SES School, Studie en Onderwijs
Wiskunde in de brugklas, Frans voor het examen of een studie Personeel en Arbeid? Moeilijke formulieren van DUO? Iets weten over studiefinanciering of studentenverenigingen? Dit is het forum voor leerkrachten, scholieren en studenten, van brugklas tot uni




Ik zal kort uitleggen hoe ik het heb gedaan. In mijn enquete heb ik gevraagd naar de 'hoogst genoten opleiding'. Men kon kiezen uit Lagere school, VMBO, MBO, HAVO, VWO, HBO & WO. Aan de hand van mijn theorie kon ik dit reduceren naar laagopgeleid, middelbaar opgeleid en hoogopgeleid. Zodoende kreeg ik een nieuwe variabele onderverdeeld in 3 categorieën. Wat mijn begeleider zei is dat ik naast de eerdere toets die ik had uitgevoerd ook nog een ANOVA kon doen om meer uit mijn data te halen. Daar ben ik nu dus mee bezig. Door middel van een Post-Hoc test kan ik dan ook zien welke groepen van elkaar verschillen, alleen doordat middelbaar opgeleid uit 'maar' 18 mensen bestaat weet ik niet zeker of dit wel mag.quote:Op dinsdag 19 januari 2016 12:28 schreef Zith het volgende:
In studies zie ik eigenlijk altijd het aantal studiejaren staan, niet een BSc/MSc.. kan je niet het volgende doen om een enkele variabele te creeren?
VMBO: 4 (jaar)
MBO: 7 (VMBO+3)
HAVO: 5
HBO: 9 (HAVO+4)
VWO: 6
WO: 10 (VWO + 4)
Ik ben sowieso niet dol op SPSS inderdaad, maar het punt is ook dat ik voor mijn these afgezien van factoranalyse en IRT waarschijnlijk veel ga hebben aan zelfgeschreven control structures en functies, bovenop het feit dat een bepaalde analysemethode die ik moet gebruiken een R package is die geschreven is door mijn begeleider. Voor mijn scriptie heb ik sowieso functionaliteit van R nodig die SPSS niet biedt. Plus uitdaging natuurlijk.quote:Op dinsdag 19 januari 2016 12:37 schreef MCH het volgende:
Ik had volgens mij al gelezen dat je niet dol bent op SPSS maar Factoranalyse kun je toch heel makkelijk uitvoeren met dat programma?
(en ik vind stiekem dat R sowieso de betere keuze is omdat het de gebruiker dwingt te begrijpen wat er nu precies gebeurt)
Your opinion of me is none of my business.
Nog even naar jou: als je opleidingsniveau gesplitst hebt in drie dichotome variabelen is dat een beetje omslachtig, als je ze dummy codeert, houd je maar twee variabelen over. Dat is netter. (ik kan adhv wat je vertelt niet goed achterhalen hoe je die nu precies gecodeerd hebt) Je groepen zijn idioot scheef, dus de kans dat je een betrouwbaar significant resultaat vindt lijken me sowieso al klein. Of het mag of niet, tja. Heel eerlijk gezegd is het voor jou niet zo van belang of het 'mag' of niet. Als je nu een wetenschappelijk onderzoek met beurzen en publicaties zou uitvoeren, ja, dan moet je je daar wel echt even mee bezig houden. Maar jij schrijft een scriptie en dat betekent eigenlijk dat je begeleider bepaalt wat 'mag' en niet. Als hij zegt: doe een ANOVA, dan doe jij een ANOVA. Noem er dan wel even duidelijk bij in je methodesectie van je verslag dat de data eigenlijk hier en daar wat tegenwerpingen bevat (welke en waar en welk effect dat wellicht gaat hebben op je resultaten), maar dat je toch hebt gekozen de analyse uit te voeren. Ook in je discussie dan even naar terugkoppelen.quote:
[..]
Ik zal kort uitleggen hoe ik het heb gedaan. In mijn enquete heb ik gevraagd naar de 'hoogst genoten opleiding'. Men kon kiezen uit Lagere school, VMBO, MBO, HAVO, VWO, HBO & WO. Aan de hand van mijn theorie kon ik dit reduceren naar laagopgeleid, middelbaar opgeleid en hoogopgeleid. Zodoende kreeg ik een nieuwe variabele onderverdeeld in 3 categorieën. Wat mijn begeleider zei is dat ik naast de eerdere toets die ik had uitgevoerd ook nog een ANOVA kon doen om meer uit mijn data te halen. Daar ben ik nu dus mee bezig. Door middel van een Post-Hoc test kan ik dan ook zien welke groepen van elkaar verschillen, alleen doordat middelbaar opgeleid uit 'maar' 18 mensen bestaat weet ik niet zeker of dit wel mag.
Your opinion of me is none of my business.
fetX: heb je al gekeken naar effect-coding van je opleidingsvariabele? Kan soms problemen oplossen die je met dummy-coding hebt.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Is het mogelijk om in SPSS missing values te vervangen door gemiddelde scores berekend over een bepaalde selectie?
Ik weet dat er een optie is om missing values te vervangen door het gemiddelde van een hele variabele, maar ik wil dat die bij cases A, B en C een andere selectie maakt waar die het gemiddelde van berekent dan bij cases X,Y en Z. Die selectie is dan gebaseerd op een bepaalde variabele (type_case) in de dataset.
Beetje ingewikkeld uitgelegd misschien, maar dat dus!
Ik weet dat er een optie is om missing values te vervangen door het gemiddelde van een hele variabele, maar ik wil dat die bij cases A, B en C een andere selectie maakt waar die het gemiddelde van berekent dan bij cases X,Y en Z. Die selectie is dan gebaseerd op een bepaalde variabele (type_case) in de dataset.
Beetje ingewikkeld uitgelegd misschien, maar dat dus!
"On a good day, when I run, the voices in my head get quieter until it’s just me, my breath and my feet on the sand (Dexter, E5x09)."

In R zo gepiept. Ik heb nu geen beschikking over SPSS maar het zou wel moeten kunnen in een syntax. Kan je niet eerst de geagregeerde gemiddelden uitrekenen in een aparte variabele en die waarden dan onder voorwaarde imputeren? Per rij krijgt iedereen dan eerst in een aparte variabele die je dan onder voorwaarde imputeert.
Aldus.
Omg dit is het! Ik ga even klooien. Thanks voor het in de goede richting duwen!quote:Op donderdag 21 januari 2016 16:30 schreef Z het volgende:
In R zo gepiept. Ik heb nu geen beschikking over SPSS maar het zou wel moeten kunnen in een syntax. Kan je niet eerst de geagregeerde gemiddelden uitrekenen in een aparte variabele en die waarden dan onder voorwaarde imputeren? Per rij krijgt iedereen dan eerst in een aparte variabele die je dan onder voorwaarde imputeert.
"On a good day, when I run, the voices in my head get quieter until it’s just me, my breath and my feet on the sand (Dexter, E5x09)."

Goedemorgen 
Ik heb twee datasets, beide van een ander jaar. In de sets zitten gegevens van ondernemingen in 8 landen. In mijn onderzoek kijk ik naar de verklarende kracht van het model, de adjusted R2. De verwachting is dat de adj R2 in het tweede jaar hoger is dan in het eerste jaar. Het resultaat voldoet (totaal) niet aan verwachting: het eerste jaar is de uitkomst 0,662 en het tweede jaar 0,388 . Om te onderzoeken waardoor dit ontstaat, heb ik de lineaire regressie gedraaid voor alle afzonderlijke landen (1 t/m 8), per jaar. Dat geeft het volgende beeld:
. Om te onderzoeken waardoor dit ontstaat, heb ik de lineaire regressie gedraaid voor alle afzonderlijke landen (1 t/m 8), per jaar. Dat geeft het volgende beeld:
Ik weet niet welke stappen ik nu moet zetten. Als ik er zo naar kijk, dan lijkt het alsof beide jaren hetzelfde beeld laten zien. Maar als ik de regressie draai voor de gehele dataset ineens, komt het tweede jaar een stuk lager uit ... Dat vind ik erg raar. Maar misschien wel te verklaren? Twee jaar geleden heb ik wel een cursus statistiek gehad op de opleiding maar dit soort dingen zijn we daar niet tegengekomen en de kennis is helaas ook al behoorlijk weggezakt....
Ik heb twee datasets, beide van een ander jaar. In de sets zitten gegevens van ondernemingen in 8 landen. In mijn onderzoek kijk ik naar de verklarende kracht van het model, de adjusted R2. De verwachting is dat de adj R2 in het tweede jaar hoger is dan in het eerste jaar. Het resultaat voldoet (totaal) niet aan verwachting: het eerste jaar is de uitkomst 0,662 en het tweede jaar 0,388
| 1 2 3 4 5 6 7 8 | 1 - 0,647 0,839 2 - 0,484 0,378 3 - 0,887 0,903 4 - 0,835 0,934 5 - 0,592 0,538 6 - 0,940 0,700 7 - 0,892 0,766 8 - 0,931 0,931 |
Ik weet niet welke stappen ik nu moet zetten. Als ik er zo naar kijk, dan lijkt het alsof beide jaren hetzelfde beeld laten zien. Maar als ik de regressie draai voor de gehele dataset ineens, komt het tweede jaar een stuk lager uit ... Dat vind ik erg raar. Maar misschien wel te verklaren? Twee jaar geleden heb ik wel een cursus statistiek gehad op de opleiding maar dit soort dingen zijn we daar niet tegengekomen en de kennis is helaas ook al behoorlijk weggezakt....
Waarom zou je verwachten dan in een tweede jaar de verklaarde variantie groter zou zijn? Verschillen de scores op de variabelen in het model misschien veel per land? Is de r2 in dit geval wel een goede parameter om het model op te beoordelen? Ik droom vooral over modellen met een r2 van 0,66, maar dat terzijde.
Aldus.
Er is in dat jaar een wezenlijke verandering doorgevoerd.
Maar door mijn vraag te stellen en het er met mijn vriend over te hebben, die niks weet van mijn vakgebied maar wel fijn logisch kan redeneren etc, denk ik dat ik weet wat er gebeurt. Cijfermatig vat ik het nog niet maar meer dan een derde van mijn dataset bestaat uit 1 land en in dat land is de r2 gedaald (#2 in het overzicht). Dit heeft een grote invloed op het totaalbeeld.
Overigens heeft deze methode zich in de literatuur uitgebreid bewezen, het ligt niet aan het model maar aan mij(n input). Dat is zeker
Ik droom hier niet over maar ik heb zo'n beetje nachtmerries geloof wel dat ik eerst weer verder kan.
geloof wel dat ik eerst weer verder kan.
Maar door mijn vraag te stellen en het er met mijn vriend over te hebben, die niks weet van mijn vakgebied maar wel fijn logisch kan redeneren etc, denk ik dat ik weet wat er gebeurt. Cijfermatig vat ik het nog niet maar meer dan een derde van mijn dataset bestaat uit 1 land en in dat land is de r2 gedaald (#2 in het overzicht). Dit heeft een grote invloed op het totaalbeeld.
Overigens heeft deze methode zich in de literatuur uitgebreid bewezen, het ligt niet aan het model maar aan mij(n input). Dat is zeker
Ik droom hier niet over maar ik heb zo'n beetje nachtmerries
Ervan uitgaande dat je dataset groot genoeg is kun je een factoranalyse uitvoeren, of een PCA, om te zien of je geen echte multivariate afhankelijke variabele hebt. Het kan zijn dat land * jaar een heel goed fittend model geeft.quote:Op zaterdag 30 januari 2016 10:26 schreef Serinde het volgende:
Goedemorgen
Ik heb twee datasets, beide van een ander jaar. In de sets zitten gegevens van ondernemingen in 8 landen. In mijn onderzoek kijk ik naar de verklarende kracht van het model, de adjusted R2. De verwachting is dat de adj R2 in het tweede jaar hoger is dan in het eerste jaar. Het resultaat voldoet (totaal) niet aan verwachting: het eerste jaar is de uitkomst 0,662 en het tweede jaar 0,388
[ code verwijderd ]
Ik weet niet welke stappen ik nu moet zetten. Als ik er zo naar kijk, dan lijkt het alsof beide jaren hetzelfde beeld laten zien. Maar als ik de regressie draai voor de gehele dataset ineens, komt het tweede jaar een stuk lager uit ... Dat vind ik erg raar. Maar misschien wel te verklaren? Twee jaar geleden heb ik wel een cursus statistiek gehad op de opleiding maar dit soort dingen zijn we daar niet tegengekomen en de kennis is helaas ook al behoorlijk weggezakt....
Overigens kun je met multiple regressie je model ook maken, krijg je ook r-kwadraten en de ANOVA laat dan zien welke factor significant zijn om je model te fitten. Moet je wel wat kwaliteitschecks doen, maar dat voert te ver op maandagavond...
http://onlinestatbook.com/2/regression/multiple_regression.html
Whatever...
Het is logsich dat je grootste land een grote invloed heeft op de total r2. Maar belangrijk is ook of er per land een apart patroon is. Vooral landen waar het effect tegengesteld is aan anderen geeft een slechter model. Een grote variatie in effectsize ook.quote:Op maandag 1 februari 2016 21:05 schreef Serinde het volgende:
Er is in dat jaar een wezenlijke verandering doorgevoerd.
Maar door mijn vraag te stellen en het er met mijn vriend over te hebben, die niks weet van mijn vakgebied maar wel fijn logisch kan redeneren etc, denk ik dat ik weet wat er gebeurt. Cijfermatig vat ik het nog niet maar meer dan een derde van mijn dataset bestaat uit 1 land en in dat land is de r2 gedaald (#2 in het overzicht). Dit heeft een grote invloed op het totaalbeeld.
Overigens heeft deze methode zich in de literatuur uitgebreid bewezen, het ligt niet aan het model maar aan mij(n input). Dat is zeker
Ik droom hier niet over maar ik heb zo'n beetje nachtmerries
Heb je nog andere factoren behalve 2 inputvariabelen en 1 output?
Zoals eerder gezegd moet je eigenlijk met wat multivariate methoden de dataset even bekijken om te zien of er onderliggende factoren zijn.
Whatever...
Je hebt data van meerdere landen, over 2 jaar, waarvan er in 1 een beleidsverandering is doorgevoerd?quote:
Er is in dat jaar een wezenlijke verandering doorgevoerd.
Maar door mijn vraag te stellen en het er met mijn vriend over te hebben, die niks weet van mijn vakgebied maar wel fijn logisch kan redeneren etc, denk ik dat ik weet wat er gebeurt. Cijfermatig vat ik het nog niet maar meer dan een derde van mijn dataset bestaat uit 1 land en in dat land is de r2 gedaald (#2 in het overzicht). Dit heeft een grote invloed op het totaalbeeld.
Overigens heeft deze methode zich in de literatuur uitgebreid bewezen, het ligt niet aan het model maar aan mij(n input). Dat is zeker
Ik droom hier niet over maar ik heb zo'n beetje nachtmerries
Zo ja dan kan je een difference-in-differences regressie doen. Wat in principe niet meer inhoudt dan twee dummies toevoegen:
Dummy 1: land-met-verandering: 1 en land(en)-zonder-verandering: 0.
Dummy 2: Periode voor verandering: 0, Periode na verandering: 1
En een interactie maken (dummy1 * dummy2).
Regressie: Y = b0 + b1*Dummy1 + b2*Dummy2 + b3*Interactie + bk*(de andere variablen die belangrijk kunnen zijn)
Je wilt dan dat b3 (de interactie) significant is. Als deze significant is dan kan je stellen dat de beleidswijziging positief/negatief effect heeft gehad.
Zet je data hiervoor zo in elkaar

.......Maar een analyse van 8 observaties over 2 jaar is wel erg summier....
[ Bericht 5% gewijzigd door Zith op 01-02-2016 22:12:50 ]
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Bedankt voor jullie opmerkingen! Ik ga de suggesties nakijken (met het boek van Field erbij  )
)
Ik had wat weinig informatie gegeven, ik heb 2 onafhankelijke variabelen met meetschaal ratio, een dummy voor het rechtssysteem in een land (0 of 1) en een dummy voor het land (1 tm 8, om ook per land iets te kunnen zeggen, al zijn voor sommige landen de waarnemingen beperkt). In alle landen heeft dezelfde wijziging plaatsgevonden, het effect wordt in alle landen positief verwacht, alleen het zal sterker zijn afhankelijk van het rechtssysteem.
Ik zie dat ook mijn begeleidster mijn mail beantwoord heeft. Ik heb eerst voldoende input om de komende dagen door te komen.
Toevoeging: ik heb ongeveer 750 cases per jaar.
De difference in difference komt me bekend voor uit een van de colleges van anderhalf jaar geleden.... Als ik die toepas (indien mogelijk, ik moet zoals gezegd e.e.a. uitzoeken) dan moet ik ook mijn eerste drie hoofdstukken aan gaan passen. Daar zit ik niet op te wachten. Maar wellicht een goede aanvulling en/of als robustnesscheck?! Ik zoek mijn bed op en ga morgen aan de slag. Nogmaals dank voor zover
Ik had wat weinig informatie gegeven, ik heb 2 onafhankelijke variabelen met meetschaal ratio, een dummy voor het rechtssysteem in een land (0 of 1) en een dummy voor het land (1 tm 8, om ook per land iets te kunnen zeggen, al zijn voor sommige landen de waarnemingen beperkt). In alle landen heeft dezelfde wijziging plaatsgevonden, het effect wordt in alle landen positief verwacht, alleen het zal sterker zijn afhankelijk van het rechtssysteem.
Ik zie dat ook mijn begeleidster mijn mail beantwoord heeft. Ik heb eerst voldoende input om de komende dagen door te komen.
Toevoeging: ik heb ongeveer 750 cases per jaar.
De difference in difference komt me bekend voor uit een van de colleges van anderhalf jaar geleden.... Als ik die toepas (indien mogelijk, ik moet zoals gezegd e.e.a. uitzoeken) dan moet ik ook mijn eerste drie hoofdstukken aan gaan passen. Daar zit ik niet op te wachten. Maar wellicht een goede aanvulling en/of als robustnesscheck?! Ik zoek mijn bed op en ga morgen aan de slag. Nogmaals dank voor zover
Als je 8 landen hebt moet je wel 1 land als ref. categorie gebruiken, dus 7 dummies.quote:
Bedankt voor jullie opmerkingen! Ik ga de suggesties nakijken (met het boek van Field erbij
Ik had wat weinig informatie gegeven, ik heb 2 onafhankelijke variabelen met meetschaal ratio, een dummy voor het rechtssysteem in een land (0 of 1) en een dummy voor het land (1 tm 8, om ook per land iets te kunnen zeggen, al zijn voor sommige landen de waarnemingen beperkt). In alle landen heeft dezelfde wijziging plaatsgevonden, het effect wordt in alle landen positief verwacht, alleen het zal sterker zijn afhankelijk van het rechtssysteem.
Ik zie dat ook mijn begeleidster mijn mail beantwoord heeft. Ik heb eerst voldoende input om de komende dagen door te komen.
Toevoeging: ik heb ongeveer 750 cases per jaar.
De difference in difference komt me bekend voor uit een van de colleges van anderhalf jaar geleden.... Als ik die toepas (indien mogelijk, ik moet zoals gezegd e.e.a. uitzoeken) dan moet ik ook mijn eerste drie hoofdstukken aan gaan passen. Daar zit ik niet op te wachten. Maar wellicht een goede aanvulling en/of als robustnesscheck?! Ik zoek mijn bed op en ga morgen aan de slag. Nogmaals dank voor zover
Dan mis je dus ook nog een interactie (moderator) variabele in je regressiemodel!quote:
Bedankt voor jullie opmerkingen! Ik ga de suggesties nakijken (met het boek van Field erbij
alleen het zal sterker zijn afhankelijk van het rechtssysteem.
Vanaf de mobiel...
Als in alle landen in dezelfde periode dezelfde beleidsverandering heeft plaatsgevonden dan zal diff in diffs die ik voorstelde niet werken: de interactie periode en treatment (beleidsverandering) is dan 1 in alle periode 2 observaties.
Wat je wel kan doen is dummy rechtssysteem en dummy beleidsverandering (jaar 2) beiden in de regressie en een interactie rechtssysteem*beleidsverandering. Dat, plus je andere onafhankelijke variabelen.
In principe kan je alleen zo zien welk rechtssysteem in het nieuwe beleid het beste werkt (even alle nuances en kwaliteitscontroles achter wegen latend)... Nogmaals wil je weten of de interactie significant is en of de coefficient positief of negatief is.
Bedenk ook dat een hoger R2 niet aangeeft of iets beter is, het geeft alleen aan wat de voorspellende waarde van je model is. Als ik een model maak met dummy : eet snoep / eet geen snoep, en de Dependent is of er gaatjes in de tanden ontstaan en de R2 is 0.8... Is snoep eten dan goed of slecht? Het voorspelt alleen - basic uitgelegd - dat het effect op je tanden voor 80% uitgelegd kan worden door wel of geen snoep te eten (maar niet of het eten van snoep goed of slecht is).
Om te kijken welk rechtssysteem beter is zul je moeten kijken naar de p waarde en of de coefficient positief of negatief is.
Als in alle landen in dezelfde periode dezelfde beleidsverandering heeft plaatsgevonden dan zal diff in diffs die ik voorstelde niet werken: de interactie periode en treatment (beleidsverandering) is dan 1 in alle periode 2 observaties.
Wat je wel kan doen is dummy rechtssysteem en dummy beleidsverandering (jaar 2) beiden in de regressie en een interactie rechtssysteem*beleidsverandering. Dat, plus je andere onafhankelijke variabelen.
In principe kan je alleen zo zien welk rechtssysteem in het nieuwe beleid het beste werkt (even alle nuances en kwaliteitscontroles achter wegen latend)... Nogmaals wil je weten of de interactie significant is en of de coefficient positief of negatief is.
Bedenk ook dat een hoger R2 niet aangeeft of iets beter is, het geeft alleen aan wat de voorspellende waarde van je model is. Als ik een model maak met dummy : eet snoep / eet geen snoep, en de Dependent is of er gaatjes in de tanden ontstaan en de R2 is 0.8... Is snoep eten dan goed of slecht? Het voorspelt alleen - basic uitgelegd - dat het effect op je tanden voor 80% uitgelegd kan worden door wel of geen snoep te eten (maar niet of het eten van snoep goed of slecht is).
Om te kijken welk rechtssysteem beter is zul je moeten kijken naar de p waarde en of de coefficient positief of negatief is.
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Zijn er statistische pakketen die niet automatisch 1 van de dummies omit?quote:
[..]
Als je 8 landen hebt moet je wel 1 land als ref. categorie gebruiken, dus 7 dummies.
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Ik geloof dat SPSS dit niet doet want je moet sowieso handmatig die dummies toevoegen aan je dataset. Daarnaast moet Serinde dmv een Chow-Test eerst checken of ze de data van alle landen uberhaupt wel op 1 hoop mag gooien (poolen).quote:
[..]
Zijn er statistische pakketen die niet automatisch 1 van de dummies omit?
quote:the Chow test is often used to determine whether the independent variables have different impacts on different subgroups of the population.
[ Bericht 10% gewijzigd door #ANONIEM op 02-02-2016 00:38:36 ]
Welke test zou ik moeten uitvoeren om de percentages van 2 groepen op een categorische variabele (wel/niet financiële druk) te toetsen op een significant verschil?
En kan ik dezelfde toets vervolgens gebruiken om de groepen wel/niet financiële druk te testen op positieve/negatieve beleving van beleid?
En hoe voer ik dit uit in SPSS?
En kan ik dezelfde toets vervolgens gebruiken om de groepen wel/niet financiële druk te testen op positieve/negatieve beleving van beleid?
En hoe voer ik dit uit in SPSS?
Chi-square:quote:
Welke test zou ik moeten uitvoeren om de percentages van 2 groepen op een categorische variabele (wel/niet financiële druk) te toetsen op een significant verschil?
En kan ik dezelfde toets vervolgens gebruiken om de groepen wel/niet financiële druk te testen op positieve/negatieve beleving van beleid?
En hoe voer ik dit uit in SPSS?
CROSSTABS
/TABLES=var1 BY var2
/FORMAT=AVALUE TABLES
/STATISTICS=CHISQ
/CELLS=COUNT ROW
/COUNT ROUND CELL
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Hoera jongens en meisjes ik doe gezellig even mee!
Bezig met het verwerken van de vragenlijsten voor mijn afstudeerscriptie, nu is het zo dat ik nogal wat meerkeuzevragen heb die ik wil confronteren met vragen waarbij 1 antwoord mogelijk is.
Bijvoorbeeld:
(Meerkeuzevraag) In wat voor type organisatie bent u werkzaam?
