DIG Digital Corner
Alles wat je altijd al over computers, hardware, software, internet en elektronische gadgets had willen weten, maar niet op Tweakers.net durft te vragen.



quote:Op dinsdag 22 april 2014 19:51 schreef pascal08 het volgende:
[..]
Dat is gewoon niet wat ik zoek. Ik heb zelf inmiddels al een code geschreven. Kostte uiteindelijk minder moeite dan een geschikte library vinden.

Interessante praatjes zijn datquote:
https://www.destroyallsoftware.com/talks/boundaries

Ik zit al een tijd met mijn handen in het haar betreft de FOK!vriendjes module welke ik sinds kort in het FOK!stats script heb zitten. Het probleem is dat deze erg traag is, het probleem zit in het PHP script welke blijkbaar struggles heeft met de grote hoeveelheid data welke verwerkt moet worden.
Het script doet het volgende:
1. Haal alle topic-id's op waar de ingevoerde gebruiker heeft gereageerd
2. Haal alle posts behorende bij de topic-id's op in delen van 32 topics, dit omdat Sphinx is ingesteld op max 10.000 resultaten
3. Loop over alle posts en voeg de bijbehorende topic-id's toe aan een array welke de unieke topic's per gebruiker gevat.
Uit bovenstaande stappen hou je uiteindelijk een lijst over van alle topics waar andere gebruikers samen met de ingevoerde gebruiker hebben gereageerd.
Zie het volgende stukje code, de array $resultaat["matches"] (afkomstig uit Sphinx) bevat alle unieke topic-id's waar de ingevoerde gebruiker gereageerd heeft.
Iemand een idee hoe ik het script sneller kan maken? Ik heb er nu een limiet van een maand op zitten omdat het anders veel te traag wordt. Het idee is de topics te verkrijgen waar je samen met iemand hebt gepost. Als je vaak in dezelfde topics als de ingevoerde gebruiker post zul je hoger in de lijst van die gebruiker komen te staan.
Het script doet het volgende:
1. Haal alle topic-id's op waar de ingevoerde gebruiker heeft gereageerd
2. Haal alle posts behorende bij de topic-id's op in delen van 32 topics, dit omdat Sphinx is ingesteld op max 10.000 resultaten
3. Loop over alle posts en voeg de bijbehorende topic-id's toe aan een array welke de unieke topic's per gebruiker gevat.
Uit bovenstaande stappen hou je uiteindelijk een lijst over van alle topics waar andere gebruikers samen met de ingevoerde gebruiker hebben gereageerd.
Zie het volgende stukje code, de array $resultaat["matches"] (afkomstig uit Sphinx) bevat alle unieke topic-id's waar de ingevoerde gebruiker gereageerd heeft.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | <?php if(!empty($resultaat["matches"])) { $current_count = 0; $topic_ids = array(); $users_topics = array(); $this->cl->resetGroupBy(); # loop over de gevonden topic-id's foreach($resultaat["matches"] as $mId => $mData) { $current_count++; $pCounts = $mData['attrs']; $topic_ids[] = $pCounts['topic_id']; # verwerk het in stukken van 32 topics zodat het max uit de volgende query nooit boven de 10.000 (max Sphinx) uitkomt met 310 posts per topic gerekend if(count($topic_ids) == 32 || ($current_count == $total_found && !empty($topic_ids))) { $this->cl->resetFilters(); $this->cl->SetFilter("topic_id", $topic_ids); $topic_ids = array(); $this->cl->SetLimits(0, 10000, 10000); $resultaat = $this->cl->Query('', $this->config['indices']); $total_query_time += $resultaat["time"]; if(!empty($resultaat["matches"])) { # loop over de teruggegeven posts en voeg de topic-id's toe aan de array welke de unieke topics per gebruiker bevat, dit wordt later dvm de count functie toegevoegd aan de lijst welke wordt weergegeven in de tool # dit stuk is erg traag en doet er enkele seconden over om een lijst van 15.000 posts te verweken (ingevoerde gebruiker heeft in dit geval in 50 topics gepost) foreach($resultaat["matches"] as $mId => $mData) { if($mData['attrs']['auteur_id'] != $auteurId) { if(!isset($users_topics[$mData['attrs']['auteur_id']][$mData['attrs']['topic_id']])) { $users_topics[$mData['attrs']['auteur_id']][$mData['attrs']['topic_id']] = 1; } } } } } } } ?> |
Iemand een idee hoe ik het script sneller kan maken? Ik heb er nu een limiet van een maand op zitten omdat het anders veel te traag wordt. Het idee is de topics te verkrijgen waar je samen met iemand hebt gepost. Als je vaak in dezelfde topics als de ingevoerde gebruiker post zul je hoger in de lijst van die gebruiker komen te staan.
