SES School, Studie en Onderwijs
Wiskunde in de brugklas, Frans voor het examen of een studie Personeel en Arbeid? Moeilijke formulieren van DUO? Iets weten over studiefinanciering of studentenverenigingen? Dit is het forum voor leerkrachten, scholieren en studenten, van brugklas tot uni



Ooit komt hier vast een mooie OP, maar voor nu:
Dit is een topic voor alle vragen die je hebt over statistiek, SPSS, R, Excel etcetera.
Dit is een topic voor alle vragen die je hebt over statistiek, SPSS, R, Excel etcetera.
Laatste post:

Aangezien het om een correlatie gaat, kun je de nulhypothese dat er geen correlatie is tussen de twee variabelen verwerken. 0.000 is immers lager dan 0.05. Zeggen dat er een effect is (wat ik deed in de eerste post, excuses), zou ik achterwege laten, omdat dat zou kunnen worden gelezen als "Variabele 1 beïnvloed Variabele 2" en die conclusie kun je bij correlaties niet trekken. Er is een samenhang en je kunt beoordelen of deze positief of negatief is en sterk of zwak.quote:Op dinsdag 19 mei 2015 12:12 schreef Tobi-wan het volgende:
[..]
Moet hier toch nog even op terugkomen, het is toch niet helemaal duidelijk. Als de p-waarde 0.000 is in SPSS (dus niet 0 want dat kan niet), kan je de hypothese dat iets geen effect heeft verwerpen?
De uitleg uit mijn vorige past en wat ik hierboven zeg gelden ook voor deze variabelen ja. Zoals je zelf zegt is dit resultaat te verwachten omdat je in beide vragen min of meer hetzelfde meet.quote:[ afbeelding ]
Heb even bovenstaande vergelijking gemaakt omdat het zonder onderzoek aannemelijk is dat deze gegevens met elkaar verbonden zijn. Hier geldt ook hetgeen wat je hierboven plaatste?
De correlatie is er, maar zoals oompaloompa al zei, het hoeft niet perse een lineair verband te zijn. De scatterplots kunnen helpen om daar wat meer inzicht in te krijgen.quote:Of moet ik hier de scatter plot toe te passen om te zien of er echt een correlatie tussen de twee variabelen is?
Ik kom er wel! Nogmaals bedankt! Je krijgt een eervolle vermelding in mijn voorwoordquote:
Laatste post:
[..]
Aangezien het om een correlatie gaat, kun je de nulhypothese dat er geen correlatie is tussen de twee variabelen verwerken. 0.000 is immers lager dan 0.05. Zeggen dat er een effect is (wat ik deed in de eerste post, excuses), zou ik achterwege laten, omdat dat zou kunnen worden gelezen als "Variabele 1 beïnvloed Variabele 2" en die conclusie kun je bij correlaties niet trekken. Er is een samenhang en je kunt beoordelen of deze positief of negatief is en sterk of zwak.
[..]
De uitleg uit mijn vorige past en wat ik hierboven zeg gelden ook voor deze variabelen ja. Zoals je zelf zegt is dit resultaat te verwachten omdat je in beide vragen min of meer hetzelfde meet.
[..]
De correlatie is er, maar zoals oompaloompa al zei, het hoeft niet perse een lineair verband te zijn. De scatterplots kunnen helpen om daar wat meer inzicht in te krijgen.
Graag gedaan.quote:
[..]
Ik kom er wel! Nogmaals bedankt! Je krijgt een eervolle vermelding in mijn voorwoord
vert.zoeken("*" & B1 & "*"; etc)quote:
[..]
Deze pakt die niet als die de waarde uit de cel moet halen, dus:
vert.zoeken("*B1*";A1:A100;1;ONWAAR)
Hoe werken wildcards in deze combinatie?
of, indien je cel met B1 moet beginnen zoals je later schrijft:
vert.zoeken(B1 & " *"; etc)
Sowieso moet je hier Spearman correlatie gebruiken, geen Pearson. Je hebt immers ordinale data. Zal niet veel uitmaken, is wel netter.quote:
[..]
Moet hier toch nog even op terugkomen, het is toch niet helemaal duidelijk. Als de p-waarde 0.000 is in SPSS (dus niet 0 want dat kan niet), kan je de hypothese dat iets geen effect heeft verwerpen?
[ afbeelding ]
Heb even bovenstaande vergelijking gemaakt omdat het zonder onderzoek aannemelijk is dat deze gegevens met elkaar verbonden zijn. Hier geldt ook hetgeen wat je hierboven plaatste?
[..]
Of moet ik hier de scatter plot toe te passen om te zien of er echt een correlatie tussen de twee variabelen is?
Bedankt voor de tip. Scatter plots zijn ook niet echt een optie met ordinale data of wel? Is er een andere manier waarop ik kan aantonen of er een lineair verband is tussen twee variabelen?quote:
[..]
Sowieso moet je hier Spearman correlatie gebruiken, geen Pearson. Je hebt immers ordinale data. Zal niet veel uitmaken, is wel netter.
ordinale data bij ordinale data is nauwelijks goed weer te geven, nee. Tabellen zijn eigenlijk de enige optie (al dan niet met een X*Y Chi-kwadraat toets).quote:
[..]
Bedankt voor de tip. Scatter plots zijn ook niet echt een optie met ordinale data of wel? Is er een andere manier waarop ik kan aantonen of er een lineair verband is tussen twee variabelen?
Met ordinale variabelen is een lineair verband per definitie niet mogelijk. Je moet ordinale data dan eigenlijk eerst transformeren naar een continue varabele, waarvoor je aannames moet gaan doen (bijvoorbeeld dat de 'waarde' van elke categorie gelijk is). Dit is nog enigzins goed te praten als je bijv. leeftijdscategorieen hebt die even groot zijn (bijv 0-10, 11-20, 21-30, etc), anders wordt het vervelender. Waneer je een Pearson correlatie gebruikt, doe je dit impliciet, en dat is dus niet netjes. Spearman correlatie kijkt naar de orde van observaties, en doet dit dus niet.
Oké duidelijk. Ik denk dat ik ook niet te ver hiermee moet gaan. Volgens mij is het relatief veilig om aan te nemen dat iemand die meer tijd doorbrengt op Facebook ook meer vrienden heeft en meer pagina's volgt. Ik hoop een dezer dagen het hoofdstuk resultaten af te sluiten, net nu ik het eindelijk een beetje begin te begrijpen...quote:
[..]
ordinale data bij ordinale data is nauwelijks goed weer te geven, nee. Tabellen zijn eigenlijk de enige optie (al dan niet met een X*Y Chi-kwadraat toets).
Met ordinale variabelen is een lineair verband per definitie niet mogelijk. Je moet ordinale data dan eigenlijk eerst transformeren naar een continue varabele, waarvoor je aannames moet gaan doen (bijvoorbeeld dat de 'waarde' van elke categorie gelijk is). Dit is nog enigzins goed te praten als je bijv. leeftijdscategorieen hebt die even groot zijn (bijv 0-10, 11-20, 21-30, etc), anders wordt het vervelender. Waneer je een Pearson correlatie gebruikt, doe je dit impliciet, en dat is dus niet netjes. Spearman correlatie kijkt naar de orde van observaties, en doet dit dus niet.
Helaas ben ik ook vastgelopen bij de statistische analyse! Zou iemand misschien even kunnen kijken of dit de juiste methode is voor mijn onderzoek? :
Ik onderzoek het effect van één onafhankelijke variabele (Dit gaat om 3 categorieën, namelijk de sector waarin een bedrijf actief is) op één afhankelijke variabele (een percentage, continue variabele dus). Als controlevariabele gebruik ik vier verschillende firma's, ook een categorie dus.
Ik dacht zelf aan een Two-Way ANOVA omdat het in principe gaat om twee onafhankelijke, categoriale variabelen en slechts één continue afhankelijke variabele.
Ik heb ook maar 150 bedrijven in mijn onderzoek betrokken, dus ik hou er rond de 150/(3*3) = 17 over per cel.
Excuus voor de domme vragen maar ik heb nog nooit eerder met SPSS gewerkt voor mijn masterscriptie!
Ik onderzoek het effect van één onafhankelijke variabele (Dit gaat om 3 categorieën, namelijk de sector waarin een bedrijf actief is) op één afhankelijke variabele (een percentage, continue variabele dus). Als controlevariabele gebruik ik vier verschillende firma's, ook een categorie dus.
Ik dacht zelf aan een Two-Way ANOVA omdat het in principe gaat om twee onafhankelijke, categoriale variabelen en slechts één continue afhankelijke variabele.
Ik heb ook maar 150 bedrijven in mijn onderzoek betrokken, dus ik hou er rond de 150/(3*3) = 17 over per cel.
Excuus voor de domme vragen maar ik heb nog nooit eerder met SPSS gewerkt voor mijn masterscriptie!
Op basis van je eerste stukje lijkt een Anova mij het beste (let wel op, anova kijkt of er verschillen tussen de drie groepen zijn, maar zegt niet waar die verschillen zitten, daar moet je contrasten voor gebruiken). Ik begrijp alleen niet zo goed wat je bedoelt met je "controlevariabele", is het een controle variabele of een andere groep?quote:
Helaas ben ik ook vastgelopen bij de statistische analyse! Zou iemand misschien even kunnen kijken of dit de juiste methode is voor mijn onderzoek? :
Ik onderzoek het effect van één onafhankelijke variabele (Dit gaat om 3 categorieën, namelijk de sector waarin een bedrijf actief is) op één afhankelijke variabele (een percentage, continue variabele dus). Als controlevariabele gebruik ik vier verschillende firma's, ook een categorie dus.
Ik dacht zelf aan een Two-Way ANOVA omdat het in principe gaat om twee onafhankelijke, categoriale variabelen en slechts één continue afhankelijke variabele.
Ik heb ook maar 150 bedrijven in mijn onderzoek betrokken, dus ik hou er rond de 150/(3*3) = 17 over per cel.
Excuus voor de domme vragen maar ik heb nog nooit eerder met SPSS gewerkt voor mijn masterscriptie!
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Allereerst bedankt voor deze snelle reactie! Dat eerste klopt, er is over dit onderwerp nog bijna geen onderzoek gedaan. Ik wil dus in eerste instantie gewoon bekijken óf er überhaupt verschillen zijn in de gehanteerde percentages (afhankelijke variabele) in de 3 sectoren (onafhankelijke variabele). En niet zozeer waar die verschillen door veroorzaakt worden.quote:
[..]
Op basis van je eerste stukje lijkt een Anova mij het beste (let wel op, anova kijkt of er verschillen tussen de drie groepen zijn, maar zegt niet waar die verschillen zitten, daar moet je contrasten voor gebruiken). Ik begrijp alleen niet zo goed wat je bedoelt met je "controlevariabele", is het een controle variabele of een andere groep?
Wat betreft de controlevariabele, ik heb geen controlegroep oid. Ik denk alleen dat het gehanteerde percentage niet alleen afhankelijk is van de sector, maar ook van iets anders. Daarom wil ik mijn resultaten zuiverder maken door deze variabele ook op te nemen als een onafhankelijke variabele.
Ik weet alleen of een Two-way ANOVA hier geschikt voor is.
Ik hoop dat het zo iets duidelijker is
Ik weet niet zeker of we hier hetzelfde bedoelen. Anova geeft alleen aan of er een verschil tussen de groepen is. Dus [2,2,8] geeft hetzelfde resultaat als [2,8,2] of [8,2,2].quote:
[..]
Allereerst bedankt voor deze snelle reactie! Dat eerste klopt, er is over dit onderwerp nog bijna geen onderzoek gedaan. Ik wil dus in eerste instantie gewoon bekijken óf er überhaupt verschillen zijn in de gehanteerde percentages (afhankelijke variabele) in de 3 sectoren (onafhankelijke variabele). En niet zozeer waar die verschillen door veroorzaakt worden.
Die kun je toevoegen als een covariaat in een AnCovaquote:Wat betreft de controlevariabele, ik heb geen controlegroep oid. Ik denk alleen dat het gehanteerde percentage niet alleen afhankelijk is van de sector, maar ook van iets anders. Daarom wil ik mijn resultaten zuiverder maken door deze variabele ook op te nemen als een onafhankelijke variabele.
Ik weet alleen of een Two-way ANOVA hier geschikt voor is.
Ik hoop dat het zo iets duidelijker is

Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Hmm, ik hoop wel dat we hetzelfde bedoelen haha! Ik wil gewoon onderzoeken óf er een verschil is tussen de sectoren handel, productie & dienstverlening tov de continue DV (een percentage). Als ik jou voorbeeld neem: als die 8 toe te wijzen is aan een van de sectoren, en de andere sectoren zijn beide 2, dan is voor mij dat verschil toch al bewezen?quote:
[..]
Ik weet niet zeker of we hier hetzelfde bedoelen. Anova geeft alleen aan of er een verschil tussen de groepen is. Dus [2,2,8] geeft hetzelfde resultaat als [2,8,2] of [8,2,2].
[..]
Die kun je toevoegen als een covariaat in een AnCova
Wat betreft de covariantie in een AnCova, die moet continu zijn toch? In mijn geval is het een categorie.
Even heel iets anders: Stel ik maak er geen controlevariabele van maar een modererende variabele,dan kan een Two-way Anova wel weer toch? Dan heb ik twee IV,beide categorieën, en 1 DV, een continue.
Bedankt voor je tips trouwens! Dit helpt me weer de goede kant op
Maar stel nou dat de uitslag 45%, 55% en 90% is. Dan weet je alleen dat er ergens een significant verschil is, maar bv niet of de 55% nog van de 45% verschilt, en of de 90% van de 55% verschilt. Misschien verschilt alleen de 90% van de 45%.. daar kun je contrasten voor gebruiken.quote:
[..]
Hmm, ik hoop wel dat we hetzelfde bedoelen haha! Ik wil gewoon onderzoeken óf er een verschil is tussen de sectoren handel, productie & dienstverlening tov de continue DV (een percentage). Als ik jou voorbeeld neem: als die 8 toe te wijzen is aan een van de sectoren, en de andere sectoren zijn beide 2, dan is voor mij dat verschil toch al bewezen?
Ah dat had ik niet door, dan kun je ze allebei als een losse factor in een enova gooien, en heb je dus een 3 (sector) bij 2 (controle) design en vergelijk je 6 groepen met elkaar. Met je vrij lage sample-size heb je dan wel erg weinig power maar daar valt nu niet meer zo veel aan te doen.quote:Wat betreft de covariantie in een AnCova, die moet continu zijn toch? In mijn geval is het een categorie.
Even heel iets anders: Stel ik maak er geen controlevariabele van maar een modererende variabele,dan kan een Two-way Anova wel weer toch? Dan heb ik twee IV,beide categorieën, en 1 DV, een continue.
Bedankt voor je tips trouwens! Dit helpt me weer de goede kant op
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Leuk topic, als je veel met statistiek bezig bent, kijk dan eens op het Microsoft Azure platform
https://studio.azureml.net/
https://studio.azureml.net/
🕰️₿🕰️₿🕰️₿🕰️₿🕰️₿🕰️ TikTok next Block
Mensen hier bekend met Qualtrics? Ik heb een vraag waarbij mensen een cijfer moesten geven en daarvoor een puntje op een balk konden verschuiven. Als basispositie heb ik alle puntjes op 5 gezet, echter is het nu zo dat als iemand niet met het puntje heeft geschoven en dus de 5 adequaat vond dit niet geregistreerd is als zijnde cijfer 5 ingegeven. Iemand die mij kan vertellen hoe ik dit kan corrigeren?
Als je "request response" aanzet moeten mensen verplicht iig de balk aanklikken.quote:
Mensen hier bekend met Qualtrics? Ik heb een vraag waarbij mensen een cijfer moesten geven en daarvoor een puntje op een balk konden verschuiven. Als basispositie heb ik alle puntjes op 5 gezet, echter is het nu zo dat als iemand niet met het puntje heeft geschoven en dus de 5 adequaat vond dit niet geregistreerd is als zijnde cijfer 5 ingegeven. Iemand die mij kan vertellen hoe ik dit kan corrigeren?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik weet het, alleen is het kwaad nu al geschied. In SPSS had ik de mogelijkheid om zelf het getal in te vullen als het vakje leeg was, ik zie dit in Qualtrics alleen nergens.quote:
[..]
Als je "request response" aanzet moeten mensen verplicht iig de balk aanklikken.
Ik zou dat ook niet doen aangezien je niet weet of die mensen echt 5 wilden zeggen of gewoon lui doorgeklikt hebben.quote:
[..]
Ik weet het, alleen is het kwaad nu al geschied. In SPSS had ik de mogelijkheid om zelf het getal in te vullen als het vakje leeg was, ik zie dit in Qualtrics alleen nergens.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Zit inderdaad wel een kern van waarheid in maar het waren 5 onderdelen opgenomen in 1 tabel zeg maar. Als mensen dan slechts 1 punt niet beoordeeld hebben, neem ik aan dat zij de 5 daar het geschikte cijfer vonden. Als ik dit niet meeneem in mijn analyse ben ik bang dat je een vertekend gemiddelde krijgt.quote:
[..]
Ik zou dat ook niet doen aangezien je niet weet of die mensen echt 5 wilden zeggen of gewoon lui doorgeklikt hebben.
Als je de data zelf toevoegt zou ik daar heel heel heel expliciet over zijn. Zowel dat je het hebt gedaan, als bij de interpretatie aangeven in hoeverre de interpretatie daardoor beinvloedt wordt. En zelfs als je dat doet ligt het nog best op het randje, een randje waar je zeker niet overheen wilt gaan.quote:
[..]
Zit inderdaad wel een kern van waarheid in maar het waren 5 onderdelen opgenomen in 1 tabel zeg maar. Als mensen dan slechts 1 punt niet beoordeeld hebben, neem ik aan dat zij de 5 daar het geschikte cijfer vonden. Als ik dit niet meeneem in mijn analyse ben ik bang dat je een vertekend gemiddelde krijgt.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik zal het verschil eens uitrekenen, maar dan komen we eerst weer terug bij mijn oorspronkelijke vraag: hoe voeg ik de opengelaten data toe?quote:
[..]
Als je de data zelf toevoegt zou ik daar heel heel heel expliciet over zijn. Zowel dat je het hebt gedaan, als bij de interpretatie aangeven in hoeverre de interpretatie daardoor beinvloedt wordt. En zelfs als je dat doet ligt het nog best op het randje, een randje waar je zeker niet overheen wilt gaan.
Dat zou ik dus ook in spss/excel doen, niet in qualtrics, je wilt niet handmatig dingen veranderen in je originele, ruwe, data.quote:
[..]
Ik zal het verschil eens uitrekenen, maar dan komen we eerst weer terug bij mijn oorspronkelijke vraag: hoe voeg ik de opengelaten data toe?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik kan in Qualtrics gewoon meerdere rapporten uitdraaien dus de ruwe data blijft altijd behouden. Ook heb ik gemerkt dat Qualtrics makkelijker werkt dan SPSS en ook een visueel meer aantrekkelijke weergave heeft.quote:
[..]
Dat zou ik dus ook in spss/excel doen, niet in qualtrics, je wilt niet handmatig dingen veranderen in je originele, ruwe, data.
Ik denk niet dat het kan, maar je zou dan wel de ruwe data aanpassen (want je voegt gewoon nummers toe aan je datafile) dus het zou ook echt tegen elke ethische code in gaan..quote:
[..]
Ik kan in Qualtrics gewoon meerdere rapporten uitdraaien dus de ruwe data blijft altijd behouden. Ook heb ik gemerkt dat Qualtrics makkelijker werkt dan SPSS en ook een visueel meer aantrekkelijke weergave heeft.
Je zou dit kunnen proberen, weet niet of dat voor missings werkt: http://www.qualtrics.com/(...)anced/recode-values/ afhankelijk van waar het voor is zou je de ethische code misschien kunnen negeren.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Bedankt voor je bijdrage, heeft me wel aan het denken gezet of het inderdaad wel ethisch verantwoord is. Ik ga me er nog even over beramen, het is voor een adviesrapport in het bedrijf waar ik stage loop.quote:
[..]
Ik denk niet dat het kan, maar je zou dan wel de ruwe data aanpassen (want je voegt gewoon nummers toe aan je datafile) dus het zou ook echt tegen elke ethische code in gaan..
Je zou dit kunnen proberen, weet niet of dat voor missings werkt: http://www.qualtrics.com/(...)anced/recode-values/ afhankelijk van waar het voor is zou je de ethische code misschien kunnen negeren.
De code is voor wetenschap, maar daar is een hooggoed dat je altijd alles helemaal tot de bron moet kunnen herleiden,dusje moet iemand een file kunnen geven met daarin puur alleen wat respondenten aan hebben gegeven zonder inmenging van jezelf, en anderen zouden op basis van die file tot dezelfde conclusies moeten komen als ze jou stappen volgen.quote:
[..]
Bedankt voor je bijdrage, heeft me wel aan het denken gezet of het inderdaad wel ethisch verantwoord is. Ik ga me er nog even over beramen, het is voor een adviesrapport in het bedrijf waar ik stage loop.
Iemand die ik ken, een wetenschapper, is een keer bijna in de problemen gekomen omdat zijn studenten zomaar iets vergelijkbaars deden zonder het duidelijk aan hem door te geven. Dat werd bijna een cariere-verwoestende fraudezaak, daarom hamerde ik er ook zo op.
Daarom ook mijn suggestie om, ondanks dat qualtrics er mooier uit ziet, die data echt in een onafhankelijk file toe te voegen voor je analyse. Succes er mee iig!
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik heb een SPSS analyse vraag (laatste analyse van mijn thesis). Ik ben blij dat ik me door de rest heen heb weten te slaan.
Even korte uitleg:
Ik heb het grafisch inzicht en de prestaties op stock-flow taken (2 onafhankelijke variabelen, ratio niveau, parametrisch) onderzocht bij VMBO scholieren. Nu heb ik deze vergeleken met VWO scholieren uit een andere thesis en bleek zoals verwacht dat VWO scholieren op beide variabelen beter scoorden. Echter is er een significant leeftijdsverschil tussen de VMBO groep en VWO groep (VWO groep is gemiddeld 0.85 jaar ouder). Nu wil ik onderzoeken/analyseren of dit leeftijdsverschil een grotere invloed heeft op de 2 variabelen dan het opleidingsniveau (VWO of VMBO). Mijn begeleider heeft me een aanzet gegeven door te zeggen dat ik hiervoor ANCOVA analyse moet gebruiken. Ik heb echter geen idee hoe ik dit via deze analyse kan analyseren in SPSS en hoe ik dit uiteindelijk in mijn thesis moet opschrijven. Dit wil ik namelijk gebruiken in mijn discussie zodat ik hopelijk kan ontkrachten dat het leeftijdsverschil een grotere invloed heeft.
Kan iemand mij hiermee helpen? Ik hoop dat ik het duidelijk heb omschreven. Alvast enorm bedankt!
Even korte uitleg:
Ik heb het grafisch inzicht en de prestaties op stock-flow taken (2 onafhankelijke variabelen, ratio niveau, parametrisch) onderzocht bij VMBO scholieren. Nu heb ik deze vergeleken met VWO scholieren uit een andere thesis en bleek zoals verwacht dat VWO scholieren op beide variabelen beter scoorden. Echter is er een significant leeftijdsverschil tussen de VMBO groep en VWO groep (VWO groep is gemiddeld 0.85 jaar ouder). Nu wil ik onderzoeken/analyseren of dit leeftijdsverschil een grotere invloed heeft op de 2 variabelen dan het opleidingsniveau (VWO of VMBO). Mijn begeleider heeft me een aanzet gegeven door te zeggen dat ik hiervoor ANCOVA analyse moet gebruiken. Ik heb echter geen idee hoe ik dit via deze analyse kan analyseren in SPSS en hoe ik dit uiteindelijk in mijn thesis moet opschrijven. Dit wil ik namelijk gebruiken in mijn discussie zodat ik hopelijk kan ontkrachten dat het leeftijdsverschil een grotere invloed heeft.
Kan iemand mij hiermee helpen? Ik hoop dat ik het duidelijk heb omschreven. Alvast enorm bedankt!
Davarias gains
Je kunt idd een Ancova gebruiken, waar je leeftijd als een covariaat toevoegt.quote:
Ik heb een SPSS analyse vraag (laatste analyse van mijn thesis). Ik ben blij dat ik me door de rest heen heb weten te slaan.
Even korte uitleg:
Ik heb het grafisch inzicht en de prestaties op stock-flow taken (2 onafhankelijke variabelen, ratio niveau, parametrisch) onderzocht bij VMBO scholieren. Nu heb ik deze vergeleken met VWO scholieren uit een andere thesis en bleek zoals verwacht dat VWO scholieren op beide variabelen beter scoorden. Echter is er een significant leeftijdsverschil tussen de VMBO groep en VWO groep (VWO groep is gemiddeld 0.85 jaar ouder). Nu wil ik onderzoeken/analyseren of dit leeftijdsverschil een grotere invloed heeft op de 2 variabelen dan het opleidingsniveau (VWO of VMBO). Mijn begeleider heeft me een aanzet gegeven door te zeggen dat ik hiervoor ANCOVA analyse moet gebruiken. Ik heb echter geen idee hoe ik dit via deze analyse kan analyseren in SPSS en hoe ik dit uiteindelijk in mijn thesis moet opschrijven. Dit wil ik namelijk gebruiken in mijn discussie zodat ik hopelijk kan ontkrachten dat het leeftijdsverschil een grotere invloed heeft.
Kan iemand mij hiermee helpen? Ik hoop dat ik het duidelijk heb omschreven. Alvast enorm bedankt!
Je vraag is nu nog iets te vaag om te beantwoorden, kijk anders even hoe ver je komt
Voor het idee daarachter zie bijvoorbeeld: http://www.stat.purdue.ed(...)512notes/topic10.pdf
Voor de interpretatie zie bv hier: https://statistics.laerd.(...)pss-statistics-2.php
Ik denk, maar ben net wakker dus neem het met een korreltje zout, dat je nooit helemaal precies accuraat kan schatten welk deel voor hoeveel variantie verantwoordelijk is omdat niveau en leeftijd nou eenmaal heel sterk correleren.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Heel erg bedankt, ga hier mee aan de slag!quote:
[..]
Je kunt idd een Ancova gebruiken, waar je leeftijd als een covariaat toevoegt.
Je vraag is nu nog iets te vaag om te beantwoorden, kijk anders even hoe ver je komt
Voor het idee daarachter zie bijvoorbeeld: http://www.stat.purdue.ed(...)512notes/topic10.pdf
Voor de interpretatie zie bv hier: https://statistics.laerd.(...)pss-statistics-2.php
Ik denk, maar ben net wakker dus neem het met een korreltje zout, dat je nooit helemaal precies accuraat kan schatten welk deel voor hoeveel variantie verantwoordelijk is omdat niveau en leeftijd nou eenmaal heel sterk correleren.
Davarias gains
Ik heb geprobeerd met behulp van Ancova analyse te onderzoeken of het leeftijdsverschil een grotere invloed heeft op grafisch inzicht dan het opleidingsniveau. Nu krijg ik de volgende resultaten (zie foto):
De covariaat (leeftijd) heeft amper de gemiddelden veranderd, maar het verschil tussen beide opleidingsniveaus is nog steeds significant (p < .001) nadat de covariaat is toegevoegd. Ik begrijp (ook na het bestuderen van Field) niet hoe ik deze data nu precies moet interpreteren en op moet schrijven.
Hopelijk kan iemand mij helpen?