- Optie 1
- Optie 2
- etc.
Confronteren met
(1 antwoord mogelijk) Is er binnen uw organisatie een inkoopafdeling aanwezig?
- Ja
- Nee
--------------------------------------------------------------------------------------------------------------
Ik zoek mij momenteel vrij scheel op het internet en tussen de opties, bij multiple response analyses kan ik wel multiple respons vragen met elkaar confronteren, maar niet met een vraag waar een antwoord mogelijk is.
Wanneer ik een grafiek wil maken, dan lukt dit ook niet met de multiple respons vraag. Heb de variabelen zo ingedeeld dat wanneer 1 is ingegeven in data view het antwoord aangevinkt is en 0 betekent dat het antwoord niet aangevinkt is.
Logischerwijs zou ik zeggen dat het mogelijk zou moeten zijn om alle 1'tjes (vinkjes) in een pie chart te zetten, ik kom hier echter niet helemaal uit.
Bezig met het verwerken van de vragenlijsten voor mijn afstudeerscriptie, nu is het zo dat ik nogal wat meerkeuzevragen heb die ik wil confronteren met vragen waarbij 1 antwoord mogelijk is.
Bijvoorbeeld:
(Meerkeuzevraag) In wat voor type organisatie bent u werkzaam?
- Optie 1
- Optie 2
- etc.
Confronteren met
(1 antwoord mogelijk) Is er binnen uw organisatie een inkoopafdeling aanwezig?
- Ja
- Nee
--------------------------------------------------------------------------------------------------------------
Ik zoek mij momenteel vrij scheel op het internet en tussen de opties, bij multiple response analyses kan ik wel multiple respons vragen met elkaar confronteren, maar niet met een vraag waar een antwoord mogelijk is.
Wanneer ik een grafiek wil maken, dan lukt dit ook niet met de multiple respons vraag. Heb de variabelen zo ingedeeld dat wanneer 1 is ingegeven in data view het antwoord aangevinkt is en 0 betekent dat het antwoord niet aangevinkt is.
Logischerwijs zou ik zeggen dat het mogelijk zou moeten zijn om alle 1'tjes (vinkjes) in een pie chart te zetten, ik kom hier echter niet helemaal uit.
"Victoria Concordia Crescit"
Ik ben niet zo scherp vandaag, maar wat bedoel je precies met confronteren?quote:
Hoera jongens en meisjes ik doe gezellig even mee!
Bezig met het verwerken van de vragenlijsten voor mijn afstudeerscriptie, nu is het zo dat ik nogal wat meerkeuzevragen heb die ik wil confronteren met vragen waarbij 1 antwoord mogelijk is.
Bijvoorbeeld:
(Meerkeuzevraag) In wat voor type organisatie bent u werkzaam?
- Optie 1
- Optie 2
- etc.
Confronteren met
(1 antwoord mogelijk) Is er binnen uw organisatie een inkoopafdeling aanwezig?
- Ja
- Nee
--------------------------------------------------------------------------------------------------------------
Ik zoek mij momenteel vrij scheel op het internet en tussen de opties, bij multiple response analyses kan ik wel multiple respons vragen met elkaar confronteren, maar niet met een vraag waar een antwoord mogelijk is.
Wanneer ik een grafiek wil maken, dan lukt dit ook niet met de multiple respons vraag. Heb de variabelen zo ingedeeld dat wanneer 1 is ingegeven in data view het antwoord aangevinkt is en 0 betekent dat het antwoord niet aangevinkt is.
Logischerwijs zou ik zeggen dat het mogelijk zou moeten zijn om alle 1'tjes (vinkjes) in een pie chart te zetten, ik kom hier echter niet helemaal uit.
De antwoorden op vraag twee vergelijken met 1 keuzemogelijkheid van vraag 1. Bijvoorbeeld:quote:
[..]
Ik ben niet zo scherp vandaag, maar wat bedoel je precies met confronteren?
Het antwoord op vraag 1 is = Huisartsenpraktijk
Het antwoord op vraag 2 is = Nee
Nu is het zo dat vraag 1 een multiple response vraag is, terwijl vraag 2 dit niet is.
"Victoria Concordia Crescit"
Oh wacht, de data moet anders worden gestructureerd voor mijn oplossing. Nu heeft elke optie een ja/nee antwoord in plaats van dat er één variabele is waar elke optie zijn eigen waarde heeft. Dus, hercoderen naar een enkele variabele en daarna de chi-square doen.
Linkje voor het hercoderen:
http://www.spsslog.com/2007/04/10/combine-two-variables-into-one/
Linkje voor het hercoderen:
http://www.spsslog.com/2007/04/10/combine-two-variables-into-one/

Hoe modelleer ik dit?quote:Are people that have a characteristic A, more likely to do X when X has the condition Y .
A = ofwel continuous ofwel verdeelt in 2 groepen (groep met mensen die veel A hebben en groep met mensen die weinig A hebben)
X = ja/nee (wel/niet) e.g. likelihood dat hij wel X
Y = conditie dat ook weer continuous kan zijn (undervalued --> overvalued) ofwel een vaste conditie (overvalued)
maw andere modellen vinden een positief effect van A op X. Ik wil kijken of dit effect er ook is als X de conditie Y heeft.
Oké, sorry als ik een stomme vraag stel, maar ik ben nog maar een paar weken bezig in SPSS. 
Ben nu bezig met een opdracht voor studie. We hebben een vooraf aangeleverde dataset.
Hiervan heb ik net sales over boekjaar 2014 als te verklaren variabele.
Vooraf wil ik dus kijken of deze normaal is verdeeld. Nee dus, ook niet als Ln-functie.
Maar in de boxplot zie ik 3 uitschieters, ook vanuit de dataset lijken deze vreemd (bijvoorbeeld opmerkelijk hoge omzet i.v.m. aantal medewerkers).
Als ik de net sales van die drie uitschieters uit mijn dataset verwijder, is de Ln-functie normaal verdeeld (volgens de Kolomogorov-Smirnov methode).
Maar, kan ik nu zomaar die uitschieters verwijderen? Wanneer ik dan toelicht in m'n paper waarom ik dit heb gedaan.
Voor deze uitschieters: als ik ze verwijderd, moet dan de gehele waarneming of enkel de net sales? Mijn gevoel zegt de gehele waarneming, want anders heb ik wel gegevens in een waarneming zitten maar geen te verklaren variabele.
Ben nu bezig met een opdracht voor studie. We hebben een vooraf aangeleverde dataset.
Hiervan heb ik net sales over boekjaar 2014 als te verklaren variabele.
Vooraf wil ik dus kijken of deze normaal is verdeeld. Nee dus, ook niet als Ln-functie.
Maar in de boxplot zie ik 3 uitschieters, ook vanuit de dataset lijken deze vreemd (bijvoorbeeld opmerkelijk hoge omzet i.v.m. aantal medewerkers).
Als ik de net sales van die drie uitschieters uit mijn dataset verwijder, is de Ln-functie normaal verdeeld (volgens de Kolomogorov-Smirnov methode).
Maar, kan ik nu zomaar die uitschieters verwijderen? Wanneer ik dan toelicht in m'n paper waarom ik dit heb gedaan.
Voor deze uitschieters: als ik ze verwijderd, moet dan de gehele waarneming of enkel de net sales? Mijn gevoel zegt de gehele waarneming, want anders heb ik wel gegevens in een waarneming zitten maar geen te verklaren variabele.
Please consider the environment before printing this post.
Op zaterdag 27 mei 2017 00:36 schreef d4v1d het volgende:
Kabuf is af en toe best een prima kerel.
Op zaterdag 27 mei 2017 00:36 schreef d4v1d het volgende:
Kabuf is af en toe best een prima kerel.
Er zijn verschillende methodes om outliers te quantificeren. Eigenlijk zou je wel van te voren moeten plannen wat je doet, aangezien je nu gaat "vissen" wat je foutmarge kan beinvloeden.quote:
Oké, sorry als ik een stomme vraag stel, maar ik ben nog maar een paar weken bezig in SPSS.
Ben nu bezig met een opdracht voor studie. We hebben een vooraf aangeleverde dataset.
Hiervan heb ik net sales over boekjaar 2014 als te verklaren variabele.
Vooraf wil ik dus kijken of deze normaal is verdeeld. Nee dus, ook niet als Ln-functie.
Maar in de boxplot zie ik 3 uitschieters, ook vanuit de dataset lijken deze vreemd (bijvoorbeeld opmerkelijk hoge omzet i.v.m. aantal medewerkers).
Als ik de net sales van die drie uitschieters uit mijn dataset verwijder, is de Ln-functie normaal verdeeld (volgens de Kolomogorov-Smirnov methode).
Maar, kan ik nu zomaar die uitschieters verwijderen? Wanneer ik dan toelicht in m'n paper waarom ik dit heb gedaan.
Voor deze uitschieters: als ik ze verwijderd, moet dan de gehele waarneming of enkel de net sales? Mijn gevoel zegt de gehele waarneming, want anders heb ik wel gegevens in een waarneming zitten maar geen te verklaren variabele.
De meest standaard versies zijn om te bepalden dat je datapunten verwijdert die, x sd van de mean van de groep afliggen (bijvoorbeeld 3 sd), in een lineare regressie die een cooks distance van meer dan x hebben, of je data te trimmen door bv de hoogste en laagste x percent te droppen.
Sowieso wat je doet altijd vermelden, en ik rapporteer zelf ook altijd de effecten voor de hele dataset om zo open mogelijk naar de lezer te zijn.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Moderated mediation in een logistische regressie?quote:Op woensdag 2 maart 2016 18:24 schreef Sokz het volgende:
[..]
Hoe modelleer ik dit?
maw andere modellen vinden een positief effect van A op X. Ik wil kijken of dit effect er ook is als X de conditie Y heeft.
(denk ik op basis van vrij summiere informatie
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Je kijkt dan ook niet of de variabele normaal verdeeld is, je moet kijken of de residuals van de variabelen normaal verdeeld zijn.quote:
Oké, sorry als ik een stomme vraag stel, maar ik ben nog maar een paar weken bezig in SPSS.
Ben nu bezig met een opdracht voor studie. We hebben een vooraf aangeleverde dataset.
Hiervan heb ik net sales over boekjaar 2014 als te verklaren variabele.
Vooraf wil ik dus kijken of deze normaal is verdeeld. Nee dus, ook niet als Ln-functie.
Maar in de boxplot zie ik 3 uitschieters, ook vanuit de dataset lijken deze vreemd (bijvoorbeeld opmerkelijk hoge omzet i.v.m. aantal medewerkers).
Als ik de net sales van die drie uitschieters uit mijn dataset verwijder, is de Ln-functie normaal verdeeld (volgens de Kolomogorov-Smirnov methode).
Maar, kan ik nu zomaar die uitschieters verwijderen? Wanneer ik dan toelicht in m'n paper waarom ik dit heb gedaan.
Voor deze uitschieters: als ik ze verwijderd, moet dan de gehele waarneming of enkel de net sales? Mijn gevoel zegt de gehele waarneming, want anders heb ik wel gegevens in een waarneming zitten maar geen te verklaren variabele.
[ Bericht 0% gewijzigd door #ANONIEM op 02-03-2016 20:29:47 ]
Thanksquote:
[..]
Er zijn verschillende methodes om outliers te quantificeren. Eigenlijk zou je wel van te voren moeten plannen wat je doet, aangezien je nu gaat "vissen" wat je foutmarge kan beinvloeden.
De meest standaard versies zijn om te bepalden dat je datapunten verwijdert die, x sd van de mean van de groep afliggen (bijvoorbeeld 3 sd), in een lineare regressie die een cooks distance van meer dan x hebben, of je data te trimmen door bv de hoogste en laagste x percent te droppen.
Sowieso wat je doet altijd vermelden, en ik rapporteer zelf ook altijd de effecten voor de hele dataset om zo open mogelijk naar de lezer te zijn.
Ja maar ons is geleerd dat in het begin van je onderzoek een normaal verdeelde te verklaren variabele een goede indicatie is voor een normale verdeling van je residuals.quote:
[..]
Je kijkt dan ook niet of de variabele normaal verdeeld is, je moet kijken of de residuals van de variabelen normaal verdeeld is.
Please consider the environment before printing this post.
Op zaterdag 27 mei 2017 00:36 schreef d4v1d het volgende:
Kabuf is af en toe best een prima kerel.
Op zaterdag 27 mei 2017 00:36 schreef d4v1d het volgende:
Kabuf is af en toe best een prima kerel.
Gewoon een logistische regressie met 1 moderator.quote:
[..]
Moderated mediation in een logistische regressie?
(denk ik op basis van vrij summiere informatie
Dan doe je het zoals je geleerd is. Ik denk ook niet dat je docent van je verlangt dat je dan allerlei extra dingen gaat testen die je toch niet onderwezen zijn.quote:
[..]
Thanks
[..]
Ja maar ons is geleerd dat in het begin van je onderzoek een normaal verdeelde te verklaren variabele een goede indicatie is voor een normale verdeling van je residuals.
Nou ja, uiteindelijk check ik wel of de residuals normaal verdeeld zijn uiteraard. Maar betekent het dan niks voor mijn onderzoek als mijn te verklaren variabele niet normaal verdeeld is?quote:
[..]
Dan doe je het zoals je geleerd is. Ik denk ook niet dat je docent van je verlangt dat je dan allerlei extra dingen gaat testen die je toch niet onderwezen zijn.
Please consider the environment before printing this post.
Op zaterdag 27 mei 2017 00:36 schreef d4v1d het volgende:
Kabuf is af en toe best een prima kerel.
Op zaterdag 27 mei 2017 00:36 schreef d4v1d het volgende:
Kabuf is af en toe best een prima kerel.
Dan zou het kunnen zijn dat je p-values onbetrouwbaar zijn.quote:
[..]
Nou ja, uiteindelijk check ik wel of de residuals normaal verdeeld zijn uiteraard. Maar betekent het dan niks voor mijn onderzoek als mijn te verklaren variabele niet normaal verdeeld is?
Je kan ook nog een dummy in je regressie mee laten draaien. Geef al je cases een 0 voor de niet outliers en de cases met outliers een 1. Dan test je daarna opnieuw op normaliteit.
Nee want het effect van Y is continuous (dacht ik op basis van de uitleg)quote:
[..]
Gewoon een logistische regressie met 1 moderator.
Op basis van verdere info:quote:
[..]
Hoe modelleer ik dit?
maw andere modellen vinden een positief effect van A op X. Ik wil kijken of dit effect er ook is als X de conditie Y heeft.
Originele effect: hoger op A (continuous) --> Hogere probability X (dv, dichotoom)
De vraag nu is of hetzelfde effect geldt voor een specifieke vorm van X (dv, nog steeds dichotoom maar nu op 2 attributes)
Dus de vergelijking is:
Hoger A --> hogere probability X1 (x-overvalued)
Hoger A --> ook hogere probability X2 (x-undervalued)
Heb ik het zo goed begrepen?
En zo ja, hoeveel metingen per DV heb je per observatie?
Geldt voor elk individu dat ze alleen een beslissing maken voor 1 X (die ofwel overvalued is ofwel undervalued)
Of maakt elk individu meerdere beslissingen voor meerdere X-en?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-

Een moderator kan prima continuous zijn.quote:
[..]
Nee want het effect van Y is continuous (dacht ik op basis van de uitleg)
[..]
Op basis van verdere info:
Originele effect: hoger op A (continuous) --> Hogere probability X (dv, dichotoom)
De vraag nu is of hetzelfde effect geldt voor een specifieke vorm van X (dv, nog steeds dichotoom maar nu op 2 attributes)
Dus de vergelijking is:
Hoger A --> hogere probability X1 (x-overvalued)
Hoger A --> ook hogere probability X2 (x-undervalued)
Heb ik het zo goed begrepen?
En zo ja, hoeveel metingen per DV heb je per observatie?
Geldt voor elk individu dat ze alleen een beslissing maken voor 1 X (die ofwel overvalued is ofwel undervalued)
Of maakt elk individu meerdere beslissingen voor meerdere X-en?
Je hebt gelijk ik verzon dingen erbij die helemaal niet gezegd werdenquote:Op woensdag 2 maart 2016 21:08 schreef MCH het volgende:
[..]
Een moderator kan prima continuous zijn.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
quote:
[..]
Je hebt gelijk ik verzon dingen erbij die helemaal niet gezegd werden
Vanochtend met professor overlegt en denk dat ik nu verder kom. Bedankt voor de reacties!
Wat moet je nu doen dan?quote:
[..]
Vanochtend met professor overlegt en denk dat ik nu verder kom. Bedankt voor de reacties!
Hij vond het verstandiger om mijn dataset te cutten zodat ik alleen obs met voorwaarde Y heb/include en dan simpel een logit van X op A. Voor mijn gevoel gaat nu wel redelijk wat info verloren maar c'est ca.quote:
Dat kun je toch gaan vergelijken met exact hetzelfde model op de overige observaties?quote:
[..]
Hij vond het verstandiger om mijn dataset te cutten zodat ik alleen obs met voorwaarde Y heb/include en dan simpel een logit van X op A. Voor mijn gevoel gaat nu wel redelijk wat info verloren maar c'est ca.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.

Ik ben nu bezig met een codeboek schrijven van een bestaande enquête. Hierin zit een vraag waarin de respondent er maximaal drie mag aankruisen(van de 11). Betekent dit dat ik 11 variabelen moet maken of is er een eenvoudigere manier beschikbaar?
ligt eraan wat je wil analyserenquote:Op maandag 7 maart 2016 11:24 schreef truedestiny het volgende:
Ik ben nu bezig met een codeboek schrijven van een bestaande enquête. Hierin zit een vraag waarin de respondent er maximaal drie mag aankruisen(van de 11). Betekent dit dat ik 11 variabelen moet maken of is er een eenvoudigere manier beschikbaar?
Het is een meningsinventarisatie. Ik wil graag uit de resultaten halen wat de meest voorkomende redenen zijn om een actie niet te ondernemen.quote:
Kijk, als je alleen wil weten hoe vaak optie 1-11 gebruikt zijn, heb je 11 variabelen nodig.quote:
[..]
Het is een meningsinventarisatie. Ik wil graag uit de resultaten halen wat de meest voorkomende redenen zijn om een actie niet te ondernemen.
Als je ook nog eens wil kijken naar combinaties (bijv 1+3+7) moet je deze ook apart analyseren. Dit kan allemaal alleen in één variabele als je je resultaten wil reduceren tot één antwoord (bijv vrouwen tikken vaker hogere opties aan dan mannen).
Praktisch alle statistische pakketten hebben overigens methoden om automatisch dummy variabelen te maken wanneer je dit soort vragen als nominaal markeert.
Kan Qualtrics dit niet voor je doen?quote:
Ik ben nu bezig met een codeboek schrijven van een bestaande enquête. Hierin zit een vraag waarin de respondent er maximaal drie mag aankruisen(van de 11). Betekent dit dat ik 11 variabelen moet maken of is er een eenvoudigere manier beschikbaar?
Thanks!quote:
[..]
Kijk, als je alleen wil weten hoe vaak optie 1-11 gebruikt zijn, heb je 11 variabelen nodig.
Als je ook nog eens wil kijken naar combinaties (bijv 1+3+7) moet je deze ook apart analyseren. Dit kan allemaal alleen in één variabele als je je resultaten wil reduceren tot één antwoord (bijv vrouwen tikken vaker hogere opties aan dan mannen).
Praktisch alle statistische pakketten hebben overigens methoden om automatisch dummy variabelen te maken wanneer je dit soort vragen als nominaal markeert.
Niet bekend mee. Ik zal eens kijkenquote:
Zoals anderen zeggen, ligt er een beetje aan wat je wil analyseren etc.quote:
Ik ben nu bezig met een codeboek schrijven van een bestaande enquête. Hierin zit een vraag waarin de respondent er maximaal drie mag aankruisen(van de 11). Betekent dit dat ik 11 variabelen moet maken of is er een eenvoudigere manier beschikbaar?
Als het geprinte vragenlijsten zijn en iemand moet ze invoeren in de computer, dan lijkt het me handiger om 3 variabelen (keuze 1, 2 3) aan te maken met 11 opties, dan 11 variabelen met ja/nee. Dat maakt het invoeren een stuk makkelijker.
Vraag! 
Ik heb drie testen die ik analyseer, allemaal gemaakt door dezelfde groep personen, en ik wil onderzoeken of er verschil te vinden is tussen twee subgroepen van mijn totale groep proefpersonen. Verdeling is ruwweg 85/15. Nu heb ik daarvoor drie K-S testen uitgevoerd. Geen enkele nulhypothese verworpen, maar voor de test A die ik vooraf al op het oog had wel een p van ~0.11 (ik test tweezijdig en mijn cutoff is op 0.05). Nu is dit ook de enige test waarvoor groep X beter scoort dan groep Y. Op de andere twee tests B&C scoort groep Y beter dan X (p 0.33 en 0.49 oid). Nou kan ik er zo al meer dan zat over vertellen natuurlijk, maar het zou wel leuk zijn om daar nog wat verder in te duiken.
Mijn vraag: is er een manier om die drie analyses te combineren en de richting van het verschil tussen groepen mee te nemen? Ik zat oorspronkelijk te denken aan het vergelijken van rangscores (als iedereen uit X op zichzelf een hogere rangscore heeft in test A dan de hoogste van B,C, is daar in ieder geval consistentie van richting van een effect mee aangetoond). Iemand nog een beter idee?
Noot: ik gebruik R
Ik heb drie testen die ik analyseer, allemaal gemaakt door dezelfde groep personen, en ik wil onderzoeken of er verschil te vinden is tussen twee subgroepen van mijn totale groep proefpersonen. Verdeling is ruwweg 85/15. Nu heb ik daarvoor drie K-S testen uitgevoerd. Geen enkele nulhypothese verworpen, maar voor de test A die ik vooraf al op het oog had wel een p van ~0.11 (ik test tweezijdig en mijn cutoff is op 0.05). Nu is dit ook de enige test waarvoor groep X beter scoort dan groep Y. Op de andere twee tests B&C scoort groep Y beter dan X (p 0.33 en 0.49 oid). Nou kan ik er zo al meer dan zat over vertellen natuurlijk, maar het zou wel leuk zijn om daar nog wat verder in te duiken.
Mijn vraag: is er een manier om die drie analyses te combineren en de richting van het verschil tussen groepen mee te nemen? Ik zat oorspronkelijk te denken aan het vergelijken van rangscores (als iedereen uit X op zichzelf een hogere rangscore heeft in test A dan de hoogste van B,C, is daar in ieder geval consistentie van richting van een effect mee aangetoond). Iemand nog een beter idee?
Noot: ik gebruik R
Your opinion of me is none of my business.
Hier kun je niet zat over vertellen natuurlijk. Het ene niet significante resultaat is niet beter dan het andere n.s. resultaat.quote:
Op de andere twee tests B&C scoort groep Y beter dan X (p 0.33 en 0.49 oid). Nou kan ik er zo al meer dan zat over vertellen natuurlijk,
Je kunt wat zeggen over de richting van een effect, over de resultaten in relatie tot de verwachting, over de betrouwbaarheidsintervallen, over de effectgrootte... Er is zat te vertellen zonder significante resultaten.quote:
[..]
Hier kun je niet zat over vertellen natuurlijk. Het ene niet significante resultaat is niet beter dan het andere n.s. resultaat.
Your opinion of me is none of my business.
Allemaal nee, want het is niet significant. Je zou hooguit een verklaring kunnen verzinnen, eigenlijk moeten geven waarom jouw data niet significant is.quote:
[..]
Je kunt wat zeggen over de richting van een effect, over de resultaten in relatie tot de verwachting, over de betrouwbaarheidsintervallen, over de effectgrootte... Er is zat te vertellen zonder significante resultaten.
[ Bericht 0% gewijzigd door #ANONIEM op 13-03-2016 22:32:22 ]
Het effect is er nog steeds hoor, ook al is het niet significant. Het effect heeft een richting, een effectgrootte, je kunt voor verschillende verdelingen een betrouwbaarheidsinterval opstellen en dat bekijken... Geen significant resultaat betekent niet dat je alles net zo goed de prullenbak in kunt flikkeren. Het betekent alleen dat je de nulhypothese niet mag verwerpen, niet dat je de alternatieve hypothese MOET verwerpen.quote:
[..]
Allemaal nee, want het is niet significant. Je zou hooguit een verklaring kunnen verzinnen, eigenlijk moeten geven waarom jouw data niet significant is.
Your opinion of me is none of my business.
Ja, dan zeg je zoiets van: although the result is in the expected direction, it is not significant. En dan stop je. Zo lees ik dat altijd in artikelen of jij niet? Achja, scripties met niet significante resultaten zijn meer regel dan uitzondering.quote:
[..]
