SES School, Studie en Onderwijs
Wiskunde in de brugklas, Frans voor het examen of een studie Personeel en Arbeid? Moeilijke formulieren van DUO? Iets weten over studiefinanciering of studentenverenigingen? Dit is het forum voor leerkrachten, scholieren en studenten, van brugklas tot uni



Lieve FOK!kers, ik heb over een maandje mijn toelatingsexamen voor mijn Sociologie master aan de VU. Ik kom van het hbo af en heb dus niet/nauwelijks statistiek of wiskunde gehad. Ben al druk aan het oefenen, maar hebben jullie nog tips, tricks of linkjes naar goede samenvattingen of oefenmogelijkheden?
Welke onderwerpen zijn het meest belangrijk bij wiskunde ihkv statistiek?
Welke onderwerpen zijn het meest belangrijk bij wiskunde ihkv statistiek?

Als bij een multiple logistische regressie een interactieterm (onafhankelijke variabele1*onafhankelijke variabele2) niet significant is, dan kan ik deze interactieterm weglaten uit mijn analyse toch om het effect van deze onafhankelijke variabelen an sich te bepalen?
Situatie is namelijk als volgt: onafhankelijke variabelen 1 en 2 zijn beiden significant in mijn logistische regressiemodel, maar als ik een interactieterm introduceer met deze variabelen, is deze interactieterm niet significant, maar worden ook de variabelen individueel niet significant.
Volgens mij kan ik mijn interactieterm dan weglaten en de significante variabelen als zodanig rapporteren.
Situatie is namelijk als volgt: onafhankelijke variabelen 1 en 2 zijn beiden significant in mijn logistische regressiemodel, maar als ik een interactieterm introduceer met deze variabelen, is deze interactieterm niet significant, maar worden ook de variabelen individueel niet significant.
Volgens mij kan ik mijn interactieterm dan weglaten en de significante variabelen als zodanig rapporteren.
Nee, tell me more?quote:
Ik heb alleen mijn multipele logistische regressie herhaald met alle originele onafhankelijke variabelen plus de interactieterm. Toen was de interactieterm niet significant, maar de twee onafhankelijke variabelen die eerst wel significant waren, ook niet meer.
Met een F-test test je of je variabelen samen significant zijn, om het in hypethesissen te verwoorden:
F test: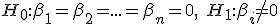 voor een
voor een ![i \in [1,n] \cap \mathbb{N}](https://forum.fok.nl/lib/mimetex.cgi?i%20%5Cin%20%5B1%2Cn%5D%20%5Ccap%20%5Cmathbb%7BN%7D)
T-test: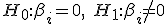
F test:
T-test:
Beste SPSS helden,
Op dit moment ben ik bezig met mijn afstudeeronderzoek en heb een vraag over een SPSS analyse.
Ik doe een onderzoek naar welke behoeften mensen hebben op een webshop en in de fysieke winkel, bijvoorbeeld, in welke mate hebben consumenten behoefte aan reviews op een webshop, of het product aanraken in de winkel etc.
Ook vraag ik in de enquête in welke mate zij de winkel/webshop beoordelen op deze punten.
Zo heb ik 2 vragen gemeten op basis van een 5 punt likert schaal:
- In welke mate vindt u de volgende functies belangrijk op een webshop? --> reviews en beoordelingen
- Hoe beoordeelt u de Euro Funcenter webshop op deze functies? --> reviews en beoordelingen
Op deze manier kan ik zien wat mensen belangrijk vinden en waar er verbeterpunten liggen, of niet.
Weet iemand een mooie duidelijke manier om naast elkaar dit aan te tonen in SPSS? ik kom er zelf niet zo goed uit namelijk. Dus bijvoorbeeld:
100 mensen vinden reviews en beoordelingen zeer belangrijk
80 mensen vinden de reviews en beoordelingen op de webshop matig.
enzovoort.
Ik hoop dat jullie me kunnen helpen!
Op dit moment ben ik bezig met mijn afstudeeronderzoek en heb een vraag over een SPSS analyse.
Ik doe een onderzoek naar welke behoeften mensen hebben op een webshop en in de fysieke winkel, bijvoorbeeld, in welke mate hebben consumenten behoefte aan reviews op een webshop, of het product aanraken in de winkel etc.