De covariaat (leeftijd) heeft amper de gemiddelden veranderd, maar het verschil tussen beide opleidingsniveaus is nog steeds significant (p < .001) nadat de covariaat is toegevoegd. Ik begrijp (ook na het bestuderen van Field) niet hoe ik deze data nu precies moet interpreteren en op moet schrijven.
Hopelijk kan iemand mij helpen?
Davarias gains
Heeft iemand hier verstand van bootstrapping met doel het ontwikkelen van observatie specifieke kritieke Wald scores? Ik probeer dit in combinatie met een SUR.
Deze procedure probeer ik na te bootsen:
Met dit systeem:
Deze procedure probeer ik na te bootsen:


Met dit systeem:

Wie kan me helpen met de volgende vraag.
Voor een onderzoek heb ik een construct dat bestaat uit twee delen: opwinding en angst (het opwinding-angst construct).
Om dit te meten heb ik in een vragenlijst vragen gehad die opwinding meten en vragen die angst meten.
Samen moet deze items één score worden voor het construct opwinding-angst. Dus iemand die zowel hoog scoort op opwinding als angst scoort hoog op dit construct maar iemand die alleen hoog scoort op angst maar niet op opwinding moet niet hoog scoren op dit construct.
Hoe los je dit het beste op, ook met het oog op factor en regressie analyse later in SPSS.
Voor een onderzoek heb ik een construct dat bestaat uit twee delen: opwinding en angst (het opwinding-angst construct).
Om dit te meten heb ik in een vragenlijst vragen gehad die opwinding meten en vragen die angst meten.
Samen moet deze items één score worden voor het construct opwinding-angst. Dus iemand die zowel hoog scoort op opwinding als angst scoort hoog op dit construct maar iemand die alleen hoog scoort op angst maar niet op opwinding moet niet hoog scoren op dit construct.
Hoe los je dit het beste op, ook met het oog op factor en regressie analyse later in SPSS.
Ik kan je helpen als je een iets grotere foto post, deze is neit te lezenquote:
Ik heb geprobeerd met behulp van Ancova analyse te onderzoeken of het leeftijdsverschil een grotere invloed heeft op grafisch inzicht dan het opleidingsniveau. Nu krijg ik de volgende resultaten (zie foto):
[ afbeelding ]
De covariaat (leeftijd) heeft amper de gemiddelden veranderd, maar het verschil tussen beide opleidingsniveaus is nog steeds significant (p < .001) nadat de covariaat is toegevoegd. Ik begrijp (ook na het bestuderen van Field) niet hoe ik deze data nu precies moet interpreteren en op moet schrijven.
Hopelijk kan iemand mij helpen?
Ik begrijp niet zo goed wat je wilt doen. Je hebt twee schalen, angst en opwinding, waarom wil je daar 1 construct van maken? Theoretisch gezien kun je er gewoon de sproductscore van nemen, ik kan me alleen moeilijk situaties voorstellen waarin dat nuttig zou zijn.quote:
Wie kan me helpen met de volgende vraag.
Voor een onderzoek heb ik een construct dat bestaat uit twee delen: opwinding en angst (het opwinding-angst construct).
Om dit te meten heb ik in een vragenlijst vragen gehad die opwinding meten en vragen die angst meten.
Samen moet deze items één score worden voor het construct opwinding-angst. Dus iemand die zowel hoog scoort op opwinding als angst scoort hoog op dit construct maar iemand die alleen hoog scoort op angst maar niet op opwinding moet niet hoog scoren op dit construct.
Hoe los je dit het beste op, ook met het oog op factor en regressie analyse later in SPSS.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Uiteindelijk wil ik teams vergelijken die hoog scoren op zowel opwinding als angst met de overige teams om te kijken of in teams die hoger scoren op de combinatie opwinding-angst er meer fouten worden gemaakt.
Daar zit een heel theoretisch verhaal aan vast waarom dat interessant is waarmee ik je niet zal vervelen (of je moet interesse hebben om mijn thesis achteraf te lezen).
Maargoed, je hebt het over productscores, of te wel het vermenigvuldigen van de twee om tot een score te komen. Dat is misschien best wel een goed oplossing!
Daar zit een heel theoretisch verhaal aan vast waarom dat interessant is waarmee ik je niet zal vervelen (of je moet interesse hebben om mijn thesis achteraf te lezen).
Maargoed, je hebt het over productscores, of te wel het vermenigvuldigen van de twee om tot een score te komen. Dat is misschien best wel een goed oplossing!
Dan zou ik ze gewoon toevoegen alstwee losse IV's en de interactie ook toevoegen, dus:quote:
Uiteindelijk wil ik teams vergelijken die hoog scoren op zowel opwinding als angst met de overige teams om te kijken of in teams die hoger scoren op de combinatie opwinding-angst er meer fouten worden gemaakt.
Daar zit een heel theoretisch verhaal aan vast waarom dat interessant is waarmee ik je niet zal vervelen (of je moet interesse hebben om mijn thesis achteraf te lezen).
Maargoed, je hebt het over productscores, of te wel het vermenigvuldigen van de twee om tot een score te komen. Dat is misschien best wel een goed oplossing!
angst + opwinding + angst*opwinding = score
Dan krijg je de invloed van elk onderdeel en test je dus of het puur een additief effect is of dat hoog op beide juist van belang is.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Hallo,
Ik wil graag efficiëntie/productiviteit van een willekeurig bedrijf berekenen aan de hand van bepaalde gegevens uit een jaarverslag .
Weet iemand of statistische berekenen met SPSS kan en welke variabelen e.d. ik hiervoor nodig heb om de efficiëntie en productiviteit te berekenen?
[ Bericht 13% gewijzigd door RustCohle op 29-05-2015 20:28:24 ]
Ik wil graag efficiëntie/productiviteit van een willekeurig bedrijf berekenen aan de hand van bepaalde gegevens uit een jaarverslag .
Weet iemand of statistische berekenen met SPSS kan en welke variabelen e.d. ik hiervoor nodig heb om de efficiëntie en productiviteit te berekenen?
[ Bericht 13% gewijzigd door RustCohle op 29-05-2015 20:28:24 ]
Dat lijkt me niet iets dat je in spss moet doen, aangezien je niets voorspelt maar gewoon met unieke data een unieke berekening maakt?quote:
Hallo,
Ik wil graag efficiëntie/productiviteit van een willekeurig bedrijf berekenen aan de hand van bepaalde gegevens uit een jaarverslag .
Weet iemand of statistische berekenen met SPSS kan en welke variabelen e.d. ik hiervoor nodig heb om de efficiëntie en productiviteit te berekenen?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Beste forumleden,
Ik als SPSS noob ben bezig met mijn afstudeeronderzoek. Kan iemand mij misschien helpen met onderstaande kwestie?
Het is zo dat ik uit de dataset mensen moet excluderen die van een bepaalde selectie aan vragen er 10 of meer niet ingevuld hebben. Is er in SPSS een functie om dit te doen? Of moet ik echt handmatig selecteren? (het is nogal een grote dataset..)
Ik als SPSS noob ben bezig met mijn afstudeeronderzoek. Kan iemand mij misschien helpen met onderstaande kwestie?
Het is zo dat ik uit de dataset mensen moet excluderen die van een bepaalde selectie aan vragen er 10 of meer niet ingevuld hebben. Is er in SPSS een functie om dit te doen? Of moet ik echt handmatig selecteren? (het is nogal een grote dataset..)
Er zal vast een elegante oplossing zijn, maar wat me zo even te binnen schiet: De missing values coderen als iets heel groots (1000 ofzo). Vervolgens compute variable -> alle variabelen van die selectie optellen. Daarna Select Cases waarbij die variable kleiner is dan 10.000. (Heb even geen SPSS bij de hand, dus een elegantere oplossing zoeken zit er voor mij even niet in.)quote:
Beste forumleden,
Ik als SPSS noob ben bezig met mijn afstudeeronderzoek. Kan iemand mij misschien helpen met onderstaande kwestie?
Het is zo dat ik uit de dataset mensen moet excluderen die van een bepaalde selectie aan vragen er 10 of meer niet ingevuld hebben. Is er in SPSS een functie om dit te doen? Of moet ik echt handmatig selecteren? (het is nogal een grote dataset..)
Goedemiddag,
Momenteel heb ik twee soorten gegevens verzameld: enerzijds de kosten van een bedrijf, anderzijds het aantal geleverde diensten. Ik wil meten in hoeverre de kosten van een bedrijf en het aantal geleverde diensten een verband met elkaar hebben. Daarnaast wil ik een kostencurve schetsen met op de X-as het aantal geleverde diensten (output) en op de Y-as de bedrijfskosten.
Om dit te doen, wil ik gebruik maken van SPSS. Heeft iemand enig idee welke opties/analyses van SPSS geschikt zijn voor het uitvoeren van de gewenste berekeningen/simulaties?
Momenteel heb ik twee soorten gegevens verzameld: enerzijds de kosten van een bedrijf, anderzijds het aantal geleverde diensten. Ik wil meten in hoeverre de kosten van een bedrijf en het aantal geleverde diensten een verband met elkaar hebben. Daarnaast wil ik een kostencurve schetsen met op de X-as het aantal geleverde diensten (output) en op de Y-as de bedrijfskosten.
Om dit te doen, wil ik gebruik maken van SPSS. Heeft iemand enig idee welke opties/analyses van SPSS geschikt zijn voor het uitvoeren van de gewenste berekeningen/simulaties?
Ik zou een regressie doen van kosten op output en dan verschillende relaties proberen. De standaard-regressie test een linear verband (dus x*kosten = output) maar je kunt verschillende vormen testen, en je kunt zelfs je eigen varianten testen.quote:
Goedemiddag,
Momenteel heb ik twee soorten gegevens verzameld: enerzijds de kosten van een bedrijf, anderzijds het aantal geleverde diensten. Ik wil meten in hoeverre de kosten van een bedrijf en het aantal geleverde diensten een verband met elkaar hebben. Daarnaast wil ik een kostencurve schetsen met op de X-as het aantal geleverde diensten (output) en op de Y-as de bedrijfskosten.
Om dit te doen, wil ik gebruik maken van SPSS. Heeft iemand enig idee welke opties/analyses van SPSS geschikt zijn voor het uitvoeren van de gewenste berekeningen/simulaties?
Misschien het beste als eerste een scatterplot maken met kosten op k-as en output op y om visueel te kijken wat voor soort verband er lijkt te bestaan?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Welke soort regressietest raad jij mij aan? Wat is precies het verschil tussen een scatterplot en een regressietest, aangezien beide testen berekenen/weergeven in hoeverre er een verband is waar te nemen?quote:
[..]
Ik zou een regressie doen van kosten op output en dan verschillende relaties proberen. De standaard-regressie test een linear verband (dus x*kosten = output) maar je kunt verschillende vormen testen, en je kunt zelfs je eigen varianten testen.
Misschien het beste als eerste een scatterplot maken met kosten op k-as en output op y om visueel te kijken wat voor soort verband er lijkt te bestaan?
Scatterplot geeft je gewoon een grafiekje, de regressie test het verband.quote:
[..]
Welke soort regressietest raad jij mij aan? Wat is precies het verschil tussen een scatterplot en een regressietest, aangezien beide testen berekenen/weergeven in hoeverre er een verband is waar te nemen?
Welk verband uiteindelijk het beste je data omschrijft weet ik niet, dat ligt aan je data
Daarom ook het beste beginnen met een scatterplot!
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
http://nl.wikipedia.org/wiki/Spreidingsdiagramquote:
[..]
Scatterplot geeft je gewoon een grafiekje, de regressie test het verband.
Welk verband uiteindelijk het beste je data omschrijft weet ik niet, dat ligt aan je data
Daarom ook het beste beginnen met een scatterplot!
''Voorbeeld 1
Uit de bevolking is een steekproef van 100 proefpersonen getrokken en van elke proefpersoon is de lengte L en het gewicht G gemeten. De grafiek van de 100 punten (Li,Gi) geeft een puntenwolk, waarin men het "verband" tussen lengte en gewicht kan zien.''
http://www.spsshandboek.nl/regressie_analyse/
''Je gebruikt de regressie analyse om te toetsen of een onafhankelijke variabele invloed heeft op een afhankelijke variabele en of dit een positief of een negatief effect is''
Beide kijken toch in principe naar de correlatie?
Nee, daar kunnen we in het abstracte over blijven praten, of je kunt het gewoon proberen en dan zul je zien dat het iets anders doetquote:
[..]
http://nl.wikipedia.org/wiki/Spreidingsdiagram
''Voorbeeld 1
Uit de bevolking is een steekproef van 100 proefpersonen getrokken en van elke proefpersoon is de lengte L en het gewicht G gemeten. De grafiek van de 100 punten (Li,Gi) geeft een puntenwolk, waarin men het "verband" tussen lengte en gewicht kan zien.''
http://www.spsshandboek.nl/regressie_analyse/
''Je gebruikt de regressie analyse om te toetsen of een onafhankelijke variabele invloed heeft op een afhankelijke variabele en of dit een positief of een negatief effect is''
Beide kijken toch in principe naar de correlatie?
Zoals ik al eerder zei, een scatterplot laat alleen punten zien, een regressie berekent een verband, dat verband dat je wilt testen kun je zelf aangeven. Je kunt duizenden verbanden testen maar dat kost nogal veel energie, darom kun je het beste eerst naar de data kijken, om uit te zoeken welke verbanden logisch zijn om te testen.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik wil kort gezegd een grafiek schetsen met SPSS om te kijken of er een bepaalde vorm is te vinden tussen Y (gemiddelde bedrijfskosten) en X (output, geleverde diensten). Zo ja, dan wordt de hypothese als waar aangenomen. Zo niet, dan wordt de hypothese verworpen.quote:
[..]
Nee, daar kunnen we in het abstracte over blijven praten, of je kunt het gewoon proberen en dan zul je zien dat het iets anders doet
Zoals ik al eerder zei, een scatterplot laat alleen punten zien, een regressie berekent een verband, dat verband dat je wilt testen kun je zelf aangeven. Je kunt duizenden verbanden testen maar dat kost nogal veel energie, darom kun je het beste eerst naar de data kijken, om uit te zoeken welke verbanden logisch zijn om te testen.
Echter wil ik daarnaast een test uitvoeren waarbij er een bepaalde grens zit om de hypothese als (on)waar te beschouwen. Het kan wel grafisch gezien een bepaalde vorm hebben, maar er moet wel een 'significantie' test erop uitgevoerd worden om zodoende, statistisch gezien, het visuele te bevestigen/ontkrachten.
Het legt echt veel gemakkelijker uit als je de data er bij kunt zien. Zodra je een plotje etc post kan ik meer uitleggen over de verschillende mogelijkheden en hoe die werken.quote:
[..]
Ik wil kort gezegd een grafiek schetsen met SPSS om te kijken of er een bepaalde vorm is te vinden tussen Y (gemiddelde bedrijfskosten) en X (output, geleverde diensten). Zo ja, dan wordt de hypothese als waar aangenomen. Zo niet, dan wordt de hypothese verworpen.
Echter wil ik daarnaast een test uitvoeren waarbij er een bepaalde grens zit om de hypothese als (on)waar te beschouwen. Het kan wel grafisch gezien een bepaalde vorm hebben, maar er moet wel een 'significantie' test erop uitgevoerd worden om zodoende, statistisch gezien, het visuele te bevestigen/ontkrachten.
[ Bericht 10% gewijzigd door oompaloompa op 31-05-2015 17:31:53 ]
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Begrijp je zelf wel wat je wilt doen? Het klinkt namelijk erg vaag en abstract.quote:
[..]
Ik wil kort gezegd een grafiek schetsen met SPSS om te kijken of er een bepaalde vorm is te vinden tussen Y (gemiddelde bedrijfskosten) en X (output, geleverde diensten). Zo ja, dan wordt de hypothese als waar aangenomen. Zo niet, dan wordt de hypothese verworpen.
Echter wil ik daarnaast een test uitvoeren waarbij er een bepaalde grens zit om de hypothese als (on)waar te beschouwen. Het kan wel grafisch gezien een bepaalde vorm hebben, maar er moet wel een 'significantie' test erop uitgevoerd worden om zodoende, statistisch gezien, het visuele te bevestigen/ontkrachten.
Als je een hypothese wilt testen, dan moet je over het algemeen een regressie doen. Welke vorm? Dat hangt inderdaad af van de data en jouw kennis. Maar zoals oompaloompa al zegt, nuttig advies is lastig te geven als je niet concreter bent over je dataset.
quote:
[..]
Het legt echt veel gemakkelijker uit als je de data er bij kunt zien. Zodra je een plotje etc post kan ik meer uitleggen over de verschillende mogelijkheden en hoe die werken.
Ik ben er al uit! Bedankt in ieder geval. Ik heb uiteindelijk gekozen voor een regressie-analyse en een diagram in plaats van een scatterplot.quote:
[..]
Begrijp je zelf wel wat je wilt doen? Het klinkt namelijk erg vaag en abstract.
Als je een hypothese wilt testen, dan moet je over het algemeen een regressie doen. Welke vorm? Dat hangt inderdaad af van de data en jouw kennis. Maar zoals oompaloompa al zegt, nuttig advies is lastig te geven als je niet concreter bent over je dataset.
Echter heb ik wel een ander vraagje met betrekking tot SPSS. Het is makkelijk aan te tonen, maar heb dit gelieve via SPSS:
Ik wil aantonen dat de kosten in periode 2 gedaald zijn ten opzichte van periode 1. Hoe kan ik dit het beste aantonen via SPSS? Periode 1 bestaat uit vier jaren en periode 2 bestaat uit drie jaren.
Ok dan heb je dus een linear verband getest.quote:
[..]
[..]
Ik ben er al uit! Bedankt in ieder geval. Ik heb uiteindelijk gekozen voor een regressie-analyse en een diagram in plaats van een scatterplot.
Als de specifieke kosten gedaald zijn, dan hoef je daar geen toets op uit te voeren, alleen als je het wil generaliseren naar de populatie hoef je een toets te doen. Als je random observaties hebt, 1 per bedrijf, kun je een anova doen of een t-test om het gemiddelde van de twee periodes met elkaar te vergelijken. Als je data binnen bedrijven hebt van meerdere bedrijven zul je een repeated measures toe moeten passen, bv. een Mancova (of bij 2 datapunten per bedrijf, 1 in periode 1, 1 in periode 2) kun je een paired t-test doen.quote:Echter heb ik wel een ander vraagje met betrekking tot SPSS. Het is makkelijk aan te tonen, maar heb dit gelieve via SPSS:
Ik wil aantonen dat de kosten in periode 2 gedaald zijn ten opzichte van periode 1. Hoe kan ik dit het beste aantonen via SPSS? Periode 1 bestaat uit vier jaren en periode 2 bestaat uit drie jaren.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Dat hoef je niet met statistiek aan te tonen, dat is zo, of dat is niet zo. Je hoeft alleen statistiek te gebruiken als je het wilt generaliseren naar bedrijven in het algemeen, maar dan zul je meer dan 1 case nodig hebben.quote:
[..]
Ik heb de data in SPSS zo ingevoerd dat er sprake is van drie bedrijven:
Bedrijf 1 is een fusiebedrijf
Bedrijf 2 is één van de twee bedrijven ontstaan door de opsplitsing van bedrijf 1.
Bedrijf 3 is één van de twee bedrijven ontstaan door de opsplitsing van bedrijf 1.
Wat ik wil aantonen, via SPSS, is dat de kosten van zowel bedrijf 2 als 3 gedaald zijn na opsplitsing van bedrijf 1.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Dat ik daar geen statistiek voor nodig heb, is mij duidelijk. Dat gaf ik al in mijn eerste post betreffende deze vraag aan. Desondanks vind ik het altijd leuk om statistiek te gebruiken, hoe simpel de vraag ook mag zijn.quote:
[..]
Dat hoef je niet met statistiek aan te tonen, dat is zo, of dat is niet zo. Je hoeft alleen statistiek te gebruiken als je het wilt generaliseren naar bedrijven in het algemeen, maar dan zul je meer dan 1 case nodig hebben.
Echt niet lullig bedoeld, maar ik weet gewoon niet hoe ik hier op moet antwoorden, je vraag slaat nergens op.quote:
[..]
Dat ik daar geen statistiek voor nodig heb, is mij duidelijk. Dat gaf ik al in mijn eerste post betreffende deze vraag aan. Desondanks vind ik het altijd leuk om statistiek te gebruiken, hoe simpel de vraag ook mag zijn.
Het is een beetje alsof je vraagt hoe je kaas bij voetbal moet gebruiken.
betere metafoor; het is alsof je vraagt hoe je de wet van Newton toe moet passen om te weten wanneer de Tweede wereldoorlog begon, ja wikipedia is idd gemakkelijker maar ik vind het leuker om d.m.v. natuurkundige formules tot een antwoord te komen.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Hallo,
Ik heb een model gemaakt via een regressie-analyse met de volgende variabelen:
-Onafhankelijke variabele: output
-Afhankelijke variabele: gemiddelde bedrijfskosten
De resultaten zijn het volgende, waarbij b = gemiddelde bedrijfskosten en c = output:
Ik heb een model gemaakt via een regressie-analyse met de volgende variabelen:
-Onafhankelijke variabele: output
-Afhankelijke variabele: gemiddelde bedrijfskosten
De resultaten zijn het volgende, waarbij b = gemiddelde bedrijfskosten en c = output:
SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.In de laatste figuur staan er twee significanties.. Naar welke zou ik moeten kijken en wat zou ik kunnen concluderen? Is er een negatief, geen of een positief verband?
[ Bericht 0% gewijzigd door Super-B op 02-06-2015 14:57:49 ]

