SES School, Studie en Onderwijs
Wiskunde in de brugklas, Frans voor het examen of een studie Personeel en Arbeid? Moeilijke formulieren van DUO? Iets weten over studiefinanciering of studentenverenigingen? Dit is het forum voor leerkrachten, scholieren en studenten, van brugklas tot uni



Super thx! 't is geluktquote:Op vrijdag 5 april 2013 14:46 schreef Z het volgende:
AGGREGATE
/OUTFILE=* MODE=ADDVARIABLES
/BREAK=VAR1
/VAR00002_sum=SUM(VAR2).
Zoiets.
Misschien is mijn vraag wel een eitje voor jullie, maar ik kom er zelf echt niet aan uit.
Ik heb enquêtes ingevuld in SPSS. Ik heb een vraag over een vraag in mijn enquête.
De vraag is:
Wat vind je van de middelen die het bedrijf inzet?
De antwoordmogelijkheden zijn: slecht, neutraal, goed en niet mee bekend.
Dat geven ze dan aan voor: open dag, meeloopdagen, voorlichtingen, website enz.
Nu wil ik eigenlijk in een geclusterd staafdiagram de resultaten weergeven.
Dus op de X-as wil ik dan 'open dag', 'meeloopdagen', 'voorlichtingen' enzovoorts.
En ik hoopte dan een geclusterd staafdiagram te krijgen waarin je per middel kon zien hoeveel respondenten 'slecht, neutraal, goed en niet mee bekend' hadden ingevuld.
Maar als ik alle middelen toevoeg aan het geclusterd staafdiagram, dan kan ik niet op OK drukken.
Kan iemand mij hier mee helpen? Of kan het gewoon niet wat ik wil?
Ik heb enquêtes ingevuld in SPSS. Ik heb een vraag over een vraag in mijn enquête.
De vraag is:
Wat vind je van de middelen die het bedrijf inzet?
De antwoordmogelijkheden zijn: slecht, neutraal, goed en niet mee bekend.
Dat geven ze dan aan voor: open dag, meeloopdagen, voorlichtingen, website enz.
Nu wil ik eigenlijk in een geclusterd staafdiagram de resultaten weergeven.
Dus op de X-as wil ik dan 'open dag', 'meeloopdagen', 'voorlichtingen' enzovoorts.
En ik hoopte dan een geclusterd staafdiagram te krijgen waarin je per middel kon zien hoeveel respondenten 'slecht, neutraal, goed en niet mee bekend' hadden ingevuld.
Maar als ik alle middelen toevoeg aan het geclusterd staafdiagram, dan kan ik niet op OK drukken.
Kan iemand mij hier mee helpen? Of kan het gewoon niet wat ik wil?
Dat wordt denk ik een stacked bar diagram of een histogram.
Maar ik moet zeggen dat ik daar niet heel erg in thuis ben. Ik moet ook altijd heel vaak dingen uitproberen met die grafieken.
Maar ik moet zeggen dat ik daar niet heel erg in thuis ben. Ik moet ook altijd heel vaak dingen uitproberen met die grafieken.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Bij een stacked bar diagram kan ik ook niet op OK klikken, als ik een histogram pak dan krijg ik het gemiddelde (slecht =0, neutraal =1, goed= 2, niet mee bekend=3). Dan komt de open dag bijv. uit op 2.. Maar dat is niet wat ik zoek haha

Waarom doe je het niet in Excel? Dat is qua grafieken veel gebruiksvriendelijker. SPSS data kan je makelijk als .xlsx opslaan en ook je output (bijvoorbeel tabellen) is makkelijk te exporteren naar Excel.
Aldus.
Ik heb een probleem met mijn factor analyse, wanneer ik extract op: 'Based on eigenvalues greater than 1' correleert alles met elkaar, maar wanneer ik extract op: 'fixed number of factors' correleren de items met elkaar die ook met elkaar moeten correleren.
Kan ik in mijn thesis beschreven dat ik gebruik heb gemaakt van 'fixed number of factors', of moet het echt op eigenvalues gebaseerd zijn?
Kan ik in mijn thesis beschreven dat ik gebruik heb gemaakt van 'fixed number of factors', of moet het echt op eigenvalues gebaseerd zijn?
BlaBlaBla
Het aantal factoren moet je baseren op een aantal criteria, bijvoorbeeld Catell's scree plot, Eigenvalues > 1 of een totaal aantal % verklaarde variantie. Dan heb je ook nog parallel analyse maar dat wordt niet zo veel gebruikt en is ook lastiger.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Fixed number of factors mag dus nietquote:Op vrijdag 12 april 2013 11:31 schreef crossover het volgende:
Het aantal factoren moet je baseren op een aantal criteria, bijvoorbeeld Catell's scree plot, Eigenvalues > 1 of een totaal aantal % verklaarde variantie. Dan heb je ook nog parallel analyse maar dat wordt niet zo veel gebruikt en is ook lastiger.
BlaBlaBla
Jawel, maar dan moet je dus op basis van die criteria bepalen hoeveel je er dan precies neemt.quote:
[..]
Fixed number of factors mag dus niet
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Vaak draait men in SPSS twee analyses bij EFA. De eerste om te kijken hoeveel factoren het meest waarschijnlijk 'onder' de variabelen liggen, dat doe je dus met de optie 'Eigenvalues greater than 1'. Vervolgens pas je die criteria toe en draai je de analyse nogmaals met het door jou opgegeven aantal factoren. Dat wordt dan de uiteindelijke output (omdat de pattern en structure matrix dat betreffende aantal factoren weergeeft en dan is niet per se het juiste aantal factoren bij de optie 'Eigenvalues greater than 1').
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Dat is niet lastig voor mij omdat ik gewoon 6 constructs heb, en voor iedere construct heb ik een stel vragen. Dus als ik een fixed number of factors gebruik, pak ik gewoon 6, omdat ik 6 constructs heb. Maar dat mag dus ook gewoonquote:
Vaak draait men in SPSS twee analyses bij EFA. De eerste om te kijken hoeveel factoren het meest waarschijnlijk 'onder' de variabelen liggen, dat doe je dus met de optie 'Eigenvalues greater than 1'. Vervolgens pas je die criteria toe en draai je de analyse nogmaals met het door jou opgegeven aantal factoren. Dat wordt dan de uiteindelijke output (omdat de pattern en structure matrix dat betreffende aantal factoren weergeeft en dan is niet per se het juiste aantal factoren bij de optie 'Eigenvalues greater than 1').
BlaBlaBla
Jup.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Thnks! Ik heb alleen nog 1 'klein' probleempje met mijn principal components analysis. 1 construct lijkt voor geen meter te kloppen, maar die items eruit laten is geen optie. Kan ik die items + model + spss output naar je sturen, ik drop ze wel in een PDFje ofzo. Want ik weet even niet wat ik ermee aan moet. Als je aanbod iig nog staat 
Heb ook nog een andere vraagje, is het altijd nodig om een EFA of een PCA voor een confirmatory factor analysis uit te voeren? Want ik zie dat in veel onderzoeken meteen naar de confirmatory factor analysis wordt gegaan. EFA of een PCA wordt dus geskipt.
[ Bericht 38% gewijzigd door Soldier2000 op 12-04-2013 14:46:43 ]
Heb ook nog een andere vraagje, is het altijd nodig om een EFA of een PCA voor een confirmatory factor analysis uit te voeren? Want ik zie dat in veel onderzoeken meteen naar de confirmatory factor analysis wordt gegaan. EFA of een PCA wordt dus geskipt.
[ Bericht 38% gewijzigd door Soldier2000 op 12-04-2013 14:46:43 ]
BlaBlaBla
Ja hoor, stuur maar op. Liefst idd in pdf inclusief syntax.
Het is niet noodzakelijk om het beide te doen. Kan wel, dat wordt kruisvalidatie (cross-validation) genoemd.
Het is niet noodzakelijk om het beide te doen. Kan wel, dat wordt kruisvalidatie (cross-validation) genoemd.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Als ik in de syntax
COMPUTE varnew=LN(var) doe dat heeft de nieuwe variabele alleen stippeltjes als output. Als ik het via Transform --> compute variable probeer dan is Functions and Special Variables leeg, en dus geen LN te selecteren, what to do?
COMPUTE varnew=LN(var) doe dat heeft de nieuwe variabele alleen stippeltjes als output. Als ik het via Transform --> compute variable probeer dan is Functions and Special Variables leeg, en dus geen LN te selecteren, what to do?
Thanks. Ik heb ze net in excel gezet waar het uiteraard een eitje is. Bepaalde waarden zijn >1 (bijvoorbeeld 0.5), hierbij krijg ik dus negatieve LN waardes. Is dit een probleem?quote:
Het in Excel doen? Wellicht heeft jouw versie van SPSS deze functionaliteit niet.
Het doel van de LN functie is voor leeftijd en expertise een normalere verdeling te krijgen voor regressie analyse.
Nog een vraagje:
1Beide variabelen worden na LN normaler verdeeld dan voorheen. Maar wat schiet ik hiermee op? Wat is het probleem voor je regressie analyse als zo'n variabele niet normaal verdeeld is? Alleen dat P waarde gebaseerd is op een normale verdeling?
