
Hier verder met Deel 5.
Links:
http://www.spsslog.com/
http://www.spss.com/nl/
Aha! Ik snap hetquote:Op maandag 9 juli 2012 23:44 schreef oompaloompa het volgende:
Probleem ontdekt en omdat andere mensen hier misschien ook tegenaan kunnen lopen post ik het hier maar.
Als je een multivariate / manova doet, vallen in principe cases met 1 of meer missing values gewoon af. Omdat je dataset zo veel missings heeft, houdt je uiteindelijk minder dan de helft over. Wat nog cru-er is, is dat van 1 conditie je helemaal niemand meer overhoudt. Daarom kun je geen contrasten meer doen.
Nu zijn er 2 opties:
1 je imputeert de missings.
2 je doet allemaal losse univariates
En die losse univariates had ik al gedaan. Nog één vraagje erover. Maakt dat dan veel uit dat ik nu univariates doe? En moet / kan ik dat dan gewoon verantwoorden in mijn discussie of hoeft dat allemaal niet?
Met allemaal losse toetsen vergroot je de kans op een type 1 fout. En ik zou het inderdaad wel vermelden.quote:
[..]
Aha! Ik snap het
En die losse univariates had ik al gedaan. Nog één vraagje erover. Maakt dat dan veel uit dat ik nu univariates doe? En moet / kan ik dat dan gewoon verantwoorden in mijn discussie of hoeft dat allemaal niet?
Oh God, dat hebben we ook nog jaquote:
[..]
Met allemaal losse toetsen vergroot je de kans op een type 1 fout. En ik zou het inderdaad wel vermelden.
Ah ok, fijn dat je je tabel toegevoegd hebt.quote:
[..]
Thanks, stukje 'meand +/- 1.96*sd omvat 0' is helaas nog even onbekende taal voor mij. Ik heb met studie geen statistiek gehad, en probeer nu zelf snel te leren zo goed en zo kwaad als het kan. Heb even uitdraai gemaakt.
[ afbeelding ]
Nu had ik daarover al wel gelezen in SPSS Survival Guide:
While there are tests that you can use to evaluate skewness and kurtosis values, these are too sensitive with large samples. Tabachnick and Fidell (2007, p. 81) recommend inspecting the shape of the distribution (e.g. using a histogram).
Nu zien zij 200+ als een large sample las ik elders in het boek... terwijl ik n=126 heb
Verderop in het boek adviseren ze iig een Normal Q-Q plot als alternatief.
[..]
Maar wanneer zouden mensen ervaren met statistiek het nog 'reasonable' noemen is dan mijn vraag betreffende bv de Q-Q plot die ik liet zien.
Iemand anders een goede website voor basis tot gemiddeld niveau analyses voor surveys? Werken met likert schalen, multiple choise etc. Ik heb alle data-invoer goed zover ik weet, maar niet overzichtelijk wélke analyses het meest relevant zijn voor een dergelijke enquete. Heb helaas zeer beperkt de tijd me goed in te lezen.
Met skewness en kurtosis kun je een beetje fdoen zoals je ook normale andere toetsen doet.
Als ik kijk naar je skewness (even verzonnen, pas zo de nummers aan) dan zie je dat het gemiddelde .500 is (of zo). Dat betekent dat je gemiddelde .5 afligt van de 0 waar het zou moeten zijn als je geen skewness hebt ("scheve normaalverdeling"). Is dat significant anders? Darvoor gebruik je de standaardverdeling van de skewness (laten we zeggen dat die .2 is even) en die doe je keer 1.96. Nu heb je de 95% confidence interval van je 0.5 mean. Als je die erbij optelt & aftrekt heb je dus een confidence interval van 0.1 -- 0.9. Het gemiddelde waar je op hoopt, 0.0, ligt daar niet tussen. Dit betekent dat je significante skewness hebt en je data dus niet normaal verdeeld is.
Hiervoor zijn een aantal oplossingen.
1. negeren en gewoon doorgaan. Je resultaten zijn minder betrouwbaar, maar als je resultaten heel erg sterk zijn maakt dat niet heel erg veel uit.
2. Je data hercoderen waardoor ze normaal verdeeld raken. Bijvoorbeeld door een log0transformatie of er de wortel van te nemen.
3. Een nonparametrische toets er op toepassen. Deze zijn wat conservatiever maar hebben, bij data die in de buurt van een normaalverdeling liggen minder power.
Als handige guide kan ik Pallant aanraden.
Ja gewoon in je discussie zeggen; vanwege missing values niet mogelijk multivariate te doen dus daarom 4 univariates. Zolang je eerlijk rapporteert is er geen probleem. Als je hypothese per los construct had is er ook geen type-1 probleem, als je alleen overall effect voorspeld had en op ene wel vindt en op andere niet, heb je wel een probleem qua zowel type 1 als type 2 :pquote:
[..]
Aha! Ik snap het
En die losse univariates had ik al gedaan. Nog één vraagje erover. Maakt dat dan veel uit dat ik nu univariates doe? En moet / kan ik dat dan gewoon verantwoorden in mijn discussie of hoeft dat allemaal niet?
Thank you very muchquote:
[..]
Ah ok, fijn dat je je tabel toegevoegd hebt.
Met skewness en kurtosis kun je een beetje fdoen zoals je ook normale andere toetsen doet.
Als ik kijk naar je skewness (even verzonnen, pas zo de nummers aan) dan zie je dat het gemiddelde .500 is (of zo). Dat betekent dat je gemiddelde .5 afligt van de 0 waar het zou moeten zijn als je geen skewness hebt ("scheve normaalverdeling"). Is dat significant anders? Darvoor gebruik je de standaardverdeling van de skewness (laten we zeggen dat die .2 is even) en die doe je keer 1.96. Nu heb je de 95% confidence interval van je 0.5 mean. Als je die erbij optelt & aftrekt heb je dus een confidence interval van 0.1 -- 0.9. Het gemiddelde waar je op hoopt, 0.0, ligt daar niet tussen. Dit betekent dat je significante skewness hebt en je data dus niet normaal verdeeld is.
Hiervoor zijn een aantal oplossingen.
1. negeren en gewoon doorgaan. Je resultaten zijn minder betrouwbaar, maar als je resultaten heel erg sterk zijn maakt dat niet heel erg veel uit.
2. Je data hercoderen waardoor ze normaal verdeeld raken. Bijvoorbeeld door een log0transformatie of er de wortel van te nemen.
3. Een nonparametrische toets er op toepassen. Deze zijn wat conservatiever maar hebben, bij data die in de buurt van een normaalverdeling liggen minder power.
Als handige guide kan ik Pallant aanraden.
[..]
Ja gewoon in je discussie zeggen; vanwege missing values niet mogelijk multivariate te doen dus daarom 4 univariates. Zolang je eerlijk rapporteert is er geen probleem. Als je hypothese per los construct had is er ook geen type-1 probleem, als je alleen overall effect voorspeld had en op ene wel vindt en op andere niet, heb je wel een probleem qua zowel type 1 als type 2 :p
Nog één vraag voor ik weer zelf de boeken in zal duiken: wat doen jullie met enquetes met antwoorden ahv een likert schaal. Behandelen jullie het als numerieke data (1 t/m 5) met Scale dus als measurement type, en daar de passende analyses op loslaten. Of als categorische data met Ordinal als measurement type?
(bonusvraag: als je 5-schalige likert hebt maar tevens een 'geen mening/niet van toepassing' optie, kan je het dan nog wel als ordinal behandelen? Want de optie geen mening/nvt ligt dan niet in lijn met de likert data.
Yeap, als je helemaal een goede indruk wilt maken, interpreteer je nog even op welke wijze dat minder nauwkeurig is. Kan ik je wel mee helpen. In principe komt het er op neer dat je de spreiding aan de ene kant overschat en aan de andere kant onderschat. Afhankelijk van de vergelijking is je toets dus óf te strikt (= goed voor je, zelfs met een te strenge test nog verschil) of een tikkie te zwak (dan moet je uitleggen dat je significantiewaarde waarschijnlijk iets hoger is dan wat spss rapporteert)quote:
[..]
Thank you very muchHet is voor HBO, dus ze zijn wat makkelijker impressed denk ik; dus met dat in achterhoofd zou ik denk ik goed voor optie 1 kunnen gaan en kort uitleggen dat de betrouwbaarheid iets lager ligt omdat de normality niet helemaal voldoet aan de eisen, toch?
Nog één vraag voor ik weer zelf de boeken in zal duiken: wat doen jullie met enquetes met antwoorden ahv een likert schaal. Behandelen jullie het als numerieke data (1 t/m 5) met Scale dus als measurement type, en daar de passende analyses op loslaten. Of als categorische data met Ordinal als measurement type?
(bonusvraag: als je 5-schalige likert hebt maar tevens een 'geen mening/niet van toepassing' optie, kan je het dan nog wel als ordinal behandelen? Want de optie geen mening/nvt ligt dan niet in lijn met de likert data.
Likertschaal is officieel ordinaal maar kun je als scale benaderen (zijn wat simulatiepapers over)
bonusvraag: nee
Moet ik die vragen met likertschaal en de geen mening/nvt recoden zodat alleen likert overblijft? De geen mening/nvt bijvoorbeeld een 'Missing' value geven?
Dit even aannemende dat als men likertschaal vragen in zn enquete heeft, je de beste analyses kan doen met Ordinal en niet met Nominal.
bron kan b.v.http://xa.yimg.com/kq/gro(...)9%25E2%2580%2599.pdf zijn. (dubbelcheck het even, heb alleen net ter plekke abstract bekeken)
Graciasquote:
Ik zou het gewoon als scale doen, doet iedereen. dan voor bonuspunten nog even slim doen en zeggen "is officieel ordinaal, maar (bron) heeft aangetoond dat ook dan scale toegepast kan worden.
bron kan b.v.http://xa.yimg.com/kq/gro(...)9%25E2%2580%2599.pdf zijn. (dubbelcheck het even, heb alleen net ter plekke abstract bekeken)
(de geen mening/nvt nog wel even recoden naar Missing dus? of is daar betere oplossing voor?)
Succes!
Je mag alles doen wat je wilt met getransformeerde variabelen zolang je maar vervolgens bij de interpratie rekening houdt met je transformatie.quote:
Even een vraag over transformaties, ik heb een logtransformatie gedaan voor de afhankelijke variabele. Voor toetsen mag dit allemaal zonder problemen, tegen niet getransformeerde variabelen? Maar geldt dit ook voor een ANOVA?
Als je een single paired comparison ANOVA moet doen, dan kan dat toch gewoon via general linear model --> univariate en dan optie 'single' bij contrasts? Ik heb data uit 3 surveys die ik moet vergelijken, vandaar. Ik heb alle data in 1 groot bestand, met een nieuwe variabele die bij elke respondent aangeeft uit welke survey hij komt.
Volgens mijn begeleider moet ik met allemaal formules en hercoderingen gaan zitten werken
huh? Er van uitgaande dat jij je begeleider goed hebt begrepen heb jij gelijkquote:
Pfff
Als je een single paired comparison ANOVA moet doen, dan kan dat toch gewoon via general linear model --> univariate en dan optie 'single' bij contrasts? Ik heb data uit 3 surveys die ik moet vergelijken, vandaar. Ik heb alle data in 1 groot bestand, met een nieuwe variabele die bij elke respondent aangeeft uit welke survey hij komt.
Volgens mijn begeleider moet ik met allemaal formules en hercoderingen gaan zitten werken
Then again, in principe kun je verschillende surveys niet zo maar met elkaar vergelijken..
Gister zei de begeleider echter: je kunt die drie groepen niet zomaar met elkaar vergelijken vanwege verschil in grootte, je moet een paired comparison ANOVA doen. Nu heb ik me scheel zitten lezen in zo'n kutboek en allemaal zitten kutten met SPSS, maar ik kom niet verder. Dat boek komt met allemaal formules aanzetten (geen idee waar je die zou moeten invoeren), en volgens de tutorials op YouTube kun je gewoon dus doen wat ik omschreef: contrasts --> single selecteren.
Jij ziet er uit als iemand die er meer van weet dan ik: hoe zie jij dat?
Heh? Dat klopt gewoon echt niet.quote:
Thanks voor je antwoord. Dit is de situatie: ik heb drie surveys afgenomen, en wil deze vergelijken op een bepaalde variabele, bijvoorbeeld 'competence'. Wat ik had gedaan: een variabele gemaakt waarin elke respondent getagd wordt uit welke survey hij afkomstig is. Daarmee had ik ANOVA's gemaakt, door gewoon univariate ANOVA te doen. Daar kwam dan een significantie van .182 uit.
Gister zei de begeleider echter: je kunt die drie groepen niet zomaar met elkaar vergelijken vanwege verschil in grootte, je moet een paired comparison ANOVA doen. Nu heb ik me scheel zitten lezen in zo'n kutboek en allemaal zitten kutten met SPSS, maar ik kom niet verder. Dat boek komt met allemaal formules aanzetten (geen idee waar je die zou moeten invoeren), en volgens de tutorials op YouTube kun je gewoon dus doen wat ik omschreef: contrasts --> single selecteren.
Jij ziet er uit als iemand die er meer van weet dan ik: hoe zie jij dat?Als ik het op die laatste manier doe, wordt er dan rekening gehouden met verschil in aantal respondenten?
Als eerste doe je een anova, als daar geen verschil uit blijkt houdt het eigenlijk op.
Je kunt ook nog contrasten tussen de losse groepen doen. je kunt of post-hocs doen (hoef je niks aan te passen) of planned contrasts. Voor planned contrasts is groepsgrootte alleen relevant (volgens mij & collega naast me) als je meerdere groepen samen vergelijkt met andere groepen samen.
Ter illustratie, stel ik heb de volgende groepen
1: n=25
2: n = 50
3: n = 100
4: n = 250
Je kunt gewoon 2 and 3 met elkaar vergelijken.
Wat wel een probleem wordt is als je 1&2 met 3&4 samen zou willen vergelijken, dan moet je binnen die paren rekening houden met groepsgrootte.
wat voor iemand moetik je voorstellen bij je begeleider, wetenschappelijk onderzoeker of eerder mbo-methodologiedocent en zelfgetrained enqueteur?
Ik ben vrij zeker van mijn antwoord, maar het is een beetje afhankelijk van het relatief verschil in expertise op wie je beter af kunt gaan ^^
In mijn geval heb ik hypothesen die over verschil tussen survey1 en survey 2+3 gaan, en hypothesen die tussen verschil tussen survey 1, 2 en 3 gaan.
Survey 1: n=36
Survey 2: n=40
Survey 3: n=28.
Volgens mijn begeleider kan ik deze dus niet zomaar met elkaar vergelijken omdat n teveel verschilt.
Ik had bij alle hypothesen een ANOVA gedaan en nergens kwam trouwens verschil uit.
Ik snap er zelf dus helemaal geen kut van. Godver wat een gezeik
Je begeleider heeft gelijk m.b.t. je eerste toetsquote:
Begeleider is een AIO.
In mijn geval heb ik hypothesen die over verschil tussen survey1 en survey 2+3 gaan, en hypothesen die tussen verschil tussen survey 1, 2 en 3 gaan.
Survey 1: n=36
Survey 2: n=40
Survey 3: n=28.
Volgens mijn begeleider kan ik deze dus niet zomaar met elkaar vergelijken omdat n teveel verschilt.
Ik had bij alle hypothesen een ANOVA gedaan en nergens kwam trouwens verschil uit.
Ik snap er zelf dus helemaal geen kut van. Godver wat een gezeik
daarvoor moet je groep 1 op -1 zetten
groep 2 op 40/68 en groep 3 op 28/68
Omdat groep 2 en 3 een andere grootte hebben moet je ze anders wegen. Overigens is het een beetje zinloos planned contrasts te doen als je geen plan had en de anova sowieso al niet sig is, maar dat terzijde.
Tsjah, het slaat ook nergens op. Al die tijd die in die zinloze analyses gaat zitten, terwijl in beginsel al niks significant isquote:
[..]
Je begeleider heeft gelijk m.b.t. je eerste toets
daarvoor moet je groep 1 op -1 zetten
groep 2 op 40/68 en groep 3 op 28/68
Omdat groep 2 en 3 een andere grootte hebben moet je ze anders wegen. Overigens is het een beetje zinloos planned contrasts te doen als je geen plan had en de anova sowieso al niet sig is, maar dat terzijde.
Ik heb je even PM gestuurd over hoe dat 'op -1 zetten' etc werkt. Hoop dat je er even naar wil kijken. Thanks alvast
De hypothese is dat het verschil tussen survey 1 en 2/3 voor var1 groter is dan voor var2.
Hoe moet ik dit nu doen? Als ik snel een repeated measure ANOVA doe dan komen er allemaal dingen uit waarvan ik niet echt snap wat ze betekenen. Ik kan ook geen onderscheid zien tussen survey 1 en 2/3. Is er iemand die me kan helpen?
Was je hier al uitgekomen of heb je nog steeds hulp nodig?quote:
Mensen, ben ik weer. Ik ben er bijna helemaal uit, ik moet alleen nog een repeated measure ANOVA doen voor twee variabelen. Laat ik ze even var1 en var2 noemen. Ik wil de score van de respondenten uit survey 1 op deze variabelen vergelijken met de score van de respondenten op survey2+3 samen. Var1 en var2 zijn within-subject variabelen, en survey1 en survey2+3 zijn natuurlijk between-variabelen, dus moet ik van mijn begeleider een repeated measure doen. Zoals ik hier al zei: ik heb een grote dataset met alle respondenten erin, en zelf een soort variabele aangemaakt die aangeeft uit welke survey mensen afkomstig zijn.
De hypothese is dat het verschil tussen survey 1 en 2/3 voor var1 groter is dan voor var2.
Hoe moet ik dit nu doen? Als ik snel een repeated measure ANOVA doe dan komen er allemaal dingen uit waarvan ik niet echt snap wat ze betekenen. Ik kan ook geen onderscheid zien tussen survey 1 en 2/3. Is er iemand die me kan helpen?
Zo ja, kun je even een screenshot maken van wat je in het eerste en wteede scherm van repeated in hebt gevuld?
Bedankt!
Hoe moet ik dit precies interpreteren en is het gewoon invoegen van year-dummies de beste manier om te controleren op jaarinvloeden op data?
Nice, hoop dat het allemaal goedgekeurd wordtquote:
Ik denk dat ik eruit ben, ik zal morgen even laten weten wat de begeleider ervan zei... Misschien moet ik het wel opnieuw doen (weet niet zeker of ik het goed heb gedaan), als dat zo is dan geef ik weer even een sein.
Bedankt!
Interpretatie; verschillen op dv worden verklaard door jaar-verschillen.quote:
Ik heb ook even een vraag over een onderzoek van mij. Ik heb van mijn afhankelijke variabele data verzameld over 10 jaar verspreid. Vervolgens een een regressieanalyse met 7 onafhankelijke variabelen. Uitkomsten hiervan waren prachtig ook al omdat ik wist dat die zaken een sterk effect zouden hebben op mijn afhankelijke variabele. Nu wilt mijn begeleider alleen dat ik ook jaar-dummies gebruik. Als ik dit echter doe is het effect van een jaar enorm op mijn afhankelijke variabele en de effecten van al mijn eerste onafhankelijke variabelen zijn nu nihil.
Hoe moet ik dit precies interpreteren en is het gewoon invoegen van year-dummies de beste manier om te controleren op jaarinvloeden op data?