Zitten hier ook R specialisten... Ik heb een R package geschreven en heb een import voor mijn dependencies in de NAMESPACE gezet maar als ik hem nu in een lege R installeert gaat hij de pakketten niet instaleren, ook komt één pakket niet van CRAN maar van bioconductor dus moet ik de repository wijzigen, ik heb geen idee waar ik dat moet aangeven... Of moet dat gewoon hard in de DESCRIPTION of NAMESPACE gezet worden (en hoe)...
Een ander ding waar ik nog wel eens tegen aan loop en hier ook gelijk wel eens kan vragen als je een apply (of variant daarvan lapply mapply vapply) doet is het dan ook mogelijk om daar het iteratie nummer uit te halen, zeg maar welk deel van de loop hij daadwerkelijk mee bezig is.
Een ander ding waar ik nog wel eens tegen aan loop en hier ook gelijk wel eens kan vragen als je een apply (of variant daarvan lapply mapply vapply) doet is het dan ook mogelijk om daar het iteratie nummer uit te halen, zeg maar welk deel van de loop hij daadwerkelijk mee bezig is.
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
quote:
Hallo,
Ik heb een model gemaakt via een regressie-analyse met de volgende variabelen:
-Onafhankelijke variabele: output
-Afhankelijke variabele: bedrijfskosten
De resultaten zijn het volgende, waarbij b = bedrijfskosten en c = output:Niet dat je gaat luisteren, maar je kunt vrij weinig concluderen aangezien standard-error 0 is en je dus op basis van 1 observatie lijkt te werken? (gokje, kan ook iets anders zijn eventueel maar een SE van 0 verpest je analyses)SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.In de laatste figuur staan er twee significanties.. Naar welke zou ik moeten kijken en wat zou ik kunnen concluderen? Is er een negatief, geen of een positief verband?Geen oplossing, maar kun je ze niet gewoon handmatig permanent in R zetten?quote:Op dinsdag 2 juni 2015 14:48 schreef Bosbeetle het volgende:
Zitten hier ook R specialisten... Ik heb een R package geschreven en heb een import voor mijn dependencies in de NAMESPACE gezet maar als ik hem nu in een lege R installeert gaat hij de pakketten niet instaleren, ook komt één pakket niet van CRAN maar van bioconductor dus moet ik de repository wijzigen, ik heb geen idee waar ik dat moet aangeven... Of moet dat gewoon hard in de DESCRIPTION of NAMESPACE gezet worden (en hoe)...Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Jawel maar ik wil dat pakket gaan distribueren onder mensen met wie ik samenwerk en ik wil hun graag een pakketje leveren dat werkt en dus zelf al de dependencies gaat installeren. Ik ben redelijk op weg en heb nu fatsoenlijke robuste S3methodes voor image analyse lopen maar het blijft een geetter om het even snel op een andere computer te zetten.quote:
Geen oplossing, maar kun je ze niet gewoon handmatig permanent in R zetten?
Ik zit nu heel hard te twijfelen of ik moet investeren in Rcpp om de boel nog sneller te krijgen.
Ben ook bezig om een shiny interface er bij te maken maar dat heeft ook nogal wat voeten in de aarde....
[ Bericht 15% gewijzigd door Bosbeetle op 02-06-2015 14:58:21 ]
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Wat is handig om toe te voegen als observatie? De winst?quote:
[..]
Niet dat je gaat luisteren, maar je kunt vrij weinig concluderen aangezien standard-error 0 is en je dus op basis van 1 observatie lijkt te werken? (gokje, kan ook iets anders zijn eventueel maar een SE van 0 verpest je analyses)
[..]
Geen oplossing, maar kun je ze niet gewoon handmatig permanent in R zetten?
Ik werk met y = gemiddelde bedrijfskosten (afhankelijke) en x = output (onafhankelijke).
En gewoon als eerste een blokje schrijven dat get & installt wat dus redundant is als ze de packages al hebben en anders gewoon runt? Niet de meest charmante oplossing, maar zou wel moeten werken toch?quote:
[..]
Jawel maar ik wil dat pakket gaan distribueren onder mensen met wie ik samenwerk en ik wil hun graag een pakketje leveren dat werkt en dus zelf al de dependencies gaat installeren. Ik ben redelijk op weg en heb nu fatsoenlijke robuste S3methodes voor image analyse lopen maar het blijft een geetter om het even snel op een andere computer te zetten.
Sorry gebruik R heel weinig, ed scripts die ik gebruik doen het meestal op de slordige get manier.
Je hebt 5 onafhankelijke datapunten toch?quote:
[..]
Wat is handig om toe te voegen als observatie? De winst?
Ik werk met y = bedrijfskosten (afhankelijke) en x = output (onafhankelijke).
Dus van 5 random bedrijven de kosten en de output, zo niet, wat zijn precies je observaties?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik heb de afhankelijke variabele veranderd: van gemiddelde bedrijfskosten naar totale bedrijfskosten en er blijkt nu wél een standaard error te zijn.quote:
[..]
Niet dat je gaat luisteren, maar je kunt vrij weinig concluderen aangezien standard-error 0 is en je dus op basis van 1 observatie lijkt te werken? (gokje, kan ook iets anders zijn eventueel maar een SE van 0 verpest je analyses)
[..]
Geen oplossing, maar kun je ze niet gewoon handmatig permanent in R zetten?
Ik heb de kosten en de output van de afgelopen vier jaren op een rij gezet in SPSS van drie bedrijven, maar ik observeer de relatie tussen de kosten en output van één bedrijf.quote:
[..]
En gewoon als eerste een blokje schrijven dat get & installt wat dus redundant is als ze de packages al hebben en anders gewoon runt? Niet de meest charmante oplossing, maar zou wel moeten werken toch?
Sorry gebruik R heel weinig, ed scripts die ik gebruik doen het meestal op de slordige get manier.
[..]
Je hebt 5 onafhankelijke datapunten toch?
Dus van 5 random bedrijven de kosten en de output, zo niet, wat zijn precies je observaties?
Tja maar ik weet dus niet waar ik een stukje code neer moet zetten zodat hij het runt als je het package installeert... het installeren van het package gaat prima en als je de dependencies al hebt geinstalleert dan doet hij de library() stapjes wel automagisch maar het installeren dus niet...quote:
En gewoon als eerste een blokje schrijven dat get & installt wat dus redundant is als ze de packages al hebben en anders gewoon runt? Niet de meest charmante oplossing, maar zou wel moeten werken toch?
Sorry gebruik R heel weinig, ed scripts die ik gebruik doen het meestal op de slordige get manier.
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Ok, het is sowieso waarschijnlijk incorrect, maar als je in de regressie output kijken staat daar ergens links een B-waarde in de tweede colom, dat is het effect van X op Y. als de B bijvoorbeeld 0.5 is, is het effect van X een stapje hoger maken een toename van Y van 0.5.quote:
[..]
Ik heb de kosten en de output van de afgelopen vier jaren op een rij gezet in SPSS van drie bedrijven, maar ik observeer de relatie tussen de kosten en output van één bedrijf.
De sig-waarde zegt (kort door de bocht) hoe groot de kans zou zijn zo'n B-waarde of een hogere te vinden als er in de populatie eigenlijk geen effect van X op Y is.
Sorry dude, dit is way beyond me danquote:
[..]
Tja maar ik weet dus niet waar ik een stukje code neer moet zetten zodat hij het runt als je het package installeert... het installeren van het package gaat prima en als je de dependencies al hebt geinstalleert dan doet hij de library() stapjes wel automagisch maar het installeren dus niet...
Veel succes!
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
quote:
Sorry dude, dit is way beyond me dan
Veel succes!
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Naar welke sig zou ik moeten kijken? Naar de sig in de eerste of de tweede rij?quote:
[..]
Ok, het is sowieso waarschijnlijk incorrect, maar als je in de regressie output kijken staat daar ergens links een B-waarde in de tweede colom, dat is het effect van X op Y. als de B bijvoorbeeld 0.5 is, is het effect van X een stapje hoger maken een toename van Y van 0.5.
De sig-waarde zegt (kort door de bocht) hoe groot de kans zou zijn zo'n B-waarde of een hogere te vinden als er in de populatie eigenlijk geen effect van X op Y is.
[..]
Sorry dude, dit is way beyond me dan
Veel succes!
Naar de rij die bij je variabele hoort. Links (precies het vakje dat je af gesneden hebt in je foto) staat als het goed is de veriabele naam. De eerste is je intercept, die kun je negeren, de tweede zou iets van kosten moeten zijn.quote:
[..]
Naar welke sig zou ik moeten kijken? Naar de sig in de eerste of de tweede rij?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Je hebt echt 0,0 aan een regressie als je zo weinig observaties hebt. Je steekproef moet echt veel groter zijn om er nuttige conclusies uit te trekken.
Zo diep gaat mijn R kennis helaas ook niet.quote:
Zitten hier ook R specialisten... Ik heb een R package geschreven en heb een import voor mijn dependencies in de NAMESPACE gezet maar als ik hem nu in een lege R installeert gaat hij de pakketten niet instaleren, ook komt één pakket niet van CRAN maar van bioconductor dus moet ik de repository wijzigen, ik heb geen idee waar ik dat moet aangeven... Of moet dat gewoon hard in de DESCRIPTION of NAMESPACE gezet worden (en hoe)...
Een ander ding waar ik nog wel eens tegen aan loop en hier ook gelijk wel eens kan vragen als je een apply (of variant daarvan lapply mapply vapply) doet is het dan ook mogelijk om daar het iteratie nummer uit te halen, zeg maar welk deel van de loop hij daadwerkelijk mee bezig is.
Misschien de R-package-devel of R-devel mailinglist eens proberen?
http://www.r-project.org/mail.html
Daar is iedereen het hier over eens, maar om de een of andere reden wil Super-B het toch proberen omdat hij het leuk vindt om iets nutteloos te doen geloof ik.quote:
Je hebt echt 0,0 aan een regressie als je zo weinig observaties hebt. Je steekproef moet echt veel groter zijn om er nuttige conclusies uit te trekken.
Beste FOKkers,
Nu mijn vorige kwestie is opgelost, een nieuwe vraag:
(Ja, dit is de eerste keer dat ik met SPSS werk, nee ik ben er totaal niet handig mee en ja, ik heb een erg strakke deadline , bij deze dus mijn excuses)
, bij deze dus mijn excuses)
Ik heb een dataset met daarin per case informatie over hulp bij de bevalling en met 5 somscores van een persoonlijkheidstest (NEO-FFI voor de liefhebber). Ik wil in een tabel het gemiddelde aantal spontane geboortes en kunstverlossingen uitzetten tegen de verschillende persoonlijkheidstypes.
Kan iemand mij vertellen hoe ik in SPSS deze tabel het beste kan maken? Ik heb Crosstabs geprobeerd maar krijg dan per persoonlijkheidstype een tabel met alle mogelijke somscores en per somscore het aantal kunst/spontane geboortes.
Sorry voor de onduidelijke uitleg, krijg mijn printscreen van de tabel niet in het bericht gevoegd.
Nu mijn vorige kwestie is opgelost, een nieuwe vraag:
(Ja, dit is de eerste keer dat ik met SPSS werk, nee ik ben er totaal niet handig mee en ja, ik heb een erg strakke deadline
Ik heb een dataset met daarin per case informatie over hulp bij de bevalling en met 5 somscores van een persoonlijkheidstest (NEO-FFI voor de liefhebber). Ik wil in een tabel het gemiddelde aantal spontane geboortes en kunstverlossingen uitzetten tegen de verschillende persoonlijkheidstypes.
Kan iemand mij vertellen hoe ik in SPSS deze tabel het beste kan maken? Ik heb Crosstabs geprobeerd maar krijg dan per persoonlijkheidstype een tabel met alle mogelijke somscores en per somscore het aantal kunst/spontane geboortes.
Sorry voor de onduidelijke uitleg, krijg mijn printscreen van de tabel niet in het bericht gevoegd.
Als je wilt weten wat de invloed is van de persoonlijkheidstypes op aantal kunstverlossingen / spontane geboortes zou ik een regressie doen, dit omdat persoonlijkheid een schaal is. Wat die regressie kort door de bocht test is bv hoe neurotischer iemand is, hoe groter de kans op x.quote:
Beste FOKkers,
Nu mijn vorige kwestie is opgelost, een nieuwe vraag:
(Ja, dit is de eerste keer dat ik met SPSS werk, nee ik ben er totaal niet handig mee en ja, ik heb een erg strakke deadline
Ik heb een dataset met daarin per case informatie over hulp bij de bevalling en met 5 somscores van een persoonlijkheidstest (NEO-FFI voor de liefhebber). Ik wil in een tabel het gemiddelde aantal spontane geboortes en kunstverlossingen uitzetten tegen de verschillende persoonlijkheidstypes.
Kan iemand mij vertellen hoe ik in SPSS deze tabel het beste kan maken? Ik heb Crosstabs geprobeerd maar krijg dan per persoonlijkheidstype een tabel met alle mogelijke somscores en per somscore het aantal kunst/spontane geboortes.
Sorry voor de onduidelijke uitleg, krijg mijn printscreen van de tabel niet in het bericht gevoegd.
Omdat je afhankelijke dichotoom is (ja of nee) zul je een logistische regressie moeten doen. Speel daar anders even mee en kijk hoe ver je komt. Als je de output post kunnen wij in de thread je met de interpretatie helpen, maar dat gaat fijner met behulp van de output.
Een andere optie is om je data juist te splitsen op kunstgeboorte vs spontane geboorte en dan kijken of de gemiddelden op de persoonlijkheidsschalen tussen die twee groepen verschillen. Dat is een stuk gemakkelijker om te doen maar dat geeft je niet echt een antwoord op hoe groot het effect is van persoonlijkheid op die kans, alleen of er een verschil is. (het geeft je wel iets van grootte maar die is moeilijk interpreteerbaar).
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
printscreen of zo maken (of rechtermuisknop save as jpg kan volgens mij ook, en dan uploaden op bv imgur.com. Dan krijg je een linkje dat je hier kunt postenquote:
Ok, misschien een stomme vraag maar hoe kan ik de output hier posten?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ben nu druk bezig met mijn bijlage in orde te maken. Aanstaande maandag mijn scriptie inleveren 
Heb bijna alleen gebruik gemaakt van schalen waardoor ik ordinale variabelen heb. Is het dan interessant om de standaarddeviatie er bij te zetten of kan ik dat beter weg laten. Ze zitten allemaal tussen den 0,8 en 1 wat volgens mij komt omdat de antwoorden altijd 1, 2, 3, 4 of 5 zijn.
Daarnaast heb ik niet een hele grote populatie. Volgens mij verteld de standaarddeviatie mij niet zoveel...
Edit: volgens mij moet std. dev. er altijd bij als je met gemiddeldes werkt.
[ Bericht 7% gewijzigd door Tobi-wan op 03-06-2015 14:03:32 ]
Heb bijna alleen gebruik gemaakt van schalen waardoor ik ordinale variabelen heb. Is het dan interessant om de standaarddeviatie er bij te zetten of kan ik dat beter weg laten. Ze zitten allemaal tussen den 0,8 en 1 wat volgens mij komt omdat de antwoorden altijd 1, 2, 3, 4 of 5 zijn.
Daarnaast heb ik niet een hele grote populatie. Volgens mij verteld de standaarddeviatie mij niet zoveel...
Edit: volgens mij moet std. dev. er altijd bij als je met gemiddeldes werkt.
[ Bericht 7% gewijzigd door Tobi-wan op 03-06-2015 14:03:32 ]
De standaard deviatie geeft iets aan over de spreiding. Zo zou je een gemiddelde van 1.8 kunnen hebben op je schaal met een SD van bijna 0 (iedereen zegt 2 een paar zeggen 1) of een enorme hoge SD (veel mensen zeggen 4 of 5, meeste zeggen 1 of 2). Ik zou hem dus altijd rapporterenquote:
Ben nu druk bezig met mijn bijlage in orde te maken. Aanstaande maandag mijn scriptie inleveren
Heb bijna alleen gebruik gemaakt van schalen waardoor ik ordinale variabelen heb. Is het dan interessant om de standaarddeviatie er bij te zetten of kan ik dat beter weg laten. Ze zitten allemaal tussen den 0,8 en 1 wat volgens mij komt omdat de antwoorden altijd 1, 2, 3, 4 of 5 zijn.
Daarnaast heb ik niet een hele grote populatie. Volgens mij verteld de standaarddeviatie mij niet zoveel...
Edit: volgens mij moet std. dev. er altijd bij als je met gemiddeldes werkt.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Bedankt! Het is inderdaad wel nuttige informatie. Van al die cijfers wordt ik af een toe een beetje duizelig en dan ontgaat het logisch nadenken mij enigszins.quote:
[..]
De standaard deviatie geeft iets aan over de spreiding. Zo zou je een gemiddelde van 1.8 kunnen hebben op je schaal met een SD van bijna 0 (iedereen zegt 2 een paar zeggen 1) of een enorme hoge SD (veel mensen zeggen 4 of 5, meeste zeggen 1 of 2). Ik zou hem dus altijd rapporteren
Ik heb eerder in dit topic om hulp gevraagd bij het implementeren van een bepaalde procedure en geen hulp gehad, maar ik heb van de originele auteur de code gekregen. Helaas wel in TSP, een gedateerd programma, dus nu is het zaak om deze code om te schrijven naar R of Stata. Heeft iemand kennis van TSP en R/Stata die mij hierbij kan helpen? Of iemand die mij een pb kan sturen met een link naar TSP?
Ik heb wel wat kennis van R, maar niet zo heel veel/diepgaande. Ik wil wel proberen je te helpen, maar ik kan niks garanderen (ik ben een beetje je long shot). PM/DM mag altijd.quote:
Ik heb eerder in dit topic om hulp gevraagd bij het implementeren van een bepaalde procedure en geen hulp gehad, maar ik heb van de originele auteur de code gekregen. Helaas wel in TSP, een gedateerd programma, dus nu is het zaak om deze code om te schrijven naar R of Stata. Heeft iemand kennis van TSP en R/Stata die mij hierbij kan helpen? Of iemand die mij een pb kan sturen met een link naar TSP?
Overigens een aanstelling gekregen bij de methodology shop op de uni.
Your opinion of me is none of my business.
Bleh, zit even vast.
Ik onderzoek hoe een zestal antecedenten in relatie staat tot een afhankelijke variabele. De afhankelijke variabele is Organizational Identification - hoe mensen zich identificeren met een organisatie. Komt uiteindelijk dus een regressie analyse aan te pas, en een standaard regressie analyse heb ik ook al wel gehad in de studie.
Maar zitten wat haken en ogen aan bij mij:
- Ik richt mij op alle betaald voetbalclubs *Eredivisie en Jupiler)
- Ik maak een vergelijking tussen 3 stakeholder groepen (supporters, sponsoren en lokale politiek)
Van supporters heb ik van 33 clubs respondenten. Maar van PSV heb ik er bijvoorbeeld 380, van Ajax 140, van Vitesse 120 en van NEC 110... maar van kleine clubs als een Helmond Sport maar 1 bijvoorbeeld. In totaal heb ik er 1132
Van sponsoren heb ik er een stuk of 40 van Heerenveen, 30 van Willem II, 15 van FC Twente en voor aantal andere clubs rond de 10 elk. In totaal 323 sponsoren als respondent. Maar ik heb er 0 voor PSV en Ajax, die bij supporters het gros van de respondenten vormen.
Lokale politiek in de vorm van gemeenteraadsleden heb ik 10 a 15 respondenten voor elke gemeente, in totaal 417 respondenten.
Origineel was het idee om voor 1 club het onderzoek te doen. Maar omdat je van sponsoren en gemeenteraadsleden maar een tiental respondenten zou krijgen besloten om meer clubs bijeen te pakken en 'een betaald voetbalclub' het onderwerp te maken ipv bijvoorbeeld 'Vitesse' of 'Ajax'. Want voor multiple regression liefst 20 respondenten per onafhankelijke variabele, in mijn geval dus 120.
Nu zit ik dus met de volgende dingen:
- Mbt poolen van de data: kan je het zomaar allemaal bij elkaar gooien of zijn daar methodes voor en moet je gewichten er aan hangen oid? Kan via google niet echt vinden.
- Ik vergelijk dus 3 stakeholder groepen; als ik items ga verwijderen op basis van Reliability test (Cronbach alpha) en Discriminant validity (Factor analyse, dubbelladers en structuur) moet ik dan hetzelfde verwijderen bij elke groep? Dus als item X een dubbellader is bij de Supporters, maar niet bij de Sponsoren, dan wel bij beiden weghalen zodat beide modellen gelijk zijn aan elkaar als je gaat vergelijken, of wel op maat maken per groep?
- Supporters identificeren zich sws al vrij snel met hun club, en het is dus enigszins skewed. Is hier voor dit specifieke geval een goed remedie voor? Zou ik ook bijvoorbeeld gezien de grote sample de cases zodanig selecteren dat de afhankelijke variabele normaal verdeeld is?
- Als ik de drie groepen met elkaar vergelijk dan pak ik nu bijvoorbeeld voor lokale politiek Willem II, Vitesse, AZ, Twente en Heerenveen samen zodat ik er voldoende voor regression analyse heb én ik voor deze clubs ook voldoende sponsoren en fans heb. Maar de verhoudingen zijn wel totaal anders per stakeholder groep voor deze clubs. Waar het voor lokale politiek ongeveer 20,20,20,20,20 is, is het voor sponsoren iets van 35, 25, 15, 15, 10 en voor fans soortgelijke verdeling als sponsoren maar dan andere volgorde. Moeten deze verhoudingen gelijk zijn?
Moeten misschien zelfs de absolute aantallen gelijk zijn? Ik vergelijk uiteindelijk de standardized B van de onafhankelijke variabelen in de groepen. Daarnaast heb ik al wel variabele gemaakt die grootte van de club weergeeft waarvoor dus gecontroleerd kan worden.
Bleh, warrig verhaal aan het worden. In kort: ik zit met multiple regression met pooled data en met drie samples die vergeleken moeten worden; best practice?
Ik onderzoek hoe een zestal antecedenten in relatie staat tot een afhankelijke variabele. De afhankelijke variabele is Organizational Identification - hoe mensen zich identificeren met een organisatie. Komt uiteindelijk dus een regressie analyse aan te pas, en een standaard regressie analyse heb ik ook al wel gehad in de studie.
Maar zitten wat haken en ogen aan bij mij:
- Ik richt mij op alle betaald voetbalclubs *Eredivisie en Jupiler)
- Ik maak een vergelijking tussen 3 stakeholder groepen (supporters, sponsoren en lokale politiek)
Van supporters heb ik van 33 clubs respondenten. Maar van PSV heb ik er bijvoorbeeld 380, van Ajax 140, van Vitesse 120 en van NEC 110... maar van kleine clubs als een Helmond Sport maar 1 bijvoorbeeld. In totaal heb ik er 1132
Van sponsoren heb ik er een stuk of 40 van Heerenveen, 30 van Willem II, 15 van FC Twente en voor aantal andere clubs rond de 10 elk. In totaal 323 sponsoren als respondent. Maar ik heb er 0 voor PSV en Ajax, die bij supporters het gros van de respondenten vormen.
Lokale politiek in de vorm van gemeenteraadsleden heb ik 10 a 15 respondenten voor elke gemeente, in totaal 417 respondenten.
Origineel was het idee om voor 1 club het onderzoek te doen. Maar omdat je van sponsoren en gemeenteraadsleden maar een tiental respondenten zou krijgen besloten om meer clubs bijeen te pakken en 'een betaald voetbalclub' het onderwerp te maken ipv bijvoorbeeld 'Vitesse' of 'Ajax'. Want voor multiple regression liefst 20 respondenten per onafhankelijke variabele, in mijn geval dus 120.
Nu zit ik dus met de volgende dingen:
- Mbt poolen van de data: kan je het zomaar allemaal bij elkaar gooien of zijn daar methodes voor en moet je gewichten er aan hangen oid? Kan via google niet echt vinden.
- Ik vergelijk dus 3 stakeholder groepen; als ik items ga verwijderen op basis van Reliability test (Cronbach alpha) en Discriminant validity (Factor analyse, dubbelladers en structuur) moet ik dan hetzelfde verwijderen bij elke groep? Dus als item X een dubbellader is bij de Supporters, maar niet bij de Sponsoren, dan wel bij beiden weghalen zodat beide modellen gelijk zijn aan elkaar als je gaat vergelijken, of wel op maat maken per groep?
- Supporters identificeren zich sws al vrij snel met hun club, en het is dus enigszins skewed. Is hier voor dit specifieke geval een goed remedie voor? Zou ik ook bijvoorbeeld gezien de grote sample de cases zodanig selecteren dat de afhankelijke variabele normaal verdeeld is?
- Als ik de drie groepen met elkaar vergelijk dan pak ik nu bijvoorbeeld voor lokale politiek Willem II, Vitesse, AZ, Twente en Heerenveen samen zodat ik er voldoende voor regression analyse heb én ik voor deze clubs ook voldoende sponsoren en fans heb. Maar de verhoudingen zijn wel totaal anders per stakeholder groep voor deze clubs. Waar het voor lokale politiek ongeveer 20,20,20,20,20 is, is het voor sponsoren iets van 35, 25, 15, 15, 10 en voor fans soortgelijke verdeling als sponsoren maar dan andere volgorde. Moeten deze verhoudingen gelijk zijn?
Moeten misschien zelfs de absolute aantallen gelijk zijn? Ik vergelijk uiteindelijk de standardized B van de onafhankelijke variabelen in de groepen. Daarnaast heb ik al wel variabele gemaakt die grootte van de club weergeeft waarvoor dus gecontroleerd kan worden.
Bleh, warrig verhaal aan het worden. In kort: ik zit met multiple regression met pooled data en met drie samples die vergeleken moeten worden; best practice?
Dat ziet er best nice uit! Hoe kom je daar terecht? Lijkt mij als econometriestudent wel een leuk bijbaantje.quote:
[..]
Overigens een aanstelling gekregen bij de methodology shop op de uni.Dus deze zomer even wat extra inlezen en misschien nog wat extra bijleren (Stata bijvoorbeeld) en hopelijk gedurende volgend jaar ook veel bijleren waar ik tijdens m'n eigen scriptie ook veel aan heb.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.

Is hier alleen voor psychologie en sociologie, via de vacaturebank in BlackBoard.quote:
[..]
Dat ziet er best nice uit! Hoe kom je daar terecht? Lijkt mij als econometriestudent wel een leuk bijbaantje.
Your opinion of me is none of my business.
Ik heb alleen kennis van R in een aantal specifieke domeinen. Heb wel thuis op mn HD een aantal goede tutorials/courses staan, weet niet of je er iets aan hebt maar deel ze graag met je.quote:
Ik heb eerder in dit topic om hulp gevraagd bij het implementeren van een bepaalde procedure en geen hulp gehad, maar ik heb van de originele auteur de code gekregen. Helaas wel in TSP, een gedateerd programma, dus nu is het zaak om deze code om te schrijven naar R of Stata. Heeft iemand kennis van TSP en R/Stata die mij hierbij kan helpen? Of iemand die mij een pb kan sturen met een link naar TSP?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Gefeliciteerd!quote:
[..]
Ik heb wel wat kennis van R, maar niet zo heel veel/diepgaande. Ik wil wel proberen je te helpen, maar ik kan niks garanderen (ik ben een beetje je long shot). PM/DM mag altijd.
Overigens een aanstelling gekregen bij de methodology shop op de uni.
Klinkt als een multilevel model.quote:
Bleh, zit even vast.
Ik onderzoek hoe een zestal antecedenten in relatie staat tot een afhankelijke variabele. De afhankelijke variabele is Organizational Identification - hoe mensen zich identificeren met een organisatie. Komt uiteindelijk dus een regressie analyse aan te pas, en een standaard regressie analyse heb ik ook al wel gehad in de studie.
Maar zitten wat haken en ogen aan bij mij:
- Ik richt mij op alle betaald voetbalclubs *Eredivisie en Jupiler)
- Ik maak een vergelijking tussen 3 stakeholder groepen (supporters, sponsoren en lokale politiek)
Van supporters heb ik van 33 clubs respondenten. Maar van PSV heb ik er bijvoorbeeld 380, van Ajax 140, van Vitesse 120 en van NEC 110... maar van kleine clubs als een Helmond Sport maar 1 bijvoorbeeld. In totaal heb ik er 1132
Van sponsoren heb ik er een stuk of 40 van Heerenveen, 30 van Willem II, 15 van FC Twente en voor aantal andere clubs rond de 10 elk. In totaal 323 sponsoren als respondent. Maar ik heb er 0 voor PSV en Ajax, die bij supporters het gros van de respondenten vormen.
Lokale politiek in de vorm van gemeenteraadsleden heb ik 10 a 15 respondenten voor elke gemeente, in totaal 417 respondenten.
Origineel was het idee om voor 1 club het onderzoek te doen. Maar omdat je van sponsoren en gemeenteraadsleden maar een tiental respondenten zou krijgen besloten om meer clubs bijeen te pakken en 'een betaald voetbalclub' het onderwerp te maken ipv bijvoorbeeld 'Vitesse' of 'Ajax'. Want voor multiple regression liefst 20 respondenten per onafhankelijke variabele, in mijn geval dus 120.
Nu zit ik dus met de volgende dingen:
- Mbt poolen van de data: kan je het zomaar allemaal bij elkaar gooien of zijn daar methodes voor en moet je gewichten er aan hangen oid? Kan via google niet echt vinden.
- Ik vergelijk dus 3 stakeholder groepen; als ik items ga verwijderen op basis van Reliability test (Cronbach alpha) en Discriminant validity (Factor analyse, dubbelladers en structuur) moet ik dan hetzelfde verwijderen bij elke groep? Dus als item X een dubbellader is bij de Supporters, maar niet bij de Sponsoren, dan wel bij beiden weghalen zodat beide modellen gelijk zijn aan elkaar als je gaat vergelijken, of wel op maat maken per groep?
- Supporters identificeren zich sws al vrij snel met hun club, en het is dus enigszins skewed. Is hier voor dit specifieke geval een goed remedie voor? Zou ik ook bijvoorbeeld gezien de grote sample de cases zodanig selecteren dat de afhankelijke variabele normaal verdeeld is?
- Als ik de drie groepen met elkaar vergelijk dan pak ik nu bijvoorbeeld voor lokale politiek Willem II, Vitesse, AZ, Twente en Heerenveen samen zodat ik er voldoende voor regression analyse heb én ik voor deze clubs ook voldoende sponsoren en fans heb. Maar de verhoudingen zijn wel totaal anders per stakeholder groep voor deze clubs. Waar het voor lokale politiek ongeveer 20,20,20,20,20 is, is het voor sponsoren iets van 35, 25, 15, 15, 10 en voor fans soortgelijke verdeling als sponsoren maar dan andere volgorde. Moeten deze verhoudingen gelijk zijn?
Moeten misschien zelfs de absolute aantallen gelijk zijn? Ik vergelijk uiteindelijk de standardized B van de onafhankelijke variabelen in de groepen. Daarnaast heb ik al wel variabele gemaakt die grootte van de club weergeeft waarvoor dus gecontroleerd kan worden.
Bleh, warrig verhaal aan het worden. In kort: ik zit met multiple regression met pooled data en met drie samples die vergeleken moeten worden; best practice?
Is essentie komt het er op neer dat je je data een soort van trapsgewijs bekijkt.
Dus al je datapunt splits je eerst op over de verschillende clubs (waarbij je het effect van club berekent), daarna kun je binnen de clubs het effect van supporter / sponsor / etc. bekijken.
Het is niet heel ingewikkeld om te doen, maar ook niet het allergemakkelijkste.
Kijk anders even met google of zo of je denkt dat dit voor je kan werken, en kom dan terug?
Tegen de skewness zou je een logtransformatie kunnen gebruiken, maar de meeste toetsen zijn vrij robust zolang je n hoger dan 30 is, als het je uitkomst al beinvloedt zal dat enorm in de marge zijn dus ik zou me daar denk ik niet te druk om maken.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Niet helemaal waar:quote:Op vrijdag 5 juni 2015 15:15 schreef Sarasi het volgende:
[..]
Is hier alleen voor psychologie en sociologie, via de vacaturebank in BlackBoard.
Maargoed, Nestor maar in de gaten houden dus.quote:Omdat de Methodologiewinkel een dienst is van de GMW faculteit krijgen GMW studenten in drukke periodes voorrang op studenten van andere faculteiten.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Dat is voor hulp, niet voor sollicitanten.quote:
[..]
Niet helemaal waar:
[..]
Maargoed, Nestor maar in de gaten houden dus.
Your opinion of me is none of my business.
Aha, op die fiets. Je zin was dubbelzinnig.quote:
[..]
Dat is voor hulp, niet voor sollicitanten.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.