Wat is precies de bottleneck? Om wat voor orde van grootte gaat het in die loops? Zegt bijv. de xdebug profiler iets zinnigs?

Bij dit stuk gaat het traag:quote:
Wat is precies de bottleneck? Om wat voor orde van grootte gaat het in die loops? Zegt bijv. de xdebug profiler iets zinnigs?
| 1 2 3 4 5 6 7 8 9 | <?php foreach($resultaat["matches"] as $mId => $mData) { if($mData['attrs']['auteur_id'] != $auteurId) { if(!isset($users_topics[$mData['attrs']['auteur_id']][$mData['attrs']['topic_id']])) { $users_topics[$mData['attrs']['auteur_id']][$mData['attrs']['topic_id']] = 1; } } } ?> |
Bovenstaande voegt de teruggegeven data uit Sphinx toe aan de array waar de topics per gebruiker staan. Het gaat hier om losse posts, als een gebruiker in bijvoorbeeld 50 topics heeft gepost binnen een gekozen periode dan komt dat neer op ongeveer 15050 posts, ervan uitgaande dat er binnen elk topic 301 posts (incl. OP) staan.
Er zijn in dit geval dus 15050 loops nodig om alles bij langs te gaan, het meest trage is de isset en het toevoegen van de gegevens aan de array. Als dit dus op een andere, snellere manier zou kunnen dan zou dat een grote winst zijn aangezien ik de maximaal te selecteren periode dan kan ophogen, dit is nu een maand.
De overige stats worden allemaal door Sphinx zelf gegenereerd en dat gaat veel sneller. Deze statistiek is echter niet volledig te doen in Sphinx omdat ik op twee waarden moet groeperen, namelijk user_id en topic_id, dit omdat de topic-id's slechts één keer per gebruiker mogen worden geteld.
Een andere optie welke ik heb overwogen is het toevoegen van een gecombineerde waarde (user_id+topic_id) aan de index en daarop groeperen in de Sphinx query. Deze methode maakt de index echter significant groter en kost meer geheugen waar ik al niet teveel van heb in mijn server.
xdebug heb ik nog niet geprobeerd en heb ik ook geen ervaring mee. Ik ga daar ff naar kijken.
| 1 2 3 4 5 6 7 8 9 | <?php foreach($resultaat["matches"] as $mId => $mData) { if($mData['attrs']['auteur_id'] != $auteurId) { if(!isset($users_topics[$mData['attrs']['auteur_id']][$mData['attrs']['topic_id']])) { $users_topics[$mData['attrs']['auteur_id']][$mData['attrs']['topic_id']] = 1; } } } ?> |
Hier vallen me een paar dingen op. Om te beginnen ben ik benieuwd wat er in $auteurId staat en waarom er een != wordt gebruikt voor die vergelijking. Verder heb je de isset()-check niet nodig. Je set de waarde op 1, en als die toevallig al geset was, verandert er niets. En je benadert (ook zonder isset()) $mData['attrs']['auteur_id'] meerdere keren. Niet fout, maar ik zou er een variabele van maken (en dat waarschijnlijk ook doen voor $mData['attrs']['topic_id']), al was het maar voor een betere leesbaarheid.

Ik denk dat in het eerste if statement met de $auteurId wordt gekeken of de post niet van degene zelf is.quote:
[ code verwijderd ]
Hier vallen me een paar dingen op. Om te beginnen ben ik benieuwd wat er in $auteurId staat en waarom er een != wordt gebruikt voor die vergelijking. Verder heb je de isset()-check niet nodig. Je set de waarde op 1, en als die toevallig al geset was, verandert er niets. En je benadert (ook zonder isset()) $mData['attrs']['auteur_id'] meerdere keren. Niet fout, maar ik zou er een variabele van maken (en dat waarschijnlijk ook doen voor $mData['attrs']['topic_id']), al was het maar voor een betere leesbaarheid.
Die lijkt mij onhandig. De enkele keer dat ie nuttig is, weegt niet op tegen de keren dat ie niet nuttig is. Mijn idee is om die eruit te halen en eventueel na de foreach loop die ene entry uit $users_topics ($users_topics[$auteurId]) te halen.