Dummies is waarschijnlijk niet het beste, het geeft je erg veel degrees of freedom. Is er een reden warom je jaar niet als continue kunt zien? En heb je niet per proefpersoon een meting per jaar?
Overigens is 17 IV's echt enorm veel, hoe groot is je dataset?
Ik probeer het aantal fusie's en overnames in Europa over 11 jaar gezien (per maand bekeken) te verklaren door 7 economische indicatoren. Ik heb dus voor 132 maanden het aantal fusies en overnames en daarbij dan die waarden van de indicatoren voor de betreffende periode. Ik begrijp dat 17 IV's echt heel veel is, maar mijn begeleider blijft maar doorzeuren over het controleren op jaarinvloeden. Is er dan nog een andere manier waarop ik iets kan doen met de invloed van het jaar zelf zonder dummies te gebruiken?quote:
[..]
Interpretatie; verschillen op dv worden verklaard door jaar-verschillen.
Dummies is waarschijnlijk niet het beste, het geeft je erg veel degrees of freedom. Is er een reden warom je jaar niet als continue kunt zien? En heb je niet per proefpersoon een meting per jaar?
Overigens is 17 IV's echt enorm veel, hoe groot is je dataset?
Dit is echt totaal niet wat ik normaal doe, dus ik kan het moeilijk beantwoorden. Aangenomen dat jaar geen linear verband heeft kun je het niet als losse variabele meenemen, maar dummies lijkt me ook echt een waardeloze oplossing, moet ik even over nadenken. (ik doe voornamelijk experimenteel onderzoek dus ben minder thuis in correlationeel onderzoek en modelleren, alhoewel ik wel wat relevante statistiek vakken er over heb gehad, maar dat is ondertussen een beetje weggezaktquote:
[..]
Ik probeer het aantal fusie's en overnames in Europa over 11 jaar gezien (per maand bekeken) te verklaren door 7 economische indicatoren. Ik heb dus voor 132 maanden het aantal fusies en overnames en daarbij dan die waarden van de indicatoren voor de betreffende periode. Ik begrijp dat 17 IV's echt heel veel is, maar mijn begeleider blijft maar doorzeuren over het controleren op jaarinvloeden. Is er dan nog een andere manier waarop ik iets kan doen met de invloed van het jaar zelf zonder dummies te gebruiken?
Dan een andere vraag, het lijkt me logisch dat jaar samenhant met veel van die economische indicatoren, ik weet niet welke indicatoren je gebruikt maar als er een effect van jaar is, zou ik juist verwachten dat dat via die economische factoren gaat (2001 was een slecht jaar economische gezien, daardoor waren er meer overnames). Als dat zo is, en je controleert voor jaar, controleer je onbedoeld ook juist voor de dingen waarin je geinteresseerd bent, lijkt me ook niet de bedoeling..
En ik heb dichotomous gedaan, dus 1tjes en nulletjes. Maar heb ook cases erbij die de hele vraag niet beantwoord hebben, daar heb ik nu allemaal 0 staan. Maakt dat nog wat uit voor de analyses? Moet ik die vervangen met bv 99 - missing value? Of kijkt SPSS sowieso alleen naar de 1tjes en maakt het niet uit?
Nog een vraag over MPR:
Als je bijvoorbeeld de vraag hebt 'In welk(e) land(en) bent u op vakantie geweest in 2011?' en men kan meerdere antwoorden aanvinken.
En frequentietabel van de MPR geeft bijvoorbeeld aan dat 60% van de cases in Spanje is geweest en 40% van de cases in Italië....
.. is het dan vervolgens ook mogelijk om te kijken hoeveel cases er zowel in Spanje als Italië zijn geweest in 2011?
En zoja kan je die dan vervolgens in een variabele stoppen zodat je analyses kan doen over het segment dat in beide landen is geweest?
BVD!
Select cases klikken en dan select cases if... Daar kun je aangeven dat alleen cases meedoen die in een bepaald land zijn geweest. Ook kun je met het AND commando alleen de cases selecteren die in beide landen zijn geweest. Bijvoorbeeld: if Spanje = 1 AND Italië = 1. Ik ga er even vanuit dat zo je variabelen heten en dat 1 staat voor "er op vakantie geweest". Dan selecteer je dus alleen cases die in beide landen zijn geweest.quote:Op zaterdag 14 juli 2012 21:05 schreef VacaLoca het volgende:
Lijkt niet uit te maken, wat betreft die missing values...
Nog een vraag over MPR:
Als je bijvoorbeeld de vraag hebt 'In welk(e) land(en) bent u op vakantie geweest in 2011?' en men kan meerdere antwoorden aanvinken.
En frequentietabel van de MPR geeft bijvoorbeeld aan dat 60% van de cases in Spanje is geweest en 40% van de cases in Italië....
.. is het dan vervolgens ook mogelijk om te kijken hoeveel cases er zowel in Spanje als Italië zijn geweest in 2011?
En zoja kan je die dan vervolgens in een variabele stoppen zodat je analyses kan doen over het segment dat in beide landen is geweest?
BVD!
Succes!
De onafhankelijke variabelen in het model heb ik ingedeeld in vier groepen (fysieke, sociale, locatie en prijs variabelen). Om uiteindelijk statistisch het sterkste model te vinden gebruik ik de zgn. 'enter methode' voor het toevoegen van de variabelen (groepen) aan het model. Het komt er op neer dat ik uiteindelijk vier regressie modellen heb. Het eerste model heeft slechts 1 groep onafhankelijke variabelen in het model, terwijl het vierde model alle vier de groepen in het model meeneemt.
Dit vierde model is dan ook het sterkste. Althans dat heeft de hoogste verklarende waarde (R-square).
Dit is ook uit te lezen in de 'model summary' die hier beneden is afgebeeld. Wat ik graag wil weten is wat de individuele verklarende waarde is per groep in het laatste model. Dus wat is de statistisch verklarende waarde van groep 1, 2, 3 en 4 in model 4. Dus welk percentage van 73,8% (R-square) verklaart elke groep individueel. De model summary geeft deze statistiek alleen cumulatief. Is er in SPSS een manier om dit te vinden? Zo ja, hoe?

Als het goed is heb je in de output nog een tabel staan met de regressiecoefficienten (betas en B waarden) per predictor.quote:
Ook ik heb wat SPSS hulp nodig. Voor mijn scriptie onderzoek voer ik regressies uit in SPSS.
De onafhankelijke variabelen in het model heb ik ingedeeld in vier groepen (fysieke, sociale, locatie en prijs variabelen). Om uiteindelijk statistisch het sterkste model te vinden gebruik ik de zgn. 'enter methode' voor het toevoegen van de variabelen (groepen) aan het model. Het komt er op neer dat ik uiteindelijk vier regressie modellen heb. Het eerste model heeft slechts 1 groep onafhankelijke variabelen in het model, terwijl het vierde model alle vier de groepen in het model meeneemt.
Dit vierde model is dan ook het sterkste. Althans dat heeft de hoogste verklarende waarde (R-square).
Dit is ook uit te lezen in de 'model summary' die hier beneden is afgebeeld. Wat ik graag wil weten is wat de individuele verklarende waarde is per groep in het laatste model. Dus wat is de statistisch verklarende waarde van groep 1, 2, 3 en 4 in model 4. Dus welk percentage van 73,8% (R-square) verklaart elke groep individueel. De model summary geeft deze statistiek alleen cumulatief. Is er in SPSS een manier om dit te vinden? Zo ja, hoe?
[ afbeelding ]
Ja dat klopt en zelfs nog een hele hoop andere output. Maar het is mij niet duidelijk hoe ik die kan gebruiken om hetgeen te vinden waarnaar ik op zoek ben. De verklarende waarde per groep variabelen dus. Kan jij me dat uitleggen?quote:
[..]
Als het goed is heb je in de output nog een tabel staan met de regressiecoefficienten (betas en B waarden) per predictor.
Dank
Kun je even de tabel copy pasten van model 4 met de regressiecoefficienten?quote:
[..]
Ja dat klopt en zelfs nog een hele hoop andere output. Maar het is mij niet duidelijk hoe ik die kan gebruiken om hetgeen te vinden waarnaar ik op zoek ben. De verklarende waarde per groep variabelen dus. Kan jij me dat uitleggen?
Dank
Het percentage dat zo'n extra variabele verklaart is het verschil tussen de R2 met en zonder die variabele(volgens mij, of anders dat getal met een verwaarloosbaar verschil).quote:
Ook ik heb wat SPSS hulp nodig. Voor mijn scriptie onderzoek voer ik regressies uit in SPSS.
De onafhankelijke variabelen in het model heb ik ingedeeld in vier groepen (fysieke, sociale, locatie en prijs variabelen). Om uiteindelijk statistisch het sterkste model te vinden gebruik ik de zgn. 'enter methode' voor het toevoegen van de variabelen (groepen) aan het model. Het komt er op neer dat ik uiteindelijk vier regressie modellen heb. Het eerste model heeft slechts 1 groep onafhankelijke variabelen in het model, terwijl het vierde model alle vier de groepen in het model meeneemt.
Dit vierde model is dan ook het sterkste. Althans dat heeft de hoogste verklarende waarde (R-square).
Dit is ook uit te lezen in de 'model summary' die hier beneden is afgebeeld. Wat ik graag wil weten is wat de individuele verklarende waarde is per groep in het laatste model. Dus wat is de statistisch verklarende waarde van groep 1, 2, 3 en 4 in model 4. Dus welk percentage van 73,8% (R-square) verklaart elke groep individueel. De model summary geeft deze statistiek alleen cumulatief. Is er in SPSS een manier om dit te vinden? Zo ja, hoe?
[ afbeelding ]
Het staat trouwens gewoon theoretisch vast dat je met een extra variabele nooit slechter kan verklaren, dus dat zou geen verrassing moeten zijn dat een model met meer variabelen een hogere R2 heeft.
Nee dat i niet helemaal waar. Stel dat je twee variabelen hebt, A en B. A en B correleren met elkaar met .5quote:
[..]
Het percentage dat zo'n extra variabele verklaart is het verschil tussen de R2 met en zonder die variabele(volgens mij, of anders dat getal met een verwaarloosbaar verschil).
Het staat trouwens gewoon theoretisch vast dat je met een extra variabele nooit slechter kan verklaren, dus dat zou geen verrassing moeten zijn dat een model met meer variabelen een hogere R2 heeft.
Als je alleen A in het model toevoegt zal de verklaarde variantie van A overschat worden omdat dat gedeelte dat door B verklaard wordt maar niet in het model meegenomen is, voor die .5 door A vrklaard zal worden.
Dat is dus niet waar, want het is sterk afhankelijk van de volgorde waarin de groepen van variabelen worden toegevoegd. Via die 'enter methode' heb ik dus de beste volgorde gevonden en daarmee het definitieve model. Nu wil ik weten wat de verklarende waarde per groep is in dit definitieve model. Volgens mij is dit dus niet zo simpel als verschillen in R2...quote:
[..]
Het percentage dat zo'n extra variabele verklaart is het verschil tussen de R2 met en zonder die variabele(volgens mij, of anders dat getal met een verwaarloosbaar verschil).
Het staat trouwens gewoon theoretisch vast dat je met een extra variabele nooit slechter kan verklaren, dus dat zou geen verrassing moeten zijn dat een model met meer variabelen een hogere R2 heeft.
Klopt, dus post die tabel eventjes dan kan ik het uitleggen ^^quote:
[..]
Dat is dus niet waar, want het is sterk afhankelijk van de volgorde waarin de groepen van variabelen worden toegevoegd. Via die 'enter methode' heb ik dus de beste volgorde gevonden en daarmee het definitieve model. Nu wil ik weten wat de verklarende waarde per groep is in dit definitieve model. Volgens mij is dit dus niet zo simpel als verschillen in R2...
Feit is wel dat je nooit een hogere R2 kan krijgen met minder (van dezelfde) variabelen.quote:
[..]
Nee dat i niet helemaal waar. Stel dat je twee variabelen hebt, A en B. A en B correleren met elkaar met .5
Als je alleen A in het model toevoegt zal de verklaarde variantie van A overschat worden omdat dat gedeelte dat door B verklaard wordt maar niet in het model meegenomen is, voor die .5 door A vrklaard zal worden.
Alvast bedankt voor je hulp. Hier kan je een excel file downloaden met de volledige output.quote:
[..]
Kun je even de tabel copy pasten van model 4 met de regressiecoefficienten?
Klopt. Daarom heb je helemaal op het einde van de tabel de sig. F change. Die kijkt of de toegenomen verklaarde variantie t.o.v. de toegenomen degrees of freedom wel significant is.quote:
[..]
Feit is wel dat je nooit een hogere R2 kan krijgen met minder (van dezelfde) variabelen.
In de excell file staat alleen dezelfde tabel als die je hier gepost hebt.quote:
[..]
Alvast bedankt voor je hulp. Hier kan je een excel file downloaden met de volledige output.
Edit: ik kan niet lezen
Ik probeer het wel even zonder de tabel.
bij de regression coefficients heb je als het goed is een B (ongestandaardiseerd) en een beta.
De B betekent ongeveer dat elke toename van 1 in die variabele leidt tot een toename van B in je afhankelijke.
Voor de betas zijn alle onafhankelijken gestandaardiseerd, is de variantie van alke onafhankelijke op 1 gezet. Dat betekent dus dat de beta laat zien hoeveel een toename van 1 standaardeviatie uitmaakt voor de afhankelijke. Omdat die allemaal gestandaardiseerd zijn, kun je je onafhankelijken vergelijken op de betas. Heeft bv onafhankelijke a een beta van 2, en onafhankelijke b eentje van 1. Dan is het effect van onafhankelijke 1 twee keer zo groot (per toename van 1 std) als het effect van onafhankelijke b.
Hopelijk is dat een beetje begrijpelijk
Over dat fijne programma gesproken; ik heb in mijn enquete een vraag die met ja / nee beantwoord kan worden en vervolgens ook een veld met toelichting eraan gekoppeld (maar niet verplicht om in te vullen). Hoe verwerk ik dit in mijn variable view? Kom er niet echt aan uit..
Thanks!
Hm, alleen dit zijn Kaplan-meier plots en heb geen zin om alle data en vervolgens de grafieken etc ook weer aan te passen in excel..quote:
Ik maak mijn grafieken altijd in excell omdat je daar veel flexibeler in kunt zijn, geen oplossing voor je probleem maar misschien wle een goede b-optie.
Macro's in word ken ik niet?
1) een Westers land
2) een Opkomende Economie
3) maakt niet uit
Hiervoor heb ik aan de hand van theorie 6 variabelen ontwikkelt en een vragenlijst geconstrueerd, met meerdere items per variabele.
Dit is mijn conceptuele model:

Gezien mijn afhankelijke variabele een categorische(/nominale) is met 3 categorieën, moet ik volgens veel literatuur een Discriminantmieanalyse of een Logistische regressie uitvoeren. Met de uitkomst van deze toetsen krijg ik voornamelijk kansverwachtingen.
Het klinkt voor mij echter intuďtiever om een er een analyse op basis van T-testen op los te laten, zoals een ANOVA. Ik wil uiteindelijk immers de verschillen in gemiddelden weten, om te bepalen of studenten die kiezen voor een Westers land bijvoorbeeld meer aangetrokken worden door een hogere levenskwaliteit, en diegenen die voor opkomende economieën kiezen (bijvoorbeeld) voor de Cultuur.
>>Wat is jullie mening? Heb ik mijn conceptueel model gewoon verkeerd getekend?
Is je DV categorisch? Dus mensen hebben of westers, of opkomend of maakt niet uit, of is het een schaal?quote:
Ik ben bezig met mijn bachelorscriptie, waarin ik onderzoek doe naar de verschillen tussen studenten die een internationale carriere nastreven in
1) een Westers land
2) een Opkomende Economie
3) maakt niet uit
Hiervoor heb ik aan de hand van theorie 6 variabelen ontwikkelt en een vragenlijst geconstrueerd, met meerdere items per variabele.
Dit is mijn conceptuele model:
[ link | afbeelding ]
Gezien mijn afhankelijke variabele een categorische(/nominale) is met 3 categorieën, moet ik volgens veel literatuur een Discriminantmieanalyse of een Logistische regressie uitvoeren. Met de uitkomst van deze toetsen krijg ik voornamelijk kansverwachtingen.
Het klinkt voor mij echter intuďtiever om een er een analyse op basis van T-testen op los te laten, zoals een ANOVA. Ik wil uiteindelijk immers de verschillen in gemiddelden weten, om te bepalen of studenten die kiezen voor een Westers land bijvoorbeeld meer aangetrokken worden door een hogere levenskwaliteit, en diegenen die voor opkomende economieën kiezen (bijvoorbeeld) voor de Cultuur.
>>Wat is jullie mening? Heb ik mijn conceptueel model gewoon verkeerd getekend?
(Als je met DV Dependent Variabele bedoelt): Ik heb dit inderdaad een beetje onduidelijk aangeven.quote:
[..]
Is je DV categorisch? Dus mensen hebben of westers, of opkomend of maakt niet uit, of is het een schaal?
Ik heb een vragenlijst uitgedeeld waarin de respondenten eerst 7 voorkeurslanden mochten aangeven. Daaruit heb ik de drie categorieën gemaakt:
Als er 6 of 7 Westerse landen werden gemarkeerd: Klasse = Westers
Als er 6 of 7 Opkomende landen werden gemarkeerd: Klasse = Opkomend
Als dit niet het geval was: Geen specifieke voorkeur.
Ik zou dit natuurlijk ook als een metrische schaal kunnen zien (Westers met de waarden 1,2,3,4,5,6 of 7)..
Ik heb de oplossing zelf gevonden, dus voor iedereen die hier ook problemen mee heeft:quote:
Iemand enig idee hoe je verschillende grafieken op dezelfde grootte kan maken? Dus als je ze dan in word plakt, ze dan precies op 1 lijn naast elkaar komen staan. Height en width hetzelfde maken werkt op 1 of andere manier niet..
In je graph editor kun je van een bestaande grafiek een template maken (ergens onder file) en deze kun je dan weer toepassen op je andere grafieken
Ik zou gewoon 0-7 doen en anovas / t-toetsen. Zodra je het hercategoriseert verlies je waardevolle informatie (6 is niet hetzelfde als 7 net zomin als 0 hetzelfde als 5 niet-westers) vraag is alleen of je westers v.s. opkomend als 1 categorie met twee uitersten kunt zien of dat je westers en opkomend als twee losse Dependents moet nemen.quote:
[..]
(Als je met DV Dependent Variabele bedoelt): Ik heb dit inderdaad een beetje onduidelijk aangeven.
Ik heb een vragenlijst uitgedeeld waarin de respondenten eerst 7 voorkeurslanden mochten aangeven. Daaruit heb ik de drie categorieën gemaakt:
Als er 6 of 7 Westerse landen werden gemarkeerd: Klasse = Westers
Als er 6 of 7 Opkomende landen werden gemarkeerd: Klasse = Opkomend
Als dit niet het geval was: Geen specifieke voorkeur.
Ik zou dit natuurlijk ook als een metrische schaal kunnen zien (Westers met de waarden 1,2,3,4,5,6 of 7)..
Nice, goed om te weten als ik ooit tegen dit probleem aanloop!quote:
[..]
