SES School, Studie en Onderwijs
Wiskunde in de brugklas, Frans voor het examen of een studie Personeel en Arbeid? Moeilijke formulieren van DUO? Iets weten over studiefinanciering of studentenverenigingen? Dit is het forum voor leerkrachten, scholieren en studenten, van brugklas tot uni



Lieve FOK!kers, ik heb over een maandje mijn toelatingsexamen voor mijn Sociologie master aan de VU. Ik kom van het hbo af en heb dus niet/nauwelijks statistiek of wiskunde gehad. Ben al druk aan het oefenen, maar hebben jullie nog tips, tricks of linkjes naar goede samenvattingen of oefenmogelijkheden?
Welke onderwerpen zijn het meest belangrijk bij wiskunde ihkv statistiek?
Welke onderwerpen zijn het meest belangrijk bij wiskunde ihkv statistiek?

Als bij een multiple logistische regressie een interactieterm (onafhankelijke variabele1*onafhankelijke variabele2) niet significant is, dan kan ik deze interactieterm weglaten uit mijn analyse toch om het effect van deze onafhankelijke variabelen an sich te bepalen?
Situatie is namelijk als volgt: onafhankelijke variabelen 1 en 2 zijn beiden significant in mijn logistische regressiemodel, maar als ik een interactieterm introduceer met deze variabelen, is deze interactieterm niet significant, maar worden ook de variabelen individueel niet significant.
Volgens mij kan ik mijn interactieterm dan weglaten en de significante variabelen als zodanig rapporteren.
Situatie is namelijk als volgt: onafhankelijke variabelen 1 en 2 zijn beiden significant in mijn logistische regressiemodel, maar als ik een interactieterm introduceer met deze variabelen, is deze interactieterm niet significant, maar worden ook de variabelen individueel niet significant.
Volgens mij kan ik mijn interactieterm dan weglaten en de significante variabelen als zodanig rapporteren.
Nee, tell me more?quote:
Ik heb alleen mijn multipele logistische regressie herhaald met alle originele onafhankelijke variabelen plus de interactieterm. Toen was de interactieterm niet significant, maar de twee onafhankelijke variabelen die eerst wel significant waren, ook niet meer.
Met een F-test test je of je variabelen samen significant zijn, om het in hypethesissen te verwoorden:
F test: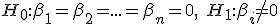 voor een
voor een ![i \in [1,n] \cap \mathbb{N}](https://forum.fok.nl/lib/mimetex.cgi?i%20%5Cin%20%5B1%2Cn%5D%20%5Ccap%20%5Cmathbb%7BN%7D)
T-test: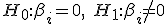
F test:
T-test:
Beste SPSS helden,
Op dit moment ben ik bezig met mijn afstudeeronderzoek en heb een vraag over een SPSS analyse.
Ik doe een onderzoek naar welke behoeften mensen hebben op een webshop en in de fysieke winkel, bijvoorbeeld, in welke mate hebben consumenten behoefte aan reviews op een webshop, of het product aanraken in de winkel etc.
Ook vraag ik in de enquête in welke mate zij de winkel/webshop beoordelen op deze punten.
Zo heb ik 2 vragen gemeten op basis van een 5 punt likert schaal:
- In welke mate vindt u de volgende functies belangrijk op een webshop? --> reviews en beoordelingen
- Hoe beoordeelt u de Euro Funcenter webshop op deze functies? --> reviews en beoordelingen
Op deze manier kan ik zien wat mensen belangrijk vinden en waar er verbeterpunten liggen, of niet.
Weet iemand een mooie duidelijke manier om naast elkaar dit aan te tonen in SPSS? ik kom er zelf niet zo goed uit namelijk. Dus bijvoorbeeld:
100 mensen vinden reviews en beoordelingen zeer belangrijk
80 mensen vinden de reviews en beoordelingen op de webshop matig.
enzovoort.
Ik hoop dat jullie me kunnen helpen!
Op dit moment ben ik bezig met mijn afstudeeronderzoek en heb een vraag over een SPSS analyse.
Ik doe een onderzoek naar welke behoeften mensen hebben op een webshop en in de fysieke winkel, bijvoorbeeld, in welke mate hebben consumenten behoefte aan reviews op een webshop, of het product aanraken in de winkel etc.
Ook vraag ik in de enquête in welke mate zij de winkel/webshop beoordelen op deze punten.
Zo heb ik 2 vragen gemeten op basis van een 5 punt likert schaal:
- In welke mate vindt u de volgende functies belangrijk op een webshop? --> reviews en beoordelingen
- Hoe beoordeelt u de Euro Funcenter webshop op deze functies? --> reviews en beoordelingen
Op deze manier kan ik zien wat mensen belangrijk vinden en waar er verbeterpunten liggen, of niet.
Weet iemand een mooie duidelijke manier om naast elkaar dit aan te tonen in SPSS? ik kom er zelf niet zo goed uit namelijk. Dus bijvoorbeeld:
100 mensen vinden reviews en beoordelingen zeer belangrijk
80 mensen vinden de reviews en beoordelingen op de webshop matig.
enzovoort.
Ik hoop dat jullie me kunnen helpen!
Analyze -> descriptive statistics -> frequenciesquote:Op woensdag 2 juli 2014 11:51 schreef surfertjejesper het volgende:
Beste SPSS helden,
Op dit moment ben ik bezig met mijn afstudeeronderzoek en heb een vraag over een SPSS analyse.
Ik doe een onderzoek naar welke behoeften mensen hebben op een webshop en in de fysieke winkel, bijvoorbeeld, in welke mate hebben consumenten behoefte aan reviews op een webshop, of het product aanraken in de winkel etc.
Ook vraag ik in de enquête in welke mate zij de winkel/webshop beoordelen op deze punten.
Zo heb ik 2 vragen gemeten op basis van een 5 punt likert schaal:
- In welke mate vindt u de volgende functies belangrijk op een webshop? --> reviews en beoordelingen
- Hoe beoordeelt u de Euro Funcenter webshop op deze functies? --> reviews en beoordelingen
Op deze manier kan ik zien wat mensen belangrijk vinden en waar er verbeterpunten liggen, of niet.
Weet iemand een mooie duidelijke manier om naast elkaar dit aan te tonen in SPSS? ik kom er zelf niet zo goed uit namelijk. Dus bijvoorbeeld:
100 mensen vinden reviews en beoordelingen zeer belangrijk
80 mensen vinden de reviews en beoordelingen op de webshop matig.
enzovoort.
Ik hoop dat jullie me kunnen helpen!
Als je zorgt dat je in je variabelen scherm de labels van de values hebt aangepast naar de benamingen die je noemt kun je op deze manier een tabel krijgen met de aantallen die je zoekt.
Als je eerst nog op Charts klikt (voor je op OK klikt) dan kun je nog kiezen uit wat grafiekjes.
Klopt! Deze manier had ik eerst ook. Alleen ik dacht, misschien is er een mooiere manier om dit naast elkaar weer te geven. Zodat je in een snelle oogopslag kan zien bv: 80% vind reviews 'zeer belangrijk', maar 70% beoordeeld bedrijf xx op dit punt 'matig'. Dan weet je dat hier verbeterpunten liggen.quote:
[..]
Analyze -> descriptive statistics -> frequencies
Als je zorgt dat je in je variabelen scherm de labels van de values hebt aangepast naar de benamingen die je noemt kun je op deze manier een tabel krijgen met de aantallen die je zoekt.
Als je eerst nog op Charts klikt (voor je op OK klikt) dan kun je nog kiezen uit wat grafiekjes.
ik weet niet of dit mogelijk is, of is het verstandiger om het gewoon simpel te houden
In ieder geval bedankt voor je tip alvast!
Ah op die manier. Dan zou ik op basis van de frequency tabellen de data in Excel plaatsen en op die manier grafieken maken. Het zal vast ook kunnen in SPSS, maar ik ben niet zo thuis in de Chartbuilder.quote:
[..]
Klopt! Deze manier had ik eerst ook. Alleen ik dacht, misschien is er een mooiere manier om dit naast elkaar weer te geven. Zodat je in een snelle oogopslag kan zien bv: 80% vind reviews 'zeer belangrijk', maar 70% beoordeeld bedrijf xx op dit punt 'matig'. Dan weet je dat hier verbeterpunten liggen.
ik weet niet of dit mogelijk is, of is het verstandiger om het gewoon simpel te houden
In ieder geval bedankt voor je tip alvast!
Ik ben bijna klaar met het afronden van mijn masterscriptie, maar hik al enige weken tegen hetzelfde probleem aan.
Wat ik heb: iedere respondent kreeg 3 namen onder ogen te zien, OF alle 3 in het Engels OF alle 3 in het Nederlands. Respondenten zelf verschilden qua nationaliteit: het waren Nederlanders of Belgen. Per voorgelegde naam gaven zij hun mening, die vervolgens zijn gecodeerd naar 0 = negatief, 1 = neutraal en 2 = positief. In totaal heb ik 155 (respondenten) x 3 (voorgelegde namen) = 465 meningen.
Wat ik wil: iets zinnigs kunnen zeggen over eventuele verschillen in aantallen. Ik wil in eerste instantie het aantal negatieve, neutrale en positieve meningen vergelijken tussen de Engelse en de Nederlandse versie. Kijken of deze verschillen in totale aantal en in aantal negatieve, neutrale of positieve meningen. Tenslotte zou ik ook nog willen kijken in hoeverre de meningen verschillen als het aankomt op nationaliteit; dus verschilt het totale aantal meningen en het aantal negatieve, neutrale en positieve meningen tussen Belgen en Nederlanders.
Kan iemand mij hiermee helpen?
UPDATE: Ter verduidelijking onderstaande uitkomst van een chi-kwadraat. Kan ik hier nu iets zeggen over dat de totale aantallen significant verschillen. Of ook welke onderling verschillen?
[ Bericht 11% gewijzigd door Jiveje op 08-07-2014 12:16:57 ]
Wat ik heb: iedere respondent kreeg 3 namen onder ogen te zien, OF alle 3 in het Engels OF alle 3 in het Nederlands. Respondenten zelf verschilden qua nationaliteit: het waren Nederlanders of Belgen. Per voorgelegde naam gaven zij hun mening, die vervolgens zijn gecodeerd naar 0 = negatief, 1 = neutraal en 2 = positief. In totaal heb ik 155 (respondenten) x 3 (voorgelegde namen) = 465 meningen.
Wat ik wil: iets zinnigs kunnen zeggen over eventuele verschillen in aantallen. Ik wil in eerste instantie het aantal negatieve, neutrale en positieve meningen vergelijken tussen de Engelse en de Nederlandse versie. Kijken of deze verschillen in totale aantal en in aantal negatieve, neutrale of positieve meningen. Tenslotte zou ik ook nog willen kijken in hoeverre de meningen verschillen als het aankomt op nationaliteit; dus verschilt het totale aantal meningen en het aantal negatieve, neutrale en positieve meningen tussen Belgen en Nederlanders.
Kan iemand mij hiermee helpen?
UPDATE: Ter verduidelijking onderstaande uitkomst van een chi-kwadraat. Kan ik hier nu iets zeggen over dat de totale aantallen significant verschillen. Of ook welke onderling verschillen?

[ Bericht 11% gewijzigd door Jiveje op 08-07-2014 12:16:57 ]
Als ik een Mann-Whitney U test doe met een geïmputeerde dataset, krijg ik wel netjes de P-waarden voor mijn originele data en elke imputatiestap (10), maar ik krijg geen P-waarden voor mijn 'pooled' dataset. Terwijl ik wel ranks krijg voor de pooled data.
Waarom krijg ik hiervoor geen p-waarde en hoe kan ik ervoor zorgen dat ik die wel krijg?