Ook vraag ik in de enquête in welke mate zij de winkel/webshop beoordelen op deze punten.
Zo heb ik 2 vragen gemeten op basis van een 5 punt likert schaal:
- In welke mate vindt u de volgende functies belangrijk op een webshop? --> reviews en beoordelingen
- Hoe beoordeelt u de Euro Funcenter webshop op deze functies? --> reviews en beoordelingen
Op deze manier kan ik zien wat mensen belangrijk vinden en waar er verbeterpunten liggen, of niet.
Weet iemand een mooie duidelijke manier om naast elkaar dit aan te tonen in SPSS? ik kom er zelf niet zo goed uit namelijk. Dus bijvoorbeeld:
100 mensen vinden reviews en beoordelingen zeer belangrijk
80 mensen vinden de reviews en beoordelingen op de webshop matig.
enzovoort.
Ik hoop dat jullie me kunnen helpen!
Analyze -> descriptive statistics -> frequenciesquote:Op woensdag 2 juli 2014 11:51 schreef surfertjejesper het volgende:
Beste SPSS helden,
Op dit moment ben ik bezig met mijn afstudeeronderzoek en heb een vraag over een SPSS analyse.
Ik doe een onderzoek naar welke behoeften mensen hebben op een webshop en in de fysieke winkel, bijvoorbeeld, in welke mate hebben consumenten behoefte aan reviews op een webshop, of het product aanraken in de winkel etc.
Ook vraag ik in de enquête in welke mate zij de winkel/webshop beoordelen op deze punten.
Zo heb ik 2 vragen gemeten op basis van een 5 punt likert schaal:
- In welke mate vindt u de volgende functies belangrijk op een webshop? --> reviews en beoordelingen
- Hoe beoordeelt u de Euro Funcenter webshop op deze functies? --> reviews en beoordelingen
Op deze manier kan ik zien wat mensen belangrijk vinden en waar er verbeterpunten liggen, of niet.
Weet iemand een mooie duidelijke manier om naast elkaar dit aan te tonen in SPSS? ik kom er zelf niet zo goed uit namelijk. Dus bijvoorbeeld:
100 mensen vinden reviews en beoordelingen zeer belangrijk
80 mensen vinden de reviews en beoordelingen op de webshop matig.
enzovoort.
Ik hoop dat jullie me kunnen helpen!
Als je zorgt dat je in je variabelen scherm de labels van de values hebt aangepast naar de benamingen die je noemt kun je op deze manier een tabel krijgen met de aantallen die je zoekt.
Als je eerst nog op Charts klikt (voor je op OK klikt) dan kun je nog kiezen uit wat grafiekjes.
Klopt! Deze manier had ik eerst ook. Alleen ik dacht, misschien is er een mooiere manier om dit naast elkaar weer te geven. Zodat je in een snelle oogopslag kan zien bv: 80% vind reviews 'zeer belangrijk', maar 70% beoordeeld bedrijf xx op dit punt 'matig'. Dan weet je dat hier verbeterpunten liggen.quote:
[..]
Analyze -> descriptive statistics -> frequencies
Als je zorgt dat je in je variabelen scherm de labels van de values hebt aangepast naar de benamingen die je noemt kun je op deze manier een tabel krijgen met de aantallen die je zoekt.
Als je eerst nog op Charts klikt (voor je op OK klikt) dan kun je nog kiezen uit wat grafiekjes.
ik weet niet of dit mogelijk is, of is het verstandiger om het gewoon simpel te houden
In ieder geval bedankt voor je tip alvast!
Ah op die manier. Dan zou ik op basis van de frequency tabellen de data in Excel plaatsen en op die manier grafieken maken. Het zal vast ook kunnen in SPSS, maar ik ben niet zo thuis in de Chartbuilder.quote:
[..]
Klopt! Deze manier had ik eerst ook. Alleen ik dacht, misschien is er een mooiere manier om dit naast elkaar weer te geven. Zodat je in een snelle oogopslag kan zien bv: 80% vind reviews 'zeer belangrijk', maar 70% beoordeeld bedrijf xx op dit punt 'matig'. Dan weet je dat hier verbeterpunten liggen.
ik weet niet of dit mogelijk is, of is het verstandiger om het gewoon simpel te houden
In ieder geval bedankt voor je tip alvast!