2Verder, welke onafhankelijke variabelen controleer je op normale verdeling? Schalen gebaseerd op een likert schaal niet lijkt me? Ik heb ook een schaal die een soort persoonlijkheid meet door bepaalde eigenschappen aan te vinken, hier krijg ieder dus een discrete score voor deze soort persoonlijkheid. Dienst deze ook normaal verdeeld te zijn?
3 Weet iemand hoe het kan dat als ik een variable die eerst een niet normale verdeling heeft transformeer naar een normale verdeling, dat mij regressie model dan een lagere R2 krijgt dan voorheen?
[ Bericht 19% gewijzigd door GoobyPls op 17-04-2013 18:35:52 ]
1Beide variabelen worden na LN normaler verdeeld dan voorheen. Maar wat schiet ik hiermee op? Wat is het probleem voor je regressie analyse als zo'n variabele niet normaal verdeeld is? Alleen dat P waarde gebaseerd is op een normale verdeling?
2Verder, welke onafhankelijke variabelen controleer je op normale verdeling? Schalen gebaseerd op een likert schaal niet lijkt me? Ik heb ook een schaal die een soort persoonlijkheid meet door bepaalde eigenschappen aan te vinken, hier krijg ieder dus een discrete score voor deze soort persoonlijkheid. Dienst deze ook normaal verdeeld te zijn?
3 Weet iemand hoe het kan dat als ik een variable die eerst een niet normale verdeling heeft transformeer naar een normale verdeling, dat mij regressie model dan een lagere R2 krijgt dan voorheen?
[ Bericht 19% gewijzigd door GoobyPls op 17-04-2013 18:35:52 ]
even een vraagje over significantie. Ik heb een t toets uitgevoerd en krijg de volgende resultaten:
(ik heb de naam van de variabelen onduidelijk gemaakt, resultaten van het onderzoek moeten nog even anoniem blijven )
)
Ik heb hier dus drie toetsen uitgevoerd.
Bij de eerste is de p waarde in het tweede blok 0.019 en dus significant, maar in het vierde blok (sig 2 tailed) staat 0.246 en 0.243. Bij welke moet ik nu precies kijken?
Hetzelfde geldt voor de andere toetsen, maar lijkt me dat dit overal hetzelfde wordt toegepast
(ik heb de naam van de variabelen onduidelijk gemaakt, resultaten van het onderzoek moeten nog even anoniem blijven
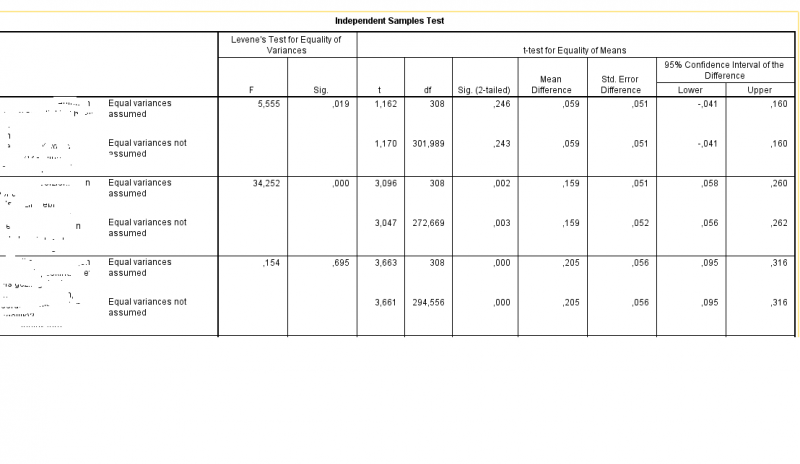
Ik heb hier dus drie toetsen uitgevoerd.
Bij de eerste is de p waarde in het tweede blok 0.019 en dus significant, maar in het vierde blok (sig 2 tailed) staat 0.246 en 0.243. Bij welke moet ik nu precies kijken?
Hetzelfde geldt voor de andere toetsen, maar lijkt me dat dit overal hetzelfde wordt toegepast

links is de significantie van levenes test, en rechts die van de t-testquote:
even een vraagje over significantie. Ik heb een t toets uitgevoerd en krijg de volgende resultaten:
(ik heb de naam van de variabelen onduidelijk gemaakt, resultaten van het onderzoek moeten nog even anoniem blijven
[ afbeelding ]
Ik heb hier dus drie toetsen uitgevoerd.
Bij de eerste is de p waarde in het tweede blok 0.019 en dus significant, maar in het vierde blok (sig 2 tailed) staat 0.246 en 0.243. Bij welke moet ik nu precies kijken?
Hetzelfde geldt voor de andere toetsen, maar lijkt me dat dit overal hetzelfde wordt toegepast
Okee, die linkse dan niet dus, dankje!. Maar hoe kom ik er dan achter of de varianties gelijk zijn of niet?quote:Op donderdag 25 april 2013 18:05 schreef Silverdigger2 het volgende:
[..]
links is de significantie van levenes test, en rechts die van de t-test
Zo frustrerend dit, heb dit nog niet zo lang geleden gehad, maar het is allemaal zo snel weer weggezakt en ik weet niet goed waar ik dit kan vinden

http://academic.udayton.edu/gregelvers/psy216/spss/ttests.htm
en dan de independent sample t-test
succes
en dan de independent sample t-test
succes
Die is helder, thanks!quote:Op vrijdag 26 april 2013 10:35 schreef Silverdigger2 het volgende:
http://academic.udayton.edu/gregelvers/psy216/spss/ttests.htm
en dan de independent sample t-test
succes
weet iemand toevallig hoe je een variabele hercodeert in gemakkelijke syntax?
ik heb een schaal van 0-100 die ik wil omschalen naar afwijkingen van 50.
dus dan wordt 50 -> 0, en 49->1, 51->1, enz. Nu heb ik dit tot nu toe met de hand gedaan, en kan niet echt een syntax voor dit omcoderen vinden via google
moet dit met de hand of heeft iemand hier een trucje voor?
ik heb een schaal van 0-100 die ik wil omschalen naar afwijkingen van 50.
dus dan wordt 50 -> 0, en 49->1, 51->1, enz. Nu heb ik dit tot nu toe met de hand gedaan, en kan niet echt een syntax voor dit omcoderen vinden via google
moet dit met de hand

Zoiets:quote:
weet iemand toevallig hoe je een variabele hercodeert in gemakkelijke syntax?
ik heb een schaal van 0-100 die ik wil omschalen naar afwijkingen van 50.
dus dan wordt 50 -> 0, en 49->1, 51->1, enz. Nu heb ik dit tot nu toe met de hand gedaan, en kan niet echt een syntax voor dit omcoderen vinden via google
moet dit met de hand
COMPUTE Nieuw=ABS(Oud-50).
EXECUTE.
Waarbij Oud de naam van de ongecodeerde variabele is en Nieuw de hercodeerde variabele.
quote:Op maandag 13 mei 2013 09:14 schreef MrBadGuy het volgende:
[..]
Zoiets:
COMPUTE Nieuw=ABS(Oud-50).
EXECUTE.
Waarbij Oud de naam van de ongecodeerde variabele is en Nieuw de hercodeerde variabele.
hmm misschien niet zo duidelijk opgeschreven maar bedoel echt dat zeg maar dat het midden de nieuwe 0 waarden zijn, en dan de rest van de waarden gerekent vanaf 50 een nieuwe absolute schaal zijn.quote:
recode varx (0 thru 50 = 1) (51 thru 100 = 2) into vary.
exe.
val lab vary
1 '0-50'
2 '51-100'
.
50=0, 51=1, 52=2,53=3
en 49=1, 48=2, 47=3.
ben bang dat het typen wordt
edit: gelukt
[ Bericht 4% gewijzigd door Silverdigger2 op 13-05-2013 11:38:03 ]
ben niet zon held met syntax, en bedacht me dat het uitzoeken langer duurde dan het uittypen, maar kan je het zo snel coderen ( 0 thru 50 = 50 thru 0) (51 thru 100 = 1 thru 50) ?quote:
Dat kan je toch gewoon doen door mijn syntax wat aan te passen.
Ik heb een multiple choice vraag met de mogelijkheid tot het geven van meerdere antwoorden in mijn enquete en daar wil ik graag een tabel van. Verder heb ik al gekeken op maar ik kom er niet uit SES / Centraal SPSS Topic
Vraag:
Op welke manier kunnen externen (klanten, leveranciers) contact opnemen met het bedrijf waar u werkzaam bent (meerdere antwoorden mogelijk)?
Variable view: Value, Label:
1 = "Direct mail"
2 = "Website"
3 = "Telefonisch"
4 = "Social-media (Twitter, Google+, Facebook, LinkedIn etc.)"
5 = "E-mail"
6 = "Free publicity"
En bij Dataview heb ik dus meerdere antwoorden: 1, 2, 3, 4, 5, ingevoerd maar dit wilt niet werken. Verder zou ik niet met meerdere Variabelen willen werken omdat ik veel meerkeuzevragen met meerdere antwoorden heb.
Is het mogelijk om dit te analyseren?
Vraag:
Op welke manier kunnen externen (klanten, leveranciers) contact opnemen met het bedrijf waar u werkzaam bent (meerdere antwoorden mogelijk)?
Variable view: Value, Label:
1 = "Direct mail"
2 = "Website"
3 = "Telefonisch"
4 = "Social-media (Twitter, Google+, Facebook, LinkedIn etc.)"