Het effect is er nog steeds hoor, ook al is het niet significant. Het effect heeft een richting, een effectgrootte, je kunt voor verschillende verdelingen een betrouwbaarheidsinterval opstellen en dat bekijken... Geen significant resultaat betekent niet dat je alles net zo goed de prullenbak in kunt flikkeren. Het betekent alleen dat je de nulhypothese niet mag verwerpen, niet dat je de alternatieve hypothese MOET verwerpen.
En hopelijk vertaal je dat dan naar implicaties voor vervolgonderzoek etc ja. Dat zijn nog steeds meer woorden dan als je wel een significant resultaat had. Maar concluderend heb je dus geen antwoord op mijn vraag?quote:
[..]
Ja, dan zeg je zoiets van: although the result is in the expected direction, it is not significant. En dan stop je. Zo lees ik dat altijd in artikelen of jij niet? Achja, scripties met niet significante resultaten zijn meer regel dan uitzondering.
Your opinion of me is none of my business.
Een p van .5 is vrijwel de minst inzichtelijke uitkomst die je kunt hebben. Als de H0 waar is, heb je een kans van 50-50 om zo'n verschil of een groter verschil te vinden.quote:
[..]
Het effect is er nog steeds hoor, ook al is het niet significant. Het effect heeft een richting, een effectgrootte, je kunt voor verschillende verdelingen een betrouwbaarheidsinterval opstellen en dat bekijken... Geen significant resultaat betekent niet dat je alles net zo goed de prullenbak in kunt flikkeren. Het betekent alleen dat je de nulhypothese niet mag verwerpen, niet dat je de alternatieve hypothese MOET verwerpen.
Al,s het within is, kun je (zou je) een repeated measures test kunnen doen.
Sowieso met een n van 15 wordt het moeilijk iets significants te vinden.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Oh nee dat begrijp je verkeerd. De n is 850 ofzo, 15/85 is de verdeling van de twee groepen. En ik heb dus bij de meest interessante test een p van 0.11, dat vind ik nog niet zo oninteressant.quote:
[..]
Een p van .5 is vrijwel de minst inzichtelijke uitkomst die je kunt hebben. Als de H0 waar is, heb je een kans van 50-50 om zo'n verschil of een groter verschil te vinden.
Al,s het within is, kun je (zou je) een repeated measures test kunnen doen.
Sowieso met een n van 15 wordt het moeilijk iets significants te vinden.
Your opinion of me is none of my business.
De drie testen zijn niet per persoon?quote:
[..]
Oh nee dat begrijp je verkeerd. De n is 850 ofzo, 15/85 is de verdeling van de twee groepen. En ik heb dus bij de meest interessante test een p van 0.11, dat vind ik nog niet zo oninteressant.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Dat wel, maar niet op verschillende tijdstippen afgenomen en ze meten alle drie iets heel anders. Gewoon een testbatterij, zeg maar.quote:
[..]
De drie testen zijn niet per persoon?
Your opinion of me is none of my business.
Dan ben ik bang dat je er niet heel erg veel mee kunt doenquote:
[..]
Dat wel, maar niet op verschillende tijdstippen afgenomen en ze meten alle drie iets heel anders. Gewoon een testbatterij, zeg maar.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-

En je snapt 0.11 niet.. Je kunt niet zeggen ik zet mn cut off op 0.05 en mn uitkomst was 0.11 maar vind ik wel wat.
Nee, als je voor 0.05 kiest dan betekent dat je alles hoger dan dat als GEEN resultaat ziet. Dus 0.11 is zoals eerder gezegd, niks. Je kunt zoals ook al eerder gezegd, een richting aan geven maar dat houdt dus op bij 'maar dit was enkel bij deze studie en het resultaat bij andere studies kan anders zijn, want het resultaat was niet significant'.
Nee, als je voor 0.05 kiest dan betekent dat je alles hoger dan dat als GEEN resultaat ziet. Dus 0.11 is zoals eerder gezegd, niks. Je kunt zoals ook al eerder gezegd, een richting aan geven maar dat houdt dus op bij 'maar dit was enkel bij deze studie en het resultaat bij andere studies kan anders zijn, want het resultaat was niet significant'.
Baby darling doll face honey
Ik snap het prima. Het betekent dat er een kans is van 11% dat ik mijn huidige resultaten vindt onder de assumptie van de nulhypothese. Omdat ik mijn cutoff op 5% heb gezet, heb ik a priori besloten dat 11% dus niet voldoende bewijs is om de alternatieve hypothese aan te nemen en de nulhypothese te verwerpen. Dat betekent, nogmaals, niet dat ik bij een p van 11% de nulhypothese aanneem. Je kunt nooit iets bevestigen, alleen ontkrachten. Ik test de nulhypothese, dus die kan ik niet bevestigen. Bij een significant resultaat kan het resultaat bij een volgende studie net zo goed anders zijn, want de p waarde differentieert niet tussen een echt bewijs voor de alternatieve hypothese in de populatie en gewoon een zeer onwaarschijnlijke steekproef. Sorry dat ik geen significantiefapper ben.quote:Op maandag 14 maart 2016 01:42 schreef Crack_ het volgende:
En je snapt 0.11 niet.. Je kunt niet zeggen ik zet mn cut off op 0.05 en mn uitkomst was 0.11 maar vind ik wel wat.
Nee, als je voor 0.05 kiest dan betekent dat je alles hoger dan dat als GEEN resultaat ziet. Dus 0.11 is zoals eerder gezegd, niks. Je kunt zoals ook al eerder gezegd, een richting aan geven maar dat houdt dus op bij 'maar dit was enkel bij deze studie en het resultaat bij andere studies kan anders zijn, want het resultaat was niet significant'.
Verder boeit deze test niet eens zo heel veel want het is maar een zijweggetje van mijn tweede hoofdvraag. Ik vroeg me alleen af of ik, gezien de richting van de ene test de andere kant op gaat, de rangscores nog op een andere manier tegen elkaar uit kon zetten.
Your opinion of me is none of my business.

Mooi, en sorry dat ik dat wel benquote:
[..]
Ik snap het prima. Het betekent dat er een kans is van 11% dat ik mijn huidige resultaten vindt onder de assumptie van de nulhypothese. Omdat ik mijn cutoff op 5% heb gezet, heb ik a priori besloten dat 11% dus niet voldoende bewijs is om de alternatieve hypothese aan te nemen en de nulhypothese te verwerpen. Dat betekent, nogmaals, niet dat ik bij een p van 11% de nulhypothese aanneem. Je kunt nooit iets bevestigen, alleen ontkrachten. Ik test de nulhypothese, dus die kan ik niet bevestigen. Bij een significant resultaat kan het resultaat bij een volgende studie net zo goed anders zijn, want de p waarde differentieert niet tussen een echt bewijs voor de alternatieve hypothese in de populatie en gewoon een zeer onwaarschijnlijke steekproef. Sorry dat ik geen significantiefapper ben.
Verder boeit deze test niet eens zo heel veel want het is maar een zijweggetje van mijn tweede hoofdvraag. Ik vroeg me alleen af of ik, gezien de richting van de ene test de andere kant op gaat, de rangscores nog op een andere manier tegen elkaar uit kon zetten.
Verder kan ik je helaas niet helpen, succes nog verder. Hopelijk kun je er nog iets mee.
Baby darling doll face honey
Zijn waarden van snijpunten tussen groepen te toetsen? Dus bij de ene groep is het snijpunt 2,53 en bij de andere groep 2,89. Is dit verschil significant? Ik kan er geen toets bij bedenken.
Aldus.
dan heb je dus geen verschil op je meest interessante test. aangezien de cutoff op .05 zitquote:
[..]
Omdat ik mijn cutoff op 5% heb gezet, heb ik a priori besloten dat 11% dus niet voldoende bewijs is om de alternatieve hypothese aan te nemen en de nulhypothese te verwerpen.
[..]
Sorry dat ik geen significantiefapper ben.
[..]
En ik heb dus bij de meest interessante test een p van 0.11, dat vind ik nog niet zo oninteressant.
een p van .0500000001 was ook niet significant geweest.
Heb je nagedacht waarom die .05 gekozen wordt? en niet bijvoorbeeld .01?
Als je bepaalt dat de cutoff ergens is, kan je niet achteraf de regels nog aanpassen! waarom onderzoek doen als je je niet aan je eigen regels houdt?
Surely god loves the .06 nearly as much as the .05
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Kun je iets meer uitleg geven? Snijpunt van wat met wat? Zou iig te toetsen moeten zijn.quote:
Zijn waarden van snijpunten tussen groepen te toetsen? Dus bij de ene groep is het snijpunt 2,53 en bij de andere groep 2,89. Is dit verschil significant? Ik kan er geen toets bij bedenken.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Dat kan prima. er moet immers ook brood op de plank komen. Zolang hij geen cijfers gaat vervalsen mogen anderen er van vinden wat ze willen (ie. geen hoge significantie, maar een knipoog naar een bepaalde richting).quote:
[..]
Als je bepaalt dat de cutoff ergens is, kan je niet achteraf de regels nog aanpassen! waarom onderzoek doen als je je niet aan je eigen regels houdt?
Niemand zal hem serieus nemen als hij zegt dat 0.11 significant is, maar het is prima wetenschap om resultaten te laten zien met 0.11 p-values en aan te geven dat het niet significant is maar dat het eventueel in een bepaalde richting kan wijzen.
[ Bericht 8% gewijzigd door Zith op 14-03-2016 17:56:43 ]
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Zij, maar verder ongeveer dit ja. Ik ga echt niet zeggen dat het bijna significant is, helemaal significant, whatever. Maar als een resultaat niet significant is, kan het nog steeds wel interessant zijn. Als je een bepaald effect verwacht en je krijgt een p van 0.98 is dat ook ontiegelijk interessant. En dat een verschil niet significant is, betekent niet dat er helemaal geen verschil (in de steekproef) is. Of is een gemiddelde van 23 opeens gelijk aan een gemiddelde van 28 omdat de p waarde niet onder de Alpha zit?quote:
[..]
Dat kan prima. er moet immers ook brood op de plank komen. Zolang hij geen cijfers gaat vervalsen mogen anderen er van vinden wat ze willen (ie. geen hoge significantie, maar een knipoog naar een bepaalde richting).
Niemand zal hem serieus nemen als hij zegt dat 0.11 significant is, maar het is prima wetenschap om resultaten te laten zien met 0.11 p-values en aan te geven dat het niet significant is maar dat het eventueel in een bepaalde richting kan wijzen.
Your opinion of me is none of my business.
Je kan alleen eigenlijk niets zeggen over of dat verschil ruis is of niet.quote:
[..]
Zij, maar verder ongeveer dit ja. Ik ga echt niet zeggen dat het bijna significant is, helemaal significant, whatever. Maar als een resultaat niet significant is, kan het nog steeds wel interessant zijn. Als je een bepaald effect verwacht en je krijgt een p van 0.98 is dat ook ontiegelijk interessant. En dat een verschil niet significant is, betekent niet dat er helemaal geen verschil (in de steekproef) is. Of is een gemiddelde van 23 opeens gelijk aan een gemiddelde van 28 omdat de p waarde niet onder de Alpha zit?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
er is geen bewijs dat het verschil verklaard kan worden door de in jouw model opgenomen variabelen, dat kan je er zeker over zeggen als de gemiddelden van de groepen die je in jouw test vergeleek 23 en 28 zijn.quote:
Of is een gemiddelde van 23 opeens gelijk aan een gemiddelde van 28 omdat de p waarde niet onder de Alpha zit?
Dit kan zeker, maar de tendens had je ook kunnen baseren op eerder onderzoek.quote:
[..]
Niemand zal hem serieus nemen als hij zegt dat 0.11 significant is, maar het is prima wetenschap om resultaten te laten zien met 0.11 p-values en aan te geven dat het niet significant is maar dat het eventueel in een bepaalde richting kan wijzen.
"en je probeert dit goed te praten onder een confirmation bias."
Als je zegt dat je tevreden bent met een p<.05 dan is bij een p>.05 je 0-hypothese niet verworpen.
Een niet significant verschil is ook een significante bijdrage aan de wetenschapquote:Dat kan prima. er moet immers ook brood op de plank komen.
Wat moet ik doen als ik bij mijn chi-square teveel cellen heb met een expected count less than five? Ik las dat bij meer dan 20% de resultaten niet valide zijn? Bij sommige variabelen is het bij mij 60%.
Cellen samenvoegen als dat kan, anders houdt het op.quote:
Wat moet ik doen als ik bij mijn chi-square teveel cellen heb met een expected count less than five? Ik las dat bij meer dan 20% de resultaten niet valide zijn? Bij sommige variabelen is het bij mij 60%.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Hoe doe ik dat?quote:
[..]
Cellen samenvoegen als dat kan, anders houdt het op.
Als je bv geinteresseerd bent in verschil man-vrouw en schrijfkleur rood-blauw op een bepaalde uitkomst, je test beperken tot verschil kleur (of verschil gender).quote:
Verder valt er helaas weinig te doen. (nou lijkt het me ook dat of dezelfde rij erg laag is in je experiment dus 98% - 2% voor groep 1 en 97% - 3% voor groep 2, en dan kun je zelfs zonder test wel zien dat er geen effect is, of juist het tegenovergestelde 99-1 voor groep 1 en 1-99 voor groep 2 en dan heb je eigenlijk ook niet echt een test meer nodig).
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Aahh zo, ik snap het, thanks!quote:
[..]
Als je bv geinteresseerd bent in verschil man-vrouw en schrijfkleur rood-blauw op een bepaalde uitkomst, je test beperken tot verschil kleur (of verschil gender).
Verder valt er helaas weinig te doen. (nou lijkt het me ook dat of dezelfde rij erg laag is in je experiment dus 98% - 2% voor groep 1 en 97% - 3% voor groep 2, en dan kun je zelfs zonder test wel zien dat er geen effect is, of juist het tegenovergestelde 99-1 voor groep 1 en 1-99 voor groep 2 en dan heb je eigenlijk ook niet echt een test meer nodig).
Bijdraaien? :pquote:
[..]
Aahh zo, ik snap het, thanks!
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik heb een prijsmeter-analyse gedaan voor verschillende versies van producten.quote:
[..]
Kun je iets meer uitleg geven? Snijpunt van wat met wat? Zou iig te toetsen moeten zijn.

De snijpunten, prijs in euro's, wil ik toetsen.
Aldus.
Meer data verzamelen.quote:
Wat moet ik doen als ik bij mijn chi-square teveel cellen heb met een expected count less than five? Ik las dat bij meer dan 20% de resultaten niet valide zijn? Bij sommige variabelen is het bij mij 60%.
Ik ben een dataset aan het maken met SPSS. Niet super moeilijk, maar ik loop echter tegen één probleem aan. Het gaat hier om een patiëntenbestand met verschillende parameters. Deze patiënten hebben een bepaalde operatie ondergaan en sommige patiënten hebben hier naderhand complicaties van ondervonden. Ik heb echter de grootste moeite om deze complicaties op een efficiëntie manier in SPSS te zetten. Sommige patiënten hebben namelijk meerdere complicaties gehad.
Ik heb de volgende dingen al geprobeerd:
1) Één variabele Complicaties aanmaken, alle verschillende complicaties labelen. Dit werkt dus niet omdat sommige patiënten bijv. zowel een fistel als een abces kunnen hebben. Ik kan complicaties combineren onder één label (0 = fistel, 1 = abces, 2 = fistel en abces bijv.), maar dan krijg ik dubbel zoveel labels als dat ik complicaties heb en dat gaat echt een gigantische lijst worden.
2) Voor elke complicatie een variabele aanmaken. Dit werkt op zich wel, maar ik heb nu al 17 complicaties in mijn dataset staan (er staan nu 25 patiënten in, het worden er waarschijnlijk honderden). Ik verwacht dat dit aantal nog enigszins zal groeien. Er moet toch een andere manier zijn om te voorkomen dat ik met een monster van een dataset eindig, haha.
3) Complicaties groeperen binnen variabelen. Ik heb eerst geprobeerd om te groeperen naar een variabele maag-darmkanaal complicaties, cardiale complicaties, pulmonale complicaties en etc. Echter, zoals ik hierboven al heb beschreven, sommige mensen hebben bijv. zowel een fistel als een abces (beide maag-darmkanaal complicaties), ik loop op deze manier weer tegen probleem 1 aan. Vervolgens heb ik 4 variabelen aangemaakt, Complicaties 1 t/m 4 met allemaal dezelfde labels. Dit werkt niet, als ik een statistische analyse wil doen dan krijg ik vier verschillende tabellen met dezelfde complicaties in groepjes verspreid over al deze tabellen. Dit is prima voor frequenties, maar niet als ik er meer geavanceerde dingen mee wil doen.
Kortom, is er een manier om deze complicaties op een efficiënte manier in SPSS te krijgen of moet ik toch echt losse variabelen maken?
Ik heb de volgende dingen al geprobeerd:
1) Één variabele Complicaties aanmaken, alle verschillende complicaties labelen. Dit werkt dus niet omdat sommige patiënten bijv. zowel een fistel als een abces kunnen hebben. Ik kan complicaties combineren onder één label (0 = fistel, 1 = abces, 2 = fistel en abces bijv.), maar dan krijg ik dubbel zoveel labels als dat ik complicaties heb en dat gaat echt een gigantische lijst worden.
2) Voor elke complicatie een variabele aanmaken. Dit werkt op zich wel, maar ik heb nu al 17 complicaties in mijn dataset staan (er staan nu 25 patiënten in, het worden er waarschijnlijk honderden). Ik verwacht dat dit aantal nog enigszins zal groeien. Er moet toch een andere manier zijn om te voorkomen dat ik met een monster van een dataset eindig, haha.
3) Complicaties groeperen binnen variabelen. Ik heb eerst geprobeerd om te groeperen naar een variabele maag-darmkanaal complicaties, cardiale complicaties, pulmonale complicaties en etc. Echter, zoals ik hierboven al heb beschreven, sommige mensen hebben bijv. zowel een fistel als een abces (beide maag-darmkanaal complicaties), ik loop op deze manier weer tegen probleem 1 aan. Vervolgens heb ik 4 variabelen aangemaakt, Complicaties 1 t/m 4 met allemaal dezelfde labels. Dit werkt niet, als ik een statistische analyse wil doen dan krijg ik vier verschillende tabellen met dezelfde complicaties in groepjes verspreid over al deze tabellen. Dit is prima voor frequenties, maar niet als ik er meer geavanceerde dingen mee wil doen.
Kortom, is er een manier om deze complicaties op een efficiënte manier in SPSS te krijgen of moet ik toch echt losse variabelen maken?
Wat is het maximale aantal complicaties bij een patiënt? Stel dat dat er 10 zijn, dan maak je tien variabelen aan met alle complicaties per variabele zoals je bij (1) gedaan hebt. De vorm die je kiest hangt mogelijk samen met de analyses die je wil doen, iets om rekening mee te houden.
Aldus.
Ik zat te denken aan logistic regression en ik heb n.a.v. jouw post zojuist het halve internet ondersteboven gekeerd en ik kom er dus achter dat je a) één dependent variable kunt aangeven, b) deze variable maar twee catagorieën kan hebben, wat dus waarschijnlijk betekent dat ik mijn complicaties als losse variabelen in SPSS moet zetten wil ik er wat mee kunnen, haha. Dus volgens mij ben ik er zo wel uit.
Je kan, ten behoeve van de logistische regressie, categoriale variabelen hercoderen naar dummies. Dat kan SPSS automatisch geloof ik. Tip: lees je ook nog even in over vrijheidsgraden.
Aldus.
Het is mij niet helemaal duidelijk wat nou precies je dependent variabele moet worden. Kun je dat nog eens toelichten?quote:
Ik zat te denken aan logistic regression en ik heb n.a.v. jouw post zojuist het halve internet ondersteboven gekeerd en ik kom er dus achter dat je a) één dependent variable kunt aangeven, b) deze variable maar twee catagorieën kan hebben, wat dus waarschijnlijk betekent dat ik mijn complicaties als losse variabelen in SPSS moet zetten wil ik er wat mee kunnen, haha. Dus volgens mij ben ik er zo wel uit.
[ Bericht 24% gewijzigd door #ANONIEM op 21-03-2016 22:10:40 ]
De complicaties worden de dependent variables. Dus wat ik zou kunnen doen is kijken wat de invloed is van bijv. roken op het ontwikkelen van een abces postoperatief (= complicatie). Roken zou dan mijn independent variable worden (0 = nooit, 1 = ja, 2 = gestopt), het ontwikkelen van een abces mijn dependent variable (0 = nee, 1 = ja).
Dat hercoderen ziet er inderdaad wel interessant uit. Ik zal me er eens in verdiepen.
Dat hercoderen ziet er inderdaad wel interessant uit. Ik zal me er eens in verdiepen.
Ik heb een dataset met een aantal dummy variabelen (STATA) en ik vraag mij af hoe je uit een regressie output kunt afleiden of het handig is om bepaalde dummy variabelen met elkaar te combineren. En als er dummy variabelen gecombineerd worden welke restricties er getest moeten worden. Weet iemand dit toevallig? Wat betreft het testen van restricties dacht ik aan een joint restrictie.. maar ik kan het fout hebben.
Alvast bedankt.
Alvast bedankt.
Wow, dan krijg je dus een ontelbare hoeveelheid dv's als je een lange lijst met complicaties hebt. Ik weet niet of het relevant is maar je zou ook nog een Poisson regression kunnen uitvoeren om te kijken welke factoren een invloed hebben op het aantal bijwerkingen dat iemand krijgt.quote:
De complicaties worden de dependent variables. Dus wat ik zou kunnen doen is kijken wat de invloed is van bijv. roken op het ontwikkelen van een abces postoperatief (= complicatie). Roken zou dan mijn independent variable worden (0 = nooit, 1 = ja, 2 = gestopt), het ontwikkelen van een abces mijn dependent variable (0 = nee, 1 = ja).
Dat hercoderen ziet er inderdaad wel interessant uit. Ik zal me er eens in verdiepen.
Weet iemand hoe ik een bepaalde excel data file het beste in eviews kan importeren?
Ik heb op de y-as de verschillende identifiers (in mijn geval bedrijven) en op de x-as de datum (in mijn geval een periode van ongeveer 300 dagen) en voor de rest een variabele per worksheet (6 variabelen en dus 6 worksheets totaal). Normaal moet je bij eviews (volgensmij) op de y-as zowel de datum als de identifiers zetten om het correct te kunnen importeren, maar in mijn geval was het niet mogelijk het op deze manier te downloaden en dan zou het bovendien redelijk onleesbaar worden vanwege het grote aantal datums en bedrijven.
Als iemand me een linkje kunnen sturen die ongeveer beschrijft hoe ik dit het beste kan aanpakken zou ik dit ook erg op prijs stellen uiteraard! Volgensmij betreft mijn dataset 'unstacked panel data', maar dat weet ik niet zeker. Heb uiteraard al op google gezocht maar vind geen relevante resultaten.
Bij voorbaat dank!
Ik heb op de y-as de verschillende identifiers (in mijn geval bedrijven) en op de x-as de datum (in mijn geval een periode van ongeveer 300 dagen) en voor de rest een variabele per worksheet (6 variabelen en dus 6 worksheets totaal). Normaal moet je bij eviews (volgensmij) op de y-as zowel de datum als de identifiers zetten om het correct te kunnen importeren, maar in mijn geval was het niet mogelijk het op deze manier te downloaden en dan zou het bovendien redelijk onleesbaar worden vanwege het grote aantal datums en bedrijven.
Als iemand me een linkje kunnen sturen die ongeveer beschrijft hoe ik dit het beste kan aanpakken zou ik dit ook erg op prijs stellen uiteraard! Volgensmij betreft mijn dataset 'unstacked panel data', maar dat weet ik niet zeker. Heb uiteraard al op google gezocht maar vind geen relevante resultaten.
Bij voorbaat dank!
Ik ga voor mijn scriptie kijken naar het volgende onderwerp:
Scoren leerlingen die op een basisschool 8 jaar Frans hebben gehad beter op Frans in de 1e klas dan leerlingen die de taal niet hebben gehad, rekening houdend met de algemene cognitie?
Er zijn 5 leerlingen die Frans hebben gehad in verschillende klassen. Van alle leerlingen uit deze klassen heb ik het gemiddelde van Frans en van Nederlands, geschiedenis en wiskunde (voor de algemene cognitie) om te kunnen vergelijken.
Ik dacht dat ik een independent t-test moest doen, maar dan kan ik niet controleren op algemene cognitie. En ik kan toch niet zomaar de gegevens van alle klassen samenvoegen zonder te kijken naar het gemiddelde van elke specifieke klas?