Ik heb de oplossing zelf gevonden, dus voor iedereen die hier ook problemen mee heeft:
In je graph editor kun je van een bestaande grafiek een template maken (ergens onder file) en deze kun je dan weer toepassen op je andere grafieken.
Ik zit er nog even overna te denken waarom ik destijds in mijn onderzoeksopzet voor de categorieën gekozen heb. Ik denk dat de 0-7 oplossing inderdaad duidelijker is. Ik zit alleen nog met een klein probleem: er zijn meer 'westerse' landen in de landenlijst dan 'opkomende landen'.. De kans dat men voor een westers land kiest is dus groter. Moet en kan ik hiervoor corrigeren?quote:
[..]
Ik zou gewoon 0-7 doen en anovas / t-toetsen. Zodra je het hercategoriseert verlies je waardevolle informatie (6 is niet hetzelfde als 7 net zomin als 0 hetzelfde als 5 niet-westers) vraag is alleen of je westers v.s. opkomend als 1 categorie met twee uitersten kunt zien of dat je westers en opkomend als twee losse Dependents moet nemen.
Zolang je mensen onderling vergelijkt niet, als je absolute claims wilt maken wel, maar dat gaat nogal moeilijk. Zou het alleen noemen in de discussie.quote:
[..]
Ik zit er nog even overna te denken waarom ik destijds in mijn onderzoeksopzet voor de categorieën gekozen heb. Ik denk dat de 0-7 oplossing inderdaad duidelijker is. Ik zit alleen nog met een klein probleem: er zijn meer 'westerse' landen in de landenlijst dan 'opkomende landen'.. De kans dat men voor een westers land kiest is dus groter. Moet en kan ik hiervoor corrigeren?
Sorry dat ik weet terugkom met mijn vraag, maar ik kom er echt niet meer uit
Het komt erop neer dat ik onderzoek:
->Welke factoren van invloed zijn op de keuze tussen een westers of een opkomend land (deze deelvraag is reeds onderzocht in het literaire deel, daaruit heb ik zes variabelen gemaakt en gemeten)
Een volgende deelvraag is:
Wat de verschillen in motieven zijn om in een opkomend- of een westers land te willen werken. Hierbij verwacht ik dus dat op sommige variabelen de westerse groep hoger scoort dan de andere groep (de opkomende landen).
Simpel zou je zeggen: Gooi er in SPSS een ANOVA overheen, de 6 variabelen worden dan ingevuld als dependent, en de landklasse (westers, opkomend, geen voorkeur) als 'factor' waarop wordt gegroepeerd. Ik krijg dan ook netjes de significante verschillen in gemiddelden, hiep hiep hoera!
Maarrr.. Kijkend naar mijn conceptuele model (zie figuur in mijn post hierboven) mag ik toch helemaal geen ANOVA gebruiken? De onafhankelijke variabelen zijn in mijn SPSS invoer ingevoerd als de AFhankelijke? Ik keer als het ware mijn hele conceptuele model om, dat is toch vreemd?
[edit]: verder lees ik dat ANOVA gebruikelijk is in experimenten, terwijl mijn onderzoek natuurlijk de werkelijkheid tracht te omschrijven, zonder als onderzoeker deze te beďnvloeden[/edit]
Mijn data bestaat uit kinderen van 5 - 18 jaar met een ziekte. In de leeftijdsgroep van 8-12 jaar heb ik data van gezonde kinderen. Ik heb daarom deze kinderen in één bestand gezet met mijn zieke kinderen van 8-12 jaar en daarbij heb ik gekeken of er verschillen zijn. Dit ging gewoon prima.
Nu heb ik een artikel gevonden waar ook data in staat van gezonde kinderen, in dezelfde leeftijdsgroep en deze ga ik als (extra) referentie-groep gebruiken.
Ik heb deze gemiddelden nu in een SPSS bestand gezet en daarbij ook mijn eigen gemiddelden. Hier heb ik een t-test op los gelaten (totale groep van 5-18 jaar, gezond/ziek) en daar kwamen de nodige getallen uit. Prima.
Maar... Nu wil ik nog de gemiddelde toetsen van 5-7 jaar en 13-18 jaar met deze referentiegroep. Echter, ik snap niet goed hoe ik dat moet doen
Ik heb daarbij de data (dus alleen de gemiddelden van de vier variabelen van gezonde als zieke kinderen) van 5-7 in een bestand gezet.
Als ik het namelijk doe zoals ik het bij de hele groep heb gedaan (dus 5-18 gezond en 5-18 ziek), dan rekent hij verder niets uit.
Neem dit niet verkeerd op, maar het klinkt alsof je eigenlijk niet zo goed weet wat je aan het doen bent.quote:
(echt bedankt voor je snelle reacties oompaloompa!)
Sorry dat ik weet terugkom met mijn vraag, maar ik kom er echt niet meer uit
Het komt erop neer dat ik onderzoek:
->Welke factoren van invloed zijn op de keuze tussen een westers of een opkomend land (deze deelvraag is reeds onderzocht in het literaire deel, daaruit heb ik zes variabelen gemaakt en gemeten)
Een volgende deelvraag is:
Wat de verschillen in motieven zijn om in een opkomend- of een westers land te willen werken. Hierbij verwacht ik dus dat op sommige variabelen de westerse groep hoger scoort dan de andere groep (de opkomende landen).
Simpel zou je zeggen: Gooi er in SPSS een ANOVA overheen, de 6 variabelen worden dan ingevuld als dependent, en de landklasse (westers, opkomend, geen voorkeur) als 'factor' waarop wordt gegroepeerd. Ik krijg dan ook netjes de significante verschillen in gemiddelden, hiep hiep hoera!
Maarrr.. Kijkend naar mijn conceptuele model (zie figuur in mijn post hierboven) mag ik toch helemaal geen ANOVA gebruiken? De onafhankelijke variabelen zijn in mijn SPSS invoer ingevoerd als de AFhankelijke? Ik keer als het ware mijn hele conceptuele model om, dat is toch vreemd?
[edit]: verder lees ik dat ANOVA gebruikelijk is in experimenten, terwijl mijn onderzoek natuurlijk de werkelijkheid tracht te omschrijven, zonder als onderzoeker deze te beďnvloeden[/edit]
Anovas en regressies zijn techinisch hetzelfde, statistiek is niets anders dan formules dus de analyse die je gebruikt zal niet opeens de werkelijkheid beinvloeden o.i.d.
Als je gemeten motieven continu zijn kun je waarschijnlijk het beste een regressie doen met het aantal landen als adhankelijke (test wel eerst even de assumpties, kijk of er daadwerkelijk een linear verband is etc.)
Als je motiven enkele categorien zijn is het gemakkelijker een anova te doen.
Ik snap totaal niet wat je bedoeltquote:
Oke... Ik voel mijzelf nu echt onwijs stom
Mijn data bestaat uit kinderen van 5 - 18 jaar met een ziekte. In de leeftijdsgroep van 8-12 jaar heb ik data van gezonde kinderen. Ik heb daarom deze kinderen in één bestand gezet met mijn zieke kinderen van 8-12 jaar en daarbij heb ik gekeken of er verschillen zijn. Dit ging gewoon prima.
Nu heb ik een artikel gevonden waar ook data in staat van gezonde kinderen, in dezelfde leeftijdsgroep en deze ga ik als (extra) referentie-groep gebruiken.
Ik heb deze gemiddelden nu in een SPSS bestand gezet en daarbij ook mijn eigen gemiddelden. Hier heb ik een t-test op los gelaten (totale groep van 5-18 jaar, gezond/ziek) en daar kwamen de nodige getallen uit. Prima.
Maar... Nu wil ik nog de gemiddelde toetsen van 5-7 jaar en 13-18 jaar met deze referentiegroep. Echter, ik snap niet goed hoe ik dat moet doen
Ik heb daarbij de data (dus alleen de gemiddelden van de vier variabelen van gezonde als zieke kinderen) van 5-7 in een bestand gezet.
Als ik het namelijk doe zoals ik het bij de hele groep heb gedaan (dus 5-18 gezond en 5-18 ziek), dan rekent hij verder niets uit.
Je hebt alle data toch of alleen gemiddelde en sd?
Kun je even precies zeggen wat je probeert te doen en wat je van spss terug krijgt?
Nee, van de referentiegroep uit het artikel heb ik alleen de gemiddelde (en eventueel ook de SD, maar ik heb nu alleen de gemiddelde in een bestand gezet).
En ik probeerde een t-test te doen. Ik kom er zo even op terug!
Maar hoe doe je een t-test zonder sd?quote:
Uitleg is niet mijn sterkte kant
Nee, van de referentiegroep uit het artikel heb ik alleen de gemiddelde (en eventueel ook de SD, maar ik heb nu alleen de gemiddelde in een bestand gezet).
En ik probeerde een t-test te doen. Ik kom er zo even op terug!
je kunt niet gewoon een 1-sample doen
Weet ik veelquote:
[..]
Maar hoe doe je een t-test zonder sd?
je kunt niet gewoon een 1-sample doen
Dat van die one-sample was ik al achter. Momentje. Ik ga het even openen.
Tuurlijk, ben alleen wel zo weg van internet, dus alvast een tip. Om een t-test te doen heb je een gemiddelde en spreiding nodig. Als je geen raw data hebt, is het waarschijnlijk het gemakkelijkste gewoon een t-test met de hand (excell/rekenmachine) te doen.quote:
Mag ik het anders even "duidelijk" (althans... dat probeer ik) in een mailtje zetten?
Een t-test met de hand?! Oh hemel... Heb ik dat ooit geleerd?
Als je methodenonderwijs een beetje goed is, heb je dat gehad jaquote:
Mailtje is al onderweg, haha. Geen probleem als het niet lukt om er naar te kijken!
Een t-test met de hand?! Oh hemel... Heb ik dat ooit geleerd?
Ja, dat is vast goed geweest, maar ook jij kent mijn SPSS / Statistiek / MTO kunstenquote:
[..]
Als je methodenonderwijs een beetje goed is, heb je dat gehad ja
Ik heb een soort van Counts tabel waarin staat hoe vaak een variabele is gekozen (f) hoe vaak die voorkwam (b) en percentueel (%) tov de andere variabelen. Zo dus:
Sample Size 229 229 100,00
Groep 1:.................................f .......... b.....%
1............................................103... 203....50,74
2 ............................................ 71 203 34,98
3............................................ 29 203 14,29
Groep 2:
1............................................63 170 37,06
2 ............................................48 170 28,24
3 ............................................ 59 170 34,71
Nou is me aangeraden om een chi˛ toets te doen om te kijken of er een significant verschil in aantal keer gekozen zit. Ik dacht dit gedaan te hebben in Excel, door te verwachten dat ze allemaal gelijk werden gekozen (per groep) en dan een chi square per groep. Maar, steeds als ik het in SPSS doe, en nu ik het in een excel macro doe, heb je 2 datasets nodig om de chi˛ te doen.
Hoe moet ik hem dan doen? Oftewel: welke variabelen moet ik invoeren? HELP!
Of ben ik al klaar als ik de variabelen in kolommen zet ipv rijen?
Edit: layout probleempje..
(1) geeft aan of het om groep 1 of 2 gaat
(2) geeft aan of het 1, 2 of 3 betreft
(3) de aantallen, die je vervolgens weegt via data - weigh variables of zo. Ergens onderaan de lijst.
Bij crosstabs geeft je dan de variabele van groep 1 en groep twee als layer op.
Maar, ik heb dat onduidelijk weergegeven, de variabelen in groep 1 en 2 zijn andere variabelen. Het gaat om een conjunct analyse waarbij Groep 1 een type kamer is, waarvan 1 = eenpersoonskamer, 2 = tweepersoonskamer en 3 is 4 of meer persoonskamer. En Groep twee is Uitzicht met 1 landschap, 2 stad, 3 park. Mensen die een eenpersoonskamer kiezne kunnen dus ook kiezen voor een landschap maar daar heb ik geen informatie over. Dan mag ik ze toch niet op die manier vergelijken?quote:
Volgens mij moet je drie variabelen maken.
(1) geeft aan of het om groep 1 of 2 gaat
(2) geeft aan of het 1, 2 of 3 betreft
(3) de aantallen, die je vervolgens weegt via data - weigh variables of zo. Ergens onderaan de lijst.
Bij crosstabs geeft je dan de variabele van groep 1 en groep twee als layer op.
Ik wil juist weten binnen een zo'n groep of daar inderdaad grote verschillen zitten in de frequentie van keuze..
Oke, geeft niets! Ik had er professionele hulp voor ingeschakeld, maar zei had eigenlijk alleen gezegd dat ik een chi˛ kon doen hierop om te kijken of ze verschilden maar nu ben ik zelf enorm gaan twijfelen en is zij op vakantie.. Paniek hier dus!quote:
Ik zou hier dieper op in moeten gaan om hier goed antwoord op te geven en daar heb ik helaas geen tijd voor.. misschien kan je professionele hulp inschakelen of een collega(-student) vragen?
Toch bedankt voor je hulp.
deze vraag is vooral naar Vreemdeeend gericht, maar anderen mogen natuurlijk ook antwoorden.
Ik heb in SPSS (wat anders) een onafhankelijke variabele "jaar". Deze variabele bestaat uit de jaren 1999, 2006 en 2010. Ik gebruik namelijk data van deze drie jaren om mijn onderzoek te verrichten. Ik wil onderzoeken of deze variabele ook een invloed heeft op mijn afhankelijke variabele.
Ik vraag me nu echter af hoe ik deze variabele moet coderen? Gebruik ik hem als continue variabele en steek ik hem "gewoon" in mijn model OF zet ik het over in dummy's waarbij ik een referentiecategorie kies?
Alvast bedankt!
Heb je alleen jaar als onafhankelijke variabele? Dan is het een simpele 1-way-ANOVA en hoef je niets te hercoderen.quote:
Hey allemaal,
deze vraag is vooral naar Vreemdeeend gericht, maar anderen mogen natuurlijk ook antwoorden.
Ik heb in SPSS (wat anders) een onafhankelijke variabele "jaar". Deze variabele bestaat uit de jaren 1999, 2006 en 2010. Ik gebruik namelijk data van deze drie jaren om mijn onderzoek te verrichten. Ik wil onderzoeken of deze variabele ook een invloed heeft op mijn afhankelijke variabele.
Ik vraag me nu echter af hoe ik deze variabele moet coderen? Gebruik ik hem als continue variabele en steek ik hem "gewoon" in mijn model OF zet ik het over in dummy's waarbij ik een referentiecategorie kies?
Alvast bedankt!
Mijn onafhankelijke variabelen zijn: jaar, arbeidsmarktstatus, opleidingsniveau, inkomen en gezondheidstoestand
Mijn afhankelijke variabele zijn consumptie-uitgaven.
Het is dus de bedoeling om een meervoudige lineaire regressie uit te voeren.
Maar het is met de variabele jaar dat ik vastzit. Ik weet niet goed hoe deze in mijn model thuishoort. Maar het is wel belangrijk aangezien het jaar ook een invloed kan hebben op de consumptie-uitgaven.
[ Bericht 24% gewijzigd door Melli7 op 08-08-2012 23:54:51 (verduidelijking) ]
Maar denk dat ik het probleem dan alleen maar verleg....
Zullen het eens met dummy's proberen!
In ieder geval bedankt!
Welk van de twee methoden zou jij toepassen?
(Sorry voor het lastigvallen he)
Ik zou in dit geval voor de optie gaan met de minste variabelen (en dus minder vrijheidsgraden, dus meer accurate voorspellingen, dus eerder significantie). Dus omrekenen naar leeftijd en vervolgens als één variabele toevoegen.
Het valt me trouwens nu wel op dat je maar drie categorieen hebt, dus bovenstaand verhaal van mij weegt niet zo zwaar omdat je met dummies maar 1 extra variabele hebt.... dit brengt me weer aan het twijfelen.... ik zou er toch dummy's van maken vanwege het gebrek aan variantie.
[ Bericht 3% gewijzigd door crossover op 09-08-2012 12:11:04 ]
Klopt, gewoon dummy-variabelen gebruiken in dit gevalquote:
Geeft niet ;-)
Ik zou in dit geval voor de optie gaan met de minste variabelen (en dus minder vrijheidsgraden, dus meer accurate voorspellingen, dus eerder significantie). Dus omrekenen naar leeftijd en vervolgens als één variabele toevoegen.
Het valt me trouwens nu wel op dat je maar drie categorieen hebt, dus bovenstaand verhaal van mij weegt niet zo zwaar omdat je met dummies maar 1 extra variabele hebt.... dit brengt me weer aan het twijfelen.... ik zou er toch dummy's van maken vanwege het gebrek aan variantie.
Bedankt allemaal, kan nu tenminste weer verder met zekerheid!
Ik heb bij meerdere regressie analyses enkele onverklaarbare negatieve Beta waarden. Deze horen overduidelijk niet negatief te zijn.
Wat zou er mis kunnen zijn gegaan?
De data is redelijk normaal verdeeld, dus dat is het probleem niet..
Oja en nog een vraagje over de output, als ik dus een lineaire regressie analsye doe, dan komt er een tabel genaamd coefficients (met oa de beta waarden). (na het anova tabel waarin mijn significante r2change in staan)
Ik doe meerdere stappen (dmv Enter), moet ik dan als ik naar de Beta waarden kijk alleen naar het laatste model kijken? (In die tabel staat er een verdeling van model 1, 2 en 3, waarbij alle variabelen er in de 3e in staan). Ik heb namelijk soms in bijv deel 2 wel significante beta waarden, maar dan in deel 3 zijn ze nonsign geworden.
Ik hoop dat iemand mn vragen begrijpt (en antwoorden weet).
Over je eerste vraag vond ik dit op internet. Vrij duidelijk uitgelegd:quote:
hallo, kan iemand mij met het volgende helpen?
Ik heb bij meerdere regressie analyses enkele onverklaarbare negatieve Beta waarden. Deze horen overduidelijk niet negatief te zijn.
Wat zou er mis kunnen zijn gegaan?
De data is redelijk normaal verdeeld, dus dat is het probleem niet..
Oja en nog een vraagje over de output, als ik dus een lineaire regressie analsye doe, dan komt er een tabel genaamd coefficients (met oa de beta waarden). (na het anova tabel waarin mijn significante r2change in staan)
Ik doe meerdere stappen (dmv Enter), moet ik dan als ik naar de Beta waarden kijk alleen naar het laatste model kijken? (In die tabel staat er een verdeling van model 1, 2 en 3, waarbij alle variabelen er in de 3e in staan). Ik heb namelijk soms in bijv deel 2 wel significante beta waarden, maar dan in deel 3 zijn ze nonsign geworden.
Ik hoop dat iemand mn vragen begrijpt (en antwoorden weet).
Voor die tweede zou ik in mijn statistiek bijbel van Field moeten kijken en die heb ik nu niet bij de hand..SPOILERHi. In a multiple regression, the beta coefficients are technically the same as the partial derivatives with respect to that variable, holding all other independent variables constant. So say I have 3 independent variables, X1, X2, X3.
The beta coefficient B1 of X1 is the expected change in Y(our dependent variable) for each one unit change in X, holding X2 and X3 constant. HOWEVER when your variables are in standardized form, the interpretation is a litte different. With standardized variables, a 1 standard deviation change in X1 equals B1 (the beta 1 coefficient) standard deviations in Y. We standardize our coefficients primarily because it allows us to directly compare the beta coefficients. Normally if we don't standardize the coefficients, each variable must be interpreted on the basis of its own units of measurement. Regardless, standardizing variables will not affect whether or not the coefficients are significant.
