankelijk van je kennis en vaardigheid met statistiek. Mensen die daar wat vaardiger in zijn zouden kunnen proberen of een vorm van penalized regression het probleem oplost (Ridge regression bv.) of ipv regressie een andere methode proberen als die past bij de dataset. Beginners zullen moeten proberen om de 2 variabelen die sterk met elkaar correleren, proberen samen te voegen. Eentje van de 2 gewoon niet meenemen is ook een optie, maar ja, dan gooi je dus een hoop informatie weg en ik kan me voorstellen dat het niet leuk is om een onderzoek op te stellen met 4 voorspellers en er vervolgens 1 niet kunnen gebruiken. Andere optie is om het gewoon zo te laten, maar ja dan moet je dus wel uitleggen dat de gevonden R-squared eigenlijk nergens meer op slaat, en waarom.
Bedankt voor jullie reacties! Mijn kennis van statistiek is basis dus ik heb geprobeerd de 2 variabelen samen te voegen, maar dat haalde helaas niks uit qua R-squared. Ik haal daarom toch maar 1 van de 2 variabelen uit de analyse. Idd jammer, maar dan slaat het in ieder geval nog ergens op (hoop ik).
Wat ik dan alleen nog niet begrijp is dat de adjusted r-squared nog steeds naar ,60 stijgt in model 2, terwijl ik geen tekens van multicollineariteit kan ontdekken (VIF waarden rond de 1.0 en onderlinge correlaties tussen de onafhankelijke variabelen zijn niet hoger dan .48).
Ik ben allang blij dat het de r-squared ,80 naar ,60 is gedaald maar toch lijkt dat me nog steeds erg hoog. Hebben jullie een idee of er nog een andere oorzaak kan zijn? Of is dit een acceptabele waarde?
Wat ik dan alleen nog niet begrijp is dat de adjusted r-squared nog steeds naar ,60 stijgt in model 2, terwijl ik geen tekens van multicollineariteit kan ontdekken (VIF waarden rond de 1.0 en onderlinge correlaties tussen de onafhankelijke variabelen zijn niet hoger dan .48).
Ik ben allang blij dat het de r-squared ,80 naar ,60 is gedaald maar toch lijkt dat me nog steeds erg hoog. Hebben jullie een idee of er nog een andere oorzaak kan zijn? Of is dit een acceptabele waarde?
Waarom denk je dat een hoge r-squared slecht is?quote:
Bedankt voor jullie reacties! Mijn kennis van statistiek is basis dus ik heb geprobeerd de 2 variabelen samen te voegen, maar dat haalde helaas niks uit qua R-squared. Ik haal daarom toch maar 1 van de 2 variabelen uit de analyse. Idd jammer, maar dan slaat het in ieder geval nog ergens op (hoop ik).
Wat ik dan alleen nog niet begrijp is dat de adjusted r-squared nog steeds naar ,60 stijgt in model 2, terwijl ik geen tekens van multicollineariteit kan ontdekken (VIF waarden rond de 1.0 en onderlinge correlaties tussen de onafhankelijke variabelen zijn niet hoger dan .48).
Ik ben allang blij dat het de r-squared ,80 naar ,60 is gedaald maar toch lijkt dat me nog steeds erg hoog. Hebben jullie een idee of er nog een andere oorzaak kan zijn? Of is dit een acceptabele waarde?
Wat is eigenlijk hoog?
Het centrale idee bij statistiek is dat al die cijfertjes niet een absoluut natuurkundig gegeven zijn die zomaar uit de lucht komen vallen... ze zijn het resultaat van formules waar weer allemaal andere cijfertjes ingestopt zijn, en die formules zijn ergens, op een gegeven moment, ook maar bedacht door iemand, die er voor koos om er een bepaalde interpretatie aan te geven.
Weet je wat een R-squared is en waar het voor staat?
Dan weet je ook of een R-squared van 0.6 of 0.8 (of wat dan ook) in jou geval hoog of laag is
Als ik het goed heb begrepen staat het percentage van R-squared voor de verklaring van de variantie in de afhankelijke variabele (in mijn geval is de afhankelijke variabele de motivatie om ergens aan mee te doen). Dus de variantie in die motivatie is in mijn geval voor 80 of 60% afhankelijk van de variabelen in mijn model.