Wie kan mij helpen?
Scoren leerlingen die op een basisschool 8 jaar Frans hebben gehad beter op Frans in de 1e klas dan leerlingen die de taal niet hebben gehad, rekening houdend met de algemene cognitie?
Er zijn 5 leerlingen die Frans hebben gehad in verschillende klassen. Van alle leerlingen uit deze klassen heb ik het gemiddelde van Frans en van Nederlands, geschiedenis en wiskunde (voor de algemene cognitie) om te kunnen vergelijken.
Ik dacht dat ik een independent t-test moest doen, maar dan kan ik niet controleren op algemene cognitie. En ik kan toch niet zomaar de gegevens van alle klassen samenvoegen zonder te kijken naar het gemiddelde van elke specifieke klas?
Wie kan mij helpen?
Omdat het zo lomp is als niemand op je vraag reageert: Sorry, ik had voor je post nog nooit van eviews gehoord, dus geen flauw idee hoe je daar kunt importeren. Misschien eens kijken naar of er online wat te vinden is over .csv bestanden importeren? (Je kunt een Excel bestand heel makkelijk opslaan als .csv en soms geeft dat wat meer opties.)quote:
Weet iemand hoe ik een bepaalde excel data file het beste in eviews kan importeren?
Ik heb op de y-as de verschillende identifiers (in mijn geval bedrijven) en op de x-as de datum (in mijn geval een periode van ongeveer 300 dagen) en voor de rest een variabele per worksheet (6 variabelen en dus 6 worksheets totaal). Normaal moet je bij eviews (volgensmij) op de y-as zowel de datum als de identifiers zetten om het correct te kunnen importeren, maar in mijn geval was het niet mogelijk het op deze manier te downloaden en dan zou het bovendien redelijk onleesbaar worden vanwege het grote aantal datums en bedrijven.
Als iemand me een linkje kunnen sturen die ongeveer beschrijft hoe ik dit het beste kan aanpakken zou ik dit ook erg op prijs stellen uiteraard! Volgensmij betreft mijn dataset 'unstacked panel data', maar dat weet ik niet zeker. Heb uiteraard al op google gezocht maar vind geen relevante resultaten.
Bij voorbaat dank!
Dus als ik het goed begrijp heb je twee groepen:quote:
Ik ga voor mijn scriptie kijken naar het volgende onderwerp:
Scoren leerlingen die op een basisschool 8 jaar Frans hebben gehad beter op Frans in de 1e klas dan leerlingen die de taal niet hebben gehad, rekening houdend met de algemene cognitie?
Er zijn 5 leerlingen die Frans hebben gehad in verschillende klassen. Van alle leerlingen uit deze klassen heb ik het gemiddelde van Frans en van Nederlands, geschiedenis en wiskunde (voor de algemene cognitie) om te kunnen vergelijken.
Ik dacht dat ik een independent t-test moest doen, maar dan kan ik niet controleren op algemene cognitie. En ik kan toch niet zomaar de gegevens van alle klassen samenvoegen zonder te kijken naar het gemiddelde van elke specifieke klas?
Wie kan mij helpen?
1. 5 leerlingen die Frans hebben gehad.
2. Gruwelijke veel leerlingen (meerdere klassen) die geen Frans hebben gehad.
Klopt dat?
In dat geval is je grootste probleem dat je slechts 5 leerlingen hebt die Frans hebben gehad. Die groep is te klein om iets zinvols over te kunnen zeggen.
Als je de klas waartoe iemand behoort wil analyseren dan kom je al snel uit op multilevel analyses, maar ik zou me kunnen voorstellen dat, gezien de rest van je project, dat dermate hooggegrepen is dat je begeleider je dat niet aan wil doen.
Operc heeft gelijk, wat je wilt doen valt abstract / technisch te doen, maar niet met de data die je hebt.
Een simpelere, minder juiste versie valt ook niet echt te doen, maar kun je in ieder geval wel runnen (zou de resultaten alleen niet vertrouwen) en dat is gewoon opdelen in wel of niet frans als groepen. Andere scores meenemen als covariaat in Anova en dat gebruiken.
Een simpelere, minder juiste versie valt ook niet echt te doen, maar kun je in ieder geval wel runnen (zou de resultaten alleen niet vertrouwen) en dat is gewoon opdelen in wel of niet frans als groepen. Andere scores meenemen als covariaat in Anova en dat gebruiken.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Mensen, ik vul data in in STATA.
Heb nu twee variabelen gemaakt, maar als ik vervolgens "summarize" in tik dan geeft STATA aan dat er voor beide variabelen 0 observaties zijn terwijl ze er toch echt staan. Bijvoorbeeld de variabele "Year" aangemaakt en vervolgens staat daaronder (in de data editor) 1950 t/m 2010.
Dit is de eerste keer dat ik zelf data in het programma gooi. Wat kan ik verkeerd doen? Hulp is zeer welkom.
Heb nu twee variabelen gemaakt, maar als ik vervolgens "summarize" in tik dan geeft STATA aan dat er voor beide variabelen 0 observaties zijn terwijl ze er toch echt staan. Bijvoorbeeld de variabele "Year" aangemaakt en vervolgens staat daaronder (in de data editor) 1950 t/m 2010.
Dit is de eerste keer dat ik zelf data in het programma gooi. Wat kan ik verkeerd doen? Hulp is zeer welkom.
Ik gebruik geen STATA dus het is een wilde gok, maar zijn de variabelen nog hoofdlettergevoelig misschien? En is het type variabele juist? (Dat je niet stiekem string hebt terwijl het integer moet zijn.)quote:
Mensen, ik vul data in in STATA.
Heb nu twee variabelen gemaakt, maar als ik vervolgens "summarize" in tik dan geeft STATA aan dat er voor beide variabelen 0 observaties zijn terwijl ze er toch echt staan. Bijvoorbeeld de variabele "Year" aangemaakt en vervolgens staat daaronder (in de data editor) 1950 t/m 2010.
Dit is de eerste keer dat ik zelf data in het programma gooi. Wat kan ik verkeerd doen? Hulp is zeer welkom.
Ook ik ken srata niet, maar heb wel eens gehad dat de vorm van de data in de kolommen verkeerd ingesteld was een p die manier gaf de software dan aan dat er geen observaties waren...quote:
Mensen, ik vul data in in STATA.
Heb nu twee variabelen gemaakt, maar als ik vervolgens "summarize" in tik dan geeft STATA aan dat er voor beide variabelen 0 observaties zijn terwijl ze er toch echt staan. Bijvoorbeeld de variabele "Year" aangemaakt en vervolgens staat daaronder (in de data editor) 1950 t/m 2010.
Dit is de eerste keer dat ik zelf data in het programma gooi. Wat kan ik verkeerd doen? Hulp is zeer welkom.
Whatever...
Ik heb een vraag omtrent een schaal (SPSS).
Ik onderzoek de relatie tussen Facebookgebruik, zelfbeeld en eetgedrag. Nu onderzoek ik eetgedrag met behulp van de Eating Attitudes Test 26 (EAT-26). Deze bestaat uit drie delen:
(A) Gewicht en lengte (waar ik BMI van heb gemaakt),
(B) 26 vragen
(C) 4 gedragsvragen variërend van (nooit, 1x per maand of minder, 2-3x per maand, 1x per week, 2-6x per week en 1x per dag of meer) en 2 extra (heftige) vragen waar alleen (ja of nee) kan worden beantwoord.
De scoring voor die 26 vragen heb ik al verwerkt via Transform - Recode zodat ik op een totaal van 20 of meer kom wat problematisch eetgedrag blijkt. Dit staat op: http://www.eat-26.com/scoring.php. Maar er staat verder geen score bij de overige delen, behalve dan kruisjes bij wat problematisch gedrag is. Hoe kan ik (A) BMI en (C) de vragen waarbij een andere score wordt gehanteerd, dan samenvoegen met de 26 vragen? Ik moet toch uiteindelijk op een schaal komen, namelijk eetgedrag.
Mijn dank zal groot zijn.
Ik onderzoek de relatie tussen Facebookgebruik, zelfbeeld en eetgedrag. Nu onderzoek ik eetgedrag met behulp van de Eating Attitudes Test 26 (EAT-26). Deze bestaat uit drie delen:
(A) Gewicht en lengte (waar ik BMI van heb gemaakt),
(B) 26 vragen
(C) 4 gedragsvragen variërend van (nooit, 1x per maand of minder, 2-3x per maand, 1x per week, 2-6x per week en 1x per dag of meer) en 2 extra (heftige) vragen waar alleen (ja of nee) kan worden beantwoord.
De scoring voor die 26 vragen heb ik al verwerkt via Transform - Recode zodat ik op een totaal van 20 of meer kom wat problematisch eetgedrag blijkt. Dit staat op: http://www.eat-26.com/scoring.php. Maar er staat verder geen score bij de overige delen, behalve dan kruisjes bij wat problematisch gedrag is. Hoe kan ik (A) BMI en (C) de vragen waarbij een andere score wordt gehanteerd, dan samenvoegen met de 26 vragen? Ik moet toch uiteindelijk op een schaal komen, namelijk eetgedrag.
Mijn dank zal groot zijn.
Kun je vraag C niet als robustnesscheck inbouwen. Dus je doet eerst je onderzoek op basis van B. Dan doe je het nogmaals met C. Of ik zou BMI als moderator beschouwen. Ik denk namelijk niet dat een BMI alles zegt over problematisch eetgedrag. Een skinny bitch kan toch net zo goed een problematische eter zijn.quote:
Ik heb een vraag omtrent een schaal (SPSS).
Ik onderzoek de relatie tussen Facebookgebruik, zelfbeeld en eetgedrag. Nu onderzoek ik eetgedrag met behulp van de Eating Attitudes Test 26 (EAT-26). Deze bestaat uit drie delen:
(A) Gewicht en lengte (waar ik BMI van heb gemaakt),
(B) 26 vragen
(C) 4 gedragsvragen variërend van (nooit, 1x per maand of minder, 2-3x per maand, 1x per week, 2-6x per week en 1x per dag of meer) en 2 extra (heftige) vragen waar alleen (ja of nee) kan worden beantwoord.
De scoring voor die 26 vragen heb ik al verwerkt via Transform - Recode zodat ik op een totaal van 20 of meer kom wat problematisch eetgedrag blijkt. Dit staat op: http://www.eat-26.com/scoring.php. Maar er staat verder geen score bij de overige delen, behalve dan kruisjes bij wat problematisch gedrag is. Hoe kan ik (A) BMI en (C) de vragen waarbij een andere score wordt gehanteerd, dan samenvoegen met de 26 vragen? Ik moet toch uiteindelijk op een schaal komen, namelijk eetgedrag.
Mijn dank zal groot zijn.
[ Bericht 8% gewijzigd door #ANONIEM op 10-04-2016 14:54:40 ]
Probeer de volgende dingen/commando's:quote:
Mensen, ik vul data in in STATA.
Heb nu twee variabelen gemaakt, maar als ik vervolgens "summarize" in tik dan geeft STATA aan dat er voor beide variabelen 0 observaties zijn terwijl ze er toch echt staan. Bijvoorbeeld de variabele "Year" aangemaakt en vervolgens staat daaronder (in de data editor) 1950 t/m 2010.
Dit is de eerste keer dat ik zelf data in het programma gooi. Wat kan ik verkeerd doen? Hulp is zeer welkom.
-count.
-inspect [variabele namen]
Zoals hierboven ook al gezegd wordt, kijk of je geen hoofdletters hebt gebruikt en of het wel numerieke variabelen zijn. Alle commando's zijn hoofdlettergevoelig.
Kopieer de data naar excel en importeer het dan als nieuwe dataset.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Mijn kennis van statistiek is uitermate belabberd, maar toch durf ik wat vraagtekens bij het volgende experiment te zetten. Gaarne jullie input.
Men doet 22 operaties op patienten, en na die operatie voert men een meting met een speciaal instrument uit op de wond. Die meting wordt na een week herhaald, en na een maand na de operatie, twee maanden na de operatie, drie maanden na de operatie en vier maanden na de operatie. Tijdens ieder meetpunt kijkt de dokter mee, en geeft een oordeel over de kwaliteit van de wond. Of de wond netjes geheeld is ("good"), of dat er een lelijk litteken is ("moderate"), of dat er complicaties zijn ("poor").
Op basis van die metingen worden ROC curves gemaakt. Wat men namelijk wil weten, is of de metingen met dat speciale instrument in een vroeg stadium kunnen voorspellen of er later complicaties zullen zijn.
Die ROC curves blijken erg onbetrouwbaar te zijn voor data die direct na de operatie is verzameld, of die een week na de operatie is verzameld.
Maar na 1 maand blijkt dat in 6 van de 9 gevallen dat het apparaat een rood sein gaf, er tussen maand 1 en 4 idd. een complicatie is opgetreden. In 1 van de 13 gevallen dat het apparaat aangaf dat alles ok was, is er in die periode ook een complicatie opgetreden.
Kun je op basis van zo weinig metingen uberhaupt ROC curves maken, en zo ja, hoe betrouwbaar is zo'n curve dan?
[ Bericht 1% gewijzigd door Lyrebird op 04-05-2016 15:18:43 ]
Men doet 22 operaties op patienten, en na die operatie voert men een meting met een speciaal instrument uit op de wond. Die meting wordt na een week herhaald, en na een maand na de operatie, twee maanden na de operatie, drie maanden na de operatie en vier maanden na de operatie. Tijdens ieder meetpunt kijkt de dokter mee, en geeft een oordeel over de kwaliteit van de wond. Of de wond netjes geheeld is ("good"), of dat er een lelijk litteken is ("moderate"), of dat er complicaties zijn ("poor").
Op basis van die metingen worden ROC curves gemaakt. Wat men namelijk wil weten, is of de metingen met dat speciale instrument in een vroeg stadium kunnen voorspellen of er later complicaties zullen zijn.
Die ROC curves blijken erg onbetrouwbaar te zijn voor data die direct na de operatie is verzameld, of die een week na de operatie is verzameld.
Maar na 1 maand blijkt dat in 6 van de 9 gevallen dat het apparaat een rood sein gaf, er tussen maand 1 en 4 idd. een complicatie is opgetreden. In 1 van de 13 gevallen dat het apparaat aangaf dat alles ok was, is er in die periode ook een complicatie opgetreden.
Kun je op basis van zo weinig metingen uberhaupt ROC curves maken, en zo ja, hoe betrouwbaar is zo'n curve dan?
[ Bericht 1% gewijzigd door Lyrebird op 04-05-2016 15:18:43 ]
Good intentions and tender feelings may do credit to those who possess them, but they often lead to ineffective — or positively destructive — policies ... Kevin D. Williamson
Hallo mensen!
Ik hoop dat iemand hier mij kan helpen met mijn vraag.
Ik doe een onderzoekje met een dataset waarin respondenten uit vier landen zitten.
Er is een variabele die ik heb bewerkt, en uiteindelijk omgezet naar een dichotome variabele. Dit heb ik per land gedaan, omdat de oorspronkelijke categorieen in de verschillende landen niet met elkaar te vergelijken waren.
Ik heb nu dus vier dichotome variabelen, per land. Elke respondent komt dus ook maar één keer voor in al deze vier variabelen.
Nu wil ik er eigenlijk weer één variabele van maken. Iedereen heeft nu eenzelfde score (1 of 0), dus ik denk dat dit wel mogelijk is.
Maar hoe moet ik dit doen?
Ik werk trouwens met SPSS Syntax, dus als iemand er ook nog eens een syntax code voor zou weten zou ik helemaal gelukkig zijn....
Ik hoop dat iemand hier mij kan helpen met mijn vraag.
Ik doe een onderzoekje met een dataset waarin respondenten uit vier landen zitten.
Er is een variabele die ik heb bewerkt, en uiteindelijk omgezet naar een dichotome variabele. Dit heb ik per land gedaan, omdat de oorspronkelijke categorieen in de verschillende landen niet met elkaar te vergelijken waren.
Ik heb nu dus vier dichotome variabelen, per land. Elke respondent komt dus ook maar één keer voor in al deze vier variabelen.
Nu wil ik er eigenlijk weer één variabele van maken. Iedereen heeft nu eenzelfde score (1 of 0), dus ik denk dat dit wel mogelijk is.
Maar hoe moet ik dit doen?
Ik werk trouwens met SPSS Syntax, dus als iemand er ook nog eens een syntax code voor zou weten zou ik helemaal gelukkig zijn....
Regenboog, regenboog
gelukkig ben je krom,
anders heette je regenstreep,
en dat klinkt toch wel zo stom
gelukkig ben je krom,
anders heette je regenstreep,
en dat klinkt toch wel zo stom
recode naar 1-2 op de dv van het land, geef ze 0 op de dv's die ze niet hebben en tel dan de 4 kolommen op voor de overkoepelende dv?quote:
Hallo mensen!
Ik hoop dat iemand hier mij kan helpen met mijn vraag.
Ik doe een onderzoekje met een dataset waarin respondenten uit vier landen zitten.
Er is een variabele die ik heb bewerkt, en uiteindelijk omgezet naar een dichotome variabele. Dit heb ik per land gedaan, omdat de oorspronkelijke categorieen in de verschillende landen niet met elkaar te vergelijken waren.
Ik heb nu dus vier dichotome variabelen, per land. Elke respondent komt dus ook maar één keer voor in al deze vier variabelen.
Nu wil ik er eigenlijk weer één variabele van maken. Iedereen heeft nu eenzelfde score (1 of 0), dus ik denk dat dit wel mogelijk is.
Maar hoe moet ik dit doen?
Ik werk trouwens met SPSS Syntax, dus als iemand er ook nog eens een syntax code voor zou weten zou ik helemaal gelukkig zijn....
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Mijn statistiekkennis is nogal weggezakt, dus vandaar de volgende vraag:
Ik wil het effect van de verandering van een variabele onderzoeken. Ik heb in principe twee tijdsperiodes: zeg maar bijvoorbeeld oktober - december 2011 - 2013 (dus 3 tijdsperiodes) en 2012 en 2013 helemaal (dus 2 tijdsperiodes). Je moet dit onderzoek zien als een experiment.
Tussentijds is (dit is een voorbeeldje) 3x het loon gestegen. Stel ik zou willen onderzoeken of dit effect heeft op de arbeidsproductiviteit, hoe pak ik dit dan aan? Voor een panel analysis is de tijdsperiode te kort. Hoe kan ik het beste het effect van deze variabele over de tijd onderzoeken? En als ik wil weten of er verschil is tussen mannen en vrouwen?
Bedankt!
Ik wil het effect van de verandering van een variabele onderzoeken. Ik heb in principe twee tijdsperiodes: zeg maar bijvoorbeeld oktober - december 2011 - 2013 (dus 3 tijdsperiodes) en 2012 en 2013 helemaal (dus 2 tijdsperiodes). Je moet dit onderzoek zien als een experiment.
Tussentijds is (dit is een voorbeeldje) 3x het loon gestegen. Stel ik zou willen onderzoeken of dit effect heeft op de arbeidsproductiviteit, hoe pak ik dit dan aan? Voor een panel analysis is de tijdsperiode te kort. Hoe kan ik het beste het effect van deze variabele over de tijd onderzoeken? En als ik wil weten of er verschil is tussen mannen en vrouwen?
Bedankt!
Begrijp ik het goed dat je hoogstens 3 periodes hebt met verschillende lonen?quote:
Mijn statistiekkennis is nogal weggezakt, dus vandaar de volgende vraag:
Ik wil het effect van de verandering van een variabele onderzoeken. Ik heb in principe twee tijdsperiodes: zeg maar bijvoorbeeld oktober - december 2011 - 2013 (dus 3 tijdsperiodes) en 2012 en 2013 helemaal (dus 2 tijdsperiodes). Je moet dit onderzoek zien als een experiment.
Tussentijds is (dit is een voorbeeldje) 3x het loon gestegen. Stel ik zou willen onderzoeken of dit effect heeft op de arbeidsproductiviteit, hoe pak ik dit dan aan? Voor een panel analysis is de tijdsperiode te kort. Hoe kan ik het beste het effect van deze variabele over de tijd onderzoeken? En als ik wil weten of er verschil is tussen mannen en vrouwen?
Bedankt!
[ Bericht 0% gewijzigd door #ANONIEM op 17-05-2016 15:54:31 ]
Oh sorry, dat was ik vergeten te vermelden. Ik heb rond de 1300 bruikbare observaties (totaal circa 1600).
Heb je al gewoon een regressie gedraaid met als moderator geslacht?quote:
Oh sorry, dat was ik vergeten te vermelden. Ik heb rond de 1300 bruikbare observaties (totaal circa 1600).
Nee, ik heb nog niets uitgevoerd. Voor het scriptievoorstel moet ik de methode beschrijven, dus ik probeer erachter te komen welke statistische analyse ik precies moet uitvoeren.
Drukke dag gehad dus misschien zeg ik domme dingen, MCH zal dat dan wel laten weten.
Fixed effects? Elk persoon telt dan 2x als observatie met de verschillen tussen 2011-2012 en 2012-2013 als input. Al kan je dan niet dingen als geslacht doen omdat deze niet veranderen.
Heb je ook personen die geen opslag kregen? Dan Difference in differeces? Groepen 2011-2012 en 2012-2013,maak een dummy (periode) waarbij het eerst jaar 0 is en het tweede 1, maak een dummy voor opslag of niet tussen periode 0 en 1. Zet dit allemaal onder elkaar, dus elke persoon twee keer. Doe de regressie op output = periode, opslag, periode*opslag, (ln)salaris (en andere variabelen die je hebt). De interactie is waar je dan naar kijkt. Is die significant en positief dan heeft het krijgen van een opslag een positie effect op de output van de komende periode.
___
Maar wellicht is er een reden waarom mensen opslag krijgen, bijvoorbeeld omdat ze de periode ervoor heel erg productief waren? Dan zou je bijvoorbeeld de productiviteit van de periode ervoor als lag kunnen toevoegen.
[ Bericht 9% gewijzigd door Zith op 17-05-2016 19:41:10 ]
Fixed effects? Elk persoon telt dan 2x als observatie met de verschillen tussen 2011-2012 en 2012-2013 als input. Al kan je dan niet dingen als geslacht doen omdat deze niet veranderen.
Heb je ook personen die geen opslag kregen? Dan Difference in differeces? Groepen 2011-2012 en 2012-2013,maak een dummy (periode) waarbij het eerst jaar 0 is en het tweede 1, maak een dummy voor opslag of niet tussen periode 0 en 1. Zet dit allemaal onder elkaar, dus elke persoon twee keer. Doe de regressie op output = periode, opslag, periode*opslag, (ln)salaris (en andere variabelen die je hebt). De interactie is waar je dan naar kijkt. Is die significant en positief dan heeft het krijgen van een opslag een positie effect op de output van de komende periode.
___
Maar wellicht is er een reden waarom mensen opslag krijgen, bijvoorbeeld omdat ze de periode ervoor heel erg productief waren? Dan zou je bijvoorbeeld de productiviteit van de periode ervoor als lag kunnen toevoegen.
[ Bericht 9% gewijzigd door Zith op 17-05-2016 19:41:10 ]
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Hi,
Ik ben momenteel bezig met analyse van robuustheid resultaten. Nu wil ik outliers eruit filteren/ervoor controllen, maar zie ik door de bomen het bos niet meer.
Ik heb daarom een aantal vragen
1. Wat is het verschil tussen outliers en influential factors, en waar kan ik me beter op focussen?
2. Mahalanobis concentreert zich alleen op multivariate outliers. Moet ik nog iets doen met dependent variable?
3. Winsorizen: er wordt vaak gesproken over winsorizen op 5% level aan beide kanten. Moet dit worden gedaan voor zowel X als Y variabele?
4. Welke outlier detection/removal technique gebruiken jullie altijd. Ik zie bijv ook nog: Leverage, Cook's, Trimming, Hat's, Likelihood, etc.
5. Hoe zit het met outliers van indicator variables/dummies. Bijv Mahalanobis haalt 1 hele variabele weg die 4x voorkomt. Is dit wel juist? Of moet ik alleen outliers checken op niet-dummies?
Thanks in advance!
Ik ben momenteel bezig met analyse van robuustheid resultaten. Nu wil ik outliers eruit filteren/ervoor controllen, maar zie ik door de bomen het bos niet meer.
Ik heb daarom een aantal vragen
1. Wat is het verschil tussen outliers en influential factors, en waar kan ik me beter op focussen?
2. Mahalanobis concentreert zich alleen op multivariate outliers. Moet ik nog iets doen met dependent variable?
3. Winsorizen: er wordt vaak gesproken over winsorizen op 5% level aan beide kanten. Moet dit worden gedaan voor zowel X als Y variabele?