5 = "E-mail"
6 = "Free publicity"
En bij Dataview heb ik dus meerdere antwoorden: 1, 2, 3, 4, 5, ingevoerd maar dit wilt niet werken. Verder zou ik niet met meerdere Variabelen willen werken omdat ik veel meerkeuzevragen met meerdere antwoorden heb.
Is het mogelijk om dit te analyseren?
Beste forummer,
Ik ben bezig met SPSS voor mijn scriptie en heb allemaal categoriserende, discrete variabelen waarbij er op een likert schaal van 1-7 antwoord is gegeven. Vraag is nu welk type regressie ik dien te gebruiken.
Als ik regressie goed begrijp heb je voor lineare regressie een afhankelijke variabele nodig die een continue schaal (bv. leeftijd) heeft. Aangezien mijn afhankelijke variable ordinaal is dien ik volgens mij dus ordinale regressie te gebruiken. Is het hierbij een probleem dat ook mijn onafhankelijke variabelen ordinale variabelen zijn? 4
Verder: hoe kan ik gebruik maken van lineare regressie met deze data, kan dit simpelweg gedaan worden door de 'measure' kolom in het variablen overzicht aan te passen van ordinaal naar schaal om dit te bereiken? Dit zodat mijn discrete variabele in een continue variabele veranderd
Alvast bedankt voor enig antwoord!
Ik ben bezig met SPSS voor mijn scriptie en heb allemaal categoriserende, discrete variabelen waarbij er op een likert schaal van 1-7 antwoord is gegeven. Vraag is nu welk type regressie ik dien te gebruiken.
Als ik regressie goed begrijp heb je voor lineare regressie een afhankelijke variabele nodig die een continue schaal (bv. leeftijd) heeft. Aangezien mijn afhankelijke variable ordinaal is dien ik volgens mij dus ordinale regressie te gebruiken. Is het hierbij een probleem dat ook mijn onafhankelijke variabelen ordinale variabelen zijn? 4
Verder: hoe kan ik gebruik maken van lineare regressie met deze data, kan dit simpelweg gedaan worden door de 'measure' kolom in het variablen overzicht aan te passen van ordinaal naar schaal om dit te bereiken? Dit zodat mijn discrete variabele in een continue variabele veranderd
Alvast bedankt voor enig antwoord!
Maak je gebruik van een Model?quote:
Beste forummer,
Ik ben bezig met SPSS voor mijn scriptie en heb allemaal categoriserende, discrete variabelen waarbij er op een likert schaal van 1-7 antwoord is gegeven. Vraag is nu welk type regressie ik dien te gebruiken.
Als ik regressie goed begrijp heb je voor lineare regressie een afhankelijke variabele nodig die een continue schaal (bv. leeftijd) heeft. Aangezien mijn afhankelijke variable ordinaal is dien ik volgens mij dus ordinale regressie te gebruiken. Is het hierbij een probleem dat ook mijn onafhankelijke variabelen ordinale variabelen zijn? 4
Verder: hoe kan ik gebruik maken van lineare regressie met deze data, kan dit simpelweg gedaan worden door de 'measure' kolom in het variablen overzicht aan te passen van ordinaal naar schaal om dit te bereiken? Dit zodat mijn discrete variabele in een continue variabele veranderd
Alvast bedankt voor enig antwoord!
BlaBlaBla
Als je een conceptueel model bedoeld, ja.
Ik bekijk de invloed van een aantal variabelen op een set andere variabelen. Ik doe dit voor elke afhankelijke variabele opnieuw gezien je maar 1 afhankelijke variabele per keer kan invoeren.
Ik bekijk de invloed van een aantal variabelen op een set andere variabelen. Ik doe dit voor elke afhankelijke variabele opnieuw gezien je maar 1 afhankelijke variabele per keer kan invoeren.
En waarom maak je dan gebruik van SPSS, en niet van Amos of een PLS applicatiequote:
Als je een conceptueel model bedoeld, ja.
Ik bekijk de invloed van een aantal variabelen op een set andere variabelen. Ik doe dit voor elke afhankelijke variabele opnieuw gezien je maar 1 afhankelijke variabele per keer kan invoeren.
BlaBlaBla
Ik gebruik SPSS omdat ik hier kennis en ervaring mee heb en dit programma op mijn computer staat. Voor zowel lineare regressie alswel factor analyse. Geen idee wat Amos of een PLS applicatie zijn.
Kan je verder bevestigen of ik het bij het juiste eind heb met mijn veronderstellingen? Ik heb ervaring met voornamelijk lineare regressie via SPSS door effecten te toetsen of afhankelijke, continue variabelen. Dat gaat bij mijn huidige dataset echter helaas niet op.
Kan je verder bevestigen of ik het bij het juiste eind heb met mijn veronderstellingen? Ik heb ervaring met voornamelijk lineare regressie via SPSS door effecten te toetsen of afhankelijke, continue variabelen. Dat gaat bij mijn huidige dataset echter helaas niet op.
Ga dan toch maar eens kijken naar Amos of bijv. SmartPLS. Ik heb namelijk het idee dat je steeds 1 relatie wilt gaan testen, terwijl je model uit meerdere relaties bestaat. En dan moet je geen SPSS gebruiken, omdat je dan geen rekening houdt met de effecten van andere relaties op die ene relatie die je aan het testen bent.quote:
Ik gebruik SPSS omdat ik hier kennis en ervaring mee heb en dit programma op mijn computer staat. Voor zowel lineare regressie alswel factor analyse. Geen idee wat Amos of een PLS applicatie zijn.
Kan je verder bevestigen of ik het bij het juiste eind heb met mijn veronderstellingen? Ik heb ervaring met voornamelijk lineare regressie via SPSS door effecten te toetsen of afhankelijke, continue variabelen. Dat gaat bij mijn huidige dataset echter helaas niet op.
BlaBlaBla
Ik test meerdere variabelen op één afhankelijke variabele tegelijk en VIF (variance of inflation of iets dergelijks) geeft aan dat er geen colineariteit is dus dat is het probleem niet. Probleem is dat ik een effecten meet van een ordinale schaal op een ordinale schaal maar heb geen idee hoe dit anders zou kunnen.
Ook is via een scatterplot te zien dat er meestal geen lijn in te trekken is in de relatie tussen 2 variabelen en dat het lijkt alsof alle waarden gewoon willekeurig van elkaar zijn.
Ook is via een scatterplot te zien dat er meestal geen lijn in te trekken is in de relatie tussen 2 variabelen en dat het lijkt alsof alle waarden gewoon willekeurig van elkaar zijn.
Laat ik het anders stellen, als jij een valide onderzoek wilt uitvoeren dan moet je je model in 1x testen, dus niet iedere relatie individueel. Daarnaast is de VIF een indicatie, en daar houdt het bij op, er kan nog steeds sprake zijn van enige correlatie tussen variabelen. Daarnaast moet je ook mediation uittestenquote:
Ik test meerdere variabelen op één afhankelijke variabele tegelijk en VIF (variance of inflation of iets dergelijks) geeft aan dat er geen colineariteit is dus dat is het probleem niet. Probleem is dat ik een effecten meet van een ordinale schaal op een ordinale schaal maar heb geen idee hoe dit anders zou kunnen.
Ook is via een scatterplot te zien dat er meestal geen lijn in te trekken is in de relatie tussen 2 variabelen en dat het lijkt alsof alle waarden gewoon willekeurig van elkaar zijn.
In jouw geval zou ik gewoon beginnen met een exploratory factor analysis, en daarna een confirmatory factor analysis uitvoeren. En check voor de gein gewoon eens SmartPLS, er gaat echt een wereld voor je open, trust me
En dat betekent niet dat je SPSS niet meer kunt gebruiken, want SPSS heb je nog steeds nodig voor de EFA, en andere analyses.
Heb je al een frequentie tabel geprobeerd? Analyse - descriptive statistics - frequenties.quote:
Ik heb een multiple choice vraag met de mogelijkheid tot het geven van meerdere antwoorden in mijn enquete en daar wil ik graag een tabel van. Verder heb ik al gekeken op maar ik kom er niet uit SES / Centraal SPSS Topic
Vraag:
Op welke manier kunnen externen (klanten, leveranciers) contact opnemen met het bedrijf waar u werkzaam bent (meerdere antwoorden mogelijk)?
Variable view: Value, Label:
1 = "Direct mail"
2 = "Website"
3 = "Telefonisch"
4 = "Social-media (Twitter, Google+, Facebook, LinkedIn etc.)"
5 = "E-mail"
6 = "Free publicity"
En bij Dataview heb ik dus meerdere antwoorden: 1, 2, 3, 4, 5, ingevoerd maar dit wilt niet werken. Verder zou ik niet met meerdere Variabelen willen werken omdat ik veel meerkeuzevragen met meerdere antwoorden heb.
Is het mogelijk om dit te analyseren?
[ Bericht 16% gewijzigd door Soldier2000 op 21-05-2013 21:20:58 ]
BlaBlaBla
quote:
Ik heb een multiple choice vraag met de mogelijkheid tot het geven van meerdere antwoorden in mijn enquete en daar wil ik graag een tabel van. Verder heb ik al gekeken op maar ik kom er niet uit SES / Centraal SPSS Topic
Vraag:
Op welke manier kunnen externen (klanten, leveranciers) contact opnemen met het bedrijf waar u werkzaam bent (meerdere antwoorden mogelijk)?