Als ik een two-sample t-test doe, krijg ik wel een p-waarde voor de pooled data, maar dat is natuurlijk niet helemaal netjes, omdat ik niet parametrisch mag testen.
Waarom krijg ik hiervoor geen p-waarde en hoe kan ik ervoor zorgen dat ik die wel krijg?
Als ik een two-sample t-test doe, krijg ik wel een p-waarde voor de pooled data, maar dat is natuurlijk niet helemaal netjes, omdat ik niet parametrisch mag testen.
Een chi-square test alleen of er verschillen zijn, maar niet waar die verschillen zitten.quote:
Ik ben bijna klaar met het afronden van mijn masterscriptie, maar hik al enige weken tegen hetzelfde probleem aan.
Wat ik heb: iedere respondent kreeg 3 namen onder ogen te zien, OF alle 3 in het Engels OF alle 3 in het Nederlands. Respondenten zelf verschilden qua nationaliteit: het waren Nederlanders of Belgen. Per voorgelegde naam gaven zij hun mening, die vervolgens zijn gecodeerd naar 0 = negatief, 1 = neutraal en 2 = positief. In totaal heb ik 155 (respondenten) x 3 (voorgelegde namen) = 465 meningen.
Wat ik wil: iets zinnigs kunnen zeggen over eventuele verschillen in aantallen. Ik wil in eerste instantie het aantal negatieve, neutrale en positieve meningen vergelijken tussen de Engelse en de Nederlandse versie. Kijken of deze verschillen in totale aantal en in aantal negatieve, neutrale of positieve meningen. Tenslotte zou ik ook nog willen kijken in hoeverre de meningen verschillen als het aankomt op nationaliteit; dus verschilt het totale aantal meningen en het aantal negatieve, neutrale en positieve meningen tussen Belgen en Nederlanders.
Kan iemand mij hiermee helpen?
UPDATE: Ter verduidelijking onderstaande uitkomst van een chi-kwadraat. Kan ik hier nu iets zeggen over dat de totale aantallen significant verschillen. Of ook welke onderling verschillen?
[ afbeelding ]
Het gemakkelijkste is om een chi-square uit te voeren voor elk los contrast.
Dus contrast 1: positief vs de rest
Contrast 2: negatief vs de rest
en eventueel (ligt aan je hypothese) neutraal vs de rest.
Wat bedoel je met de pooled data? Kun je de output posten?quote:
Als ik een Mann-Whitney U test doe met een geïmputeerde dataset, krijg ik wel netjes de P-waarden voor mijn originele data en elke imputatiestap (10), maar ik krijg geen P-waarden voor mijn 'pooled' dataset. Terwijl ik wel ranks krijg voor de pooled data.
Waarom krijg ik hiervoor geen p-waarde en hoe kan ik ervoor zorgen dat ik die wel krijg?
Als ik een two-sample t-test doe, krijg ik wel een p-waarde voor de pooled data, maar dat is natuurlijk niet helemaal netjes, omdat ik niet parametrisch mag testen.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Het gaat in dit geval om een Wilcoxon signed ranks test, maar hetzelfde probleem doet zich eigenlijk voor bij alle non-parametrische testen:
Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.


Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.
Whoops sorry, verkeerde knopjequote:
Het gaat in dit geval om een Wilcoxon signed ranks test, maar hetzelfde probleem doet zich eigenlijk voor bij alle non-parametrische testen:
Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.
Ik ben er iets meer ingedoken, en Wilkinson is voor dependent samples (dus elke case wordt 2x gemeten, bv voor en na interventie), ik denk dus niet dat dat de juiste test voor je is.quote:
Het gaat in dit geval om een Wilcoxon signed ranks test, maar hetzelfde probleem doet zich eigenlijk voor bij alle non-parametrische testen:
[ afbeelding ]
[ afbeelding ]
Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.
Welke test wel zou moeten werken is de Mann Whitney. Ik heb zelf net wat data gesimuleerd en dan werkt het gewoon. Misschien heb je je dataset niet goed opgezet? (of misschien begrijp ik verkeerd wat je wilt doen
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik weet dat een Wilcoxon een test is voor dependent samples. Ik heb op dezelfde data zowel een Wilcoxon signed ranks test als een Mann-Whitney U test gedaan, om de within and between groups differences te testen. Daar ging m'n vraag ook niet over.quote:
[..]
Ik ben er iets meer ingedoken, en Wilkinson is voor dependent samples (dus elke case wordt 2x gemeten, bv voor en na interventie), ik denk dus niet dat dat de juiste test voor je is.
Welke test wel zou moeten werken is de Mann Whitney. Ik heb zelf net wat data gesimuleerd en dan werkt het gewoon. Misschien heb je je dataset niet goed opgezet? (of misschien begrijp ik verkeerd wat je wilt doen)
Ik wil weten waarom ik geen testuitslagen krijg voor m'n gepoolde data na imputatie. Ik heb namelijk een p-waarde voor de originele data (voordat er geïmputeerd is voor missing data) en ik wil dus een p-waarde voor m'n dataset na imputatie, dit is de 'pooled data'. Hiervoor krijg ik dus wel descriptives en ranks, maar geen p-waarde.
Nu begin ik het te begrijpen, helaas geen goed nieuws, dat kan niet in SPSS. Je kunt kijken of je een macro er voor kunt vinden.quote:
[..]
Ik weet dat een Wilcoxon een test is voor dependent samples. Ik heb op dezelfde data zowel een Wilcoxon signed ranks test als een Mann-Whitney U test gedaan, om de within and between groups differences te testen. Daar ging m'n vraag ook niet over.
Ik wil weten waarom ik geen testuitslagen krijg voor m'n gepoolde data na imputatie. Ik heb namelijk een p-waarde voor de originele data (voordat er geïmputeerd is voor missing data) en ik wil dus een p-waarde voor m'n dataset na imputatie, dit is de 'pooled data'. Hiervoor krijg ik dus wel descriptives en ranks, maar geen p-waarde.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
quote:
[..]
Nu begin ik het te begrijpen, helaas geen goed nieuws, dat kan niet in SPSS. Je kunt kijken of je een macro er voor kunt vinden.
nou je ik weet het ook niet zeker ik heb nog nooit met imputed data gewerkt, internet zegt allen dat het niet kan. Hier kun je misschien meer vinden: http://jeremyjaytaylor.sq(...)discuss/post/1436944quote:
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Bij partiële correlatie heb ik gevonden dat Y significant negatief gecorreleerd is met X, gecorrigeerd voor W en Z. Om dit visueel weer te geven, gebruik ik een lineaire regressie met Y als dependent variable en X, W en Z als independent variables. Ik laat alle partial plots weergeven.
Echter, X heeft in mijn dataset een range van 38-1120, maar in mijn partial plot krijg ik ook punten in de puntenwolk met een negatieve X-waarde. Als ik mijn X-as wil aanpassen in de chart editor, geeft 'ie aan dat de range in de data loopt van -39 tot 43.
Als ik toch de minimum X-as op 0 zet, is het visuele effect van mijn correlatie weg.
Hoe komt het dat ik een heel andere range van mijn X krijg, en hoe los ik dit op?
Echter, X heeft in mijn dataset een range van 38-1120, maar in mijn partial plot krijg ik ook punten in de puntenwolk met een negatieve X-waarde. Als ik mijn X-as wil aanpassen in de chart editor, geeft 'ie aan dat de range in de data loopt van -39 tot 43.
Als ik toch de minimum X-as op 0 zet, is het visuele effect van mijn correlatie weg.
Hoe komt het dat ik een heel andere range van mijn X krijg, en hoe los ik dit op?
Kun je even screenshotje posten van regressieresultaten en de plotjes?quote:
Bij partiële correlatie heb ik gevonden dat Y significant negatief gecorreleerd is met X, gecorrigeerd voor W en Z. Om dit visueel weer te geven, gebruik ik een lineaire regressie met Y als dependent variable en X, W en Z als independent variables. Ik laat alle partial plots weergeven.
Echter, X heeft in mijn dataset een range van 38-1120, maar in mijn partial plot krijg ik ook punten in de puntenwolk met een negatieve X-waarde. Als ik mijn X-as wil aanpassen in de chart editor, geeft 'ie aan dat de range in de data loopt van -39 tot 43.
Als ik toch de minimum X-as op 0 zet, is het visuele effect van mijn correlatie weg.
Hoe komt het dat ik een heel andere range van mijn X krijg, en hoe los ik dit op?
Ik vermoed overigens dat het komt omdat je x-as niet variabele X weergeeft maar de residuals van X en als dat zo is hoef je dat natuurlijk niet op te lossen
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-



Zo te zien komt dat doordat alleen de partial effecten van beide variabelen geplot zijn (zoals eigenlijk ook hoort). Ik denk dat het mogelijk is om de residuals op te slaan in je dataset dan zou je zelf een plotje IQ vs residuals DV kunnen maken.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Met andere woorden, je kan niet IQ vs DV maken, gecorrigeerd voor een aantal variabelen. Dan moet je dus altijd de residuals plotten?quote:
Zo te zien komt dat doordat alleen de partial effecten van beide variabelen geplot zijn (zoals eigenlijk ook hoort). Ik denk dat het mogelijk is om de residuals op te slaan in je dataset dan zou je zelf een plotje IQ vs residuals DV kunnen maken.
Ola senors en senoritas. Op deze mooie zomerse dag ben ik eens bezig gegaan met SPSS voor mijn masterscriptie, en ik loop eigenlijk al gelijk vast..
Ik wil mijn respondenten selecteren op twee variabelen; doe je X op school of buiten school? Deze twee variabelen lopen van 1 t/m 4 (1 = nooit, 2 = 1 of 2 keer, 3 = +- 1x per week en 4 = meerdere keren per week).
Ik wil mijn respondenten selecteren op dat zij zowel op variabele één als op twee, 2 of hoger geantwoord hebben. Dus ik vul bij select cases in: Var1 = 2 | 3 | 4 & Var2 = 2 | 3 | 4 En vervolgens vertelt SPSS me dat "The sequence of operators found is invalid. Check the expression for ommited or extra operands, operators, and parentheses. Maar ik kan dus echt niet verzinnen wat ik anders zou moeten doen; nergens staat een extra spatie oid. En als ik >1 i.p.v. 2 | 3 | 4 invul krijg ik precies hetzelfde... Wie o wie kan mij helpen?
Ik wil mijn respondenten selecteren op twee variabelen; doe je X op school of buiten school? Deze twee variabelen lopen van 1 t/m 4 (1 = nooit, 2 = 1 of 2 keer, 3 = +- 1x per week en 4 = meerdere keren per week).
Ik wil mijn respondenten selecteren op dat zij zowel op variabele één als op twee, 2 of hoger geantwoord hebben. Dus ik vul bij select cases in: Var1 = 2 | 3 | 4 & Var2 = 2 | 3 | 4 En vervolgens vertelt SPSS me dat "The sequence of operators found is invalid. Check the expression for ommited or extra operands, operators, and parentheses. Maar ik kan dus echt niet verzinnen wat ik anders zou moeten doen; nergens staat een extra spatie oid. En als ik >1 i.p.v. 2 | 3 | 4 invul krijg ik precies hetzelfde... Wie o wie kan mij helpen?
SPSS snapt "Var1 = 2 | 3 | 4" niet.
Dat moet iets zijn als:
(Var1 = 2 | Var1 = 3 | Var1 = 4) & (...)
Dat moet iets zijn als:
(Var1 = 2 | Var1 = 3 | Var1 = 4) & (...)
Aldus.
