SES School, Studie en Onderwijs
Wiskunde in de brugklas, Frans voor het examen of een studie Personeel en Arbeid? Moeilijke formulieren van DUO? Iets weten over studiefinanciering of studentenverenigingen? Dit is het forum voor leerkrachten, scholieren en studenten, van brugklas tot uni



Nee, tell me more?quote:
Ik heb alleen mijn multipele logistische regressie herhaald met alle originele onafhankelijke variabelen plus de interactieterm. Toen was de interactieterm niet significant, maar de twee onafhankelijke variabelen die eerst wel significant waren, ook niet meer.
Met een F-test test je of je variabelen samen significant zijn, om het in hypethesissen te verwoorden:
F test: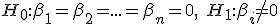 voor een
voor een ![i \in [1,n] \cap \mathbb{N}](https://forum.fok.nl/lib/mimetex.cgi?i%20%5Cin%20%5B1%2Cn%5D%20%5Ccap%20%5Cmathbb%7BN%7D)
T-test: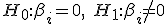
F test:
T-test:
Beste SPSS helden,
Op dit moment ben ik bezig met mijn afstudeeronderzoek en heb een vraag over een SPSS analyse.
Ik doe een onderzoek naar welke behoeften mensen hebben op een webshop en in de fysieke winkel, bijvoorbeeld, in welke mate hebben consumenten behoefte aan reviews op een webshop, of het product aanraken in de winkel etc.
Ook vraag ik in de enquête in welke mate zij de winkel/webshop beoordelen op deze punten.
Zo heb ik 2 vragen gemeten op basis van een 5 punt likert schaal:
- In welke mate vindt u de volgende functies belangrijk op een webshop? --> reviews en beoordelingen
- Hoe beoordeelt u de Euro Funcenter webshop op deze functies? --> reviews en beoordelingen
Op deze manier kan ik zien wat mensen belangrijk vinden en waar er verbeterpunten liggen, of niet.
Weet iemand een mooie duidelijke manier om naast elkaar dit aan te tonen in SPSS? ik kom er zelf niet zo goed uit namelijk. Dus bijvoorbeeld:
100 mensen vinden reviews en beoordelingen zeer belangrijk
80 mensen vinden de reviews en beoordelingen op de webshop matig.
enzovoort.
Ik hoop dat jullie me kunnen helpen!
Op dit moment ben ik bezig met mijn afstudeeronderzoek en heb een vraag over een SPSS analyse.
Ik doe een onderzoek naar welke behoeften mensen hebben op een webshop en in de fysieke winkel, bijvoorbeeld, in welke mate hebben consumenten behoefte aan reviews op een webshop, of het product aanraken in de winkel etc.
Ook vraag ik in de enquête in welke mate zij de winkel/webshop beoordelen op deze punten.
Zo heb ik 2 vragen gemeten op basis van een 5 punt likert schaal:
- In welke mate vindt u de volgende functies belangrijk op een webshop? --> reviews en beoordelingen
- Hoe beoordeelt u de Euro Funcenter webshop op deze functies? --> reviews en beoordelingen
Op deze manier kan ik zien wat mensen belangrijk vinden en waar er verbeterpunten liggen, of niet.
Weet iemand een mooie duidelijke manier om naast elkaar dit aan te tonen in SPSS? ik kom er zelf niet zo goed uit namelijk. Dus bijvoorbeeld:
100 mensen vinden reviews en beoordelingen zeer belangrijk
80 mensen vinden de reviews en beoordelingen op de webshop matig.
enzovoort.
Ik hoop dat jullie me kunnen helpen!
Analyze -> descriptive statistics -> frequenciesquote:Op woensdag 2 juli 2014 11:51 schreef surfertjejesper het volgende:
Beste SPSS helden,
Op dit moment ben ik bezig met mijn afstudeeronderzoek en heb een vraag over een SPSS analyse.
Ik doe een onderzoek naar welke behoeften mensen hebben op een webshop en in de fysieke winkel, bijvoorbeeld, in welke mate hebben consumenten behoefte aan reviews op een webshop, of het product aanraken in de winkel etc.
Ook vraag ik in de enquête in welke mate zij de winkel/webshop beoordelen op deze punten.
Zo heb ik 2 vragen gemeten op basis van een 5 punt likert schaal:
- In welke mate vindt u de volgende functies belangrijk op een webshop? --> reviews en beoordelingen
- Hoe beoordeelt u de Euro Funcenter webshop op deze functies? --> reviews en beoordelingen
Op deze manier kan ik zien wat mensen belangrijk vinden en waar er verbeterpunten liggen, of niet.
Weet iemand een mooie duidelijke manier om naast elkaar dit aan te tonen in SPSS? ik kom er zelf niet zo goed uit namelijk. Dus bijvoorbeeld:
100 mensen vinden reviews en beoordelingen zeer belangrijk
80 mensen vinden de reviews en beoordelingen op de webshop matig.
enzovoort.
Ik hoop dat jullie me kunnen helpen!
Als je zorgt dat je in je variabelen scherm de labels van de values hebt aangepast naar de benamingen die je noemt kun je op deze manier een tabel krijgen met de aantallen die je zoekt.
Als je eerst nog op Charts klikt (voor je op OK klikt) dan kun je nog kiezen uit wat grafiekjes.
Klopt! Deze manier had ik eerst ook. Alleen ik dacht, misschien is er een mooiere manier om dit naast elkaar weer te geven. Zodat je in een snelle oogopslag kan zien bv: 80% vind reviews 'zeer belangrijk', maar 70% beoordeeld bedrijf xx op dit punt 'matig'. Dan weet je dat hier verbeterpunten liggen.quote:
[..]