Ik ben bijna klaar met het afronden van mijn masterscriptie, maar hik al enige weken tegen hetzelfde probleem aan.
Wat ik heb: iedere respondent kreeg 3 namen onder ogen te zien, OF alle 3 in het Engels OF alle 3 in het Nederlands. Respondenten zelf verschilden qua nationaliteit: het waren Nederlanders of Belgen. Per voorgelegde naam gaven zij hun mening, die vervolgens zijn gecodeerd naar 0 = negatief, 1 = neutraal en 2 = positief. In totaal heb ik 155 (respondenten) x 3 (voorgelegde namen) = 465 meningen.
Wat ik wil: iets zinnigs kunnen zeggen over eventuele verschillen in aantallen. Ik wil in eerste instantie het aantal negatieve, neutrale en positieve meningen vergelijken tussen de Engelse en de Nederlandse versie. Kijken of deze verschillen in totale aantal en in aantal negatieve, neutrale of positieve meningen. Tenslotte zou ik ook nog willen kijken in hoeverre de meningen verschillen als het aankomt op nationaliteit; dus verschilt het totale aantal meningen en het aantal negatieve, neutrale en positieve meningen tussen Belgen en Nederlanders.
Kan iemand mij hiermee helpen?
UPDATE: Ter verduidelijking onderstaande uitkomst van een chi-kwadraat. Kan ik hier nu iets zeggen over dat de totale aantallen significant verschillen. Of ook welke onderling verschillen?
[ Bericht 11% gewijzigd door Jiveje op 08-07-2014 12:16:57 ]
Wat ik heb: iedere respondent kreeg 3 namen onder ogen te zien, OF alle 3 in het Engels OF alle 3 in het Nederlands. Respondenten zelf verschilden qua nationaliteit: het waren Nederlanders of Belgen. Per voorgelegde naam gaven zij hun mening, die vervolgens zijn gecodeerd naar 0 = negatief, 1 = neutraal en 2 = positief. In totaal heb ik 155 (respondenten) x 3 (voorgelegde namen) = 465 meningen.
Wat ik wil: iets zinnigs kunnen zeggen over eventuele verschillen in aantallen. Ik wil in eerste instantie het aantal negatieve, neutrale en positieve meningen vergelijken tussen de Engelse en de Nederlandse versie. Kijken of deze verschillen in totale aantal en in aantal negatieve, neutrale of positieve meningen. Tenslotte zou ik ook nog willen kijken in hoeverre de meningen verschillen als het aankomt op nationaliteit; dus verschilt het totale aantal meningen en het aantal negatieve, neutrale en positieve meningen tussen Belgen en Nederlanders.
Kan iemand mij hiermee helpen?
UPDATE: Ter verduidelijking onderstaande uitkomst van een chi-kwadraat. Kan ik hier nu iets zeggen over dat de totale aantallen significant verschillen. Of ook welke onderling verschillen?

[ Bericht 11% gewijzigd door Jiveje op 08-07-2014 12:16:57 ]
Als ik een Mann-Whitney U test doe met een geïmputeerde dataset, krijg ik wel netjes de P-waarden voor mijn originele data en elke imputatiestap (10), maar ik krijg geen P-waarden voor mijn 'pooled' dataset. Terwijl ik wel ranks krijg voor de pooled data.
Waarom krijg ik hiervoor geen p-waarde en hoe kan ik ervoor zorgen dat ik die wel krijg?
Als ik een two-sample t-test doe, krijg ik wel een p-waarde voor de pooled data, maar dat is natuurlijk niet helemaal netjes, omdat ik niet parametrisch mag testen.
Waarom krijg ik hiervoor geen p-waarde en hoe kan ik ervoor zorgen dat ik die wel krijg?
Als ik een two-sample t-test doe, krijg ik wel een p-waarde voor de pooled data, maar dat is natuurlijk niet helemaal netjes, omdat ik niet parametrisch mag testen.
Een chi-square test alleen of er verschillen zijn, maar niet waar die verschillen zitten.quote:
Ik ben bijna klaar met het afronden van mijn masterscriptie, maar hik al enige weken tegen hetzelfde probleem aan.