4. Welke outlier detection/removal technique gebruiken jullie altijd. Ik zie bijv ook nog: Leverage, Cook's, Trimming, Hat's, Likelihood, etc.
5. Hoe zit het met outliers van indicator variables/dummies. Bijv Mahalanobis haalt 1 hele variabele weg die 4x voorkomt. Is dit wel juist? Of moet ik alleen outliers checken op niet-dummies?
Thanks in advance!
Omdat het geen psychologisch onderzoek is, maar waargebeurde financial events. Dan kan ikk niet zeggen: oh die is me wat te hoog, dan negeer/corrigeer ik die.quote:
Hoezo ga je na je uitkomsten en tijdens je robustness checks pas kijken naar je outliers?
Is dit voor een scriptie oid of moet het echt een paper worden uiteindelijk? In dat tweede geval zou ik, als het niet al te laat is, eerst je plan opstellen, dit vastleggen en dan pas naar de data kijken. Nu loop je het risico (on)bewust je uitkomsten te beinvloeden.quote:
[..]
Omdat het geen psychologisch onderzoek is, maar waargebeurde financial events. Dan kan ikk niet zeggen: oh die is me wat te hoog, dan negeer/corrigeer ik die.
Wat je moet gebruiken ligt heel erg aan het type data en kan ik weinig over zeggen op basis van de beperkte informatie.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik beinvloed niet.quote:
[..]
Is dit voor een scriptie oid of moet het echt een paper worden uiteindelijk? In dat tweede geval zou ik, als het niet al te laat is, eerst je plan opstellen, dit vastleggen en dan pas naar de data kijken. Nu loop je het risico (on)bewust je uitkomsten te beinvloeden.
Wat je moet gebruiken ligt heel erg aan het type data en kan ik weinig over zeggen op basis van de beperkte informatie.
Cook's Distance <1 voor alle observations
Winsorizing 5% geeft tevens geen verandering in results.
Wat had je gedaan als het wel een verschil zou maken?quote:
[..]
Ik beinvloed niet.
Cook's Distance <1 voor alle observations
Winsorizing 5% geeft tevens geen verandering in results.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ook gerapporteerd. Mn initiele event window geeft ook insignificantie.quote:
[..]
Wat had je gedaan als het wel een verschil zou maken?
Mn p-value neemt wel af van <0.05 naar <0.10 na winsorizen, de ander blijft constant.
Ja dan moet je nu dus beslissen wat je hoofdconclusie is / wat de beste methode is (met of zonder winsor) terwijl je al weet wat dat voor je uitkomsten doet...quote:
[..]
Ook gerapporteerd. Mn initiele event window geeft ook insignificantie.
Mn p-value neemt wel af van <0.05 naar <0.10 na winsorizen, de ander blijft constant.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik zie geen enkele reden om vooraf te winsorizen. Waarom zou je dat doen?quote:
[..]
Ja dan moet je nu dus beslissen wat je hoofdconclusie is / wat de beste methode is (met of zonder winsor) terwijl je al weet wat dat voor je uitkomsten doet...
Niet van te voren doen, van te voren bepalen of je het gaat doen of niet.quote:
[..]
Ik zie geen enkele reden om vooraf te winsorizen. Waarom zou je dat doen?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik heb een vraag omtrent Stata.
Ik heb een data base met verschillende regios en verschillende jaren.
Ik heb een model waar de GDP wordt beinvloed door Investments, Labor force, Unemployment, Educatie, Internet variabelen (internet penetratie) en populatie density.
Dit is een panel set analyse en ik moet uitzoeken wat het effect is van de internet variabelen.
Echter weet ik niet wat de juiste stappen zijn die ik moet ondernemen.
Graag zou ik beginnen alle variabelen naar growth variabelen te zetten. Echter kom ik er gewoon niet uit icm data panel set.
Als iemand hier goed is in STATA contacteer mij dan alsjeblieft.
Ik heb een data base met verschillende regios en verschillende jaren.
Ik heb een model waar de GDP wordt beinvloed door Investments, Labor force, Unemployment, Educatie, Internet variabelen (internet penetratie) en populatie density.
Dit is een panel set analyse en ik moet uitzoeken wat het effect is van de internet variabelen.
Echter weet ik niet wat de juiste stappen zijn die ik moet ondernemen.
Graag zou ik beginnen alle variabelen naar growth variabelen te zetten. Echter kom ik er gewoon niet uit icm data panel set.
Als iemand hier goed is in STATA contacteer mij dan alsjeblieft.
Dit is nou niet echt een specifieke vraag over STATA. Denk dat je in plaats van op "stata", moet gaan googlen op "statistiek".quote:
Ik heb een vraag omtrent Stata.
Ik heb een data base met verschillende regios en verschillende jaren.
Ik heb een model waar de GDP wordt beinvloed door Investments, Labor force, Unemployment, Educatie, Internet variabelen (internet penetratie) en populatie density.
Dit is een panel set analyse en ik moet uitzoeken wat het effect is van de internet variabelen.
Echter weet ik niet wat de juiste stappen zijn die ik moet ondernemen.
Graag zou ik beginnen alle variabelen naar growth variabelen te zetten. Echter kom ik er gewoon niet uit icm data panel set.
Als iemand hier goed is in STATA contacteer mij dan alsjeblieft.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Dankjewel voor je meedenken!quote:
[..]
recode naar 1-2 op de dv van het land, geef ze 0 op de dv's die ze niet hebben en tel dan de 4 kolommen op voor de overkoepelende dv?
Ik heb uiteindelijk één van de variabele gekopieerd, en deze met behulp van een serie if-jes gehercodeerd.
Erg omslachtig, maar uiteindelijk is het goed gekomen
Regenboog, regenboog
gelukkig ben je krom,
anders heette je regenstreep,
en dat klinkt toch wel zo stom
gelukkig ben je krom,
anders heette je regenstreep,
en dat klinkt toch wel zo stom
Ik neem aan dat dit voor je bachelor scriptie is? (Gezien het scriptie topic.) Aangezien je geen enkel idee lijkt te hebben wat je moet doen lijkt het me handig als je je statistiekboeken raadpleegt, aangezien mensen hier best willen helpen, maar niet alles gaan voorkauwen.quote:
Ik heb een vraag omtrent Stata.
Ik heb een data base met verschillende regios en verschillende jaren.
Ik heb een model waar de GDP wordt beinvloed door Investments, Labor force, Unemployment, Educatie, Internet variabelen (internet penetratie) en populatie density.
Dit is een panel set analyse en ik moet uitzoeken wat het effect is van de internet variabelen.
Echter weet ik niet wat de juiste stappen zijn die ik moet ondernemen.
Graag zou ik beginnen alle variabelen naar growth variabelen te zetten. Echter kom ik er gewoon niet uit icm data panel set.
Als iemand hier goed is in STATA contacteer mij dan alsjeblieft.
Goedemiddag. Ik ben bezig mijn resultaten in te voeren in SPSS. Ik heb het boek Handleiding SPSS voor mij liggen maar heb een vraag.
Mijn enquête bestaat uit 30 vragen. Bij een aantal vragen kan het voorkomen dat je door het geven van een antwoord de eerstvolgende vragen overslaat (omdat je daar door het antwoord niet meer voor in aanmerking komt) en verder gaat bij bijv. 5 vragen verder op. Dan kom je dus met een vijftal vragen te zitten die blanco blijven. Hoe voer ik dit in in SPSS?
Moet ik het desbetreffende vakje voor de 'overgeslagen' vragen in de Data View helemaal leeg laten?
Ik zal het verduidelijken met een eenvoudig voorbeeld, stel:
Vraag 1: Naam
Vraag 2: Antwoord
Vraag 3: Krijg je zakgeld (Ja, ga naar vraag 4 - Nee, ga naar vraag 5)
Vraag 4: Hoeveel zakgeld krijg je?
Vraag 5: Waar geef je je zakgeld aan uit?
Dus, iemand vult bij vraag 3 'Nee' in en gaat dus naar vraag 5 en slaat vraag 4 over. Wat vul ik in SPSS in als 'antwoord' bij vraag 4 voor deze respondent?
[ Bericht 26% gewijzigd door carebaer op 21-05-2016 17:43:49 ]
Mijn enquête bestaat uit 30 vragen. Bij een aantal vragen kan het voorkomen dat je door het geven van een antwoord de eerstvolgende vragen overslaat (omdat je daar door het antwoord niet meer voor in aanmerking komt) en verder gaat bij bijv. 5 vragen verder op. Dan kom je dus met een vijftal vragen te zitten die blanco blijven. Hoe voer ik dit in in SPSS?
Moet ik het desbetreffende vakje voor de 'overgeslagen' vragen in de Data View helemaal leeg laten?
Ik zal het verduidelijken met een eenvoudig voorbeeld, stel:
Vraag 1: Naam
Vraag 2: Antwoord
Vraag 3: Krijg je zakgeld (Ja, ga naar vraag 4 - Nee, ga naar vraag 5)
Vraag 4: Hoeveel zakgeld krijg je?
Vraag 5: Waar geef je je zakgeld aan uit?
Dus, iemand vult bij vraag 3 'Nee' in en gaat dus naar vraag 5 en slaat vraag 4 over. Wat vul ik in SPSS in als 'antwoord' bij vraag 4 voor deze respondent?
[ Bericht 26% gewijzigd door carebaer op 21-05-2016 17:43:49 ]
?quote:
Goedemiddag. Ik ben bezig mijn resultaten in te voeren in SPSS. Ik heb het boek Handleiding SPSS voor mij liggen maar heb een vraag.
Mijn enquête bestaat uit 30 vragen. Bij een aantal vragen kan het voorkomen dat je door het geven van een antwoord de eerstvolgende vragen overslaat (omdat je daar door het antwoord niet meer voor in aanmerking komt) en verder gaat bij bijv. 5 vragen verder op. Dan kom je dus met een vijftal vragen te zitten die blanco blijven. Hoe voer ik dit in in SPSS?
Moet ik het desbetreffende vakje voor de 'overgeslagen' vragen in de Data View helemaal leeg laten?
Ik zal het verduidelijken met een eenvoudig voorbeeld, stel:
Vraag 1: Naam
Vraag 2: Antwoord
Vraag 3: Krijg je zakgeld (Ja, ga naar vraag 4 - Nee, ga naar vraag 5)
Vraag 4: Hoeveel zakgeld krijg je?
Vraag 5: Waar geef je je zakgeld aan uit?
Dus, iemand vult bij vraag 3 'Nee' in en gaat dus naar vraag 5 en slaat vraag 4 over. Wat vul ik in SPSS in als 'antwoord' bij vraag 4 voor deze respondent?

Super, precies wat ik bedoelde. Kan dus n.v.t. gebruiken!quote:
Inmiddels heb ik alle gegevens/variabelen ingevuld. Stuit ik weer op een probleem.
Ik heb op den duur een vraag waar mensen een bedrag moeten invullen, en ik heb deze gezet op ratio-niveau. Maar het kan ook voorkomen dat de vraag n.v.t. is op iemand.
Hoe kan ik er voor zorgen dat er een 'code' n.v.t. komt te staan bij iemand die de vraag niet hoeft in te vullen, maar wel een getal voor de mensen die een bedrag invullen?
Ik heb op den duur een vraag waar mensen een bedrag moeten invullen, en ik heb deze gezet op ratio-niveau. Maar het kan ook voorkomen dat de vraag n.v.t. is op iemand.
Hoe kan ik er voor zorgen dat er een 'code' n.v.t. komt te staan bij iemand die de vraag niet hoeft in te vullen, maar wel een getal voor de mensen die een bedrag invullen?
Ik zou ze gewoon leeglaten eigenlijk. Dan kun je een missing value instellen voor de mensen die die vraag onterecht hebben leeggelaten (in de variable view).quote:
Inmiddels heb ik alle gegevens/variabelen ingevuld. Stuit ik weer op een probleem.
Ik heb op den duur een vraag waar mensen een bedrag moeten invullen, en ik heb deze gezet op ratio-niveau. Maar het kan ook voorkomen dat de vraag n.v.t. is op iemand.
Hoe kan ik er voor zorgen dat er een 'code' n.v.t. komt te staan bij iemand die de vraag niet hoeft in te vullen, maar wel een getal voor de mensen die een bedrag invullen?
Oke. Is het onmogelijk om nominale + ratio antwoorden te combineren in één vraag?quote:
[..]
Ik zou ze gewoon leeglaten eigenlijk. Dan kun je een missing value instellen voor de mensen die die vraag onterecht hebben leeggelaten (in de variable view).
SPSS zal een variabele altijd als één soort variabele zien en in die zin kun je nominaal en ratio niet combineren. Je kunt wel bij ratio een extra code/label aanmaken dat bijvoorbeeld 99 niet van toepassing betekent, maar de vraag is een beetje wat je er aan hebt. Als je de cel leeglaat kun je gewoon de analyses doen met de beschikbare data en als je NVT invult moet je die toch weer uitsluiten van je analyse later. Daarnaast kun je het percentage NVT gewoon berekenen met het antwoord op de vraag die de NVT als gevolg heeft.quote:
[..]
Oke. Is het onmogelijk om nominale + ratio antwoorden te combineren in één vraag?
Ik snap het. Zou je me kunnen vertellen waar ik die uitzondering toevoeg? Als leek met SPSS vind ik het toch wel handig om in het overzicht van de data die extra nvt toe te voegenquote:
[..]
SPSS zal een variabele altijd als één soort variabele zien en in die zin kun je nominaal en ratio niet combineren. Je kunt wel bij ratio een extra code/label aanmaken dat bijvoorbeeld 99 niet van toepassing betekent, maar de vraag is een beetje wat je er aan hebt. Als je de cel leeglaat kun je gewoon de analyses doen met de beschikbare data en als je NVT invult moet je die toch weer uitsluiten van je analyse later. Daarnaast kun je het percentage NVT gewoon berekenen met het antwoord op de vraag die de NVT als gevolg heeft.
Je kiest voor NVT een waarde uit die niet in die variabele voorkomt als 'echte' waarde. Dus stel dat je ratio variabele scores heeft tussen 0 en 10, dan kun je vanaf 11 een willekeurige waarde kiezen. Die waarde vul je in bij de cellen die NVT zijn in die variabele. Vervolgens kun je in Variable View in het kopje Values aangeven wat elke waarde betekent. Dus stel 11 is NVT, dan kun je dat daar invullen en toevoegen.quote:
[..]
Ik snap het. Zou je me kunnen vertellen waar ik die uitzondering toevoeg? Als leek met SPSS vind ik het toch wel handig om in het overzicht van de data die extra nvt toe te voegen
Als je dan in je Data View NVT wil zien in plaats van 11, klik je op het icoontje met '1' en 'A' met een pijl ertussen, dan zie je de labels die je aan de values hebt gegeven in plaats van de getalletjes. (En je kunt er wel mee blijven rekenen.)
Ah het werkt net als bij nominaal en ordinaal zie ik inderdaad, je kan het gewoon toeveogen. Thanks!quote:
[..]
Je kiest voor NVT een waarde uit die niet in die variabele voorkomt als 'echte' waarde. Dus stel dat je ratio variabele scores heeft tussen 0 en 10, dan kun je vanaf 11 een willekeurige waarde kiezen. Die waarde vul je in bij de cellen die NVT zijn in die variabele. Vervolgens kun je in Variable View in het kopje Values aangeven wat elke waarde betekent. Dus stel 11 is NVT, dan kun je dat daar invullen en toevoegen.
Als je dan in je Data View NVT wil zien in plaats van 11, klik je op het icoontje met '1' en 'A' met een pijl ertussen, dan zie je de labels die je aan de values hebt gegeven in plaats van de getalletjes. (En je kunt er wel mee blijven rekenen.)
Eindelijk kan ik mijn data is kruistabellen gaan analyseren en in mijn rapport zetten. Nu kom ik weer een probleem tegen. Wat is SPSS toch een fijn programma...
Als ik een kruistabel kopieer en in word plak, valt het rechterdeel van de tabel buiten de breedte van het word bestand. Ik kan 'm ook niet verkleinen. Hoe zorg ik er voor dat het tabel schaalt met word zodat hij volledig leesbaar is?
Ik heb het zowel geprobeerd met kopiëren plakken als met exporteren naar word. Beide manieren zorgen voor dezelfde problemen. Sterker nog: zodra ik het exporteer naar word worden de tabellen in tweeën gesplitst in sommige gevallen.
Als ik een kruistabel kopieer en in word plak, valt het rechterdeel van de tabel buiten de breedte van het word bestand. Ik kan 'm ook niet verkleinen. Hoe zorg ik er voor dat het tabel schaalt met word zodat hij volledig leesbaar is?
Ik heb het zowel geprobeerd met kopiëren plakken als met exporteren naar word. Beide manieren zorgen voor dezelfde problemen. Sterker nog: zodra ik het exporteer naar word worden de tabellen in tweeën gesplitst in sommige gevallen.
Ah helaas. Ik heb vannacht de deadline voor concept en hierna heb ik nog 2 weken voor definitief. Dan heb ik aan tijd om alles netjes te maken, maar voor nu wil ik de tabellen zo snel mogelijk naar word hebben. Dan eerst maar even met printscreen denk ik..quote:
Maak je eigen tabel. SPSS output in je scriptie.
Dus even exporteren naar excel.
Edit: Ik vind het toch wel vreemd dat SPSS of Word het niet zo maken dat dit makkelijk te kopiëren en te plakken is, sinds efficiëntie in onze samenleving zo belangrijk is
Stiekem is SPSS echt een bizar slecht programma, alleen omdat het zo wordt aangeleerd valt het niet zo op.quote:
[..]
Ah helaas. Ik heb vannacht de deadline voor concept en hierna heb ik nog 2 weken voor definitief. Dan heb ik aan tijd om alles netjes te maken, maar voor nu wil ik de tabellen zo snel mogelijk naar word hebben. Dan eerst maar even met printscreen denk ik..
Edit: Ik vind het toch wel vreemd dat SPSS of Word het niet zo maken dat dit makkelijk te kopiëren en te plakken is, sinds efficiëntie in onze samenleving zo belangrijk is
Doe ik. Bedankt voor je hulp en vlotte reactie!quote:
Focus je nu maar op de deadline. Dan maak je het voor de finale versie allemaal mooi.
Eens, ik probeer ook zoveel mogelijk in R te doen. Maar vandaag ben ik weer zielsgelukkig met SPSS en de fantastische restructure-functie.quote:
[..]
Stiekem is SPSS echt een bizar slecht programma,
[...]
Aldus.
Wat doet dat ook alweer?quote:Op maandag 23 mei 2016 17:05 schreef Z het volgende:
[..]
Eens, ik probeer ook zoveel mogelijk in R te doen. Maar vandaag ben ik weer zielsgelukkig met SPSS en de fantastische restructure-functie.
Er zijn meerdere opties. Je kan van cases variabelen en van variabelen cases. Databestanden herstructureren dus.quote:
Aldus.
Ahzo, ja dat gaat makkelijker in SPSS dan R ja.quote:
[..]
Er zijn meerdere opties. Je kan van cases variabelen en van variabelen cases. Databestanden herstructureren dus.
Ik heb ook een vraag omdat ik vastloop met mn master thesis.
Voor mijn (uiteindelijk 3-way) ANOVA heb ik een independent variable (type of assortment) die bestaat uit 2 nominale variabelen (evidently equivalent en non equivalent). Deze variabele is echter niet gecodeerd in SPSS omdat iedere participant vragen heeft beantwoord over beide types of assortment.
Met een andere independent variable behoren participanten wel gewoon tot één van de twee nominale groepen (whether they have a broad or narrow scope of attention) en kan ik wel gewoon een ANOVA uitvoeren.
Hoe moet ik nu verder? Moet ik een dummy variable creëren? En op basis van welke data? Ik kreeg als tip dat ik misschien een nieuwe dataset moest creëren en dan de data van het ene assortiment onder dat van het andere assortiment te plakken. Maar hoe zou dit er dan uit komen te zien?
Ik hoop dat het een beetje duidelijk is
Voor mijn (uiteindelijk 3-way) ANOVA heb ik een independent variable (type of assortment) die bestaat uit 2 nominale variabelen (evidently equivalent en non equivalent). Deze variabele is echter niet gecodeerd in SPSS omdat iedere participant vragen heeft beantwoord over beide types of assortment.
Met een andere independent variable behoren participanten wel gewoon tot één van de twee nominale groepen (whether they have a broad or narrow scope of attention) en kan ik wel gewoon een ANOVA uitvoeren.
Hoe moet ik nu verder? Moet ik een dummy variable creëren? En op basis van welke data? Ik kreeg als tip dat ik misschien een nieuwe dataset moest creëren en dan de data van het ene assortiment onder dat van het andere assortiment te plakken. Maar hoe zou dit er dan uit komen te zien?
Ik hoop dat het een beetje duidelijk is
Kun je dit eens uitleggen. Je hebt een variabele die bestaat uit twee variabelen?quote:
Voor mijn (uiteindelijk 3-way) ANOVA heb ik een independent variable (type of assortment) die bestaat uit 2 nominale variabelen (evidently equivalent en non equivalent). Deze variabele is echter niet gecodeerd in SPSS omdat iedere participant vragen heeft beantwoord over beide types of assortment.
Excuses, ik bedoel dat die variabele bestaat uit 2 groepen.quote:
[..]
Kun je dit eens uitleggen. Je hebt een variabele die bestaat uit twee variabelen?
mijn variabele is dus 'type of assortment' en mijn groups zijn 'evidently equivalent' en 'non equivalent' .quote:Assumption #2: Your three independent variables should each consist of two or more categorical, independent groups. Example independent variables that meet this criterion include gender (two groups: male or female), ethnicity (three groups: Caucasian, African American and Hispanic), profession (five groups: surgeon, doctor, nurse, dentist, therapist), and so forth.
Dus eigenlijk heb je maar twee independent variabelen: type of assortment (evidently equi en non equi) en attention (broad or narrow)?quote:
[..]
Excuses, ik bedoel dat die variabele bestaat uit 2 groepen.
[..]
mijn variabele is dus 'type of assortment' en mijn groups zijn 'evidently equivalent' en 'non equivalent' .
Plus nog een derde, motivational orientation. die ook weer bestaat uit 2 groups.quote:
[..]
Dus eigenlijk heb je maar twee independent variabelen: type of assortment (evidently equi en non equi) en attention (broad or narrow)?
Alleen van die variabele type of assortment snap ik dus niet hoe ik hem mee moet nemen in de ANOVA omdat alle respondenten dus vragen hebben beantwoord over beide groepen. De andere 2 variabelen hebben dat niet, alle respondenten vallen hierbij netjes in 1 van de 2 categorieën.
Dus je hebt dit probleem?quote:
[..]
Plus nog een derde, motivational orientation. die ook weer bestaat uit 2 groups.
Alleen van die variabele type of assortment snap ik dus niet hoe ik hem mee moet nemen in de ANOVA omdat alle respondenten dus vragen hebben beantwoord over beide groepen. De andere 2 variabelen hebben dat niet, alle respondenten vallen hierbij netjes in 1 van de 2 categorieën.
Assumption #3: You should have independence of observations, which means that there is no relationship between the observations in each group or between the groups themselves. For example, there must be different participants in each group with no participant being in more than one group. This is more of a study design issue than something you would test for, but it is an important assumption of the three-way ANOVA. If your study fails this assumption, you will need to use another statistical test instead of the three-way ANOVA (e.g., a repeated measures design). If you are unsure whether your study meets this assumption, you can use our Statistical Test Selector, which is part of our enhanced guides.
Ik stel trouwens voor dat iedereen voortaan z'n conceptuele model hier ook post. Dat maakt vragen beantwoorden vaak wat makkelijker.
Stargazer.quote:
Maak je eigen tabel. SPSS output in je scriptie.
Dus even exporteren naar excel.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ik lees het nu. Maar die tip/hint die ik van mijn begeleider kreeg dan? Een nieuwe dataset creëren? Is er iemand die hier iets meer over weet? Het zou toch echt met een three-way ANOVA moeten kunnen blijkbaar.quote:
[..]
Dus je hebt dit probleem?
Assumption #3: You should have independence of observations, which means that there is no relationship between the observations in each group or between the groups themselves. For example, there must be different participants in each group with no participant being in more than one group. This is more of a study design issue than something you would test for, but it is an important assumption of the three-way ANOVA. If your study fails this assumption, you will need to use another statistical test instead of the three-way ANOVA (e.g., a repeated measures design). If you are unsure whether your study meets this assumption, you can use our Statistical Test Selector, which is part of our enhanced guides.
Heb je nou een fout gemaakt in je questionnaire? Mensen konden het assortiment tegelijk evidently equivalent en non equivalent vinden?quote:
[..]