Kun je wel maar 1 van de twee variabelen selecteren zoals je wil, of komt er dan ook een foutmelding?quote:
Ola senors en senoritas. Op deze mooie zomerse dag ben ik eens bezig gegaan met SPSS voor mijn masterscriptie, en ik loop eigenlijk al gelijk vast..
Ik wil mijn respondenten selecteren op twee variabelen; doe je X op school of buiten school? Deze twee variabelen lopen van 1 t/m 4 (1 = nooit, 2 = 1 of 2 keer, 3 = +- 1x per week en 4 = meerdere keren per week).
Ik wil mijn respondenten selecteren op dat zij zowel op variabele één als op twee, 2 of hoger geantwoord hebben. Dus ik vul bij select cases in: Var1 = 2 | 3 | 4 & Var2 = 2 | 3 | 4 En vervolgens vertelt SPSS me dat "The sequence of operators found is invalid. Check the expression for ommited or extra operands, operators, and parentheses. Maar ik kan dus echt niet verzinnen wat ik anders zou moeten doen; nergens staat een extra spatie oid. En als ik >1 i.p.v. 2 | 3 | 4 invul krijg ik precies hetzelfde... Wie o wie kan mij helpen?
Ga ik even proberen, thanksquote:Op dinsdag 5 augustus 2014 15:24 schreef Z het volgende:
SPSS snapt "Var1 = 2 | 3 | 4" niet.
Dat moet iets zijn als:
(Var1 = 2 | Var1 = 3 | Var1 = 4) & (...)
Eentje lukt wel gewoon inderdaad.quote:
[..]
Kun je wel maar 1 van de twee variabelen selecteren zoals je wil, of komt er dan ook een foutmelding?
quote:
SPSS snapt "Var1 = 2 | 3 | 4" niet.
Dat moet iets zijn als:
(Var1 = 2 | Var1 = 3 | Var1 = 4) & (...)
Alleen moest & in mijn geval | worden, maar dat is mijn eigen fout
Even geprobeerd, als je ook data hebt met veel mogelijkheden: VAR1>1 AND VAR2>1 zou ook moeten werken.quote:
[..]Je bent geweldig
Dit was de oplossing!
Alleen moest & in mijn geval | worden, maar dat is mijn eigen fout
| 1 2 3 4 5 6 7 8 | DATASET ACTIVATE DataSet0. USE ALL. COMPUTE filter_$=(VAR00001>1 AND VAR00002>1). VARIABLE LABELS filter_$ 'VAR00001>1 AND VAR00002>1 (FILTER)'. VALUE LABELS filter_$ 0 'Not Selected' 1 'Selected'. FORMATS filter_$ (f1.0). FILTER BY filter_$. EXECUTE. |
Die had ik ook geprobeerd inderdaad, maar die pakte hij ook niet bij de tweede variabele.quote:
[..]
Even geprobeerd, als je ook data hebt met veel mogelijkheden: VAR1>1 AND VAR2>1 zou ook moeten werken.
[ code verwijderd ]
Oh ja, daar kan ik me vaag iets van herinneren inderdaad. Het is al weer een tijdje geleden dat ik met SPSS heb gewerkt, dus ik moet er echt weer even inkomen.quote:
En als het verschillende waarden moeten zijn ANY(var1,3,6,8)
Super bedankt voor de snelle reacties allemaal!

Beste Fok-buddies(  ),
),
Ik ben voor mijn afstudeeronderzoek gestrand bij de regressie-analyse. Mijn onderzoeksvraag is:
Welke factoren zijn van invloed op de merkmeerwaarde?
Merkmeerwaarde bestaat uit 5 onafhankelijke variabelen (gehaald uit de theorie), namelijk:
• Merkidentiteit
• Merkbetekenis
• Merkrespons
• Merkrelatie
• Content
Deze 5 variabelen heb ik in mijn survey verwerkt in 42 vragen die allen te beantwoorden zijn op basis van een 5-puntsschaal. Vervolgens heb ik een Cronbach's Alpha toegepast op alle factoren en vervolgens de vragen in een schaal geplaatst. Nu rest dus alleen nog een Regressie-analyse om er achter te komen in hoeverre de vijf factoren van invloed zijn op de merkmeerwaarde. ... En zodat ik te weten kom welke factor het meeste van invloed is, zodat ik daar mijn aanbevelingen op kan baseren.
Echter krijg ik bij het uitdraaien van de Regressie-analyse de volgende warning:
"For the final model with dependent variable Merkmeerwaarde, influence statistics can not be computed because the fit is perfect."
Ik begrijp dat dit komt omdat de afhankelijke variabele (Merkmeerwaarde) bestaat uit de 5 onafhankelijke variabelen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content).
Mijn vraag: Hoe kan ik dit oplossen, zodat ik alsnog iets kan zeggen over de invloed van de 5 (afzonderlijke) onafhankelijke variabelen op de afhankelijke variabele? (Welke variabele heeft de meeste invloed / is de sterkste predictor?)
|
|
Ik heb zeg maar 0 les gehad in SPSS en er wordt dan ook niet verwacht dat ik een uitgebreide, wiskundige analyse in mijn scriptie verwerk. Hoe simpeler, hoe beter!
Ik moet uiteraard wel een antwoord kunnen geven op mijn onderzoeksvraag. Ik hoop dat hier iemand een oplossing heeft. In elk geval alvast bedankt!
Ik ben voor mijn afstudeeronderzoek gestrand bij de regressie-analyse. Mijn onderzoeksvraag is:
Welke factoren zijn van invloed op de merkmeerwaarde?
Merkmeerwaarde bestaat uit 5 onafhankelijke variabelen (gehaald uit de theorie), namelijk:
• Merkidentiteit
• Merkbetekenis
• Merkrespons
• Merkrelatie
• Content
Deze 5 variabelen heb ik in mijn survey verwerkt in 42 vragen die allen te beantwoorden zijn op basis van een 5-puntsschaal. Vervolgens heb ik een Cronbach's Alpha toegepast op alle factoren en vervolgens de vragen in een schaal geplaatst. Nu rest dus alleen nog een Regressie-analyse om er achter te komen in hoeverre de vijf factoren van invloed zijn op de merkmeerwaarde. ... En zodat ik te weten kom welke factor het meeste van invloed is, zodat ik daar mijn aanbevelingen op kan baseren.
Echter krijg ik bij het uitdraaien van de Regressie-analyse de volgende warning:
"For the final model with dependent variable Merkmeerwaarde, influence statistics can not be computed because the fit is perfect."
Ik begrijp dat dit komt omdat de afhankelijke variabele (Merkmeerwaarde) bestaat uit de 5 onafhankelijke variabelen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content).
Mijn vraag: Hoe kan ik dit oplossen, zodat ik alsnog iets kan zeggen over de invloed van de 5 (afzonderlijke) onafhankelijke variabelen op de afhankelijke variabele? (Welke variabele heeft de meeste invloed / is de sterkste predictor?)
|
|
Ik heb zeg maar 0 les gehad in SPSS en er wordt dan ook niet verwacht dat ik een uitgebreide, wiskundige analyse in mijn scriptie verwerk. Hoe simpeler, hoe beter!
Ik moet uiteraard wel een antwoord kunnen geven op mijn onderzoeksvraag. Ik hoop dat hier iemand een oplossing heeft. In elk geval alvast bedankt!
Heb je ze wel allemaal apart in je regressie analyse gedaan, dus een voor een ipv allemaal tegelijk?quote:
Beste Fok-buddies(
Ik ben voor mijn afstudeeronderzoek gestrand bij de regressie-analyse. Mijn onderzoeksvraag is:
Welke factoren zijn van invloed op de merkmeerwaarde?
Merkmeerwaarde bestaat uit 5 onafhankelijke variabelen (gehaald uit de theorie), namelijk:
• Merkidentiteit
• Merkbetekenis
• Merkrespons
• Merkrelatie
• Content
Deze 5 variabelen heb ik in mijn survey verwerkt in 42 vragen die allen te beantwoorden zijn op basis van een 5-puntsschaal. Vervolgens heb ik een Cronbach's Alpha toegepast op alle factoren en vervolgens de vragen in een schaal geplaatst. Nu rest dus alleen nog een Regressie-analyse om er achter te komen in hoeverre de vijf factoren van invloed zijn op de merkmeerwaarde. ... En zodat ik te weten kom welke factor het meeste van invloed is, zodat ik daar mijn aanbevelingen op kan baseren.
Echter krijg ik bij het uitdraaien van de Regressie-analyse de volgende warning:
"For the final model with dependent variable Merkmeerwaarde, influence statistics can not be computed because the fit is perfect."
Ik begrijp dat dit komt omdat de afhankelijke variabele (Merkmeerwaarde) bestaat uit de 5 onafhankelijke variabelen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content).
Mijn vraag: Hoe kan ik dit oplossen, zodat ik alsnog iets kan zeggen over de invloed van de 5 (afzonderlijke) onafhankelijke variabelen op de afhankelijke variabele? (Welke variabele heeft de meeste invloed / is de sterkste predictor?)
|
|
Ik heb zeg maar 0 les gehad in SPSS en er wordt dan ook niet verwacht dat ik een uitgebreide, wiskundige analyse in mijn scriptie verwerk. Hoe simpeler, hoe beter!
Ik moet uiteraard wel een antwoord kunnen geven op mijn onderzoeksvraag. Ik hoop dat hier iemand een oplossing heeft. In elk geval alvast bedankt!
Edit: Ik ben er al uit en de vraag was iets te herkenbaar, dus hij is weer weg
[ Bericht 75% gewijzigd door fh101 op 05-08-2014 19:26:28 ]
[ Bericht 75% gewijzigd door fh101 op 05-08-2014 19:26:28 ]
Ja, dat heb ik gedaan maar zodra ik de vijfde dan toevoeg krijg ik de foutmelding. Dat komt waarschijnlijk omdat de 5 onafhankelijke variabelen samen de afhankelijke variabele vormen..quote:
[..]
Heb je ze wel allemaal apart in je regressie analyse gedaan, dus een voor een ipv allemaal tegelijk?
Dat klopt. Dit heet colinneariteit.quote:
[..]
Ja, dat heb ik gedaan maar zodra ik de vijfde dan toevoeg krijg ik de foutmelding. Dat komt waarschijnlijk omdat de 5 onafhankelijke variabelen samen de afhankelijke variabele vormen..
Overigens zegt Cronbachs alfa niets over onderliggende factoren, maar alleen iets over betrouwbaarheid van een schaal (mits je steekproef groot genoeg is, anders is het een slechte schatter maar dat geldt eigenlijk altijd bij statistiek).
Wat je hier wil doen is een zinloze exercitie, omdat je afhankelijke variabele bestaat uit de onafhankelijke variabelen. Dit zegt uiteindelijk dus niets nuttigs.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Cronbachs Alfa is inderdaad om de betrouwbaarheid van de schalen te meten, daar heb ik het ook voor gebruiktquote:
[..]
Dat klopt. Dit heet colinneariteit.
Overigens zegt Cronbachs alfa niets over onderliggende factoren, maar alleen iets over betrouwbaarheid van een schaal (mits je steekproef groot genoeg is, anders is het een slechte schatter maar dat geldt eigenlijk altijd bij statistiek).
Wat je hier wil doen is een zinloze exercitie, omdat je afhankelijke variabele bestaat uit de onafhankelijke variabelen. Dit zegt uiteindelijk dus niets nuttigs.
Hmm, is er geen andere methode om alsnog de gewenste gegevens uitgedraaid te krijgen?
Beste Fokkers, (Dubbelpost, mn topic hierover mag dan wel weg)
Google kan me niet helpen, jullie misschien.