[ Bericht 19% gewijzigd door Maringo op 26-04-2014 11:03:51 ]
Kan je deze logica niet veel beter in je SQL oplossen, dat lijkt me vele malen sneller dan het oplossen in PHP.quote:Op vrijdag 25 april 2014 22:56 schreef bondage het volgende:
Het script doet het volgende:
1. Haal alle topic-id's op waar de ingevoerde gebruiker heeft gereageerd
2. Haal alle posts behorende bij de topic-id's op in delen van 32 topics, dit omdat Sphinx is ingesteld op max 10.000 resultaten
3. Loop over alle posts en voeg de bijbehorende topic-id's toe aan een array welke de unieke topic's per gebruiker gevat.
In theory there is no difference between theory and practice. In practice there is.
In $auteurId staat het id van de user welke de post heeft geplaatst, aangezien ik de posts van degene waar op wordt gezocht wil negeren (wat Maringo al aangaf) gebruik ik die vergelijking.quote:
[ code verwijderd ]
Hier vallen me een paar dingen op. Om te beginnen ben ik benieuwd wat er in $auteurId staat en waarom er een != wordt gebruikt voor die vergelijking. Verder heb je de isset()-check niet nodig. Je set de waarde op 1, en als die toevallig al geset was, verandert er niets. En je benadert (ook zonder isset()) $mData['attrs']['auteur_id'] meerdere keren. Niet fout, maar ik zou er een variabele van maken (en dat waarschijnlijk ook doen voor $mData['attrs']['topic_id']), al was het maar voor een betere leesbaarheid.
Die isset is idd niet nodig, dom dat ik me dat niet eerder had gerealiseerd aangezien ik heel goed weet dat het in dit geval geen effect op de resulterende array heeft. Ik haal deze sowieso weg.
De waarden in $mData['attrs']['auteur_id'] en $mData['attrs']['topic_id'] zet ik in een variable, zelfs al levert het maar weinig op ben ik al blij.
In ieder geval heel erg bedankt voor het meedenken.
Dank. Ik ga het ff aanpassen en checken of het winst oplevertquote:Op zaterdag 26 april 2014 10:36 schreef Maringo het volgende:
Mijn idee is om die eruit te halen en eventueel na de foreach loop die ene entry uit $users_topics ($users_topics[$auteurId]) te halen.
Geprobeerd, met de volgende query:quote:
[..]
Kan je deze logica niet veel beter in je SQL oplossen, dat lijkt me vele malen sneller dan het oplossen in PHP.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | SELECT COUNT(*), naam FROM ( SELECT fok_user.naam, `fok_post`.auteur FROM `fok_post` RIGHT JOIN ( SELECT DISTINCT topicid FROM `fok_post` WHERE `auteur` = 128465 AND `fok_post`.`tijdstip` BETWEEN UNIX_TIMESTAMP('2014-04-01 00:00:01') AND UNIX_TIMESTAMP('2014-04-26 23:59:59') AND `fok_post`.`year` = 2014 ) AS t ON (`fok_post`.topicid = t.topicid) JOIN fok_user ON `fok_post`.auteur = fok_user.id WHERE `fok_post`.auteur != 128465 GROUP BY `fok_post`.auteur, `fok_post`.topicid ) AS u GROUP BY auteur ORDER BY COUNT(*) DESC LIMIT 100 |
Helaas een stuk trager dan mijn PHP oplossing
[ Bericht 61% gewijzigd door bondage op 26-04-2014 16:11:06 ]
Ahja, je wilt een overzicht van vriendjes maken. Hoe moet ik dat zien? Een lijst van users die in dezelfde topics gepost hebben?quote:Op zaterdag 26 april 2014 16:03 schreef bondage het volgende:
[..]
In $auteurId staat het id van de user welke de post heeft geplaatst, aangezien ik de posts van degene waar op wordt gezocht wil negeren (wat Maringo al aangaf) gebruik ik die vergelijking.
Die isset is idd niet nodig, dom dat ik me dat niet eerder had gerealiseerd aangezien ik heel goed weet dat het in dit geval geen effect op de resulterende array heeft. Ik haal deze sowieso weg.
De waarden in $mData['attrs']['auteur_id'] en $mData['attrs']['topic_id'] zet ik in een variable, zelfs al levert het maar weinig op ben ik al blij.
In ieder geval heel erg bedankt voor het meedenken.
Klopt. Zo is dit mijn lijstje wat ie eens op verzoek maakte:quote:
[..]
Ahja, je wilt een overzicht van vriendjes maken. Hoe moet ik dat zien? Een lijst van users die in dezelfde topics gepost hebben?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | 142 Rezania 139 d4v1d 120 Amarantha 118 FL_Freak 118 Lt.Surge 103 SgtPorkbeans 96 LittleBrownie 96 Flippiee 95 gianni61 94 Fopje 91 BBQSausage 85 Bitterlemon 84 Snowbells 74 Roburtt 72 HeaN82 |
getallen zijn het aantal topics.