Analyze -> descriptive statistics -> frequencies
Als je zorgt dat je in je variabelen scherm de labels van de values hebt aangepast naar de benamingen die je noemt kun je op deze manier een tabel krijgen met de aantallen die je zoekt.
Als je eerst nog op Charts klikt (voor je op OK klikt) dan kun je nog kiezen uit wat grafiekjes.
ik weet niet of dit mogelijk is, of is het verstandiger om het gewoon simpel te houden
In ieder geval bedankt voor je tip alvast!
Ah op die manier. Dan zou ik op basis van de frequency tabellen de data in Excel plaatsen en op die manier grafieken maken. Het zal vast ook kunnen in SPSS, maar ik ben niet zo thuis in de Chartbuilder.quote:
[..]
Klopt! Deze manier had ik eerst ook. Alleen ik dacht, misschien is er een mooiere manier om dit naast elkaar weer te geven. Zodat je in een snelle oogopslag kan zien bv: 80% vind reviews 'zeer belangrijk', maar 70% beoordeeld bedrijf xx op dit punt 'matig'. Dan weet je dat hier verbeterpunten liggen.
ik weet niet of dit mogelijk is, of is het verstandiger om het gewoon simpel te houden
In ieder geval bedankt voor je tip alvast!
Ik ben bijna klaar met het afronden van mijn masterscriptie, maar hik al enige weken tegen hetzelfde probleem aan.
Wat ik heb: iedere respondent kreeg 3 namen onder ogen te zien, OF alle 3 in het Engels OF alle 3 in het Nederlands. Respondenten zelf verschilden qua nationaliteit: het waren Nederlanders of Belgen. Per voorgelegde naam gaven zij hun mening, die vervolgens zijn gecodeerd naar 0 = negatief, 1 = neutraal en 2 = positief. In totaal heb ik 155 (respondenten) x 3 (voorgelegde namen) = 465 meningen.
Wat ik wil: iets zinnigs kunnen zeggen over eventuele verschillen in aantallen. Ik wil in eerste instantie het aantal negatieve, neutrale en positieve meningen vergelijken tussen de Engelse en de Nederlandse versie. Kijken of deze verschillen in totale aantal en in aantal negatieve, neutrale of positieve meningen. Tenslotte zou ik ook nog willen kijken in hoeverre de meningen verschillen als het aankomt op nationaliteit; dus verschilt het totale aantal meningen en het aantal negatieve, neutrale en positieve meningen tussen Belgen en Nederlanders.
Kan iemand mij hiermee helpen?
UPDATE: Ter verduidelijking onderstaande uitkomst van een chi-kwadraat. Kan ik hier nu iets zeggen over dat de totale aantallen significant verschillen. Of ook welke onderling verschillen?
[ Bericht 11% gewijzigd door Jiveje op 08-07-2014 12:16:57 ]
Wat ik heb: iedere respondent kreeg 3 namen onder ogen te zien, OF alle 3 in het Engels OF alle 3 in het Nederlands. Respondenten zelf verschilden qua nationaliteit: het waren Nederlanders of Belgen. Per voorgelegde naam gaven zij hun mening, die vervolgens zijn gecodeerd naar 0 = negatief, 1 = neutraal en 2 = positief. In totaal heb ik 155 (respondenten) x 3 (voorgelegde namen) = 465 meningen.
Wat ik wil: iets zinnigs kunnen zeggen over eventuele verschillen in aantallen. Ik wil in eerste instantie het aantal negatieve, neutrale en positieve meningen vergelijken tussen de Engelse en de Nederlandse versie. Kijken of deze verschillen in totale aantal en in aantal negatieve, neutrale of positieve meningen. Tenslotte zou ik ook nog willen kijken in hoeverre de meningen verschillen als het aankomt op nationaliteit; dus verschilt het totale aantal meningen en het aantal negatieve, neutrale en positieve meningen tussen Belgen en Nederlanders.
Kan iemand mij hiermee helpen?
UPDATE: Ter verduidelijking onderstaande uitkomst van een chi-kwadraat. Kan ik hier nu iets zeggen over dat de totale aantallen significant verschillen. Of ook welke onderling verschillen?

[ Bericht 11% gewijzigd door Jiveje op 08-07-2014 12:16:57 ]
Als ik een Mann-Whitney U test doe met een geïmputeerde dataset, krijg ik wel netjes de P-waarden voor mijn originele data en elke imputatiestap (10), maar ik krijg geen P-waarden voor mijn 'pooled' dataset. Terwijl ik wel ranks krijg voor de pooled data.
Waarom krijg ik hiervoor geen p-waarde en hoe kan ik ervoor zorgen dat ik die wel krijg?
Als ik een two-sample t-test doe, krijg ik wel een p-waarde voor de pooled data, maar dat is natuurlijk niet helemaal netjes, omdat ik niet parametrisch mag testen.
Waarom krijg ik hiervoor geen p-waarde en hoe kan ik ervoor zorgen dat ik die wel krijg?
Als ik een two-sample t-test doe, krijg ik wel een p-waarde voor de pooled data, maar dat is natuurlijk niet helemaal netjes, omdat ik niet parametrisch mag testen.
Een chi-square test alleen of er verschillen zijn, maar niet waar die verschillen zitten.quote:
Ik ben bijna klaar met het afronden van mijn masterscriptie, maar hik al enige weken tegen hetzelfde probleem aan.