Wat ik heb: iedere respondent kreeg 3 namen onder ogen te zien, OF alle 3 in het Engels OF alle 3 in het Nederlands. Respondenten zelf verschilden qua nationaliteit: het waren Nederlanders of Belgen. Per voorgelegde naam gaven zij hun mening, die vervolgens zijn gecodeerd naar 0 = negatief, 1 = neutraal en 2 = positief. In totaal heb ik 155 (respondenten) x 3 (voorgelegde namen) = 465 meningen.
Wat ik wil: iets zinnigs kunnen zeggen over eventuele verschillen in aantallen. Ik wil in eerste instantie het aantal negatieve, neutrale en positieve meningen vergelijken tussen de Engelse en de Nederlandse versie. Kijken of deze verschillen in totale aantal en in aantal negatieve, neutrale of positieve meningen. Tenslotte zou ik ook nog willen kijken in hoeverre de meningen verschillen als het aankomt op nationaliteit; dus verschilt het totale aantal meningen en het aantal negatieve, neutrale en positieve meningen tussen Belgen en Nederlanders.
Kan iemand mij hiermee helpen?
UPDATE: Ter verduidelijking onderstaande uitkomst van een chi-kwadraat. Kan ik hier nu iets zeggen over dat de totale aantallen significant verschillen. Of ook welke onderling verschillen?
[ afbeelding ]
Het gemakkelijkste is om een chi-square uit te voeren voor elk los contrast.
Dus contrast 1: positief vs de rest
Contrast 2: negatief vs de rest
en eventueel (ligt aan je hypothese) neutraal vs de rest.
Wat bedoel je met de pooled data? Kun je de output posten?quote:
Als ik een Mann-Whitney U test doe met een geïmputeerde dataset, krijg ik wel netjes de P-waarden voor mijn originele data en elke imputatiestap (10), maar ik krijg geen P-waarden voor mijn 'pooled' dataset. Terwijl ik wel ranks krijg voor de pooled data.
Waarom krijg ik hiervoor geen p-waarde en hoe kan ik ervoor zorgen dat ik die wel krijg?
Als ik een two-sample t-test doe, krijg ik wel een p-waarde voor de pooled data, maar dat is natuurlijk niet helemaal netjes, omdat ik niet parametrisch mag testen.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Het gaat in dit geval om een Wilcoxon signed ranks test, maar hetzelfde probleem doet zich eigenlijk voor bij alle non-parametrische testen:
Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.


Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.
Whoops sorry, verkeerde knopjequote:
Het gaat in dit geval om een Wilcoxon signed ranks test, maar hetzelfde probleem doet zich eigenlijk voor bij alle non-parametrische testen:
Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.
Ik ben er iets meer ingedoken, en Wilkinson is voor dependent samples (dus elke case wordt 2x gemeten, bv voor en na interventie), ik denk dus niet dat dat de juiste test voor je is.quote:
Het gaat in dit geval om een Wilcoxon signed ranks test, maar hetzelfde probleem doet zich eigenlijk voor bij alle non-parametrische testen:
[ afbeelding ]
[ afbeelding ]
Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.
Welke test wel zou moeten werken is de Mann Whitney. Ik heb zelf net wat data gesimuleerd en dan werkt het gewoon. Misschien heb je je dataset niet goed opgezet? (of misschien begrijp ik verkeerd wat je wilt doen
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik weet dat een Wilcoxon een test is voor dependent samples. Ik heb op dezelfde data zowel een Wilcoxon signed ranks test als een Mann-Whitney U test gedaan, om de within and between groups differences te testen. Daar ging m'n vraag ook niet over.quote:
[..]
Ik ben er iets meer ingedoken, en Wilkinson is voor dependent samples (dus elke case wordt 2x gemeten, bv voor en na interventie), ik denk dus niet dat dat de juiste test voor je is.
Welke test wel zou moeten werken is de Mann Whitney. Ik heb zelf net wat data gesimuleerd en dan werkt het gewoon. Misschien heb je je dataset niet goed opgezet? (of misschien begrijp ik verkeerd wat je wilt doen)
Ik wil weten waarom ik geen testuitslagen krijg voor m'n gepoolde data na imputatie. Ik heb namelijk een p-waarde voor de originele data (voordat er geïmputeerd is voor missing data) en ik wil dus een p-waarde voor m'n dataset na imputatie, dit is de 'pooled data'. Hiervoor krijg ik dus wel descriptives en ranks, maar geen p-waarde.