Ik vind de r-squared van 0.8 vooral hoog in vergelijking met mijn eerste model, waar alleen de controlevariabelen in zitten en maar 0.06 verklaart. En als ik naar andere onderzoeken kijk, waar ik het mijne op gebaseerd heb, is 80% heel hoog. Maar waardoor het in mijn geval komt (buiten multicollineariteit), dat snap ik dan helaas weer net niet.
[ Bericht 0% gewijzigd door Bruinvis op 29-12-2015 20:49:52 ]
Ik vind de r-squared van 0.8 vooral hoog in vergelijking met mijn eerste model, waar alleen de controlevariabelen in zitten en maar 0.06 verklaart. En als ik naar andere onderzoeken kijk, waar ik het mijne op gebaseerd heb, is 80% heel hoog. Maar waardoor het in mijn geval komt (buiten multicollineariteit), dat snap ik dan helaas weer net niet.
[ Bericht 0% gewijzigd door Bruinvis op 29-12-2015 20:49:52 ]
Klopt.quote:
Als ik het goed heb begrepen staat het percentage van R-squared voor de verklaring van de variantie in de afhankelijke variabele (in mijn geval is de afhankelijke variabele de motivatie om ergens aan mee te doen). Dus de variantie in die motivatie is in mijn geval voor 80 of 60% afhankelijk van de variabelen in mijn model.
Ik vind de r-squared van 0.8 vooral hoog in vergelijking met mijn eerste model, waar alleen de controlevariabelen in zitten en maar 0.06 verklaart. En als ik naar andere onderzoeken kijk, waar ik het mijne op gebaseerd heb, is 80% heel hoog. Maar waardoor het in mijn geval komt (buiten multicollineariteit), dat snap ik dan helaas weer net niet.
En tja, zonder verder zelf de data te bekijken kan ik het verder ook niet beoordelen.
Het weglaten van een variabele maakt je model ook makkelijker te interpreteren niet? Dat is ook een winst.
Aldus.
Een Excelvraagje aangezien ik weinig ervaring heb met dit programma.
Weet iemand hoe je handig deze cijfers sorteert?
http://www.theguardian.co(...)dustry-atlas-smoking
Als je dat kopiëert en in Excel plaatst dan komt het keurig in kolommen te staan maar wanneer je sorteert (A-Z) dan zet Excel de integers bovenaan en de decemialen daaronder (met daar tussenin de streepjes maar dat doet er nu even niet toe). Ik heb geprobeerd om van al die cellen hetzelfde getalformat te maken maar Excel gebruikt dan hardnekkig een komma voor de integers terwijl het een punt blijft gebruiken voor de decimalen.
Het is vast zoiets wat heel erg simpel is maar waar je eventjes naar kan zoeken.
Weet iemand hoe je handig deze cijfers sorteert?
http://www.theguardian.co(...)dustry-atlas-smoking
Als je dat kopiëert en in Excel plaatst dan komt het keurig in kolommen te staan maar wanneer je sorteert (A-Z) dan zet Excel de integers bovenaan en de decemialen daaronder (met daar tussenin de streepjes maar dat doet er nu even niet toe). Ik heb geprobeerd om van al die cellen hetzelfde getalformat te maken maar Excel gebruikt dan hardnekkig een komma voor de integers terwijl het een punt blijft gebruiken voor de decimalen.
Het is vast zoiets wat heel erg simpel is maar waar je eventjes naar kan zoeken.
ING en ABN investeerden honderden miljoenen euro in DAPL.
#NoDAPL
#NoDAPL
Ik had het kunnen weten: Libreoffice kan het wel direct normaal sorteren. 
Daarom een extra vraagje over Libre Office, wat is bij Libre Office het equivalent van "end-mode"? Bij Excel kan je direct naar de laatste regel in een kolom gaan door eerst op end te klikken (end-mode activeren) en vervolgens op de onderste pijl (stom toeval dat ik dat ontdekte doordat ik even wat uitprobeerde).
Daarom een extra vraagje over Libre Office, wat is bij Libre Office het equivalent van "end-mode"? Bij Excel kan je direct naar de laatste regel in een kolom gaan door eerst op end te klikken (end-mode activeren) en vervolgens op de onderste pijl (stom toeval dat ik dat ontdekte doordat ik even wat uitprobeerde).
ING en ABN investeerden honderden miljoenen euro in DAPL.
#NoDAPL
#NoDAPL
Dat met punten en komma's is een probleem van excel/libreoffice in combinatie met de taal van je OS. Naar beneden kun je met page down.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Typisch Microsoft.quote:
Dat met punten en komma's is een probleem van excel/libreoffice in combinatie met de taal van je OS. Naar beneden kun je met page down.