A negative beta coefficient means that a 1 unit positive standard deviation change in X is expected to result in a negative beta coefficient change in Y. So if your beta is, say, -3, a 1 unit standard deviation change in X is expected to result in a -3 standard deviation change in Y. It's very similar to the slope (it is the slope of our regression line, keeping all other variables constant).
DO NOT ignore the negative sign! It means your two variables (x,Y) are negatively associated/correlated. However, if you notice that the beta coefficient seems to change sign as you add or subtract other X variables, you may have a problem called multicollinearity, where the X variables are highly correlated with each other. This is especially true if the Betas correlate and the R-Square is high (R-Square tells you how much of the variance in Y the model explains). Normally the beta coefficient should not change sign as you add more independent variables. What is the correlation between X and Y? That is, if you simply doa correlate procedure (which is the same as a simple regression), is the sign still negative? If it is, then that's good, it means the two variables are likely negatively associated.
A negative or positive value on the beta coefficient SAYS NOTHING about significance. The only way to calculate significance is to divide the beta coefficient by its standard error. Usually, the rule of thumb is that any value (t-score) greater than 2 is significant at the usual 95% level of significance.
Heb ook geen idee of je vraag nu is opgelost hoor, maar ik was wel benieuwd wat negatieve Betas betekenden dus had het opgezocht
Ik heb zelf ook field voor mn neus, maar kan het niet vinden.
Ik heb geen multicollinearity volgens mij, zelfs als ik puur alleen 1 trek in de regressie analyse doe, heeft deze een negatieve beta waarde. (al is deze nu niet meer significant....)
Een negatieve beta waarde an sich is geen probleem, als het logisch zou zijn.
Maar bij mij is het soms tegenstrijdig met wereldwijde bekende resultaten, en soms met pure logica.
Dankjewel voor het helpen, ik zoek zelf ook nog verder door uiteraard..
Je tweede vraag ligt aan wat je vraagstelling is.
Als b.v het idee is dat met warmer weer, meer mensen naar het strand gaan, en er dus meer mensen verdrinken,
zou je in model 1 waar je alleen warmte --> verdrinken meet een significante beta verwachten maar nadat je hoeveelheid mensen die naar het strand gaan die beta nonsig moeten worden. Als dat je hypothese is, is die verandering in beta dus verschrikkelijk interessant en moet je dat noemen. Als je een exploratief iets doet waar je gewoon van 10 onafhankeleijke het effect wilt bekijken, neem je alleen je uiteindelijke model.
Verder is het raar dat die betas negatief zijn, aangezien uit de literatuur blijkt dat die positief horen te zijn.
Het is dus zeer tegenstrijdig met alle literatuur die er over dit onderwerp bestaat.
ik denk dat ik dubieuze data heb.
Ik zou even een correlatiematrix maken en die goed bekijken.quote:
dankjewel! ik moet dus idd naar het laatste model kijken.
Verder is het raar dat die betas negatief zijn, aangezien uit de literatuur blijkt dat die positief horen te zijn.
Het is dus zeer tegenstrijdig met alle literatuur die er over dit onderwerp bestaat.
ik denk dat ik dubieuze data heb.
Stel bv. je meet inkomen, IQ en openheid t.o.v. andere culturen.
Conceptueel zouden de eerste en de twee positief moeten correleren, maar de eerste twee negatief met de derde. Zoiets kun je ook doen met jouw variabelen en kun je kijken of de basis-relaties overeenkomen met de literatuur. Als dat allemaal klopt, kun je kijken of je de analyse goed uit hebt gevoerd. Als daar al vreemde patronen in zitten, kun je kijken of je misschien toevallig 1-2 vreemde mensen hebt of dat er een geheel onverklaarbaar patroon in je data zit.
Voor het pre-schooljaar heeft mijn zusje een opdracht met SPSS gekregen. Met mijn vroegere studie Technische bedrijfskunde
Situatie: ze heeft een enquęte m.b.t. stemgedrag afgenomen bij zo'n 30 personen. Deze personen moesten maximaal 2 antwoorden kiezen uit 4 keuzes. Keuzemogelijkheden A-B-C-D.
Kortom: sommige personen hebben alleen A geantwoord, sommige zowel A en B.
In SPSS (data view) zijn de personen in de linker kolom weergegeven. De variabelen staan in de kolom daarnaast en zijn in de variable view omgezet in: A=1, B=2, C=3, D=4.
Vraag: in SPSS (data view) zijn dus twee kolommen aangemaakt, Kolom 1=bedrijven en Kolom 2= variabele (het antwoord). Echter kan er maar één variabele in het invoerveld worden ingevuld. Ofwel 1, 2, 3, 4. Voor deze opdracht moeten er meerdere variabelen ingevuld kunnen worden. Zo komt het er uit te zien:
Kolom 1 - Kolom 2
Anne - 3, 4
Ben - 2
Carla- 1, 2
Het bovenstaande lukt alleen bij 'Ben' (1 invoer), twee getallen pakt hij niet. Is dit simpel op te lossen? Anders ga ik haar adviseren de vragen nog wat anders op te stellen o.i.d.
bedrijf, A, B, C, D
henkiesgehakt, 0, 1, 0, 0
schoonnmaakexpres 0 , 1, 1, 0
de eerste persoon heeft alleen B aangevinkt, de tweede B en C.
Je zou eventueel om meer info vast te leggen er nog voor kunnen kiezen de mensen die slechts 1 kozen een 2 te geven, de mensen die er twee kozen 1 per antwoord.
Voorbeeld:

Je redenatie verwisselt oorzaak en gevolg. Als het alleen maar zou zijn om moeilijker significant te worden, zou je gewoon een correctie kunnen gebruiken.quote:
Wie weet er waarom de DF lager wordt wanneer de assumptie van gelijke varianties (Levene's test) wordt geschonden (dus significant is)? Is dit om te compenseren voor een type 1 fout? Mijn redenatie is dat bij verlaging van de df het effect groter moet zijn om een significant verschil te krijgen. Any thoughts?
Voorbeeld:
[ afbeelding ]
De reden achter de lagere DF is dat de variantie van de twee groepen (en het verband daartussen) op een andere manier geschat moet worden. In plaats van geschatte gedeelde variantie moet je het verband tussen de variantie in groep 1 en 2 bepalen. De volgende formule wordt daarvoor gebruikt: http://en.wikipedia.org/wiki/Welch%E2%80%93Satterthwaite_equation
Hmm niet helemaal.quote:
Dus het komt er op neer dat niet de reguliere df gebruikt kan worden maar omdat er sprake is van ongelijke varianties moet deze op een andere manier geschat worden?
Stel je voor dat je 4 getallen hebt met een gemiddelde van 10. Dan heb je 3 degrees of freedom. De eerste 3 getallen kunnen zijn wat je wilt, het vierde getal moet een bepaald getal zijn om het gemiddelde van 10 te krijgen.
Bij gedeelde variantie, bepaal je maar 1 ding, er blijft dus heel veel "vrijheid" over. Bij die andere variantie, bepaald je het verband tussen de twee varianties, dat is er definitie een minder "vrije" bepaling. Ik weet niet precies hoe de test werkt, maar ga er van uit dat je meerdere zaken bepaalt, b.v. gemiddelde variantie groep 1, gemiddelde 2 en de correlatie ertussen. Dit beperkt de vrijheid van je groep getallen, daarom kom je terecht op minder degrees of freedom.
Het is dus niet zo dat je iets van reguliere df hebt en dat je dat aan kunt passen, de df die je over houdt is eigenlijk de vrijheid van je data nadat je er beperkingen op hebt losgelaten. De t-test heeft maar weinig beperkingen, je "verliest" 1 df per groepsgemiddelde, die andere test heeft meer beperkingen, naast de groepsgemiddelden beperk je je data ook bij de benadering van de variantie.
Hoop dat dit duidelijk is
Schouderklopjes meldtopic.quote:
Als het goed is kun je op de tabel in je output dubbelclicken. Daarin kun je aanassen hoeveel getallen je achter de comma wilt dus ik vermoed dat je daar ook de max charaters voor strings aan kunt passen.quote:
Ik heb een databestand met strings van 1200 characters. Die wil ik graag "listen", maar in de output krijg ik ze maar tot 255 characters. Hij breekt de informatie dus af in de viewer. Hoe stel ik het in dat ik alles te zien krijg?
Het is me niet gelukt. Ik heb het nu met summarize gedaan.quote:
Als het goed is kun je op de tabel in je output dubbelclicken. Daarin kun je aanassen hoeveel getallen je achter de comma wilt dus ik vermoed dat je daar ook de max charaters voor strings aan kunt passen.
Alleen x1 op y1 geeft een significant verband.
Alleen x2 op y1 geeft een significant verband.
Alleen x3 op y1 geeft een significant verband.
Maar:
x1 en x2 en x3 tegelijk in het model gooien geeft voor allen een niet significant verband.
Kan iemand mij de logica hierachter uitleggen?
-edit-
multicollineariteit...
[ Bericht 2% gewijzigd door yozd op 29-08-2012 14:29:06 ]
Ik vind dit toch nog steeds moeilijk te vatten. Ander voorbeeld;quote:
Ik heb een dichotome afhankelijke variabele (y1): "wel" of "niet". Nu heb ik 3 (x1, x2, x3) onafhankelijke variabelen (op interval schaal) waarvan ik wil testen wat de invloed van ze is op die afhankelijke.
Alleen x1 op y1 geeft een significant verband.
Alleen x2 op y1 geeft een significant verband.
Alleen x3 op y1 geeft een significant verband.
Maar:
x1 en x2 en x3 tegelijk in het model gooien geeft voor allen een niet significant verband.
Kan iemand mij de logica hierachter uitleggen?
Stel ik voer 3 OLS regressies uit:
(1) Alleen x1 op y1 geeft:
R^2 = 0,28
het totale model is significant (ANOVA-tabel met die F-waarde).
Een significant verband tussen x1 en y1
(2) Alleen x2 op y1 geeft:
R^2 = 0,17
het totale model is significant (ANOVA-tabel met die F-waarde).
Een significant verband tussen x1 en y1
(3) x1 en x2 op y1 geeft:
R^2 adjusted = 0,36
het totale model is significant (ANOVA-tabel met die F-waarde).
Een significant verband tussen x1 en y1(Coefficients-tabel)
Geen significant verband tussen x2 en y1(Coefficients-tabel)
Het totale model is beter, want R^2 adjusted is hoger dan de R^2 van elk van de andere modellen. Het model is significant, maar 1 variabele niet. Hoe interpreteer ik dit?
Ik heb er totaal geen problemen mee, werkt al jaren als een trein.quote:
Werkt dat een beetje? Hoor van een aantal mensen dat hij vaak vast loopt e.d.
Het enige waar ik aan kan denken is via een heel ingewikkeld proces de 19 rep-meas columns in een column te plakken en dan in een andere column per conditie de iteratie op te schrijven, maar dat moet toch wel makkelijker kunnen?
Met RV.NORMAL kan ik een normaal verdeelde dataset maken. Maar hoe krijg ik dan een minimum van getal 1 en een maximum van 10? En is bij een normaal verdeelde dataset tussen 1 en 10 het gemiddelde 5?
Met RV.UNIFORM kan ik wel een minimum en een maximum aangeven, maar dan wordt de dataset niet normaal verdeeld.
De letterlijke opdracht is: Simuleer eerst een onafhankelijke variabele zodanig dat deze normaal verdeeld is en een score heeft tussen 1 en 10.
met de volgende syntax maak je een databestand aan met 600 cases, die zijn nodig voordat je data kan genereren:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | INPUT PROGRAM. LOOP #i=1 to 600. COMPUTE id=#i. COMPUTE x=RV.NORMAL(0,1). END CASE. END LOOP. END FILE. END INPUT PROGRAM. EXECUTE. |
compute Zxnormaalverdeeld = 5.5 + (2.8*x).
execute.
En dan een beetje zoeken naar een juiste verdeling?
Er is vast een manier om dit exact te berekenen, maar dit is misschien voldoende.
[ Bericht 13% gewijzigd door crossover op 21-10-2012 16:52:43 ]
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | INPUT PROGRAM. LOOP #i=1 to 600. COMPUTE id=#i. COMPUTE x=RV.NORMAL(0,1). END CASE. END LOOP. END FILE. END INPUT PROGRAM. EXECUTE. DESCRIPTIVES VARIABLES=x /SAVE /STATISTICS=MEAN STDDEV MIN MAX. compute Zxnormaalverdeeld = 5.5 + (1.80*Zx). execute. EXAMINE VARIABLES=Zxnormaalverdeeld /PLOT BOXPLOT STEMLEAF NPPLOT /COMPARE GROUPS /STATISTICS DESCRIPTIVES /CINTERVAL 95 /MISSING LISTWISE /NOTOTAL. |

De loggers hebben elke 45 minuten te temperatuur gemeten (Niet allemaal op exact hetzelfde moment maar welk dicht bij elkaar, binnen 15 minuten). Misschien hebben jullie wat handige tips waarmee je leuke grafieken kan krijgen en met welke statistische toets ik de temperaturen kan toetsen.
Dan kan ik toch met een indepentend t-test checken of het aantal uren voorbereiden gemiddeld voor de groepen geslaagd of niet-geslaagd verschilt?
Of moet dat met een andere test? Zijn de groepen niet onafhankelijk?
(1). Inderdaad, een onafhankelijke t-toets met geslaagd/niet geslaagd als als onafhankelijke variabele om te kijken of het gemiddelde aantal uren studeren verschilt voor de twee groepen.
(2). Logistische regressie waarbij je bekijkt wat de kans is op slagen bij een stijging van x uren studeren.
Optie 1 ligt het meest voor de hand, tenzij je bij enkelvoudige regressie kan controleren voor andere relevante variabelen.
Links is hoe mijn docent het heeft gedaan. Recht is hoe ik de Boxplot krijg.SPOILER

Mijn vraag is, hoe krijg ik de boxplot zo omgedraaid, dat de assen hetzelfde staan, als de linker boxplot? Het gaat mij niet om lay out etc, echt puur om het draaien van de assen.
Ik heb mij suf gegoogled, het boek geraadpleegd, nergens tref ik ook maar iets hierover aan. Zelfs op google afbeeldingen, staan alle boxplots zo als de rechter boxplot.
Can someone pls help me out?
quote:
Dubbelklik op de grafiek, Options, Transpose chart.
Kreeg dit zojuist van iemand door.. Tnx.. Begrijp niet dat dit nergens in mijn boek vermeld staat.
Ik ben voor mijn afstuderen bezig met het analyseren van een enquęte.
Daar in staan een aantal stellingen en kan men antwoord geven 'helemaal mee ons eens' tot 'helemaal mee eens'.
In SPSS dit in cijfers 1 t/m 5 gezet. Alleen men had ook de keus 'Weet niet' in te vullen, nummert 6.
Nu wil ik deze stellingen vergelijken en via Comput Variable heb ik al die stellingen bij elkaar op laten tellen. Bij lage cijfers kan ik dan zeggen helemaal mee oneens en bij hoge cijfers zijn de respondenten het er mee eens.
Alleen. nu kom ik tot de conclusie dat nummer 6 overal meegerekend wordt en dus hoge cijfers ook een hoop 'Weet niet' kunnen betekenen. Oeps!
Via Select Case geprobeerd om de '6' weg te laten bij élke stelling zodat er maar van 1 tot 5 geteld wordt. Alleen daar kom ik niet uit.
Ik kan meerder stellingen toevoegen bij Select Cases alleen als iemand dan op stelling één een 'Weetniet' geeft maar verder wel de antwoorden 1 tm 5 geeft wordt die gehele respondent niet mee geteld! En dat is natuurlijk niet de bedoeling.
Heeft iemand enig idee hoe ik dit het beste kan oplossen?
Dank is groooot!
Het zou me heel wat analyses opnieuw doen schelen...
Als een SPSS-bestand (.sav) is aangemaakt en opgeslagen op een Windows PC, is dat bestand dan altijd zonder meer te openen op een Mac?
Want krijg net van een Mac gebruiker te horen dat hij alleen maar een rits met verschillende tekens te zien krijgt als hij het bestand opent, terwijl het er bij mij gewoon goed uit ziet.
Iemand een idee wat hier het probleem kan zijn (conversie-programma nodig ofzo)?
Ik werk met de Mac versie en ik kon zonder problemen bestanden uitwisselen met windowsgebruikers toen dat nodig was. Gebruiken jullie een verschillende versie? (qua nummer dan)quote:
Vraagje over SPSS i.c.m. met Windows en Mac:
Als een SPSS-bestand (.sav) is aangemaakt en opgeslagen op een Windows PC, is dat bestand dan altijd zonder meer te openen op een Mac?
Want krijg net van een Mac gebruiker te horen dat hij alleen maar een rits met verschillende tekens te zien krijgt als hij het bestand opent, terwijl het er bij mij gewoon goed uit ziet.
Iemand een idee wat hier het probleem kan zijn (conversie-programma nodig ofzo)?
Dat kan ik inderdaad nog wel even vragen ja! Maar dat zou toch over het algemeen ook geen probleem moeten zijn, of wel?quote:
[..]
Ik werk met de Mac versie en ik kon zonder problemen bestanden uitwisselen met windowsgebruikers toen dat nodig was. Gebruiken jullie een verschillende versie? (qua nummer dan)
Bovenstaande vraag staat nog steeds... En inmiddels nog een vraag erbij.quote:
Oké, waarschijnlijk kom ik nu echt met de domste vraag ever.... Maar als ik mijn output opsla op een computer, die output vervolgens mail (en opsla op de harde schijf) en probeer te openen op een andere computer, krijg ik die output niet normaal geopend. Alle grafieken opent 'ie netjes, maar alle tabellen blijven tot in den eeuwigheid op "processing" staan. Ergo: ik doe iets verkeerd. Maar wat....? En hoe doe ik het wel goed?
Het zou me heel wat analyses opnieuw doen schelen...
Het gaat om een (hďerarchische) regressieanalyse.
In mijn model summary heb ik twee F-waardes. Nu dacht ik eigenlijk dat die F-waardes (incl. significantie) gelijk moesten zijn aan de F-waardes in de ANOVA-tabel. Dat is dus niet zo. Alleen de F-waarde van model 1 is gelijk, maar de F-waarde van model 2 wijkt af. Wat is die F-waarde van model 2 in de ANOVA-tabel dan? En waarom gebruik ik bij de beschrijving van mijn resultaten wel de vrijheidsgraden uit de ANOVA-tabel?
Het gaat om:
-Omzetten van stellingen in waarden op vier determinanten
-Deze determinanten linken aan gekozen vormen voor samenwerking
-Deze vormen van samenwerking linken aan stellingen die effectiviteit meten
Ik kom er niet meer uit
heb hier een tijdje geleden veel mensen uit dit topic zelf geholpen met SPSS, maar ik heb mijn laatste vak vijf jaar geleden gehad. Ben er helemaal uit en heb geen tijd om het me weer eigen te maken.
Ik ga er vanuit van niet nee. Je mag hem best even naar mij sturen, dan kijk ik even of ik het op mijn mac gewoon kan uitlezen.quote:
[..]