quote:
[..]
Ik heb alleen kennis van R in een aantal specifieke domeinen. Heb wel thuis op mn HD een aantal goede tutorials/courses staan, weet niet of je er iets aan hebt maar deel ze graag met je.
Hebben jullie kennis van bootstrappen? Het gaat om het bootstrappen van een test statistic (Wald test in dit geval).quote:
[..]
Ik heb wel wat kennis van R, maar niet zo heel veel/diepgaande. Ik wil wel proberen je te helpen, maar ik kan niks garanderen (ik ben een beetje je long shot). PM/DM mag altijd.
Overigens een aanstelling gekregen bij de methodology shop op de uni.
En gefeliciteerd met je aanstelling, Sarasi.
Sorry voor de onduidelijkheid.quote:
[..]
Aha, op die fiets. Je zin was dubbelzinnig.
Nee, sorry.quote:Op vrijdag 5 juni 2015 17:34 schreef Banaanensuiker het volgende:
[..]
[..]
Hebben jullie kennis van bootstrappen? Het gaat om het bootstrappen van een test statistic (Wald test in dit geval).
En gefeliciteerd met je aanstelling, Sarasi.
Your opinion of me is none of my business.
Ja maar alleen in het abstracte / als concept, verder alleen gebruik gemaakt bij mediatie-analyses.quote:
[..]
[..]
Hebben jullie kennis van bootstrappen? Het gaat om het bootstrappen van een test statistic (Wald test in dit geval).
En gefeliciteerd met je aanstelling, Sarasi.
In principe komt het gewoon neer op data genereren van een bestaande dataset, analyse op uitvoeren, en dit 100.000 (of hoeveel je wilt) keer doen om een betrouwbaardere statistic te krijgen toch? Ik weet niet of jij het voor hetzelfde wilt gebruiken als hoe ik het ken, heb geen ervaring met het gebruik bij een Wald-test maar als het conceptueel een beetje vergelijkbaar is kan ik misschien nog iets nuttigs zeggen
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Nou, nu verschillende dingen gekeken en gelezen er over. Steeds maakte begin uitleg me enthousiast aangezien het leek te behandelen wat ik nodig heb, maar dan gaat het al snel voorbij wat ik ooit geleerd heb met syntax en andere statistiek tools etc.quote:
[..]
Gefeliciteerd!
[..]
Klinkt als een multilevel model.
Is essentie komt het er op neer dat je je data een soort van trapsgewijs bekijkt.
Dus al je datapunt splits je eerst op over de verschillende clubs (waarbij je het effect van club berekent), daarna kun je binnen de clubs het effect van supporter / sponsor / etc. bekijken.
Het is niet heel ingewikkeld om te doen, maar ook niet het allergemakkelijkste.
Kijk anders even met google of zo of je denkt dat dit voor je kan werken, en kom dan terug?
Tegen de skewness zou je een logtransformatie kunnen gebruiken, maar de meeste toetsen zijn vrij robust zolang je n hoger dan 30 is, als het je uitkomst al beinvloedt zal dat enorm in de marge zijn dus ik zou me daar denk ik niet te druk om maken.
Ook lijkt het vooral te concentreren op longitudinaal onderzoek waar bijvoorbeeld leeftijd als variabele gemeten is om de 2 jaar. Daar is wel voorbeeld van voor SPSS met Mixed Models maar daar heb je dan bv age1 age2 age3 als variabelen.. lijkt niet te zijn wat ik moet hebben.
/lost
Qua concept is het inderdaad wat ik wil doen. Ik quote even een eerdere post van mij zodat je direct kan zien of je er wat mee kan:quote:
[..]
Ja maar alleen in het abstracte / als concept, verder alleen gebruik gemaakt bij mediatie-analyses.
In principe komt het gewoon neer op data genereren van een bestaande dataset, analyse op uitvoeren, en dit 100.000 (of hoeveel je wilt) keer doen om een betrouwbaardere statistic te krijgen toch? Ik weet niet of jij het voor hetzelfde wilt gebruiken als hoe ik het ken, heb geen ervaring met het gebruik bij een Wald-test maar als het conceptueel een beetje vergelijkbaar is kan ik misschien nog iets nuttigs zeggen
quote:
Heeft iemand hier verstand van bootstrapping met doel het ontwikkelen van observatie specifieke kritieke Wald scores? Ik probeer dit in combinatie met een SUR.
Deze procedure probeer ik na te bootsen:
[ afbeelding ]
[ afbeelding ]
Met dit systeem:
[ afbeelding ]
De voorbeelden die vaak gebruikt worden is idd longitudinaal onderzoek, daar zijn de jaren meetpunten, en is de "groep" het individu. Dus per individu heb je x-aantal meetpunten. Bij jou zou het individu de club zijn, en heb je per club een aantal meetpunten (binding van sponsoren en binding van supporters).quote:
[..]
Nou, nu verschillende dingen gekeken en gelezen er over. Steeds maakte begin uitleg me enthousiast aangezien het leek te behandelen wat ik nodig heb, maar dan gaat het al snel voorbij wat ik ooit geleerd heb met syntax en andere statistiek tools etc.
Ook lijkt het vooral te concentreren op longitudinaal onderzoek waar bijvoorbeeld leeftijd als variabele gemeten is om de 2 jaar. Daar is wel voorbeeld van voor SPSS met Mixed Models maar daar heb je dan bv age1 age2 age3 als variabelen.. lijkt niet te zijn wat ik moet hebben.
/lost
Het is niet extreem moeilijk, maar misschien wel te moeilijk om duidelijk hier zo op een forum uit te leggen.
Voor welke uni / opleiding / sciptie(?) is het? Misschien kun je er mee wegkomen een gemakkelijker maar minder correct model te gebruiken, of als heel belangrijk zouden ze mensen moeten hebben die je er mee kunnen helpen (lijkt me). Het is, weet ik vrij zeker, de beste oplossing, maar als dit ver buiten wat je geleerd hebt gaat zou het vreemd zijn als ze van je verwachten dit gewoon even te doen.
Ik kom van psy en ben heel erg slecht in het lezen van wiskundige noteringen (quote:
[..]
Qua concept is het inderdaad wat ik wil doen. Ik quote even een eerdere post van mij zodat je direct kan zien of je er wat mee kan:
[..]
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Business Administration aan Radboud, master thesis. Meer dan de meest basic multiple regression hebben we niet gehad. Bespreek de analyse komende week pas voor het eerst met begeleider (in totaal maar 5 contacturen gehad hooguit) maar over 2 weken is deadline scriptie al.quote:
[..]
De voorbeelden die vaak gebruikt worden is idd longitudinaal onderzoek, daar zijn de jaren meetpunten, en is de "groep" het individu. Dus per individu heb je x-aantal meetpunten. Bij jou zou het individu de club zijn, en heb je per club een aantal meetpunten (binding van sponsoren en binding van supporters).
Het is niet extreem moeilijk, maar misschien wel te moeilijk om duidelijk hier zo op een forum uit te leggen.
Voor welke uni / opleiding / sciptie(?) is het? Misschien kun je er mee wegkomen een gemakkelijker maar minder correct model te gebruiken, of als heel belangrijk zouden ze mensen moeten hebben die je er mee kunnen helpen (lijkt me). Het is, weet ik vrij zeker, de beste oplossing, maar als dit ver buiten wat je geleerd hebt gaat zou het vreemd zijn als ze van je verwachten dit gewoon even te doen.
Wat je nu schetst neemt dus al de stakeholder groepen mee. Vergelijking tussen stakeholder groepen is echter aparte hypothese. Ik test ook relaties onafhankelijke variabelen met afhankelijk per stakeholder groep apart.
Even een versimpelde mockup van de data:

(In werkelijkheid 6 onafhankelijke en 1 afhankelijke en dus voor veel clubs)
Met multiple regression dus hypotheses testen
1a: Independent1 has a positive effect on Dependent for Fans
1b: Independent1 has a positive effect on Dependent for Sponsors
1c: Independent1 has a positive effect on Dependent for Local Government (Gemeente)
2a: Independent2 has a positive effect on Dependent for Fans
2b: Independent2 has a positive effect on Dependent for Sponsors
2c: Independent2 has a positive effect on Dependent for Local Government (Gemeente)
En dan aparte hypothese:
The effects of the different antecedents of Dependent differ among stakeholder groups
Waarbij in soortgelijk onderzoek de standardized effect sizes (B) vergeleken werden.
Maar als je mijn geval bekijkt.. in voorbeelden gebruiken ze Age1, Age2, Age3 bijvoorbeeld. Dat is 1 item over 3 metingen. Als ik 1 item had gehad, laten we ook even leeftijd nemen. Dan zou ik dus 3 variabelen moeten hebben; Age_Sponsor, Age_Fan, Age_Gemeente en dan in SPSS met Data > Restructure die variabelen moeten transposen.
Maar in mijn mockup voorbeeld zou ik dan IND1_Item1_Sponsor, IND1_item1_Fan, IND1_Item2_Gemeente etc moeten maken? Of voor de recoded scale? (IND1 met MEAN(item1,item2) en IND2) en dan IND1_Fan, IND1_Sponsor, IND1_Gemeente IND2_Fan etc?
Krijg er nog niet echt vat op omdat ik overal maar de helft van de uitleg lees en de rest in syntax is wat ik nooit gehad heb.
Weet niet hoeveel ze van me verwachten, die vorig jaar zijn afgestudeerd hiermee hadden het wel met simpele multiple regression gedaan maar die hadden geen pooled data. Veel meer dan dat ik het wel op mijn manier kon doen (meerdere clubs om sample te vergroten) dmv poolen heb ik niet meegekregen tot dusver. Maar heb het idee dat ik niet echt statistisch verantwoord bezig ben met gewooon de multiple regression draaien met respondenten van alle clubs op 1 hoop.
Thanks voor antwoorden btw!
Dag mensen,
Ik ben bezig met mijn scriptie en heb twee vragen. Mijn eerste vraag: ik ga de aandelenprijs proberen te voorspellen aan de hand van onder andere CEO tenure (de variabele waarin ik geinteresseerd ben, wijkt deze significant af van 0?). Ik wil dit doen voor alle S&P500 companies, en later voor alleen technologie bedrijven binnen de S&P500. Als ik deze technologie bedrijven allemaal in een regressie wil stoppen, hoe doe ik dat op een efficiente manier? Ik neem aan dat 1 voor 1 niet de juiste methode is.
Ik hoor het graag van jullie. Vriendelijke groet
Ik ben bezig met mijn scriptie en heb twee vragen. Mijn eerste vraag: ik ga de aandelenprijs proberen te voorspellen aan de hand van onder andere CEO tenure (de variabele waarin ik geinteresseerd ben, wijkt deze significant af van 0?). Ik wil dit doen voor alle S&P500 companies, en later voor alleen technologie bedrijven binnen de S&P500. Als ik deze technologie bedrijven allemaal in een regressie wil stoppen, hoe doe ik dat op een efficiente manier? Ik neem aan dat 1 voor 1 niet de juiste methode is.
Ik hoor het graag van jullie. Vriendelijke groet
Ik ga het op een andere manier doen; samen met mijn supervisor besloten dat er in mijn geval efficiëntere tijdsbesteding is. In ieder geval bedankt voor je bereidheid tot helpen.quote:
[..]
Ik kom van psy en ben heel erg slecht in het lezen van wiskundige noteringen (ik weet het...) dus daar moet ik even voor gaan zitten. Kom je wel tot een bepaald punt of gaat het in het begin al mis?
Hoef je niet te testen of de effecten van de fans / sponsors / local government sig van elkaar verschillen? Dat maakt alles al een heel stuk gemakkelijker.quote:
[..]
Business Administration aan Radboud, master thesis. Meer dan de meest basic multiple regression hebben we niet gehad. Bespreek de analyse komende week pas voor het eerst met begeleider (in totaal maar 5 contacturen gehad hooguit) maar over 2 weken is deadline scriptie al.
Wat je nu schetst neemt dus al de stakeholder groepen mee. Vergelijking tussen stakeholder groepen is echter aparte hypothese. Ik test ook relaties onafhankelijke variabelen met afhankelijk per stakeholder groep apart.
Even een versimpelde mockup van de data:
[ afbeelding ]
(In werkelijkheid 6 onafhankelijke en 1 afhankelijke en dus voor veel clubs)
Met multiple regression dus hypotheses testen
1a: Independent1 has a positive effect on Dependent for Fans
1b: Independent1 has a positive effect on Dependent for Sponsors
1c: Independent1 has a positive effect on Dependent for Local Government (Gemeente)
2a: Independent2 has a positive effect on Dependent for Fans
2b: Independent2 has a positive effect on Dependent for Sponsors
2c: Independent2 has a positive effect on Dependent for Local Government (Gemeente)
En dan aparte hypothese:
The effects of the different antecedents of Dependent differ among stakeholder groups
Waarbij in soortgelijk onderzoek de standardized effect sizes (B) vergeleken werden.
Maar als je mijn geval bekijkt.. in voorbeelden gebruiken ze Age1, Age2, Age3 bijvoorbeeld. Dat is 1 item over 3 metingen. Als ik 1 item had gehad, laten we ook even leeftijd nemen. Dan zou ik dus 3 variabelen moeten hebben; Age_Sponsor, Age_Fan, Age_Gemeente en dan in SPSS met Data > Restructure die variabelen moeten transposen.
Maar in mijn mockup voorbeeld zou ik dan IND1_Item1_Sponsor, IND1_item1_Fan, IND1_Item2_Gemeente etc moeten maken? Of voor de recoded scale? (IND1 met MEAN(item1,item2) en IND2) en dan IND1_Fan, IND1_Sponsor, IND1_Gemeente IND2_Fan etc?
Krijg er nog niet echt vat op omdat ik overal maar de helft van de uitleg lees en de rest in syntax is wat ik nooit gehad heb.
Weet niet hoeveel ze van me verwachten, die vorig jaar zijn afgestudeerd hiermee hadden het wel met simpele multiple regression gedaan maar die hadden geen pooled data. Veel meer dan dat ik het wel op mijn manier kon doen (meerdere clubs om sample te vergroten) dmv poolen heb ik niet meegekregen tot dusver. Maar heb het idee dat ik niet echt statistisch verantwoord bezig ben met gewooon de multiple regression draaien met respondenten van alle clubs op 1 hoop.
Thanks voor antwoorden btw!
Een gewone multiple regressie met alles op een hoop is niet per se heel erg fout, maar geeft je minder asccurate schattingen etc. gewoon omdat je het effect van club niet meeneemt, dat filter je er in een multilevel uit.
Ik ben even aan aan het kloten met een voorbeeld dataset, maar moet zo weg. Als het niet op tijd lukt zou ik denk ik een gewone muiltiple regressie doen, dit meenemen naar de meeting (zeker aangezien je maar zo weinig meet, wat slecht eigenlijk :/ ) en dan in de meeting aangeven dat je extre hebt gekeken wat de beste analyse is, dit multilevel lijkt te zijn maar dit ver boven wat je hebt geleerd uitgaat, en niet iets is dat je jezelf gemakkelijk aanleert en dan vragen of je daar support bij kan krijgen.
Dan geef je aan dat je het 1. heel serieus hebt genomen, 2. je ook nog een backup analyse hebt gedaan zoals je hem hebt geleerd, and hopelijk krijg je hulp bij 3. of krijg je te horen dat het niet nodig is, totale win-win situatie lijkt me
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Dat moet wel, maar de eerste hypotheses meten de relaties per stakeholder groep apart. Kijken of effecten sig verschillen doe ik dus ook maar voor een latere hypothese (maar wat wel de hoofdvraag is zo'n beetje van het onderzoek - of ze sig verschillen)quote:
[..]
Hoef je niet te testen of de effecten van de fans / sponsors / local government sig van elkaar verschillen? Dat maakt alles al een heel stuk gemakkelijker.
Thanks!!quote:Een gewone multiple regressie met alles op een hoop is niet per se heel erg fout, maar geeft je minder asccurate schattingen etc. gewoon omdat je het effect van club niet meeneemt, dat filter je er in een multilevel uit.
Ik ben even aan aan het kloten met een voorbeeld dataset, maar moet zo weg. Als het niet op tijd lukt zou ik denk ik een gewone muiltiple regressie doen, dit meenemen naar de meeting (zeker aangezien je maar zo weinig meet, wat slecht eigenlijk :/ ) en dan in de meeting aangeven dat je extre hebt gekeken wat de beste analyse is, dit multilevel lijkt te zijn maar dit ver boven wat je hebt geleerd uitgaat, en niet iets is dat je jezelf gemakkelijk aanleert en dan vragen of je daar support bij kan krijgen.
Dan geef je aan dat je het 1. heel serieus hebt genomen, 2. je ook nog een backup analyse hebt gedaan zoals je hem hebt geleerd, and hopelijk krijg je hulp bij 3. of krijg je te horen dat het niet nodig is, totale win-win situatie lijkt me
Ik zorg inderdaad dat ik een uitwerking heb van de methode zoals we die geleerd hebben en zal het zeker behandelen in gesprek. Alleen aardige tijdnood dus helaas. Heel hoofdstuk 4, 5 en 6 in 13 dagen plus nog een herkansing
Even een simplere vraag tussendoor: Als je meerdere groepen in een sample hebt zoals eerder beschreven, doe je dan factor analyse voor discriminant validity controleren voor de hele sample of per groep?
Had per groep gedaan, maar lees nu een paper met soortgelijke situatie (die helaas niet uitweiden over hoe ze de regressieanalyse gedaan hebben) waarin ze voor totale sample hebben gedaan.
Had per groep gedaan, maar lees nu een paper met soortgelijke situatie (die helaas niet uitweiden over hoe ze de regressieanalyse gedaan hebben) waarin ze voor totale sample hebben gedaan.
Bleh, shoot me.
Nog wat aan het zoeken en puzzelen geweest.
Is dit enigszins juist?:
Volgende syntax gedraaid:
Om te beoordelen of Multi Model wel nodig is aan de hand van intraclass correlation (ICC) op basis van de Clubs
Heb dit gedaan per stakeholder groep en volgende output:
Local Government:
0.071456 / (0.071456 + 0.855686) = 0.077 = 7.7%
Sponsors:
0.027478 / (0.027478 + 0.955224) = 0.027 = 2.7%
Fans:
0.031911 / (0.031911+0.795851) = 0.038 = 3.8%
Deze lijken me niet genoeg impact te hebben om over te gaan op Multi Model als ik per stakeholder groep de relaties wil testen met regressieanalyse?
Ook gekeken naar de -2 Log Likelihood van het model met de random component Club en zonder. Het is bij Local Government bijvoorbeeld 1138.8 ten opzichte van 1150.
Nu zag ik het volgende in een voorbeeld:
Chi2 is toch in mijn geval:
Ofwel niet significant?
Welke is het in dit geval? Bij laatste bevestigd het dat one-level volstaat, maar als de waarde 11.2 is dan is het <0.01 en wijst dat op two-level
Voor hele sample is ICC voor clubs trouwens 15% maar dat lijkt me meer verklaard worden door de stakeholder groepen. Als ik bovenstaande ICC test met de stakeholder groep als random component dan is de ICC 28% dus dat is wel aanzienlijk met een p<0.001 bij Likelihood vergelijking welk getal ik ook pak.
Maar voor clubs dus twijfel
Nog wat aan het zoeken en puzzelen geweest.
Is dit enigszins juist?:
Volgende syntax gedraaid:
| 1 2 3 4 5 | mixed OrganizationalIdentification with DomainInvolvement RegionalAffiliation PerceivedCSR OrgPrestige OrgDistinctiveness ContactFrequency /fixed = /method = ml /random = intercept | subject(ClubID) /print = solution. |
Om te beoordelen of Multi Model wel nodig is aan de hand van intraclass correlation (ICC) op basis van de Clubs
Heb dit gedaan per stakeholder groep en volgende output:
Local Government:

0.071456 / (0.071456 + 0.855686) = 0.077 = 7.7%
Sponsors:

0.027478 / (0.027478 + 0.955224) = 0.027 = 2.7%
Fans:

0.031911 / (0.031911+0.795851) = 0.038 = 3.8%
Deze lijken me niet genoeg impact te hebben om over te gaan op Multi Model als ik per stakeholder groep de relaties wil testen met regressieanalyse?
Ook gekeken naar de -2 Log Likelihood van het model met de random component Club en zonder. Het is bij Local Government bijvoorbeeld 1138.8 ten opzichte van 1150.
Nu zag ik het volgende in een voorbeeld:
Maar daar slaan ze stukje over toch? Chi2 is toch niet puur het verschil tussen de 2 getallen en dan bij df=1 kijken of het hoger is dan 3.84?quote:Chi square=203 026.467 - 196 165.706 = 6860.76, with 1 df, p=0.000. The outcome is highly significant and indicates that a two-level model is necessary.
Chi2 is toch in mijn geval:
| 1 2 3 | (1150-1138.8)[sup]2[/sup] ---------------------------------- = 0.109 1150 |
Ofwel niet significant?
Welke is het in dit geval? Bij laatste bevestigd het dat one-level volstaat, maar als de waarde 11.2 is dan is het <0.01 en wijst dat op two-level
Voor hele sample is ICC voor clubs trouwens 15% maar dat lijkt me meer verklaard worden door de stakeholder groepen. Als ik bovenstaande ICC test met de stakeholder groep als random component dan is de ICC 28% dus dat is wel aanzienlijk met een p<0.001 bij Likelihood vergelijking welk getal ik ook pak.
Maar voor clubs dus twijfel
Ik heb een vraagje. In mijn thesis doe ik onderzoek naar 'gerrymandering' in the USA (het herverdelen van kiesdistricten om een meerderheid te verkrijgen). ik heb zelf de data over gerrymandering verzameld tussen 1961 en nu en heb van mijn begeleider de data gekregen met wie er in welk district de verkiezingen heeft gewonnen en met hoeveel procent vd stemmen. Mijn eigen data werkt helemaal met cijfers (geen gerrymandering is een nul, wel een 1). Maar die van mijn begeleider werkt uiteraard met namen. Nu bestaat zijn data uit meet dan 20.000 records, dus handmatig overzetten in werkbare cijfers gaat een tijd duren. Is er nog een andere manier waarop ik met beide datasets een regressie kan uitvoeren (in eviews of SPSS, want daar heb ik ervaring mee. we hebben op de uni evt ook Stata) zonder dat ik alles handmatig in cijfers hoef te veranderen.
Het gaat dus vooral om het transformeren van de begeleider zijn data in iets wat SPSS of eviews begrijpt. Als ik dat eenmaal heb lukt het uitvoeren van een regressie wel. Ik kan dit ook aan mijn begeleider vragen, maar die is er tot maandag niet meer en maandag heb ik een afspraak met hem waarbij ik eigenlijk hoop al wat resultaten te kunnen overleggen.
Het gaat dus vooral om het transformeren van de begeleider zijn data in iets wat SPSS of eviews begrijpt. Als ik dat eenmaal heb lukt het uitvoeren van een regressie wel. Ik kan dit ook aan mijn begeleider vragen, maar die is er tot maandag niet meer en maandag heb ik een afspraak met hem waarbij ik eigenlijk hoop al wat resultaten te kunnen overleggen.
life is what happens to you, while you're busy making other plans.
Zijn dat 20 000 verschillende namen of maar een paar? Je kunt wel een scriptje schrijven waarin je alle namen een nummer geeft, waarna je met dat nummer gaat rekenen en er na afloop weer die naam aan koppelt. In R is dat niet bijzonder moeilijk weet ik, Stata zou ook wel te doen zijn. SPSS en eviews heb ik niet genoeg kennis van.quote:
Ik heb een vraagje. In mijn thesis doe ik onderzoek naar 'gerrymandering' in the USA (het herverdelen van kiesdistricten om een meerderheid te verkrijgen). ik heb zelf de data over gerrymandering verzameld tussen 1961 en nu en heb van mijn begeleider de data gekregen met wie er in welk district de verkiezingen heeft gewonnen en met hoeveel procent vd stemmen. Mijn eigen data werkt helemaal met cijfers (geen gerrymandering is een nul, wel een 1). Maar die van mijn begeleider werkt uiteraard met namen. Nu bestaat zijn data uit meet dan 20.000 records, dus handmatig overzetten in werkbare cijfers gaat een tijd duren. Is er nog een andere manier waarop ik met beide datasets een regressie kan uitvoeren (in eviews of SPSS, want daar heb ik ervaring mee. we hebben op de uni evt ook Stata) zonder dat ik alles handmatig in cijfers hoef te veranderen.
Het gaat dus vooral om het transformeren van de begeleider zijn data in iets wat SPSS of eviews begrijpt. Als ik dat eenmaal heb lukt het uitvoeren van een regressie wel. Ik kan dit ook aan mijn begeleider vragen, maar die is er tot maandag niet meer en maandag heb ik een afspraak met hem waarbij ik eigenlijk hoop al wat resultaten te kunnen overleggen.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Het zit er qua aantal tussenin. Het gaat om de verkiezingen sinds 1960 tot van alle districten. Een naam komt uiteraard vaker voor, wanneer iemand vaker heeft meegedaan aan verkiezingen, maar het zijn zeker duizenden namen.quote:
[..]
Zijn dat 20 000 verschillende namen of maar een paar? Je kunt wel een scriptje schrijven waarin je alle namen een nummer geeft, waarna je met dat nummer gaat rekenen en er na afloop weer die naam aan koppelt. In R is dat niet bijzonder moeilijk weet ik, Stata zou ook wel te doen zijn. SPSS en eviews heb ik niet genoeg kennis van.
life is what happens to you, while you're busy making other plans.
Ah ja, dat dacht ik al.quote:
[..]
Het zit er qua aantal tussenin. Het gaat om de verkiezingen sinds 1960 tot van alle districten. Een naam komt uiteraard vaker voor, wanneer iemand vaker heeft meegedaan aan verkiezingen, maar het zijn zeker duizenden namen.
Voorbeeld in R pseudocode:
| 1 2 3 4 5 6 7 8 9 10 11 | data$nieuwekolom <- NA for(i in 1:20000){ for(j in 1:i){ if(naam[i] == naam[j]{ data$nieuwekolom[i] = j } else{ data$nieuwekolom[i] = i } } } |
Aan zoiets moet je denken. Die if statement moet je even mee opletten want strings vergelijken gaat niet zomaar.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ok dankje Het is fijn om te weten dat er in ieder geval methodes bestaan om er mee te puzzelen. Alles handmatig leek me een tikkeltje overdreven.
life is what happens to you, while you're busy making other plans.
Dag mensen,
kunnen jullie mij helpen? Ik wil (denk ik) een logregressie uitvoeren. Hierbij is de log de dependent variable, oftewel de abnormal return (abnormalret). thirtysix, ninetysix, hundredfiftysix en hunfiftysixPLUS zijn dummy variabelen die gelijk staan aan 1 indien de waardes van tenure respectievelijk 0-35, 36-95, 96-155 en 156+ zijn. Ten slotte is er ook nog de marktcapitalisatie die ik als variabele in wil voeren in het model.
Mijn model moet worden: logabnormalret = b1*thirtysix + b2*ninetysix + b3*hundredfiftysix + b4*hunfiftysixPLUS + b5*marketcap.
Hoe doe ik dit? Ik probeer ten eerste de normale abnormalret in mijn edit tabel te replacen met logabnormalret, maar volgens mij kan logabnormalret niet bestaan zonder abnormalret? Ten tweede wil ik tenure niet in mijn model maar moet ik het volgens mij wel invoeren in de edit tabel omdat de dummyvariabelen anders niet werken?
Ik heb net geprobeerd regressies te doen maar ik kreeg steeds de melding dat er geen observaties waren? Bij die regressie probeerde ik logabnormal ret te regresseren op de 4 dummies en marketcap.
Kunnen jullie mij helpen? Ben een zieke STATA noob en weet niet wat wel en niet kan, en wat ik fout doe. Vriendelijke groet.
http://i.imgur.com/ckQYiow.png
kunnen jullie mij helpen? Ik wil (denk ik) een logregressie uitvoeren. Hierbij is de log de dependent variable, oftewel de abnormal return (abnormalret). thirtysix, ninetysix, hundredfiftysix en hunfiftysixPLUS zijn dummy variabelen die gelijk staan aan 1 indien de waardes van tenure respectievelijk 0-35, 36-95, 96-155 en 156+ zijn. Ten slotte is er ook nog de marktcapitalisatie die ik als variabele in wil voeren in het model.
Mijn model moet worden: logabnormalret = b1*thirtysix + b2*ninetysix + b3*hundredfiftysix + b4*hunfiftysixPLUS + b5*marketcap.
Hoe doe ik dit? Ik probeer ten eerste de normale abnormalret in mijn edit tabel te replacen met logabnormalret, maar volgens mij kan logabnormalret niet bestaan zonder abnormalret? Ten tweede wil ik tenure niet in mijn model maar moet ik het volgens mij wel invoeren in de edit tabel omdat de dummyvariabelen anders niet werken?
Ik heb net geprobeerd regressies te doen maar ik kreeg steeds de melding dat er geen observaties waren? Bij die regressie probeerde ik logabnormal ret te regresseren op de 4 dummies en marketcap.
Kunnen jullie mij helpen? Ben een zieke STATA noob en weet niet wat wel en niet kan, en wat ik fout doe. Vriendelijke groet.
http://i.imgur.com/ckQYiow.png
Het heeft met multicollinearity te maken maar zelfs als ik dingen verander ervaar ik hetzelfde!!
http://i.imgur.com/RlIKye9.png
Zou de formule: log(abnormal return) = constant + b1*tenure0-3jaar + b2*tenure13+jaar + b3*marketcap dit oplossen? Omdat er dan niet per se een dummy variabele is? Of, omdat de constant dan eigenlijk de waarde van de vorige dummy variabeles die nu zijn verdwenen meeneemt (3-8 jaar en 8-13 jaar) krijg ik nog steeds hetzelfde probleem? Zo niet, verklaart de constante dan in het nieuwe geval het effect van 3-13 jaar tenure?
[ Bericht 52% gewijzigd door haha94boem op 14-06-2015 03:13:54 ]
http://i.imgur.com/RlIKye9.png
Zou de formule: log(abnormal return) = constant + b1*tenure0-3jaar + b2*tenure13+jaar + b3*marketcap dit oplossen? Omdat er dan niet per se een dummy variabele is? Of, omdat de constant dan eigenlijk de waarde van de vorige dummy variabeles die nu zijn verdwenen meeneemt (3-8 jaar en 8-13 jaar) krijg ik nog steeds hetzelfde probleem? Zo niet, verklaart de constante dan in het nieuwe geval het effect van 3-13 jaar tenure?
[ Bericht 52% gewijzigd door haha94boem op 14-06-2015 03:13:54 ]
Het is bijna altijd slim om de constant er gewoon in te laten. Dit gebeurt automatisch in stata.
Daarnaast is het slim om eerst de dummy variabelen te creëren voordat je je model schat.
Als je abnormalret in je dataset hebt en je wilt de log is dit de syntax:
gen logabnormalret=Log(abnormalret)
Daarnaast is het slim om eerst de dummy variabelen te creëren voordat je je model schat.
Als je abnormalret in je dataset hebt en je wilt de log is dit de syntax:
gen logabnormalret=Log(abnormalret)
Ik zie je screenshot nu pas, en je probleem zit hem waarschijnlijk in het lage aantal observaties. Daardoor is er geen variantie tussen observatie en kan er niks geschat worden.
In dit geval is dus een regressie geen optie.
In dit geval is dus een regressie geen optie.
Die foutmelding 'no observations' heeft er waarschijnlijk mee te maken dat stata altijd alleen observaties meeneemt zonder missings. Misschien wil je de missings in een 0 veranderen? Tenminste, als dat dummies zijn.
Overigens kan je ook originele variabelen gebruiken en in er 'ib2.' voor zetten (als de tweede categorie je referentie is, anders ib1. of ib3 of wat dan ook).
Overigens kan je ook originele variabelen gebruiken en in er 'ib2.' voor zetten (als de tweede categorie je referentie is, anders ib1. of ib3 of wat dan ook).
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Dag mensen,
Bedankt voor jullie reacties. Ik heb inmiddels geprobeerd om gewoon alle data in te voeren en nu lukte het wel. Weet niet of het dan daadwerkelijk ligt aan een te lage hoeveelheid observaties in het eerste geval.
In ieder geval, ik heb nog een vraag. Ik denk dat ik log(abnormalreturn) wil regressen ipv abnormal return. Echter, als ik gen logabnormalreturn = log(abnormalreturn) doe, worden mijn negatieve waardes 'verwijderd' bij log: http://i.imgur.com/LT5PI8c.png
Hoe kan ik nu een logregressie doen? Ik moet ook de negatieve abnormal returns meenemen voor mijn onderzoek, maar ik weet niet wat ik nu moet doen om dit op te lossen. Heeft iemand tips?
Bedankt voor jullie reacties. Ik heb inmiddels geprobeerd om gewoon alle data in te voeren en nu lukte het wel. Weet niet of het dan daadwerkelijk ligt aan een te lage hoeveelheid observaties in het eerste geval.
In ieder geval, ik heb nog een vraag. Ik denk dat ik log(abnormalreturn) wil regressen ipv abnormal return. Echter, als ik gen logabnormalreturn = log(abnormalreturn) doe, worden mijn negatieve waardes 'verwijderd' bij log: http://i.imgur.com/LT5PI8c.png
Hoe kan ik nu een logregressie doen? Ik moet ook de negatieve abnormal returns meenemen voor mijn onderzoek, maar ik weet niet wat ik nu moet doen om dit op te lossen. Heeft iemand tips?
Probeer gen logabnormalreturn=ln(abnormalreturn)quote:
Dag mensen,
Bedankt voor jullie reacties. Ik heb inmiddels geprobeerd om gewoon alle data in te voeren en nu lukte het wel. Weet niet of het dan daadwerkelijk ligt aan een te lage hoeveelheid observaties in het eerste geval.
In ieder geval, ik heb nog een vraag. Ik denk dat ik log(abnormalreturn) wil regressen ipv abnormal return. Echter, als ik gen logabnormalreturn = log(abnormalreturn) doe, worden mijn negatieve waardes 'verwijderd' bij log: http://i.imgur.com/LT5PI8c.png
Hoe kan ik nu een logregressie doen? Ik moet ook de negatieve abnormal returns meenemen voor mijn onderzoek, maar ik weet niet wat ik nu moet doen om dit op te lossen. Heeft iemand tips?
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>