Bij Libre-office is het geen probleem, die kan daar wel mee omgaan en sorteert het keurig terwijl de input identiek is.
ING en ABN investeerden honderden miljoenen euro in DAPL.
#NoDAPL
#NoDAPL
Vertel Microsoft gewoon wat jij als decimaal scheidingsteken wil, en het komt helemaal goed. Excel neemt standaard de instelling van je OS over (afhankelijk van je taal/locatie). Je kan het ook handmatig aanpassen in Excel.quote:
[..]
Typisch Microsoft.
Bij Libre-office is het geen probleem, die kan daar wel mee omgaan en sorteert het keurig terwijl de input identiek is.
Volgens mij had ik met LibreOffice op Linux ook dat probleem een keer. Kwestie van even instellen en klaar is kees. Is dus niet iets van Microsoft.quote:
[..]
Vertel Microsoft gewoon wat jij als decimaal scheidingsteken wil, en het komt helemaal goed. Excel neemt standaard de instelling van je OS over (afhankelijk van je taal/locatie). Je kan het ook handmatig aanpassen in Excel.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ik heb er ook last van als ik csv'tjes inlees en het decimaal scheidingsteken van de ene op de andere dag verandert.quote:
[..]
Volgens mij had ik met LibreOffice op Linux ook dat probleem een keer. Kwestie van even instellen en klaar is kees. Is dus niet iets van Microsoft.
Ik wil voor een variabele uitgesplitst naar acht groepen per groep de sd uitrekenen. Dat is makkelijk. Maar ik wil dat ook uitrekenen voor de rest van de groepen. Dus:
Groep 1 en Groep 2 t/m Groep 8
Groep 2 en Groep 1 + Groep 3 t/m Groep 8
Groep 3 en Groep 1 + Groep 2 en Groep 4 t/m Groep 8
enzovoorts.
Is er in SPSS een type 'contrast' waar dat mee kan? Of een andere slimme oplossing? Er is volgens mijn geen contrast-type voor één groep ten opzichte van de rest.
Groep 1 en Groep 2 t/m Groep 8
Groep 2 en Groep 1 + Groep 3 t/m Groep 8
Groep 3 en Groep 1 + Groep 2 en Groep 4 t/m Groep 8
enzovoorts.
Is er in SPSS een type 'contrast' waar dat mee kan? Of een andere slimme oplossing? Er is volgens mijn geen contrast-type voor één groep ten opzichte van de rest.
Aldus.
Gewoon snel even zelf kolommen van de groepen maken in Excel.quote:
Ik wil voor een variabele uitgesplitst naar acht groepen per groep de sd uitrekenen. Dat is makkelijk. Maar ik wil dat ook uitrekenen voor de rest van de groepen. Dus:
Groep 1 en Groep 2 t/m Groep 8
Groep 2 en Groep 1 + Groep 3 t/m Groep 8
Groep 3 en Groep 1 + Groep 2 en Groep 4 t/m Groep 8
enzovoorts.
Is er in SPSS een type 'contrast' waar dat mee kan? Of een andere slimme oplossing? Er is volgens mijn geen contrast-type voor één groep ten opzichte van de rest.
Syntax schrijvenquote:
Hmja, het gaat helaas niet om 1 variabele maar om 128 ...


quote:
Wat is er pijnlijk aan het gebruiken van veel fijnere software waar je veel meer controle hebt over wat je doet?quote:
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ik ben gisteravond gestart met SmartPLS 2.0. Ik vraag me echter af of het nu waard is om SmartPLS 3.0 te proberen? Ik las dat je die ook per maand kan betalen voor 20$, ik ben benieuwd of er hier mensen die hier ook mee werken en het waard vinden, ik heb het programma voor ongeveer 9 maanden nodig.
”Maar als je verlangen naar de lekke band niet verhoord wordt, zit er niets anders op dan te lijden.” - De Renner
R heeft ook een package semPLS, geen idee hoe bedreven je in R bent maar dat is waarschijnlijk een mooi en gratis alternatief.quote:
Ik ben gisteravond gestart met SmartPLS 2.0. Ik vraag me echter af of het nu waard is om SmartPLS 3.0 te proberen? Ik las dat je die ook per maand kan betalen voor 20$, ik ben benieuwd of er hier mensen die hier ook mee werken en het waard vinden, ik heb het programma voor ongeveer 9 maanden nodig.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Nog helemaal niet bekend mee, ik ga het eens proberen! Ben geen doorgewinterde statisticus vandaar dat ik eerst even wat wil oriënteren. Dit is nu mijn tweede studie maar de eerste is van 8 jaar terug.quote:
[..]