Ik heb in excel nogal wat data gekregen (17.000 respondenten). Nu heb ik dat in excel allemaal wat leesbaarder gemaakt en vervolgens geëxporteerd naar SPSS.
In SPSS is (bijna) alles heel mooi. Alleen 1 variabele heeft als type "string" met een nominal measure maar die moet "numeric" met een linear measure zijn. Als ik dat verander in the variable view vervallen opeens een groot aantal responsen.
Hoe kan ik deze variabele wel veranderen in numeriek zodat ik er wel statistische testen mee kan doen.
Let op: alle data die ingevuld is bij de variabele is al numeriek (1-100). Alleen de instellingen kloppen dus niet.
Ik kijk uit naar reacties!
Google kan me niet helpen, jullie misschien.
Ik heb in excel nogal wat data gekregen (17.000 respondenten). Nu heb ik dat in excel allemaal wat leesbaarder gemaakt en vervolgens geëxporteerd naar SPSS.
In SPSS is (bijna) alles heel mooi. Alleen 1 variabele heeft als type "string" met een nominal measure maar die moet "numeric" met een linear measure zijn. Als ik dat verander in the variable view vervallen opeens een groot aantal responsen.
Hoe kan ik deze variabele wel veranderen in numeriek zodat ik er wel statistische testen mee kan doen.
Let op: alle data die ingevuld is bij de variabele is al numeriek (1-100). Alleen de instellingen kloppen dus niet.
Ik kijk uit naar reacties!
Je vraag is heel erg raar. Je hebt 42 vragen die allemaal voor 1/42 meetellen in een schaal. Nu wil je een regressie doen om te kijken hoeveel die vragen meetellen, wat dus per definitie 1/42 is per vraag.quote:
[..]
Cronbachs Alfa is inderdaad om de betrouwbaarheid van de schalen te meten, daar heb ik het ook voor gebruikt. Maar ik moet nu dus de regressie analyse toepassen om te bekijken in hoeverre de factoren van invloed zijn op de merkmeerwaarde.
Hmm, is er geen andere methode om alsnog de gewenste gegevens uitgedraaid te krijgen?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Komt het toevalllig omdat de antwoorden met punten als decimalen gegeven zijn in excell maar spss met commas werkt oid? Dat is bij mij meestal het probleem. De responses die vervallen, vervallen meestal omdat spss ze niet omgezet krijgt in een nummer, daar zou het probleem dus moeten liggen. Misschien dat er spaties in staat of iets anders?quote:
Beste Fokkers, (Dubbelpost, mn topic hierover mag dan wel weg)
Google kan me niet helpen, jullie misschien.
Ik heb in excel nogal wat data gekregen (17.000 respondenten). Nu heb ik dat in excel allemaal wat leesbaarder gemaakt en vervolgens geëxporteerd naar SPSS.
In SPSS is (bijna) alles heel mooi. Alleen 1 variabele heeft als type "string" met een nominal measure maar die moet "numeric" met een linear measure zijn. Als ik dat verander in the variable view vervallen opeens een groot aantal responsen.
Hoe kan ik deze variabele wel veranderen in numeriek zodat ik er wel statistische testen mee kan doen.
Let op: alle data die ingevuld is bij de variabele is al numeriek (1-100). Alleen de instellingen kloppen dus niet.
Ik kijk uit naar reacties!
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
quote:quote:
0s.gif Op woensdag 6 augustus 2014 17:04 schreef Wallcrawler-GP het volgende:
Beste Fokkers, (Dubbelpost, mn topic hierover mag dan wel weg)
Google kan me niet helpen, jullie misschien.
Ik heb in excel nogal wat data gekregen (17.000 respondenten). Nu heb ik dat in excel allemaal wat leesbaarder gemaakt en vervolgens geëxporteerd naar SPSS.
In SPSS is (bijna) alles heel mooi. Alleen 1 variabele heeft als type "string" met een nominal measure maar die moet "numeric" met een linear measure zijn. Als ik dat verander in the variable view vervallen opeens een groot aantal responsen.
Hoe kan ik deze variabele wel veranderen in numeriek zodat ik er wel statistische testen mee kan doen.
Let op: alle data die ingevuld is bij de variabele is al numeriek (1-100). Alleen de instellingen kloppen dus niet.
Ik kijk uit naar reacties!
Super bedankt! Met zoeken en vervangen de punten voor komma's vervangen en daarna kon ik de variabele wel numeriek maken:)quote:Komt het toevalllig omdat de antwoorden met punten als decimalen gegeven zijn in excell maar spss met commas werkt oid? Dat is bij mij meestal het probleem. De responses die vervallen, vervallen meestal omdat spss ze niet omgezet krijgt in een nummer, daar zou het probleem dus moeten liggen. Misschien dat er spaties in staat of iets anders?
Wel gek want in excel (het originele bestand) stonden alle variabelen gelijk. Allemaal met komma. Alleen voor deze ene variabele maakt spss er een punt van. Maar geen punt, het is opgelost. Bedankt Oompaloompa!
Volgens mij heb ik het fout uitgelegd dan. Ik heb inderdaad 42 vragen, die zijn opgedeeld in 5 schalen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content). Nu wil ik een regressie-analyse inzetten om erachter te komen in hoeverre elke schaal van invloed is op de afhankelijke variabele (merkmeerwaarde) en welke schaal het meest van invloed is.quote:
[..]
Je vraag is heel erg raar. Je hebt 42 vragen die allemaal voor 1/42 meetellen in een schaal. Nu wil je een regressie doen om te kijken hoeveel die vragen meetellen, wat dus per definitie 1/42 is per vraag.
Maar omdat de 5 schalen samen de afhankelijke variabele vormen, geeft SPSS de foutmelding "the fit is perfect". Vandaar mijn vraag of ik op een andere manier kan aantonen in hoeverre de 5 schalen van invloed zijn
Hopelijk is het zo wat duidelijker
Begrijp ik het goed dat elk van die subschalen gemeten wordt met ongeveer 8 van de 42 vragen en dat het alle 42 vragen samen merkmeerwaarde meten?quote:
[..]
Volgens mij heb ik het fout uitgelegd dan. Ik heb inderdaad 42 vragen, die zijn opgedeeld in 5 schalen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content). Nu wil ik een regressie-analyse inzetten om erachter te komen in hoeverre elke schaal van invloed is op de afhankelijke variabele (merkmeerwaarde) en welke schaal het meest van invloed is.
Maar omdat de 5 schalen samen de afhankelijke variabele vormen, geeft SPSS de foutmelding "the fit is perfect". Vandaar mijn vraag of ik op een andere manier kan aantonen in hoeverre de 5 schalen van invloed zijn
Hopelijk is het zo wat duidelijker
Ik heb al een tijd geen regressie-analyse meer gedaan, maar meet je daarmee niet doorgaans de invloed van andere factoren op de afhankelijke variabele? (Factoren zoals leeftijd, salarisschaal etc.)quote:
[..]
Volgens mij heb ik het fout uitgelegd dan. Ik heb inderdaad 42 vragen, die zijn opgedeeld in 5 schalen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content). Nu wil ik een regressie-analyse inzetten om erachter te komen in hoeverre elke schaal van invloed is op de afhankelijke variabele (merkmeerwaarde) en welke schaal het meest van invloed is.
Maar omdat de 5 schalen samen de afhankelijke variabele vormen, geeft SPSS de foutmelding "the fit is perfect". Vandaar mijn vraag of ik op een andere manier kan aantonen in hoeverre de 5 schalen van invloed zijn
Hopelijk is het zo wat duidelijker
Je wil nu analyseren hoe een deel van de afhankelijke variabele deel is van de afhankelijke variabele (zo lijkt het in ieder geval.)
Volgens mij bedoelt hij dat ja.quote:
[..]
Begrijp ik het goed dat elk van die subschalen gemeten wordt met ongeveer 8 van de 42 vragen en dat het alle 42 vragen samen merkmeerwaarde meten?
Moet je niet kijken naar hoeveel elk van de scores op de subschalen de variatie op de totale schaal verklaart? Kom je dan niet bij een ANOVA uit? Daar heb ik eigenlijk geen verstand van, moet ik bekennen.
Ik wil erachter komen in hoeverre de 5 schalen van invloed zijn en welke schaal het meest van invloed is (gezien vanuit de consument).quote:
[..]
Ik heb al een tijd geen regressie-analyse meer gedaan, maar meet je daarmee niet doorgaans de invloed van andere factoren op de afhankelijke variabele? (Factoren zoals leeftijd, salarisschaal etc.)
Je wil nu analyseren hoe een deel van de afhankelijke variabele deel is van de afhankelijke variabele (zo lijkt het in ieder geval.)
Dat weet je al: ~8/42quote:
[..]
Ik wil erachter komen in hoeverre de 5 schalen van invloed zijn
Dit lijkt meer op de vraag die je moet stellen inderdaad.quote:en welke schaal het meest van invloed is (gezien vanuit de consument).
Als ik daarmee kan aantonen welke schaal de respondenten van de survey het belangrijkste vinden en welke de grootste invloed heeft op de totale schaal, dan lijkt me dat zeker een oplossing.quote:
Moet je niet kijken naar hoeveel elk van de scores op de subschalen de variatie op de totale schaal verklaart? Kom je dan niet bij een ANOVA uit? Daar heb ik eigenlijk geen verstand van, moet ik bekennen.
Iemand die dit kan bevestigen?
Maar als bij de eerste schaal alle respondenten bij de 8 vragen "zeer eens" hebben ingevuld, en bij de tweede schaal alle respondenten "zeer oneens" zijn, dan is dat niet dezelfde mate van invloed op de totale schaal?quote:
[..]
Dat weet je al: ~8/42
[..]
Dit lijkt meer op de vraag die je moet stellen inderdaad.
In feite kom ik al een heel eind als ik kan aantonen welke schaal het meest van invloed is. Wat is een gebruikelijke methode om dit te doen?
(sorry als ik sommige termen in de war haal of als ik het niet meteen helemaal begrijp. Zoals gezegd: 0 les gehad in SPSS, dus amper verstand ervan
Welke kant de score op gaat hoort niet de mate van invloed te bepalen. Hoe bereken je die totale schaal? Alle scores van de Likerts bij elkaar opgeteld? De score op de subschalen omgerekend naar percentages en die bij elkaar opgeteld?quote:
[..]
Maar als bij de eerste schaal alle respondenten bij de 8 vragen "zeer eens" hebben ingevuld, en bij de tweede schaal alle respondenten "zeer oneens" zijn, dan is dat niet dezelfde mate van invloed op de totale schaal?
quote:
[..]
Welke kant de score op gaat hoort niet de mate van invloed te bepalen. Hoe bereken je die totale schaal? Alle scores van de Likerts bij elkaar opgeteld? De score op de subschalen omgerekend naar percentages en die bij elkaar opgeteld?
De totale schaal is inderdaad de som van de 5 schalen.quote:
[..]
Welke kant de score op gaat hoort niet de mate van invloed te bepalen. Hoe bereken je die totale schaal? Alle scores van de Likerts bij elkaar opgeteld? De score op de subschalen omgerekend naar percentages en die bij elkaar opgeteld?
Ik heb een Cronbach's alfa uitgevoerd en vervolgens de schalen ingedeeld. Toen wilde ik beginnen met de regressie-analyse, maar kwam ik al snel uit op het probleem.
Ik kan je mijn Output bestand wel even sturen, misschien zie je dan hoe ik het het gedaan. Want ik vind het best lastig uitleggen met mijn beperkte kennis van SPSS
Np, ik heb dit helaas zelf ook veel te vaak meegemaaktquote:
[..]
[..]