Exactquote:
[..]
Ahja, je wilt een overzicht van vriendjes maken. Hoe moet ik dat zien? Een lijst van users die in dezelfde topics gepost hebben?
Ik heb je query wat herschreven, zonder subqueries en right joins. Ongetest, uiteraard.quote:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 | SELECT count(DISTINCT friend_post.topic_id) cnt, u.naam FROM fok_user u INNER JOIN fok_post search_user_post ON search_user_post.auteur = 128465 AND search_user_post.tijdstip BETWEEN UNIX_TIMESTAMP('2014-01-01 00:00:01') AND UNIX_TIMESTAMP('2014-04-26 23:59:59') AND search_user_post.year = 2014 INNER JOIN fok_post friend_post ON friend_post.auteur = u.id AND friend_post.auteur != 128465 AND friend_post.topic_id = search_user_post.topic_id GROUP BY u.naam ORDER BY cnt DESC LIMIT 100; |
Oeh, ik ga hem ff testen.quote:
SELECT count(DISTINCT friend_post.topic_id) cnt, u.naam
FROM fok_user u
INNER JOIN fok_post search_user_post
ON search_user_post.auteur = 128465
AND search_user_post.tijdstip BETWEEN UNIX_TIMESTAMP('2014-01-01 00:00:01') AND UNIX_TIMESTAMP('2014-04-26 23:59:59')
AND search_user_post.year = 2014
INNER JOIN fok_post friend_post
ON friend_post.auteur = u.id
AND friend_post.auteur != 128465
AND friend_post.topic_id = search_user_post.topic_id
GROUP BY u.naam
ORDER BY cnt DESC
LIMIT 100;

Ik heb de twee query's getest met het volgende resultaat (uiteraard SQL_NO_CACHE toegevoegd):
Jouw query:
Weergave van records 100 - 99 ( 100 totaal, query duurde 0.8366 sec)
Mijn query:
Weergave van records 100 - 99 ( 100 totaal, query duurde 4.1594 sec)
Die van jou is een stuk sneller. Ik ga even testen over langere periodes. Als dit goed werkt kan ik dit beter gebruiken dan de PHP oplossing.
[ Bericht 7% gewijzigd door bondage op 26-04-2014 18:18:21 ]
Jouw query:
Weergave van records 100 - 99 ( 100 totaal, query duurde 0.8366 sec)
| 1 2 3 4 | id select_type table type possible_keys key key_len ref rows Extra 1 SIMPLE search_user_post ref topicid,tijdstip,auteur,year auteur 4 const 12009 Using where; Using temporary; Using filesort 1 SIMPLE friend_post ref topicid,auteur topicid 4 fokstats.search_user_post.topicid 100 Using where 1 SIMPLE u eq_ref PRIMARY PRIMARY 4 fokstats.friend_post.auteur 1 |
Mijn query:
Weergave van records 100 - 99 ( 100 totaal, query duurde 4.1594 sec)
| 1 2 3 4 5 6 | id select_type table type possible_keys key key_len ref rows Extra 1 PRIMARY <derived2> ALL NULL NULL NULL NULL 2919 Using temporary; Using filesort 2 DERIVED <derived3> ALL NULL NULL NULL NULL 110 Using temporary; Using filesort 2 DERIVED fok_post ref topicid,auteur topicid 4 t.topicid 100 Using where 2 DERIVED fok_user eq_ref PRIMARY PRIMARY 4 fokstats.fok_post.auteur 1 3 DERIVED fok_post ref tijdstip,auteur,year auteur 4 12008 Using where; Using temporary |
Die van jou is een stuk sneller. Ik ga even testen over langere periodes. Als dit goed werkt kan ik dit beter gebruiken dan de PHP oplossing.
[ Bericht 7% gewijzigd door bondage op 26-04-2014 18:18:21 ]
Is het niet sowieso handiger om zoveel mogelijk het ophalen van de juiste data door een database engine te laten doen ipv dat ik PHP na te gaan bootsen? De database engine zal hierin bijna altijd sneller zijn, tenzij je 10 subqueries ofzo gebruikt.
Stroek: Sitethief, die is heel groot en sterk :Y.