Ik lees het nu. Maar die tip/hint die ik van mijn begeleider kreeg dan? Een nieuwe dataset creëren? Is er iemand die hier iets meer over weet? Het zou toch echt met een three-way ANOVA moeten kunnen blijkbaar.
Het enige wat ik kan bedenken is dat je een variabele aanmaakt met 0 als ze beide 0 hebben, 1 als 1 van de opties, 2 de andere optie en 3 als ze beide opties hebben aangekruist.

Dat is een package voor R die je output omzet naar LaTeX-code. Werkt fantastisch.quote:
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
newmatrix <- t(matrix). Moet je je dataset wel even als matrix lezen.quote:
[..]
Ahzo, ja dat gaat makkelijker in SPSS dan R ja.
Als ik het goed begrijp, is het probleem dat de variabele "type of assortment" ongestructureerd is, omdat deze bestaat uit de antwoorden op een open vraag? Dat betekent dat je deze zal moeten coderen. Open je dataset in Excel, stel codes op voor de verschillende antwoordcategorieën en codeer vervolgens alle antwoorden die je hebt gekregen in een nieuwe, lege kolom. Zeker voor een scriptie zal dat moeten volstaan.quote:
[..]
Ik lees het nu. Maar die tip/hint die ik van mijn begeleider kreeg dan? Een nieuwe dataset creëren? Is er iemand die hier iets meer over weet? Het zou toch echt met een three-way ANOVA moeten kunnen blijkbaar.
Het zijn geen open vragen. Voor deze variabele heb ik voor beide groepen (beide assortimenten dus) een figuur met hierop verschillende producten. Van deze producten moet men er 1 uitkiezen. En dat dan voor beide assortimenten. Het product dat je omcirkelt is dan de 'location of product' (mijn dependent variable). Ik wil dus onderzoeken of er een verschil zit tussen de 2 verschillende assortimenten en de location of products die mensen kiezen.quote:
[..]
Als ik het goed begrijp, is het probleem dat de variabele "type of assortment" ongestructureerd is, omdat deze bestaat uit de antwoorden op een open vraag? Dat betekent dat je deze zal moeten coderen. Open je dataset in Excel, stel codes op voor de verschillende antwoordcategorieën en codeer vervolgens alle antwoorden die je hebt gekregen in een nieuwe, lege kolom. Zeker voor een scriptie zal dat moeten volstaan.
Maar iedere respondent heeft dus voor beide assortimenten een product omcirkelt, waardoor ik nu niet kan zeggen: respondent 1 valt voor de variabele type of assortment in groep 1 of 2. Dit kan wel bij "normale" variabelen in een ANOVA.
Dan moet je een nieuwe variabele creëren die controleert of keuze bij assortiment A en keuze bij assortiment B gelijk dan wel ongelijk is. Zowel in R als in SPSS vergt dit een klein beetje syntax.quote:
[..]
Het zijn geen open vragen. Voor deze variabele heb ik voor beide groepen (beide assortimenten dus) een figuur met hierop verschillende producten. Van deze producten moet men er 1 uitkiezen. En dat dan voor beide assortimenten. Het product dat je omcirkelt is dan de 'location of product' (mijn dependent variable). Ik wil dus onderzoeken of er een verschil zit tussen de 2 verschillende assortimenten en de location of products die mensen kiezen.
Maar iedere respondent heeft dus voor beide assortimenten een product omcirkelt, waardoor ik nu niet kan zeggen: respondent 1 valt voor de variabele type of assortment in groep 1 of 2. Dit kan wel bij "normale" variabelen in een ANOVA.
Gewoon handmatig gaat denk ik sneller met zo´n studentenenquete.quote:
[..]
Dan moet je een nieuwe variabele creëren die controleert of keuze bij assortiment A en keuze bij assortiment B gelijk dan wel ongelijk is. Zowel in R als in SPSS vergt dit een klein beetje syntax.

Leer ze nou niet het verkeerde aan. Syntax is altijd beter.quote:
[..]
Gewoon handmatig gaat denk ik sneller met zo´n studentenenquete.
Aldus.
Ik heb een sterk vermoeden dat de vraagsteller weinig syntaxen of uberhaupt statistiek nodig heeft in z'n verdere beroepsleven.quote:Op donderdag 26 mei 2016 12:58 schreef Z het volgende:
[..]
Leer ze nou niet het verkeerde aan. Syntax is altijd beter.
Studeert PlukvdP Marketing in Groningen?
[ Bericht 0% gewijzigd door #ANONIEM op 26-05-2016 13:16:49 ]
[ Bericht 0% gewijzigd door #ANONIEM op 26-05-2016 13:16:49 ]
Nog bedankt voor de eerdere reactie.
Ik heb inmiddels een model kunnen maken.
Ik gebruik panel data over een 3 jarige periode en 30 regio's. Ik heb GDP en GDP growth als dependent variables. Bij GDP klinkt alles vrij logisch, de variabelen die effect zouden moeten hebben zijn significant. Echter bij GDP growth is het een compleet ander verhaal. Ik ben vrij zeker van m'n GDP growth variabelen, dat zij de juiste waardes hebben. Ik heb dit zowel handmatig uitgerekend als via m'n software (STATA). Echter zijn de independent variables en control variables compleet onlogisch. Variables die een positief effect zouden moeten hebben, bijvoorbeeld het growth percentage van employment, unemployment (negatief), investeringen, import en export increase, nemen negatieve waardes aan! Verder zijn zij vrijwel allemaal negatief.
Ik snap er niks van, ik heb zowel een normale regressie gedaan, als een fixed en random effect regressie.
Heeft iemand dit wel eens meegemaakt? Dat de resultaten van de regressie totaal onverwacht zijn... Waar zou dit aan kunnen liggen?
Ik heb inmiddels een model kunnen maken.
Ik gebruik panel data over een 3 jarige periode en 30 regio's. Ik heb GDP en GDP growth als dependent variables. Bij GDP klinkt alles vrij logisch, de variabelen die effect zouden moeten hebben zijn significant. Echter bij GDP growth is het een compleet ander verhaal. Ik ben vrij zeker van m'n GDP growth variabelen, dat zij de juiste waardes hebben. Ik heb dit zowel handmatig uitgerekend als via m'n software (STATA). Echter zijn de independent variables en control variables compleet onlogisch. Variables die een positief effect zouden moeten hebben, bijvoorbeeld het growth percentage van employment, unemployment (negatief), investeringen, import en export increase, nemen negatieve waardes aan! Verder zijn zij vrijwel allemaal negatief.
Ik snap er niks van, ik heb zowel een normale regressie gedaan, als een fixed en random effect regressie.
Heeft iemand dit wel eens meegemaakt? Dat de resultaten van de regressie totaal onverwacht zijn... Waar zou dit aan kunnen liggen?
Dan heb je geen bewijs gevonden voor je hypothese?quote:
Heeft iemand dit wel eens meegemaakt? Dat de resultaten van de regressie totaal onverwacht zijn... Waar zou dit aan kunnen liggen?
Sign of the coefficient speelt ook een rol natuurlijk. Ga jij het maar uitleggen als b.v. advertising een negatief effect heeft op sales terwijl je logisch gezien natuurlijk een positief effect zal mogen verwachten.quote:
[..]
Dan heb je geen bewijs gevonden voor je hypothese?
Post je model / output en de VIF. Post ook een (screenshot van) correlatietabel. Er zijn verschillende redenen waarom een coefficient negatief kan worden terwijl je andersom verwacht, multicollinearity is daar een van. Aangezien je een economisch model probeert te maken waarin alles elkaar beinvloed lijkt me dat wel voor de hand liggend.
Probeer ook eens de variablen een voor een toe te voegen om te kijken hoe de coefficients veranderen in bijzijn van andere.
Probeer ook eens de variablen een voor een toe te voegen om te kijken hoe de coefficients veranderen in bijzijn van andere.
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Het is erger dan dat, de H0 wordt zo wel weerlegd, alleen niet op de manier die verwacht was.quote:
[..]
Dan heb je geen bewijs gevonden voor je hypothese?
Anyway - zo lang er geen info is over de betrouwbaarheid van het model (is er multicollinearity, endogeneity, homoscedasticity?) is het nog niet duidelijk of het model realistisch/betrouwbaar is.
Ik zou trouwens bij dit soort onderzoeken altijd beginnen met autoregressions, omdat de huidige GDP altijd zeer (95%+) afhankelijk is van de GDP t-1, t-2, , enz.. Als je niet de benodigde hoeveelheid data hebt hiervoor (veel tijdsperiodes) dan kan je GDP t-1 als lag toevoegen voor een snelle oplossing...
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!

Is dit hetzelfde?quote:
Ik zou trouwens bij dit soort onderzoeken altijd beginnen met autoregressions, omdat de huidige GDP altijd zeer (95%+) afhankelijk is van de GDP t-1, t-2, , enz.. Als je niet de benodigde hoeveelheid data hebt hiervoor (veel tijdsperiodes) dan kan je GDP t-1 als lag toevoegen voor een snelle oplossing...
Traditionally, the first-order autoregressive process (AR(1)) represented by (5.11)
has been the primary autocorrelation process considered in econometrics (Judge
et al. 1985, pp. 226–227). For annual data, the AR(1)-process is often sufficient
for models with autocorrelated disturbances (with the caveat that it may mask
other shortcomings in model specification).
Zeker in gevallen als GDP-groei zou ik ook al snel denken aan een algemeen gebrek aan statistische kracht (niet genoeg observaties) en gecorreleerde meetfouten (observaties beïnvloeden elkaar door omstandigheden).quote:
[..]
Het is erger dan dat, de H0 wordt zo wel weerlegd, alleen niet op de manier die verwacht was.
Anyway - zo lang er geen info is over de betrouwbaarheid van het model (is er multicollinearity, endogeneity, homoscedasticity?) is het nog niet duidelijk of het model realistisch/betrouwbaar is.
Ik zou trouwens bij dit soort onderzoeken altijd beginnen met autoregressions, omdat de huidige GDP altijd zeer (95%+) afhankelijk is van de GDP t-1, t-2, , enz.. Als je niet de benodigde hoeveelheid data hebt hiervoor (veel tijdsperiodes) dan kan je GDP t-1 als lag toevoegen voor een snelle oplossing...
http://imgur.com/97VD57L
Bedanktt
Dit is een model over 3 jaren met jaarlijkse data en 31 regios.
GRP = gross regional product
GRPcapgrowth = % groei in GRP capita
fixedinvesrgrowth = % groei in fixed asset investments
intusergrowth = % groei internet penetratie (internet gebruikers/populatie)
gcf = gross capital formation
higheducper = % van populatie die hoger onderwijs volgt
urbanunper = unemployment % in urban cities
grptert2 = grp tertiary/grp
popdensity = populatie density
Verder weet ik dit dit model niet optimaal is, en heb het met verschillende constructies geprobeerd maar allen geven soortgelijke resultaten.
Mijn normale non-groei model werkt wel heel goed. Maar alleen de growth werkt van geen meter. Bijvoorbeeld de R-squared van reg GRP fixedassetinvestments is 75%. Maar de R-squared van reg GRPgrowth fixedassetinvestmentsgrowth = 0.04%!
[ Bericht 64% gewijzigd door ScriptieIdee12345 op 27-05-2016 15:35:57 ]
Bedanktt
Dit is een model over 3 jaren met jaarlijkse data en 31 regios.
GRP = gross regional product
GRPcapgrowth = % groei in GRP capita
fixedinvesrgrowth = % groei in fixed asset investments
intusergrowth = % groei internet penetratie (internet gebruikers/populatie)
gcf = gross capital formation
higheducper = % van populatie die hoger onderwijs volgt
urbanunper = unemployment % in urban cities
grptert2 = grp tertiary/grp
popdensity = populatie density
Verder weet ik dit dit model niet optimaal is, en heb het met verschillende constructies geprobeerd maar allen geven soortgelijke resultaten.
Mijn normale non-groei model werkt wel heel goed. Maar alleen de growth werkt van geen meter. Bijvoorbeeld de R-squared van reg GRP fixedassetinvestments is 75%. Maar de R-squared van reg GRPgrowth fixedassetinvestmentsgrowth = 0.04%!
[ Bericht 64% gewijzigd door ScriptieIdee12345 op 27-05-2016 15:35:57 ]
Mij is verteld dat met panel data al die dingen worden verholpen door fixed en random effects, door middel van xtreg, fe en xtreg, re. Is dit onjuist?
Okay, je doet geen echte fixed effects want je zet de variablen die voor het fixed effects model zorgen niet vast
Zie http://www.jblumenstock.com/files/courses/econ174/FEModels.pdf vanaf Fixed effects regression in practice
Goed, ik zou het volgende doen:
Kies een paar variablen die je echt wil hebben en die niet echt gecorreleerd zijn (corr var1 var2 var3), werk hiermee met de volgende stappen :
-Maak dummy voor Year 2, Year 3. Probeer de reg met deze twee dummies en je gekozen v
variablen.
-Maak een dummy voor elke regio die je hebt behalve 1. Probeer de reg met de year dummies en deze dummies en je variabelen. ( stata command: tabulate regio, generate(regio) zet de regio's in dummies)
Je hebt nu een fixed effect model.
Helpt het niet?
-Maak een variable gdpgrowth_1 en maak hiervan de GDPgrowth van de vorige periode, dus voor de group uit jaar 3 neem je de gdpgrowth van jaar 2. Als je geen dgpgrowth van jaar 0 hebt, dan zul je afscheid moeten nemen van je year 1 observaties in je analyse.
-Probeer de gdpgrowth lag met de regressie + year 2 + year 3
-Probeer de gdpgrowth met de hele fixed effects model.
ADDITIONEEL:
-Type hettest na een regressie, is het resultaat significant?
-Bekijk de VIFs of multicollinearity condition index (find collin)
-Probeer eeens na een regressie command het volgende: , vce(robust) of , vce(cluster regio)
Zie http://www.jblumenstock.com/files/courses/econ174/FEModels.pdf vanaf Fixed effects regression in practice
Goed, ik zou het volgende doen:
Kies een paar variablen die je echt wil hebben en die niet echt gecorreleerd zijn (corr var1 var2 var3), werk hiermee met de volgende stappen :
-Maak dummy voor Year 2, Year 3. Probeer de reg met deze twee dummies en je gekozen v
variablen.
-Maak een dummy voor elke regio die je hebt behalve 1. Probeer de reg met de year dummies en deze dummies en je variabelen. ( stata command: tabulate regio, generate(regio) zet de regio's in dummies)
Je hebt nu een fixed effect model.
Helpt het niet?
-Maak een variable gdpgrowth_1 en maak hiervan de GDPgrowth van de vorige periode, dus voor de group uit jaar 3 neem je de gdpgrowth van jaar 2. Als je geen dgpgrowth van jaar 0 hebt, dan zul je afscheid moeten nemen van je year 1 observaties in je analyse.
-Probeer de gdpgrowth lag met de regressie + year 2 + year 3
-Probeer de gdpgrowth met de hele fixed effects model.
ADDITIONEEL:
-Type hettest na een regressie, is het resultaat significant?
-Bekijk de VIFs of multicollinearity condition index (find collin)
-Probeer eeens na een regressie command het volgende: , vce(robust) of , vce(cluster regio)
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Hoi, ik heb even een kort vraagje.
Ik wil in mijn lineaire regressieanalyse (in SPSS) controleren voor een aantal (scale meetniveau) variabelen.
Doe ik dat gewoon door de controlevariabelen in het eerst block (method:enter) in te voeren, en in het tweede block mijn onafhankelijke variabele?
En waar kijk ik dan als ik de significantie, R² en F van de predictor wil weten?
Ik raak namelijk helemaal in de war. Wat zegt het als het gehele model wel significant is maar de predictor niet? Dat betekent toch dat de predictor niks toevoegt aan het model, maar dat de significante controlevariabelen daarvoor zorgen?
Ik wil vooral weten wat ik nu precies moet rapporteren.
[ Bericht 5% gewijzigd door PluisigNijntje op 28-05-2016 19:49:16 ]
Ik wil in mijn lineaire regressieanalyse (in SPSS) controleren voor een aantal (scale meetniveau) variabelen.
Doe ik dat gewoon door de controlevariabelen in het eerst block (method:enter) in te voeren, en in het tweede block mijn onafhankelijke variabele?
En waar kijk ik dan als ik de significantie, R² en F van de predictor wil weten?
Ik raak namelijk helemaal in de war. Wat zegt het als het gehele model wel significant is maar de predictor niet? Dat betekent toch dat de predictor niks toevoegt aan het model, maar dat de significante controlevariabelen daarvoor zorgen?
Ik wil vooral weten wat ik nu precies moet rapporteren.
[ Bericht 5% gewijzigd door PluisigNijntje op 28-05-2016 19:49:16 ]
Nomnomnomnomnomnomnomnomnomnom
Het
Je laatste stelling/vraag klopt. Kijk voor voorbeelden van hoe je dit rapporteert in Pallant of Field.
Het hangt er een beetje vanaf wat die controlevariabelen zijn. In de sociale wetenschappen is het gebruikelijk dat je demografische variabelen eerst erin zet. De achtergrond van die gedachte is dat deze kenmerken namelijk al aanwezig zijn. De verklaarde variantie wordt dan eerst toegeschreven aan die variabelen. Hier is natuurlijk over te discussieren. Keith heeft hier een heldere uitleg over opgenomen in Multiple Regression and Beyond.quote:
Hoi, ik heb even een kort vraagje.
Ik wil in mijn lineaire regressieanalyse (in SPSS) controleren voor een aantal (scale meetniveau) variabelen.
Doe ik dat gewoon door de controlevariabelen in het eerst block (method:enter) in te voeren, en in het tweede block mijn onafhankelijke variabele?
En waar kijk ik dan als ik de significantie, R² en F van de predictor wil weten?
Ik raak namelijk helemaal in de war. Wat zegt het als het gehele model wel significant is maar de predictor niet? Dat betekent toch dat de predictor niks toevoegt aan het model, maar dat de significante controlevariabelen daarvoor zorgen?
Ik wil vooral weten wat ik nu precies moet rapporteren.
Je laatste stelling/vraag klopt. Kijk voor voorbeelden van hoe je dit rapporteert in Pallant of Field.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Betreft de lineaire regressie analyse heb ik ook een vraag. Ik wil het effect meten van een independent variable op een dependent variable. De sample size is 205. Als ik een control variable toevoeg (gender) blijft de sample size 205. Als ik een tweede control variable toevoeg (age) veranderd de sample size naar 26. Hoe kan dit? Ik heb gezocht op google maar kan er niks over vinden.
Wie helpt mij uit de brand? Vast bedankt!
Wie helpt mij uit de brand? Vast bedankt!
quote:
[..]
Wauw, stom dat ik dit gemist heb. Hoe makkelijk kan het soms zijn. Dankjewel!
Erg bedankt voor je reactie. Op de een of andere manier lukt het nu wel.quote:
Okay, je doet geen echte fixed effects want je zet de variablen die voor het fixed effects model zorgen niet vast
Zie http://www.jblumenstock.com/files/courses/econ174/FEModels.pdf vanaf Fixed effects regression in practice
Goed, ik zou het volgende doen:
Kies een paar variablen die je echt wil hebben en die niet echt gecorreleerd zijn (corr var1 var2 var3), werk hiermee met de volgende stappen :
-Maak dummy voor Year 2, Year 3. Probeer de reg met deze twee dummies en je gekozen v
variablen.
-Maak een dummy voor elke regio die je hebt behalve 1. Probeer de reg met de year dummies en deze dummies en je variabelen. ( stata command: tabulate regio, generate(regio) zet de regio's in dummies)
Je hebt nu een fixed effect model.
Helpt het niet?
-Maak een variable gdpgrowth_1 en maak hiervan de GDPgrowth van de vorige periode, dus voor de group uit jaar 3 neem je de gdpgrowth van jaar 2. Als je geen dgpgrowth van jaar 0 hebt, dan zul je afscheid moeten nemen van je year 1 observaties in je analyse.
-Probeer de gdpgrowth lag met de regressie + year 2 + year 3
-Probeer de gdpgrowth met de hele fixed effects model.
ADDITIONEEL:
-Type hettest na een regressie, is het resultaat significant?
-Bekijk de VIFs of multicollinearity condition index (find collin)
-Probeer eeens na een regressie command het volgende: , vce(robust) of , vce(cluster regio)
Super bedankt voor je uitleg.
Hettest werkt niet hier, de andere wel maar veranderen niet heel veel aan de waardes. Echter is het model nu wel ok (lijkt zo).
Een andere vraag.
Is log(GDP) hetzelfde als GDP growth?
Ja.quote:
Een andere vraag.
Is log(GDP) hetzelfde als GDP growth?
Ik baseer mij op Google, kun je zelf ook gebruiken: Noticequote:
that if we difference log GDP, we get the growth rate of GDP.
Niet helemaal. Het is een benadering, maar wel een benadering die door iedereen als goed genoeg wordt beschouwd.quote:
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Fijn dat het helpt!quote:
[..]
Erg bedankt voor je reactie. Op de een of andere manier lukt het nu wel.
Super bedankt voor je uitleg.
Hettest werkt niet hier, de andere wel maar veranderen niet heel veel aan de waardes. Echter is het model nu wel ok (lijkt zo).
Hmm, ik zou zeggen - zoals ik de vraag begrijp - Nee.quote:Een andere vraag.
Is log(GDP) hetzelfde als GDP growth?
GDP = 300 miljard
LOG(GDP) = 11.47
Hoe je hier een GDP growth in ziet weet ik niet
Misschien bedoel je het volgende:
EDIT:quote:Trend measured in natural-log units = ~percentage growth: Because changes in the natural logarithm are (almost) equal to percentage changes in the original series, it follows that the slope of a trend line fitted to logged data is equal to the average percentage growth in the original series. http://people.duke.edu/~rnau/411log.htm#trend
Dat klopt ook; als je log(dependent variable) gebruik in regressies dan zijn de coefficienten van de independent variables ongeveer de percentage groei van de dependent, maar het wijkt meer af wijkt meer af bij hogere percentages.quote:
[..]
Niet helemaal. Het is een benadering, maar wel een benadering die door iedereen als goed genoeg wordt beschouwd.
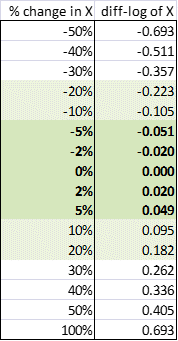
[ Bericht 4% gewijzigd door Zith op 01-06-2016 20:29:31 ]
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Ik ben bezig met een aantal logistische regressies, waaronder regressies met interactie-effecten.
Nu heb ik een beetje moeite met het uitvoeren ervan, maar ook met de interpretatie ervan.
Is er misschien iemand die morgen wat tijd over heeft om mijn regressies en interpretaties door te kijken en te voorzien van wat behulpzaam commentaar?
Mijn dank zal groot zijn
Nu heb ik een beetje moeite met het uitvoeren ervan, maar ook met de interpretatie ervan.
Is er misschien iemand die morgen wat tijd over heeft om mijn regressies en interpretaties door te kijken en te voorzien van wat behulpzaam commentaar?
Mijn dank zal groot zijn
Regenboog, regenboog
gelukkig ben je krom,
anders heette je regenstreep,
en dat klinkt toch wel zo stom
gelukkig ben je krom,
anders heette je regenstreep,
en dat klinkt toch wel zo stom
Ik heb een toets gedaan met een kruistabel, maar nu komt er geen cramer's v uit. Er waren echter ook maar 2 respondenten die het antwoord kozen. Moet je aan een bepaald aantal 'antwoorden' voldoen voor er een cramer's v uitrolt?
Wel aangeklikt natuurlijk?quote:
Ik heb een toets gedaan met een kruistabel, maar nu komt er geen cramer's v uit. Er waren echter ook maar 2 respondenten die het antwoord kozen. Moet je aan een bepaald aantal 'antwoorden' voldoen voor er een cramer's v uitrolt?
Als jet deze ochtend plaatst, kijk ik er tijdens de lunch naar.quote:
Ik ben bezig met een aantal logistische regressies, waaronder regressies met interactie-effecten.
Nu heb ik een beetje moeite met het uitvoeren ervan, maar ook met de interpretatie ervan.
Is er misschien iemand die morgen wat tijd over heeft om mijn regressies en interpretaties door te kijken en te voorzien van wat behulpzaam commentaar?
Mijn dank zal groot zijn
Aangeboden hulp niet aanpakken.quote:
[..]
Als jet deze ochtend plaatst, kijk ik er tijdens de lunch naar.
Weet iemand wat je zou moeten doen bij (Augmented) Dickey-Fuller test na first differencing als je vóór first differencing een lag length van 1 gebruikte? Zou je dan nog dezelfde lag length moeten kiezen of moet deze dan op 0?