Super bedankt! Met zoeken en vervangen de punten voor komma's vervangen en daarna kon ik de variabele wel numeriek maken:)
Wel gek want in excel (het originele bestand) stonden alle variabelen gelijk. Allemaal met komma. Alleen voor deze ene variabele maakt spss er een punt van. Maar geen punt, het is opgelost. Bedankt Oompaloompa!
Maar merkwaarde bestaat toch uit die 5 schalen?quote:
[..]
Volgens mij heb ik het fout uitgelegd dan. Ik heb inderdaad 42 vragen, die zijn opgedeeld in 5 schalen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content). Nu wil ik een regressie-analyse inzetten om erachter te komen in hoeverre elke schaal van invloed is op de afhankelijke variabele (merkmeerwaarde) en welke schaal het meest van invloed is.
Maar omdat de 5 schalen samen de afhankelijke variabele vormen, geeft SPSS de foutmelding "the fit is perfect". Vandaar mijn vraag of ik op een andere manier kan aantonen in hoeverre de 5 schalen van invloed zijn
Hopelijk is het zo wat duidelijker
Dus je hebt 42 vragen die 5 scchalen vormen. Laten we even voor het gemak 8 vragen per schaal nemen. Daarna bestaat je afhankelijke uit de som van de 5 schalen. Dat betekent dus dat elke vraag voor 1/40 invloed op merkwaarde heeft (of elke schaal 20%). Je vraag klopt niet, en daarom geeft SPSS errors. Je beslist namelijk eerst zelf hoeveel invloed elke schaal op merkwaarde heeft omdat je het concept merkwaarde definieert als een combinatie van de schalen.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Okay, bedankt voor je reactie!quote:
[..]
Np, ik heb dit helaas zelf ook veel te vaak meegemaakt
[..]
Maar merkwaarde bestaat toch uit die 5 schalen?
Dus je hebt 42 vragen die 5 scchalen vormen. Laten we even voor het gemak 8 vragen per schaal nemen. Daarna bestaat je afhankelijke uit de som van de 5 schalen. Dat betekent dus dat elke vraag voor 1/40 invloed op merkwaarde heeft (of elke schaal 20%). Je vraag klopt niet, en daarom geeft SPSS errors. Je beslist namelijk eerst zelf hoeveel invloed elke schaal op merkwaarde heeft omdat je het concept merkwaarde definieert als een combinatie van de schalen.
Hoe moet ik het nu oplossen om met mijn verkregen data uit het surveyonderzoek alsnog iets over de merkmeerwaarde te kunnen zeggen?
Hmm dat wordt moeilijk aangezien je merkwaarde hebt gedefinieerd als de combinatie van die schalen. Je zou wel bv kunnen kijken hoe de subschalen onderling verband met elkaar houden en of demografische gegevens bv geslacht / leeftijd invloed hebben. Maar als je wilt weten hoe de schalen samenhangen met merkwaarde had je merkwaarde op een andere, independent, manier moeten meten.quote:
[..]
Okay, bedankt voor je reactie!
Hoe moet ik het nu oplossen om met mijn verkregen data uit het surveyonderzoek alsnog iets over de merkmeerwaarde te kunnen zeggen?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
En een stap terugnemen en de schalen op een andere manier indelen is geen optie?quote:
[..]
Hmm dat wordt moeilijk aangezien je merkwaarde hebt gedefinieerd als de combinatie van die schalen. Je zou wel bv kunnen kijken hoe de subschalen onderling verband met elkaar houden en of demografische gegevens bv geslacht / leeftijd invloed hebben. Maar als je wilt weten hoe de schalen samenhangen met merkwaarde had je merkwaarde op een andere, independent, manier moeten meten.
Onderling verband met de verschillende schalen is niet persé wat ik zoek namelijk. Ik wil weten welk aspect van merkmeerwaarde de respondenten het belangrijkst vinden, zodat de organisatie zich daar op kan focussen. En als ik de resultaten bekijk, dan zie ik dat de meest positieve antwoorden zijn ingevuld bij de schaal content. Hoe laat ik dit zien door middel van een test?
Is er geen andere toets (Mann-Whitney U Test / Pearson R / Anova ??) die ik hiervoor kan inzetten?
Want als het niet lukt via SPSS, dan lijkt het me beter om gewoon de survey resultaten te analyseren en zelf grafieken te maken over hoe positief (of negatief) de respondenten de vragen uit de verschillende vragen hebben beantwoord.
Ik heb voor mijn scriptie onderzoek gedaan naar de volgorde van persoonlijk voornaamwoorden in het Nieuwgrieks door middel van het afnemen van een enquête. Ik heb 5 algemene vragen gesteld om te bepalen of de respondenten tot de doelgroep behoren (of dat de enquête eventueel afgebroken moet worden), uit welke regio van Griekenland de respondent afkomstig is en wat het geslacht en de leeftijd van de respondent is. Vervolgens heb ik 19 zinnen voorgelegd, waarbij de respondenten op een schaal van 1 tot 4 konden kiezen (ja, waarschijnlijk wel, waarschijnlijk niet, nee) in hoeverre het mogelijk was die zinnen te horen in hun omgeving.
Uiteindelijk heeft mijn enquête 92 respondenten opgeleverd. Een voldoende aantal binnen de taalwetenschap. Met een χ2-toets heb ik vervolgens per vraag bepaald in hoeverre de verdeling over de antwoordmogelijkheden willekeurig is (verdeling 23-23-23-23). Er is geen hypothese die getoetst kan worden, omdat er slechts twee halve alinea's over geschreven zijn door twee verschillende auteurs en hun beweringen lijnrecht tegenover elkaar staan. Van de 19 zinnen hield ik er 14 over met p<0,01 2 met 0,01<p<0,05. 1 zin met 0,05<p<0,1 en 2 met p>0,1. Ik heb besloten alledrie deze zinnen buiten het onderzoek te houden.
Ik heb met een ongepaarde t-toets gekeken of er een significant verschil zat tussen mannen en vrouwen om zo deze insignificantie te kunnen verklaren, maar dat leverde niets op. Ook dit verschil was insignificant.
Met de mediaan heb ik vervolgens bepaald of een zin wel of niet aangenomen kan worden als acceptabel. Mediaan 1-2 is acceptabel en mediaan 3-4 is niet acceptabel. Uiteindelijk blijkt dat beide volgorden met meerdere zinnen acceptabel zijn. Van de 19 zinnen kon ik in verband met het wegvallen van een aantal zinnen door gebrek aan significantie 6 paren vormen. Bij het bekijken van de gemiddelden zag ik dat er toch wat verschillen in het gemiddelde zaten die op een voorkeur voor de ene of de andere volgorde zouden kunnen wijzen.
Hoe kan ik bepalen of er tussen twee onafhankelijke (?) variabelen met dezelfde schaalverdeling van 1 tot 4 een significant verschil bestaat? Ik had in eerste instantie gedacht aan een gepaarde t-toets, maar volgens mij is deze alleen voor afhankelijke variabelen of heb ik dat mis?
Alle statistiek die ik heb gebruikt tot nu toe, heb ik in de afgelopen 3 a 4 dagen bijgespijkerd, na N&T op het VWO met biologie (gelukkig snapte ik dus wel de χ2-toets) heb ik besloten een talenstudie te gaan doen. Ik heb dus alleen Wiskunde B gedaan en nooit iets met statistiek te maken gehad. Ik maak gebruik van SPSS, dus als jullie hier rekening mee zouden willen houden in jullie tips, zou dat fijn zijn!
Uiteindelijk heeft mijn enquête 92 respondenten opgeleverd. Een voldoende aantal binnen de taalwetenschap. Met een χ2-toets heb ik vervolgens per vraag bepaald in hoeverre de verdeling over de antwoordmogelijkheden willekeurig is (verdeling 23-23-23-23). Er is geen hypothese die getoetst kan worden, omdat er slechts twee halve alinea's over geschreven zijn door twee verschillende auteurs en hun beweringen lijnrecht tegenover elkaar staan. Van de 19 zinnen hield ik er 14 over met p<0,01 2 met 0,01<p<0,05. 1 zin met 0,05<p<0,1 en 2 met p>0,1. Ik heb besloten alledrie deze zinnen buiten het onderzoek te houden.
Ik heb met een ongepaarde t-toets gekeken of er een significant verschil zat tussen mannen en vrouwen om zo deze insignificantie te kunnen verklaren, maar dat leverde niets op. Ook dit verschil was insignificant.
Met de mediaan heb ik vervolgens bepaald of een zin wel of niet aangenomen kan worden als acceptabel. Mediaan 1-2 is acceptabel en mediaan 3-4 is niet acceptabel. Uiteindelijk blijkt dat beide volgorden met meerdere zinnen acceptabel zijn. Van de 19 zinnen kon ik in verband met het wegvallen van een aantal zinnen door gebrek aan significantie 6 paren vormen. Bij het bekijken van de gemiddelden zag ik dat er toch wat verschillen in het gemiddelde zaten die op een voorkeur voor de ene of de andere volgorde zouden kunnen wijzen.
Hoe kan ik bepalen of er tussen twee onafhankelijke (?) variabelen met dezelfde schaalverdeling van 1 tot 4 een significant verschil bestaat? Ik had in eerste instantie gedacht aan een gepaarde t-toets, maar volgens mij is deze alleen voor afhankelijke variabelen of heb ik dat mis?
Alle statistiek die ik heb gebruikt tot nu toe, heb ik in de afgelopen 3 a 4 dagen bijgespijkerd, na N&T op het VWO met biologie (gelukkig snapte ik dus wel de χ2-toets) heb ik besloten een talenstudie te gaan doen. Ik heb dus alleen Wiskunde B gedaan en nooit iets met statistiek te maken gehad. Ik maak gebruik van SPSS, dus als jullie hier rekening mee zouden willen houden in jullie tips, zou dat fijn zijn!
Ik denk dat het grootste punt is dat je enkel afhankelijke variabelen hebt. Doordat de vijf schalen samen de afhankelijke variabelen vormen, zijn ze zelf ook afhankelijke variabelen. Als je merkwaarde ook nog op een andere manier kunt meten, dan kun je de relatie tussen de vijf schalen in je vragenlijst en merkwaarde meten. Als je dat niet hebt is de vraag of je een of meerdere onafhankelijke variabelen hebt in je data waar je iets mee kunt.quote:
[..]
En een stap terugnemen en de schalen op een andere manier indelen is geen optie?
Onderling verband met de verschillende schalen is niet persé wat ik zoek namelijk. Ik wil weten welk aspect van merkmeerwaarde de respondenten het belangrijkst vinden, zodat de organisatie zich daar op kan focussen. En als ik de resultaten bekijk, dan zie ik dat de meest positieve antwoorden zijn ingevuld bij de schaal content. Hoe laat ik dit zien door middel van een test?
Is er geen andere toets (Mann-Whitney U Test / Pearson R / Anova ??) die ik hiervoor kan inzetten?
Want als het niet lukt via SPSS, dan lijkt het me beter om gewoon de survey resultaten te analyseren en zelf grafieken te maken over hoe positief (of negatief) de respondenten de vragen uit de verschillende vragen hebben beantwoord.
Een ander punt is: Wat zegt een hogere score op een bepaalde subschaal? Aangezien je de subschalen optelt zorgt een hogere score op een subschaal voor een hogere merkwaarde, maar dat betekent niet dat de invloed alleen maar groot is als de score hoog is. Een subschaal waar laag op wordt gescoord kan ook een grote invloed hebben.