Gebeurt hetzelfde, helaas.quote:
[..]
Probeer gen logabnormalreturn=ln(abnormalreturn)
Indexeren of een ratio maken. Logaritmes van negatieve getallen is niet mogelijk namelijk.quote:
Dag mensen,
Bedankt voor jullie reacties. Ik heb inmiddels geprobeerd om gewoon alle data in te voeren en nu lukte het wel. Weet niet of het dan daadwerkelijk ligt aan een te lage hoeveelheid observaties in het eerste geval.
In ieder geval, ik heb nog een vraag. Ik denk dat ik log(abnormalreturn) wil regressen ipv abnormal return. Echter, als ik gen logabnormalreturn = log(abnormalreturn) doe, worden mijn negatieve waardes 'verwijderd' bij log: http://i.imgur.com/LT5PI8c.png
Hoe kan ik nu een logregressie doen? Ik moet ook de negatieve abnormal returns meenemen voor mijn onderzoek, maar ik weet niet wat ik nu moet doen om dit op te lossen. Heeft iemand tips?
Bedankt.quote:
[..]
Indexeren of een ratio maken. Logaritmes van negatieve getallen is niet mogelijk namelijk.
Weet je misschien het antwoord op de volgende vraag: als ik van mijn dummyvariabelen een log maak, dus b1*log(tenure0-3years) ipv b1*tenure0-3years, krijg ik dan een correcte interpretatie? Als ik ln(1) op mijn rekenmachine intype krijg ik namelijk 0, dus klopt mijn stata model dan wel?
Een doube log specificatie betekent dat de beta's geinterpreteerd kunnen worden als point elasticities. Met een dummy variable is dit niet echt logisch, gezien dit discrete waarden zijn, dus 0 of 1. Met waarden die continu zijn is dit een stuk logischer.quote:
[..]
Bedankt.
Weet je misschien het antwoord op de volgende vraag: als ik van mijn dummyvariabelen een log maak, dus b1*log(tenure0-3years) ipv b1*tenure0-3years, krijg ik dan een correcte interpretatie? Als ik ln(1) op mijn rekenmachine intype krijg ik namelijk 0, dus klopt mijn stata model dan wel?
Je moet je afvragen waarom je een log log specificatie wilt doen, en of dit thereotisch gezien ergens op slaat.
Onjuist, dat is wel mogelijk.quote:
[..]
Indexeren of een ratio maken. Logaritmes van negatieve getallen is niet mogelijk namelijk.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Natuurlijk logaritme van negatief getal is niet gedefinieerd, en daar gaat het in dit geval om. Maar anderzijds heb je gelijk ja.quote:
Dat is ook niet correct. Het natuurlijk logartime van een negatief is namelijk wel gedefinieerd, te weten als een complex getal.quote:
[..]
Natuurlijk logaritme van negatief getal is niet gedefinieerd, en daar gaat het in dit geval om. Maar anderzijds heb je gelijk ja.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ha iedereen!
Ik loop behoorlijk vast met SPSS. Het gaat om het volgende:
Mijn enquete is (voornamelijk) op Likert-schaal afgenomen. De y = gemiddelde behaalde cijfer op Likert schaal:
1 = <4,
2 = 4,1 t/m 5
3 = 5,1 t/m 6
4 = 6,1-7
etc.
Al onze x'en zijn ook op Likert schaal afgenomen (van 0=helemaal oneens naar 5=helemaal eens)
Volgens mijn docent mag ik gewoon een Likert-schaal op interval/ratio niveau gebruiken.
Ik heb de y en alle x'en op schaalniveau ingesteld en (na SomScores te hebben gemaakt van meerdere variabelen) deze ingevoerd en getest voor lineariteit en normaliteit. De bijlagen geven mijn resultaten weer. Klopt het dat ik iets totaal verkeerd heb gedaan? En zo niet, op welke toets moet ik nu overstappen?
http://nl.tinypic.com/r/b665gj/8
http://nl.tinypic.com/r/1zf78tg/8
http://nl.tinypic.com/r/260er9i/8
Ik loop behoorlijk vast met SPSS. Het gaat om het volgende:
Mijn enquete is (voornamelijk) op Likert-schaal afgenomen. De y = gemiddelde behaalde cijfer op Likert schaal:
1 = <4,
2 = 4,1 t/m 5
3 = 5,1 t/m 6
4 = 6,1-7
etc.
Al onze x'en zijn ook op Likert schaal afgenomen (van 0=helemaal oneens naar 5=helemaal eens)
Volgens mijn docent mag ik gewoon een Likert-schaal op interval/ratio niveau gebruiken.
Ik heb de y en alle x'en op schaalniveau ingesteld en (na SomScores te hebben gemaakt van meerdere variabelen) deze ingevoerd en getest voor lineariteit en normaliteit. De bijlagen geven mijn resultaten weer. Klopt het dat ik iets totaal verkeerd heb gedaan? En zo niet, op welke toets moet ik nu overstappen?
http://nl.tinypic.com/r/b665gj/8
http://nl.tinypic.com/r/1zf78tg/8
http://nl.tinypic.com/r/260er9i/8
Even een vraagje. Ik heb zo'n 200 respondenten een kennisquiz laten afnemen. Die resultaten heb ik verwerkt en ik wil ze nu verdelen in drie categoriëen. Hoog scorend, laagscorend en gemiddeld scorend.
Nu is mijn vraag: hoe verdeel ik die. Doe ik dat zo gelijk mogelijk (dus 3 ongeveer even grote groepen) of moet ik dan werken met standaarddeviaties. Want ook dat heb ik ergens gelezen in een artikel.
Ter verduidelijking, die tweede methode is als volgt:
LOW 0 tot (median-standaarddeviatie)
MED (median-standaarddeviatie) tot (median+standaarddeviatie)
HIGH (median+standaarddeviatie) tot 10
Die drie groepen wil ik dan constant met elkaar vergelijken met andere resultaten uit mijn enquete.
Ik weet dus wel hoe ik die groepen verdeel, maar wil graag weten wat beter is.
Nu is mijn vraag: hoe verdeel ik die. Doe ik dat zo gelijk mogelijk (dus 3 ongeveer even grote groepen) of moet ik dan werken met standaarddeviaties. Want ook dat heb ik ergens gelezen in een artikel.
Ter verduidelijking, die tweede methode is als volgt:
LOW 0 tot (median-standaarddeviatie)
MED (median-standaarddeviatie) tot (median+standaarddeviatie)
HIGH (median+standaarddeviatie) tot 10
Die drie groepen wil ik dan constant met elkaar vergelijken met andere resultaten uit mijn enquete.
Ik weet dus wel hoe ik die groepen verdeel, maar wil graag weten wat beter is.
Dan moet je splitsen op het 33ste percentiel en 66e percentiel.quote:
Even een vraagje. Ik heb zo'n 200 respondenten een kennisquiz laten afnemen. Die resultaten heb ik verwerkt en ik wil ze nu verdelen in drie categoriëen. Hoog scorend, laagscorend en gemiddeld scorend.
Nu is mijn vraag: hoe verdeel ik die. Doe ik dat zo gelijk mogelijk (dus 3 ongeveer even grote groepen) of moet ik dan werken met standaarddeviaties. Want ook dat heb ik ergens gelezen in een artikel.
Ter verduidelijking, die tweede methode is als volgt:
LOW 0 tot (median-standaarddeviatie)
MED (median-standaarddeviatie) tot (median+standaarddeviatie)
HIGH (median+standaarddeviatie) tot 10
Die drie groepen wil ik dan constant met elkaar vergelijken met andere resultaten uit mijn enquete.
Ik weet dus wel hoe ik die groepen verdeel, maar wil graag weten wat beter is.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
In je tweede foto (en trouwens ook je derde) zie je dat je verdeling sterk afwijkt van een normale verdeling. Daarmee schendt je een assumptie van regressie. Je kan eens proberen om alles te hercoderen naar een log schaalquote:
Ha iedereen!
Ik loop behoorlijk vast met SPSS. Het gaat om het volgende:
Mijn enquete is (voornamelijk) op Likert-schaal afgenomen. De y = gemiddelde behaalde cijfer op Likert schaal:
1 = <4,
2 = 4,1 t/m 5
3 = 5,1 t/m 6
4 = 6,1-7
etc.
Al onze x'en zijn ook op Likert schaal afgenomen (van 0=helemaal oneens naar 5=helemaal eens)
Volgens mijn docent mag ik gewoon een Likert-schaal op interval/ratio niveau gebruiken.
Ik heb de y en alle x'en op schaalniveau ingesteld en (na SomScores te hebben gemaakt van meerdere variabelen) deze ingevoerd en getest voor lineariteit en normaliteit. De bijlagen geven mijn resultaten weer. Klopt het dat ik iets totaal verkeerd heb gedaan? En zo niet, op welke toets moet ik nu overstappen?
http://nl.tinypic.com/r/b665gj/8
http://nl.tinypic.com/r/1zf78tg/8
http://nl.tinypic.com/r/260er9i/8
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Eerdere vragen van mij zijn grotendeels wel besproken met begeleider inmiddels. Nu even een simpele (denk ik) vraag die wat makkelijker beantwoord kan worden gok ik:
In m'n theoretisch framework heb ik 6 predictors/antecedenten. Ik gebruik multiple regression. Er zijn guidelines die zeggen van bv 20 cases per predictor variable nodig. In dit geval dus 120.
Maar als ik nu in SPSS bij de regressie nog bv 3 dummies erbij opneem (waarvan 1 als reference gebruikt zal worden) en 18 interacties (de 6 antecedenten elk keer de 3 dummies) waarvan 6 als reference, en ook nog 3 controle variabelen...
.. Dan geeft SPSS weer dat ik 23 predictors heb (telt reference dus niet mee)
Gaat diezelfde guideline dan op en moet ik dan idealiter 460 cases hebben? Of tellen sommige niet mee zoals bijvoorbeeld interactie termen? Of mss zelfs zo dat ik de reference van de dummies er ook nog bij moet tellen omdat ie daar berekeningen voor maakt en ik 30 x 20 = 600 cases moet hebben?
In m'n theoretisch framework heb ik 6 predictors/antecedenten. Ik gebruik multiple regression. Er zijn guidelines die zeggen van bv 20 cases per predictor variable nodig. In dit geval dus 120.
Maar als ik nu in SPSS bij de regressie nog bv 3 dummies erbij opneem (waarvan 1 als reference gebruikt zal worden) en 18 interacties (de 6 antecedenten elk keer de 3 dummies) waarvan 6 als reference, en ook nog 3 controle variabelen...
.. Dan geeft SPSS weer dat ik 23 predictors heb (telt reference dus niet mee)
Gaat diezelfde guideline dan op en moet ik dan idealiter 460 cases hebben? Of tellen sommige niet mee zoals bijvoorbeeld interactie termen? Of mss zelfs zo dat ik de reference van de dummies er ook nog bij moet tellen omdat ie daar berekeningen voor maakt en ik 30 x 20 = 600 cases moet hebben?

We nemen 3 ballen zonder teruglegging
De kans op 2 zwarte en 1 witte bal is
In totaal zijn er 14 ballen waarvan 8 zwart en 6 wit. Hoe kan ik deze bewerking uitvoeren op mijn TI-83?
De kans op 2 zwarte en 1 witte bal is
In totaal zijn er 14 ballen waarvan 8 zwart en 6 wit. Hoe kan ik deze bewerking uitvoeren op mijn TI-83?
Man is de baas, vrouw kent haar plaats.

Je zit in het verkeerde topic. Wat jij nodig hebt, is het kansrekeningtopic.quote:Op woensdag 24 juni 2015 14:57 schreef phpmystyle het volgende:
We nemen 3 ballen zonder teruglegging
De kans op 2 zwarte en 1 witte bal is
In totaal zijn er 14 ballen waarvan 8 zwart en 6 wit. Hoe kan ik deze bewerking uitvoeren op mijn TI-83?
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ik zit nog steeds met mjin onderzoek over Gerrymandering (zie paar pagina's terug). Ben inmiddels wel een stuk verder, alles met de data is gelukt. Maar nu wil ik een bepaalde regressie invoeren in stata (ik kan geen ander programma gebruiken, omdat mijn data correct getransformeerd is met stata en niet met andere programma's). De regressie is als volgt:
Probit(gerrymandering_t)=Delta(voteshare_(t-1)-voteshare_t)+e_t
Probit is een stata commando, gerrymandering is een van mijn variabelen (net als voteshare overigens). t staat uiteraard voor tijd en delta voor verandering. Het gene wat hiermee uitgerekend moet worden is de kans dat een verandering in de hoeveelheid stemmen die een winnende partij krijgt dit keer ten opzichte van de vorige keer, (deels) komt door gerrymandering.
De vraag uiteindelijk is: hoe laat je stata deze bewerking uitvoeren? probit is dus een bestaande commando maar ik weet niet hoe je in stata werkt met verandering (delta) en met het deel ' voteshare_(t-1)-voteshare_t'
Probit(gerrymandering_t)=Delta(voteshare_(t-1)-voteshare_t)+e_t
Probit is een stata commando, gerrymandering is een van mijn variabelen (net als voteshare overigens). t staat uiteraard voor tijd en delta voor verandering. Het gene wat hiermee uitgerekend moet worden is de kans dat een verandering in de hoeveelheid stemmen die een winnende partij krijgt dit keer ten opzichte van de vorige keer, (deels) komt door gerrymandering.
De vraag uiteindelijk is: hoe laat je stata deze bewerking uitvoeren? probit is dus een bestaande commando maar ik weet niet hoe je in stata werkt met verandering (delta) en met het deel ' voteshare_(t-1)-voteshare_t'
life is what happens to you, while you're busy making other plans.
Goedemiddag, weet iemand hoe ik de volgende twee vragen kan maken? Ik loop vast met het feit dat er sprake is van een correlatie in plaats van dat het onafhankelijke variabelen zijn:
Ten slotte een vraag over een opgave :
Waarom kom ik wel op het goede antwoord uit als ik de variantie bereken en vervolgens de wortel hiervan neem, maar kom ik op een fout antwoord uit als ik de standaarddeviatie direct wil berekenen?


Ten slotte een vraag over een opgave :

Waarom kom ik wel op het goede antwoord uit als ik de variantie bereken en vervolgens de wortel hiervan neem, maar kom ik op een fout antwoord uit als ik de standaarddeviatie direct wil berekenen?
mijn vraag: nvm, het is al gelukt inmiddels
life is what happens to you, while you're busy making other plans.
Hoi allen,
Ik ben momenteel hard bezig met mijn masterscriptie. Loop nu alleen tegen een probleempje op. Ik heb een groep respondenten een vragenlijst voorgelegd met daarin (onder andere) drie schalen voor drie soorten leiderschapsstijl.
In dit geval authentiek leiderschap, transformationeel leiderschap en transactioneel leiderschap. Dit heb ik ordinaal gemeten. Een van mijn hypotheses is dat authentiek leiderschap een autonoom concept is en dus gezien kan worden als ''echte leiderschapsstijl''.
Nu wil ik dus gaan controleren of personen die hoog scoren op Authentiek leiderschap laag scoren op de twee andere vormen van leiderschap en vice versa.
Nu weet ik alleen niet precies hoe ik dit kan toetsen.. Heb een hele lijst met data maar weet niet hoe ik de mensen aan de hand van hun score kan categoriseren bij een van de drie stijlen. M'n begeleider gaf aan dat hij het zelf ook niet zo goed wist en dat hij dacht dat ik iets van een betrouwbaarheidsinterval voor ieder van de drie stijlen moest uitvoeren en vervolgens moest kijken of deze overlap hebben... Maar volgens mij moet dit ook anders kunnen toch?
Heeft een van jullie een idee?
Ik ben momenteel hard bezig met mijn masterscriptie. Loop nu alleen tegen een probleempje op. Ik heb een groep respondenten een vragenlijst voorgelegd met daarin (onder andere) drie schalen voor drie soorten leiderschapsstijl.
In dit geval authentiek leiderschap, transformationeel leiderschap en transactioneel leiderschap. Dit heb ik ordinaal gemeten. Een van mijn hypotheses is dat authentiek leiderschap een autonoom concept is en dus gezien kan worden als ''echte leiderschapsstijl''.
Nu wil ik dus gaan controleren of personen die hoog scoren op Authentiek leiderschap laag scoren op de twee andere vormen van leiderschap en vice versa.
Nu weet ik alleen niet precies hoe ik dit kan toetsen.. Heb een hele lijst met data maar weet niet hoe ik de mensen aan de hand van hun score kan categoriseren bij een van de drie stijlen. M'n begeleider gaf aan dat hij het zelf ook niet zo goed wist en dat hij dacht dat ik iets van een betrouwbaarheidsinterval voor ieder van de drie stijlen moest uitvoeren en vervolgens moest kijken of deze overlap hebben... Maar volgens mij moet dit ook anders kunnen toch?
Heeft een van jullie een idee?
Fantasie is belangrijker dan kennis, want kennis is begrensd.
Heb je al de Likertschalen samengevoegd tot één ratiovariabele (mits de cronbachs alpha goed zit natuurlijk)? Dan kan je wel mikken of ze significant van elkaar verschillen.
Wat je zou kunnen doen, maar dat is maar een hersenscheetje, is vaststellen wat 'hoog' is. Bijvoorbeeld, boven de 3,5 gemiddeld. Dan maak je drie nieuwe dichotome variabelen (stijl 1 hoog of laag, etc). Vergelijk dan de gemiddelden van stijl 2 tussen de twee groepen 'stijl 1 hoog' en 'stijl 1 laag'. Als daar significant verschil in zit, heb je een conclusie.
Maar nogmaals, is maar een hersenscheetje.
Wat je zou kunnen doen, maar dat is maar een hersenscheetje, is vaststellen wat 'hoog' is. Bijvoorbeeld, boven de 3,5 gemiddeld. Dan maak je drie nieuwe dichotome variabelen (stijl 1 hoog of laag, etc). Vergelijk dan de gemiddelden van stijl 2 tussen de twee groepen 'stijl 1 hoog' en 'stijl 1 laag'. Als daar significant verschil in zit, heb je een conclusie.
Maar nogmaals, is maar een hersenscheetje.
Er zat WEL genoeg koriander in.
Hoe bedoel je dat precies? In de spoiler is mijn factoranalyse te zien.. hierin moeten de eerste 16 items de eerste leiderschapsstijl meten, de volgende 19 items de 2e leiderschapsstijl en de laatste 10 items de 3e leiderschapsstijlquote:
Heb je al de Likertschalen samengevoegd tot één ratiovariabele (mits de cronbachs alpha goed zit natuurlijk)? Dan kan je wel mikken of ze significant van elkaar verschillen.
Wat je zou kunnen doen, maar dat is maar een hersenscheetje, is vaststellen wat 'hoog' is. Bijvoorbeeld, boven de 3,5 gemiddeld. Dan maak je drie nieuwe dichotome variabelen (stijl 1 hoog of laag, etc). Vergelijk dan de gemiddelden van stijl 2 tussen de twee groepen 'stijl 1 hoog' en 'stijl 1 laag'. Als daar significant verschil in zit, heb je een conclusie.
Maar nogmaals, is maar een hersenscheetje.
SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.De cronbach's alphas zijn allemaal boven de 0.6 dus acceptabel. Alleen hoe moet ik nu precies verder? Het lastige is dus dat een stijl uit meerdere dimensies (=factoren?) bestaat.Fantasie is belangrijker dan kennis, want kennis is begrensd.
Kan je niet gewoon het gemiddelde nemen van elke stijl? Dus dat je van de eerste zestien items een gemiddelde neemt, waarmee je verder gaat rekenen?
En trouwens, vaak ligt de Cronbach's Alpha-grens op de 0,7 en niet de 0,6, maar dat verschilt nog per studie denk ik.
En trouwens, vaak ligt de Cronbach's Alpha-grens op de 0,7 en niet de 0,6, maar dat verschilt nog per studie denk ik.
Er zat WEL genoeg koriander in.
Hmm ja dat zou nog wel eens kunnen.. Dan moet ik per respondent zijn gemiddelde score nemen van de eerste 16 items, de volgende items behorende bij de andere leiderschapsstijl en van de laatste itemsquote:
Kan je niet gewoon het gemiddelde nemen van elke stijl? Dus dat je van de eerste zestien items een gemiddelde neemt, waarmee je verder gaat rekenen?
En trouwens, vaak ligt de Cronbach's Alpha-grens op de 0,7 en niet de 0,6, maar dat verschilt nog per studie denk ik.
Fantasie is belangrijker dan kennis, want kennis is begrensd.
Dat is volgens mij wel het idee van een Likertschaal, dat je het gemiddelde daarvan als ratiovariabele kan beschouwen. Is het een soort Likertschaal?quote:
[..]
Hmm ja dat zou nog wel eens kunnen.. Dan moet ik per respondent zijn gemiddelde score nemen van de eerste 16 items, de volgende items behorende bij de andere leiderschapsstijl en van de laatste items
Er zat WEL genoeg koriander in.
Yes! 7 punts likertschalen inderdaad. Heb via compute nu voor iedere leiderschapsstijl een nieuwe variabele gemaakt met het gemiddelde van alle bijbehorende itemscores. Dus nu drie nieuwe variabelen. Eens kijken wat ik nu moet gaan doen om dit te vergelijkenquote:
[..]
Dat is volgens mij wel het idee van een Likertschaal, dat je het gemiddelde daarvan als ratiovariabele kan beschouwen. Is het een soort Likertschaal?
Fantasie is belangrijker dan kennis, want kennis is begrensd.
Er wordt geen hypothese getest en wordt slechts om een betrouwbaarheidsinterval gevraagdquote:
Goedemiddag! Ik zit met een kleine vraag waar ik momenteel geen antwoord op weet, vandaar dat ik het hier kom vragen:
Bij het antwoord op het volgende vraagstuk wordt een z-score gebruikt van 1.960 (bijbehorend bij een betrouwbaarheidsinterval van 95% en een one-sided P van 0,025). Waarom wordt daarentegen geen z-score van 1.645 gebruikt (bijbehorend bij een one-sided P van 0,05 en een betrouwbaarheidsinterval van 90%). Het is immers een eenzijdige hypothese test?:
[ afbeelding ]
[ afbeelding ]
Bij deze vraag, ook een eenzijdige hypothese test, wordt wel een z-score van 1.645 genomen (one-sided p van 0,05 en een betrouwbaarheidsinterval van 90%).
Zo ver ik weet kijk je naar de rij van betrouwbaarheidsintervallen bij tweezijdige hypothese testen, waartegen je kijkt naar de rij van one-sided p bij eenzijdige hypothese testen (?).
Heeft iemand enig idee?
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ik heb een vraag mbt de standaarddeviatie:
Hoe moet vraag 14 berekend worden?
Het antwoord is het volgende:
Ik begrijp er alleen niks van.

Hoe moet vraag 14 berekend worden?
Het antwoord is het volgende:

Ik begrijp er alleen niks van.
Weet iemand hoe ik vraag 19 kan berekenen?
[ Bericht 82% gewijzigd door GeschiktX op 13-07-2015 18:14:24 ]

[ Bericht 82% gewijzigd door GeschiktX op 13-07-2015 18:14:24 ]
Hoi!
Stel ik krijg de vraag op een tentamen om onderstaand te ordenen op basis van de kans waarop de nulhypothese wordt verworpen (van klein naar groot).
Je zou dan met tabel B.11 en de niet-centraliteitsparameter voor elke apart kunnen berekenen wat het onderscheidend vermorgen is en het op die manier ordenen, maar volgens mij moet je deze vraag ook zonder kunnen beantwoorden. Weet iemand een handige manier om dat te kunnen doen/benaderen? De vorige keer hadden ze die tabel en formule er nml niet bij gegeven.
Stel ik krijg de vraag op een tentamen om onderstaand te ordenen op basis van de kans waarop de nulhypothese wordt verworpen (van klein naar groot).

Je zou dan met tabel B.11 en de niet-centraliteitsparameter voor elke apart kunnen berekenen wat het onderscheidend vermorgen is en het op die manier ordenen, maar volgens mij moet je deze vraag ook zonder kunnen beantwoorden. Weet iemand een handige manier om dat te kunnen doen/benaderen? De vorige keer hadden ze die tabel en formule er nml niet bij gegeven.
Dat is een beetje een vreemde vraag want de nulhypothese wordt wel of niet verworpen, daar zit geen "kans" in. Met de informatie die je hebt kun je een t-value uitrekenen (verschil in means gedeeld door standaard-deviatie gedeeld door wortel n). Om van de t-value naar een p-waarde te gaan of om op tezoeken of dat extremer dan de alpha is heb je een tabel of grafische rekenmachine of internet / spss nodig. Als de alphas overal hetzelfde waren geweest had je het op t-waarde kunnen rangschikken.quote:
Hoi!
Stel ik krijg de vraag op een tentamen om onderstaand te ordenen op basis van de kans waarop de nulhypothese wordt verworpen (van klein naar groot).
[ afbeelding ]
Je zou dan met tabel B.11 en de niet-centraliteitsparameter voor elke apart kunnen berekenen wat het onderscheidend vermorgen is en het op die manier ordenen, maar volgens mij moet je deze vraag ook zonder kunnen beantwoorden. Weet iemand een handige manier om dat te kunnen doen/benaderen? De vorige keer hadden ze die tabel en formule er nml niet bij gegeven.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Klopt, maar het onderscheidend vermogen is natuurlijk niet overal even hoog.quote:
[..]
Dat is een beetje een vreemde vraag want de nulhypothese wordt wel of niet verworpen, daar zit geen "kans" in. Met de informatie die je hebt kun je een t-value uitrekenen (verschil in means gedeeld door standaard-deviatie gedeeld door wortel n). Om van de t-value naar een p-waarde te gaan of om op tezoeken of dat extremer dan de alpha is heb je een tabel of grafische rekenmachine of internet / spss nodig. Als de alphas overal hetzelfde waren geweest had je het op t-waarde kunnen rangschikken.