R heeft ook een package semPLS, geen idee hoe bedreven je in R bent maar dat is waarschijnlijk een mooi en gratis alternatief.
”Maar als je verlangen naar de lekke band niet verhoord wordt, zit er niets anders op dan te lijden.” - De Renner
Wat studeer je nu en wat heb je gestudeerd?quote:
[..]
Nog helemaal niet bekend mee, ik ga het eens proberen! Ben geen doorgewinterde statisticus vandaar dat ik eerst even wat wil oriënteren. Dit is nu mijn tweede studie maar de eerste is van 8 jaar terug.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Eerder HBO Bedrijfseconomie en nu WO Bestuurskunde.quote:
[..]
Wat studeer je nu en wat heb je gestudeerd?
”Maar als je verlangen naar de lekke band niet verhoord wordt, zit er niets anders op dan te lijden.” - De Renner
In je hoeveelste jaar zit je? Lijkt me sterk dat je zulke softwarepaketten moet gebruiken, bij de meeste sociale wetenschappen kom je met SPSS overal wel.quote:
[..]
Eerder HBO Bedrijfseconomie en nu WO Bestuurskunde.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ben in mijn scriptie beland, heb op het HBO SPSS gebruikt, was een eigen keuze omdat ik het interessant vond. Nu kreeg ik smartPLS aangeraden door mijn begeleider en na het zien van wat Youtube filmpjes ziet dat er makkelijker uit dan SPSS.quote:
[..]
In je hoeveelste jaar zit je? Lijkt me sterk dat je zulke softwarepaketten moet gebruiken, bij de meeste sociale wetenschappen kom je met SPSS overal wel.
”Maar als je verlangen naar de lekke band niet verhoord wordt, zit er niets anders op dan te lijden.” - De Renner
Wat houdt het eigenlijk in als de intercept significant is?
| 1 2 3 4 5 6 7 | Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -7.671e+00 8.245e-01 -9.304 < 2e-16 *** Q2a_1 1.353e-03 1.998e-01 0.007 0.994598 Q2a_2 2.434e-02 1.732e-01 0.140 0.888274 Q2a_3 2.963e-02 1.918e-01 0.154 0.877243 Q2a_4 -4.119e-01 1.894e-01 -2.175 0.029611 * |
Aldus.

Dat als al je variabelen gelijk zijn aan 0, je y de waarde van de constante aanneemt met hoge significantie?quote:
Wat houdt het eigenlijk in als de intercept significant is?
[ code verwijderd ]
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Dat, als de waarde van de intercept in werkelijkheid 0 is, de kans om de geobserveerde waarde van de intercept (in dit geval -7.67) of een waarde die nog verder van 0 is verwijderd te observeren, heel erg klein is.quote:
Wat houdt het eigenlijk in als de intercept significant is?
[ code verwijderd ]
R^2 bedoel je?quote:
Ah, dank. Zegt het ook nog iets over het model?
Alleen als al je andere variabelen tegelijk een zinvolle 0 kunnen aannemen.quote:
Nee, dat de intercept 'ver' van 0 ligt en significant is.
Ik heb een vraagje of permutaties en combinatoriek;
Stel je hebt een vaas met daarin 8 ballen waarvan 5 zwart en 3 ballen wit. De ballen worden met teruglegging uit gehaald. Willekeurig worden er 3 ballen uitgehaald, hoe groot is de kans op 3 zwarte ballen? Nu weet ik alleen zo'n opgave te maken zonder teruglegging doormiddel van ncr te gebruiken.
Maar zodra er vragen kommen als '' hoe groot is de kans op minstens 1 bal'' dan weet ik niet hoe ik dit moet berekenen, en in het boek staat het niet
Wie o wie kan mij helpen?
Stel je hebt een vaas met daarin 8 ballen waarvan 5 zwart en 3 ballen wit. De ballen worden met teruglegging uit gehaald. Willekeurig worden er 3 ballen uitgehaald, hoe groot is de kans op 3 zwarte ballen? Nu weet ik alleen zo'n opgave te maken zonder teruglegging doormiddel van ncr te gebruiken.