Variable view: Value, Label:
1 = "Direct mail"
2 = "Website"
3 = "Telefonisch"
4 = "Social-media (Twitter, Google+, Facebook, LinkedIn etc.)"
5 = "E-mail"
6 = "Free publicity"
En bij Dataview heb ik dus meerdere antwoorden: 1, 2, 3, 4, 5, ingevoerd maar dit wilt niet werken. Verder zou ik niet met meerdere Variabelen willen werken omdat ik veel meerkeuzevragen met meerdere antwoorden heb.
Is het mogelijk om dit te analyseren?
Je moet deze hercoderen naar enkele dichotome variabelen. In jouw geval 6.quote:
Ik heb een multiple choice vraag met de mogelijkheid tot het geven van meerdere antwoorden in mijn enquete en daar wil ik graag een tabel van. Verder heb ik al gekeken op maar ik kom er niet uit SES / Centraal SPSS Topic
Vraag:
Op welke manier kunnen externen (klanten, leveranciers) contact opnemen met het bedrijf waar u werkzaam bent (meerdere antwoorden mogelijk)?
Variable view: Value, Label:
1 = "Direct mail"
2 = "Website"
3 = "Telefonisch"
4 = "Social-media (Twitter, Google+, Facebook, LinkedIn etc.)"
5 = "E-mail"
6 = "Free publicity"
En bij Dataview heb ik dus meerdere antwoorden: 1, 2, 3, 4, 5, ingevoerd maar dit wilt niet werken. Verder zou ik niet met meerdere Variabelen willen werken omdat ik veel meerkeuzevragen met meerdere antwoorden heb.
Is het mogelijk om dit te analyseren?
Vx_1 Direct mail
Vx_2 Website
Vx_3 ...
Vx_4 ...
Vx_5 ...
Vx_6 ...
Een '0' in deze variabele als deze niet gekozen is een '1' als het antwoord wel gekozen is.
Via analyse --> multiple response kan je een multiple response variabele samenstellen en er freq's van draaien.
Aldus.

Ja oke, ik heb alles een aparte variable gegeven wat een hele klus is ..quote:
[..]
[..]
Je moet deze hercoderen naar enkele dichotome variabelen. In jouw geval 6.
Vx_1 Direct mail
Vx_2 Website
Vx_3 ...
Vx_4 ...
Vx_5 ...
Vx_6 ...
Een '0' in deze variabele als deze niet gekozen is een '1' als het antwoord wel gekozen is.
Via analyse --> multiple response kan je een multiple response variabele samenstellen en er freq's van draaien.
Ja maar ik heb verschillende bedrijven met verschillende antwoorden.
Voorbeeld:
Stel eens voor dat ik van 3 bedrijven een enquête heb afgenomen o.a.:
Bedrijf 1: Direct Mail, Website
Bedrijf 2, Free publicity, Direcht mail, Social-media,
Bedrijf 3, Telefonisch
Dan zou ik graag een tabel willen van.
Van de totale 3 bedrijven heeft, 10% direct mail, 5 telefonisch, 80%, social-media ..
Maar dat geeft tie niet aan, hij geeft de response aan:
Case Summary
Cases
Valid Missing Total
N Percent N Percent N Percent
$Bedrijfsbranchea 0 0,0% 72 100,0% 72 100,0%
a Group
Verder heb ik ook een vraag van welke branche een bedrijf zit, dan zou ik daar een pie/cake (taart) diagram van willen met verschil in % van elke branche. Ik kan dat wel 'per' variable doen maar dan krijg ik 20 verschillende taarten..
Omdat mijn vraag op de enquête een meerkeuze vraag was met meerdere antwoorden heb ik dus alles een aparte variabele gegeven bijv.:
Variabel_Visserij = 0 is niet gekozen, 1 is wel gekozen
Variabel_Horeca = ~
Variabel_Dienstverlenend = ~
Maar ik wil alle cirkeldiagrammen samenvoegen enz 1 cirkel hebben met verschillende stukjes
quote:
[..]
[..]
Je moet deze hercoderen naar enkele dichotome variabelen. In jouw geval 6.
Vx_1 Direct mail
Vx_2 Website
Vx_3 ...
Vx_4 ...
Vx_5 ...
Vx_6 ...
Een '0' in deze variabele als deze niet gekozen is een '1' als het antwoord wel gekozen is.
Via analyse --> multiple response kan je een multiple response variabele samenstellen en er freq's van draaien.
Het is mij eindelijk gelukt maar ik kan hier helaas geen bar/pie charts van maken of wel? Voor duidelijke grafieken ter presentatie voor mijn docent ..
Voor mijn thesis gebruik ik het concept 'religiousness' waarbij ik kijk naar vijf items. Het concept is echter ook op te splitsen in twee concepten (sociale aspect en dogmatische aspect van religie).
Theoretisch gezien klopt dit. Statistisch gezien blijft de vijf-item-scale betrouwbaarder dan de drie-item scale en bovendien wijst Factor Analyse uit dat alle vijf de items hoog laden op het concept 'religiousness'. Het betreft dichotome variabelen.
Wat is wijsheid? Het concept splitsen of niet ?
Theoretisch gezien klopt dit. Statistisch gezien blijft de vijf-item-scale betrouwbaarder dan de drie-item scale en bovendien wijst Factor Analyse uit dat alle vijf de items hoog laden op het concept 'religiousness'. Het betreft dichotome variabelen.
Wat is wijsheid? Het concept splitsen of niet ?
FA met 5 items is tricky, het is erg weinig. Wat komt eruit als je twee factoren opgeeft? Wat zijn de eigenvalues?quote:
Voor mijn thesis gebruik ik het concept 'religiousness' waarbij ik kijk naar vijf items. Het concept is echter ook op te splitsen in twee concepten (sociale aspect en dogmatische aspect van religie).
Theoretisch gezien klopt dit. Statistisch gezien blijft de vijf-item-scale betrouwbaarder dan de drie-item scale en bovendien wijst Factor Analyse uit dat alle vijf de items hoog laden op het concept 'religiousness'. Het betreft dichotome variabelen.
Wat is wijsheid? Het concept splitsen of niet ?
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Twee factoren geeft ook duidelijk één factor aan; eigenvalue is 3,571, met 71% v/d variantie.
Component matrix laat ook zien dat 'het sociale aspect' veel hoger laadt (.792) op het algemene concept dan op het tweede concept (.519).
Component matrix laat ook zien dat 'het sociale aspect' veel hoger laadt (.792) op het algemene concept dan op het tweede concept (.519).
wat is de eigenvalue van de tweede factor dan?
hoe groot is je N?
welke rotatie gebruik je?
hoe groot is je N?
welke rotatie gebruik je?
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Tweede factor is 0,488.
N = zo'n 37.000 respondenten.
Rotatie is Oblimin.
Correctie: 'het sociale aspect' laadt 0,519 op de tweede component (samen met nog één item boven de 0.3). Maar het is overduidelijk dat de items beter laden op de eerste (allen boven 0.79).
[ Bericht 54% gewijzigd door Arnoldus_K op 23-05-2013 11:42:34 ]
N = zo'n 37.000 respondenten.
Rotatie is Oblimin.
Correctie: 'het sociale aspect' laadt 0,519 op de tweede component (samen met nog één item boven de 0.3). Maar het is overduidelijk dat de items beter laden op de eerste (allen boven 0.79).
[ Bericht 54% gewijzigd door Arnoldus_K op 23-05-2013 11:42:34 ]
Factors extracten is een combinatie met het bekijken van de criteria's: fixed number of factors, eigen values, scree plot en total variance explained. Als je 2de factor een EV van 0.488 heeft, en de eerste factor een variance explained van 71% heeft, wordt het lastig om er toch 2 factors uit te halen
Ik zou het op 1 factor houden
Ik zou het op 1 factor houden
BlaBlaBla
Je zou nog wel Varimax of Promax kunnen proberen, maar waarschijnlijk heb je dat al gedaan.
BlaBlaBla

Hm, een SPSS probleempje. Hopelijk kan iemand hier me helpen.
Ik moet een regressie uitvoeren waar een interactie in zit. Hierbij test ik hoe het zijn van een immigrant (Znonwestern) invloed heeft op het bewustzijn van deze persoon (ZAON) en hoe de generatie van een de immigrant (Zgeneratie) deze relatie beïnvloedt. Hiervoor heb ik een interactievariabele gemaakt die in het laatste model (model 3) wordt ingevoerd. De syntax ziet er dan als volgt uit:
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT ZAON
/METHOD=ENTER Znonwestern Zgeneratie
/METHOD=ENTER gen_nonwest.
Het probleem is nu dat, wanneer ik dit command run, SPSS automatisch de interactie uit mijn model verwijderd. In mijn output wordt model 3 (daar waar de interactie erbij komt) helemaal niet meer weergegeven. Hij is dan alleen nog maar terug te vinden in de tabel van de 'excluded variables'.
Ik hoop dat ik het zo duidelijk heb omschreven. Heeft iemand enig idee wat hier fout gaat? Of wat de oplossing hiervoor is?

Ik moet een regressie uitvoeren waar een interactie in zit. Hierbij test ik hoe het zijn van een immigrant (Znonwestern) invloed heeft op het bewustzijn van deze persoon (ZAON) en hoe de generatie van een de immigrant (Zgeneratie) deze relatie beïnvloedt. Hiervoor heb ik een interactievariabele gemaakt die in het laatste model (model 3) wordt ingevoerd. De syntax ziet er dan als volgt uit:
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT ZAON
/METHOD=ENTER Znonwestern Zgeneratie
/METHOD=ENTER gen_nonwest.