Wat ik heb: iedere respondent kreeg 3 namen onder ogen te zien, OF alle 3 in het Engels OF alle 3 in het Nederlands. Respondenten zelf verschilden qua nationaliteit: het waren Nederlanders of Belgen. Per voorgelegde naam gaven zij hun mening, die vervolgens zijn gecodeerd naar 0 = negatief, 1 = neutraal en 2 = positief. In totaal heb ik 155 (respondenten) x 3 (voorgelegde namen) = 465 meningen.
Wat ik wil: iets zinnigs kunnen zeggen over eventuele verschillen in aantallen. Ik wil in eerste instantie het aantal negatieve, neutrale en positieve meningen vergelijken tussen de Engelse en de Nederlandse versie. Kijken of deze verschillen in totale aantal en in aantal negatieve, neutrale of positieve meningen. Tenslotte zou ik ook nog willen kijken in hoeverre de meningen verschillen als het aankomt op nationaliteit; dus verschilt het totale aantal meningen en het aantal negatieve, neutrale en positieve meningen tussen Belgen en Nederlanders.
Kan iemand mij hiermee helpen?
UPDATE: Ter verduidelijking onderstaande uitkomst van een chi-kwadraat. Kan ik hier nu iets zeggen over dat de totale aantallen significant verschillen. Of ook welke onderling verschillen?
[ afbeelding ]
Het gemakkelijkste is om een chi-square uit te voeren voor elk los contrast.
Dus contrast 1: positief vs de rest
Contrast 2: negatief vs de rest
en eventueel (ligt aan je hypothese) neutraal vs de rest.
Wat bedoel je met de pooled data? Kun je de output posten?quote:
Als ik een Mann-Whitney U test doe met een geïmputeerde dataset, krijg ik wel netjes de P-waarden voor mijn originele data en elke imputatiestap (10), maar ik krijg geen P-waarden voor mijn 'pooled' dataset. Terwijl ik wel ranks krijg voor de pooled data.
Waarom krijg ik hiervoor geen p-waarde en hoe kan ik ervoor zorgen dat ik die wel krijg?
Als ik een two-sample t-test doe, krijg ik wel een p-waarde voor de pooled data, maar dat is natuurlijk niet helemaal netjes, omdat ik niet parametrisch mag testen.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Het gaat in dit geval om een Wilcoxon signed ranks test, maar hetzelfde probleem doet zich eigenlijk voor bij alle non-parametrische testen:
Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.


Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.
Whoops sorry, verkeerde knopjequote:
Het gaat in dit geval om een Wilcoxon signed ranks test, maar hetzelfde probleem doet zich eigenlijk voor bij alle non-parametrische testen:
Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.
Ik ben er iets meer ingedoken, en Wilkinson is voor dependent samples (dus elke case wordt 2x gemeten, bv voor en na interventie), ik denk dus niet dat dat de juiste test voor je is.quote:
Het gaat in dit geval om een Wilcoxon signed ranks test, maar hetzelfde probleem doet zich eigenlijk voor bij alle non-parametrische testen:
[ afbeelding ]
[ afbeelding ]
Je ziet dus bij de "ranks" wel onderin de pooled data (data van alle imputatiestappen samen) staan, maar niet in de "statistics" tabel. Ik heb echter wel een p-waarde nodig voor mijn WSRT voor de pooled data, omdat dat in principe mijn data is na multipele imputatie.
Als ik parametrisch test (paired t-test), dan krijg ik hiervoor wel een p-waarde.
Welke test wel zou moeten werken is de Mann Whitney. Ik heb zelf net wat data gesimuleerd en dan werkt het gewoon. Misschien heb je je dataset niet goed opgezet? (of misschien begrijp ik verkeerd wat je wilt doen
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik weet dat een Wilcoxon een test is voor dependent samples. Ik heb op dezelfde data zowel een Wilcoxon signed ranks test als een Mann-Whitney U test gedaan, om de within and between groups differences te testen. Daar ging m'n vraag ook niet over.quote:
[..]
Ik ben er iets meer ingedoken, en Wilkinson is voor dependent samples (dus elke case wordt 2x gemeten, bv voor en na interventie), ik denk dus niet dat dat de juiste test voor je is.
Welke test wel zou moeten werken is de Mann Whitney. Ik heb zelf net wat data gesimuleerd en dan werkt het gewoon. Misschien heb je je dataset niet goed opgezet? (of misschien begrijp ik verkeerd wat je wilt doen)
Ik wil weten waarom ik geen testuitslagen krijg voor m'n gepoolde data na imputatie. Ik heb namelijk een p-waarde voor de originele data (voordat er geïmputeerd is voor missing data) en ik wil dus een p-waarde voor m'n dataset na imputatie, dit is de 'pooled data'. Hiervoor krijg ik dus wel descriptives en ranks, maar geen p-waarde.
Nu begin ik het te begrijpen, helaas geen goed nieuws, dat kan niet in SPSS. Je kunt kijken of je een macro er voor kunt vinden.quote:
[..]
Ik weet dat een Wilcoxon een test is voor dependent samples. Ik heb op dezelfde data zowel een Wilcoxon signed ranks test als een Mann-Whitney U test gedaan, om de within and between groups differences te testen. Daar ging m'n vraag ook niet over.