Dat kan ik inderdaad nog wel even vragen ja! Maar dat zou toch over het algemeen ook geen probleem moeten zijn, of wel?
Die tweede vraag heb ik geen antwoord op. Wat betreft de eerste: Heb je op die andere computer wel SPSS geďnstalleerd staan? En als je analyses liever niet opnieuw wil doen (qua knopjes aanklikken) is het misschien handig om voortaan de syntax ook op te slaan. Dan kun je daarna met 1 druk op de knop alle output genereren van de analyses die je op de data hebt losgelaten.quote:
[..]
Bovenstaande vraag staat nog steeds... En inmiddels nog een vraag erbij.
Ja, ik heb op die computer SPSS staan. Die syntax sla ik nu inderdaad op, maar irritant blijft het. Bedankt voor je input in ieder geval!quote:
[..]
Die tweede vraag heb ik geen antwoord op. Wat betreft de eerste: Heb je op die andere computer wel SPSS geďnstalleerd staan? En als je analyses liever niet opnieuw wil doen (qua knopjes aanklikken) is het misschien handig om voortaan de syntax ook op te slaan. Dan kun je daarna met 1 druk op de knop alle output genereren van de analyses die je op de data hebt losgelaten.
Ik zou willen, maar zoals je het hierboven stelt, snap ik er helemaal niets van. Dus ik ben bang dat ik je niet kán helpen.quote:Op woensdag 21 november 2012 18:15 schreef Skv het volgende:
Zijn hier mensen die aardig kunnen SPSSen en willen helpen met analyses?
Het gaat om:
-Omzetten van stellingen in waarden op vier determinanten
-Deze determinanten linken aan gekozen vormen voor samenwerking
-Deze vormen van samenwerking linken aan stellingen die effectiviteit meten
Ik kom er niet meer uit
heb hier een tijdje geleden veel mensen uit dit topic zelf geholpen met SPSS, maar ik heb mijn laatste vak vijf jaar geleden gehad. Ben er helemaal uit en heb geen tijd om het me weer eigen te maken.
Wat bedoel je precies met dat eerste? Omscoren "mee eens" etc naar cijfers?quote:
Zijn hier mensen die aardig kunnen SPSSen en willen helpen met analyses?
Het gaat om:
-Omzetten van stellingen in waarden op vier determinanten
-Deze determinanten linken aan gekozen vormen voor samenwerking
-Deze vormen van samenwerking linken aan stellingen die effectiviteit meten
En "linken" bedoel je daarmee het analyseren van het effect van het ene op het andere?
Normaal gezien zou de outputfile wel gewoon moeten werken, misschien computer opnieuw opstarten of iets dergelijks? (Of een versie probleem ofzo?)quote:
[..]
Ja, ik heb op die computer SPSS staan. Die syntax sla ik nu inderdaad op, maar irritant blijft het. Bedankt voor je input in ieder geval!
[..]
Ik zou willen, maar zoals je het hierboven stelt, snap ik er helemaal niets van. Dus ik ben bang dat ik je niet kán helpen.
Ik zal mijn best doen het even normaal te verwoordenquote:
[..]
Ja, ik heb op die computer SPSS staan. Die syntax sla ik nu inderdaad op, maar irritant blijft het. Bedankt voor je input in ieder geval!
[..]
Ik zou willen, maar zoals je het hierboven stelt, snap ik er helemaal niets van. Dus ik ben bang dat ik je niet kán helpen.
Er zijn genoeg bedrijfjes die je daar bij kunnen helpen. Op marktplaats staan ze bijvoorbeeld.quote:
[..]
Ik zal mijn best doen het even normaal te verwoorden
Je eerste vraag; dat is een bekend probleem. De dataset is dan nodig voor die ander om de output te kunnen zien. Heb het ook heel erg vaak gehad. Een work around is om de output te exporteren naar .doc of .pdf.quote:
[..]
Bovenstaande vraag staat nog steeds... En inmiddels nog een vraag erbij.
Het gaat om een (hďerarchische) regressieanalyse.
In mijn model summary heb ik twee F-waardes. Nu dacht ik eigenlijk dat die F-waardes (incl. significantie) gelijk moesten zijn aan de F-waardes in de ANOVA-tabel. Dat is dus niet zo. Alleen de F-waarde van model 1 is gelijk, maar de F-waarde van model 2 wijkt af. Wat is die F-waarde van model 2 in de ANOVA-tabel dan? En waarom gebruik ik bij de beschrijving van mijn resultaten wel de vrijheidsgraden uit de ANOVA-tabel?
Je tweede vraag. Wat je eigenlijk doet met hierarchische regressie is meerdere modellen toetsen en dan bepalen of deze significant meer variantie verklaren. Hierbij maak je gebruik van een zogenaamde F-toets voor modelvergelijking. In die Model Summary staat de F-change en of die verandering significant afwijkt van nul. Dat kan dus dezelfde waarde zijn voor model 1 in de ANOVA tabel.
Je rapporteert de vrijheidsgraden uit de ANOVA-tabel omdat dat de enige vrijheidsgraden zijn die er bestaan in een regressieanalyse, in die twee tabellen zijn ze ook gelijk namelijk. (Mocht je om de een of andere reden toch verschillende DF hebben gevonden, dan is mijn antwoord dat 'we' nu eenmaal hebben afgesproken om de waarden uit de ANOVA tabel te rapporteren.
[ Bericht 2% gewijzigd door crossover op 22-11-2012 09:41:49 ]
Ik zou dan met veel mensen gaan spreken en daarna op basis daarvan mensen met 1 t/m 10 laten aangeven wat voor hen doorslaggevend was.
Dank je voor je antwoord. Het roept nog meer vragen op, dus die stel ik gewoon. Als je geen zin hebt om antwoord te geven, dan hoeft dat of course niet.quote:
[..]
Er zijn genoeg bedrijfjes die je daar bij kunnen helpen. Op marktplaats staan ze bijvoorbeeld.
[..]
Je eerste vraag; dat is een bekend probleem. De dataset is dan nodig voor die ander om de output te kunnen zien. Heb het ook heel erg vaak gehad. Een work around is om de output te exporteren naar .doc of .pdf.
Je tweede vraag. Wat je eigenlijk doet met hierarchische regressie is meerdere modellen toetsen en dan bepalen of deze significant meer variantie verklaren. Hierbij maak je gebruik van een zogenaamde F-toets voor modelvergelijking. In die Model Summary staat de F-change en of die verandering significant afwijkt van nul. Dat kan dus dezelfde waarde zijn voor model 1 in de ANOVA tabel.
Je rapporteert de vrijheidsgraden uit de ANOVA-tabel omdat dat de enige vrijheidsgraden zijn die er bestaan in een regressieanalyse, in die twee tabellen zijn ze ook gelijk namelijk. (Mocht je om de een of andere reden toch verschillende DF hebben gevonden, dan is mijn antwoord dat 'we' nu eenmaal hebben afgesproken om de waarden uit de ANOVA tabel te rapporteren.)
1. Ik had de data erbij en geopend. Maar wat moet ik met die data doen om de computer te laten weten dat de data geopend zijn?
2. Waar staan precies die F-waarden in de ANOVA-tabel voor? Waarover wordt die ANOVA uitgevoerd? Niet over het model als geheel, dat begrijp ik...
2. dat is een toetsingsmaat, het toetst of er in dat betreffende model variantie in de afhankelijke variabele wordt verklaard door de onafhankelijke variabele(n) met deze formule:

De gegevens uit de ANOVA tabel worden berekend met deze formule. Althans, de F wordt berekend hiermee en afgezet tegen de kritische waarde van F, en dat resulteerd in de sig/p-waarde.
Zoek anders even een boek over regressie, het is niet heel ingewikkeld.
Eén heeft een standaardbegrip gemeten (A, B, of C) is dus nominaal.
Twee is een score op een statement (schaal van 0 tot 10, dat is toch interval?).
Ik wil deze twee samenvoegen tot één nieuwe variabele. Is dit mogelijk?
Wil je ze samenvoegen tot één score? Dus dat je A, B en C omrekent naar een getal en daarna de twee variabelen optelt, of moet er komen te staan "A5", "C9" etcetera? Dat eerste is mogelijk door de letter variabele te recoden en daarna via compute variable op te tellen. Het tweede kan ik je niet bij helpen.quote:
Ik heb een vraag over het samenvoegen van twee variabelen.
Eén heeft een standaardbegrip gemeten (A, B, of C) is dus nominaal.
Twee is een score op een statement (schaal van 0 tot 10, dat is toch interval?).
Ik wil deze twee samenvoegen tot één nieuwe variabele. Is dit mogelijk?
Ik heb inmiddels een overzicht ontvangen van school met de verschillen qua hoofdstukken. Dat ik niet hoofdstuk 10 ga lezen van SPSS18 terwijl ze de theorie van hoofdstuk 9 bedoelen.quote:Op donderdag 3 januari 2013 13:05 schreef Z het volgende:
Ik zou geen nieuw boek kopen. Overlap is vast groot.
Andy Field staat op de aanbevolen literatuurlijst en heb ik inmiddels ook op de ereader staan. De reviews waren iig erg te spreken over dit boek. Zal ook even naar Pallant kijken. Ben een echte complete newbie op dit gebied, maar vind het wel verdomd interessant.quote:
Inderdaad. En daarbij zijn er genoeg boeken online te vinden via de niet gebruikelijke wegen. Ik vind die van Andy Field erg fijn vanwege de heldere uitleg van achterliggende theorie en Pallant als je wat beknopter alle informatie wil.
Mijn hypotheses gaan uit van een combinatie van waarden op TRUS, PARTIC, GOALC en NLVL die leidt tot de keuze voor een netwerkvorm (die dan weer al dan niet effectief kan zijn, gebaseerd op COST, RESOURCE, LEGIT en CLIENT_OUT). Ik zat te denken aan (multiple) regressie-analyse, maar hiervoor is mijn N te klein. Kan iemand me wat tips geven over hoe ik onderstaande hypothesen zou kunnen onderzoeken? Ik zat zelf in ieder geval te denken om COST, RESOURCE, LEGIT en CLIENT_OUT samen te voegen tot 'effectiveness' om het geheel wat makkelijker te maken.
Als het nodig is kan ik m'n hypotheses ook wel even doorgeven.
Zoals je zelf al aangeeft, kan je inderdaad variabelen samenvoegen. Wat je ook kan doen is groepen maken met behulp van een mediaansplit of kwartielen en dan ANOVA inzetten.
Ik wil voor mijn onderzoek de construct validity gaan bepalen, dit wil ik weer gaan doen door de convergent en discriminability validity te gaan bepalen.
Convergent validity kun je bepalen met behulp van de average variance extracted en communlity index.
Discriminant validiteit kun je meten door te kijken of de average variance extracted groter is dan het kwadraat van de construct correlations met de andere factoren.
Maarja, hoe doe je dit nu in SPSS. Ik heb al flink wat gegoogled, maar ik kom gewoon geen mooie SPSS handleiding tegen. Wie o wie weet hier iets meer over
Normaal doe ik dit via Transform -> Compute -> 5MEAN(Var1 TO Var7), maar aangezien het voor een groot aantal likerschalen moet worden gedaan wil ik dit via Syntax laten uitvoeren.
Wat ik in Syntax invoeren?Ik krijg het namelijk niet voor elkaar..
Voor mij gaat dit feest ook beginnen. Dus je bent niet de enige newbie hierquote:
Binnenkort ook werken met SPSS voor school, dus ik meld me alvast al aan
recalculate variables in different variable:
if[variabele] = 1 --> [nieuwevariabele] = 1
if [variabele] =/= 1 --> [nieuwevariabele] = 0
Volgens mij houdt SPSS geen rekening met Stapel-methodesquote:
Als je in SPSS compute variable doet en bijvoorbeeld een variable maakt die een gemiddelde berekent dan lijkt dit niet interactief te zijn. Dat wil zeggen dat als ik een van de items wijzig waarvan die het gemiddelde berekent dan wijzigt die de score niet interactief mee (zoals in excel), kan dit wel?
Ik denk dat je opnieuw compute moet doen, maar als je de syntax bewaart is dat twee seconden werk.
Goed idee, ik bewaar de syntax gewoon voor als ik nog eventueel wijzigingen heb in de data.quote:
[..]
Volgens mij houdt SPSS geen rekening met Stapel-methodes
Ik denk dat je opnieuw compute moet doen, maar als je de syntax bewaart is dat twee seconden werk.
Edit: al gevonden, voor geďnteresseerden http://www.ats.ucla.edu/stat/spss/icu/custom_win.htm
Als je een kwantitatieve scriptie schrijft dan zul je SPSS gebruiken, bij een kwalitatieve scriptie niet.quote:
Ik vraag me af of mensen die hun bachelorscriptie schrijven, spss ook heel erg nodig hebben? Ik moet volgend jaar ook mijn scriptie schrijven maar ben bang dat ik het dan allemaal al weer vergeten ben...het boek van Andy Field helpt trouwens wel goed, daar staat meestal wel uitgelegd hoe alles moet enzo.
@Mainport, ik zou hem opnieuw installeren.
Ik zit een beetje tegen de interpretatie van de standard error of mean te hikken. Verschillende bronnen leren mij wat het in theorie is en hoe ik deze kan berekenen, maar niemand die geeft mij aan hoe ik de uitkomst moet lezen. Nu heb ik een mean van 1,8157 en 1,8846 met een standaard deviatie van respectievelijk ,40326 en ,50993 en een standard error mean van respectievelijk ,07129 en ,06230.
Wat zeggen die ,07129 en ,06230 mij over de betrouwbaarheid van de sample ten opzichte van de gehele populatie?
Je standaarderror is de stanaarddeviatie van je means.quote:
Even een typische zaterdagavond vraagHet is gelukkig een newbie vraag.
Ik zit een beetje tegen de interpretatie van de standard error of mean te hikken. Verschillende bronnen leren mij wat het in theorie is en hoe ik deze kan berekenen, maar niemand die geeft mij aan hoe ik de uitkomst moet lezen. Nu heb ik een mean van 1,8157 en 1,8846 met een standaard deviatie van respectievelijk ,40326 en ,50993 en een standard error mean van respectievelijk ,07129 en ,06230.
Wat zeggen die ,07129 en ,06230 mij over de betrouwbaarheid van de sample ten opzichte van de gehele populatie?
In het kort komt het er op neer dat e verwacht dat 95% van de samples die je trekt binnen 2 standaarderrors van de mean af liggen. Hoe kleiner je standaarderror dus is, hoe dichter jouw gevonden mean bij de populatiemean zal liggen over het algemeen.
Ok, dan snap ik hem. Bedanktquote:
[..]
Je standaarderror is de stanaarddeviatie van je means.
In het kort komt het er op neer dat e verwacht dat 95% van de samples die je trekt binnen 2 standaarderrors van de mean af liggen. Hoe kleiner je standaarderror dus is, hoe dichter jouw gevonden mean bij de populatiemean zal liggen over het algemeen.
Dan heb ik nog een vraag. Ik ben nu een correlatiematrix aan het lezen van de independent samples tests en daarin zijn zowel de natuurlijke logaritme als de 'gewone' variabele in opgenomen. Nu staat mij iets bij over dat je de natuurlijke logaritme niet bij alle vergelijkingen kunt gebruiken, omdat deze aangepast is om een normale verdeling te krijgen. Geldt dat ook voor de correlation matrix van de independent samples tests?
Sorry, nogal late reactie.quote:
[..]
Ok, dan snap ik hem. Bedankt
Dan heb ik nog een vraag. Ik ben nu een correlatiematrix aan het lezen van de independent samples tests en daarin zijn zowel de natuurlijke logaritme als de 'gewone' variabele in opgenomen. Nu staat mij iets bij over dat je de natuurlijke logaritme niet bij alle vergelijkingen kunt gebruiken, omdat deze aangepast is om een normale verdeling te krijgen. Geldt dat ook voor de correlation matrix van de independent samples tests?
Ja als je een logaritmische schaal gebruikt geldt ook voor correlaties dat je daar rekening mee moet houden bij de interpretatie.
Dat kun je snel bekijken door met een voorbeeld te werken. Bv:
1 10
2 100
3 1000
4 10000
met log10 transformatie:
1 1
2 2
3 3
4 4
5 5
De correlatie zal in het tweede geval hoger uitkomen dan in het eerste
Ik heb schalen de gemiddelden van de independant variables (X+Y) en de dependant variable (Z), verder heb ik nog controle variabelen in de vorm van gemiddelden en dummy variabelen.
Als ik alle dummy's en onafhankelijke variabelen toevoeg aan "independant variables" bij de lineaire regressie dan krijgen sommige een enorm hoge .Sig (0.9), onder andere 1 van mijn 2 independant variable schalen. Als ik deze schaal in zijn eentje afzet tegen de dependant variable dan is de Sig. wel heel laag, hoe kan dat?
Dan correleren je IV's hoog.quote:
Vraagje, ik heb SPSS data en wil een multi-lineaire regressie doen.
Ik heb schalen de gemiddelden van de independant variables (X+Y) en de dependant variable (Z), verder heb ik nog controle variabelen in de vorm van gemiddelden en dummy variabelen.
Als ik alle dummy's en onafhankelijke variabelen toevoeg aan "independant variables" bij de lineaire regressie dan krijgen sommige een enorm hoge .Sig (0.9), onder andere 1 van mijn 2 independant variable schalen. Als ik deze schaal in zijn eentje afzet tegen de dependant variable dan is de Sig. wel heel laag, hoe kan dat?
Stel bv je hebt een groep kinderen van 1-5 jaar.
Je hebt ook hun lengte.
Met leeftijd en lengte probeer je hun gewicht te voorspellen.
Lengte alleen zal heel erg sig zijn.
Leeftijd alleen zal heel erg sig zijn.
Maar omdat leeftijd en lengte zo samenhangen, zal wanneer je ze allebei toevoegt het effect enorm afnemen.
wat je moet doen ligt aan de opdracht en aan wat je iv's zijn. In mijn voorbeeld zou het heel erg logisch zijn om te zeggen dat leeftijd lengte voorspelt, maar dat dat komt omdat leeftijd lengste voorspelt wat vervolgens weer gewicht voorspelt. Andersom zou gewoon logisch onmogelijk zijn. Als het om twee persoonlijkheids-schalen gaat, ligt ht al weer wat moeilijker.quote:
Maar de andere IV heeft wel een lage Sig. value. Wat is dan het beste te doen, als ik ze beide in het model plaats kan ik de een natuurlijk niet gebruiken omdat de Sig. te hoog is.
Als je hier advies over wilt, zul je dus het hele verhaal eventjes uit moeten typen
sowieso zal de interpretatie moeilijk zijn (als ze correleren, check dat even, misschien is er iets anders aan de hand).
Bij mijn volgende vraag aangekomen. Ik heb een aantal controle variabelen (geen constanten, maar covariables waar ik voor wil controleren zoals geslacht, werkervaring, afdeling), sommigen gewoon ordinaal, sommige in de vorm van dummy variabelen.
Hoe kan ik zien dat het toevoegen van de controle variabelen het gewenste effect heeft? Ik zie bijvoorbeeld dat de R square toeneemt dus dat lijkt me wenselijk, waar moet ik nog meer op letten?
[ Bericht 4% gewijzigd door GoobyPls op 09-03-2013 11:27:22 ]
De R2 is inderdaad een goede indicatie. Verder even kijken of de controle variabelen ook daadwerkelijk de juiste (verwachtte) richting op gaan.quote:
Thanks Oompaloompa.