Wat heb je precies gemeten in je schalen? Zijn dat algemene vragen: "Voor mij is tevredenheid belangrijk." of specifieke vragen: "Ik ben heel erg tevreden met merk X." In dat laatste geval kun je aanbevelingen doen op basis van de data met betrekking tot het merk. Bijvoorbeeld "Deelnemers waren erg tevreden over de kwaliteit van het merk, maar niet tevreden over de prijs. Als jullie de merkwaarde willen vergroten is het dus verstanding om nog eens naar de prijs te kijken in plaats van te focussen op de kwaliteit."
(Overigens zijn mijn voorbeelden totaal uit de lucht gegrepen aangezien ik je onderzoek niet echt ken, maar misschien kun je er iets mee.)
Je probleem is geen probleem van de toets maar, no offense, van een verkeerd opgezet onderzoek. De vraag die je wilt beantwoorden kun je niet beantwoorden met de data die je verzameld hebt.quote:
[..]
En een stap terugnemen en de schalen op een andere manier indelen is geen optie?
Onderling verband met de verschillende schalen is niet persé wat ik zoek namelijk. Ik wil weten welk aspect van merkmeerwaarde de respondenten het belangrijkst vinden, zodat de organisatie zich daar op kan focussen. En als ik de resultaten bekijk, dan zie ik dat de meest positieve antwoorden zijn ingevuld bij de schaal content. Hoe laat ik dit zien door middel van een test?
Is er geen andere toets (Mann-Whitney U Test / Pearson R / Anova ??) die ik hiervoor kan inzetten?
Want als het niet lukt via SPSS, dan lijkt het me beter om gewoon de survey resultaten te analyseren en zelf grafieken te maken over hoe positief (of negatief) de respondenten de vragen uit de verschillende vragen hebben beantwoord.
Ik snap niet zo goed wat je hier doet. Waarom zouden die antwoorden gelijk verdeeld moeten zijn? Waarom haal je de gelijk verdeelde zinner er uit?quote:
Ik heb voor mijn scriptie onderzoek gedaan naar de volgorde van persoonlijk voornaamwoorden in het Nieuwgrieks door middel van het afnemen van een enquête. Ik heb 5 algemene vragen gesteld om te bepalen of de respondenten tot de doelgroep behoren (of dat de enquête eventueel afgebroken moet worden), uit welke regio van Griekenland de respondent afkomstig is en wat het geslacht en de leeftijd van de respondent is. Vervolgens heb ik 19 zinnen voorgelegd, waarbij de respondenten op een schaal van 1 tot 4 konden kiezen (ja, waarschijnlijk wel, waarschijnlijk niet, nee) in hoeverre het mogelijk was die zinnen te horen in hun omgeving.
Uiteindelijk heeft mijn enquête 92 respondenten opgeleverd. Een voldoende aantal binnen de taalwetenschap. Met een χ2-toets heb ik vervolgens per vraag bepaald in hoeverre de verdeling over de antwoordmogelijkheden willekeurig is (verdeling 23-23-23-23).
Er is geen hypothese die getoetst kan worden, omdat er slechts twee halve alinea's over geschreven zijn door twee verschillende auteurs en hun beweringen lijnrecht tegenover elkaar staan. Van de 19 zinnen hield ik er 14 over met p<0,01 2 met 0,01<p<0,05. 1 zin met 0,05<p<0,1 en 2 met p>0,1. Ik heb besloten alledrie deze zinnen buiten het onderzoek te houden.
Welke insignificantie? In snap nog steeds niet helemaal de bedoeling van de chi-square toets maar 3/19 n.s. is niet vreemd en hoeft ook niet verklaard te worden, het is statistisch vrij logisch dat niet altijd alles significant verschilt zelfs wanneer er in de wekelijkheid wel zo'n verband is.quote:Ik heb met een ongepaarde t-toets gekeken of er een significant verschil zat tussen mannen en vrouwen om zo deze insignificantie te kunnen verklaren, maar dat leverde niets op. Ook dit verschil was insignificant.
De beoordeling van de zinnen is een afhankelijke variabele dus je kunt gewoon een paired t-test doen.quote:Met de mediaan heb ik vervolgens bepaald of een zin wel of niet aangenomen kan worden als acceptabel. Mediaan 1-2 is acceptabel en mediaan 3-4 is niet acceptabel. Uiteindelijk blijkt dat beide volgorden met meerdere zinnen acceptabel zijn. Van de 19 zinnen kon ik in verband met het wegvallen van een aantal zinnen door gebrek aan significantie 6 paren vormen. Bij het bekijken van de gemiddelden zag ik dat er toch wat verschillen in het gemiddelde zaten die op een voorkeur voor de ene of de andere volgorde zouden kunnen wijzen.
Hoe kan ik bepalen of er tussen twee onafhankelijke (?) variabelen met dezelfde schaalverdeling van 1 tot 4 een significant verschil bestaat? Ik had in eerste instantie gedacht aan een gepaarde t-toets, maar volgens mij is deze alleen voor afhankelijke variabelen of heb ik dat mis?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-

Hallo allemaal!
Ik ben bezig met mijn onderzoek naar de kwaliteit van de Nederlandse kinderopvang en de rol die pedagogisch medewerkers (pm'ers) hierin spelen. De constructen in de vragenlijst worden zowel op een directe als een indirecte manier gemeten. Bij de indirecte manier worden telkens twee vragen gesteld (die elk een andere antwoordschaal hebben) en de score van deze items worden met elkaar vermenigvuldigd.
Bijvoorbeeld het construct "sociale norm" wordt op een indirecte manier gemeten door:
- vraag 1: "mijn collega's werken... [Niet -3 -2 -1 0 +1 +2 +3 Wel]... volgens de pedagogische visie van de instelling"
x
- vraag 2: "doen wat andere collega's ook doen is belangrijk voor mij" [Zeer oneens 1 2 3 4 5 6 7 Zeer eens].
+ vraag3 x vraag4, etc. etc.
Dus: het construct "sociale norm" = (vraag1 x vraag2) + (vraag3 x vraag4) + (etc. etc.). etc.
Nou vraag ik me af hoe ik deze items in moet voeren in mijn variable view van spss. Ik heb ze ingevoerd als ordinale variabelen en wilde daarbij de values toevoegen. Ik weet niet goed hoe ik dit aan moet pakken. Mogen de values in spss ook negatieve waarden bevatten? Of kan dit later problemen veroorzaken met bepaalde berekeningen?
En kan ik spss ook een variabele aanmaken die de totale constructscore berekent/weergeeft? Zo ja, hoe?
Ik ben bezig met mijn onderzoek naar de kwaliteit van de Nederlandse kinderopvang en de rol die pedagogisch medewerkers (pm'ers) hierin spelen. De constructen in de vragenlijst worden zowel op een directe als een indirecte manier gemeten. Bij de indirecte manier worden telkens twee vragen gesteld (die elk een andere antwoordschaal hebben) en de score van deze items worden met elkaar vermenigvuldigd.
Bijvoorbeeld het construct "sociale norm" wordt op een indirecte manier gemeten door:
- vraag 1: "mijn collega's werken... [Niet -3 -2 -1 0 +1 +2 +3 Wel]... volgens de pedagogische visie van de instelling"
x
- vraag 2: "doen wat andere collega's ook doen is belangrijk voor mij" [Zeer oneens 1 2 3 4 5 6 7 Zeer eens].
+ vraag3 x vraag4, etc. etc.
Dus: het construct "sociale norm" = (vraag1 x vraag2) + (vraag3 x vraag4) + (etc. etc.). etc.
Nou vraag ik me af hoe ik deze items in moet voeren in mijn variable view van spss. Ik heb ze ingevoerd als ordinale variabelen en wilde daarbij de values toevoegen. Ik weet niet goed hoe ik dit aan moet pakken. Mogen de values in spss ook negatieve waarden bevatten? Of kan dit later problemen veroorzaken met bepaalde berekeningen?
En kan ik spss ook een variabele aanmaken die de totale constructscore berekent/weergeeft? Zo ja, hoe?
Je kunt in spss gewoon negatieve waardes gebruiken. Als je een schaal gebruikt hoef je geen ordinale schaal aan te geven maar kun je gewoon continu/interval gebruiken.quote:Op donderdag 21 augustus 2014 01:10 schreef Natoo het volgende:
Hallo allemaal!
Ik ben bezig met mijn onderzoek naar de kwaliteit van de Nederlandse kinderopvang en de rol die pedagogisch medewerkers (pm'ers) hierin spelen. De constructen in de vragenlijst worden zowel op een directe als een indirecte manier gemeten. Bij de indirecte manier worden telkens twee vragen gesteld (die elk een andere antwoordschaal hebben) en de score van deze items worden met elkaar vermenigvuldigd.
Bijvoorbeeld het construct "sociale norm" wordt op een indirecte manier gemeten door:
- vraag 1: "mijn collega's werken... [Niet -3 -2 -1 0 +1 +2 +3 Wel]... volgens de pedagogische visie van de instelling"
x
- vraag 2: "doen wat andere collega's ook doen is belangrijk voor mij" [Zeer oneens 1 2 3 4 5 6 7 Zeer eens].
+ vraag3 x vraag4, etc. etc.
Dus: het construct "sociale norm" = (vraag1 x vraag2) + (vraag3 x vraag4) + (etc. etc.). etc.
Nou vraag ik me af hoe ik deze items in moet voeren in mijn variable view van spss. Ik heb ze ingevoerd als ordinale variabelen en wilde daarbij de values toevoegen. Ik weet niet goed hoe ik dit aan moet pakken. Mogen de values in spss ook negatieve waarden bevatten? Of kan dit later problemen veroorzaken met bepaalde berekeningen?
En kan ik spss ook een variabele aanmaken die de totale constructscore berekent/weergeeft? Zo ja, hoe?
Je kunt een variabele aanmaken die tde total score weergeeft door in compute de variabelen op te tellen of het gemiddelde te nemen (wat je wilt).
Heb je zelf bedacht om die twee variabelen te vermeningvuldigen of is dat standaard gebruik? Het is namelijk nogal vreemd om dat te doen omdat je daarmee statistische verbanden creeert waarvan je niet weet of die eigenlijk representatief zijn voor datgene dat je probeert te meten.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Dank voor je snelle reactie! Ik begrijp niet helemaal waarom het dan continu/interval (dus "scale") is. Want in principe gaat het toch om ordinale variabelen als "zeer oneens", "een beetje oneens", etc.?quote:Als je een schaal gebruikt hoef je geen ordinale schaal aan te geven maar kun je gewoon continu/interval gebruiken.
En als het een scale-variabele is, moet/kan ik dan wel gewoon values aanmaken? En zo ja, neem je dan alleen de uiteinden (dus bijvoorbeeld: "value 1 = zeer oneens" en "value 7 = zeer eens")?. Of vul ik de middelste values zelf in (bijvoorbeeld met "value 2 = oneens", "value 3 = een beetje oneens", etc.)?
Helaas hoort dit bij het type vragenlijst dat ik heb gebruikt.quote:Heb je zelf bedacht om die twee variabelen te vermeningvuldigen of is dat standaard gebruik? Het is namelijk nogal vreemd om dat te doen omdat je daarmee statistische verbanden creeert waarvan je niet weet of die eigenlijk representatief zijn voor datgene dat je probeert te meten. .
Wat je zegt klopt officieel, maar het is gebleken dat als je likert-type schalen gebruikt met 5 of meer opties (en je schaal neit extreem vreemd is) je eigenlijk geen onderschatte p-waardes krijgt met parametrische (t-test/anova) toetsen.En aangezien parametrische toetsen sterker zijn en gemakkelijker te interpreteren/vertalen naar de echte wereld zou ik die gebruiken. Er zijn best veel papers over geschreven als je een bron nodig hebt om het te beargumenterenquote:
[..]