Ik wil weten waarom ik geen testuitslagen krijg voor m'n gepoolde data na imputatie. Ik heb namelijk een p-waarde voor de originele data (voordat er geïmputeerd is voor missing data) en ik wil dus een p-waarde voor m'n dataset na imputatie, dit is de 'pooled data'. Hiervoor krijg ik dus wel descriptives en ranks, maar geen p-waarde.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
quote:
[..]
Nu begin ik het te begrijpen, helaas geen goed nieuws, dat kan niet in SPSS. Je kunt kijken of je een macro er voor kunt vinden.
nou je ik weet het ook niet zeker ik heb nog nooit met imputed data gewerkt, internet zegt allen dat het niet kan. Hier kun je misschien meer vinden: http://jeremyjaytaylor.sq(...)discuss/post/1436944quote:
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Bij partiële correlatie heb ik gevonden dat Y significant negatief gecorreleerd is met X, gecorrigeerd voor W en Z. Om dit visueel weer te geven, gebruik ik een lineaire regressie met Y als dependent variable en X, W en Z als independent variables. Ik laat alle partial plots weergeven.
Echter, X heeft in mijn dataset een range van 38-1120, maar in mijn partial plot krijg ik ook punten in de puntenwolk met een negatieve X-waarde. Als ik mijn X-as wil aanpassen in de chart editor, geeft 'ie aan dat de range in de data loopt van -39 tot 43.
Als ik toch de minimum X-as op 0 zet, is het visuele effect van mijn correlatie weg.
Hoe komt het dat ik een heel andere range van mijn X krijg, en hoe los ik dit op?
Echter, X heeft in mijn dataset een range van 38-1120, maar in mijn partial plot krijg ik ook punten in de puntenwolk met een negatieve X-waarde. Als ik mijn X-as wil aanpassen in de chart editor, geeft 'ie aan dat de range in de data loopt van -39 tot 43.
Als ik toch de minimum X-as op 0 zet, is het visuele effect van mijn correlatie weg.
Hoe komt het dat ik een heel andere range van mijn X krijg, en hoe los ik dit op?
Kun je even screenshotje posten van regressieresultaten en de plotjes?quote:
Bij partiële correlatie heb ik gevonden dat Y significant negatief gecorreleerd is met X, gecorrigeerd voor W en Z. Om dit visueel weer te geven, gebruik ik een lineaire regressie met Y als dependent variable en X, W en Z als independent variables. Ik laat alle partial plots weergeven.
Echter, X heeft in mijn dataset een range van 38-1120, maar in mijn partial plot krijg ik ook punten in de puntenwolk met een negatieve X-waarde. Als ik mijn X-as wil aanpassen in de chart editor, geeft 'ie aan dat de range in de data loopt van -39 tot 43.
Als ik toch de minimum X-as op 0 zet, is het visuele effect van mijn correlatie weg.
Hoe komt het dat ik een heel andere range van mijn X krijg, en hoe los ik dit op?
Ik vermoed overigens dat het komt omdat je x-as niet variabele X weergeeft maar de residuals van X en als dat zo is hoef je dat natuurlijk niet op te lossen
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-



Zo te zien komt dat doordat alleen de partial effecten van beide variabelen geplot zijn (zoals eigenlijk ook hoort). Ik denk dat het mogelijk is om de residuals op te slaan in je dataset dan zou je zelf een plotje IQ vs residuals DV kunnen maken.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Met andere woorden, je kan niet IQ vs DV maken, gecorrigeerd voor een aantal variabelen. Dan moet je dus altijd de residuals plotten?quote:
Zo te zien komt dat doordat alleen de partial effecten van beide variabelen geplot zijn (zoals eigenlijk ook hoort). Ik denk dat het mogelijk is om de residuals op te slaan in je dataset dan zou je zelf een plotje IQ vs residuals DV kunnen maken.
Ola senors en senoritas. Op deze mooie zomerse dag ben ik eens bezig gegaan met SPSS voor mijn masterscriptie, en ik loop eigenlijk al gelijk vast..
Ik wil mijn respondenten selecteren op twee variabelen; doe je X op school of buiten school? Deze twee variabelen lopen van 1 t/m 4 (1 = nooit, 2 = 1 of 2 keer, 3 = +- 1x per week en 4 = meerdere keren per week).
Ik wil mijn respondenten selecteren op dat zij zowel op variabele één als op twee, 2 of hoger geantwoord hebben. Dus ik vul bij select cases in: Var1 = 2 | 3 | 4 & Var2 = 2 | 3 | 4 En vervolgens vertelt SPSS me dat "The sequence of operators found is invalid. Check the expression for ommited or extra operands, operators, and parentheses. Maar ik kan dus echt niet verzinnen wat ik anders zou moeten doen; nergens staat een extra spatie oid. En als ik >1 i.p.v. 2 | 3 | 4 invul krijg ik precies hetzelfde... Wie o wie kan mij helpen?
Ik wil mijn respondenten selecteren op twee variabelen; doe je X op school of buiten school? Deze twee variabelen lopen van 1 t/m 4 (1 = nooit, 2 = 1 of 2 keer, 3 = +- 1x per week en 4 = meerdere keren per week).
Ik wil mijn respondenten selecteren op dat zij zowel op variabele één als op twee, 2 of hoger geantwoord hebben. Dus ik vul bij select cases in: Var1 = 2 | 3 | 4 & Var2 = 2 | 3 | 4 En vervolgens vertelt SPSS me dat "The sequence of operators found is invalid. Check the expression for ommited or extra operands, operators, and parentheses. Maar ik kan dus echt niet verzinnen wat ik anders zou moeten doen; nergens staat een extra spatie oid. En als ik >1 i.p.v. 2 | 3 | 4 invul krijg ik precies hetzelfde... Wie o wie kan mij helpen?