Het probleem is nu dat, wanneer ik dit command run, SPSS automatisch de interactie uit mijn model verwijderd. In mijn output wordt model 3 (daar waar de interactie erbij komt) helemaal niet meer weergegeven. Hij is dan alleen nog maar terug te vinden in de tabel van de 'excluded variables'.
Ik hoop dat ik het zo duidelijk heb omschreven. Heeft iemand enig idee wat hier fout gaat? Of wat de oplossing hiervoor is?
:)
In je syntax staat dat je maar twee modellen hebt.quote:Op donderdag 23 mei 2013 13:03 schreef TWP het volgende:
Hm, een SPSS probleempje. Hopelijk kan iemand hier me helpen.
Ik moet een regressie uitvoeren waar een interactie in zit. Hierbij test ik hoe het zijn van een immigrant (Znonwestern) invloed heeft op het bewustzijn van deze persoon (ZAON) en hoe de generatie van een de immigrant (Zgeneratie) deze relatie beïnvloedt. Hiervoor heb ik een interactievariabele gemaakt die in het laatste model (model 3) wordt ingevoerd. De syntax ziet er dan als volgt uit:
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT ZAON
/METHOD=ENTER Znonwestern Zgeneratie
/METHOD=ENTER gen_nonwest.
Het probleem is nu dat, wanneer ik dit command run, SPSS automatisch de interactie uit mijn model verwijderd. In mijn output wordt model 3 (daar waar de interactie erbij komt) helemaal niet meer weergegeven. Hij is dan alleen nog maar terug te vinden in de tabel van de 'excluded variables'.
Ik hoop dat ik het zo duidelijk heb omschreven. Heeft iemand enig idee wat hier fout gaat? Of wat de oplossing hiervoor is?
Kan je eens eens de frequentietabellen plaatsen van je variabelen?
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Oja sorry, ik ben m'n controlevariabelen vergeten te vermelden in de syntax. Dat is het eerste model.quote:
[..]
In je syntax staat dat je maar twee modellen hebt.
Kan je eens eens de frequentietabellen plaatsen van je variabelen?
De frequentietabellen zijn als volgt (gestandaardiseerd):
SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.Is dit wat je bedoelt?:)
Ja dat bedoel ik. Waarom heb je alles gestandaardiseerd? Is niet nodig en mag voor categorische / dichotomie variabelen niet eens. Neem daar eens de normale variabelen voor om te kijken of het probleem daarmee te maken heeft. Zo nee, post dan nogmaals de syntax, foutmelding en wat descriptieve gegevens. Vergeet ook niet de assumpties te checken.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Nee, ook daar heeft het niet mee te maken. Maar ik zie al waar het probleem ligt. De verdeling van de interactie is namelijk precies het zelfde als die van een van de hoofdeffecten. Dus de interactie verklaart niks extra's ten opzichte van het hoofdeffect.quote:
Ja dat bedoel ik. Waarom heb je alles gestandaardiseerd? Is niet nodig en mag voor categorische / dichotomie variabelen niet eens. Neem daar eens de normale variabelen voor om te kijken of het probleem daarmee te maken heeft. Zo nee, post dan nogmaals de syntax, foutmelding en wat descriptieve gegevens. Vergeet ook niet de assumpties te checken.
SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.Op welke manier moet ik dan een interactie maken van twee dichitome variabelen?:)
Door de dichotome variabele te vermenigvuldigen met de (andere) variabele.
dus
compute XxY = X * Y.
exeucute.
dus
compute XxY = X * Y.
exeucute.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Dat heb ik inderdaad gedaan, maar dan krijg ik de variabelen die ik in mijn vorige post heb gezet. En dat blijkt niet te werken in de regressie. Ergens gaat het dus niet helemaal goed?quote:
Door de dichotome variabele te vermenigvuldigen met de (andere) variabele.
dus
compute XxY = X * Y.
exeucute.
:)
De variabelen gen en gen_nonwest zijn identiek aan elkaar en worden daarom niet meegenomen in je regressie.quote:
[..]
Dat heb ik inderdaad gedaan, maar dan krijg ik de variabelen die ik in mijn vorige post heb gezet. En dat blijkt niet te werken in de regressie. Ergens gaat het dus niet helemaal goed?
Dat vermoed ik.
Kan je een kruistabel maken en posten?
[ Bericht 2% gewijzigd door crossover op 24-05-2013 14:31:30 ]
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
--
[ Bericht 100% gewijzigd door crossover op 24-05-2013 14:31:25 ]
[ Bericht 100% gewijzigd door crossover op 24-05-2013 14:31:25 ]
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
quote:
[..]
De variabelen gen en gen_nonwest zijn identiek aan elkaar en worden daarom niet meegenomen in je regressie.
Dat vermoed ik.
Kan je een kruistabel maken en posten?

Ik vind het trouwens echt top dat je zo wilt helpen.
:)
NPquote:
[..]
[ afbeelding ]
Ik vind het trouwens echt top dat je zo wilt helpen.
Maar, zoals ik al dacht, er is sprake van multicollineariteit in de meest extreme vorm. Volledige samenhang, variabelen zijn identiek etc etc etc; dus daarom wordt ie eruit gegooid.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Zou je misschien weten op welke manier ik dan de interactie alsnog kan testen? Zou ik het op een andere manier kunnen aanpakken?quote:
[..]
NP
Maar, zoals ik al dacht, er is sprake van multicollineariteit in de meest extreme vorm. Volledige samenhang, variabelen zijn identiek etc etc etc; dus daarom wordt ie eruit gegooid.
:)
Je moet even nagaan hoe het komt dat die variabelen identiek zijn. Als je daar geen verklaring voor hebt en je kunt het niet oplossen dan houdt het op.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Hoi,
refererend naar mijn vraag van vorige week over welke regressie type ik dien te gebruiken heb ik van mijn scriptiebegeleider te horen gekregen dat, indien de afhankelijke en onafhankelijke variabele op dezelfde schaal zijn gemeten (bij mij 1-7 likert scales) je dus gewoon linear regression kan gebruiken (godzijdank).
Mijn vraag is nu, gezien ik 1-7 likert scales categorische data heb, of ik nu chi-square tests kan uitvoeren om te kijken of de variabelen onafhankelijk van elkaar zijn of niet. Nu heb ik een tabel van 7 bij 7 terwijl je in de praktijk meestal 2x2 tabellen ziet. Is mijn tabel nog wel enig verklarend en kan ik pearson's chi-square significantie van dit 7x7 tabel zonder problemen overnemen?
Verder heb ik ook in mijn dataset demografische, categorische data (land, industrie soort, aantal werknemers (onderverdeeld in groepen), en sales (ook onderverdeeld in groepen)) die ik via chi-square wil testen op (on)afhankelijkheid van elke 1-7 likert scale variabele wil testen. Uit de analyse komen helaas weinig significante pearson chi-squares, wat duidt op onafhankelijkheid van de variabele (bijv land=spanje) met een 1-7 likert scale. Klopt ook hier mijn methodiek of dien ik een andere methode toe te passen?
alvast bedankt voor jullie antwoorden!
refererend naar mijn vraag van vorige week over welke regressie type ik dien te gebruiken heb ik van mijn scriptiebegeleider te horen gekregen dat, indien de afhankelijke en onafhankelijke variabele op dezelfde schaal zijn gemeten (bij mij 1-7 likert scales) je dus gewoon linear regression kan gebruiken (godzijdank
Mijn vraag is nu, gezien ik 1-7 likert scales categorische data heb, of ik nu chi-square tests kan uitvoeren om te kijken of de variabelen onafhankelijk van elkaar zijn of niet. Nu heb ik een tabel van 7 bij 7 terwijl je in de praktijk meestal 2x2 tabellen ziet. Is mijn tabel nog wel enig verklarend en kan ik pearson's chi-square significantie van dit 7x7 tabel zonder problemen overnemen?
Verder heb ik ook in mijn dataset demografische, categorische data (land, industrie soort, aantal werknemers (onderverdeeld in groepen), en sales (ook onderverdeeld in groepen)) die ik via chi-square wil testen op (on)afhankelijkheid van elke 1-7 likert scale variabele wil testen. Uit de analyse komen helaas weinig significante pearson chi-squares, wat duidt op onafhankelijkheid van de variabele (bijv land=spanje) met een 1-7 likert scale. Klopt ook hier mijn methodiek of dien ik een andere methode toe te passen?
alvast bedankt voor jullie antwoorden!
Omdat ik een dataset van 173 bedrijven heb is het helaas wel zo dat ik regelmatig minder dan 5 waarnemingen heb per cel, regelmatig 0. Dat zou zeker betekenen dat de chi-square test voor onafhankelijkheid geen goede test is om onafhankelijkheid aan te tonen?
alvast bedankt
alvast bedankt
Beste mensen,
Ik heb een korte SPSS vraag. Voor mij is het de eerste keer dat ik met SPSS werk maar het hoeft allemaal niet zo diepgaand...
Ik meet met 4 vragen de houding van mensen naar een bepaald gedrag. (kwantitatief onderzoek, survey). Het is mij gelukt om deze vier vragen samen te voegen middels Analyse-Dimension reduction--> factor.