Bij mijn volgende vraag aangekomen. Ik heb een aantal controle variabelen (geen constanten, maar covariables waar ik voor wil controleren zoals geslacht, werkervaring, afdeling), sommigen gewoon ordinaal, sommige in de vorm van dummy variabelen.
Hoe kan ik zien dat het toevoegen van de controle variabelen het gewenste effect heeft? Ik zie bijvoorbeeld dat de R square toeneemt dus dat lijkt me wenselijk, waar moet ik nog meer op letten?
verder geldt voor controle variabelen hetzelfde als het stuk dat ik eerder heb getypt. Als je controle variabelen samenhangen met je IV's, wordt het weer moeilijker om te interpreteren omdat je niet wilt over- of onder- controleren.
Zou een beetje een karige uitkomst zijn van mijn scriptie.
\Ben bang dat dat ongeveer klopt.quote:
Wat kan ik zeggen als mijn verklaarde variantie (r-square) van mijn twee onafhankelijke variabelen en de afhankelijke respectievelijk 0,01 (Sig. 0,6) en 0,022 (Sig 0,437) zijn? Er is positieve relatie, maar niet significant? En betekent dit dan dat er eigenlijk geen donder bewezen is?
Zou een beetje een karige uitkomst zijn van mijn scriptie.
Je gegevens betekenen dat er een verband is in je steekproef, maar dat dat verband niet sterk genoeg is om uit te sluiten dat het puur door kans op treedt, je kunt het dus niet generaliseren naar de populatie.
Trouwens de r-square zegt niets over de richting van het verband, om te weten of het een positief of negatief verband is, moet je naar de B kijken.
Yeap inderdaad.quote:
B is toch de coëfficient van de lijn? Die heb ik weergegeven in mijn scatterplot en geeft een flauwe positieve relatie aan. Probleem is waarschijnlijk dat mijn N (30) gewoon te laag is, dus dat kan ik er bij aangeven.
N=30 is inderdaad heel erg laag, kijk voor de gein maar eens op pagina 13-16 hiervan: http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2205186
Je zou het bayeseaans kunnen analyseren, maar vermoed dat je daar niet veel verder mee komt.quote:
I know, maar het totale veld waar ik uitspraken over wil doen bestaat uit 400 organisaties. Hiervan heb ik er 200 aangeschreven, waarvan ik 30 respons van heb gekregen. Iedereen heeft wel wat beters te doenHad het iets te optimistisch ingeschat. Wel een paar interviews aanvullend.
Dat helptquote:
[..]
Sorry, nogal late reactie.
Ja als je een logaritmische schaal gebruikt geldt ook voor correlaties dat je daar rekening mee moet houden bij de interpretatie.
Dat kun je snel bekijken door met een voorbeeld te werken. Bv:
1 10
2 100
3 1000
4 10000
met log10 transformatie:
1 1
2 2
3 3
4 4
5 5
De correlatie zal in het tweede geval hoger uitkomen dan in het eerste
Thanks, wat weet jij veel van statistiek. ^^quote:
[..]
\Ben bang dat dat ongeveer klopt.
Je gegevens betekenen dat er een verband is in je steekproef, maar dat dat verband niet sterk genoeg is om uit te sluiten dat het puur door kans op treedt, je kunt het dus niet generaliseren naar de populatie.
Trouwens de r-square zegt niets over de richting van het verband, om te weten of het een positief of negatief verband is, moet je naar de B kijken.
Ik zit nu in mijn lineaire regressie te kijken en krijg 2x Sig. waardes. In de eerste plaats in de correlations tabel waar een rij Sig. (1 tailed) staat, en in de tweede plaats in de coefficients tabel waar een kolom Sig. staat. Deze waardes komen voor dezelfde relaties echter niet overeen (de Sig. 1 tailed zijn veel lager), welke moet ik gebruiken en wat is het verschil?
In de correlations tabel staan simpelweg de correlaties tussen al je variabelen. Deze worden vaak gerapporteerd. In de coefficients tabel staan de beta-waardes en de daarbij horende sig-waardes. Die heb je dus nodig voor het interpreteren van de regressieanalyse.
Onder het kopje 'Extraction' kun je bij 'Extract' een vast aantal factoren opgeven.quote:
Ik moet een factor analyse doen met varimax rotatie op een schaal waarin 4 subschalen zitten. Nou komen er meer componenten dan dat uit en kun je als goed is in SPSS een varimax draaien waarin je een X aantal componenten wenst te krijgen (in dit geval 4), hoe doe ik dat?
Bedankt!quote:
[..]
Onder het kopje 'Extraction' kun je bij 'Extract' een vast aantal factoren opgeven.
Het is dus de bedoeling om de variabele van iedere case op te tellen voor zolang ID = lag(ID)
Iemand?
Bij een N van minder dan 30 moet je volgens mij ook de t-toets doen ipv de f-toets.quote:
B is toch de coëfficient van de lijn? Die heb ik weergegeven in mijn scatterplot en geeft een flauwe positieve relatie aan. Probleem is waarschijnlijk dat mijn N (30) gewoon te laag is, dus dat kan ik er bij aangeven.
Ik denk dat de date and time series er niets mee te maken hebben.quote:
Gebruik je 'Transform' --> 'Date and Time Wizard'? Als je de syntax paste kan je er vast wat filters omheen zetten.
1 0.33 01.02.2007 0.33
1 0.50 20.03.2007 0.83
1 1.00 01.05.2008 1.00
1 1.00 15.05.2008 2.00
1 0.22 01.02.2008 2.22
1 0.22 20.03.2008 2.44
1 1.00 01.05.2008 3.44
1 1.00 15.05.2008 4.44
3 0.10 01.02.2006 0.10
3 0.33 20.03.2006 0.43
3 1.00 01.05.2006 1.43
3 0.98 15.05.2008 0.98
4 0.98 01.02.2008 0.98
4 0.77 02.03.2008 1.75
4 1.00 01.05.2010 1.00
Ik wil kolom 2 optellen zolang de ID van de vorige kolom hetzelfde is, en deze waarde printen in een nieuwe variabele (Kolom 4). De datum (kolom 3) is voor mij niet relevant omdat deze in mijn dataset al in de ID-variabele zit.
/OUTFILE=* MODE=ADDVARIABLES
/BREAK=VAR1
/VAR00002_sum=SUM(VAR2).
Zoiets.
Super thx! 't is geluktquote:
AGGREGATE
/OUTFILE=* MODE=ADDVARIABLES
/BREAK=VAR1
/VAR00002_sum=SUM(VAR2).
Zoiets.
Ik heb enquętes ingevuld in SPSS. Ik heb een vraag over een vraag in mijn enquęte.
De vraag is:
Wat vind je van de middelen die het bedrijf inzet?
De antwoordmogelijkheden zijn: slecht, neutraal, goed en niet mee bekend.
Dat geven ze dan aan voor: open dag, meeloopdagen, voorlichtingen, website enz.
Nu wil ik eigenlijk in een geclusterd staafdiagram de resultaten weergeven.
Dus op de X-as wil ik dan 'open dag', 'meeloopdagen', 'voorlichtingen' enzovoorts.
En ik hoopte dan een geclusterd staafdiagram te krijgen waarin je per middel kon zien hoeveel respondenten 'slecht, neutraal, goed en niet mee bekend' hadden ingevuld.
Maar als ik alle middelen toevoeg aan het geclusterd staafdiagram, dan kan ik niet op OK drukken.
Kan iemand mij hier mee helpen? Of kan het gewoon niet wat ik wil?
Maar ik moet zeggen dat ik daar niet heel erg in thuis ben. Ik moet ook altijd heel vaak dingen uitproberen met die grafieken.
Kan ik in mijn thesis beschreven dat ik gebruik heb gemaakt van 'fixed number of factors', of moet het echt op eigenvalues gebaseerd zijn?
Fixed number of factors mag dus nietquote:
Het aantal factoren moet je baseren op een aantal criteria, bijvoorbeeld Catell's scree plot, Eigenvalues > 1 of een totaal aantal % verklaarde variantie. Dan heb je ook nog parallel analyse maar dat wordt niet zo veel gebruikt en is ook lastiger.
Jawel, maar dan moet je dus op basis van die criteria bepalen hoeveel je er dan precies neemt.quote:
[..]
Fixed number of factors mag dus niet
Dat is niet lastig voor mij omdat ik gewoon 6 constructs heb, en voor iedere construct heb ik een stel vragen. Dus als ik een fixed number of factors gebruik, pak ik gewoon 6, omdat ik 6 constructs heb. Maar dat mag dus ook gewoonquote:
Vaak draait men in SPSS twee analyses bij EFA. De eerste om te kijken hoeveel factoren het meest waarschijnlijk 'onder' de variabelen liggen, dat doe je dus met de optie 'Eigenvalues greater than 1'. Vervolgens pas je die criteria toe en draai je de analyse nogmaals met het door jou opgegeven aantal factoren. Dat wordt dan de uiteindelijke output (omdat de pattern en structure matrix dat betreffende aantal factoren weergeeft en dan is niet per se het juiste aantal factoren bij de optie 'Eigenvalues greater than 1').
Heb ook nog een andere vraagje, is het altijd nodig om een EFA of een PCA voor een confirmatory factor analysis uit te voeren? Want ik zie dat in veel onderzoeken meteen naar de confirmatory factor analysis wordt gegaan. EFA of een PCA wordt dus geskipt.
[ Bericht 38% gewijzigd door Soldier2000 op 12-04-2013 14:46:43 ]
Het is niet noodzakelijk om het beide te doen. Kan wel, dat wordt kruisvalidatie (cross-validation) genoemd.
COMPUTE varnew=LN(var) doe dat heeft de nieuwe variabele alleen stippeltjes als output. Als ik het via Transform --> compute variable probeer dan is Functions and Special Variables leeg, en dus geen LN te selecteren, what to do?
Thanks. Ik heb ze net in excel gezet waar het uiteraard een eitje is. Bepaalde waarden zijn >1 (bijvoorbeeld 0.5), hierbij krijg ik dus negatieve LN waardes. Is dit een probleem?quote:
Het in Excel doen? Wellicht heeft jouw versie van SPSS deze functionaliteit niet.
Het doel van de LN functie is voor leeftijd en expertise een normalere verdeling te krijgen voor regressie analyse.
1Beide variabelen worden na LN normaler verdeeld dan voorheen. Maar wat schiet ik hiermee op? Wat is het probleem voor je regressie analyse als zo'n variabele niet normaal verdeeld is? Alleen dat P waarde gebaseerd is op een normale verdeling?
2Verder, welke onafhankelijke variabelen controleer je op normale verdeling? Schalen gebaseerd op een likert schaal niet lijkt me? Ik heb ook een schaal die een soort persoonlijkheid meet door bepaalde eigenschappen aan te vinken, hier krijg ieder dus een discrete score voor deze soort persoonlijkheid. Dienst deze ook normaal verdeeld te zijn?
3 Weet iemand hoe het kan dat als ik een variable die eerst een niet normale verdeling heeft transformeer naar een normale verdeling, dat mij regressie model dan een lagere R2 krijgt dan voorheen?
[ Bericht 19% gewijzigd door GoobyPls op 17-04-2013 18:35:52 ]
(ik heb de naam van de variabelen onduidelijk gemaakt, resultaten van het onderzoek moeten nog even anoniem blijven
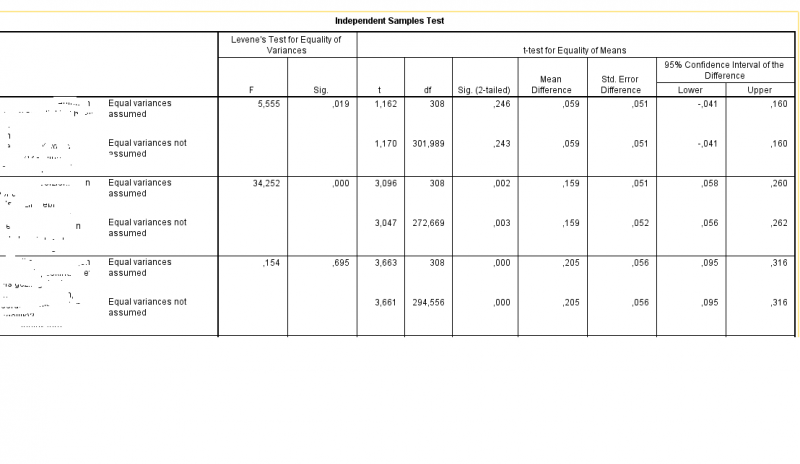
Ik heb hier dus drie toetsen uitgevoerd.
Bij de eerste is de p waarde in het tweede blok 0.019 en dus significant, maar in het vierde blok (sig 2 tailed) staat 0.246 en 0.243. Bij welke moet ik nu precies kijken?
Hetzelfde geldt voor de andere toetsen, maar lijkt me dat dit overal hetzelfde wordt toegepast
links is de significantie van levenes test, en rechts die van de t-testquote:
even een vraagje over significantie. Ik heb een t toets uitgevoerd en krijg de volgende resultaten:
(ik heb de naam van de variabelen onduidelijk gemaakt, resultaten van het onderzoek moeten nog even anoniem blijven)
[ afbeelding ]
Ik heb hier dus drie toetsen uitgevoerd.
Bij de eerste is de p waarde in het tweede blok 0.019 en dus significant, maar in het vierde blok (sig 2 tailed) staat 0.246 en 0.243. Bij welke moet ik nu precies kijken?
Hetzelfde geldt voor de andere toetsen, maar lijkt me dat dit overal hetzelfde wordt toegepast
Okee, die linkse dan niet dus, dankje!. Maar hoe kom ik er dan achter of de varianties gelijk zijn of niet?quote:Op donderdag 25 april 2013 18:05 schreef Silverdigger2 het volgende:
[..]
links is de significantie van levenes test, en rechts die van de t-test
Zo frustrerend dit, heb dit nog niet zo lang geleden gehad, maar het is allemaal zo snel weer weggezakt en ik weet niet goed waar ik dit kan vinden
en dan de independent sample t-test
succes
Die is helder, thanks!quote:Op vrijdag 26 april 2013 10:35 schreef Silverdigger2 het volgende:
http://academic.udayton.edu/gregelvers/psy216/spss/ttests.htm
en dan de independent sample t-test
succes
ik heb een schaal van 0-100 die ik wil omschalen naar afwijkingen van 50.
dus dan wordt 50 -> 0, en 49->1, 51->1, enz. Nu heb ik dit tot nu toe met de hand gedaan, en kan niet echt een syntax voor dit omcoderen vinden via google
moet dit met de hand
Zoiets:quote:
weet iemand toevallig hoe je een variabele hercodeert in gemakkelijke syntax?
ik heb een schaal van 0-100 die ik wil omschalen naar afwijkingen van 50.
dus dan wordt 50 -> 0, en 49->1, 51->1, enz. Nu heb ik dit tot nu toe met de hand gedaan, en kan niet echt een syntax voor dit omcoderen vinden via google
moet dit met de hand
COMPUTE Nieuw=ABS(Oud-50).
EXECUTE.
Waarbij Oud de naam van de ongecodeerde variabele is en Nieuw de hercodeerde variabele.
exe.
val lab vary
1 '0-50'
2 '51-100'
.
quote:
[..]
Zoiets:
COMPUTE Nieuw=ABS(Oud-50).
EXECUTE.
Waarbij Oud de naam van de ongecodeerde variabele is en Nieuw de hercodeerde variabele.
hmm misschien niet zo duidelijk opgeschreven maar bedoel echt dat zeg maar dat het midden de nieuwe 0 waarden zijn, en dan de rest van de waarden gerekent vanaf 50 een nieuwe absolute schaal zijn.quote:
recode varx (0 thru 50 = 1) (51 thru 100 = 2) into vary.
exe.
val lab vary
1 '0-50'
2 '51-100'
.
50=0, 51=1, 52=2,53=3
en 49=1, 48=2, 47=3.
ben bang dat het typen wordt
edit: gelukt
[ Bericht 4% gewijzigd door Silverdigger2 op 13-05-2013 11:38:03 ]
ben niet zon held met syntax, en bedacht me dat het uitzoeken langer duurde dan het uittypen, maar kan je het zo snel coderen ( 0 thru 50 = 50 thru 0) (51 thru 100 = 1 thru 50) ?quote:
Dat kan je toch gewoon doen door mijn syntax wat aan te passen.
Vraag:
Op welke manier kunnen externen (klanten, leveranciers) contact opnemen met het bedrijf waar u werkzaam bent (meerdere antwoorden mogelijk)?
Variable view: Value, Label:
1 = "Direct mail"
2 = "Website"
3 = "Telefonisch"
4 = "Social-media (Twitter, Google+, Facebook, LinkedIn etc.)"
5 = "E-mail"
6 = "Free publicity"
En bij Dataview heb ik dus meerdere antwoorden: 1, 2, 3, 4, 5, ingevoerd maar dit wilt niet werken. Verder zou ik niet met meerdere Variabelen willen werken omdat ik veel meerkeuzevragen met meerdere antwoorden heb.
Is het mogelijk om dit te analyseren?
Ik ben bezig met SPSS voor mijn scriptie en heb allemaal categoriserende, discrete variabelen waarbij er op een likert schaal van 1-7 antwoord is gegeven. Vraag is nu welk type regressie ik dien te gebruiken.
Als ik regressie goed begrijp heb je voor lineare regressie een afhankelijke variabele nodig die een continue schaal (bv. leeftijd) heeft. Aangezien mijn afhankelijke variable ordinaal is dien ik volgens mij dus ordinale regressie te gebruiken. Is het hierbij een probleem dat ook mijn onafhankelijke variabelen ordinale variabelen zijn? 4
Verder: hoe kan ik gebruik maken van lineare regressie met deze data, kan dit simpelweg gedaan worden door de 'measure' kolom in het variablen overzicht aan te passen van ordinaal naar schaal om dit te bereiken? Dit zodat mijn discrete variabele in een continue variabele veranderd
Alvast bedankt voor enig antwoord!
Maak je gebruik van een Model?quote:
Beste forummer,
Ik ben bezig met SPSS voor mijn scriptie en heb allemaal categoriserende, discrete variabelen waarbij er op een likert schaal van 1-7 antwoord is gegeven. Vraag is nu welk type regressie ik dien te gebruiken.
Als ik regressie goed begrijp heb je voor lineare regressie een afhankelijke variabele nodig die een continue schaal (bv. leeftijd) heeft. Aangezien mijn afhankelijke variable ordinaal is dien ik volgens mij dus ordinale regressie te gebruiken. Is het hierbij een probleem dat ook mijn onafhankelijke variabelen ordinale variabelen zijn? 4
Verder: hoe kan ik gebruik maken van lineare regressie met deze data, kan dit simpelweg gedaan worden door de 'measure' kolom in het variablen overzicht aan te passen van ordinaal naar schaal om dit te bereiken? Dit zodat mijn discrete variabele in een continue variabele veranderd
Alvast bedankt voor enig antwoord!
Ik bekijk de invloed van een aantal variabelen op een set andere variabelen. Ik doe dit voor elke afhankelijke variabele opnieuw gezien je maar 1 afhankelijke variabele per keer kan invoeren.
En waarom maak je dan gebruik van SPSS, en niet van Amos of een PLS applicatiequote:
Als je een conceptueel model bedoeld, ja.