Maar zodra er vragen kommen als '' hoe groot is de kans op minstens 1 bal'' dan weet ik niet hoe ik dit moet berekenen, en in het boek staat het niet
Wie o wie kan mij helpen?
"Fifty years ago the Leningrad street taught me a rule - if a fight is inevitable, you have to throw the first punch."
Vladimir Putin
“To forgive the terrorists is up to God, but to send them there is up to me.”
Vladimir Putin
Vladimir Putin
“To forgive the terrorists is up to God, but to send them there is up to me.”
Vladimir Putin
(5/8)^3quote:Op maandag 18 januari 2016 19:40 schreef phpmystyle het volgende:
Ik heb een vraagje of permutaties en combinatoriek;
Stel je hebt een vaas met daarin 8 ballen waarvan 5 zwart en 3 ballen wit. De ballen worden met teruglegging uit gehaald. Willekeurig worden er 3 ballen uitgehaald, hoe groot is de kans op 3 zwarte ballen? Nu weet ik alleen zo'n opgave te maken zonder teruglegging doormiddel van ncr te gebruiken.
De kans op minstens 1 bal is afhankelijk van of je een bal pakt of niet.quote:Maar zodra er vragen kommen als '' hoe groot is de kans op minstens 1 bal'' dan weet ik niet hoe ik dit moet berekenen, en in het boek staat het niet
Wie o wie kan mij helpen?
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ze pakken 3 willekeurige ballen. Hoe voer ik jou bewerking uit op een GR-machine?quote:
[..]
(5/8)^3
[..]
De kans op minstens 1 bal is afhankelijk van of je een bal pakt of niet.
"Fifty years ago the Leningrad street taught me a rule - if a fight is inevitable, you have to throw the first punch."
Vladimir Putin
“To forgive the terrorists is up to God, but to send them there is up to me.”
Vladimir Putin
Vladimir Putin
“To forgive the terrorists is up to God, but to send them there is up to me.”
Vladimir Putin

Als je 3 willekeurige ballen pakt, is dat kans dat je minstens 1 bal pakt, gelijk aan 1.quote:
[..]
Ze pakken 3 willekeurige ballen. Hoe voer ik jou bewerking uit op een GR-machine?
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
En hoe doe jij die rekenkundige bewerking met GR?quote:Op maandag 18 januari 2016 20:18 schreef wimjongil het volgende:
[..]
Als je 3 willekeurige ballen pakt, is dat kans dat je minstens 1 bal pakt, gelijk aan 1.
"Fifty years ago the Leningrad street taught me a rule - if a fight is inevitable, you have to throw the first punch."
Vladimir Putin
“To forgive the terrorists is up to God, but to send them there is up to me.”
Vladimir Putin
Vladimir Putin
“To forgive the terrorists is up to God, but to send them there is up to me.”
Vladimir Putin
Welke?quote:
[..]
En hoe doe jij die rekenkundige bewerking met GR?
Kijk nog eens naar wat je precies vraagt en wat je precies moet weten. Volgens mij heb je hier vergeten om de kleur van de bal te specificiëren namelijk.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Deze opgave bijvoorbeeld.quote:
[..]
Welke?
Kijk nog eens naar wat je precies vraagt en wat je precies moet weten. Volgens mij heb je hier vergeten om de kleur van de bal te specificiëren namelijk.
De eerste kwam ik uit:

Excuus voor de slechte foto
5/8 tot de 3e macht. De tweede al niet meer 5 ncr 2 x 3 ncr 1/ 8 ncr 3. Ofwel; 30/56. Echter klopt dat antwoord niet. En hoe ik die derde opgave moet maken is mij helemaal een raadsel
"Fifty years ago the Leningrad street taught me a rule - if a fight is inevitable, you have to throw the first punch."
Vladimir Putin
“To forgive the terrorists is up to God, but to send them there is up to me.”
Vladimir Putin
Vladimir Putin
“To forgive the terrorists is up to God, but to send them there is up to me.”
Vladimir Putin
Combinaties gebruiken kan alleen maar zonder teruglegging, dus bij vraag 5. 4 kan je alleen maar met kansen doen. :quote:
[..]
Deze opgave bijvoorbeeld.