Wil ik dit zelfde doen voor een andere variabele die gemeten word door 4 vragen krijg ik 2 outputs van die factor reduction.
Iemand enig idee waarom dit gebeurt en hoe ik deze 2 nu kan vergelijken in bv correlations?
Of betekend dit dat mijn vragen blijkbaar niet het zelfde meten?
Alvast bedankt!
Ik heb een korte SPSS vraag. Voor mij is het de eerste keer dat ik met SPSS werk maar het hoeft allemaal niet zo diepgaand...
Ik meet met 4 vragen de houding van mensen naar een bepaald gedrag. (kwantitatief onderzoek, survey). Het is mij gelukt om deze vier vragen samen te voegen middels Analyse-Dimension reduction--> factor.
Wil ik dit zelfde doen voor een andere variabele die gemeten word door 4 vragen krijg ik 2 outputs van die factor reduction.
Iemand enig idee waarom dit gebeurt en hoe ik deze 2 nu kan vergelijken in bv correlations?
Of betekend dit dat mijn vragen blijkbaar niet het zelfde meten?
Alvast bedankt!
Aigh aigh Captain!
Als je bij factor analyse 2 eigenvalues boven de 1 krijgt dan zijn er 2 factoren. Ofwel, enkele vragen van die 4 behoren dus eigenlijk tot de andere factor en verklaren/meten iets anders. In component matrix oid zie je welke variabele het meeste variantie verklaren van een factor en dus bij de ene of andere factor hoort.
Je kan ook aangeven dat je slechts 1 factor uit de analyse wilt hebben via 'extraction' menu.
Je kan ook aangeven dat je slechts 1 factor uit de analyse wilt hebben via 'extraction' menu.
Bedankt! ik dacht al dat het iets te maken had met wat de vraag eigenlijk mat. Als ik ze geforceerd samen voeg via het extraction menu heeft dat natuurlijk wel impact op de uiteindelijke uitkomst?
Aigh aigh Captain!
Kort vraagje mbt het aanmaken van een 'missing-dummy', die ik vervolgens in een logistische regressie wil meenemen. Deze missing-dummy geeft een '1' aan de cases waarbij de data missing is (voor een betreffende variabele) en een '0' aan de cases waar data wel gewoon aanwezig is.
Heb nu dit syntax-command, maar op de een of andere manier herkent hij de missing values niet.
recode v204 (-2 -1=1)(else=0) into authomis.
Bij een cross-tabulation van v204 & authomis geeft SPSS aan dat de missing-dummy enkel een '0'-categorie heeft, terwijl er meer dan 400 cases zijn met een missing. Heeft dit te maken met hoe de missing-value is aangemerkt in variabele v204?
Heb nu dit syntax-command, maar op de een of andere manier herkent hij de missing values niet.
recode v204 (-2 -1=1)(else=0) into authomis.
Bij een cross-tabulation van v204 & authomis geeft SPSS aan dat de missing-dummy enkel een '0'-categorie heeft, terwijl er meer dan 400 cases zijn met een missing. Heeft dit te maken met hoe de missing-value is aangemerkt in variabele v204?
En direct nog een vraag er achteraan:
Heb in mijn logistische regressie een dichotome afhankelijke variabele 'tol' waarbij 1=tolerant , 0=niet tolerant.
Daarnaast heb ik als onafhankelijke variabele een geaggregeerde variabele van 'tol' aangemaakt, die de gemiddeldes van de landen opneemt. Ik wil zo kijken naar het effect van het 'normatieve klimaat' in een land op individuele tolerantie-niveaus.
Echter, de Odds Ratio is belachelijk hoog, namelijk 482,52. De twee variabelen zijn niet ernstig met elkaar gecorreleerd (0.245) en ook een crosstab wijst multicollineariteit af (zie plaatje).
PS: Geaggregeerde variabele is zo aangemaakt:
AGGREGATE
/break = country
/drugtolmean = mean(drugtol).
freq drugtolmean.
Heb in mijn logistische regressie een dichotome afhankelijke variabele 'tol' waarbij 1=tolerant , 0=niet tolerant.
Daarnaast heb ik als onafhankelijke variabele een geaggregeerde variabele van 'tol' aangemaakt, die de gemiddeldes van de landen opneemt. Ik wil zo kijken naar het effect van het 'normatieve klimaat' in een land op individuele tolerantie-niveaus.
Echter, de Odds Ratio is belachelijk hoog, namelijk 482,52. De twee variabelen zijn niet ernstig met elkaar gecorreleerd (0.245) en ook een crosstab wijst multicollineariteit af (zie plaatje).

PS: Geaggregeerde variabele is zo aangemaakt:
AGGREGATE
/break = country
/drugtolmean = mean(drugtol).
freq drugtolmean.
Ik heb een vraag.
Ik moet (eventuele) mediatie aantonen. Ik heb X (dichotome variabele) en Y uiteraard, en 4 mogelijke mediatoren M1, M2, M3 en M4.
De opdracht: "Voer in SPSS op de bijgeleverde dataset de analyses uit waarmee je test voor mediatie
0 - Alle noodzakelijke regressieanalyses
0 - Sobel-test(s)"
De "hoofdvraag" is of de mate van M1 groter is als X danwel 0, danwel 1 is. (voor de rest kijken of er andere effecten aanwezig zijn dus)
Alleen ik heb nu dus geen ènkel idee hoe ik hier mee moet beginnen... Waarmee moet ik beginnen om bepaalde effecten te bekijken, wat is stap 1? Ik kan op internet wel mediatie analyse vinden, en ook wel met 2 mediatoren, maar niet meer meerdere...
Ik moet (eventuele) mediatie aantonen. Ik heb X (dichotome variabele) en Y uiteraard, en 4 mogelijke mediatoren M1, M2, M3 en M4.
De opdracht: "Voer in SPSS op de bijgeleverde dataset de analyses uit waarmee je test voor mediatie
0 - Alle noodzakelijke regressieanalyses
0 - Sobel-test(s)"
De "hoofdvraag" is of de mate van M1 groter is als X danwel 0, danwel 1 is. (voor de rest kijken of er andere effecten aanwezig zijn dus)
Alleen ik heb nu dus geen ènkel idee hoe ik hier mee moet beginnen... Waarmee moet ik beginnen om bepaalde effecten te bekijken, wat is stap 1? Ik kan op internet wel mediatie analyse vinden, en ook wel met 2 mediatoren, maar niet meer meerdere...
Zoek effe op het Indirect script van Hayes. Misschien lastig om werkend te krijgen, maar als dat het doet dan is het echt ideaal.quote:
Ik heb een vraag.
Ik moet (eventuele) mediatie aantonen. Ik heb X (dichotome variabele) en Y uiteraard, en 4 mogelijke mediatoren M1, M2, M3 en M4.
De opdracht: "Voer in SPSS op de bijgeleverde dataset de analyses uit waarmee je test voor mediatie
0 - Alle noodzakelijke regressieanalyses
0 - Sobel-test(s)"
De "hoofdvraag" is of de mate van M1 groter is als X danwel 0, danwel 1 is. (voor de rest kijken of er andere effecten aanwezig zijn dus)
Alleen ik heb nu dus geen ènkel idee hoe ik hier mee moet beginnen... Waarmee moet ik beginnen om bepaalde effecten te bekijken, wat is stap 1? Ik kan op internet wel mediatie analyse vinden, en ook wel met 2 mediatoren, maar niet meer meerdere...
Dat ziet er dan zo uit:

http://afhayes.com/spss-sas-and-mplus-macros-and-code.html
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Waarom doe je niet gewoon spearman rank correlation?quote:
Hoi,
refererend naar mijn vraag van vorige week over welke regressie type ik dien te gebruiken heb ik van mijn scriptiebegeleider te horen gekregen dat, indien de afhankelijke en onafhankelijke variabele op dezelfde schaal zijn gemeten (bij mij 1-7 likert scales) je dus gewoon linear regression kan gebruiken (godzijdank
Mijn vraag is nu, gezien ik 1-7 likert scales categorische data heb, of ik nu chi-square tests kan uitvoeren om te kijken of de variabelen onafhankelijk van elkaar zijn of niet. Nu heb ik een tabel van 7 bij 7 terwijl je in de praktijk meestal 2x2 tabellen ziet. Is mijn tabel nog wel enig verklarend en kan ik pearson's chi-square significantie van dit 7x7 tabel zonder problemen overnemen?
Verder heb ik ook in mijn dataset demografische, categorische data (land, industrie soort, aantal werknemers (onderverdeeld in groepen), en sales (ook onderverdeeld in groepen)) die ik via chi-square wil testen op (on)afhankelijkheid van elke 1-7 likert scale variabele wil testen. Uit de analyse komen helaas weinig significante pearson chi-squares, wat duidt op onafhankelijkheid van de variabele (bijv land=spanje) met een 1-7 likert scale. Klopt ook hier mijn methodiek of dien ik een andere methode toe te passen?
alvast bedankt voor jullie antwoorden!
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
recode v204 (SYSMIS,-2,-1=1) (else=0) into authomis.quote:
Kort vraagje mbt het aanmaken van een 'missing-dummy', die ik vervolgens in een logistische regressie wil meenemen. Deze missing-dummy geeft een '1' aan de cases waarbij de data missing is (voor een betreffende variabele) en een '0' aan de cases waar data wel gewoon aanwezig is.