Nu begin ik het te begrijpen, helaas geen goed nieuws, dat kan niet in SPSS. Je kunt kijken of je een macro er voor kunt vinden.quote:
[..]
Ik weet dat een Wilcoxon een test is voor dependent samples. Ik heb op dezelfde data zowel een Wilcoxon signed ranks test als een Mann-Whitney U test gedaan, om de within and between groups differences te testen. Daar ging m'n vraag ook niet over.
Ik wil weten waarom ik geen testuitslagen krijg voor m'n gepoolde data na imputatie. Ik heb namelijk een p-waarde voor de originele data (voordat er geïmputeerd is voor missing data) en ik wil dus een p-waarde voor m'n dataset na imputatie, dit is de 'pooled data'. Hiervoor krijg ik dus wel descriptives en ranks, maar geen p-waarde.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
quote:
[..]
Nu begin ik het te begrijpen, helaas geen goed nieuws, dat kan niet in SPSS. Je kunt kijken of je een macro er voor kunt vinden.
nou je ik weet het ook niet zeker ik heb nog nooit met imputed data gewerkt, internet zegt allen dat het niet kan. Hier kun je misschien meer vinden: http://jeremyjaytaylor.sq(...)discuss/post/1436944quote:
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Bij partiële correlatie heb ik gevonden dat Y significant negatief gecorreleerd is met X, gecorrigeerd voor W en Z. Om dit visueel weer te geven, gebruik ik een lineaire regressie met Y als dependent variable en X, W en Z als independent variables. Ik laat alle partial plots weergeven.
Echter, X heeft in mijn dataset een range van 38-1120, maar in mijn partial plot krijg ik ook punten in de puntenwolk met een negatieve X-waarde. Als ik mijn X-as wil aanpassen in de chart editor, geeft 'ie aan dat de range in de data loopt van -39 tot 43.
Als ik toch de minimum X-as op 0 zet, is het visuele effect van mijn correlatie weg.
Hoe komt het dat ik een heel andere range van mijn X krijg, en hoe los ik dit op?
Echter, X heeft in mijn dataset een range van 38-1120, maar in mijn partial plot krijg ik ook punten in de puntenwolk met een negatieve X-waarde. Als ik mijn X-as wil aanpassen in de chart editor, geeft 'ie aan dat de range in de data loopt van -39 tot 43.
Als ik toch de minimum X-as op 0 zet, is het visuele effect van mijn correlatie weg.
Hoe komt het dat ik een heel andere range van mijn X krijg, en hoe los ik dit op?
Kun je even screenshotje posten van regressieresultaten en de plotjes?quote:
Bij partiële correlatie heb ik gevonden dat Y significant negatief gecorreleerd is met X, gecorrigeerd voor W en Z. Om dit visueel weer te geven, gebruik ik een lineaire regressie met Y als dependent variable en X, W en Z als independent variables. Ik laat alle partial plots weergeven.
Echter, X heeft in mijn dataset een range van 38-1120, maar in mijn partial plot krijg ik ook punten in de puntenwolk met een negatieve X-waarde. Als ik mijn X-as wil aanpassen in de chart editor, geeft 'ie aan dat de range in de data loopt van -39 tot 43.
Als ik toch de minimum X-as op 0 zet, is het visuele effect van mijn correlatie weg.
Hoe komt het dat ik een heel andere range van mijn X krijg, en hoe los ik dit op?
Ik vermoed overigens dat het komt omdat je x-as niet variabele X weergeeft maar de residuals van X en als dat zo is hoef je dat natuurlijk niet op te lossen
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-



Zo te zien komt dat doordat alleen de partial effecten van beide variabelen geplot zijn (zoals eigenlijk ook hoort). Ik denk dat het mogelijk is om de residuals op te slaan in je dataset dan zou je zelf een plotje IQ vs residuals DV kunnen maken.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Met andere woorden, je kan niet IQ vs DV maken, gecorrigeerd voor een aantal variabelen. Dan moet je dus altijd de residuals plotten?quote:
Zo te zien komt dat doordat alleen de partial effecten van beide variabelen geplot zijn (zoals eigenlijk ook hoort). Ik denk dat het mogelijk is om de residuals op te slaan in je dataset dan zou je zelf een plotje IQ vs residuals DV kunnen maken.