SPSS snapt "Var1 = 2 | 3 | 4" niet.
Dat moet iets zijn als:
(Var1 = 2 | Var1 = 3 | Var1 = 4) & (...)
Dat moet iets zijn als:
(Var1 = 2 | Var1 = 3 | Var1 = 4) & (...)
Aldus.
Kun je wel maar 1 van de twee variabelen selecteren zoals je wil, of komt er dan ook een foutmelding?quote:
Ola senors en senoritas. Op deze mooie zomerse dag ben ik eens bezig gegaan met SPSS voor mijn masterscriptie, en ik loop eigenlijk al gelijk vast..
Ik wil mijn respondenten selecteren op twee variabelen; doe je X op school of buiten school? Deze twee variabelen lopen van 1 t/m 4 (1 = nooit, 2 = 1 of 2 keer, 3 = +- 1x per week en 4 = meerdere keren per week).
Ik wil mijn respondenten selecteren op dat zij zowel op variabele één als op twee, 2 of hoger geantwoord hebben. Dus ik vul bij select cases in: Var1 = 2 | 3 | 4 & Var2 = 2 | 3 | 4 En vervolgens vertelt SPSS me dat "The sequence of operators found is invalid. Check the expression for ommited or extra operands, operators, and parentheses. Maar ik kan dus echt niet verzinnen wat ik anders zou moeten doen; nergens staat een extra spatie oid. En als ik >1 i.p.v. 2 | 3 | 4 invul krijg ik precies hetzelfde... Wie o wie kan mij helpen?
Ga ik even proberen, thanksquote:Op dinsdag 5 augustus 2014 15:24 schreef Z het volgende:
SPSS snapt "Var1 = 2 | 3 | 4" niet.
Dat moet iets zijn als:
(Var1 = 2 | Var1 = 3 | Var1 = 4) & (...)
Eentje lukt wel gewoon inderdaad.quote:
[..]
Kun je wel maar 1 van de twee variabelen selecteren zoals je wil, of komt er dan ook een foutmelding?
quote:
SPSS snapt "Var1 = 2 | 3 | 4" niet.
Dat moet iets zijn als:
(Var1 = 2 | Var1 = 3 | Var1 = 4) & (...)
Alleen moest & in mijn geval | worden, maar dat is mijn eigen fout
Even geprobeerd, als je ook data hebt met veel mogelijkheden: VAR1>1 AND VAR2>1 zou ook moeten werken.quote:
[..]Je bent geweldig
Dit was de oplossing!
Alleen moest & in mijn geval | worden, maar dat is mijn eigen fout
| 1 2 3 4 5 6 7 8 | DATASET ACTIVATE DataSet0. USE ALL. COMPUTE filter_$=(VAR00001>1 AND VAR00002>1). VARIABLE LABELS filter_$ 'VAR00001>1 AND VAR00002>1 (FILTER)'. VALUE LABELS filter_$ 0 'Not Selected' 1 'Selected'. FORMATS filter_$ (f1.0). FILTER BY filter_$. EXECUTE. |
Die had ik ook geprobeerd inderdaad, maar die pakte hij ook niet bij de tweede variabele.quote:
[..]
Even geprobeerd, als je ook data hebt met veel mogelijkheden: VAR1>1 AND VAR2>1 zou ook moeten werken.
[ code verwijderd ]
Oh ja, daar kan ik me vaag iets van herinneren inderdaad. Het is al weer een tijdje geleden dat ik met SPSS heb gewerkt, dus ik moet er echt weer even inkomen.quote:
En als het verschillende waarden moeten zijn ANY(var1,3,6,8)
Super bedankt voor de snelle reacties allemaal!

Beste Fok-buddies(  ),
),
Ik ben voor mijn afstudeeronderzoek gestrand bij de regressie-analyse. Mijn onderzoeksvraag is:
Welke factoren zijn van invloed op de merkmeerwaarde?
Merkmeerwaarde bestaat uit 5 onafhankelijke variabelen (gehaald uit de theorie), namelijk:
• Merkidentiteit
• Merkbetekenis
• Merkrespons
• Merkrelatie
• Content
Deze 5 variabelen heb ik in mijn survey verwerkt in 42 vragen die allen te beantwoorden zijn op basis van een 5-puntsschaal. Vervolgens heb ik een Cronbach's Alpha toegepast op alle factoren en vervolgens de vragen in een schaal geplaatst. Nu rest dus alleen nog een Regressie-analyse om er achter te komen in hoeverre de vijf factoren van invloed zijn op de merkmeerwaarde. ... En zodat ik te weten kom welke factor het meeste van invloed is, zodat ik daar mijn aanbevelingen op kan baseren.
Echter krijg ik bij het uitdraaien van de Regressie-analyse de volgende warning:
"For the final model with dependent variable Merkmeerwaarde, influence statistics can not be computed because the fit is perfect."
Ik begrijp dat dit komt omdat de afhankelijke variabele (Merkmeerwaarde) bestaat uit de 5 onafhankelijke variabelen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content).
Mijn vraag: Hoe kan ik dit oplossen, zodat ik alsnog iets kan zeggen over de invloed van de 5 (afzonderlijke) onafhankelijke variabelen op de afhankelijke variabele? (Welke variabele heeft de meeste invloed / is de sterkste predictor?)
|
|
Ik heb zeg maar 0 les gehad in SPSS en er wordt dan ook niet verwacht dat ik een uitgebreide, wiskundige analyse in mijn scriptie verwerk. Hoe simpeler, hoe beter!