Grafische rekenmachine en SPSS/internet zijn geen optie helaas. Het moet echt uit het hoofd door de steekproefgroottes, standaardafwijkingen en significanties te vergelijken. Dat de kans bij C bijvoorbeeld kleiner is dan D is logisch, aangezien de nulhypothese bij een significantie van 0.05 eerder zal worden verworpen dan bij een significantie van 0.02. Als ik zo het antwoord zie 'snap' ik het wel. Maar om dat onderling allemaal te ordenen bij verschillende steekproefgroottes en dergelijke vind ik op een tentamen niet te doen.
Het beroerde is dat ik gewoon vrij zeker weet dat die vraag gaat komen en dat ik hem niet precies goed ga ordenen.
Ik gok dat je statistiekdocent wil dat je inzicht hebt in hoe statistische toetsen werken. Als je dan eerst kijkt naar de gemiddelden, dan zie je dat in twee gevallen de drie gemiddeldes hetzelfde zijn. Daarnaast zie je dat bij A-D de verschillen in principe hetzelfde zijn. A-D zullen dan een hogere "kans" op significantie hebben (tussen aanhalingstekens wegens oompa's terechte post). Vervolgens kun je bij die verschillende varianten gaan kijken naar de andere gegevens en op basis van de formules die doorgaans gebruikt worden schatten wat het meeste de "kans" beïnvloed etc.quote:
[..]
Klopt, maar het onderscheidend vermogen is natuurlijk niet overal even hoog.
[ afbeelding ]
Grafische rekenmachine en SPSS/internet zijn geen optie helaas. Het moet echt uit het hoofd door de steekproefgroottes, standaardafwijkingen en significanties te vergelijken. Dat de kans bij C bijvoorbeeld kleiner is dan D is logisch, aangezien de nulhypothese bij een significantie van 0.05 eerder zal worden verworpen dan bij een significantie van 0.02. Als ik zo het antwoord zie 'snap' ik het wel. Maar om dat onderling allemaal te ordenen bij verschillende steekproefgroottes en dergelijke vind ik op een tentamen niet te doen.
Het beroerde is dat ik gewoon vrij zeker weet dat die vraag gaat komen en dat ik hem niet precies goed ga ordenen.
Ik hoop niet dat de vraag gaat komen, want de vraag klopt nietquote:
[..]
Klopt, maar het onderscheidend vermogen is natuurlijk niet overal even hoog.
[ afbeelding ]
Grafische rekenmachine en SPSS/internet zijn geen optie helaas. Het moet echt uit het hoofd door de steekproefgroottes, standaardafwijkingen en significanties te vergelijken. Dat de kans bij C bijvoorbeeld kleiner is dan D is logisch, aangezien de nulhypothese bij een significantie van 0.05 eerder zal worden verworpen dan bij een significantie van 0.02. Als ik zo het antwoord zie 'snap' ik het wel. Maar om dat onderling allemaal te ordenen bij verschillende steekproefgroottes en dergelijke vind ik op een tentamen niet te doen.
Het beroerde is dat ik gewoon vrij zeker weet dat die vraag gaat komen en dat ik hem niet precies goed ga ordenen.
Bij welke opleiding hoort dit?
Je kunt met berederen redelijk ver komen. Bv E en F hebben identieke gemiddeldes, daar zit dus zeker geen verschil tussen.
G en A zijn in essentie hetzelfde, de ene heeft een verschil van 10 met een sd van 10, de andere een verschil van 20 met een sd van 20. Als je die in de formule zou stoppen zou er (aangezien de n bij allebei 100 is) exact dezelfde t waarde uit moeten komen, etc.
B is hetzelfde als A maar met een grotere sd, dus B zal minder sig zijn dan A.
D is hetzelfde als B, maar met een lagere n, als je dat in de formule zou stoppen zou er dus een lagere t uitkomen dus is nog minder sig.
C is als D maar met een strengere alfa die is dus nog minder significant.
Kom je uit op:
E&F, C, D, B, A&G
Het antwoord dat gegeven wordt klopt niet, E&F zouden de laagste plaats moeten delen.
[ Bericht 6% gewijzigd door oompaloompa op 19-07-2015 18:25:47 ]
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Klopt wel, tussen de gemiddeldes van E en F zit namelijk geen verschil (alle drie 100). De nulhypothese dat de gemiddeldes van elkaar verschillen zal dus niet verworpen worden bij een hoog onderscheidend vermogen. Gezien de steekproeven van n=500 en n=1000 zal het onderscheidend vermogen hoog zijn, waardoor de kans van E & F om verworpen te worden kleiner is dan bij de rest.quote:
[..]
Ik hoop niet dat de vraag gaat komen, want de vraag klopt niet
Bij welke opleiding hoort dit?
Je kunt met berederen redelijk ver komen. Bv E en F hebben identieke gemiddeldes, daar zit dus zeker geen verschil tussen.
G en A zijn in essentie hetzelfde, de ene heeft een verschil van 10 met een sd van 10, de andere een verschil van 20 met een sd van 20. Als je die in de formule zou stoppen zou er (aangezien de n bij allebei 100 is) exact dezelfde t waarde uit moeten komen, etc.
B is hetzelfde als A maar met een grotere sd, dus B zal minder sig zijn dan A.
D is hetzelfde als B, maar met een lagere n, als je dat in de formule zou stoppen zou er dus een lagere t uitkomen dus is nog minder sig.
C is als D maar met een strengere alfa die is dus nog minder significant.
Kom je uit op:
E&F, C, D, B, A&G
Het antwoord dat gegeven wordt klopt niet, E&F zouden de laagste plaats moeten delen.
Bedankt voor je reactie iig.
Dat is niet waar, de formule is:quote:
[..]
Klopt wel, tussen de gemiddeldes van E en F zit namelijk geen verschil (alle drie 100). De nulhypothese dat de gemiddeldes van elkaar verschillen zal dus niet verworpen worden bij een hoog onderscheidend vermogen. Gezien de steekproeven van n=500 en n=1000 zal het onderscheidend vermogen hoog zijn, waardoor de kans van E & F om verworpen te worden kleiner is dan bij de rest.
Bedankt voor je reactie iig.
verschil in means / vanalles.
Het verschil in means is in beide gevallen 0, 0/whatever is 0. de "kans" dat het verworpen wordt is voor beide situaties 0
Het is echt een extreem slechte opgave van de docent, de vraag slaat nergens op en het leert de studenten gewoon een verkeerde interpretstie van statistiek aan.
edit: sorry dit frustreert me maar het is niet richting jou. Ik geef workshops etc. statistiek en mensen interpreteren het al zo vaak verkeerd dat het zien dat docenten het verkeerd aanleren me nogal opgefokt maakt.
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Sorry ik had verkeerd gelezen. Dacht dat je bedoelde dat E & F in de ordening achteraan moesten staan.quote:
[..]
Dat is niet waar, de formule is:
verschil in means / vanalles.
Het verschil in means is in beide gevallen 0, 0/whatever is 0. de "kans" dat het verworpen wordt is voor beide situaties 0
Het is echt een extreem slechte opgave van de docent, de vraag slaat nergens op en het leert de studenten gewoon een verkeerde interpretstie van statistiek aan.
edit: sorry dit frustreert me maar het is niet richting jou. Ik geef workshops etc. statistiek en mensen interpreteren het al zo vaak verkeerd dat het zien dat docenten het verkeerd aanleren me nogal opgefokt maakt.
Ik vind het ook een belachelijke vraag voor een tentamen verder.
Hallo allemaal,
Op dit moment voer ik een lezersonderzoek uit en loop tegen een aantal zaken aan. Ik vroeg mij af of op dit forum toevallig mensen zijn die meer ervaring hebben met marktonderzoek/statistiek en voor mij iets kunnen verhelderen.
De online enquête heb ik verstuurd naar de e-mailadressen uit het adressenbestand. Na het versturen van de enquête en een herinnering blijft de respons enorm achter. Ik had gehoopt op minstens 171 respondenten, zodat ik een uitspraak zou kunnen doen met 90% betrouwbaarheid en een nauwkeurigheidsmarge van 6%. Maar omdat ik maar 101 reacties heb gekregen zit ik nu weer te rekenen met het betrouwbaarheidsniveau en de nauwkeurigheidsmarge.
Ik weet dat 5% nauwkeurigheidsmarge gangbaar is, maar voor mijn onderzoek is dat niet haalbaar. Online kan ik nergens vinden wat de consequentie is voor uitspraken in een onderzoek als de nauwkeurigheidsmarge tussen de 6-10% ligt.
In mijn specifieke geval kan ik de marges en het niveau als volgt aanpassen:
Bij 95% betrouwbaarheid en 10% nauwkeurigheidsmarge heb ik 92 respondenten nodig.
Bij 90% betrouwbaarheid en 8% nauwkeurigheidsmarge heb ik 100 respondenten nodig.
Kan ik met deze betrouwbaarheid en nauwkeurigheid nog wel uitspraken doen over het adressenbestand? Maakt een hogere nauwkeurigheidsmarge een onderzoek minder valide of een lager betrouwbaarheidsniveau? Wat is het meest verstandige om te doen?
Op dit moment voer ik een lezersonderzoek uit en loop tegen een aantal zaken aan. Ik vroeg mij af of op dit forum toevallig mensen zijn die meer ervaring hebben met marktonderzoek/statistiek en voor mij iets kunnen verhelderen.
De online enquête heb ik verstuurd naar de e-mailadressen uit het adressenbestand. Na het versturen van de enquête en een herinnering blijft de respons enorm achter. Ik had gehoopt op minstens 171 respondenten, zodat ik een uitspraak zou kunnen doen met 90% betrouwbaarheid en een nauwkeurigheidsmarge van 6%. Maar omdat ik maar 101 reacties heb gekregen zit ik nu weer te rekenen met het betrouwbaarheidsniveau en de nauwkeurigheidsmarge.
Ik weet dat 5% nauwkeurigheidsmarge gangbaar is, maar voor mijn onderzoek is dat niet haalbaar. Online kan ik nergens vinden wat de consequentie is voor uitspraken in een onderzoek als de nauwkeurigheidsmarge tussen de 6-10% ligt.
In mijn specifieke geval kan ik de marges en het niveau als volgt aanpassen:
Bij 95% betrouwbaarheid en 10% nauwkeurigheidsmarge heb ik 92 respondenten nodig.
Bij 90% betrouwbaarheid en 8% nauwkeurigheidsmarge heb ik 100 respondenten nodig.
Kan ik met deze betrouwbaarheid en nauwkeurigheid nog wel uitspraken doen over het adressenbestand? Maakt een hogere nauwkeurigheidsmarge een onderzoek minder valide of een lager betrouwbaarheidsniveau? Wat is het meest verstandige om te doen?
Delivered without an information leaflet
Ik doe vaak marktonderzoek met relatief lage n-en en kies er altijd voor 95% betrouwbaarheid. Dan kan je uiteraard niet al te stellige uitspraken doen, maar er zullen überhaupt bijna geen significante verschillen zijn. Wel significante verschillen met een lager betrouwbaarheid (of een hogere onbetrouwbaarheid) vind ik niet interessant.
Onderstaand figuur is wel inzichtelijk:
Bij 50% is de marge altijd het grootst. Dus in jouw geval, als je het onderzoek nog een keer zou uitvoeren, zal een uitkomst van 50% in ene herhalingsonderzoek ergens tussen de 40% en 60% liggen.
Let wel, dit is een mening van een marktonderzoeker, de wetenschappers hier denken er wellicht anders over.
Onderstaand figuur is wel inzichtelijk:

Bij 50% is de marge altijd het grootst. Dus in jouw geval, als je het onderzoek nog een keer zou uitvoeren, zal een uitkomst van 50% in ene herhalingsonderzoek ergens tussen de 40% en 60% liggen.
Let wel, dit is een mening van een marktonderzoeker, de wetenschappers hier denken er wellicht anders over.
Aldus.
Thanks, Z. Maar om heel eerlijk te zijn begrijp ik niet zo goed wat het verschil is tussen een grotere nauwkeurigheid of een kleinere betrouwbaarheid. Kan jij het mij uitleggen in jip en janneke taal? Ik wil het heel graag begrijpen, zodat ik mijn keuze ook goed kan verantwoorden. Het enige dat ik weet is dat je bij een nauwkeurigheid niet meer dan 10% neemt en bij een betrouwbaarheid nooit lager dan 90% gaat.. Maar wat het wezenlijke verschil nou is en "belangrijker"?quote:
Kan ik überhaupt wel afstuderen met zulke betrouwbaarheidsniveaus (95/90%) en foutmarges (10/8%)?
Delivered without an information leaflet
Heb gedaan wat jij suggereerde. Dus 3 dichtome variabelen gemaakt (hoge score/lage score per leiderschapsstijl) en vervolgens deze via een independent t-test vergeleken met de gemiddelde scores op de andere leiderschapsstijl. (uitkomst is niet significant). Maar vraag me nog altijd wel af of ik wel mag concluderen dat ze dan wel (of in dit geval dus niet) significant van elkaar verschillen..quote:
Heb je al de Likertschalen samengevoegd tot één ratiovariabele (mits de cronbachs alpha goed zit natuurlijk)? Dan kan je wel mikken of ze significant van elkaar verschillen.
Wat je zou kunnen doen, maar dat is maar een hersenscheetje, is vaststellen wat 'hoog' is. Bijvoorbeeld, boven de 3,5 gemiddeld. Dan maak je drie nieuwe dichotome variabelen (stijl 1 hoog of laag, etc). Vergelijk dan de gemiddelden van stijl 2 tussen de twee groepen 'stijl 1 hoog' en 'stijl 1 laag'. Als daar significant verschil in zit, heb je een conclusie.
Maar nogmaals, is maar een hersenscheetje.
Maar nogmaals bedankt! Ben in ieder geval al verder dan ik voorheen was
Fantasie is belangrijker dan kennis, want kennis is begrensd.
Wat voor studie doe je?quote:
[..]
Thanks, Z. Maar om heel eerlijk te zijn begrijp ik niet zo goed wat het verschil is tussen een grotere nauwkeurigheid of een kleinere betrouwbaarheid. Kan jij het mij uitleggen in jip en janneke taal? Ik wil het heel graag begrijpen, zodat ik mijn keuze ook goed kan verantwoorden. Het enige dat ik weet is dat je bij een nauwkeurigheid niet meer dan 10% neemt en bij een betrouwbaarheid nooit lager dan 90% gaat.. Maar wat het wezenlijke verschil nou is en "belangrijker"?
Kan ik überhaupt wel afstuderen met zulke betrouwbaarheidsniveaus (95/90%) en foutmarges (10/8%)?
Aldus.
Ik wil de volgende hypotheses van het onderstaande model testen (groen = significant, rood = niet significant)
Ik wil geen Sobel test gebruik om het indirect effect te berekenen, maar een bootstrap of de t/p-values. Alleen ik loop vast met het toepassen ervan, sterker nog, ik heb gewoon geen idee hoe ik dit moet berekenen.
Het model heb ik getest in SmartPLS, weet iemand hoe ik dit kan berekenen
Ik wil geen Sobel test gebruik om het indirect effect te berekenen, maar een bootstrap of de t/p-values. Alleen ik loop vast met het toepassen ervan, sterker nog, ik heb gewoon geen idee hoe ik dit moet berekenen.
Het model heb ik getest in SmartPLS, weet iemand hoe ik dit kan berekenen

BlaBlaBla
Ik heb ook nog een andere vraag, ik heb in mijn onderzoek enkele P waardes die hoger liggen dan de algemeen geaccepteerde cut-off point van p=0.05, namelijk p=0.054 en p=0.056.
Ondanks dat ze hoger dan de cut-off point liggen, wil ik er wel iets over zeggen, maar niet in de trant van: 'a nonsignificant trend' of 'a small trend'.
Tips?
Ondanks dat ze hoger dan de cut-off point liggen, wil ik er wel iets over zeggen, maar niet in de trant van: 'a nonsignificant trend' of 'a small trend'.
Tips?
BlaBlaBla
quote:
Ik heb ook nog een andere vraag, ik heb in mijn onderzoek enkele P waardes die hoger liggen dan de algemeen geaccepteerde cut-off point van p=0.05, namelijk p=0.054 en p=0.056.
Ondanks dat ze hoger dan de cut-off point liggen, wil ik er wel iets over zeggen, maar niet in de trant van: 'a nonsignificant trend' of 'a small trend'.
Tips?
SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.legio mogelijkheden!
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
quote:
[..]Maar dat is allemaal ongeveer hetzelfde in andere bewoording. Ik denk dat hij eerder iets zoekt als groepsgrootte net te klein om significantie aan te tonen. Grotere groep waarschijnlijk wel significant.SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt."Happiness is not getting more, but wanting less"
Ja, of het effect/verschil is te klein voor deze groep.quote:
[..]
Maar dat is allemaal ongeveer hetzelfde in andere bewoording. Ik denk dat hij eerder iets zoekt als groepsgrootte net te klein om significantie aan te tonen. Grotere groep waarschijnlijk wel significant.
'Expand my brain, learning juice!'
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
<a href="http://www.last.fm/user/crossover1" rel="nofollow" target="_blank">Last.fm</a>
Ik wil iets over die hypothese zeggen, niet simpel weg, hoger dan 0.05, dus niet significant, niet bewezen and that's it. Maar wel iets dat aanvaardbaar is.
BlaBlaBla
Wat we hierboven dus zeggen. Dat het effect (net) te klein is om met deze groep aan tonen, maar met een iets grotere groep waarschijnlijk wel significant is. Je kunt het nu niet significant lullen, tenzij je je data gaat aanpassen maar dan moet je Diederik Stapel maar even om advies vragen...quote:
Ik wil iets over die hypothese zeggen, niet simpel weg, hoger dan 0.05, dus niet significant, niet bewezen and that's it. Maar wel iets dat aanvaardbaar is.
"Happiness is not getting more, but wanting less"
Beste forumlezers,
Ik heb een vraag voor mijn scriptie. Ik heb de correlatie berekend tussen een onafhankelijke en een afhankelijke variabele. Deze samenhang bleek laag (+ niet significant). Nu wil ik graag weten of een andere variabele, namelijk leeftijd (continue variabele), dit verband beïnvloedt. Kan ik dit uberhaupt meten wanneer er geen significante samenhang was? En hoe dan? Via een multipele regressieanalyse? En moet ik van de moderatorvariabele dan een categorische variabele maken, of kan dit met een continue variabele? Ter informatie: de onafhankelijke en de afhankelijke variabelen zijn beiden continue, maar ik kan van de afhankelijke variabele ook een categorische variabele maken.
Groetjes,
Iris
Ik heb een vraag voor mijn scriptie. Ik heb de correlatie berekend tussen een onafhankelijke en een afhankelijke variabele. Deze samenhang bleek laag (+ niet significant). Nu wil ik graag weten of een andere variabele, namelijk leeftijd (continue variabele), dit verband beïnvloedt. Kan ik dit uberhaupt meten wanneer er geen significante samenhang was? En hoe dan? Via een multipele regressieanalyse? En moet ik van de moderatorvariabele dan een categorische variabele maken, of kan dit met een continue variabele? Ter informatie: de onafhankelijke en de afhankelijke variabelen zijn beiden continue, maar ik kan van de afhankelijke variabele ook een categorische variabele maken.
Groetjes,
Iris
Even newbie question hoor
Maar hoe kan ik het volgende in excel maken?
in cel a1 staat x, als dan in cel a2 y staat moet cel a1 rood worden.
Hoe doe ik dat met voorwaardelijke opmaak?
Maar hoe kan ik het volgende in excel maken?
in cel a1 staat x, als dan in cel a2 y staat moet cel a1 rood worden.
Hoe doe ik dat met voorwaardelijke opmaak?
Man is de baas, vrouw kent haar plaats.
Heb je hiervoor nog een oplossing gevonden? Ik heb voor mijn thesis de process macro van Hayes geïnstalleerd in SPSS. Dat werkt enorm goed alleen heeft wel enige instructie nodig.quote:
Ik wil de volgende hypotheses van het onderstaande model testen (groen = significant, rood = niet significant)
Ik wil geen Sobel test gebruik om het indirect effect te berekenen, maar een bootstrap of de t/p-values. Alleen ik loop vast met het toepassen ervan, sterker nog, ik heb gewoon geen idee hoe ik dit moet berekenen.
Het model heb ik getest in SmartPLS, weet iemand hoe ik dit kan berekenen
[ afbeelding ]
je kunt gewoon bij conditional formatting A1 selecteren "new rule" -> "use formula to determine which cells to format" ... en dan daar =A2=y in zetten als je het voor een hele kolom wil dan zet je er =$A2=y neerquote:
Even newbie question hoor
Maar hoe kan ik het volgende in excel maken?
in cel a1 staat x, als dan in cel a2 y staat moet cel a1 rood worden.
Hoe doe ik dat met voorwaardelijke opmaak?
[ Bericht 2% gewijzigd door Bosbeetle op 18-08-2015 18:42:16 ]
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Ik heb een aantal vragen over mijn dataverwerking.
-Niet elke respondent heeft op mijn enquête een leeftijd ingevuld. Ik had de keuze om die vraag verplicht te maken, echter heb je dan kans dat men de enquete daar al afbreekt. De andere optie is vragen niet allemaal verplicht maken. Ik zou volgens mijn begeleider die specifieke missende leeftijden niet mee moeten nemen. Je hebt missing-pairwise en missing-listwise maar verder gaf hij geen tips. Iemand anders zei dat je het ook op kunt lossen door op de plaats van de missende leeftijden het gemiddelde / de modus of de mediaan van alle leeftijden neer kan zetten, echter dat dit een mindere optie was. Weet iemand hoe ik deze specifieke missende leeftijden (ik denk bij 10 van de 300 respondenten) eruit laat?
-Ik heb mijn data verzamelt in Qualtrics in aparte mapjes. Dus elk projectteam wat ik ondervraagd heb staat in een aparte map met daarin een enquete. Heeft iemand een idee hoe ik dit makkelijk kan samenvoegen met de teamleider enquêtes (aparte survey).
-Vervolgens moet ik mijn data aggregeren naar team level via ICC. Ik zie wel wat filmpjes, maar welke variabelen moet ik wel en niet meeenemen in de analyse?
-Heeft er iemand verstand van de Hayes process macro waarmee je mediatoren / moderatoren kan testen?
[ Bericht 5% gewijzigd door W00fer op 15-10-2015 15:54:08 ]
-Niet elke respondent heeft op mijn enquête een leeftijd ingevuld. Ik had de keuze om die vraag verplicht te maken, echter heb je dan kans dat men de enquete daar al afbreekt. De andere optie is vragen niet allemaal verplicht maken. Ik zou volgens mijn begeleider die specifieke missende leeftijden niet mee moeten nemen. Je hebt missing-pairwise en missing-listwise maar verder gaf hij geen tips. Iemand anders zei dat je het ook op kunt lossen door op de plaats van de missende leeftijden het gemiddelde / de modus of de mediaan van alle leeftijden neer kan zetten, echter dat dit een mindere optie was. Weet iemand hoe ik deze specifieke missende leeftijden (ik denk bij 10 van de 300 respondenten) eruit laat?
-Ik heb mijn data verzamelt in Qualtrics in aparte mapjes. Dus elk projectteam wat ik ondervraagd heb staat in een aparte map met daarin een enquete. Heeft iemand een idee hoe ik dit makkelijk kan samenvoegen met de teamleider enquêtes (aparte survey).
-Vervolgens moet ik mijn data aggregeren naar team level via ICC. Ik zie wel wat filmpjes, maar welke variabelen moet ik wel en niet meeenemen in de analyse?
-Heeft er iemand verstand van de Hayes process macro waarmee je mediatoren / moderatoren kan testen?
[ Bericht 5% gewijzigd door W00fer op 15-10-2015 15:54:08 ]
Friettent dikke Willie, met Willie
Als je leeftijden alleen gebruikt als onderdeel van de demografische gegevens in je methode sectie, dan zou ik gewoon via SPSS de gemiddelde leeftijd en standaarddeviatie berekenen. Hij neemt dan automatisch (volgens mij, heb even geen SPSS bij de hand om het te proberen) alleen de cases mee waarbij er een waarde is voor die variabele. Als je met de leeftijden wilt gaan rekenen wordt het een ander verhaal, maar dan heb ik meer informatie nodig over je onderzoeksopzet.quote:
Ik heb een aantal vragen over mijn dataverwerking.
-Niet elke respondent heeft op mijn enquête een leeftijd ingevuld. Ik had de keuze om die vraag verplicht te maken, echter heb je dan kans dat men de enquete daar al afbreekt. De andere optie is vragen niet allemaal verplicht maken. Ik zou volgens mijn begeleider die specifieke missende leeftijden niet mee moeten nemen. Je hebt missing-pairwise en missing-listwise maar verder gaf hij geen tips. Iemand anders zei dat je het ook op kunt lossen door op de plaats van de missende leeftijden het gemiddelde / de modus of de mediaan van alle leeftijden neer kan zetten, echter dat dit een mindere optie was. Weet iemand hoe ik deze specifieke missende leeftijden (ik denk bij 10 van de 300 respondenten) eruit laat?
Klinkt alsof elke enquete door Qualtrics als uniek wordt gezien (met daarbinnen de data van elk projectteam). In dat geval is het handigste (denk ik) om alle data te exporteren naar SPSS, zorgen dat de variabelen hetzelfde heten en meten en dan merge files (add cases, niet variables).quote:-Ik heb mijn data verzamelt in Qualtrics in aparte mapjes. Dus elk projectteam wat ik ondervraagd heb staat in een aparte map met daarin een enquete. Heeft iemand een idee hoe ik dit makkelijk kan samenvoegen met de teamleider enquêtes (aparte survey).
ICC zegt me zo 1 2 3 niets, wat bedoel je hier precies?quote:-Vervolgens moet ik mijn data aggregeren naar team level via ICC. Ik zie wel wat filmpjes, maar welke variabelen moet ik wel en niet meeenemen in de analyse?
Geen idee, sorry.quote:-Heeft er iemand verstand van de Hayes process macro waarmee je mediatoren / moderatoren kan testen?
Om de teams uit elkaar te houden heb ik het zo gedaanquote:
[..]
Als je leeftijden alleen gebruikt als onderdeel van de demografische gegevens in je methode sectie, dan zou ik gewoon via SPSS de gemiddelde leeftijd en standaarddeviatie berekenen. Hij neemt dan automatisch (volgens mij, heb even geen SPSS bij de hand om het te proberen) alleen de cases mee waarbij er een waarde is voor die variabele. Als je met de leeftijden wilt gaan rekenen wordt het een ander verhaal, maar dan heb ik meer informatie nodig over je onderzoeksopzet.
[..]
Klinkt alsof elke enquete door Qualtrics als uniek wordt gezien (met daarbinnen de data van elk projectteam). In dat geval is het handigste (denk ik) om alle data te exporteren naar SPSS, zorgen dat de variabelen hetzelfde heten en meten en dan merge files (add cases, niet variables).
[..]
ICC zegt me zo 1 2 3 niets, wat bedoel je hier precies?
[..]
Geen idee, sorry.
Mapje HEMA team
-Teamleden enquete
-Teamleider enquete
Mapje Bart Smit team
-Teamleden enquete
-Teamleider enquete
ICC is ervoor om de resultaten van teamleden te aggregeren naar teamniveau, aangezien de variabelen in mijn onderzoeksmodel op teamniveau conclusies geven (Unit of Analysis is teamlevel, unit of observation individual level).
Wat bedoel je met die merge files met cases, voegt hij anders kolommen toe als ik voor variables kies?
Friettent dikke Willie, met Willie
Oké, ik neem aan dat je de vragenlijst dus gekopieerd hebt naar die mapjes? Dan zijn het voor Qualtrics (denk ik) onafhankelijke vragenlijsten geworden, ieder met de eigen deelnemers (HemaLeden/HemaLeider/BartLeden/BartLeider). Het is dan het handigste om dit na het downloaden van de data samen te voegen denk ik.quote:
[..]
Om de teams uit elkaar te houden heb ik het zo gedaan
Mapje HEMA team
-Teamleden enquete
-Teamleider enquete
Mapje Bart Smit team
-Teamleden enquete
-Teamleider enquete
Ik heb geen ervaring met multi-level analysis helaas, misschien dat anderen je hier daar beter mee kunnen helpen.quote:ICC is ervoor om de resultaten van teamleden te aggregeren naar teamniveau, aangezien de variabelen in mijn onderzoeksmodel op teamniveau conclusies geven (Unit of Analysis is teamlevel, unit of observation individual level).
Ja. Dus als je bijvoorbeeld een dataset hebt met leeftijd en geslacht van deelnemers 1-50 en een andere dataset met leeftijd en geslacht van deelnemers 51-100, dan kun je die tweede met die eerste 'mergen' op 'cases' om deelnemers 51-100 aan de dataset van deelnemers 1-50 toe te voegen. Als je op variabele zou mergen zou je opeens 4 variabelen hebben, geslacht, leeftijd en nog eens geslacht en leeftijd. Dat wordt een redelijke bende.quote:Wat bedoel je met die merge files met cases, voegt hij anders kolommen toe als ik voor variables kies?
Ja ik heb de lege surveys vooraf gekopieerd.quote:
[..]
Oké, ik neem aan dat je de vragenlijst dus gekopieerd hebt naar die mapjes? Dan zijn het voor Qualtrics (denk ik) onafhankelijke vragenlijsten geworden, ieder met de eigen deelnemers (HemaLeden/HemaLeider/BartLeden/BartLeider). Het is dan het handigste om dit na het downloaden van de data samen te voegen denk ik.
[..]
Ik heb geen ervaring met multi-level analysis helaas, misschien dat anderen je hier daar beter mee kunnen helpen.
[..]
Ja. Dus als je bijvoorbeeld een dataset hebt met leeftijd en geslacht van deelnemers 1-50 en een andere dataset met leeftijd en geslacht van deelnemers 51-100, dan kun je die tweede met die eerste 'mergen' op 'cases' om deelnemers 51-100 aan de dataset van deelnemers 1-50 toe te voegen. Als je op variabele zou mergen zou je opeens 4 variabelen hebben, geslacht, leeftijd en nog eens geslacht en leeftijd. Dat wordt een redelijke bende.
Enig idee hoe ik de teamleider survey aan de teamleden survey moet koppelen?
De teamleider heeft dmv 12 vragen zijn teamleden beoordeeld, de teamleden hebben dmv 19 vragen hun werkzaamheden beoordeeld. Ik neem aan dat je linaire regressie doet door bijv independent variable "werkzaamheden" op "teamprestaties" toch zijn dit compleet andere vragenlijsten? Ik wil kijken in hoeverre de werkzaamheden van invloed zijn op de prestaties.
Friettent dikke Willie, met Willie
In de SPSS bestanden even een variabele aanmaken met proefpersoonnummer van de teamleden. Daarna merge -> add variables en dan kun je als het goed is ergens aanklikken dat het gebaseerd moet zijn op dat proefpersoonnummer, dan krijg je (als het goed is) een dataset met de antwoorden van je teamleden en daarnaast de beoordelingen van de teamleider.quote:
Enig idee hoe ik de teamleider survey aan de teamleden survey moet koppelen?
Het ligt eraan of alle vragen van elke lijst hetzelfde meten (factoranalyse enzo). Als dat zo is kun je eventueel totaalscores maken en vervolgens correlaties berekenen of andere regressie-analyses uitvoeren. Dat ligt aan je onderzoeksvragen, precieze data en structuur.quote:De teamleider heeft dmv 12 vragen zijn teamleden beoordeeld, de teamleden hebben dmv 19 vragen hun werkzaamheden beoordeeld. Ik neem aan dat je linaire regressie doet door bijv independent variable "werkzaamheden" op "teamprestaties" toch zijn dit compleet andere vragenlijsten? Ik wil kijken in hoeverre de werkzaamheden van invloed zijn op de prestaties.
Moet je mediation testen of moderation?quote:
Ik heb een aantal vragen over mijn dataverwerking.
-Niet elke respondent heeft op mijn enquête een leeftijd ingevuld. Ik had de keuze om die vraag verplicht te maken, echter heb je dan kans dat men de enquete daar al afbreekt. De andere optie is vragen niet allemaal verplicht maken. Ik zou volgens mijn begeleider die specifieke missende leeftijden niet mee moeten nemen. Je hebt missing-pairwise en missing-listwise maar verder gaf hij geen tips. Iemand anders zei dat je het ook op kunt lossen door op de plaats van de missende leeftijden het gemiddelde / de modus of de mediaan van alle leeftijden neer kan zetten, echter dat dit een mindere optie was. Weet iemand hoe ik deze specifieke missende leeftijden (ik denk bij 10 van de 300 respondenten) eruit laat?
-Ik heb mijn data verzamelt in Qualtrics in aparte mapjes. Dus elk projectteam wat ik ondervraagd heb staat in een aparte map met daarin een enquete. Heeft iemand een idee hoe ik dit makkelijk kan samenvoegen met de teamleider enquêtes (aparte survey).
-Vervolgens moet ik mijn data aggregeren naar team level via ICC. Ik zie wel wat filmpjes, maar welke variabelen moet ik wel en niet meeenemen in de analyse?
-Heeft er iemand verstand van de Hayes process macro waarmee je mediatoren / moderatoren kan testen?
Beiden. Ik heb zowel een mediator als moderator.quote:
[..]
Moet je mediation testen of moderation?
Friettent dikke Willie, met Willie
Ik ga eerst de cronbachs alpha berekenen om te kijken of ik wat vragen eruit kan gooien. Die totaalscores per team hoe werkt dat?quote:
[..]
In de SPSS bestanden even een variabele aanmaken met proefpersoonnummer van de teamleden. Daarna merge -> add variables en dan kun je als het goed is ergens aanklikken dat het gebaseerd moet zijn op dat proefpersoonnummer, dan krijg je (als het goed is) een dataset met de antwoorden van je teamleden en daarnaast de beoordelingen van de teamleider.
[..]
Het ligt eraan of alle vragen van elke lijst hetzelfde meten (factoranalyse enzo). Als dat zo is kun je eventueel totaalscores maken en vervolgens correlaties berekenen of andere regressie-analyses uitvoeren. Dat ligt aan je onderzoeksvragen, precieze data en structuur.
Friettent dikke Willie, met Willie
Dus eigenlijk heb je moderated mediation? Is je moderator binary?quote:
[..]
Beiden. Ik heb zowel een mediator als moderator.
En misschien is het handig om te vertellen welke van de 76 modellen je wil gaan testen:
http://www.afhayes.com/public/templates.pdf
[ Bericht 3% gewijzigd door #ANONIEM op 16-10-2015 11:23:19 ]
http://www.afhayes.com/public/templates.pdf
[ Bericht 3% gewijzigd door #ANONIEM op 16-10-2015 11:23:19 ]
Dat kan? Nee niet binary. Team tenure is het.quote:
[..]
Dus eigenlijk heb je moderated mediation? Is je moderator binary?
[ Bericht 2% gewijzigd door W00fer op 16-10-2015 12:38:15 ]
Friettent dikke Willie, met Willie
Model 5, alleen dan zonder direct effect tussen X en Y. Via Mi en dan W heef een invloed op de relatie tussen X en Mi. Zo dus:quote:
En misschien is het handig om te vertellen welke van de 76 modellen je wil gaan testen:
http://www.afhayes.com/public/templates.pdf