5/8 tot de 3e macht. De tweede al niet meer 5 ncr 2 x 3 ncr 1/ 8 ncr 3. Ofwel; 30/56. Echter klopt dat antwoord niet. En hoe ik die derde opgave moet maken is mij helemaal een raadsel
A) (5/8)^3, maar dat wist je al
B) (5/8)^2*3/8= 75/512
C) kans op minstens 1 witte bal= 1- kans op 0 witte ballen= 1-(5/8)^3=387/512
Ok. Maar bij opgave 4 C kom ik er niet uit, ik kan alleen maar de NCR functie gebruiken op mijn GR en die is voor zonder teruglegging, hoe reken ik met teruglegging?quote:
[..]
Combinaties gebruiken kan alleen maar zonder teruglegging, dus bij vraag 5. 4 kan je alleen maar met kansen doen. :
A) (5/8)^3, maar dat wist je al
B) (5/8)^2*3/8= 75/512
C) kans op minstens 1 witte bal= 1- kans op 0 witte ballen= 1-(5/8)^3=387/512
Alvast bedankt
"Fifty years ago the Leningrad street taught me a rule - if a fight is inevitable, you have to throw the first punch."
Vladimir Putin
“To forgive the terrorists is up to God, but to send them there is up to me.”
Vladimir Putin
Vladimir Putin
“To forgive the terrorists is up to God, but to send them there is up to me.”
Vladimir Putin
Je kent deze formule? P(X>=x)=1-P(X<x), X is het aantal witte ballen.quote:[..]
Ok. Maar bij opgave 4 C kom ik er niet uit, ik kan alleen maar de NCR functie gebruiken op mijn GR en die is voor zonder teruglegging, hoe reken ik met teruglegging?
Alvast bedankt
Dit geeft dus P(X>=1)= 1- P(X<1). Omdat dit een discrete stochast is, kan je ook schrijven:
1-P(X<1) <=> 1-P(x=0) => 1-(5/8)^3= 387/512
quote:
[..]
(5/8)^3
[..]
De kans op minstens 1 bal is afhankelijk van of je een bal pakt of niet.
Nee, uitgeschreven staat er (5/8)*(5/8)*(3/8), het maakt Vandale niet uit in welke volgorde je het plaatstquote:[..]
Keer 3 toch omdat het niet uitmaakt in welke beurt je de zwarte pakt
Hoezoquote:
Oke, stel jij hebt gelijk, laten we het eens uitschrijven:
Beurt 1 Beurt 2 Beurt 3
zwarte witte zwarte = (5/8)*(3/8)*(5/8)=75/512
witte zwarte zwarte = (3/8)*(5/8)*(5/8)=75/512
zwarte zwarte witte = (5/8)*(5/8)*(3/8)=75/512
Hij heeft gelijk. Je moet die drie kansen bij elkaar optellen.quote:
[..]
Hoezo
Oke, stel jij hebt gelijk, laten we het eens uitschrijven:
Beurt 1 Beurt 2 Beurt 3
zwarte witte zwarte = (5/8)*(3/8)*(5/8)=75/512
witte zwarte zwarte = (3/8)*(5/8)*(5/8)=75/512
zwarte zwarte witte = (5/8)*(5/8)*(3/8)=75/512
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Och ja natuurlijk, stom  , Sorry Anoonumos, T is laat in de avond, vergeef me. Ik vraag me af hoe ik hier ooit een 7 voor heb kunnen halen, als ik nu al stomme foutjes zit te maken.
, Sorry Anoonumos, T is laat in de avond, vergeef me. Ik vraag me af hoe ik hier ooit een 7 voor heb kunnen halen, als ik nu al stomme foutjes zit te maken.
Ik was eigenlijk helemaal vergeten dat ik deze post hier had geplaatst (kom hier ook niet zo vaak), vandaar deze erg late reactie. Ik wil je graag bedanken voor de moeite en excuus aanbieden voor het feit dat enige reactie van mijn kant zo lang is uitgebleven.quote:
[..]
Je bent sowieso al helemaal verkeerd bezig door een correlatiemaat te berekenen over een categorische variabele. Wiskundig gezien is het nog wel mogelijk om een correlatiemaat te berekenen aangezien je 2 variabelen hebt met verschillende waarden, maar inhoudelijk gezien is het onzinnig aangezien "Opleidingsniveau" niet van intervalniveau of hoger is... snappie? Dus dat is al fout #1.
Fout #2 die je maakt is dat je, na het gebruiken van split file, je wederom een correlatiemaat probeert te berekenen tussen variabele "Opleidingsniveau" en de andere variabele, maar dan per groep van opleidingsniveau. Maar, alle mensen in één split-groep hebben natuurlijk dezelfde score op Opleidingsniveau. Dus nu is het uitrekenen van een correlatiemaat behalve onzinnig, ook nog eens wiskundig onmogelijk geworden.