Ik moet uiteraard wel een antwoord kunnen geven op mijn onderzoeksvraag. Ik hoop dat hier iemand een oplossing heeft. In elk geval alvast bedankt!
Ik ben voor mijn afstudeeronderzoek gestrand bij de regressie-analyse. Mijn onderzoeksvraag is:
Welke factoren zijn van invloed op de merkmeerwaarde?
Merkmeerwaarde bestaat uit 5 onafhankelijke variabelen (gehaald uit de theorie), namelijk:
• Merkidentiteit
• Merkbetekenis
• Merkrespons
• Merkrelatie
• Content
Deze 5 variabelen heb ik in mijn survey verwerkt in 42 vragen die allen te beantwoorden zijn op basis van een 5-puntsschaal. Vervolgens heb ik een Cronbach's Alpha toegepast op alle factoren en vervolgens de vragen in een schaal geplaatst. Nu rest dus alleen nog een Regressie-analyse om er achter te komen in hoeverre de vijf factoren van invloed zijn op de merkmeerwaarde. ... En zodat ik te weten kom welke factor het meeste van invloed is, zodat ik daar mijn aanbevelingen op kan baseren.
Echter krijg ik bij het uitdraaien van de Regressie-analyse de volgende warning:
"For the final model with dependent variable Merkmeerwaarde, influence statistics can not be computed because the fit is perfect."
Ik begrijp dat dit komt omdat de afhankelijke variabele (Merkmeerwaarde) bestaat uit de 5 onafhankelijke variabelen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content).
Mijn vraag: Hoe kan ik dit oplossen, zodat ik alsnog iets kan zeggen over de invloed van de 5 (afzonderlijke) onafhankelijke variabelen op de afhankelijke variabele? (Welke variabele heeft de meeste invloed / is de sterkste predictor?)
|
|
Ik heb zeg maar 0 les gehad in SPSS en er wordt dan ook niet verwacht dat ik een uitgebreide, wiskundige analyse in mijn scriptie verwerk. Hoe simpeler, hoe beter!
Ik moet uiteraard wel een antwoord kunnen geven op mijn onderzoeksvraag. Ik hoop dat hier iemand een oplossing heeft. In elk geval alvast bedankt!
Heb je ze wel allemaal apart in je regressie analyse gedaan, dus een voor een ipv allemaal tegelijk?quote:
Beste Fok-buddies(
Ik ben voor mijn afstudeeronderzoek gestrand bij de regressie-analyse. Mijn onderzoeksvraag is:
Welke factoren zijn van invloed op de merkmeerwaarde?
Merkmeerwaarde bestaat uit 5 onafhankelijke variabelen (gehaald uit de theorie), namelijk:
• Merkidentiteit
• Merkbetekenis
• Merkrespons
• Merkrelatie
• Content
Deze 5 variabelen heb ik in mijn survey verwerkt in 42 vragen die allen te beantwoorden zijn op basis van een 5-puntsschaal. Vervolgens heb ik een Cronbach's Alpha toegepast op alle factoren en vervolgens de vragen in een schaal geplaatst. Nu rest dus alleen nog een Regressie-analyse om er achter te komen in hoeverre de vijf factoren van invloed zijn op de merkmeerwaarde. ... En zodat ik te weten kom welke factor het meeste van invloed is, zodat ik daar mijn aanbevelingen op kan baseren.
Echter krijg ik bij het uitdraaien van de Regressie-analyse de volgende warning:
"For the final model with dependent variable Merkmeerwaarde, influence statistics can not be computed because the fit is perfect."
Ik begrijp dat dit komt omdat de afhankelijke variabele (Merkmeerwaarde) bestaat uit de 5 onafhankelijke variabelen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content).
Mijn vraag: Hoe kan ik dit oplossen, zodat ik alsnog iets kan zeggen over de invloed van de 5 (afzonderlijke) onafhankelijke variabelen op de afhankelijke variabele? (Welke variabele heeft de meeste invloed / is de sterkste predictor?)
|
|
Ik heb zeg maar 0 les gehad in SPSS en er wordt dan ook niet verwacht dat ik een uitgebreide, wiskundige analyse in mijn scriptie verwerk. Hoe simpeler, hoe beter!
Ik moet uiteraard wel een antwoord kunnen geven op mijn onderzoeksvraag. Ik hoop dat hier iemand een oplossing heeft. In elk geval alvast bedankt!
Edit: Ik ben er al uit en de vraag was iets te herkenbaar, dus hij is weer weg
[ Bericht 75% gewijzigd door fh101 op 05-08-2014 19:26:28 ]
[ Bericht 75% gewijzigd door fh101 op 05-08-2014 19:26:28 ]
Ja, dat heb ik gedaan maar zodra ik de vijfde dan toevoeg krijg ik de foutmelding. Dat komt waarschijnlijk omdat de 5 onafhankelijke variabelen samen de afhankelijke variabele vormen..quote:
[..]
Heb je ze wel allemaal apart in je regressie analyse gedaan, dus een voor een ipv allemaal tegelijk?
Dat klopt. Dit heet colinneariteit.quote:
[..]
Ja, dat heb ik gedaan maar zodra ik de vijfde dan toevoeg krijg ik de foutmelding. Dat komt waarschijnlijk omdat de 5 onafhankelijke variabelen samen de afhankelijke variabele vormen..