Ik bekijk de invloed van een aantal variabelen op een set andere variabelen. Ik doe dit voor elke afhankelijke variabele opnieuw gezien je maar 1 afhankelijke variabele per keer kan invoeren.
Kan je verder bevestigen of ik het bij het juiste eind heb met mijn veronderstellingen? Ik heb ervaring met voornamelijk lineare regressie via SPSS door effecten te toetsen of afhankelijke, continue variabelen. Dat gaat bij mijn huidige dataset echter helaas niet op.
Ga dan toch maar eens kijken naar Amos of bijv. SmartPLS. Ik heb namelijk het idee dat je steeds 1 relatie wilt gaan testen, terwijl je model uit meerdere relaties bestaat. En dan moet je geen SPSS gebruiken, omdat je dan geen rekening houdt met de effecten van andere relaties op die ene relatie die je aan het testen bent.quote:
Ik gebruik SPSS omdat ik hier kennis en ervaring mee heb en dit programma op mijn computer staat. Voor zowel lineare regressie alswel factor analyse. Geen idee wat Amos of een PLS applicatie zijn.
Kan je verder bevestigen of ik het bij het juiste eind heb met mijn veronderstellingen? Ik heb ervaring met voornamelijk lineare regressie via SPSS door effecten te toetsen of afhankelijke, continue variabelen. Dat gaat bij mijn huidige dataset echter helaas niet op.
Ook is via een scatterplot te zien dat er meestal geen lijn in te trekken is in de relatie tussen 2 variabelen en dat het lijkt alsof alle waarden gewoon willekeurig van elkaar zijn.
Laat ik het anders stellen, als jij een valide onderzoek wilt uitvoeren dan moet je je model in 1x testen, dus niet iedere relatie individueel. Daarnaast is de VIF een indicatie, en daar houdt het bij op, er kan nog steeds sprake zijn van enige correlatie tussen variabelen. Daarnaast moet je ook mediation uittestenquote:
Ik test meerdere variabelen op één afhankelijke variabele tegelijk en VIF (variance of inflation of iets dergelijks) geeft aan dat er geen colineariteit is dus dat is het probleem niet. Probleem is dat ik een effecten meet van een ordinale schaal op een ordinale schaal maar heb geen idee hoe dit anders zou kunnen.
Ook is via een scatterplot te zien dat er meestal geen lijn in te trekken is in de relatie tussen 2 variabelen en dat het lijkt alsof alle waarden gewoon willekeurig van elkaar zijn.
In jouw geval zou ik gewoon beginnen met een exploratory factor analysis, en daarna een confirmatory factor analysis uitvoeren. En check voor de gein gewoon eens SmartPLS, er gaat echt een wereld voor je open, trust me
En dat betekent niet dat je SPSS niet meer kunt gebruiken, want SPSS heb je nog steeds nodig voor de EFA, en andere analyses.
Heb je al een frequentie tabel geprobeerd? Analyse - descriptive statistics - frequenties.quote:
Ik heb een multiple choice vraag met de mogelijkheid tot het geven van meerdere antwoorden in mijn enquete en daar wil ik graag een tabel van. Verder heb ik al gekeken op maar ik kom er niet uit SES / Centraal SPSS Topic
Vraag:
Op welke manier kunnen externen (klanten, leveranciers) contact opnemen met het bedrijf waar u werkzaam bent (meerdere antwoorden mogelijk)?
Variable view: Value, Label:
1 = "Direct mail"
2 = "Website"
3 = "Telefonisch"
4 = "Social-media (Twitter, Google+, Facebook, LinkedIn etc.)"
5 = "E-mail"
6 = "Free publicity"
En bij Dataview heb ik dus meerdere antwoorden: 1, 2, 3, 4, 5, ingevoerd maar dit wilt niet werken. Verder zou ik niet met meerdere Variabelen willen werken omdat ik veel meerkeuzevragen met meerdere antwoorden heb.
Is het mogelijk om dit te analyseren?
[ Bericht 16% gewijzigd door Soldier2000 op 21-05-2013 21:20:58 ]
quote:
Ik heb een multiple choice vraag met de mogelijkheid tot het geven van meerdere antwoorden in mijn enquete en daar wil ik graag een tabel van. Verder heb ik al gekeken op maar ik kom er niet uit SES / Centraal SPSS Topic
Vraag:
Op welke manier kunnen externen (klanten, leveranciers) contact opnemen met het bedrijf waar u werkzaam bent (meerdere antwoorden mogelijk)?
Variable view: Value, Label:
1 = "Direct mail"
2 = "Website"
3 = "Telefonisch"
4 = "Social-media (Twitter, Google+, Facebook, LinkedIn etc.)"
5 = "E-mail"
6 = "Free publicity"
En bij Dataview heb ik dus meerdere antwoorden: 1, 2, 3, 4, 5, ingevoerd maar dit wilt niet werken. Verder zou ik niet met meerdere Variabelen willen werken omdat ik veel meerkeuzevragen met meerdere antwoorden heb.
Is het mogelijk om dit te analyseren?
Je moet deze hercoderen naar enkele dichotome variabelen. In jouw geval 6.quote:
Ik heb een multiple choice vraag met de mogelijkheid tot het geven van meerdere antwoorden in mijn enquete en daar wil ik graag een tabel van. Verder heb ik al gekeken op maar ik kom er niet uit SES / Centraal SPSS Topic
Vraag:
Op welke manier kunnen externen (klanten, leveranciers) contact opnemen met het bedrijf waar u werkzaam bent (meerdere antwoorden mogelijk)?
Variable view: Value, Label:
1 = "Direct mail"
2 = "Website"
3 = "Telefonisch"
4 = "Social-media (Twitter, Google+, Facebook, LinkedIn etc.)"
5 = "E-mail"
6 = "Free publicity"
En bij Dataview heb ik dus meerdere antwoorden: 1, 2, 3, 4, 5, ingevoerd maar dit wilt niet werken. Verder zou ik niet met meerdere Variabelen willen werken omdat ik veel meerkeuzevragen met meerdere antwoorden heb.
Is het mogelijk om dit te analyseren?
Vx_1 Direct mail
Vx_2 Website
Vx_3 ...
Vx_4 ...
Vx_5 ...
Vx_6 ...
Een '0' in deze variabele als deze niet gekozen is een '1' als het antwoord wel gekozen is.
Via analyse --> multiple response kan je een multiple response variabele samenstellen en er freq's van draaien.
Ja oke, ik heb alles een aparte variable gegeven wat een hele klus is ..quote:
[..]
[..]
Je moet deze hercoderen naar enkele dichotome variabelen. In jouw geval 6.
Vx_1 Direct mail
Vx_2 Website
Vx_3 ...
Vx_4 ...
Vx_5 ...
Vx_6 ...
Een '0' in deze variabele als deze niet gekozen is een '1' als het antwoord wel gekozen is.
Via analyse --> multiple response kan je een multiple response variabele samenstellen en er freq's van draaien.
Ja maar ik heb verschillende bedrijven met verschillende antwoorden.
Voorbeeld:
Stel eens voor dat ik van 3 bedrijven een enquęte heb afgenomen o.a.:
Bedrijf 1: Direct Mail, Website
Bedrijf 2, Free publicity, Direcht mail, Social-media,
Bedrijf 3, Telefonisch
Dan zou ik graag een tabel willen van.
Van de totale 3 bedrijven heeft, 10% direct mail, 5 telefonisch, 80%, social-media ..
Maar dat geeft tie niet aan, hij geeft de response aan:
Case Summary
Cases
Valid Missing Total
N Percent N Percent N Percent
$Bedrijfsbranchea 0 0,0% 72 100,0% 72 100,0%
a Group
Verder heb ik ook een vraag van welke branche een bedrijf zit, dan zou ik daar een pie/cake (taart) diagram van willen met verschil in % van elke branche. Ik kan dat wel 'per' variable doen maar dan krijg ik 20 verschillende taarten..
Omdat mijn vraag op de enquęte een meerkeuze vraag was met meerdere antwoorden heb ik dus alles een aparte variabele gegeven bijv.:
Variabel_Visserij = 0 is niet gekozen, 1 is wel gekozen
Variabel_Horeca = ~
Variabel_Dienstverlenend = ~
Maar ik wil alle cirkeldiagrammen samenvoegen enz 1 cirkel hebben met verschillende stukjes
quote:
[..]
[..]
Je moet deze hercoderen naar enkele dichotome variabelen. In jouw geval 6.
Vx_1 Direct mail
Vx_2 Website
Vx_3 ...
Vx_4 ...
Vx_5 ...
Vx_6 ...
Een '0' in deze variabele als deze niet gekozen is een '1' als het antwoord wel gekozen is.
Via analyse --> multiple response kan je een multiple response variabele samenstellen en er freq's van draaien.
Het is mij eindelijk gelukt maar ik kan hier helaas geen bar/pie charts van maken of wel? Voor duidelijke grafieken ter presentatie voor mijn docent ..
Theoretisch gezien klopt dit. Statistisch gezien blijft de vijf-item-scale betrouwbaarder dan de drie-item scale en bovendien wijst Factor Analyse uit dat alle vijf de items hoog laden op het concept 'religiousness'. Het betreft dichotome variabelen.
Wat is wijsheid? Het concept splitsen of niet ?
FA met 5 items is tricky, het is erg weinig. Wat komt eruit als je twee factoren opgeeft? Wat zijn de eigenvalues?quote:
Voor mijn thesis gebruik ik het concept 'religiousness' waarbij ik kijk naar vijf items. Het concept is echter ook op te splitsen in twee concepten (sociale aspect en dogmatische aspect van religie).
Theoretisch gezien klopt dit. Statistisch gezien blijft de vijf-item-scale betrouwbaarder dan de drie-item scale en bovendien wijst Factor Analyse uit dat alle vijf de items hoog laden op het concept 'religiousness'. Het betreft dichotome variabelen.
Wat is wijsheid? Het concept splitsen of niet ?
Component matrix laat ook zien dat 'het sociale aspect' veel hoger laadt (.792) op het algemene concept dan op het tweede concept (.519).
hoe groot is je N?
welke rotatie gebruik je?
N = zo'n 37.000 respondenten.
Rotatie is Oblimin.
Correctie: 'het sociale aspect' laadt 0,519 op de tweede component (samen met nog één item boven de 0.3). Maar het is overduidelijk dat de items beter laden op de eerste (allen boven 0.79).
[ Bericht 54% gewijzigd door Arnoldus_K op 23-05-2013 11:42:34 ]
Ik zou het op 1 factor houden
Dank u vriendelijk
Ik moet een regressie uitvoeren waar een interactie in zit. Hierbij test ik hoe het zijn van een immigrant (Znonwestern) invloed heeft op het bewustzijn van deze persoon (ZAON) en hoe de generatie van een de immigrant (Zgeneratie) deze relatie beďnvloedt. Hiervoor heb ik een interactievariabele gemaakt die in het laatste model (model 3) wordt ingevoerd. De syntax ziet er dan als volgt uit:
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT ZAON
/METHOD=ENTER Znonwestern Zgeneratie
/METHOD=ENTER gen_nonwest.
Het probleem is nu dat, wanneer ik dit command run, SPSS automatisch de interactie uit mijn model verwijderd. In mijn output wordt model 3 (daar waar de interactie erbij komt) helemaal niet meer weergegeven. Hij is dan alleen nog maar terug te vinden in de tabel van de 'excluded variables'.
Ik hoop dat ik het zo duidelijk heb omschreven. Heeft iemand enig idee wat hier fout gaat? Of wat de oplossing hiervoor is?
In je syntax staat dat je maar twee modellen hebt.quote:Op donderdag 23 mei 2013 13:03 schreef TWP het volgende:
Hm, een SPSS probleempje. Hopelijk kan iemand hier me helpen.
Ik moet een regressie uitvoeren waar een interactie in zit. Hierbij test ik hoe het zijn van een immigrant (Znonwestern) invloed heeft op het bewustzijn van deze persoon (ZAON) en hoe de generatie van een de immigrant (Zgeneratie) deze relatie beďnvloedt. Hiervoor heb ik een interactievariabele gemaakt die in het laatste model (model 3) wordt ingevoerd. De syntax ziet er dan als volgt uit:
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT ZAON
/METHOD=ENTER Znonwestern Zgeneratie
/METHOD=ENTER gen_nonwest.
Het probleem is nu dat, wanneer ik dit command run, SPSS automatisch de interactie uit mijn model verwijderd. In mijn output wordt model 3 (daar waar de interactie erbij komt) helemaal niet meer weergegeven. Hij is dan alleen nog maar terug te vinden in de tabel van de 'excluded variables'.
Ik hoop dat ik het zo duidelijk heb omschreven. Heeft iemand enig idee wat hier fout gaat? Of wat de oplossing hiervoor is?
Kan je eens eens de frequentietabellen plaatsen van je variabelen?
Oja sorry, ik ben m'n controlevariabelen vergeten te vermelden in de syntax. Dat is het eerste model.quote:
[..]
In je syntax staat dat je maar twee modellen hebt.
Kan je eens eens de frequentietabellen plaatsen van je variabelen?
De frequentietabellen zijn als volgt (gestandaardiseerd):
Is dit wat je bedoelt?SPOILER




Nee, ook daar heeft het niet mee te maken. Maar ik zie al waar het probleem ligt. De verdeling van de interactie is namelijk precies het zelfde als die van een van de hoofdeffecten. Dus de interactie verklaart niks extra's ten opzichte van het hoofdeffect.quote:
Ja dat bedoel ik. Waarom heb je alles gestandaardiseerd? Is niet nodig en mag voor categorische / dichotomie variabelen niet eens. Neem daar eens de normale variabelen voor om te kijken of het probleem daarmee te maken heeft. Zo nee, post dan nogmaals de syntax, foutmelding en wat descriptieve gegevens. Vergeet ook niet de assumpties te checken.
Op welke manier moet ik dan een interactie maken van twee dichitome variabelen?SPOILER


dus
compute XxY = X * Y.
exeucute.
Dat heb ik inderdaad gedaan, maar dan krijg ik de variabelen die ik in mijn vorige post heb gezet. En dat blijkt niet te werken in de regressie. Ergens gaat het dus niet helemaal goed?quote:
Door de dichotome variabele te vermenigvuldigen met de (andere) variabele.
dus
compute XxY = X * Y.
exeucute.
De variabelen gen en gen_nonwest zijn identiek aan elkaar en worden daarom niet meegenomen in je regressie.quote:
[..]
Dat heb ik inderdaad gedaan, maar dan krijg ik de variabelen die ik in mijn vorige post heb gezet. En dat blijkt niet te werken in de regressie. Ergens gaat het dus niet helemaal goed?
Dat vermoed ik.
Kan je een kruistabel maken en posten?
[ Bericht 2% gewijzigd door crossover op 24-05-2013 14:31:30 ]
[ Bericht 100% gewijzigd door crossover op 24-05-2013 14:31:25 ]
quote:
[..]
De variabelen gen en gen_nonwest zijn identiek aan elkaar en worden daarom niet meegenomen in je regressie.
Dat vermoed ik.
Kan je een kruistabel maken en posten?

Ik vind het trouwens echt top dat je zo wilt helpen.
NPquote:
[..]
[ afbeelding ]
Ik vind het trouwens echt top dat je zo wilt helpen.
Maar, zoals ik al dacht, er is sprake van multicollineariteit in de meest extreme vorm. Volledige samenhang, variabelen zijn identiek etc etc etc; dus daarom wordt ie eruit gegooid.
Zou je misschien weten op welke manier ik dan de interactie alsnog kan testen? Zou ik het op een andere manier kunnen aanpakken?quote:
[..]
NP
Maar, zoals ik al dacht, er is sprake van multicollineariteit in de meest extreme vorm. Volledige samenhang, variabelen zijn identiek etc etc etc; dus daarom wordt ie eruit gegooid.
refererend naar mijn vraag van vorige week over welke regressie type ik dien te gebruiken heb ik van mijn scriptiebegeleider te horen gekregen dat, indien de afhankelijke en onafhankelijke variabele op dezelfde schaal zijn gemeten (bij mij 1-7 likert scales) je dus gewoon linear regression kan gebruiken (godzijdank
Mijn vraag is nu, gezien ik 1-7 likert scales categorische data heb, of ik nu chi-square tests kan uitvoeren om te kijken of de variabelen onafhankelijk van elkaar zijn of niet. Nu heb ik een tabel van 7 bij 7 terwijl je in de praktijk meestal 2x2 tabellen ziet. Is mijn tabel nog wel enig verklarend en kan ik pearson's chi-square significantie van dit 7x7 tabel zonder problemen overnemen?
Verder heb ik ook in mijn dataset demografische, categorische data (land, industrie soort, aantal werknemers (onderverdeeld in groepen), en sales (ook onderverdeeld in groepen)) die ik via chi-square wil testen op (on)afhankelijkheid van elke 1-7 likert scale variabele wil testen. Uit de analyse komen helaas weinig significante pearson chi-squares, wat duidt op onafhankelijkheid van de variabele (bijv land=spanje) met een 1-7 likert scale. Klopt ook hier mijn methodiek of dien ik een andere methode toe te passen?
alvast bedankt voor jullie antwoorden!
alvast bedankt
Ik heb een korte SPSS vraag. Voor mij is het de eerste keer dat ik met SPSS werk maar het hoeft allemaal niet zo diepgaand...
Ik meet met 4 vragen de houding van mensen naar een bepaald gedrag. (kwantitatief onderzoek, survey). Het is mij gelukt om deze vier vragen samen te voegen middels Analyse-Dimension reduction--> factor.
Wil ik dit zelfde doen voor een andere variabele die gemeten word door 4 vragen krijg ik 2 outputs van die factor reduction.
Iemand enig idee waarom dit gebeurt en hoe ik deze 2 nu kan vergelijken in bv correlations?
Of betekend dit dat mijn vragen blijkbaar niet het zelfde meten?
Alvast bedankt!
Je kan ook aangeven dat je slechts 1 factor uit de analyse wilt hebben via 'extraction' menu.
Heb nu dit syntax-command, maar op de een of andere manier herkent hij de missing values niet.
recode v204 (-2 -1=1)(else=0) into authomis.
Bij een cross-tabulation van v204 & authomis geeft SPSS aan dat de missing-dummy enkel een '0'-categorie heeft, terwijl er meer dan 400 cases zijn met een missing. Heeft dit te maken met hoe de missing-value is aangemerkt in variabele v204?
Heb in mijn logistische regressie een dichotome afhankelijke variabele 'tol' waarbij 1=tolerant , 0=niet tolerant.
Daarnaast heb ik als onafhankelijke variabele een geaggregeerde variabele van 'tol' aangemaakt, die de gemiddeldes van de landen opneemt. Ik wil zo kijken naar het effect van het 'normatieve klimaat' in een land op individuele tolerantie-niveaus.
Echter, de Odds Ratio is belachelijk hoog, namelijk 482,52. De twee variabelen zijn niet ernstig met elkaar gecorreleerd (0.245) en ook een crosstab wijst multicollineariteit af (zie plaatje).

PS: Geaggregeerde variabele is zo aangemaakt:
AGGREGATE
/break = country
/drugtolmean = mean(drugtol).
freq drugtolmean.
Ik moet (eventuele) mediatie aantonen. Ik heb X (dichotome variabele) en Y uiteraard, en 4 mogelijke mediatoren M1, M2, M3 en M4.