Faat: *zucht* zoals gewoonlijk hoor Sitethief weer in de bocht >:)
Faat: *zucht* zoals gewoonlijk hoor Sitethief weer in de bocht >:)
De rest van de stats worden gegenereerd door Sphinx, echter heeft Sphinx niet de mogelijkheid om op meerdere velden te groeperen. Als ik dit volledig in Sphinx zou kunnen doen zou het een stuk sneller gaan.quote:
Is het niet sowieso handiger om zoveel mogelijk het ophalen van de juiste data door een database engine te laten doen ipv dat ik PHP na te gaan bootsen? De database engine zal hierin bijna altijd sneller zijn, tenzij je 10 subqueries ofzo gebruikt.
Maar ik realiseer me nu dat ik dit beter op kan lossen dmv een query ipv de data door php te laten verwerken.
Een andere optie is een betere server aanschaffen, daar heb ik echter op dit moment geen geld voor
Voer je die query uit op een 'eigen' server? Als in een database-server die je zelf beheert en waar je indexen kunt aanpassen? Dan moet er nog wel wat snelheidswinst te behalen zijn.quote:
[..]
De rest van de stats worden gegenereerd door Sphinx, echter heeft Sphinx niet de mogelijkheid om op meerdere velden te groeperen. Als ik dit volledig in Sphinx zou kunnen doen zou het een stuk sneller gaan.
Maar ik realiseer me nu dat ik dit beter op kan lossen dmv een query ipv de data door php te laten verwerken.
Een andere optie is een betere server aanschaffen, daar heb ik echter op dit moment geen geld voor
Jup, is mijn eigen server. Dit zijn de velden en indexen die ik momenteel heb:quote:
[..]
Voer je die query uit op een 'eigen' server? Als in een database-server die je zelf beheert en waar je indexen kunt aanpassen? Dan moet er nog wel wat snelheidswinst te behalen zijn.
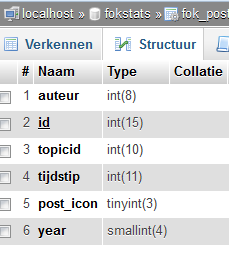
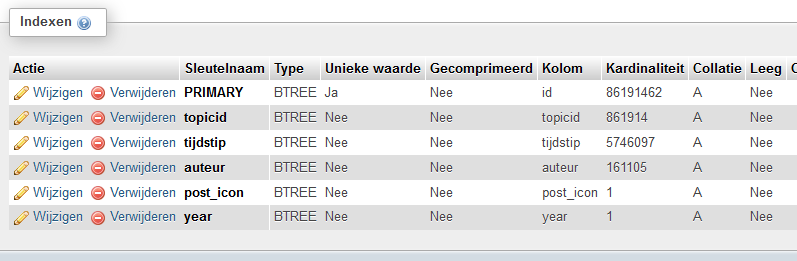
Hmm... year heeft een kardinaliteit van 1. Heb je alleen posts uit 2014 in de database staan?quote:
[..]
Jup, is mijn eigen server. Dit zijn de velden en indexen die ik momenteel heb:
[ afbeelding ]
[ afbeelding ]
Dat viel mij ook al op idd. Er staat 6 jaar aan data in die tabel.quote:
[..]
Hmm... year heeft een kardinaliteit van 1. Heb je alleen posts uit 2014 in de database staan?
Is het overigens erg dat id een int(15) is? Ik heb deze database ooit van iemand overgenomen en hier niet bij stilgestaan, ik weet echter dat een gewone int niet tot 15 gaat.
Mooiquote:
[..]
Dat viel mij ook al op idd. Er staat 6 jaar aan data in die tabel.
(Je zou ook nog in plaats van "year" de kolom "tijdstip" kunnen toevoegen, maar ik vermoed dat het verschil vrij klein is terwijl de index veel groter kan worden.)
Nee, dat getal maakt alleen uit als je zerofill gebruikt. En dat wil je niet (want voorloopnullen toevoegen hoort de database niet te doen).quote:Is het overigens erg dat id een int(15) is? Ik heb deze database ooit van iemand overgenomen en hier niet bij stilgestaan, ik weet echter dat een gewone int niet tot 15 gaat.
Dank, ik ga die twee indices even combineren en de query dan nogmaals testen. Ik gebruik geen zerofill dus dat is dan geen probleem gelukkig.quote:
[..]
MooiDan zou ik de index "auteur" wijzigen en er "year" als tweede kolom aan toevoegen. Een index mag namelijk meer dan 1 kolom bevatten
(Je zou ook nog in plaats van "year" de kolom "tijdstip" kunnen toevoegen, maar ik vermoed dat het verschil vrij klein is terwijl de index veel groter kan worden.)
[..]
Nee, dat getal maakt alleen uit als je zerofill gebruikt. En dat wil je niet (want voorloopnullen toevoegen hoort de database niet te doen).
Wat is eigenlijk het voordeel van het combineren van die twee?