Overigens vind ik het ook raar dat je de categorieën aanduid met waardes (10, 11, 12). Niet echt fout, maar wel ongebruikelijk. Waarom niet (1, 2, 3) of (0, 1, 2)?
Anyway, door het indelen van de mensen op opleidingsniveau kun je het zien als groepen, en daarom zou je dan categorische toetsen op kunnen uitvoeren (Chi-kwadraat, ANOVA)
Hopelijk helpt dit een beetje?
Uiteindelijk heb ik de conceptversie van mijn scriptie ingeleverd met een correlatie en dit werd niet fout gerekend. De correlatiemaat die ik heb gebruikt is Kendall's Tau en volgens Field kan je die gewoon gebruiken wanneer je minimaal een ordinale variabele (ook wel 'categorale variabelen' genoemd) hebt gebruikt. Het lijkt mij dat 'Opleidingsniveau' in dit geval een ordinale variabele is (laagopgeleid, middelbaar opgeleid en hoog opgeleid?). Deze zijn samengevoegd nadat ik mijn respondenten hun hoogst genoten opleiding had gevraagd (HAVO, VWO, WO, HBO etc.) Of zie ik dit nu nog verkeerd? Dan zou het vreemd zijn, aangezien de conceptversie positief is ontvangen.
Ik ben nu aan de slag met een ANOVA voor mijn definitieve versie. Dat was mij inderdaad aangeraden, aangezien ze vonden dat ik me er met een correlatie iets te makkelijk vanaf had gemaakt (maar niet fout). Echter, volgens mij kan ik die niet uivoeren daar mijn data niet voldoet aan de aannames. Hier ga ik deze week verder mee aan de slag.
Nogmaals excuses voor de late reactie van mijn kant.
Als je data niet aan de assumpties van een ANOVA voldoet, kun je nog best veel proberen om dat te fixen.quote:
[..]
Ik was eigenlijk helemaal vergeten dat ik deze post hier had geplaatst (kom hier ook niet zo vaak), vandaar deze erg late reactie. Ik wil je graag bedanken voor de moeite en excuus aanbieden voor het feit dat enige reactie van mijn kant zo lang is uitgebleven.
Uiteindelijk heb ik de conceptversie van mijn scriptie ingeleverd met een correlatie en dit werd niet fout gerekend. De correlatiemaat die ik heb gebruikt is Kendall's Tau en volgens Field kan je die gewoon gebruiken wanneer je minimaal een ordinale variabele (ook wel 'categorale variabelen' genoemd) hebt gebruikt. Het lijkt mij dat 'Opleidingsniveau' in dit geval een ordinale variabele is (laagopgeleid, middelbaar opgeleid en hoog opgeleid?). Deze zijn samengevoegd nadat ik mijn respondenten hun hoogst genoten opleiding had gevraagd (HAVO, VWO, WO, HBO etc.) Of zie ik dit nu nog verkeerd? Dan zou het vreemd zijn, aangezien de conceptversie positief is ontvangen.
Ik ben nu aan de slag met een ANOVA voor mijn definitieve versie. Dat was mij inderdaad aangeraden, aangezien ze vonden dat ik me er met een correlatie iets te makkelijk vanaf had gemaakt (maar niet fout). Echter, volgens mij kan ik die niet uivoeren daar mijn data niet voldoet aan de aannames. Hier ga ik deze week verder mee aan de slag.
Nogmaals excuses voor de late reactie van mijn kant.
Your opinion of me is none of my business.
Ik denk dat het vooral belangrijk is dat fetX snapt wat hij aan het doen is en ook opschrijft waarom hij iets doet, niet zozeer wat nou de uitkomsten van z'n onderzoek zijn. Daar kun je punten mee scoren.
Persoonlijk alvast even een vraagje... Iemand hier ervaring met IRT en/of factoranalyse in R die ik een DMmetje mag doen als ik hier binnenkort een vraag over heb?
Your opinion of me is none of my business.
Natuurlijk, maar iets uitzoeken en vanaf niks beginnen is gewoon bar moeilijk als je er zelf geen of weinig verstand van hebt. En heel eerlijk, ik verwacht niet dat iemand die een correlatie als analyse gebruikt voor z'n scriptie echt torenhoge statistische of methodologische ambities heeft.quote:
Ik denk dat het vooral belangrijk is dat fetX snapt wat hij aan het doen is en ook opschrijft waarom hij iets doet, niet zozeer wat nou de uitkomsten van z'n onderzoek zijn. Daar kun je punten mee scoren.