Sorry ik had dit topic nog niet gezien!
Maar ik heb twee vragen over SPSS en hoop dat jullie mij kunnen helpen!
1.
Ik moet een staafdiagram maken waarbij ik op de y-as kwaliteit van leven aangeef (variabele heet "EQ-5D"). Op de x-as moet ik combinaties van ziektes en aandoeningen aangeven. hiervoor heb ik dan aan de ene kant de variabele "ziekte" (met CVR=0, COPD=1 en Diabetes=2 en dan zitten daar nog 3 ziektes in die ik niet gebruik) en aan de andere kant variabelen "pers_p7.1" tot en met "pers_P7.28" waarin 28 aandoeningen omschreven worden (met 0=nee, 1=ja). Dan moet ik dus aangeven wat kwaliteit van leven is van bijvoorbeeld COPD (ziekte=1) met nierstenen (Pers_P7.6=ja). Dit moet ik voor alle combinaties van de drie ziektes (CVR, COPD en diabetes) doen in combinatie met alle 28 aandoeningen. Voor nu maakt het mij niet uit of alles in 1 staafdiagram is of dat ik per ziekte (CVR, COPD en diabetes) een aparte staafdiagram krijg.
2.
ik moet ook aangeven wat 1 ziekte (en geen aandoening) betekent voor kwaliteit van leven en als iemand 1 ziekte en 1 aandoening heeft (variabele ziekte is dus weer "ziekte" en variabele aandoening is Pers_P7.1 t/m Pers_P7.28). Of 1 ziekte en 2 aandoeningen. Of 1 ziekte en meer dan 3 aandoeningen. en dan in een staafdiagram kijken wat dit betekent voor kwaliteit van leven. Hoe doe ik dit?
Maar ik heb twee vragen over SPSS en hoop dat jullie mij kunnen helpen!
1.
Ik moet een staafdiagram maken waarbij ik op de y-as kwaliteit van leven aangeef (variabele heet "EQ-5D"). Op de x-as moet ik combinaties van ziektes en aandoeningen aangeven. hiervoor heb ik dan aan de ene kant de variabele "ziekte" (met CVR=0, COPD=1 en Diabetes=2 en dan zitten daar nog 3 ziektes in die ik niet gebruik) en aan de andere kant variabelen "pers_p7.1" tot en met "pers_P7.28" waarin 28 aandoeningen omschreven worden (met 0=nee, 1=ja). Dan moet ik dus aangeven wat kwaliteit van leven is van bijvoorbeeld COPD (ziekte=1) met nierstenen (Pers_P7.6=ja). Dit moet ik voor alle combinaties van de drie ziektes (CVR, COPD en diabetes) doen in combinatie met alle 28 aandoeningen. Voor nu maakt het mij niet uit of alles in 1 staafdiagram is of dat ik per ziekte (CVR, COPD en diabetes) een aparte staafdiagram krijg.
2.
ik moet ook aangeven wat 1 ziekte (en geen aandoening) betekent voor kwaliteit van leven en als iemand 1 ziekte en 1 aandoening heeft (variabele ziekte is dus weer "ziekte" en variabele aandoening is Pers_P7.1 t/m Pers_P7.28). Of 1 ziekte en 2 aandoeningen. Of 1 ziekte en meer dan 3 aandoeningen. en dan in een staafdiagram kijken wat dit betekent voor kwaliteit van leven. Hoe doe ik dit?
Never assume, because then you make an ass out of u and me.
Hola,
Ik kom hier even binnenvallen, maar ik heb een vraag over mijn statistiek opdracht en ik hoop dat iemand me daarbij kan helpen. De data bestaat uit scores op visuele aandacht, op twee soorten stimuli (bekende en onbekende stimuli). De deelnemers zijn baby's en worden 4 keer gestest (wanneer ze 3,4, 6 en 8 maanden zijn). Nu zijn er tussentijds baby's gestopt met deelname (op de laatste meting zijn er 13 missende waardes). en de vraag is er verschil is in de scores op de eerste meting/ verschil in geslacht tussen baby's die alle metingen hebben doorlopen en baby's die tussentijds gestopt zijn.
Nu dacht ik dit te doen met een t test. waarbij je een variabele maakt van baby's die gestopt zijn en baby's die niet gestopt zijn. maar dit blijkt niet juist te zijn.
Help me out
Ik kom hier even binnenvallen, maar ik heb een vraag over mijn statistiek opdracht en ik hoop dat iemand me daarbij kan helpen. De data bestaat uit scores op visuele aandacht, op twee soorten stimuli (bekende en onbekende stimuli). De deelnemers zijn baby's en worden 4 keer gestest (wanneer ze 3,4, 6 en 8 maanden zijn). Nu zijn er tussentijds baby's gestopt met deelname (op de laatste meting zijn er 13 missende waardes). en de vraag is er verschil is in de scores op de eerste meting/ verschil in geslacht tussen baby's die alle metingen hebben doorlopen en baby's die tussentijds gestopt zijn.
Nu dacht ik dit te doen met een t test. waarbij je een variabele maakt van baby's die gestopt zijn en baby's die niet gestopt zijn. maar dit blijkt niet juist te zijn.
Help me out
Is lichaamslengte in centimeter een interval- of ratio meetniveau?
Man is de baas, vrouw kent haar plaats.
Ratioquote:
Is lichaamslengte in centimeter een interval- of ratio meetniveau?
13 missende waardes, maar hoeveel volhardende baby's hou je over?quote:
Hola,
Ik kom hier even binnenvallen, maar ik heb een vraag over mijn statistiek opdracht en ik hoop dat iemand me daarbij kan helpen. De data bestaat uit scores op visuele aandacht, op twee soorten stimuli (bekende en onbekende stimuli). De deelnemers zijn baby's en worden 4 keer gestest (wanneer ze 3,4, 6 en 8 maanden zijn). Nu zijn er tussentijds baby's gestopt met deelname (op de laatste meting zijn er 13 missende waardes). en de vraag is er verschil is in de scores op de eerste meting/ verschil in geslacht tussen baby's die alle metingen hebben doorlopen en baby's die tussentijds gestopt zijn.
Nu dacht ik dit te doen met een t test. waarbij je een variabele maakt van baby's die gestopt zijn en baby's die niet gestopt zijn. maar dit blijkt niet juist te zijn.
Help me out
Verder zou ik zeggen dat het verschil op de eerste meting prima kan worden geanalyseerd met een t-test, maar bij geslacht kom je aan vier groepen (jongen gestopt, meisje gestopt en nog eens beide geslachten voor volhardende baby's.) Aangezien je in die situatie twee factoren hebt (geslacht en volhardendheid) kun je een 2-factor-ANOVA gebruiken. (Al zullen de groepen klein zijn of heel ongelijk.)
Geen flauw idee, sorry.quote:
Weet iemand wat je zou moeten doen bij (Augmented) Dickey-Fuller test na first differencing als je vóór first differencing een lag length van 1 gebruikte? Zou je dan nog dezelfde lag length moeten kiezen of moet deze dan op 0?
Moeten dit echt staafdiagrammen worden? De drie ziektes die je noemt zorgen al voor 7 combinaties en elke combinatie krijgt dan 28 staafjes. Dat is een boel staafjesquote:
Sorry ik had dit topic nog niet gezien!
Maar ik heb twee vragen over SPSS en hoop dat jullie mij kunnen helpen!
1.
Ik moet een staafdiagram maken waarbij ik op de y-as kwaliteit van leven aangeef (variabele heet "EQ-5D"). Op de x-as moet ik combinaties van ziektes en aandoeningen aangeven. hiervoor heb ik dan aan de ene kant de variabele "ziekte" (met CVR=0, COPD=1 en Diabetes=2 en dan zitten daar nog 3 ziektes in die ik niet gebruik) en aan de andere kant variabelen "pers_p7.1" tot en met "pers_P7.28" waarin 28 aandoeningen omschreven worden (met 0=nee, 1=ja). Dan moet ik dus aangeven wat kwaliteit van leven is van bijvoorbeeld COPD (ziekte=1) met nierstenen (Pers_P7.6=ja). Dit moet ik voor alle combinaties van de drie ziektes (CVR, COPD en diabetes) doen in combinatie met alle 28 aandoeningen. Voor nu maakt het mij niet uit of alles in 1 staafdiagram is of dat ik per ziekte (CVR, COPD en diabetes) een aparte staafdiagram krijg.
Nouja, je kunt, net als bij 1, een staafdiagram maken per aantal ziektes (waar het in 1 de combinatie van specifieke ziektes was) en dan weer staafdiagrammen maken in Excel ofzo, maar het lijkt me dat een tabel iets overzichtelijker is.quote:2.
ik moet ook aangeven wat 1 ziekte (en geen aandoening) betekent voor kwaliteit van leven en als iemand 1 ziekte en 1 aandoening heeft (variabele ziekte is dus weer "ziekte" en variabele aandoening is Pers_P7.1 t/m Pers_P7.28). Of 1 ziekte en 2 aandoeningen. Of 1 ziekte en meer dan 3 aandoeningen. en dan in een staafdiagram kijken wat dit betekent voor kwaliteit van leven. Hoe doe ik dit?
Heel erg bedankt voor je antwoord. je begint met 80 dus je houdt 67 over. Ik had inderdaad in mijn eerste verslag (dit is een herkansing) een anova gedaan, echter zei ze dat dit ook niet de juiste analyse was (was te simpel voor statistiek 3). Nu zat ik te denken dat je misschien een manova moet doen omdat je wil kijken of de uitvallers en de blijvers verschillen op meerdere afhankelijke variabelen. Of zit ik hier verkeerd?quote:
[..]
13 missende waardes, maar hoeveel volhardende baby's hou je over?
Verder zou ik zeggen dat het verschil op de eerste meting prima kan worden geanalyseerd met een t-test, maar bij geslacht kom je aan vier groepen (jongen gestopt, meisje gestopt en nog eens beide geslachten voor volhardende baby's.) Aangezien je in die situatie twee factoren hebt (geslacht en volhardendheid) kun je een 2-factor-ANOVA gebruiken. (Al zullen de groepen klein zijn of heel ongelijk.)
Ik had even gemist dat je meerdere afhankelijke variabelen had, excuses. Als je losse scores hebt met betrekking tot de bekende/onbekende stimuli, dan kun je meerdere afhankelijke variabelen meenemen inderdaad. (Als je bijvoorbeeld alleen de verschilscores tussen de verschillende stimuli hebt kan dat niet.) Wat ik meestal aanraad als het gaat om welke analyse je kunt doen, is het boek van Andy Field pakken (Discovering Statistics Using SPSS). Achterin staat een flowchart die studenten meestal nuttig vinden bij het bepalen van de juiste analyse.quote:
[..]
Heel erg bedankt voor je antwoord. je begint met 80 dus je houdt 67 over. Ik had inderdaad in mijn eerste verslag (dit is een herkansing) een anova gedaan, echter zei ze dat dit ook niet de juiste analyse was (was te simpel voor statistiek 3). Nu zat ik te denken dat je misschien een manova moet doen omdat je wil kijken of de uitvallers en de blijvers verschillen op meerdere afhankelijke variabelen. Of zit ik hier verkeerd?
Bedankt! Ik zal kijken of dat ook online te vinden is. Overigens had ik nog 1 vraag, de andere onderzoeksvraag is namelijk dit; Ten tweede wordt het effect van soort stimulus(bekend/onbekend) op de visuele aandacht en het verloop daarvan door de tijd (bij 3,4, 6 en 8 maanden) bekeken. Dus je doet een repeated measures analyse waarbij je 2 within-subjects variabelen hebt, namelijk type stimuli en tijd. Verder gebruik je dus geen between-subjects factor. is het nu een repeated measures anova of repeated measures manova?quote:
[..]
Ik had even gemist dat je meerdere afhankelijke variabelen had, excuses. Als je losse scores hebt met betrekking tot de bekende/onbekende stimuli, dan kun je meerdere afhankelijke variabelen meenemen inderdaad. (Als je bijvoorbeeld alleen de verschilscores tussen de verschillende stimuli hebt kan dat niet.) Wat ik meestal aanraad als het gaat om welke analyse je kunt doen, is het boek van Andy Field pakken (Discovering Statistics Using SPSS). Achterin staat een flowchart die studenten meestal nuttig vinden bij het bepalen van de juiste analyse.
Staan daar ook mediatie en interactie effecten?quote:
[..]
Ik had even gemist dat je meerdere afhankelijke variabelen had, excuses. Als je losse scores hebt met betrekking tot de bekende/onbekende stimuli, dan kun je meerdere afhankelijke variabelen meenemen inderdaad. (Als je bijvoorbeeld alleen de verschilscores tussen de verschillende stimuli hebt kan dat niet.) Wat ik meestal aanraad als het gaat om welke analyse je kunt doen, is het boek van Andy Field pakken (Discovering Statistics Using SPSS). Achterin staat een flowchart die studenten meestal nuttig vinden bij het bepalen van de juiste analyse.
Friettent dikke Willie, met Willie
Ben je nog steeds bezig?quote:
[..]
Staan daar ook mediatie en interactie effecten?
Interacties wel, mediation niet.
99 other problems firstquote:
[..]
Ben je nog steeds bezig?
Interacties wel, mediation niet.
Friettent dikke Willie, met Willie
Hoi, ik heb nog even een vraagje.
Ik ben nu met een uitgebreid mediatiemodel bezig en van 1 ding kan ik echt niks maken:
Ik heb een model waarbij het totale effect van X op Y in beginsel niet significant is, maar wanneer ik de mediator M meeneem wordt het direct effect ineens wel significant.Hoe is dit in vredesnaam mogelijk?
Ik ben nu met een uitgebreid mediatiemodel bezig en van 1 ding kan ik echt niks maken:
Ik heb een model waarbij het totale effect van X op Y in beginsel niet significant is, maar wanneer ik de mediator M meeneem wordt het direct effect ineens wel significant.Hoe is dit in vredesnaam mogelijk?
Nomnomnomnomnomnomnomnomnomnom
Het weglaten van de mediator kan het directe effect onderdrukken in het model. in dergelijke situaties zou ik wel extra voorzichtig zijn.quote:
Hoi, ik heb nog even een vraagje.
Ik ben nu met een uitgebreid mediatiemodel bezig en van 1 ding kan ik echt niks maken:
Ik heb een model waarbij het totale effect van X op Y in beginsel niet significant is, maar wanneer ik de mediator M meeneem wordt het direct effect ineens wel significant.Hoe is dit in vredesnaam mogelijk?
Kun je dat 'onderdrukken' uitleggen?quote:
[..]
Het weglaten van de mediator kan het directe effect onderdrukken in het model. in dergelijke situaties zou ik wel extra voorzichtig zijn.
Nomnomnomnomnomnomnomnomnomnom
Heb je dan zowel een significant mediating effect als een significant direct effect?quote:
Hoi, ik heb nog even een vraagje.
Ik ben nu met een uitgebreid mediatiemodel bezig en van 1 ding kan ik echt niks maken:
Ik heb een model waarbij het totale effect van X op Y in beginsel niet significant is, maar wanneer ik de mediator M meeneem wordt het direct effect ineens wel significant.Hoe is dit in vredesnaam mogelijk?
Ik heb me erop verkeken trouwens, hij wordt net niet significant maar wel veel dichterbij (van b1: p = .147 naar b'1: p = .059). Maar vind het nog steeds een raar feit en vraag me daarom af wat Reya precies bedoelt met onderdrukking.quote:
[..]
Heb je dan zowel een significant mediating effect als een significant direct effect?
Het mediation effect is wel significant, ik heb twee mediators die beide significant zijn (b3: p =.044, b'2: p = .029 en b3 p <.001, b'2: p <.001).
Nomnomnomnomnomnomnomnomnomnom
Ik heb bier gedronken dus ik kan het niet helemaal helder zien maar is er dan geen partial mediation?quote:
[..]
Ik heb me erop verkeken trouwens, hij wordt net niet significant maar wel veel dichterbij (van b1: p = .147 naar b'1: p = .059). Maar vind het nog steeds een raar feit en vraag me daarom af wat Reya precies bedoelt met onderdrukking.
Het mediation effect is wel significant, ik heb twee mediators die beide significant zijn (b3: p =.044, b'2: p = .029 en b3 p <.001, b'2: p <.001).
Nee, want zoals ik al zei is het directe effect dus toch net niet significant geworden. Er is een volledig indirect effect, maar de b1 was in beginsel al niet significant, wat eigenlijk wel een voorwaarde is voor mediatie.quote:
[..]
Ik heb bier gedronken dus ik kan het niet helemaal helder zien maar is er dan geen partial mediation?
Dus wat is dit dan?
Nomnomnomnomnomnomnomnomnomnom
Volgens die stoffige Baron en Kenny inderdaad. Heb je ook gebootstrapped?quote:
[..]
Nee, want zoals ik al zei is het directe effect dus toch net niet significant geworden. Er is een volledig indirect effect, maar de b1 was in beginsel al niet significant, wat eigenlijk wel een voorwaarde is voor mediatie.
Dus wat is dit dan?
Voor model 6 in PROCESS kan ik geen Sobel test meenemen, weet niet precies wat er verder te bootstrappen valt? Maar jij suggereert dus dat je dit wel mediatie mag noemen?quote:
[..]
Volgens die stoffige Baron en Kenny inderdaad. Heb je ook gebootstrapped?
Nomnomnomnomnomnomnomnomnomnom
Ah, serial mediation dus. Bij mijn onderzoek met mediators had ik niet zozeer of er mediation ontstond maar was het een manier om mijn hele model te testen. Ik had dan ook afzonderlijke hypotheses over hoe mijn independent variable de mediator zou beïnvloeden en ook hoe de mediator de dependent variable beïnvloedde. Kijk maar eens hoe ze dat in dit artikel beschrijven onder het kopje 'serial mediation'.quote:
[..]
Voor model 6 in PROCESS kan ik geen Sobel test meenemen, weet niet precies wat er verder te bootstrappen valt? Maar jij suggereert dus dat je dit wel mediatie mag noemen?
Yes, dat heb ik inderdaad ook. Bedankt voor het artikel.quote:
[..]
Ah, serial mediation dus. Bij mijn onderzoek met mediators had ik niet zozeer of er mediation ontstond maar was het een manier om mijn hele model te testen. Ik had dan ook afzonderlijke hypotheses over hoe mijn independent variable de mediator zou beïnvloeden en ook hoe de mediator de dependent variable beïnvloedde. Kijk maar eens hoe ze dat in dit artikel beschrijven onder het kopje 'serial mediation'.
Kun jij misschien nog uitleggen wat Reya bedoelde met die onderdrukking? Volgens mij heeft mijn begeleidster het er ook een keer over gehad, maar ik begrijp het niet helemaal.
Nomnomnomnomnomnomnomnomnomnom
Dat laat ik aan hem over.quote:
[..]
Yes, dat heb ik inderdaad ook. Bedankt voor het artikel.
Kun jij misschien nog uitleggen wat Reya bedoelde met die onderdrukking? Volgens mij heeft mijn begeleidster het er ook een keer over gehad, maar ik begrijp het niet helemaal.
Uh, ja ik zou je wel willen helpen maar ik weet niet helemaal wat hij wil zeggen. Hier staat het ook uitgelegd.quote:
Klopt! Ook een artikel waar naar gerefereerd wordt (MacKinnon, D. P., Krull, J. L., & Lockwood, C. M. (2000). Equivalence of the mediation, confounding, and suppression effect. Prevention Science, 1, 173-181) is super duidelijk. Hier kan ik wel wat mee. Bedankt!quote:
Beter gezegd, daar staat het perfect uitgelegd.
Nomnomnomnomnomnomnomnomnomnom
Zo zie je maar weer, in principe kun je zelf een heel eind komen.quote:
[..]
Klopt! Ook een artikel waar naar gerefereerd wordt (MacKinnon, D. P., Krull, J. L., & Lockwood, C. M. (2000). Equivalence of the mediation, confounding, and suppression effect. Prevention Science, 1, 173-181) is super duidelijk. Hier kan ik wel wat mee. Bedankt!
Hoe krijg ik in SPSS de volgende dataset:
Op deze manier gestructureerd:
| 1 2 3 4 5 6 7 8 | respnr jaar status 1 2004 A 1 2009 B 1 2012 C 2 2008 X 3 2003 F 3 2008 A 3 2011 C |
Op deze manier gestructureerd:
| 1 2 3 4 | respnr j2003 j2004 j2005 j2006 j2007 j2008 j2009 j2011 j2012 1 A B C 2 X 3 F A C |
"On a good day, when I run, the voices in my head get quieter until it’s just me, my breath and my feet on the sand (Dexter, E5x09)."
Excel gebruiken?quote:
Hoe krijg ik in SPSS de volgende dataset:
[ code verwijderd ]
Op deze manier gestructureerd:
[ code verwijderd ]
Het gaat om een enorme dataset (enkele miljoenen cases). Ik denk dat dat niet gaat werken.quote:
"On a good day, when I run, the voices in my head get quieter until it’s just me, my breath and my feet on the sand (Dexter, E5x09)."
Ik weet niet meer wat SPSS allemaal kan maar dit zou je toch moeten kunnen met een code met o.a. for en if statements?quote:
[..]
Het gaat om een enorme dataset (enkele miljoenen cases). Ik denk dat dat niet gaat werken.
Mja, ik denk dat het sneller is om het om te bouwen met python en dan weer te openen in SPSS. In R zou waarschijnlijk ook wel kunnen, maar ik worstel daarin altijd met forif statements.quote:
[..]
Ik weet niet meer wat SPSS allemaal kan maar dit zou je toch moeten kunnen met een code met o.a. for en if statements?
Your opinion of me is none of my business.
Data -> Restructure.quote:
Hoe krijg ik in SPSS de volgende dataset:
[ code verwijderd ]
Op deze manier gestructureerd:
[ code verwijderd ]
Aldus.
Hier ben ik mee gaan stoeien, maar dan krijg ik elk jaar 'n' maal het aantal keren wat de respondent voorkomt die de meeste entries heeft. Als iemand bijvoorbeeld 10x voorkomt in de dataset krijg ik bij elk jaar (in dit voorbeeld 2004):quote:
2004.1
2004.2
etc. t/m
2004.10
Op zich niet erg, maar kan ik met een commando de variabelen 2004.1 t/m 2004.n (waarbij n onbekend is) samenvoegen tot 1 variabele (namelijk 2004), waarbij 2004 1 is als er ergens in de 10 variabelen iets staat?
"On a good day, when I run, the voices in my head get quieter until it’s just me, my breath and my feet on the sand (Dexter, E5x09)."
Kan je niet eerst de data aggregeren en dan in de Restructure gooien? Dan moet je dus de data op respondentniveau + jaar aggregeren.
Aldus.
JAAAAAAA!!!! Die aggregate functie doet wat ik wil!quote:
Kan je niet eerst de data aggregeren en dan in de Restructure gooien? Dan moet je dus de data op respondentniveau + jaar aggregeren.
Heel erg bedankt
"On a good day, when I run, the voices in my head get quieter until it’s just me, my breath and my feet on the sand (Dexter, E5x09)."
Ik heb twee groepen(/condities) en beide groepen hebben 4 reactietijden geproduceerd. Ik moet tussen groepen reactietijden vergelijken en binnen groepen.
Klopt het dat ik tussen groepen een one way anova gebruik? En hoe vergelijk ik twee reactietijden binnen een groep? Help
Klopt het dat ik tussen groepen een one way anova gebruik? En hoe vergelijk ik twee reactietijden binnen een groep? Help
Zijn het 2 groepen, waarbij 1 groep een bepaalde behandeling kreeg die anders was dan van de andere groep, en waarbij je voor beide groepen een observatie voor en een observatie na de behandeling hebt?
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
1 experimentele en 1 controlegroep, ze hebben een computertaak gedaan en ik heb nu gemiddeldes van reactietijden op 4 categorieen woordenquote:
Zijn het 2 groepen, waarbij 1 groep een bepaalde behandeling kreeg die anders was dan van de andere groep, en waarbij je voor beide groepen een observatie voor en een observatie na de behandeling hebt?
Maar dus geen observaties van de experimentele groep voor (ex ante) de 'treatment' (training, behandeling, medicatie, whatever)? Dan had ik je een diff in diffs model aangeraden. ☺
Nu valt het buiten mijn expertise want heb nog nooit in mijn leven een anova gedaan.
Nu valt het buiten mijn expertise want heb nog nooit in mijn leven een anova gedaan.