Overigens zegt Cronbachs alfa niets over onderliggende factoren, maar alleen iets over betrouwbaarheid van een schaal (mits je steekproef groot genoeg is, anders is het een slechte schatter maar dat geldt eigenlijk altijd bij statistiek).
Wat je hier wil doen is een zinloze exercitie, omdat je afhankelijke variabele bestaat uit de onafhankelijke variabelen. Dit zegt uiteindelijk dus niets nuttigs.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Cronbachs Alfa is inderdaad om de betrouwbaarheid van de schalen te meten, daar heb ik het ook voor gebruiktquote:
[..]
Dat klopt. Dit heet colinneariteit.
Overigens zegt Cronbachs alfa niets over onderliggende factoren, maar alleen iets over betrouwbaarheid van een schaal (mits je steekproef groot genoeg is, anders is het een slechte schatter maar dat geldt eigenlijk altijd bij statistiek).
Wat je hier wil doen is een zinloze exercitie, omdat je afhankelijke variabele bestaat uit de onafhankelijke variabelen. Dit zegt uiteindelijk dus niets nuttigs.
Hmm, is er geen andere methode om alsnog de gewenste gegevens uitgedraaid te krijgen?
Beste Fokkers, (Dubbelpost, mn topic hierover mag dan wel weg)
Google kan me niet helpen, jullie misschien.
Ik heb in excel nogal wat data gekregen (17.000 respondenten). Nu heb ik dat in excel allemaal wat leesbaarder gemaakt en vervolgens geëxporteerd naar SPSS.
In SPSS is (bijna) alles heel mooi. Alleen 1 variabele heeft als type "string" met een nominal measure maar die moet "numeric" met een linear measure zijn. Als ik dat verander in the variable view vervallen opeens een groot aantal responsen.
Hoe kan ik deze variabele wel veranderen in numeriek zodat ik er wel statistische testen mee kan doen.
Let op: alle data die ingevuld is bij de variabele is al numeriek (1-100). Alleen de instellingen kloppen dus niet.
Ik kijk uit naar reacties!
Google kan me niet helpen, jullie misschien.
Ik heb in excel nogal wat data gekregen (17.000 respondenten). Nu heb ik dat in excel allemaal wat leesbaarder gemaakt en vervolgens geëxporteerd naar SPSS.
In SPSS is (bijna) alles heel mooi. Alleen 1 variabele heeft als type "string" met een nominal measure maar die moet "numeric" met een linear measure zijn. Als ik dat verander in the variable view vervallen opeens een groot aantal responsen.
Hoe kan ik deze variabele wel veranderen in numeriek zodat ik er wel statistische testen mee kan doen.
Let op: alle data die ingevuld is bij de variabele is al numeriek (1-100). Alleen de instellingen kloppen dus niet.
Ik kijk uit naar reacties!
Je vraag is heel erg raar. Je hebt 42 vragen die allemaal voor 1/42 meetellen in een schaal. Nu wil je een regressie doen om te kijken hoeveel die vragen meetellen, wat dus per definitie 1/42 is per vraag.quote:
[..]
Cronbachs Alfa is inderdaad om de betrouwbaarheid van de schalen te meten, daar heb ik het ook voor gebruikt. Maar ik moet nu dus de regressie analyse toepassen om te bekijken in hoeverre de factoren van invloed zijn op de merkmeerwaarde.
Hmm, is er geen andere methode om alsnog de gewenste gegevens uitgedraaid te krijgen?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Komt het toevalllig omdat de antwoorden met punten als decimalen gegeven zijn in excell maar spss met commas werkt oid? Dat is bij mij meestal het probleem. De responses die vervallen, vervallen meestal omdat spss ze niet omgezet krijgt in een nummer, daar zou het probleem dus moeten liggen. Misschien dat er spaties in staat of iets anders?quote:
Beste Fokkers, (Dubbelpost, mn topic hierover mag dan wel weg)
Google kan me niet helpen, jullie misschien.
Ik heb in excel nogal wat data gekregen (17.000 respondenten). Nu heb ik dat in excel allemaal wat leesbaarder gemaakt en vervolgens geëxporteerd naar SPSS.
In SPSS is (bijna) alles heel mooi. Alleen 1 variabele heeft als type "string" met een nominal measure maar die moet "numeric" met een linear measure zijn. Als ik dat verander in the variable view vervallen opeens een groot aantal responsen.
Hoe kan ik deze variabele wel veranderen in numeriek zodat ik er wel statistische testen mee kan doen.
Let op: alle data die ingevuld is bij de variabele is al numeriek (1-100). Alleen de instellingen kloppen dus niet.
Ik kijk uit naar reacties!
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
quote:quote:
0s.gif Op woensdag 6 augustus 2014 17:04 schreef Wallcrawler-GP het volgende:
Beste Fokkers, (Dubbelpost, mn topic hierover mag dan wel weg)
Google kan me niet helpen, jullie misschien.
Ik heb in excel nogal wat data gekregen (17.000 respondenten). Nu heb ik dat in excel allemaal wat leesbaarder gemaakt en vervolgens geëxporteerd naar SPSS.
In SPSS is (bijna) alles heel mooi. Alleen 1 variabele heeft als type "string" met een nominal measure maar die moet "numeric" met een linear measure zijn. Als ik dat verander in the variable view vervallen opeens een groot aantal responsen.
Hoe kan ik deze variabele wel veranderen in numeriek zodat ik er wel statistische testen mee kan doen.