Heb nu dit syntax-command, maar op de een of andere manier herkent hij de missing values niet.
recode v204 (-2 -1=1)(else=0) into authomis.
Bij een cross-tabulation van v204 & authomis geeft SPSS aan dat de missing-dummy enkel een '0'-categorie heeft, terwijl er meer dan 400 cases zijn met een missing. Heeft dit te maken met hoe de missing-value is aangemerkt in variabele v204?
execute.
(zoiets, kan zijn dat er ergens een foutje zit want ik doe het uit m'n hoofd. pak anders even de syntax reference erbij)
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Hier is ergens iets fout gegaan, loop al je stappen na en check alles even.quote:
En direct nog een vraag er achteraan:
Heb in mijn logistische regressie een dichotome afhankelijke variabele 'tol' waarbij 1=tolerant , 0=niet tolerant.
Daarnaast heb ik als onafhankelijke variabele een geaggregeerde variabele van 'tol' aangemaakt, die de gemiddeldes van de landen opneemt. Ik wil zo kijken naar het effect van het 'normatieve klimaat' in een land op individuele tolerantie-niveaus.
Echter, de Odds Ratio is belachelijk hoog, namelijk 482,52. De twee variabelen zijn niet ernstig met elkaar gecorreleerd (0.245) en ook een crosstab wijst multicollineariteit af (zie plaatje). [ afbeelding ]
PS: Geaggregeerde variabele is zo aangemaakt:
AGGREGATE
/break = country
/drugtolmean = mean(drugtol).
freq drugtolmean.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Ik vond t eerst een beetje een rare vraag van je, maar heb er nog eens naar gekeken en kan me er wel in vinden. Mijn data is ook eigenlijk niet normaal verdeeld dus dan is spearman een betere correlatietoets dan Pearson.quote:
[..]
Waarom doe je niet gewoon spearman rank correlation?
Betreffende de chi-square toets waar ik eigenlijk een vraag over stelde ga ik nu voor een fischer exact test ipv pearson chi-square, dit gezien ik een kleine dataset heb en er veelal niet aan de eis van pearson chi-square wordt voldaan, ik heb namelijk veelal meer dan 20% lage (<5/10) observed en expected values.
Nogmaals bedankt voor de nieuwe ingevingen.
[ Bericht 0% gewijzigd door Baldadig1989 op 28-05-2013 00:29:07 ]
Ja, het ligt volgens mij niet aan het recode-command. Heb alle mogelijke opties al langsgelopen, maar het blijft een feit dat de '1'-value bij een frequency-uitdraai wél wordt getoond, maar zodra ik een cross-tabulation met de originele variabele draai óf de missing-dummy toevoeg in een logistische regressie, deze er uit wordt gegooid omdat er enkel een waarde '0' bestaat.quote:
recode v204 (SYSMIS,-2,-1=1) (else=0) into authomis.
execute.
(zoiets, kan zijn dat er ergens een foutje zit want ik doe het uit m'n hoofd. pak anders even de syntax reference erbij)

Echter, bij een nominale variabele (waarbij ik de missing values heb vervangen door het gemiddelde, zie plaatje) pakt SPSS wél de missing dummy-value van '1'. Hier zit het verschil. Hoe kan dit?

Heb e.e.a. nagelopen, maar kom niet verder. Feit is dat de odds lager worden als ik één van de volgende opties hanteer. Ik heb weinig inzicht in wat hier 'mag'. Wellicht dat iemand hier hulp bij kan bieden?quote:
Hier is ergens iets fout gegaan, loop al je stappen na en check alles even.
1) Ik maak van de 0-1 schaal een 0-100 schaal. De OR gaat van 482 naar 1,028. (!).
2) Ik gebruik geen dichotome variabele om de geaggregeerde scores aan te maken, maar de originele variabele (met waardes tussen 0-10). De OR gaat van 482 naar 4,7.
3) Ik gebruik logged scores van de eerder aangemaakte dichotome (geaggregeerde!) schaal, om zo de relatieve afstand in acht te nemen. De OR gaat van 482 naar 4,8.
Hopelijk is het voldoende informatie die ik presenteer.
Ik hoop dat iemand mij kan helpen.
Ik moet een aantal variabelen testen in SPSS en ik had eerst n = 82.
Toen moest ik bij een test een boxplot maken, waaruit bleek dat er een aantal outliers waren. De grootste drie outliers heb ik vervolgens uitgesloten (n = 79).
Daarna ging ik verder met de rest van de tests. Moet je nu bij de tests die je nog moet uitvoeren die n = 79 aanhouden, of neem je gewoon weer dat totaal van 82 mee?
Sorry als ik onduidelijk ben of als er info mist. Ben niet echt een held in SPSS en had het werk een behoorlijke tijd weggelegd, waardoor ik er even uit ben.
Ik moet een aantal variabelen testen in SPSS en ik had eerst n = 82.
Toen moest ik bij een test een boxplot maken, waaruit bleek dat er een aantal outliers waren. De grootste drie outliers heb ik vervolgens uitgesloten (n = 79).
Daarna ging ik verder met de rest van de tests. Moet je nu bij de tests die je nog moet uitvoeren die n = 79 aanhouden, of neem je gewoon weer dat totaal van 82 mee?
Sorry als ik onduidelijk ben of als er info mist. Ben niet echt een held in SPSS en had het werk een behoorlijke tijd weggelegd, waardoor ik er even uit ben.
I like you more than pizza, and I really like pizza.
Als je analyses moet/gaat doen waarin de grootste outliers eruit zijn gehaald dan moet je n=79 gebruiken, als je die outliers alleen wilt definiëren/benoemen en verder gewoon analyses doen, dat moet je n=82 gebruiken. De outliers hebben dan natuurlijk wel invloed op je resultaten.
Aangezien je de outliers er al uit heb gehaald lijkt het mij logischer om met de nieuwe populatie van n=79 verder te gaan.
Ik hoop dat ik je hiermee heb geholpen.
Aangezien je de outliers er al uit heb gehaald lijkt het mij logischer om met de nieuwe populatie van n=79 verder te gaan.
Ik hoop dat ik je hiermee heb geholpen.
Bedankt, hier ben ik zeker mee geholpen : )quote:
Als je analyses moet/gaat doen waarin de grootste outliers eruit zijn gehaald dan moet je n=79 gebruiken, als je die outliers alleen wilt definiëren/benoemen en verder gewoon analyses doen, dat moet je n=82 gebruiken. De outliers hebben dan natuurlijk wel invloed op je resultaten.
Aangezien je de outliers er al uit heb gehaald lijkt het mij logischer om met de nieuwe populatie van n=79 verder te gaan.
Ik hoop dat ik je hiermee heb geholpen.
I like you more than pizza, and I really like pizza.
Ook belangrijk, waarom heb je ze uitgesloten?quote:
Ik hoop dat iemand mij kan helpen.
Ik moet een aantal variabelen testen in SPSS en ik had eerst n = 82.
Toen moest ik bij een test een boxplot maken, waaruit bleek dat er een aantal outliers waren. De grootste drie outliers heb ik vervolgens uitgesloten (n = 79).
Daarna ging ik verder met de rest van de tests. Moet je nu bij de tests die je nog moet uitvoeren die n = 79 aanhouden, of neem je gewoon weer dat totaal van 82 mee?
Sorry als ik onduidelijk ben of als er info mist. Ben niet echt een held in SPSS en had het werk een behoorlijke tijd weggelegd, waardoor ik er even uit ben.
BlaBlaBla
Ik mocht alleen respondenten meetellen die Nederlands als moedertaal hadden. Volgens de enquête hadden deze respondenten een zeer lage score aan zichzelf gegeven bij de vraag 'kennis van de Nederlandse taal'.quote:
[..]
Ook belangrijk, waarom heb je ze uitgesloten?
Haha, ik heb zo te zien zojuist mijn eigen vraag beantwoord.. Zoals ik al zei, ik ben er een tijdje uit geweest.. :$
Maar vroeg me dus af of ik dan die tests die ik vóór die boxplot test had gedaan, weer opnieuw moest doen met het nieuwe totaal.
I like you more than pizza, and I really like pizza.
Aaah okai, maar je moet inderdaad eerst je data screenen op missing data, outliers , normality, non response bias en common bias. En daarna ga je met je nieuwe dataset n=79 idd pas beginnen met de reliability en validity van je data.quote:
[..]
Ik mocht alleen respondenten meetellen die Nederlands als moedertaal hadden. Volgens de enquête hadden deze respondenten een zeer lage score aan zichzelf gegeven bij de vraag 'kennis van de Nederlandse taal'.
Haha, ik heb zo te zien zojuist mijn eigen vraag beantwoord.. Zoals ik al zei, ik ben er een tijdje uit geweest.. :$
Maar vroeg me dus af of ik dan die tests die ik vóór die boxplot test had gedaan, weer opnieuw moest doen met het nieuwe totaal.
BlaBlaBla
Okay thanks. Dus dan moet ik toch die eerdere tests maar voor de zekerheid opnieuw uitvoeren met die nieuwe dataset. Voor de rest heb ik alles gecheckt op outliers en missing data, dus dan kan ik met die n=79 de rest van de stapel tests gaan doen.quote:
[..]