Dank voor je snelle reactie! Ik begrijp niet helemaal waarom het dan continu/interval (dus "scale") is. Want in principe gaat het toch om ordinale variabelen als "zeer oneens", "een beetje oneens", etc.?
En als het een scale-variabele is, moet/kan ik dan wel gewoon values aanmaken? En zo ja, neem je dan alleen de uiteinden (dus bijvoorbeeld: "value 1 = zeer oneens" en "value 7 = zeer eens")?. Of vul ik de middelste values zelf in (bijvoorbeeld met "value 2 = oneens", "value 3 = een beetje oneens", etc.)?
[..]
Ik snap niet zo goed wat je daarna bedoelt met "values" dat zou hetzelfde zijn met ordinale interpretatie
Ik vind het echt een hele vreemde schaal, welke is dat? Superraar dat als je bv 0 aangeeft op vraag 1 (mijn collegas werken soms wel en soms niet volgens...) het dan niet uit zou maken of je 1 of 7 scoort op vraag 2.quote:Helaas hoort dit bij het type vragenlijst dat ik heb gebruikt.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Oja, ik begrijp het! Dankje!quote:Wat je zegt klopt officieel, maar het is gebleken dat als je likert-type schalen gebruikt met 5 of meer opties (en je schaal neit extreem vreemd is) je eigenlijk geen onderschatte p-waardes krijgt met parametrische (t-test/anova) toetsen.En aangezien parametrische toetsen sterker zijn en gemakkelijker te interpreteren/vertalen naar de echte wereld zou ik die gebruiken. Er zijn best veel papers over geschreven als je een bron nodig hebt om het te beargumenteren
Nou, ik dacht dat als je meetniveau "scale" is dat je dan eigenlijk geen values invoert.. maar dat kan dus wel? En ik begrijp niet goed hoe ik de values in moet voeren, aangezien ik alleen de uiteinden van de schaal heb.quote:Ik snap niet zo goed wat je daarna bedoelt met "values" dat zou hetzelfde zijn met ordinale interpretatie
Ja, raar is het wel! Het is de vragenlijst aangaande de Theory of Planned Behavior.. er is een manual voor ontwikkeld hoe je de vragen precies op moet stellen en hoe je ze moet scoren, en die heb ik hierbij gebruikt.quote:Ik vind het echt een hele vreemde schaal, welke is dat? Superraar dat als je bv 0 aangeeft op vraag 1 (mijn collegas werken soms wel en soms niet volgens...) het dan niet uit zou maken of je 1 of 7 scoort op vraag 2.
Hmm in mijn quote is de helft van je bericht weg. Iig die namen hoef je in spss niet aan je schaal te geven, daar kun je gewoon -3 tot +3 en 1-7 gebruiken. De anchors (helemaal wel / helemaal niet etc.) gebruik je allen in je methode-beschrijving.quote:
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Oke! Dank!!quote:Iig die namen hoef je in spss niet aan je schaal te geven, daar kun je gewoon -3 tot +3 en 1-7 gebruiken. De anchors (helemaal wel / helemaal niet etc.) gebruik je allen in je methode-beschrijving.
Laat maar 
[ Bericht 70% gewijzigd door SJK op 23-08-2014 11:21:45 ]
[ Bericht 70% gewijzigd door SJK op 23-08-2014 11:21:45 ]
Het is altijd raak met kaas van SJaaK
Hoi Jan,
Dat zijn we niet. Als je een bijles internetkunde wilt, lees de voorwaarden en regels van FOK! eens door!
Groetjes
Dat zijn we niet. Als je een bijles internetkunde wilt, lees de voorwaarden en regels van FOK! eens door!
Groetjes
Op dinsdag 25 augustus 2015 15:48 schreef Toekito het volgende:
de grootste schande van heel FOK! naast Fylax is Kano als mod.
de grootste schande van heel FOK! naast Fylax is Kano als mod.
Dag allemaal,
Ik heb een vraag over een multilevel analyse, waarvan ik hoop dat iemand me kan helpen.
Ik vergelijk twee groepen met elkaar tav van het verloop van scores over de tijd. Iedere drie maanden wordt er door de personen uit de twee groepen een vragenlijst ingevuld waar een score uit komt. De looptijd is max. een jaar, maar bij sommigen is dit korter. Niet iedereen heeft evenveel vragenlijsten ingevuld, soms is er maar 1, soms 2, soms 3 of soms 4. Mijn hypothese is dat de ene groep een vrij vlak verloop heeft (maw de score op de vragenlijsten neemt in de loop van de tijd niet af) en dat de andere groep een steiler verloop heeft (maw de score op de vragenlijsten loopt in de loop van de tijd af). Nu kwam ik op een multilevelanalyse, maar kreeg ik van mijn supervisor de vraag of de tijdsvariabele gecentreerd moet worden?! Kan iemand daar voor mij op basis van deze info iets zinnigs over zeggen? Alvast heel hartelijk dank!
Ik heb een vraag over een multilevel analyse, waarvan ik hoop dat iemand me kan helpen.
Ik vergelijk twee groepen met elkaar tav van het verloop van scores over de tijd. Iedere drie maanden wordt er door de personen uit de twee groepen een vragenlijst ingevuld waar een score uit komt. De looptijd is max. een jaar, maar bij sommigen is dit korter. Niet iedereen heeft evenveel vragenlijsten ingevuld, soms is er maar 1, soms 2, soms 3 of soms 4. Mijn hypothese is dat de ene groep een vrij vlak verloop heeft (maw de score op de vragenlijsten neemt in de loop van de tijd niet af) en dat de andere groep een steiler verloop heeft (maw de score op de vragenlijsten loopt in de loop van de tijd af). Nu kwam ik op een multilevelanalyse, maar kreeg ik van mijn supervisor de vraag of de tijdsvariabele gecentreerd moet worden?! Kan iemand daar voor mij op basis van deze info iets zinnigs over zeggen? Alvast heel hartelijk dank!
Ik kan er iets zinnigs over zeggen maar niet op basis van de gegeven infoquote:
Dag allemaal,
Ik heb een vraag over een multilevel analyse, waarvan ik hoop dat iemand me kan helpen.
Ik vergelijk twee groepen met elkaar tav van het verloop van scores over de tijd. Iedere drie maanden wordt er door de personen uit de twee groepen een vragenlijst ingevuld waar een score uit komt. De looptijd is max. een jaar, maar bij sommigen is dit korter. Niet iedereen heeft evenveel vragenlijsten ingevuld, soms is er maar 1, soms 2, soms 3 of soms 4. Mijn hypothese is dat de ene groep een vrij vlak verloop heeft (maw de score op de vragenlijsten neemt in de loop van de tijd niet af) en dat de andere groep een steiler verloop heeft (maw de score op de vragenlijsten loopt in de loop van de tijd af). Nu kwam ik op een multilevelanalyse, maar kreeg ik van mijn supervisor de vraag of de tijdsvariabele gecentreerd moet worden?! Kan iemand daar voor mij op basis van deze info iets zinnigs over zeggen? Alvast heel hartelijk dank!
Basically heb je twee opties:
niet centreren, waarbij t=0 dus t=0 blijft.
centreren waarbij de gemiddelde t 0 wordt.
afthankelijk van wat t voorstelt is het wel of niet aan te raden, aangezien het voor de statistiek niet uit maakt. (Ik ga er in deze reactie vanuit dat je tijd alleen als main-effect meeneemt, als je het als deel in een interactie gebruikt ligt het wat gecompliceerder.)
Stel je voor dat t de tijd is sinds het begin van een medicijnkuur, in dit geval is het veel logischer om tijd niet te centreren, omdat het effect van tijd ten opzichte van de gemiddelde tijd in jouw onderzoek superingewikkeld wordt om te interpreteren, het is veel logischer om het effect weer te geven in tijd sinds het begin van de kuur.
Nu wilde ik een voorbeeld geven waarin het wel logisch is om tijd te centreren maar het lukt me niet op binnen een minuut op iets te komen, nou ja punt lijkt me duidelijk toch?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Bedankt voor je reactie oompaloompa, ik gebruik wel tijd als deel van de interactie namelijk tijd x groep
Welke info kan ik nog geven zodat je daar iets over zou kunnen zeggen?
Welke info kan ik nog geven zodat je daar iets over zou kunnen zeggen?
Gebruik je dummy-coderinig voor groep? (0-1)quote:
Bedankt voor je reactie oompaloompa, ik gebruik wel tijd als deel van de interactie namelijk tijd x groep
Welke info kan ik nog geven zodat je daar iets over zou kunnen zeggen?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Dan maakt het statistisch niks uit dus zou ik gaan wat het logischt is qua interpretatiequote:
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Hallo allemaal,
Ik wil de missings in mijn dataset imputeren dus wil eerst een Little's MCAR test uitvoeren.
Ik heb begrepen dat dit alleen kan met continue variabelen. Nou vraag ik me een aantal dingen af:
• "leeftijd" of "aantal kinderen" is continu, maar dat is toch niet iets wat je laat schatten door spss?
• de meeste items (eigenlijk vrijwel alle items) bestaan uit antwoordschalen "1 = helemaal niet mee eens", etc., dus dan kan ik ze niet behandelen als continue variabelen, toch? (dan blijft er dus niks meer over om te imputeren. Ik heb een aantal 7-punts Likertschalen die ik als "scale" variabelen heb ingevoerd, dus dit is het enige wat ik zou kunnen imputeren)
• wat doe ik met de missings die ik niet kan imputeren (bijvoorbeeld omdat ze niet continu zijn)? Daar blijft dan "999" staan.. moet ik er daarna nog iets mee?
• ik heb al het één en ander geprobeerd, en uit de MCAR-test komt telkens het significantieniveau 1,000. Kan dit kloppen? (ik heb maar een kleine dataset.. 25 respondenten).
Ik hoop dat iemand mij meer duidelijkheid kan geven
Ik wil de missings in mijn dataset imputeren dus wil eerst een Little's MCAR test uitvoeren.
Ik heb begrepen dat dit alleen kan met continue variabelen. Nou vraag ik me een aantal dingen af:
• "leeftijd" of "aantal kinderen" is continu, maar dat is toch niet iets wat je laat schatten door spss?
• de meeste items (eigenlijk vrijwel alle items) bestaan uit antwoordschalen "1 = helemaal niet mee eens", etc., dus dan kan ik ze niet behandelen als continue variabelen, toch? (dan blijft er dus niks meer over om te imputeren. Ik heb een aantal 7-punts Likertschalen die ik als "scale" variabelen heb ingevoerd, dus dit is het enige wat ik zou kunnen imputeren)
• wat doe ik met de missings die ik niet kan imputeren (bijvoorbeeld omdat ze niet continu zijn)? Daar blijft dan "999" staan.. moet ik er daarna nog iets mee?
• ik heb al het één en ander geprobeerd, en uit de MCAR-test komt telkens het significantieniveau 1,000. Kan dit kloppen? (ik heb maar een kleine dataset.. 25 respondenten).
Ik hoop dat iemand mij meer duidelijkheid kan geven
Of is het dan beter om het maar gewoon zo te laten en met de oorspronkelijke dataset aan de slag te gaan? (En zo ja, moet je dan alsnog iets met die "999" of kan ik hiermee gewoon aan de slag?).
Als het niet nodig is, imputeer ik nooit data dus ik weet niet zo goed hoe het moet Maar als je de optie hebt het niet te doen, zou ik het niet doen (missings zijn volgens mij alleen een probleem bij multilevel analyses & repeated measures etc.)
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
zorg er dan trouwens wel voor dat 999 aangegeven staat als missing en niet meegenomen wordt als een score van 999! Heb ik een keer gedaan, snapte helemaal niks van m'n resultaten en duurde veel te lang voordat het kwartje viel
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Haha! Yes! Heb ik! Dank!quote:zorg er dan trouwens wel voor dat 999 aangegeven staat als missing en niet meegenomen wordt als een score van 999!