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Nee het was een meting op 1 moment. Het was een experiment waarbij twee groepen waren, experiment en controle. Deze moesten een computertaak doen waarbij reactietijd werd gemeten op 4 verschillende categorieen. Nu moet ik de reactietijd vergelijken van een aantal categorieen binnen en tussen groepen.quote:
Maar dus geen observaties van de experimentele groep voor (ex ante) de 'treatment' (training, behandeling, medicatie, whatever)? Dan had ik je een diff in diffs model aangeraden. ☺
Nu valt het buiten mijn expertise want heb nog nooit in mijn leven een anova gedaan.
Volgens mij heb je daar dus anova's voor nodig
Nog een SPSS-vraagje:
ik heb een dataset met daarin een variabele BEGINJAAR en een variabele EINDJAAR. De values van deze variabelen variëren van 2005 t/m 2015.
Daarnaast heb ik jaarvariabelen, j2005, j2006, j2007 etc. t/m j2015.
De values van de jaarvariabelen zijn '0'.
Als BEGINJAAR en/of EINDJAAR = 2005, dan j2005 is '1'.
Als BEGINJAAR en/of EINDJAAR = 2006, dan j2006 is '1'.
etc.
Dit is vrij eenvoudig in een syntax te zetten.
Kan ik daarbij ook een range gebruiken?
Ik zou graag een regel willen formuleren waarbij alle jaarvariabelen van BEGINJAAR t/m EINDJAAR een '1' krijgen (bijvoorbeeld de jaarvariabelen j2005 t/m j2008 als BEGINJAAR= 2005 en EINDJAAR = 2008). Kan dat?
ik heb een dataset met daarin een variabele BEGINJAAR en een variabele EINDJAAR. De values van deze variabelen variëren van 2005 t/m 2015.
Daarnaast heb ik jaarvariabelen, j2005, j2006, j2007 etc. t/m j2015.
De values van de jaarvariabelen zijn '0'.
Als BEGINJAAR en/of EINDJAAR = 2005, dan j2005 is '1'.
Als BEGINJAAR en/of EINDJAAR = 2006, dan j2006 is '1'.
etc.
Dit is vrij eenvoudig in een syntax te zetten.
Kan ik daarbij ook een range gebruiken?
Ik zou graag een regel willen formuleren waarbij alle jaarvariabelen van BEGINJAAR t/m EINDJAAR een '1' krijgen (bijvoorbeeld de jaarvariabelen j2005 t/m j2008 als BEGINJAAR= 2005 en EINDJAAR = 2008). Kan dat?
"On a good day, when I run, the voices in my head get quieter until it’s just me, my breath and my feet on the sand (Dexter, E5x09)."
Met recode kan je een range gebruiken.
recode V1 (1 thru 5=1) (6 thru 10=2) (11 thru HIGHEST=3) into newvar.
exe.
Misschien kan je daar wat mee?
recode V1 (1 thru 5=1) (6 thru 10=2) (11 thru HIGHEST=3) into newvar.
exe.
Misschien kan je daar wat mee?
Aldus.
Hebben jullie wel eens twijfels gehad bij een analyse omdat deze heel lang duurt? Omdat een model dan bijvoorbeeld te ingewikkeld zou zijn? M'n computer is al 72 aan het rekenen op een regressie-model.
Aldus.
Heb het opgelost:quote:
Met recode kan je een range gebruiken.
recode V1 (1 thru 5=1) (6 thru 10=2) (11 thru HIGHEST=3) into newvar.
exe.
Misschien kan je daar wat mee?
| 1 2 3 4 | COMPUTE j2004 = RANGE(2004,beginjaar,eindjaar). COMPUTE j2005 = RANGE(2005,beginjaar,eindjaar). etc. COMPUTE j2015 = RANGE(2015,beginjaar,eindjaar). |
Ook al heb ik niet direct iets aan je antwoord, op de één of andere manier zet je me wel steeds op het goede spoor! Thanks!
"On a good day, when I run, the voices in my head get quieter until it’s just me, my breath and my feet on the sand (Dexter, E5x09)."
72 wat?quote:
Hebben jullie wel eens twijfels gehad bij een analyse omdat deze heel lang duurt? Omdat een model dan bijvoorbeeld te ingewikkeld zou zijn? M'n computer is al 72 aan het rekenen op een regressie-model.
Ben je niet aan het overfitten?
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Jaarquote:
[..]
72 wat?
Ben je niet aan het overfitten?
Zou niet zo gek zijn met een computer uit 1945.quote:
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Uur. Het is een vrij simpel model maar (kennelijk) heel veel rekenwerk. Want veel cases en een variabel met veel categorieën.
Aldus.
Wat is veel?quote:
Uur. Het is een vrij simpel model maar (kennelijk) heel veel rekenwerk. Want veel cases en een variabel met veel categorieën.
Ik zou zelf al wel eerder ongeduldig worden en de analyse opnieuw doen, of met bijvoorbeeld de eerste 200 cases en/of een deel van de categorieen.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Wellicht een hele simpele vraag, maar in STATA doe ik een paneldata analyse.. De resultaten zijn nog niet zoals ik gehoopt had.
Mijn vraag: In mijn dataset is mijn DV variabele een percentage, mijn IV is een schaal (1-10). In SPSS kun je aangeven dat X een schaal is, Y een percentage, maar herkent STATA dit vanzelf? En zo niet, kan ik dit ergens ingeven of heeft iemand een oplossing wat er wel dient te gebeuren? Op internet wordt ik niet veel wijzer, helaas..
Mijn vraag: In mijn dataset is mijn DV variabele een percentage, mijn IV is een schaal (1-10). In SPSS kun je aangeven dat X een schaal is, Y een percentage, maar herkent STATA dit vanzelf? En zo niet, kan ik dit ergens ingeven of heeft iemand een oplossing wat er wel dient te gebeuren? Op internet wordt ik niet veel wijzer, helaas..
DV is percentage =
glm y varlist , family(binomial) link(logit) robust
... je dwingt hierbij dat de predicted y nooit meer of minder dan 0% of 100% kan zijn. Ikzelf vind het niet zo bijzonder en doe vaak gewoon reg.
Over een schaal IDV... waarom niet dummies? (lijkt me dat spss dit ook doet)
tab varname, gen(scale)
glm y scale*, family(binomial) link(logit) robust
[ Bericht 1% gewijzigd door Zith op 29-06-2016 23:05:02 ]
glm y varlist , family(binomial) link(logit) robust
... je dwingt hierbij dat de predicted y nooit meer of minder dan 0% of 100% kan zijn. Ikzelf vind het niet zo bijzonder en doe vaak gewoon reg.
Over een schaal IDV... waarom niet dummies?
tab varname, gen(scale)
glm y scale*, family(binomial) link(logit) robust
[ Bericht 1% gewijzigd door Zith op 29-06-2016 23:05:02 ]
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Ik weet niet zeker of het bij jouw analyse kan (iig bij -reg en -logit wel), maar je kan door i. direct voor een variabele te zetten aangeven dat het een categorische variabele is. Als je een referentiecategorie aan wil geven, gebruik je ib1. (waarbij 1 de betreffende categorie is).quote:
Wellicht een hele simpele vraag, maar in STATA doe ik een paneldata analyse.. De resultaten zijn nog niet zoals ik gehoopt had.
Mijn vraag: In mijn dataset is mijn DV variabele een percentage, mijn IV is een schaal (1-10). In SPSS kun je aangeven dat X een schaal is, Y een percentage, maar herkent STATA dit vanzelf? En zo niet, kan ik dit ergens ingeven of heeft iemand een oplossing wat er wel dient te gebeuren? Op internet wordt ik niet veel wijzer, helaas..
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Bedankt beide voor de antwoorden. Ik heb het inmiddels hulp gehad via Statalist, blijkbaar maakt het in mijn specifiek geval niet heel veel uit voor mijn resultaten. Toch bedankt voor jullie input, heb weer wat geleerd!
Weet iemand hier een goed Nederlands of Engels boek wat de (basis)concepten van statistiek uitlegt? Ik merk dat ik de praktische kennis wel heb, maar ben steeds vaker benieuwd naar de achterliggende concepten en het echt begrijpen in plaats van doen wat ik geleerd heb zeg maar.
Field heeft een goede, weet zo niet hoe dat heet. En ik vind zelf "Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences" prettig, van Cohen&Cohen.quote:
Weet iemand hier een goed Nederlands of Engels boek wat de (basis)concepten van statistiek uitlegt? Ik merk dat ik de praktische kennis wel heb, maar ben steeds vaker benieuwd naar de achterliggende concepten en het echt begrijpen in plaats van doen wat ik geleerd heb zeg maar.
Your opinion of me is none of my business.
Bedoel je zijn SPSS boek of een ander? En zal die van Cohen^2 eens zoeken.quote:
[..]
Field heeft een goede, weet zo niet hoe dat heet. En ik vind zelf "Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences" prettig, van Cohen&Cohen.
Geen flauw idee, ik krijg m steeds aangeraden wel, dus ik dacht ik geef m door.quote:
[..]
Bedoel je zijn SPSS boek of een ander? En zal die van Cohen^2 eens zoeken.
Your opinion of me is none of my business.
Eigenlijk he. Als het je gaat om de concepten, moet je eens kijken naar literatuur over foutenanalyse (Beta-studies). Daar heb ik in één vak meer begrip van statistiek gekweekt dan in de vier vakken die ik tot nu toe gehad heb. Puur omdat je daar gedwongen wordt ook op een puur wiskundige manier naar de stof te kijken. Ik heb zo geen boek meer daarvan, volgens mij hadden we een reader, maar misschien eens rondsnuffelen in de verplichte literatuur voor die vakken op de uni?quote:
Weet iemand hier een goed Nederlands of Engels boek wat de (basis)concepten van statistiek uitlegt? Ik merk dat ik de praktische kennis wel heb, maar ben steeds vaker benieuwd naar de achterliggende concepten en het echt begrijpen in plaats van doen wat ik geleerd heb zeg maar.
Your opinion of me is none of my business.
Ik zal eens kijken.quote:
[..]
Eigenlijk he. Als het je gaat om de concepten, moet je eens kijken naar literatuur over foutenanalyse (Beta-studies). Daar heb ik in één vak meer begrip van statistiek gekweekt dan in de vier vakken die ik tot nu toe gehad heb. Puur omdat je daar gedwongen wordt ook op een puur wiskundige manier naar de stof te kijken. Ik heb zo geen boek meer daarvan, volgens mij hadden we een reader, maar misschien eens rondsnuffelen in de verplichte literatuur voor die vakken op de uni?
Hahaha, ja, waarschijnlijk wel.quote:
[..]
Ik zal eens kijken.
Your opinion of me is none of my business.
Voor de basis:
John E. Freund's Mathematical Statistics with Applications, Miller & Miller
Statistical Inference Based on the Likelihood, Azzalini
En wat meer over regressies en testen:
Econometrics, Hayashi
Deze worden bij mij in ieder geval gebruikt.
John E. Freund's Mathematical Statistics with Applications, Miller & Miller
Statistical Inference Based on the Likelihood, Azzalini
En wat meer over regressies en testen:
Econometrics, Hayashi
Deze worden bij mij in ieder geval gebruikt.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Hoe zou je het op één na hoogtse getal kunnen vinden per rij over een aantal variabelen in SPSS? Zonder dit helemaal uit te hoeven schrijven.
Aldus.
quote:
Voor de basis:
John E. Freund's Mathematical Statistics with Applications, Miller & Miller
Statistical Inference Based on the Likelihood, Azzalini
En wat meer over regressies en testen:
Econometrics, Hayashi
Deze worden bij mij in ieder geval gebruikt.
Bedankt beide.quote:
Misschien is dit ook wat voor je.
http://www.stat.columbia.edu/~gelman/arm/
Pff dat is een goede.quote:
Hoe zou je het op één na hoogtse getal kunnen vinden per rij over een aantal variabelen in SPSS? Zonder dit helemaal uit te hoeven schrijven.
Mijn houtje-touwtje oplossing zou zijn de hele data in Excel zetten en transposen en dan de data sorteren op hoog naar laag, maar ik neem aan dat je ook nog wil weten bij welke variabele die waarde hoort?
Ah je wil er daarna ook nog echt iets mee doen? Misschien een IF-THEN-dingetje wat de hoogste waarde selecteert en die (tijdelijk) naar 0 hercoderen? Dan nog een keer die IF-THEN gebruiken om de hoogste waarde te selecteren en daar iets mee te doen.
En daarom --> Stata 
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Ik gebruik zelf geen SPSS, maar je kan R toch oproepen vanuit SPSS? In R is het vrij eenvoudig, voor een vector zou je
kunnen gebruiken, wat je de index geeft van het 1 na hoogste getal. (Misschien nog wel even controleren dat de lengte van de vector minstens 2 is).
Voor meerdere rijen zou je dan de apply functie kunnen gebruiken.
| 1 | which(rank(x) == length(x)-1) |
Voor meerdere rijen zou je dan de apply functie kunnen gebruiken.
You don't need a weatherman to know which way the wind blows.
---------------------------------------------------------------------------------------------------------------------------------------------
last.fm Album top 100
---------------------------------------------------------------------------------------------------------------------------------------------
last.fm Album top 100
Het is kinderlijk eenvoudig om te werken met loopjes en macro's, om voor meerdere variabelen of reeksen dezelfde handeling uit te voeren of om matrices of resultaten op te slaan en later weer op te roepen.quote:
[..]
Wat is er fijn aan stata? De keren dat ik ermee werk vind ik het vooral frustrerend werken.
Verder werkt het met een simpele syntax. Vele malen efficiënter/korter dan de syntax van SPSS, waarbij je eigenlijk altijd meerdere regels nodig hebt. Je hebt veel meer feeling met je data en het is makkelijker om deze te bewerken, zoals bij bovenstaand.
Tuurlijk, het kost wat tijd om het te leren, maar dat is bij ieder geavanceerd programma het geval
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
reg varlist, vce(robust)quote:
[..]
Het is kinderlijk eenvoudig om te werken met loopjes en macro's, om voor meerdere variabelen of reeksen dezelfde handeling uit te voeren of om matrices of resultaten op te slaan en later weer op te roepen.
Verder werkt het met een simpele syntax. Vele malen efficiënter/korter dan de syntax van SPSS, waarbij je eigenlijk altijd meerdere regels nodig hebt. Je hebt veel meer feeling met je data en het is makkelijker om deze te bewerken, zoals bij bovenstaand.
Tuurlijk, het kost wat tijd om het te leren, maar dat is bij ieder geavanceerd programma het geval
en je hebt een regressie met white's standard errors(mijn go-to analyse methode). Ik probeerde een keer dat te doen in SPSS en na een uur Googlen en klikken gaf ik het op.
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Ik vond vooral de output per scherm gruwelijk irritant, maar mogelijk deed ik daar iets verkeerd. Ik wil dat meteen een hele tabel word weergegeven etc.quote:
[..]
Het is kinderlijk eenvoudig om te werken met loopjes en macro's, om voor meerdere variabelen of reeksen dezelfde handeling uit te voeren of om matrices of resultaten op te slaan en later weer op te roepen.
Verder werkt het met een simpele syntax. Vele malen efficiënter/korter dan de syntax van SPSS, waarbij je eigenlijk altijd meerdere regels nodig hebt. Je hebt veel meer feeling met je data en het is makkelijker om deze te bewerken, zoals bij bovenstaand.
Tuurlijk, het kost wat tijd om het te leren, maar dat is bij ieder geavanceerd programma het geval
Wij hebben een aantal applicaties op SPSS draaien. Dus was het nu even handiger om het in SPSS te doen. R is een uitstekend alternatief natuurlijk. Stata ken ik niet.
[ Bericht 49% gewijzigd door Z op 11-07-2016 22:31:31 ]
[ Bericht 49% gewijzigd door Z op 11-07-2016 22:31:31 ]
Aldus.
hoi allemaal,
dit voelt als de makkelijkste vraag ooit, maar blijkbaar doe ik toch wat fout, want ik kom er niet uit.
ik heb verschillende variabelen (multi1 multi2 multi3 met alledrie de waardes 0=nee, 1=ja) en ik wil daar 1 variabele van maken (multioverall) met ook 0=nee, 1=ja.
Hoe doe ik dat?
EDIT:
Ik doe nu
compute multioverall = multi1 and multi2 and multi3.
execute.
Maar ik krijg andere waardes als andere variabelen die hetzelfde antwoord moeten hebben. Dus even m'n controlevraag of dit inderdaad de manier is om het te doen, want dan zal ik de bug waarschijnlijk in m'n andere variabelen moeten zoeken.
[ Bericht 35% gewijzigd door Liedje_ op 01-08-2016 20:59:25 ]
dit voelt als de makkelijkste vraag ooit, maar blijkbaar doe ik toch wat fout, want ik kom er niet uit.
ik heb verschillende variabelen (multi1 multi2 multi3 met alledrie de waardes 0=nee, 1=ja) en ik wil daar 1 variabele van maken (multioverall) met ook 0=nee, 1=ja.
Hoe doe ik dat?
EDIT:
Ik doe nu
compute multioverall = multi1 and multi2 and multi3.
execute.
Maar ik krijg andere waardes als andere variabelen die hetzelfde antwoord moeten hebben. Dus even m'n controlevraag of dit inderdaad de manier is om het te doen, want dan zal ik de bug waarschijnlijk in m'n andere variabelen moeten zoeken.
[ Bericht 35% gewijzigd door Liedje_ op 01-08-2016 20:59:25 ]
Never assume, because then you make an ass out of u and me.
Het zijn alleen geen meerdere antwoorden. Eigenlijk zit het zo:quote:
SPSS heeft een "multiple respons-functie".
Analyse --> Multiple Respons -> Define Sets
multi1 is een kleine subgroep met een bepaalde patientengroep, multi2 is een kleine subgroup voor een bepaalde patientengroep en multi3 is een kleine subgroup voor een bepaalde patientengroep en ik wil multioverall een grote groep van deze drie patientengroepen maken.
Ondertussen heb ik een ander probleem.
Met values 0 en 1 lukt het nu, maar als ik values 0, 1, 2 en 3 heb dan kan ik niet één grote groep maken. Ideeen?
Never assume, because then you make an ass out of u and me.
Dan:
IF MULTIGROEP1 = 1 multioverall = 1.
IF MULTIGROEP2 = 1 multioverall = 2.
IF MULTIGROEP3 = 1 multioverall = 3.
exe.
Of als de waarde uit de subgroepen in multioverall moet komen:
IF MULTIGROEP1 = 1 multioverall = MULTIGROEP1.
IF MULTIGROEP2 = 1 multioverall = MULTIGROEP2.
IF MULTIGROEP3 = 1 multioverall = MULTIGROEP3.
exe.
Of ik begrijp je nog niet helemaal.
IF MULTIGROEP1 = 1 multioverall = 1.
IF MULTIGROEP2 = 1 multioverall = 2.
IF MULTIGROEP3 = 1 multioverall = 3.
exe.
Of als de waarde uit de subgroepen in multioverall moet komen:
IF MULTIGROEP1 = 1 multioverall = MULTIGROEP1.
IF MULTIGROEP2 = 1 multioverall = MULTIGROEP2.
IF MULTIGROEP3 = 1 multioverall = MULTIGROEP3.
exe.
Of ik begrijp je nog niet helemaal.
Aldus.
Lastig uitleggen, maar bedoelde dit niet. Wel fijn dat je meedenkt!quote:
Dan:
IF MULTIGROEP1 = 1 multioverall = 1.
IF MULTIGROEP2 = 1 multioverall = 2.
IF MULTIGROEP3 = 1 multioverall = 3.
exe.
Of als de waarde uit de subgroepen in multioverall moet komen:
IF MULTIGROEP1 = 1 multioverall = MULTIGROEP1.
IF MULTIGROEP2 = 1 multioverall = MULTIGROEP2.
IF MULTIGROEP3 = 1 multioverall = MULTIGROEP3.
exe.
Of ik begrijp je nog niet helemaal.
Ik bedoel (gebruik even echte namen om het overzichtelijker te maken):
variabele 1 = COPD met values 0, 1, 2 en 3 (0 extra ziektes, 1 extra ziekte, 2 extra ziektes, 3 extra ziektes)
variabele 2 = diabetes met values 0, 1, 2, en 3
variabele 3 = CVR met values 0, 1, 2 en 3
Ik heb dus drie subgroupen.
dan wil ik kijken naar m'n hele patientengroep (bestaande uit COPD, diabetes en CVR patienten).
Dan wil ik dat SPSS alle nullen bij elkaar optelt, alle 1s bij elkaar op telt, alle 2s bij elkaar op telt en alle 3s bij elkaar op telt.
waarbij ik een nieuwe variabele maak:
Nieuwe variabele is "patientengroep" met waardes 0, 1, 2 en 3.
Hoop dat het zo duidelijker is! Weet jij het?
Never assume, because then you make an ass out of u and me.
IF ANY(0, COPD , diabetes, CVR) patientengroep = 0.
IF ANY(1, COPD , diabetes, CVR) patientengroep = 1.
IF ANY(2, COPD , diabetes, CVR) patientengroep = 2.
IF ANY(3, COPD , diabetes, CVR) patientengroep = 3.
exe.
IF ANY(1, COPD , diabetes, CVR) patientengroep = 1.
IF ANY(2, COPD , diabetes, CVR) patientengroep = 2.
IF ANY(3, COPD , diabetes, CVR) patientengroep = 3.
exe.
Aldus.
Een student hier heeft een analyse gedaan en ik ben even de weg kwijt.
Kort samengevat:
3 soorten schilderijen beoordeeld (tekeningen, houtskool, verfwerken) en vervolgens is een van de variabelen een categorisatie van wat er op het schilderij staat. (fruitmand, voertuig, mens, gebouw). Nu wil de student kijken of wat er op het schilderij staat verschilt per type schilderij. Kun je hier qua Chi-square iets mee? En kun je per soort voorwerp op het schilderij een chi-square doen om te zien of die wezenlijk van elkaar verschillen in hoe vaak ze voorkomen in de drie groepen? Ik heb het idee dat dat lastig is omdat die verschillen niet onafhankelijk zijn, maar misschien zie ik iets over het hoofd.
Kort samengevat:
3 soorten schilderijen beoordeeld (tekeningen, houtskool, verfwerken) en vervolgens is een van de variabelen een categorisatie van wat er op het schilderij staat. (fruitmand, voertuig, mens, gebouw). Nu wil de student kijken of wat er op het schilderij staat verschilt per type schilderij. Kun je hier qua Chi-square iets mee? En kun je per soort voorwerp op het schilderij een chi-square doen om te zien of die wezenlijk van elkaar verschillen in hoe vaak ze voorkomen in de drie groepen? Ik heb het idee dat dat lastig is omdat die verschillen niet onafhankelijk zijn, maar misschien zie ik iets over het hoofd.
Chi2 kan inderdaad.quote:
Een student hier heeft een analyse gedaan en ik ben even de weg kwijt.
Kort samengevat:
3 soorten schilderijen beoordeeld (tekeningen, houtskool, verfwerken) en vervolgens is een van de variabelen een categorisatie van wat er op het schilderij staat. (fruitmand, voertuig, mens, gebouw). Nu wil de student kijken of wat er op het schilderij staat verschilt per type schilderij. Kun je hier qua Chi-square iets mee? En kun je per soort voorwerp op het schilderij een chi-square doen om te zien of die wezenlijk van elkaar verschillen in hoe vaak ze voorkomen in de drie groepen? Ik heb het idee dat dat lastig is omdat die verschillen niet onafhankelijk zijn, maar misschien zie ik iets over het hoofd.
Wat je dan ook kan doen is percentages berekenen per rij of kolom (afhankelijk wat waar staat). Dan zie je of het soort voorwerp groter is per groep.
Of: je laat uitrekenen wat de het verwachte aantal is op basis van de totalen en dan zie je of het geobserveerde aantal afwijkt.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Oke, maar kun je dan daarna ook nog individuele groepen vergelijken (buiten de percentages) via een chi-square of dat niet? (Aangezien de data niet onafhankelijk zijn enzo.) En zou je daarvoor moeten heroveren naar meerdere variabelen met 0 en 1?quote:
[..]
Chi2 kan inderdaad.
Wat je dan ook kan doen is percentages berekenen per rij of kolom (afhankelijk wat waar staat). Dan zie je of het soort voorwerp groter is per groep.
Of: je laat uitrekenen wat de het verwachte aantal is op basis van de totalen en dan zie je of het geobserveerde aantal afwijkt.
Super bedankt! Hij doet hetquote:
IF ANY(0, COPD , diabetes, CVR) patientengroep = 0.
IF ANY(1, COPD , diabetes, CVR) patientengroep = 1.
IF ANY(2, COPD , diabetes, CVR) patientengroep = 2.
IF ANY(3, COPD , diabetes, CVR) patientengroep = 3.
exe.
Never assume, because then you make an ass out of u and me.