De opdracht: "Voer in SPSS op de bijgeleverde dataset de analyses uit waarmee je test voor mediatie
0 - Alle noodzakelijke regressieanalyses
0 - Sobel-test(s)"
De "hoofdvraag" is of de mate van M1 groter is als X danwel 0, danwel 1 is. (voor de rest kijken of er andere effecten aanwezig zijn dus)
Alleen ik heb nu dus geen čnkel idee hoe ik hier mee moet beginnen... Waarmee moet ik beginnen om bepaalde effecten te bekijken, wat is stap 1? Ik kan op internet wel mediatie analyse vinden, en ook wel met 2 mediatoren, maar niet meer meerdere...
Zoek effe op het Indirect script van Hayes. Misschien lastig om werkend te krijgen, maar als dat het doet dan is het echt ideaal.quote:
Ik heb een vraag.
Ik moet (eventuele) mediatie aantonen. Ik heb X (dichotome variabele) en Y uiteraard, en 4 mogelijke mediatoren M1, M2, M3 en M4.
De opdracht: "Voer in SPSS op de bijgeleverde dataset de analyses uit waarmee je test voor mediatie
0 - Alle noodzakelijke regressieanalyses
0 - Sobel-test(s)"
De "hoofdvraag" is of de mate van M1 groter is als X danwel 0, danwel 1 is. (voor de rest kijken of er andere effecten aanwezig zijn dus)
Alleen ik heb nu dus geen čnkel idee hoe ik hier mee moet beginnen... Waarmee moet ik beginnen om bepaalde effecten te bekijken, wat is stap 1? Ik kan op internet wel mediatie analyse vinden, en ook wel met 2 mediatoren, maar niet meer meerdere...
Dat ziet er dan zo uit:

http://afhayes.com/spss-sas-and-mplus-macros-and-code.html
Waarom doe je niet gewoon spearman rank correlation?quote:
Hoi,
refererend naar mijn vraag van vorige week over welke regressie type ik dien te gebruiken heb ik van mijn scriptiebegeleider te horen gekregen dat, indien de afhankelijke en onafhankelijke variabele op dezelfde schaal zijn gemeten (bij mij 1-7 likert scales) je dus gewoon linear regression kan gebruiken (godzijdank
Mijn vraag is nu, gezien ik 1-7 likert scales categorische data heb, of ik nu chi-square tests kan uitvoeren om te kijken of de variabelen onafhankelijk van elkaar zijn of niet. Nu heb ik een tabel van 7 bij 7 terwijl je in de praktijk meestal 2x2 tabellen ziet. Is mijn tabel nog wel enig verklarend en kan ik pearson's chi-square significantie van dit 7x7 tabel zonder problemen overnemen?
Verder heb ik ook in mijn dataset demografische, categorische data (land, industrie soort, aantal werknemers (onderverdeeld in groepen), en sales (ook onderverdeeld in groepen)) die ik via chi-square wil testen op (on)afhankelijkheid van elke 1-7 likert scale variabele wil testen. Uit de analyse komen helaas weinig significante pearson chi-squares, wat duidt op onafhankelijkheid van de variabele (bijv land=spanje) met een 1-7 likert scale. Klopt ook hier mijn methodiek of dien ik een andere methode toe te passen?
alvast bedankt voor jullie antwoorden!
recode v204 (SYSMIS,-2,-1=1) (else=0) into authomis.quote:
Kort vraagje mbt het aanmaken van een 'missing-dummy', die ik vervolgens in een logistische regressie wil meenemen. Deze missing-dummy geeft een '1' aan de cases waarbij de data missing is (voor een betreffende variabele) en een '0' aan de cases waar data wel gewoon aanwezig is.
Heb nu dit syntax-command, maar op de een of andere manier herkent hij de missing values niet.
recode v204 (-2 -1=1)(else=0) into authomis.
Bij een cross-tabulation van v204 & authomis geeft SPSS aan dat de missing-dummy enkel een '0'-categorie heeft, terwijl er meer dan 400 cases zijn met een missing. Heeft dit te maken met hoe de missing-value is aangemerkt in variabele v204?
execute.
(zoiets, kan zijn dat er ergens een foutje zit want ik doe het uit m'n hoofd. pak anders even de syntax reference erbij)
Hier is ergens iets fout gegaan, loop al je stappen na en check alles even.quote:
En direct nog een vraag er achteraan:
Heb in mijn logistische regressie een dichotome afhankelijke variabele 'tol' waarbij 1=tolerant , 0=niet tolerant.
Daarnaast heb ik als onafhankelijke variabele een geaggregeerde variabele van 'tol' aangemaakt, die de gemiddeldes van de landen opneemt. Ik wil zo kijken naar het effect van het 'normatieve klimaat' in een land op individuele tolerantie-niveaus.
Echter, de Odds Ratio is belachelijk hoog, namelijk 482,52. De twee variabelen zijn niet ernstig met elkaar gecorreleerd (0.245) en ook een crosstab wijst multicollineariteit af (zie plaatje). [ afbeelding ]
PS: Geaggregeerde variabele is zo aangemaakt:
AGGREGATE
/break = country
/drugtolmean = mean(drugtol).
freq drugtolmean.
Ik vond t eerst een beetje een rare vraag van je, maar heb er nog eens naar gekeken en kan me er wel in vinden. Mijn data is ook eigenlijk niet normaal verdeeld dus dan is spearman een betere correlatietoets dan Pearson.quote:
[..]
Waarom doe je niet gewoon spearman rank correlation?
Betreffende de chi-square toets waar ik eigenlijk een vraag over stelde ga ik nu voor een fischer exact test ipv pearson chi-square, dit gezien ik een kleine dataset heb en er veelal niet aan de eis van pearson chi-square wordt voldaan, ik heb namelijk veelal meer dan 20% lage (<5/10) observed en expected values.
Nogmaals bedankt voor de nieuwe ingevingen.
[ Bericht 0% gewijzigd door Baldadig1989 op 28-05-2013 00:29:07 ]
Ja, het ligt volgens mij niet aan het recode-command. Heb alle mogelijke opties al langsgelopen, maar het blijft een feit dat de '1'-value bij een frequency-uitdraai wél wordt getoond, maar zodra ik een cross-tabulation met de originele variabele draai óf de missing-dummy toevoeg in een logistische regressie, deze er uit wordt gegooid omdat er enkel een waarde '0' bestaat.quote:
recode v204 (SYSMIS,-2,-1=1) (else=0) into authomis.
execute.
(zoiets, kan zijn dat er ergens een foutje zit want ik doe het uit m'n hoofd. pak anders even de syntax reference erbij)

Echter, bij een nominale variabele (waarbij ik de missing values heb vervangen door het gemiddelde, zie plaatje) pakt SPSS wél de missing dummy-value van '1'. Hier zit het verschil. Hoe kan dit?

Heb e.e.a. nagelopen, maar kom niet verder. Feit is dat de odds lager worden als ik één van de volgende opties hanteer. Ik heb weinig inzicht in wat hier 'mag'. Wellicht dat iemand hier hulp bij kan bieden?quote:
Hier is ergens iets fout gegaan, loop al je stappen na en check alles even.
1) Ik maak van de 0-1 schaal een 0-100 schaal. De OR gaat van 482 naar 1,028. (!).
2) Ik gebruik geen dichotome variabele om de geaggregeerde scores aan te maken, maar de originele variabele (met waardes tussen 0-10). De OR gaat van 482 naar 4,7.
3) Ik gebruik logged scores van de eerder aangemaakte dichotome (geaggregeerde!) schaal, om zo de relatieve afstand in acht te nemen. De OR gaat van 482 naar 4,8.
Hopelijk is het voldoende informatie die ik presenteer.
Ik moet een aantal variabelen testen in SPSS en ik had eerst n = 82.
Toen moest ik bij een test een boxplot maken, waaruit bleek dat er een aantal outliers waren. De grootste drie outliers heb ik vervolgens uitgesloten (n = 79).
Daarna ging ik verder met de rest van de tests. Moet je nu bij de tests die je nog moet uitvoeren die n = 79 aanhouden, of neem je gewoon weer dat totaal van 82 mee?
Sorry als ik onduidelijk ben of als er info mist. Ben niet echt een held in SPSS en had het werk een behoorlijke tijd weggelegd, waardoor ik er even uit ben.
Aangezien je de outliers er al uit heb gehaald lijkt het mij logischer om met de nieuwe populatie van n=79 verder te gaan.
Ik hoop dat ik je hiermee heb geholpen.
Bedankt, hier ben ik zeker mee geholpen : )quote:
Als je analyses moet/gaat doen waarin de grootste outliers eruit zijn gehaald dan moet je n=79 gebruiken, als je die outliers alleen wilt definiëren/benoemen en verder gewoon analyses doen, dat moet je n=82 gebruiken. De outliers hebben dan natuurlijk wel invloed op je resultaten.
Aangezien je de outliers er al uit heb gehaald lijkt het mij logischer om met de nieuwe populatie van n=79 verder te gaan.
Ik hoop dat ik je hiermee heb geholpen.
Ook belangrijk, waarom heb je ze uitgesloten?quote:
Ik hoop dat iemand mij kan helpen.
Ik moet een aantal variabelen testen in SPSS en ik had eerst n = 82.
Toen moest ik bij een test een boxplot maken, waaruit bleek dat er een aantal outliers waren. De grootste drie outliers heb ik vervolgens uitgesloten (n = 79).
Daarna ging ik verder met de rest van de tests. Moet je nu bij de tests die je nog moet uitvoeren die n = 79 aanhouden, of neem je gewoon weer dat totaal van 82 mee?
Sorry als ik onduidelijk ben of als er info mist. Ben niet echt een held in SPSS en had het werk een behoorlijke tijd weggelegd, waardoor ik er even uit ben.
Ik mocht alleen respondenten meetellen die Nederlands als moedertaal hadden. Volgens de enquęte hadden deze respondenten een zeer lage score aan zichzelf gegeven bij de vraag 'kennis van de Nederlandse taal'.quote:
[..]
Ook belangrijk, waarom heb je ze uitgesloten?
Haha, ik heb zo te zien zojuist mijn eigen vraag beantwoord.. Zoals ik al zei, ik ben er een tijdje uit geweest.. :$
Maar vroeg me dus af of ik dan die tests die ik vóór die boxplot test had gedaan, weer opnieuw moest doen met het nieuwe totaal.
Aaah okai, maar je moet inderdaad eerst je data screenen op missing data, outliers , normality, non response bias en common bias. En daarna ga je met je nieuwe dataset n=79 idd pas beginnen met de reliability en validity van je data.quote:
[..]
Ik mocht alleen respondenten meetellen die Nederlands als moedertaal hadden. Volgens de enquęte hadden deze respondenten een zeer lage score aan zichzelf gegeven bij de vraag 'kennis van de Nederlandse taal'.
Haha, ik heb zo te zien zojuist mijn eigen vraag beantwoord.. Zoals ik al zei, ik ben er een tijdje uit geweest.. :$
Maar vroeg me dus af of ik dan die tests die ik vóór die boxplot test had gedaan, weer opnieuw moest doen met het nieuwe totaal.
Okay thanks. Dus dan moet ik toch die eerdere tests maar voor de zekerheid opnieuw uitvoeren met die nieuwe dataset. Voor de rest heb ik alles gecheckt op outliers en missing data, dus dan kan ik met die n=79 de rest van de stapel tests gaan doen.quote:
[..]
Aaah okai, maar je moet inderdaad eerst je data screenen op missing data, outliers , normality, non response bias en common bias. En daarna ga je met je nieuwe dataset n=79 idd pas beginnen met de reliability en validity van je data.
Ik moet de gemiddelde leeftijd van de ouders in mijn steekproef berekenen. Sommige ouders hebben de vragenlijst echter voor meerdere kinderen ingevuld en hebben dus meerdere keren hun leeftijd opgegeven. Ik heb respondentnummers, dus ik kan zien wie dit heeft gedaan. Maar hoe zorg ik dat ik hun antwoord maar een keer meeneem in mijn analyses? Daar moet toch een makkelijk trucje voor zijn?
Mag voor persuasieonderzoek anovas en t toetsen doen. Doe ik het al voor in mn broek, maar we gaan zien hoe het gaat lopen en of ik hier nog terug kom in al mijn hysterie.
Ik heb van vier variabelen een aantal missings. In mijn onderzoek wil ik logistische regressie doen.
Dit betekent dat er veel respondenten afvallen omdat er ergens missings zijn (toch? of kan je sommige respondenten toch mee laten doen, ondanks een missing in één van de variabelen?)
Nou ben ik na wat struinen op internet erachter gekomen dat je met behulp van imputatie missing values kan invullen. Nu is er allereerst de mogelijkheid voor enkelvoudige imputatie (onder missing value analysis is dit te vinden) de andere optie is multipele imputatie, dit houdt dat er meerdere datasets worden toegevoegd. Dus binnen 1 bestand komen er bijvoorbeeld 5 datasets, waarin de missing values zijn ingevuld. Wanneer ik vervolgens logistische regressie doe, krijg ik het probleem dat er ook 5 regressieanalyses worden uitgevoerd?
Welke manier van imputatie is het beste voor mij? En als dit multipele imputatie is, hoe kan ik er één logistische regressie van maken?
Hoeveel respondenten heb je die een missing value hebben, en hoeveel respondenten heb je in totaliteit?quote:
Voor mijn afstudeerscriptie ben ik bezig met een SPSS-bestand.
Ik heb van vier variabelen een aantal missings. In mijn onderzoek wil ik logistische regressie doen.
Dit betekent dat er veel respondenten afvallen omdat er ergens missings zijn (toch? of kan je sommige respondenten toch mee laten doen, ondanks een missing in één van de variabelen?)
Nou ben ik na wat struinen op internet erachter gekomen dat je met behulp van imputatie missing values kan invullen. Nu is er allereerst de mogelijkheid voor enkelvoudige imputatie (onder missing value analysis is dit te vinden) de andere optie is multipele imputatie, dit houdt dat er meerdere datasets worden toegevoegd. Dus binnen 1 bestand komen er bijvoorbeeld 5 datasets, waarin de missing values zijn ingevuld. Wanneer ik vervolgens logistische regressie doe, krijg ik het probleem dat er ook 5 regressieanalyses worden uitgevoerd?
Welke manier van imputatie is het beste voor mij? En als dit multipele imputatie is, hoe kan ik er één logistische regressie van maken?
In totaal is mijn N 279. Daarvan houd ik er 189 over wanneer ik een logistische regressie wil doen.quote:
[..]
Hoeveel respondenten heb je die een missing value hebben, en hoeveel respondenten heb je in totaliteit?
Tjeemig heb je 90 respondents met missing values??quote:
[..]
In totaal is mijn N 279. Daarvan houd ik er 189 over wanneer ik een logistische regressie wil doen.
Het gaat om data uit een systeem (politieverhoren). Niet alle data was te vinden. Bij 90 respondenten is inderdaad in ieder geval 1 variabele missend.quote:
[..]
Tjeemig heb je 90 respondents met missing values??
En wat voor variabelen mis je? Kun je een paar voorbeelden geven. Want iedere methode heeft zo zijn voor en nadelen, en je moet in je thesis echt heel goed gaan onderbouwen hoe je met deze 79 respondenten omgaat.quote:
[..]
Het gaat om data uit een systeem (politieverhoren). Niet alle data was te vinden. Bij 90 respondenten is inderdaad in ieder geval 1 variabele missend.
Al mijn missende variabelen zijn dummyvariabelen (werkend/werkloos ; alcoholgebruik/ geen alcohol gebruik ; ongehuwd / gehuwd ). Mijn informatie van de overige variabelen is compleet (leeftijd / etniciteit / wapengebruik / recidivegedrag / mishandeling ).quote:
[..]
En wat voor variabelen mis je? Kun je een paar voorbeelden geven. Want iedere methode heeft zo zijn voor en nadelen, en je moet in je thesis echt heel goed gaan onderbouwen hoe je met deze 79 respondenten omgaat.
Je hebt het over 79 respondenten; even voor de duidelijkheid: mijn N is 279, waarvan er 90 missings zijn.
Sorry, bedoelde inderdaad 90. Eigenlijk zijn er 3 opties, pairwise deletion, listwise deletion en replacements. Jij hebt zoveel missing values dat ik niet goed zou weten wat in jouw geval de beste oplossing is. Je kunt de cases eruit gooien, maar dat zal waarschijnlijk veel invloed op latere analyses gaan hebben. Als je voor een replacement techniek kiest, dan moet je die nieuwe dataset gebruiken in andere analyses. Alleen je moet wel verdomd goed onderbouwen waarom jij denkt dat dit geen biasen gaat opleveren. Want als je bijv. 50% van je missing values verkeerd zou invullen (met behulp van mean imputatie), dan krijg jij straks waarschijnlijk andere resultaten.quote:
[..]
Al mijn missende variabelen zijn dummyvariabelen (werkend/werkloos ; alcoholgebruik/ geen alcohol gebruik ; ongehuwd / gehuwd ). Mijn informatie van de overige variabelen is compleet (leeftijd / etniciteit / wapengebruik / recidivegedrag / mishandeling ).
Je hebt het over 79 respondenten; even voor de duidelijkheid: mijn N is 279, waarvan er 90 missings zijn.
Ik ben benieuwt wat crossover zijn advies is
Ik heb inmiddels gekozen om de data te imputeren (multipele imputatie bij SPSS), volgens mij is dit de meest betrouwbare methode. De dataset is nu 5 keer geimputeerd. Resultaten uit logistische regressie worden dan gepresenteerd met behulp van de gepoolde uitkomsten. Is dit een verantwoorde manier?quote:
[..]
Sorry, bedoelde inderdaad 90. Eigenlijk zijn er 3 opties, pairwise deletion, listwise deletion en replacements. Jij hebt zoveel missing values dat ik niet goed zou weten wat in jouw geval de beste oplossing is. Je kunt de cases eruit gooien, maar dat zal waarschijnlijk veel invloed op latere analyses gaan hebben. Als je voor een replacement techniek kiest, dan moet je die nieuwe dataset gebruiken in andere analyses. Alleen je moet wel verdomd goed onderbouwen waarom jij denkt dat dit geen biasen gaat opleveren. Want als je bijv. 50% van je missing values verkeerd zou invullen (met behulp van mean imputatie), dan krijg jij straks waarschijnlijk andere resultaten.
Ik ben benieuwt wat crossover zijn advies is
Oke, situatie: Ik wil weten of een hoge score op X veroorzaakt wordt door een betere score op Y. Y bestaat uit meerdere measures, bij sommige measures is een hoge score beter, bij andere is een lage beter. Daarnaast kijk ik ook naar een lineair verband tussen X en demografische gegevens.
Ik weet dat ik hiervoor een lineaire regressieanalyse moet uitvoeren. Volgens mijn afstudeerbegeleider moet ik dan een hiërarchische doen, omdat ik denk dat Y meer invloed heeft op X dan demografisch. Ik loop dus echt vast zodra ik daarmee bezig ga.
Mijn vraag dan ook: Hoe doe ik zo'n analyse en waar moet ik naar kijken in de eindeloze tabellen bij de uitkomsten? Moet ik dan ook nog rekening houden met de hoog/laag verschillen bij familie? En wat doe ik dan bij die blocks?
Hoop dat iemand kan helpen, dit is hopeloos