Your opinion of me is none of my business.
Klopt, wel een slechte opleiding dan die fetX volgt. Verlangen dat statistische toetsen worden uitgevoerd die niet door de student worden gesnapt.quote:
[..]
Natuurlijk, maar iets uitzoeken en vanaf niks beginnen is gewoon bar moeilijk als je er zelf geen of weinig verstand van hebt. En heel eerlijk, ik verwacht niet dat iemand die een correlatie als analyse gebruikt voor z'n scriptie echt torenhoge statistische of methodologische ambities heeft.En als hij straks weer terug is om te vragen wat hij nu moet doen omdat zijn resultaten niet significant zijn, kunnen we hem alsnog wijzen op dat zijn data zelf hem veel meer vertelt dan een alpha niveau.
Ik had volgens mij al gelezen dat je niet dol bent op SPSS maar Factoranalyse kun je toch heel makkelijk uitvoeren met dat programma?quote:
Persoonlijk alvast even een vraagje... Iemand hier ervaring met IRT en/of factoranalyse in R die ik een DMmetje mag doen als ik hier binnenkort een vraag over heb?
Dank voor je reactie!quote:
[..]
Als je data niet aan de assumpties van een ANOVA voldoet, kun je nog best veel proberen om dat te fixen.
Opleidingsniveau is nu een dummy variabele en mijn afhankelijke variabele is interval-niveau.
Het enige puntje is dat binnen 'Opleidingsniveau' ik (helaas) maar 18 mensen in mijn dataset heb die middelbaar zijn opgeleid (tegenover 60 laagopgeleid en 100 hoogopgeleid). Ik kan in Field echter niet vinden of dit nu een probleem is of niet. Wanneer dit geen probleem is, voldoet mijn data aan de aannames.
@MCH: Toegegeven, ik ben niet iemand die statistiek kan dromen, maar ik begrijp het wel degelijk. Heb statistiek vorig jaar met een acht afgesloten, dus ik denk niet dat je kan zeggen dat ik niets van statistiek snap. Daarnaast is mijn kwantitatieve (concept)scriptie op de Universiteit gewoon goed ontvangen, dus het is niet zo dat ik alleen maar onzin opschrijf.
Wat mij werd aangeraden is dat ik nog een ANOVA erbij zou kunnen doen, om meer uit mijn data te halen. En daar ben ik het mee eens. Helaas heb ik daar niet eerder aan gedacht. Bovendien begrijp ik prima wat voor informatie je uit een ANOVA kan halen (dwz: de interpretatie ervan). Ik zit alleen altijd te kloten met die aannames. Veel mensen vinden Field een fijn boek. Ik denk daar iets anders over. Ik vind het nogal een rommelig boek. Ik heb een jaar geleden statistiek gehad, en zodoende moet ik altijd terugkijken aan welke aannames/voorwaarden een toets precies moet voldoen.
Vind ik wel wat een heerlijk programma is het.quote:
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
3 variablen:quote:
Opleidingsniveau is nu een dummy variabele
LAAG: 1/0
MIDDEL: 1/0
HOOG: 1/0
?
Met je 18 middel zou je er misschien ook voor kunnen kiezen deze te onder te brengen bij een ander, bijv
LAAG-MIDDEL: 1/0, 78 observaties
HOOG: 100 observaties
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Klopt.quote:
[..]
3 variablen:
LAAG: 1/0
MIDDEL: 1/0
HOOG: 1/0
?
Met je 18 middel zou je er misschien ook voor kunnen kiezen deze te onder te brengen bij een ander, bijv
LAAG-MIDDEL: 1/0, 78 observaties
HOOG: 100 observaties
Dat zou inderdaad kunnen, alleen kom ik dan in de problemen met de theorie die ik heb gebruikt
In studies zie ik eigenlijk altijd het aantal studiejaren staan, niet een BSc/MSc.. kan je niet het volgende doen om een enkele variabele te creeren?
VMBO: 4 (jaar)
MBO: 7 (VMBO+3)
HAVO: 5
HBO: 9 (HAVO+4)
VWO: 6
WO: 10 (VWO + 4)
VMBO: 4 (jaar)
MBO: 7 (VMBO+3)
HAVO: 5
HBO: 9 (HAVO+4)
VWO: 6
WO: 10 (VWO + 4)
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!