Friettent dikke Willie, met Willie
Eigenlijk bedoel je dus model 7? Snap je trouwens het idee van moderated mediation of überhaupt mediation? Of bestaat je conceptuele model eigenlijk uit twee losse relaties a op b met 1 moderator en b op c als directe relatie?quote:
[..]
Model 5, alleen dan zonder direct effect tussen X en Y. Via Mi en dan W heef een invloed op de relatie tussen X en Mi. Zo dus:
[ afbeelding ]
[ Bericht 0% gewijzigd door #ANONIEM op 19-10-2015 13:12:46 ]
Nee, want Dat zou betekenen dat de moderator invloed heeft op mijn mediator. Volgens mij is dat niet in mijn model wat ik hierboven getekend heb. Het hoeft namelijk niet van invloed te zijn opquote:
[..]
Eigenlijk bedoel je dus model 7? Snap je trouwens het idee van moderated mediation of überhaupt mediation? Of bestaat je conceptuele model eigenlijk uit twee losse relaties a op b met 1 moderator en b op c als directe relatie?
In model 7 ga je uit van een directe relatie tussen X en Y en die veronderstel ik niet, alleen via de mediator.
Friettent dikke Willie, met Willie
Dan test je dus geen mediation alleen maar twee aparte relaties die jij toevallig aan elkaar hebt gekoppeld in je model.quote:
[..]
Nee, want Dat zou betekenen dat de moderator invloed heeft op mijn mediator. Volgens mij is dat niet in mijn model wat ik hierboven getekend heb. Het hoeft namelijk niet van invloed te zijn op
In model 7 ga je uit van een directe relatie tussen X en Y en die veronderstel ik niet, alleen via de mediator.
Als je ook nog eens naar de omschrijving van mediation kijkt dan is die als volgt: Er bestaat een mediating effect als variabele Z de relatie tussen x en y wegneemt of afzwakt. Als je dan die moderator erbij pakt dan check je of dat voor bepaalde waarden van die moderator geldt.
Ik heb de mediator gepakt als versterkende waarde. Dus als X aanwezig is en Z dan zal Y waarschijnlijk optreden.quote:
Als je ook nog eens naar de omschrijving van mediation kijkt dan is die als volgt: Er bestaat een mediating effect als variabele Z de relatie tussen x en y wegneemt of afzwakt. Als je dan die moderator erbij pakt dan check je of dat voor bepaalde waarden van die moderator geldt.
Friettent dikke Willie, met Willie
Dan weet ik niet wat je aan het doen bent maar iig geen mediation. Succes met je onderzoek!quote:
[..]
Ik heb de mediator gepakt als versterkende waarde. Dus als X aanwezig is en Z dan zal Y waarschijnlijk optreden.
Bedankt voor de heads-up In elk geval, hoe kan ik de variabelen testen?quote:
[..]
Dan weet ik niet wat je aan het doen bent maar iig geen mediation. Succes met je onderzoek!
Want ik heb bijvoorbeeld 5 items per construct, dan test ik die eerst op cronbachs alpha, en daarna voer ik die variabelen in de process macro. Dus zowel X als Z als Y en dan geeft hij eruit wat ik moet hebben?
Friettent dikke Willie, met Willie
Na de cronbach wel 1 variabele van maken dan. Voor die process macro zijn wel tutorials te vinden. Je mag je uitkomst hier wel neerzetten dan.quote:
[..]
Bedankt voor de heads-up In elk geval, hoe kan ik de variabelen testen?
Want ik heb bijvoorbeeld 5 items per construct, dan test ik die eerst op cronbachs alpha, en daarna voer ik die variabelen in de process macro. Dus zowel X als Z als Y en dan geeft hij eruit wat ik moet hebben?
[ Bericht 0% gewijzigd door #ANONIEM op 19-10-2015 17:34:45 ]
Al zeg ik dat model 5 fout is als je dit wil doen moet je het volgende invoeren:
Minimum PROCESS command structure
PROCESS vars = xvar mvlist yvar wvar/y=yvar/x=xvar/m=mvlist/w=wvar/model=5.
Minimum PROCESS command structure
PROCESS vars = xvar mvlist yvar wvar/y=yvar/x=xvar/m=mvlist/w=wvar/model=5.
En wat doet die mvlist precies? Ik ga nog even navragen of ik model 5 moet doen of model 7.quote:
Al zeg ik dat model 5 fout is als je dit wil doen moet je het volgende invoeren:
Minimum PROCESS command structure
PROCESS vars = xvar mvlist yvar wvar/y=yvar/x=xvar/m=mvlist/w=wvar/model=5.
Waar moet ik precies op letten wat eruit komt?
Friettent dikke Willie, met Willie
Dat is je mediator. Model 5 test de moderator op de directe relatie waarvan jij zegt dat die niet bestaat dus dan kom je uit bij model 7.quote:
[..]
En wat doet die mvlist precies? Ik ga nog even navragen of ik model 5 moet doen of model 7.
Waar moet ik precies op letten wat eruit komt?
quote:
[..]
Dat is je mediator. Model 5 test de moderator op de directe relatie waarvan jij zegt dat die niet bestaat dus dan kom je uit bij model 7.
Ok, en moet de waarde nog precies ergens boven vallen of tussen vallen? Net zoals bij KMO ofzo of significantie.quote:
[..]
Dat is je mediator. Model 5 test de moderator op de directe relatie waarvan jij zegt dat die niet bestaat dus dan kom je uit bij model 7.
Friettent dikke Willie, met Willie
Hallo allemaal, een vraagje (niet heel statistisch maar ik kom er niet uit).
Voor een onafhankelijke variabele in mijn scriptie moet ik het percentage rechtse kabinetszetels in het totale kabinet (ministers + staatssecretarissen) berekenen over de periode 1 jan 2007 t/m 31 dec 2012 voor allerlei verschillende Europese landen.
VB Nederland:
Balkenende III (53 dagen) - 48,8 procent rechts
Balkenende IV (1300 dagen) - 0 procent rechts
Rutte I (753 dagen) - 50 procent rechts
Rutte II (331) - 50 procent rechts
Nu ben ik op zoek naar het gewogen (over aantal dagen) gemiddelde in procenten rechtse kabinetszetels. Ik heb echter geen idee hoe ik dit op basis van het aantal dagen moet wegen. Heeft iemand een idee hoe ik dit kan doen of evt een formule die ik hiervoor zou kunnen gebruiken?
Alvast bedankt
Voor een onafhankelijke variabele in mijn scriptie moet ik het percentage rechtse kabinetszetels in het totale kabinet (ministers + staatssecretarissen) berekenen over de periode 1 jan 2007 t/m 31 dec 2012 voor allerlei verschillende Europese landen.
VB Nederland:
Balkenende III (53 dagen) - 48,8 procent rechts
Balkenende IV (1300 dagen) - 0 procent rechts
Rutte I (753 dagen) - 50 procent rechts
Rutte II (331) - 50 procent rechts
Nu ben ik op zoek naar het gewogen (over aantal dagen) gemiddelde in procenten rechtse kabinetszetels. Ik heb echter geen idee hoe ik dit op basis van het aantal dagen moet wegen. Heeft iemand een idee hoe ik dit kan doen of evt een formule die ik hiervoor zou kunnen gebruiken?
Alvast bedankt
Je moet overigens wel goed bedenken of je genoeg variantie in je data hebt als je het op dagniveau gaat doen.
Goedemorgen,
Ik heb een voorbeeldvraag plus uitwerking ervan, die over de de tekentoets (sign test) gaat, maar hierover heb ik een vraag.
Dit levert 14+, 5- en één 0.
X: aantal plussen
H0: p=0,5 (er is geen verschil)
H1: p>0,5 (de herkansing is beter gemaakt)
X ~ Bin(19, 0,5)
P(X ≥ 14) = 1 – P(X ≤ 13) = 0,0318
''Dat is kleiner dan 0,05. we verwerpen de nulhypothese en nemen de alternatieve hypothese aan. De herkansing is beter gemaakt dan de toets.''
Wat ik mij dus afvraag:
-Hoe had ik het moeten aanpakken als de tekentoets tweezijdig was geweest en wat is de intuïtie erachter van de aanpak?
-Hoe had ik het moeten aanpakken als de alternatieve hypothese p < 0,5 was geweest en wat is de intuïtie erachter van de aanpak?
Ik heb een voorbeeldvraag plus uitwerking ervan, die over de de tekentoets (sign test) gaat, maar hierover heb ik een vraag.

Dit levert 14+, 5- en één 0.
X: aantal plussen
H0: p=0,5 (er is geen verschil)
H1: p>0,5 (de herkansing is beter gemaakt)
X ~ Bin(19, 0,5)
P(X ≥ 14) = 1 – P(X ≤ 13) = 0,0318
''Dat is kleiner dan 0,05. we verwerpen de nulhypothese en nemen de alternatieve hypothese aan. De herkansing is beter gemaakt dan de toets.''
Wat ik mij dus afvraag:
-Hoe had ik het moeten aanpakken als de tekentoets tweezijdig was geweest en wat is de intuïtie erachter van de aanpak?
-Hoe had ik het moeten aanpakken als de alternatieve hypothese p < 0,5 was geweest en wat is de intuïtie erachter van de aanpak?
Ik ben momenteel weer bezig met de data van mijn masteronderzoek, dat ik 1 jaar en een paar maanden geleden heb afgerond, om er een manuscript van te maken om te submitten.
Daarbij kwam ik tegen dat ik voor een bepaalde analyse partiële correlatie heb gebruikt. Een collega van me vroeg me gisteren waarom ik daarvoor gekozen heb i.p.v. (multivariate) lineaire regressie.
Ik besefte me dat daar een theoretische basis aan ten grondslag ligt, maar het is voor mij even te lang geleden om dat weer voor de geest te halen.
Mijn vraag is dan ook: wat zijn de verschillen tussen partiële correlatie en (multivariate) lineaire regessie?
Daarbij kwam ik tegen dat ik voor een bepaalde analyse partiële correlatie heb gebruikt. Een collega van me vroeg me gisteren waarom ik daarvoor gekozen heb i.p.v. (multivariate) lineaire regressie.
Ik besefte me dat daar een theoretische basis aan ten grondslag ligt, maar het is voor mij even te lang geleden om dat weer voor de geest te halen.
Mijn vraag is dan ook: wat zijn de verschillen tussen partiële correlatie en (multivariate) lineaire regessie?
Volgens mij is het in essentie hetzelfde
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Ja dat dacht ik dus ook alquote:
Volgens mij is het in essentie hetzelfde
Voor zover ik het weet, maar ik ben niet 100% zeker dus als je het echt wilt claimen zou ik het dubbelchecken, is de test hetzelfde, dus je p-waardes etc. zullen hetzelfde zijn, maar is de uitput iets anders. Iets van de B-s in de regressie zijn tov de hele variantie en de correlaties alleen tov de variantie tussen x1 en x2 of zo...quote:
[..]
Ja dat dacht ik dus ook al
Op dinsdag 1 november 2016 00:05 schreef JanCees het volgende:
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
De polls worden ook in 9 van de 10 gevallen gepeild met een meerderheid democraten. Soms zelf +10% _O-
Je had gelijk. De statistics professor zei ook model 7. Ik kan alleen Hayes (nog) niet gebruiken aangezien mijn mediator en dv een curvilineair effect is en schijnbaar slikt Hayes dat niet. Dus daar moet ik nog wat op vinden.quote:
[..]
Dat is je mediator. Model 5 test de moderator op de directe relatie waarvan jij zegt dat die niet bestaat dus dan kom je uit bij model 7.
Friettent dikke Willie, met Willie
Kun je dan geen log transformation doen van je variabelen?quote:
[..]
Je had gelijk. De statistics professor zei ook model 7. Ik kan alleen Hayes (nog) niet gebruiken aangezien mijn mediator en dv een curvilineair effect is en schijnbaar slikt Hayes dat niet. Dus daar moet ik nog wat op vinden.
Wat houdt dat precies in? Ik heb daar geen kaas van gegeten.quote:
[..]
Kun je dan geen log transformation doen van je variabelen?
Friettent dikke Willie, met Willie
Hallo allemaal,
Ik ben momenteel bezig met het analyseren van data voor mijn masterscriptie. Nu is er iets waar ik niet helemaal uit kom. Mijn plan is om een meervoudige regressie analyse uit te voeren. Hiervoor heb ik 3 controlevariabelen (leeftijd, geslacht, opleiding), 3 onafhankelijke variabelen (op interval niveau) en 1 afhankelijke variabele (ook op interval niveau). Leeftijd en opleiding zijn nu ordinale variabelen en daarom heb ik hiervan dummies gemaakt, zodat ik ze kan meenemen in de regressie. De klassen die het meest voorkomen beschouw ik als de referentie-variabele, deze dummy neem ik dus niet mee in de regressie.
Nu mijn vraag: ik heb een steekproef van 57 personen, waarvan 3 de controlevariabelen in de enquete niet hebben ingevuld. Nu vraag ik mij af hoe deze missing values worden meegenomen in de dummies. Zoals ik het nu zie corresponderen de missing values (die ik aangeef met een '9') met geen van de dummies en worden deze dus automatisch (en onjuist) gezien als behorende tot de referentie-variabele? Moet ik daarom nog een dummy aanmaken voor deze missing values?
Dan nog een andere vraag. Ik doe een hiërarchische regressie analyse omdat ik wil corrigeren voor de controlevariabelen. Dus ik doe de controlevariabelen in 1 blok, de 2 onafhankelijke variabelen van de theorie die ik wil testen in blok 2, en de laatste onafhankelijke variabele in blok 3. Maar kunnen alle dummie variabelen (dus van leeftijd en opleiding) wel samen in 1 blok worden toegevoegd?
Alvast heel erg bedankt voor het meedenken!
[ Bericht 15% gewijzigd door Bruinvis op 28-11-2015 12:45:27 ]
Ik ben momenteel bezig met het analyseren van data voor mijn masterscriptie. Nu is er iets waar ik niet helemaal uit kom. Mijn plan is om een meervoudige regressie analyse uit te voeren. Hiervoor heb ik 3 controlevariabelen (leeftijd, geslacht, opleiding), 3 onafhankelijke variabelen (op interval niveau) en 1 afhankelijke variabele (ook op interval niveau). Leeftijd en opleiding zijn nu ordinale variabelen en daarom heb ik hiervan dummies gemaakt, zodat ik ze kan meenemen in de regressie. De klassen die het meest voorkomen beschouw ik als de referentie-variabele, deze dummy neem ik dus niet mee in de regressie.
Nu mijn vraag: ik heb een steekproef van 57 personen, waarvan 3 de controlevariabelen in de enquete niet hebben ingevuld. Nu vraag ik mij af hoe deze missing values worden meegenomen in de dummies. Zoals ik het nu zie corresponderen de missing values (die ik aangeef met een '9') met geen van de dummies en worden deze dus automatisch (en onjuist) gezien als behorende tot de referentie-variabele? Moet ik daarom nog een dummy aanmaken voor deze missing values?
Dan nog een andere vraag. Ik doe een hiërarchische regressie analyse omdat ik wil corrigeren voor de controlevariabelen. Dus ik doe de controlevariabelen in 1 blok, de 2 onafhankelijke variabelen van de theorie die ik wil testen in blok 2, en de laatste onafhankelijke variabele in blok 3. Maar kunnen alle dummie variabelen (dus van leeftijd en opleiding) wel samen in 1 blok worden toegevoegd?
Alvast heel erg bedankt voor het meedenken!
[ Bericht 15% gewijzigd door Bruinvis op 28-11-2015 12:45:27 ]
Kun je die drie observaties er niet gewoon uit flikkeren? Scheelt een hoop gedoe.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ik weet niet uit hoeveel categorieën opleiding en leeftijd bestaan maar je moet dan wel even oppassen dat je niet in de problemen raakt met je degrees of freedom. Je hebt namelijk nogal weinig observeringen en voor elke onafhankelijke variabele heb je wel 5 waarnemingen nodig.quote:
Hallo allemaal,
Ik ben momenteel bezig met het analyseren van data voor mijn masterscriptie. Nu is er iets waar ik niet helemaal uit kom. Mijn plan is om een meervoudige regressie analyse uit te voeren. Hiervoor heb ik 3 controlevariabelen (leeftijd, geslacht, opleiding), 3 onafhankelijke variabelen (op interval niveau) en 1 afhankelijke variabele (ook op interval niveau). Leeftijd en opleiding zijn nu ordinale variabelen en daarom heb ik hiervan dummies gemaakt, zodat ik ze kan meenemen in de regressie. De klassen die het meest voorkomen beschouw ik als de referentie-variabele, deze dummy neem ik dus niet mee in de regressie.
Nu mijn vraag: ik heb een steekproef van 57 personen, waarvan 3 de controlevariabelen in de enquete niet hebben ingevuld. Nu vraag ik mij af hoe deze missing values worden meegenomen in de dummies. Zoals ik het nu zie corresponderen de missing values (die ik aangeef met een '9') met geen van de dummies en worden deze dus automatisch (en onjuist) gezien als behorende tot de referentie-variabele? Moet ik daarom nog een dummy aanmaken voor deze missing values?
Dan nog een andere vraag. Ik doe een hiërarchische regressie analyse omdat ik wil corrigeren voor de controlevariabelen. Dus ik doe de controlevariabelen in 1 blok, de 2 onafhankelijke variabelen van de theorie die ik wil testen in blok 2, en de laatste onafhankelijke variabele in blok 3. Maar kunnen alle dummie variabelen (dus van leeftijd en opleiding) wel samen in 1 blok worden toegevoegd?
Alvast heel erg bedankt voor het meedenken!
Ik heb ze er idd uitgegooid door te kiezen voor 'exclude cases listwise'. Bedankt voor je reactie!quote:
Kun je die drie observaties er niet gewoon uit flikkeren? Scheelt een hoop gedoe.
Ik heb er inderdaad vooraf niet bij stilgestaan dat ik dummy variabelen zou moeten gebruiken en dus een grotere steekproef nodig zou hebben, achteraf niet erg handig. Ik was simpelweg uitgegaan van een totaal van 6 onafhankelijke variabelen.quote:
[..]
Ik weet niet uit hoeveel categorieën opleiding en leeftijd bestaan maar je moet dan wel even oppassen dat je niet in de problemen raakt met je degrees of freedom. Je hebt namelijk nogal weinig observeringen en voor elke onafhankelijke variabele heb je wel 5 waarnemingen nodig.
De categorieën opleiding en leeftijd bestaan beide uit 4 categorieën dus ik heb daarvoor per variabele 3 dummies meegenomen in de regressie. Daarnaast heb ik dus nog 1 nominale controlevariabele (geslacht) en 3 onafhankelijke variabelen. Daarvoor zou ik dan minimaal 50 observaties nodig hebben toch?
Zou je anders aanraden leeftijd of opleiding bijvoorbeeld weg te laten uit de analyse?
Als jij in je theoretisch kader over deze variabelen geschreven hebt en ook hypotheses over hebt opgesteld dan is het zonde om dat er nu weer uit te slopen. Je kan twee dingen doen. Als je ruim in de tijd zit nog wat extra data verzamelen of verder gaan met deze data en daar bij de limitations een vermelding over schrijven.quote:
[..]
Ik heb er inderdaad vooraf niet bij stilgestaan dat ik dummy variabelen zou moeten gebruiken en dus een grotere steekproef nodig zou hebben, achteraf niet erg handig. Ik was simpelweg uitgegaan van een totaal van 6 onafhankelijke variabelen.
De categorieën opleiding en leeftijd bestaan beide uit 4 categorieën dus ik heb daarvoor per variabele 3 dummies meegenomen in de regressie. Daarnaast heb ik dus nog 1 nominale controlevariabele (geslacht) en 3 onafhankelijke variabelen. Daarvoor zou ik dan minimaal 50 observaties nodig hebben toch?
Zou je anders aanraden leeftijd of opleiding bijvoorbeeld weg te laten uit de analyse?
Ik zit helaas niet erg ruim in de tijd nee, dus dan ga ik voor de tweede optie! Bedankt nogmaals!quote:
[..]
Als jij in je theoretisch kader over deze variabelen geschreven hebt en ook hypotheses over hebt opgesteld dan is het zonde om dat er nu weer uit te slopen. Je kan twee dingen doen. Als je ruim in de tijd zit nog wat extra data verzamelen of verder gaan met deze data en daar bij de limitations een vermelding over schrijven.
Stel we hebben een stationair time-series waarvan we het aantal units van tijd in memory willen bepalen. Kijken we naar de partial of normale autocorrelatie?
Autocorrelatie met lagged dependent variable loopt in theorie oneindig door, dus het logische antwoord is partial.quote:
Stel we hebben een stationair time-series waarvan we het aantal units van tijd in memory willen bepalen. Kijken we naar de partial of normale autocorrelatie?