Nog een vraagje.. welke opties heb ik als m'n cronbach's alpha te laag is?
- schaal eruit laten
- schaal erin laten maar terughoudend omgaan met de resultaten?
- nog andere opties?
Ik begrijp niet zo goed waarom mijn alpha zo laag is.. ik gebruik namelijk een betrouwbaar instrument (s-EMBU), waarbij vragen worden gesteld over de eigen opvoeding.. van zowel de vader als de moeder.
De alpha's bij de vader-items zijn allemaal hoog (gemiddeld .92) maar de alpha's bij de moeder-items zijn laag (.64, .65, .70). Terwijl het om dezelfde vragen gaat..
Iemand een idee?
Oja.. ik begrijp dat ik ook losse items uit de schaal kan verwijderen. Maar ook alle alpha scores van "if item deleted" zijn nog te laag (< .70).
Dat zijn toch best aardige alpha's (voor enquêtedata). Heb je missings op je schaalvragen en kan je beredeneren waarom ze missing zijn?
Aldus.
oh, volgens mij moesten wij onze alpha's boven de .70 houden..
De respondenten met missings worden eruit gelaten dacht ik? (listwise deletion).
Ik heb echter ook alpha's van .45 en .47, maar weet dus niet goed wat ik ermee aan moet..
De respondenten met missings worden eruit gelaten dacht ik? (listwise deletion).
Ik heb echter ook alpha's van .45 en .47, maar weet dus niet goed wat ik ermee aan moet..
Vraag! We mogen dit jaar ook R gebruiken in plaats van SPSS (wordt aangeraden als men de research master overweegt), dus daar ben ik nu eens mee aan het stoeien en het gaat aardig. Ik heb een achtergrond in python en C++, dus de command line is mij in ieder geval niet vreemd en het zelf schrijven van functies ook niet, dat scheelt. Desondanks is het toch weer best wel anders.  Met veel ploeteren kom ik er wel doorheen, maar nu loop ik toch echt vast.
Met veel ploeteren kom ik er wel doorheen, maar nu loop ik toch echt vast.
Ik heb drie groepen, elke groep bestaat uit een reeks getallen. Groep 1 & 2 hebben 12 getallen, groep 3 heeft er 9. Ik moet nu voor elke groep een boxplot maken en die samen laten zien in één grafiek. Ik heb elke groep als volgt ingevoerd:
> group1 <- c(27, 22, 29, 21, 19, 33, 16, 20, 24, 27, 28, 19)
> group2 <- c(12, 12, 15, 9, 20, 18, 17, 14, 14, 2, 17, 19)
> group3 <- c(18, 4, 22, 15, 18, 19, 22, 12, 12)
Een boxplot maken voor één groep is geen probleem:
> boxplot(group1, main="Boxplot", ylab="group1")
Groep 1 en 2 kan ik nog samenvoegen in één grafiek (hoewel het er wat lelijk uitziet en ik er nog wat dingen aan moet tweaken dan). Dat doe ik als volgt:
> groups12 <- data.frame(group1,group2)
> boxplot(group1,group2,data=groups12, main="Boxplot", xlab="Group", ylab="Trees")
Maar als ik probeer groep 1, 2 EN 3 samen te voegen, geeft R een error omdat de argumenten een verschillend aantal rijen hebben (12 en 9). Groep 3 aanvullen met nullen is natuurlijk geen optie.
Iemand een idee?
Ik heb drie groepen, elke groep bestaat uit een reeks getallen. Groep 1 & 2 hebben 12 getallen, groep 3 heeft er 9. Ik moet nu voor elke groep een boxplot maken en die samen laten zien in één grafiek. Ik heb elke groep als volgt ingevoerd:
> group1 <- c(27, 22, 29, 21, 19, 33, 16, 20, 24, 27, 28, 19)
> group2 <- c(12, 12, 15, 9, 20, 18, 17, 14, 14, 2, 17, 19)
> group3 <- c(18, 4, 22, 15, 18, 19, 22, 12, 12)
Een boxplot maken voor één groep is geen probleem:
> boxplot(group1, main="Boxplot", ylab="group1")
Groep 1 en 2 kan ik nog samenvoegen in één grafiek (hoewel het er wat lelijk uitziet en ik er nog wat dingen aan moet tweaken dan). Dat doe ik als volgt:
> groups12 <- data.frame(group1,group2)
> boxplot(group1,group2,data=groups12, main="Boxplot", xlab="Group", ylab="Trees")
Maar als ik probeer groep 1, 2 EN 3 samen te voegen, geeft R een error omdat de argumenten een verschillend aantal rijen hebben (12 en 9). Groep 3 aanvullen met nullen is natuurlijk geen optie.
Iemand een idee?
Your opinion of me is none of my business.
De reden dat je een foutmelding krijgt is dat een dataframe er vanuit gaat dat elke variabele die je eraan toevoegt even lang is. Als je terugdenkt aan SPSS zou je voor 3 cases een lege cel hebben in "group 3" variabele. Wat R doet is dat melden (Hallo, je mist data!) maar de boxplot werkt gewoon (toen ik het probeerde wel in ieder geval.) Als je echt heel graag van die foutmelding af wil kun je in dit geval de reeks van group3 aanvullen met NA, NA, NA op het einde. Dat geeft een missing variable aan. Mochten de getallen van de verschillende variabelen echt bij specifieke cases horen (27, 12, 18 als scores van 1 proefpersoon bijvoorbeeld) dan moet je de NA codering op de juiste, missende waarde, plek invullen.quote:
Vraag! We mogen dit jaar ook R gebruiken in plaats van SPSS (wordt aangeraden als men de research master overweegt), dus daar ben ik nu eens mee aan het stoeien en het gaat aardig. Ik heb een achtergrond in python en C++, dus de command line is mij in ieder geval niet vreemd en het zelf schrijven van functies ook niet, dat scheelt. Desondanks is het toch weer best wel anders.
Ik heb drie groepen, elke groep bestaat uit een reeks getallen. Groep 1 & 2 hebben 12 getallen, groep 3 heeft er 9. Ik moet nu voor elke groep een boxplot maken en die samen laten zien in één grafiek. Ik heb elke groep als volgt ingevoerd:
> group1 <- c(27, 22, 29, 21, 19, 33, 16, 20, 24, 27, 28, 19)
> group2 <- c(12, 12, 15, 9, 20, 18, 17, 14, 14, 2, 17, 19)
> group3 <- c(18, 4, 22, 15, 18, 19, 22, 12, 12)
Een boxplot maken voor één groep is geen probleem:
> boxplot(group1, main="Boxplot", ylab="group1")
Groep 1 en 2 kan ik nog samenvoegen in één grafiek (hoewel het er wat lelijk uitziet en ik er nog wat dingen aan moet tweaken dan). Dat doe ik als volgt:
> groups12 <- data.frame(group1,group2)
> boxplot(group1,group2,data=groups12, main="Boxplot", xlab="Group", ylab="Trees")
Maar als ik probeer groep 1, 2 EN 3 samen te voegen, geeft R een error omdat de argumenten een verschillend aantal rijen hebben (12 en 9). Groep 3 aanvullen met nullen is natuurlijk geen optie.
Iemand een idee?
quote:
Oja.. ik begrijp dat ik ook losse items uit de schaal kan verwijderen. Maar ook alle alpha scores van "if item deleted" zijn nog te laag (< .70).
Wat je kunt doen (Ik weet niet of je dit al geprobeerd hebt) is te werken met de "if item deleted" waar je het over had. Je draait die analyse en leest uit de tabel af welk item alpha het meeste zou verhogen als deze weg zou worden gelaten. Die vraag haal je eruit, en dan doe je deze analyse nog een keer. de "alpha if item deleted" zal veranderen doordat je de analyse opnieuw doet na het verwijderen van een vraag, je kunt dus niet uitgaan van de getallen van de eerste keer dat je deze analyse deed.quote:
oh, volgens mij moesten wij onze alpha's boven de .70 houden..
De respondenten met missings worden eruit gelaten dacht ik? (listwise deletion).
Ik heb echter ook alpha's van .45 en .47, maar weet dus niet goed wat ik ermee aan moet..
Dit lijkt onlogisch, omdat je leert dat het belangrijk is om een construct om meerdere manieren te meten voor een hogere betrouwbaarheid. Als echter uit je analyse blijkt dat een kleiner aantal vragen een hogere betrouwbaarheid geeft, dan is het onlogisch om vragen mee te nemen die eigenlijk niet meten wat je wil meten.
Welke boxplot werkt er dan? Het samenvoegen van drie groepen werkt niet, als ik dat probeer krijg ik de melding:quote:
[..]
De reden dat je een foutmelding krijgt is dat een dataframe er vanuit gaat dat elke variabele die je eraan toevoegt even lang is. Als je terugdenkt aan SPSS zou je voor 3 cases een lege cel hebben in "group 3" variabele. Wat R doet is dat melden (Hallo, je mist data!) maar de boxplot werkt gewoon (toen ik het probeerde wel in ieder geval.) Als je echt heel graag van die foutmelding af wil kun je in dit geval de reeks van group3 aanvullen met NA, NA, NA op het einde. Dat geeft een missing variable aan. Mochten de getallen van de verschillende variabelen echt bij specifieke cases horen (27, 12, 18 als scores van 1 proefpersoon bijvoorbeeld) dan moet je de NA codering op de juiste, missende waarde, plek invullen.
"Error in data.frame(group1, group2, group3) :
arguments imply differing number of rows: 12, 9"
Dus hoe maak je die boxplot als je niet een dataset hebt om uit te trekken?
Your opinion of me is none of my business.
Goede vraag. Ik zal fout hebben gekeken gok ik.quote:
[..]
Welke boxplot werkt er dan? Het samenvoegen van drie groepen werkt niet, als ik dat probeer krijg ik de melding:
"Error in data.frame(group1, group2, group3) :
arguments imply differing number of rows: 12, 9"
Dus hoe maak je die boxplot als je niet een dataset hebt om uit te trekken?
Onderstaande code werkt in ieder geval (dan werk je met NA)
| 1 2 3 4 5 6 | group1 <- c(27, 22, 29, 21, 19, 33, 16, 20, 24, 27, 28, 19) group2 <- c(12, 12, 15, 9, 20, 18, 17, 14, 14, 2, 17, 19) group3 <- c(18, 4, 22, 15, 18, 19, 22, 12, 12, NA, NA, NA) boxplot(group1, main="Boxplot", ylab="group1") groups123 <- data.frame(group1, group2, group3) boxplot(group1,group2, group3,data=groups123, main="Boxplot", xlab="Group", ylab="Trees") |
EDIT: Je kunt ook zonder NAs boxplotten maken, alleen dan werk je zonder dataframe.
Als je group 1, 2 en 3 hebt gedfinieerd kun je deze code gebruiken:
| 1 | boxplot(group1,group2, group3,data="group1, group2, group3", main="Boxplot", xlab="Group", ylab="Trees") |
Ik heb het net gevonden!quote:
[..]
Goede vraag. Ik zal fout hebben gekeken gok ik.
Onderstaande code werkt in ieder geval (dan werk je met NA)
[ code verwijderd ]
> boxplot(group1,group2,group3)
werkt gewoon.
Your opinion of me is none of my business.
Ah, mijn edit kwam te laat.quote:
[..]
Ik heb het net gevonden!
> boxplot(group1,group2,group3)
werkt gewoon.
Dank voor de hulp in ieder geval!quote:
[..]
Ah, mijn edit kwam te laat.
Your opinion of me is none of my business.