Aaah okai, maar je moet inderdaad eerst je data screenen op missing data, outliers , normality, non response bias en common bias. En daarna ga je met je nieuwe dataset n=79 idd pas beginnen met de reliability en validity van je data.
I like you more than pizza, and I really like pizza.
Ik kom even niet uit het volgende. Zo simpel vergeleken met andere SPSS zaken, maar het lukt niet..
Ik moet de gemiddelde leeftijd van de ouders in mijn steekproef berekenen. Sommige ouders hebben de vragenlijst echter voor meerdere kinderen ingevuld en hebben dus meerdere keren hun leeftijd opgegeven. Ik heb respondentnummers, dus ik kan zien wie dit heeft gedaan. Maar hoe zorg ik dat ik hun antwoord maar een keer meeneem in mijn analyses? Daar moet toch een makkelijk trucje voor zijn?
Ik moet de gemiddelde leeftijd van de ouders in mijn steekproef berekenen. Sommige ouders hebben de vragenlijst echter voor meerdere kinderen ingevuld en hebben dus meerdere keren hun leeftijd opgegeven. Ik heb respondentnummers, dus ik kan zien wie dit heeft gedaan. Maar hoe zorg ik dat ik hun antwoord maar een keer meeneem in mijn analyses? Daar moet toch een makkelijk trucje voor zijn?
*komt er veeeeeeel te laat achter dat FOK! hier een topic voor heeft * 
Mag voor persuasieonderzoek anovas en t toetsen doen. Doe ik het al voor in mn broek, maar we gaan zien hoe het gaat lopen en of ik hier nog terug kom in al mijn hysterie.
Mag voor persuasieonderzoek anovas en t toetsen doen. Doe ik het al voor in mn broek, maar we gaan zien hoe het gaat lopen en of ik hier nog terug kom in al mijn hysterie.
Koekje d'r bij?
Voor mijn afstudeerscriptie ben ik bezig met een SPSS-bestand.
Ik heb van vier variabelen een aantal missings. In mijn onderzoek wil ik logistische regressie doen.
Dit betekent dat er veel respondenten afvallen omdat er ergens missings zijn (toch? of kan je sommige respondenten toch mee laten doen, ondanks een missing in één van de variabelen?)
Nou ben ik na wat struinen op internet erachter gekomen dat je met behulp van imputatie missing values kan invullen. Nu is er allereerst de mogelijkheid voor enkelvoudige imputatie (onder missing value analysis is dit te vinden) de andere optie is multipele imputatie, dit houdt dat er meerdere datasets worden toegevoegd. Dus binnen 1 bestand komen er bijvoorbeeld 5 datasets, waarin de missing values zijn ingevuld. Wanneer ik vervolgens logistische regressie doe, krijg ik het probleem dat er ook 5 regressieanalyses worden uitgevoerd?
Welke manier van imputatie is het beste voor mij? En als dit multipele imputatie is, hoe kan ik er één logistische regressie van maken?
Ik heb van vier variabelen een aantal missings. In mijn onderzoek wil ik logistische regressie doen.
Dit betekent dat er veel respondenten afvallen omdat er ergens missings zijn (toch? of kan je sommige respondenten toch mee laten doen, ondanks een missing in één van de variabelen?)
Nou ben ik na wat struinen op internet erachter gekomen dat je met behulp van imputatie missing values kan invullen. Nu is er allereerst de mogelijkheid voor enkelvoudige imputatie (onder missing value analysis is dit te vinden) de andere optie is multipele imputatie, dit houdt dat er meerdere datasets worden toegevoegd. Dus binnen 1 bestand komen er bijvoorbeeld 5 datasets, waarin de missing values zijn ingevuld. Wanneer ik vervolgens logistische regressie doe, krijg ik het probleem dat er ook 5 regressieanalyses worden uitgevoerd?
Welke manier van imputatie is het beste voor mij? En als dit multipele imputatie is, hoe kan ik er één logistische regressie van maken?
Hoeveel respondenten heb je die een missing value hebben, en hoeveel respondenten heb je in totaliteit?quote:
Voor mijn afstudeerscriptie ben ik bezig met een SPSS-bestand.
Ik heb van vier variabelen een aantal missings. In mijn onderzoek wil ik logistische regressie doen.
Dit betekent dat er veel respondenten afvallen omdat er ergens missings zijn (toch? of kan je sommige respondenten toch mee laten doen, ondanks een missing in één van de variabelen?)
Nou ben ik na wat struinen op internet erachter gekomen dat je met behulp van imputatie missing values kan invullen. Nu is er allereerst de mogelijkheid voor enkelvoudige imputatie (onder missing value analysis is dit te vinden) de andere optie is multipele imputatie, dit houdt dat er meerdere datasets worden toegevoegd. Dus binnen 1 bestand komen er bijvoorbeeld 5 datasets, waarin de missing values zijn ingevuld. Wanneer ik vervolgens logistische regressie doe, krijg ik het probleem dat er ook 5 regressieanalyses worden uitgevoerd?
Welke manier van imputatie is het beste voor mij? En als dit multipele imputatie is, hoe kan ik er één logistische regressie van maken?
BlaBlaBla
In totaal is mijn N 279. Daarvan houd ik er 189 over wanneer ik een logistische regressie wil doen.quote:
[..]
Hoeveel respondenten heb je die een missing value hebben, en hoeveel respondenten heb je in totaliteit?
Tjeemig heb je 90 respondents met missing values??quote:
[..]
In totaal is mijn N 279. Daarvan houd ik er 189 over wanneer ik een logistische regressie wil doen.
BlaBlaBla
Het gaat om data uit een systeem (politieverhoren). Niet alle data was te vinden. Bij 90 respondenten is inderdaad in ieder geval 1 variabele missend.quote:
[..]
Tjeemig heb je 90 respondents met missing values??
En wat voor variabelen mis je? Kun je een paar voorbeelden geven. Want iedere methode heeft zo zijn voor en nadelen, en je moet in je thesis echt heel goed gaan onderbouwen hoe je met deze 79 respondenten omgaat.quote:
[..]
Het gaat om data uit een systeem (politieverhoren). Niet alle data was te vinden. Bij 90 respondenten is inderdaad in ieder geval 1 variabele missend.
BlaBlaBla
Al mijn missende variabelen zijn dummyvariabelen (werkend/werkloos ; alcoholgebruik/ geen alcohol gebruik ; ongehuwd / gehuwd ). Mijn informatie van de overige variabelen is compleet (leeftijd / etniciteit / wapengebruik / recidivegedrag / mishandeling ).quote:
[..]
En wat voor variabelen mis je? Kun je een paar voorbeelden geven. Want iedere methode heeft zo zijn voor en nadelen, en je moet in je thesis echt heel goed gaan onderbouwen hoe je met deze 79 respondenten omgaat.
Je hebt het over 79 respondenten; even voor de duidelijkheid: mijn N is 279, waarvan er 90 missings zijn.
Sorry, bedoelde inderdaad 90. Eigenlijk zijn er 3 opties, pairwise deletion, listwise deletion en replacements. Jij hebt zoveel missing values dat ik niet goed zou weten wat in jouw geval de beste oplossing is. Je kunt de cases eruit gooien, maar dat zal waarschijnlijk veel invloed op latere analyses gaan hebben. Als je voor een replacement techniek kiest, dan moet je die nieuwe dataset gebruiken in andere analyses. Alleen je moet wel verdomd goed onderbouwen waarom jij denkt dat dit geen biasen gaat opleveren. Want als je bijv. 50% van je missing values verkeerd zou invullen (met behulp van mean imputatie), dan krijg jij straks waarschijnlijk andere resultaten.quote:
[..]
Al mijn missende variabelen zijn dummyvariabelen (werkend/werkloos ; alcoholgebruik/ geen alcohol gebruik ; ongehuwd / gehuwd ). Mijn informatie van de overige variabelen is compleet (leeftijd / etniciteit / wapengebruik / recidivegedrag / mishandeling ).
Je hebt het over 79 respondenten; even voor de duidelijkheid: mijn N is 279, waarvan er 90 missings zijn.
Ik ben benieuwt wat crossover zijn advies is
BlaBlaBla
Ik heb inmiddels gekozen om de data te imputeren (multipele imputatie bij SPSS), volgens mij is dit de meest betrouwbare methode. De dataset is nu 5 keer geimputeerd. Resultaten uit logistische regressie worden dan gepresenteerd met behulp van de gepoolde uitkomsten. Is dit een verantwoorde manier?quote:
[..]
Sorry, bedoelde inderdaad 90. Eigenlijk zijn er 3 opties, pairwise deletion, listwise deletion en replacements. Jij hebt zoveel missing values dat ik niet goed zou weten wat in jouw geval de beste oplossing is. Je kunt de cases eruit gooien, maar dat zal waarschijnlijk veel invloed op latere analyses gaan hebben. Als je voor een replacement techniek kiest, dan moet je die nieuwe dataset gebruiken in andere analyses. Alleen je moet wel verdomd goed onderbouwen waarom jij denkt dat dit geen biasen gaat opleveren. Want als je bijv. 50% van je missing values verkeerd zou invullen (met behulp van mean imputatie), dan krijg jij straks waarschijnlijk andere resultaten.
Ik ben benieuwt wat crossover zijn advies is
| Forum Opties | |
|---|---|
| Forumhop: | |
| Hop naar: | |