Let op: alle data die ingevuld is bij de variabele is al numeriek (1-100). Alleen de instellingen kloppen dus niet.
Ik kijk uit naar reacties!
Super bedankt! Met zoeken en vervangen de punten voor komma's vervangen en daarna kon ik de variabele wel numeriek maken:)quote:Komt het toevalllig omdat de antwoorden met punten als decimalen gegeven zijn in excell maar spss met commas werkt oid? Dat is bij mij meestal het probleem. De responses die vervallen, vervallen meestal omdat spss ze niet omgezet krijgt in een nummer, daar zou het probleem dus moeten liggen. Misschien dat er spaties in staat of iets anders?
Wel gek want in excel (het originele bestand) stonden alle variabelen gelijk. Allemaal met komma. Alleen voor deze ene variabele maakt spss er een punt van. Maar geen punt, het is opgelost. Bedankt Oompaloompa!
Volgens mij heb ik het fout uitgelegd dan. Ik heb inderdaad 42 vragen, die zijn opgedeeld in 5 schalen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content). Nu wil ik een regressie-analyse inzetten om erachter te komen in hoeverre elke schaal van invloed is op de afhankelijke variabele (merkmeerwaarde) en welke schaal het meest van invloed is.quote:
[..]
Je vraag is heel erg raar. Je hebt 42 vragen die allemaal voor 1/42 meetellen in een schaal. Nu wil je een regressie doen om te kijken hoeveel die vragen meetellen, wat dus per definitie 1/42 is per vraag.
Maar omdat de 5 schalen samen de afhankelijke variabele vormen, geeft SPSS de foutmelding "the fit is perfect". Vandaar mijn vraag of ik op een andere manier kan aantonen in hoeverre de 5 schalen van invloed zijn
Hopelijk is het zo wat duidelijker
Begrijp ik het goed dat elk van die subschalen gemeten wordt met ongeveer 8 van de 42 vragen en dat het alle 42 vragen samen merkmeerwaarde meten?quote:
[..]
Volgens mij heb ik het fout uitgelegd dan. Ik heb inderdaad 42 vragen, die zijn opgedeeld in 5 schalen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content). Nu wil ik een regressie-analyse inzetten om erachter te komen in hoeverre elke schaal van invloed is op de afhankelijke variabele (merkmeerwaarde) en welke schaal het meest van invloed is.
Maar omdat de 5 schalen samen de afhankelijke variabele vormen, geeft SPSS de foutmelding "the fit is perfect". Vandaar mijn vraag of ik op een andere manier kan aantonen in hoeverre de 5 schalen van invloed zijn
Hopelijk is het zo wat duidelijker
Ik heb al een tijd geen regressie-analyse meer gedaan, maar meet je daarmee niet doorgaans de invloed van andere factoren op de afhankelijke variabele? (Factoren zoals leeftijd, salarisschaal etc.)quote:
[..]
Volgens mij heb ik het fout uitgelegd dan. Ik heb inderdaad 42 vragen, die zijn opgedeeld in 5 schalen (merkidentiteit, merkbetekenis, merkrespons, merkrelatie en content). Nu wil ik een regressie-analyse inzetten om erachter te komen in hoeverre elke schaal van invloed is op de afhankelijke variabele (merkmeerwaarde) en welke schaal het meest van invloed is.
Maar omdat de 5 schalen samen de afhankelijke variabele vormen, geeft SPSS de foutmelding "the fit is perfect". Vandaar mijn vraag of ik op een andere manier kan aantonen in hoeverre de 5 schalen van invloed zijn
Hopelijk is het zo wat duidelijker
Je wil nu analyseren hoe een deel van de afhankelijke variabele deel is van de afhankelijke variabele (zo lijkt het in ieder geval.)
Volgens mij bedoelt hij dat ja.quote:
[..]
Begrijp ik het goed dat elk van die subschalen gemeten wordt met ongeveer 8 van de 42 vragen en dat het alle 42 vragen samen merkmeerwaarde meten?
Moet je niet kijken naar hoeveel elk van de scores op de subschalen de variatie op de totale schaal verklaart? Kom je dan niet bij een ANOVA uit? Daar heb ik eigenlijk geen verstand van, moet ik bekennen.
Ik wil erachter komen in hoeverre de 5 schalen van invloed zijn en welke schaal het meest van invloed is (gezien vanuit de consument).quote:
[..]
Ik heb al een tijd geen regressie-analyse meer gedaan, maar meet je daarmee niet doorgaans de invloed van andere factoren op de afhankelijke variabele? (Factoren zoals leeftijd, salarisschaal etc.)
Je wil nu analyseren hoe een deel van de afhankelijke variabele deel is van de afhankelijke variabele (zo lijkt het in ieder geval.)
Dat weet je al: ~8/42quote:
[..]
Ik wil erachter komen in hoeverre de 5 schalen van invloed zijn
Dit lijkt meer op de vraag die je moet stellen inderdaad.quote:en welke schaal het meest van invloed is (gezien vanuit de consument).
Als ik daarmee kan aantonen welke schaal de respondenten van de survey het belangrijkste vinden en welke de grootste invloed heeft op de totale schaal, dan lijkt me dat zeker een oplossing.quote:
Moet je niet kijken naar hoeveel elk van de scores op de subschalen de variatie op de totale schaal verklaart? Kom je dan niet bij een ANOVA uit? Daar heb ik eigenlijk geen verstand van, moet ik bekennen.
Iemand die dit kan bevestigen?