Verliezen op een gegeven moment significantie though.quote:Op woensdag 9 december 2015 14:33 schreef ibrkadabra het volgende:
[..]
Autocorrelatie met lagged dependent variable loopt in theorie oneindig door, dus het logische antwoord is partial.
Is dat juist ook niet wat je wil weten uiteindelijk? Bijvoorbeeld om te voorspellen hoeveel periodes ervoor nog een goede voorspeller is van je sales.quote:Op woensdag 9 december 2015 23:15 schreef Sokz het volgende:
[..]
Verliezen op een gegeven moment significantie though.Thanks beiden!
Ja, maar dat doe je dus met de pacf. Als je een AR(1) proces hebt, heeft t-2 ook nog een invloed op je huidige waarde, maar niet direct.quote:
[..]
Is dat juist ook niet wat je wil weten uiteindelijk? Bijvoorbeeld om te voorspellen hoeveel periodes ervoor nog een goede voorspeller is van je sales.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Klopt! :p Alleen als je een coefficient van 0.97 hebt bijv. voor je 1e lag (als we een AR(1) beschouwen), dan heb je pas bij lag 100 ofzo geen significantie meer als je de ACF gebruikt.quote:
[..]
Verliezen op een gegeven moment significantie though.
Beste allen,
Ik heb een vraag mbt SPSS. Ik wil opleidingsniveau categoriseren. Ik heb in mijn enquête gevraagd naar welke opleiding iemand gevolgd heeft en deze antwoordcategorieën gebruikt: Lagere school, VMBO, MBO, HAVO, VWO, HBO/WO. Nu wil ik deze categoriseren naar laagopgeleid, middelbaar opgeleid en hoogopgeleid volgens de theorie die ik gebruik. Dit is gelukt door 'recode into different variables'. Ik heb laagopgeleid een waarde van 10, middelbaar een waarde van 11 en hoogopgeleid een waarde van 12 gegeven. Wanneer ik nu een simpele correlatie uitvoer met een andere variabele, krijg ik resultaten.
Echter, ik wil graag deze 3 groepen scheiden, waardoor ik per groep kan kijken of het correleert ja of nee. Dit doe ik door 'split file' en dan 'organize output by groups'. Helaas krijg ik nu bij de correlatie alleen maar puntjes te zien (bij Kendall's Tau; overigens ook bij de andere, maar die heb ik niet nodig). Heeft iemand enig idee wat ik fout doe? Ik kom er echt niet uit en moet maandag scriptie inleveren
[ Bericht 1% gewijzigd door fetX op 19-12-2015 13:28:10 ]
Ik heb een vraag mbt SPSS. Ik wil opleidingsniveau categoriseren. Ik heb in mijn enquête gevraagd naar welke opleiding iemand gevolgd heeft en deze antwoordcategorieën gebruikt: Lagere school, VMBO, MBO, HAVO, VWO, HBO/WO. Nu wil ik deze categoriseren naar laagopgeleid, middelbaar opgeleid en hoogopgeleid volgens de theorie die ik gebruik. Dit is gelukt door 'recode into different variables'. Ik heb laagopgeleid een waarde van 10, middelbaar een waarde van 11 en hoogopgeleid een waarde van 12 gegeven. Wanneer ik nu een simpele correlatie uitvoer met een andere variabele, krijg ik resultaten.
Echter, ik wil graag deze 3 groepen scheiden, waardoor ik per groep kan kijken of het correleert ja of nee. Dit doe ik door 'split file' en dan 'organize output by groups'. Helaas krijg ik nu bij de correlatie alleen maar puntjes te zien (bij Kendall's Tau; overigens ook bij de andere, maar die heb ik niet nodig). Heeft iemand enig idee wat ik fout doe? Ik kom er echt niet uit en moet maandag scriptie inleveren
[ Bericht 1% gewijzigd door fetX op 19-12-2015 13:28:10 ]
Je bent sowieso al helemaal verkeerd bezig door een correlatiemaat te berekenen over een categorische variabele. Wiskundig gezien is het nog wel mogelijk om een correlatiemaat te berekenen aangezien je 2 variabelen hebt met verschillende waarden, maar inhoudelijk gezien is het onzinnig aangezien "Opleidingsniveau" niet van intervalniveau of hoger is... snappie? Dus dat is al fout #1.quote:
Beste allen,
Ik heb een vraag mbt SPSS. Ik wil opleidingsniveau categoriseren. Ik heb in mijn enquête gevraagd naar welke opleiding iemand gevolgd heeft en deze antwoordcategorieën gebruikt: Lagere school, VMBO, MBO, HAVO, VWO, HBO/WO. Nu wil ik deze categoriseren naar laagopgeleid, middelbaar opgeleid en hoogopgeleid volgens de theorie die ik gebruik. Dit is gelukt door 'recode into different variables'. Ik heb laagopgeleid een waarde van 10, middelbaar een waarde van 11 en hoogopgeleid een waarde van 12 gegeven. Wanneer ik nu een simpele correlatie uitvoer met een andere variabele, krijg ik resultaten.
Echter, ik wil graag deze 3 groepen scheiden, waardoor ik per groep kan kijken of het correleert ja of nee. Dit doe ik door 'split file' en dan 'organize output by groups'. Helaas krijg ik nu bij de correlatie alleen maar puntjes te zien (bij Kendall's Tau; overigens ook bij de andere, maar die heb ik niet nodig). Heeft iemand enig idee wat ik fout doe? Ik kom er echt niet uit en moet maandag scriptie inleveren
Fout #2 die je maakt is dat je, na het gebruiken van split file, je wederom een correlatiemaat probeert te berekenen tussen variabele "Opleidingsniveau" en de andere variabele, maar dan per groep van opleidingsniveau. Maar, alle mensen in één split-groep hebben natuurlijk dezelfde score op Opleidingsniveau. Dus nu is het uitrekenen van een correlatiemaat behalve onzinnig, ook nog eens wiskundig onmogelijk geworden.
Overigens vind ik het ook raar dat je de categorieën aanduid met waardes (10, 11, 12). Niet echt fout, maar wel ongebruikelijk. Waarom niet (1, 2, 3) of (0, 1, 2)?
Anyway, door het indelen van de mensen op opleidingsniveau kun je het zien als groepen, en daarom zou je dan categorische toetsen op kunnen uitvoeren (Chi-kwadraat, ANOVA)
Hopelijk helpt dit een beetje?

Ik kan me zo voorstellen dat fetX een tikkie teveel in de stress zit om te reply-en. Maar netjes is het niet inderdaad.
Opleiding laag-midden-hoog kan je wel als continue variabele zien toch?
Opleiding laag-midden-hoog kan je wel als continue variabele zien toch?
Aldus.
Kan ook zijn dat hij (zij) zijn (haar) probleem zelf al op had gelost heeft ondertussen of wegens een andere reden niet meer in dit topic heeft gekeken.quote:
Ik kan me zo voorstellen dat fetX een tikkie teveel in de stress zit om te reply-en. Maar netjes is het niet inderdaad.
Opleiding laag-midden-hoog kan je wel als continue variabele zien toch?
En opleidingsniveau kun je in dit geval niet zien als continue variabele. Je weet niet hoe groot de stapjes zijn tussen iedere categorie. Je weet hooguit dat er een ordening in zit, dus ordinaal meetniveau. Dit is niet genoeg om correlaties mee te berekenen.
de variabele "Aantal jaren opleiding genoten" zou daarentegen wel kunnen
Dan nog kun je even het fatsoen opbrengen om een reactie te plaatsen. Vooral als je opzichtig aan het klunzen bent.
Dan ben ik het niet met je eens, aangezien het m.i. gewoon fout is. Vooral gezien het feit dat je eerder al aangaf dat je een "laag-midden-hoog" variabele beschouwt als een continue variabele, wat ook gewoon fout is. Als je met zulke verkeerde assumpties statistiek gaat beoefenen, ga je toch echt de mist in!quote:
Je hebt een punt, maar ik vind het in sommige gevallen toch niet zo'n probleem.
Hi allemaal,
Na wat feedback van mijn begeleider ben ik mijn analyse (meervoudige regressieanalyse) aan het herschrijven. 1 van de punten die ze opnoemde was dat het verschil tussen de Adjusted R squares die ik heb gevonden, namelijk van .062 (model 1 met controlevariabelen) naar .805 (model 2 met vier onafhankelijke variabelen) aardig onmogelijk is. Na alles opnieuw ingevoerd te hebben kom ik op hetzelfde uit, en snap niet wat de oorzaak hiervan is.
Ik heb nu de variabelen los van elkaar in de regressieanalyse ingevoerd en ben erachter dat de hoge r square change het resultaat is van 2 onafhankelijke variabelen die best hoog met elkaar correleren (α= .645). Heeft iemand een idee wat de oorzaak van deze hoge r square change is en wat ik hieraan kan doen?
Alvast bedankt!
[ Bericht 1% gewijzigd door Bruinvis op 29-12-2015 13:09:43 ]
Na wat feedback van mijn begeleider ben ik mijn analyse (meervoudige regressieanalyse) aan het herschrijven. 1 van de punten die ze opnoemde was dat het verschil tussen de Adjusted R squares die ik heb gevonden, namelijk van .062 (model 1 met controlevariabelen) naar .805 (model 2 met vier onafhankelijke variabelen) aardig onmogelijk is. Na alles opnieuw ingevoerd te hebben kom ik op hetzelfde uit, en snap niet wat de oorzaak hiervan is.
Ik heb nu de variabelen los van elkaar in de regressieanalyse ingevoerd en ben erachter dat de hoge r square change het resultaat is van 2 onafhankelijke variabelen die best hoog met elkaar correleren (α= .645). Heeft iemand een idee wat de oorzaak van deze hoge r square change is en wat ik hieraan kan doen?
Alvast bedankt!
[ Bericht 1% gewijzigd door Bruinvis op 29-12-2015 13:09:43 ]
Klinkt inderdaad zoals Z al aangaf als het probleem van Multicollineariteit.quote:
Hi allemaal,
Na wat feedback van mijn begeleider ben ik mijn analyse (meervoudige regressieanalyse) aan het herschrijven. 1 van de punten die ze opnoemde was dat het verschil tussen de Adjusted R squares die ik heb gevonden, namelijk van .062 (model 1 met controlevariabelen) naar .805 (model 2 met vier onafhankelijke variabelen) aardig onmogelijk is. Na alles opnieuw ingevoerd te hebben kom ik op hetzelfde uit, en snap niet wat de oorzaak hiervan is.
Ik heb nu de variabelen los van elkaar in de regressieanalyse ingevoerd en ben erachter dat de hoge r square change het resultaat is van 2 onafhankelijke variabelen die best hoog met elkaar correleren (α= .645). Heeft iemand een idee wat de oorzaak van deze hoge r square change is en wat ik hieraan kan doen?
Alvast bedankt!
Kijk maar eens naar de formule van hoe de R-squared berekend wordt als je 2 voorspellende variabelen zou hebben:
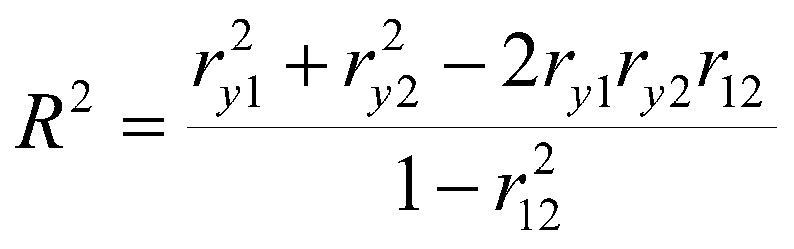
Deze formule generaliseert ook naar hogere dimensies (dus met 4 voorspellers is het hetzelfde idee). In de formule betekent de r(1,2) de correlatie tussen voorspellende variabele 1 en 2. Als deze correlatie heel klein is, of zelfs 0 (wat dus het geval is als ze onafhankelijk zijn van elkaar) vallen grote delen van de formule weg omdat deze 0 zijn. Maar als de r(1,2) groot is, dan gaat de R squared richting de 1 (en een R-squared van 1 is nooit een goed teken aangezien je data dan perfect voorspeld wordt en dat is niet de bedoeling)
Er zijn verschillende manieren om dit probleem te behandelen, afhankelijk van je kennis en vaardigheid met statistiek. Mensen die daar wat vaardiger in zijn zouden kunnen proberen of een vorm van penalized regression het probleem oplost (Ridge regression bv.) of ipv regressie een andere methode proberen als die past bij de dataset. Beginners zullen moeten proberen om de 2 variabelen die sterk met elkaar correleren, proberen samen te voegen. Eentje van de 2 gewoon niet meenemen is ook een optie, maar ja, dan gooi je dus een hoop informatie weg en ik kan me voorstellen dat het niet leuk is om een onderzoek op te stellen met 4 voorspellers en er vervolgens 1 niet kunnen gebruiken. Andere optie is om het gewoon zo te laten, maar ja dan moet je dus wel uitleggen dat de gevonden R-squared eigenlijk nergens meer op slaat, en waarom.
Bedankt voor jullie reacties! Mijn kennis van statistiek is basis dus ik heb geprobeerd de 2 variabelen samen te voegen, maar dat haalde helaas niks uit qua R-squared. Ik haal daarom toch maar 1 van de 2 variabelen uit de analyse. Idd jammer, maar dan slaat het in ieder geval nog ergens op (hoop ik).
Wat ik dan alleen nog niet begrijp is dat de adjusted r-squared nog steeds naar ,60 stijgt in model 2, terwijl ik geen tekens van multicollineariteit kan ontdekken (VIF waarden rond de 1.0 en onderlinge correlaties tussen de onafhankelijke variabelen zijn niet hoger dan .48).
Ik ben allang blij dat het de r-squared ,80 naar ,60 is gedaald maar toch lijkt dat me nog steeds erg hoog. Hebben jullie een idee of er nog een andere oorzaak kan zijn? Of is dit een acceptabele waarde?
Wat ik dan alleen nog niet begrijp is dat de adjusted r-squared nog steeds naar ,60 stijgt in model 2, terwijl ik geen tekens van multicollineariteit kan ontdekken (VIF waarden rond de 1.0 en onderlinge correlaties tussen de onafhankelijke variabelen zijn niet hoger dan .48).
Ik ben allang blij dat het de r-squared ,80 naar ,60 is gedaald maar toch lijkt dat me nog steeds erg hoog. Hebben jullie een idee of er nog een andere oorzaak kan zijn? Of is dit een acceptabele waarde?
Waarom denk je dat een hoge r-squared slecht is?quote:
Bedankt voor jullie reacties! Mijn kennis van statistiek is basis dus ik heb geprobeerd de 2 variabelen samen te voegen, maar dat haalde helaas niks uit qua R-squared. Ik haal daarom toch maar 1 van de 2 variabelen uit de analyse. Idd jammer, maar dan slaat het in ieder geval nog ergens op (hoop ik).
Wat ik dan alleen nog niet begrijp is dat de adjusted r-squared nog steeds naar ,60 stijgt in model 2, terwijl ik geen tekens van multicollineariteit kan ontdekken (VIF waarden rond de 1.0 en onderlinge correlaties tussen de onafhankelijke variabelen zijn niet hoger dan .48).
Ik ben allang blij dat het de r-squared ,80 naar ,60 is gedaald maar toch lijkt dat me nog steeds erg hoog. Hebben jullie een idee of er nog een andere oorzaak kan zijn? Of is dit een acceptabele waarde?
Wat is eigenlijk hoog?
Het centrale idee bij statistiek is dat al die cijfertjes niet een absoluut natuurkundig gegeven zijn die zomaar uit de lucht komen vallen... ze zijn het resultaat van formules waar weer allemaal andere cijfertjes ingestopt zijn, en die formules zijn ergens, op een gegeven moment, ook maar bedacht door iemand, die er voor koos om er een bepaalde interpretatie aan te geven.
Weet je wat een R-squared is en waar het voor staat?
Dan weet je ook of een R-squared van 0.6 of 0.8 (of wat dan ook) in jou geval hoog of laag is
Als ik het goed heb begrepen staat het percentage van R-squared voor de verklaring van de variantie in de afhankelijke variabele (in mijn geval is de afhankelijke variabele de motivatie om ergens aan mee te doen). Dus de variantie in die motivatie is in mijn geval voor 80 of 60% afhankelijk van de variabelen in mijn model.
Ik vind de r-squared van 0.8 vooral hoog in vergelijking met mijn eerste model, waar alleen de controlevariabelen in zitten en maar 0.06 verklaart. En als ik naar andere onderzoeken kijk, waar ik het mijne op gebaseerd heb, is 80% heel hoog. Maar waardoor het in mijn geval komt (buiten multicollineariteit), dat snap ik dan helaas weer net niet.
[ Bericht 0% gewijzigd door Bruinvis op 29-12-2015 20:49:52 ]
Ik vind de r-squared van 0.8 vooral hoog in vergelijking met mijn eerste model, waar alleen de controlevariabelen in zitten en maar 0.06 verklaart. En als ik naar andere onderzoeken kijk, waar ik het mijne op gebaseerd heb, is 80% heel hoog. Maar waardoor het in mijn geval komt (buiten multicollineariteit), dat snap ik dan helaas weer net niet.
[ Bericht 0% gewijzigd door Bruinvis op 29-12-2015 20:49:52 ]
Klopt.quote:
Als ik het goed heb begrepen staat het percentage van R-squared voor de verklaring van de variantie in de afhankelijke variabele (in mijn geval is de afhankelijke variabele de motivatie om ergens aan mee te doen). Dus de variantie in die motivatie is in mijn geval voor 80 of 60% afhankelijk van de variabelen in mijn model.
Ik vind de r-squared van 0.8 vooral hoog in vergelijking met mijn eerste model, waar alleen de controlevariabelen in zitten en maar 0.06 verklaart. En als ik naar andere onderzoeken kijk, waar ik het mijne op gebaseerd heb, is 80% heel hoog. Maar waardoor het in mijn geval komt (buiten multicollineariteit), dat snap ik dan helaas weer net niet.
En tja, zonder verder zelf de data te bekijken kan ik het verder ook niet beoordelen.
Het weglaten van een variabele maakt je model ook makkelijker te interpreteren niet? Dat is ook een winst.
Aldus.
Een Excelvraagje aangezien ik weinig ervaring heb met dit programma.
Weet iemand hoe je handig deze cijfers sorteert?
http://www.theguardian.co(...)dustry-atlas-smoking
Als je dat kopiëert en in Excel plaatst dan komt het keurig in kolommen te staan maar wanneer je sorteert (A-Z) dan zet Excel de integers bovenaan en de decemialen daaronder (met daar tussenin de streepjes maar dat doet er nu even niet toe). Ik heb geprobeerd om van al die cellen hetzelfde getalformat te maken maar Excel gebruikt dan hardnekkig een komma voor de integers terwijl het een punt blijft gebruiken voor de decimalen.
Het is vast zoiets wat heel erg simpel is maar waar je eventjes naar kan zoeken.
Weet iemand hoe je handig deze cijfers sorteert?
http://www.theguardian.co(...)dustry-atlas-smoking
Als je dat kopiëert en in Excel plaatst dan komt het keurig in kolommen te staan maar wanneer je sorteert (A-Z) dan zet Excel de integers bovenaan en de decemialen daaronder (met daar tussenin de streepjes maar dat doet er nu even niet toe). Ik heb geprobeerd om van al die cellen hetzelfde getalformat te maken maar Excel gebruikt dan hardnekkig een komma voor de integers terwijl het een punt blijft gebruiken voor de decimalen.
Het is vast zoiets wat heel erg simpel is maar waar je eventjes naar kan zoeken.
ING en ABN investeerden honderden miljoenen euro in DAPL.
#NoDAPL
#NoDAPL
Ik had het kunnen weten: Libreoffice kan het wel direct normaal sorteren.
Daarom een extra vraagje over Libre Office, wat is bij Libre Office het equivalent van "end-mode"? Bij Excel kan je direct naar de laatste regel in een kolom gaan door eerst op end te klikken (end-mode activeren) en vervolgens op de onderste pijl (stom toeval dat ik dat ontdekte doordat ik even wat uitprobeerde).
Daarom een extra vraagje over Libre Office, wat is bij Libre Office het equivalent van "end-mode"? Bij Excel kan je direct naar de laatste regel in een kolom gaan door eerst op end te klikken (end-mode activeren) en vervolgens op de onderste pijl (stom toeval dat ik dat ontdekte doordat ik even wat uitprobeerde).
ING en ABN investeerden honderden miljoenen euro in DAPL.
#NoDAPL
#NoDAPL
Dat met punten en komma's is een probleem van excel/libreoffice in combinatie met de taal van je OS. Naar beneden kun je met page down.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Typisch Microsoft.quote:
Dat met punten en komma's is een probleem van excel/libreoffice in combinatie met de taal van je OS. Naar beneden kun je met page down.
Bij Libre-office is het geen probleem, die kan daar wel mee omgaan en sorteert het keurig terwijl de input identiek is.
ING en ABN investeerden honderden miljoenen euro in DAPL.
#NoDAPL
#NoDAPL
Vertel Microsoft gewoon wat jij als decimaal scheidingsteken wil, en het komt helemaal goed. Excel neemt standaard de instelling van je OS over (afhankelijk van je taal/locatie). Je kan het ook handmatig aanpassen in Excel.quote:
[..]
Typisch Microsoft.
Bij Libre-office is het geen probleem, die kan daar wel mee omgaan en sorteert het keurig terwijl de input identiek is.
Volgens mij had ik met LibreOffice op Linux ook dat probleem een keer. Kwestie van even instellen en klaar is kees. Is dus niet iets van Microsoft.quote:
[..]
Vertel Microsoft gewoon wat jij als decimaal scheidingsteken wil, en het komt helemaal goed. Excel neemt standaard de instelling van je OS over (afhankelijk van je taal/locatie). Je kan het ook handmatig aanpassen in Excel.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ik heb er ook last van als ik csv'tjes inlees en het decimaal scheidingsteken van de ene op de andere dag verandert.quote:
[..]
Volgens mij had ik met LibreOffice op Linux ook dat probleem een keer. Kwestie van even instellen en klaar is kees. Is dus niet iets van Microsoft.
Ik wil voor een variabele uitgesplitst naar acht groepen per groep de sd uitrekenen. Dat is makkelijk. Maar ik wil dat ook uitrekenen voor de rest van de groepen. Dus:
Groep 1 en Groep 2 t/m Groep 8
Groep 2 en Groep 1 + Groep 3 t/m Groep 8
Groep 3 en Groep 1 + Groep 2 en Groep 4 t/m Groep 8
enzovoorts.
Is er in SPSS een type 'contrast' waar dat mee kan? Of een andere slimme oplossing? Er is volgens mijn geen contrast-type voor één groep ten opzichte van de rest.
Groep 1 en Groep 2 t/m Groep 8
Groep 2 en Groep 1 + Groep 3 t/m Groep 8
Groep 3 en Groep 1 + Groep 2 en Groep 4 t/m Groep 8
enzovoorts.
Is er in SPSS een type 'contrast' waar dat mee kan? Of een andere slimme oplossing? Er is volgens mijn geen contrast-type voor één groep ten opzichte van de rest.
Aldus.
Gewoon snel even zelf kolommen van de groepen maken in Excel.quote:
Ik wil voor een variabele uitgesplitst naar acht groepen per groep de sd uitrekenen. Dat is makkelijk. Maar ik wil dat ook uitrekenen voor de rest van de groepen. Dus:
Groep 1 en Groep 2 t/m Groep 8
Groep 2 en Groep 1 + Groep 3 t/m Groep 8
Groep 3 en Groep 1 + Groep 2 en Groep 4 t/m Groep 8
enzovoorts.
Is er in SPSS een type 'contrast' waar dat mee kan? Of een andere slimme oplossing? Er is volgens mijn geen contrast-type voor één groep ten opzichte van de rest.
Syntax schrijvenquote:
Hmja, het gaat helaas niet om 1 variabele maar om 128 ...

quote:
Wat is er pijnlijk aan het gebruiken van veel fijnere software waar je veel meer controle hebt over wat je doet?quote:
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ik ben gisteravond gestart met SmartPLS 2.0. Ik vraag me echter af of het nu waard is om SmartPLS 3.0 te proberen? Ik las dat je die ook per maand kan betalen voor 20$, ik ben benieuwd of er hier mensen die hier ook mee werken en het waard vinden, ik heb het programma voor ongeveer 9 maanden nodig.
”Maar als je verlangen naar de lekke band niet verhoord wordt, zit er niets anders op dan te lijden.” - De Renner
R heeft ook een package semPLS, geen idee hoe bedreven je in R bent maar dat is waarschijnlijk een mooi en gratis alternatief.quote:
Ik ben gisteravond gestart met SmartPLS 2.0. Ik vraag me echter af of het nu waard is om SmartPLS 3.0 te proberen? Ik las dat je die ook per maand kan betalen voor 20$, ik ben benieuwd of er hier mensen die hier ook mee werken en het waard vinden, ik heb het programma voor ongeveer 9 maanden nodig.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Nog helemaal niet bekend mee, ik ga het eens proberen! Ben geen doorgewinterde statisticus vandaar dat ik eerst even wat wil oriënteren. Dit is nu mijn tweede studie maar de eerste is van 8 jaar terug.quote:
[..]
R heeft ook een package semPLS, geen idee hoe bedreven je in R bent maar dat is waarschijnlijk een mooi en gratis alternatief.
”Maar als je verlangen naar de lekke band niet verhoord wordt, zit er niets anders op dan te lijden.” - De Renner
Wat studeer je nu en wat heb je gestudeerd?quote:
[..]
Nog helemaal niet bekend mee, ik ga het eens proberen! Ben geen doorgewinterde statisticus vandaar dat ik eerst even wat wil oriënteren. Dit is nu mijn tweede studie maar de eerste is van 8 jaar terug.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Eerder HBO Bedrijfseconomie en nu WO Bestuurskunde.quote:
[..]
Wat studeer je nu en wat heb je gestudeerd?
”Maar als je verlangen naar de lekke band niet verhoord wordt, zit er niets anders op dan te lijden.” - De Renner
In je hoeveelste jaar zit je? Lijkt me sterk dat je zulke softwarepaketten moet gebruiken, bij de meeste sociale wetenschappen kom je met SPSS overal wel.quote:
[..]
Eerder HBO Bedrijfseconomie en nu WO Bestuurskunde.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ben in mijn scriptie beland, heb op het HBO SPSS gebruikt, was een eigen keuze omdat ik het interessant vond. Nu kreeg ik smartPLS aangeraden door mijn begeleider en na het zien van wat Youtube filmpjes ziet dat er makkelijker uit dan SPSS.quote:
[..]
In je hoeveelste jaar zit je? Lijkt me sterk dat je zulke softwarepaketten moet gebruiken, bij de meeste sociale wetenschappen kom je met SPSS overal wel.
”Maar als je verlangen naar de lekke band niet verhoord wordt, zit er niets anders op dan te lijden.” - De Renner
Wat houdt het eigenlijk in als de intercept significant is?
| 1 2 3 4 5 6 7 | Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -7.671e+00 8.245e-01 -9.304 < 2e-16 *** Q2a_1 1.353e-03 1.998e-01 0.007 0.994598 Q2a_2 2.434e-02 1.732e-01 0.140 0.888274 Q2a_3 2.963e-02 1.918e-01 0.154 0.877243 Q2a_4 -4.119e-01 1.894e-01 -2.175 0.029611 * |
Aldus.
Dat als al je variabelen gelijk zijn aan 0, je y de waarde van de constante aanneemt met hoge significantie?quote:
Wat houdt het eigenlijk in als de intercept significant is?
[ code verwijderd ]
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Dat, als de waarde van de intercept in werkelijkheid 0 is, de kans om de geobserveerde waarde van de intercept (in dit geval -7.67) of een waarde die nog verder van 0 is verwijderd te observeren, heel erg klein is.quote:
Wat houdt het eigenlijk in als de intercept significant is?
[ code verwijderd ]
R^2 bedoel je?quote:
Ah, dank. Zegt het ook nog iets over het model?
Alleen als al je andere variabelen tegelijk een zinvolle 0 kunnen aannemen.quote:
Nee, dat de intercept 'ver' van 0 ligt en significant is.
Ik heb een vraagje of permutaties en combinatoriek;
Stel je hebt een vaas met daarin 8 ballen waarvan 5 zwart en 3 ballen wit. De ballen worden met teruglegging uit gehaald. Willekeurig worden er 3 ballen uitgehaald, hoe groot is de kans op 3 zwarte ballen? Nu weet ik alleen zo'n opgave te maken zonder teruglegging doormiddel van ncr te gebruiken.
Maar zodra er vragen kommen als '' hoe groot is de kans op minstens 1 bal'' dan weet ik niet hoe ik dit moet berekenen, en in het boek staat het niet
Wie o wie kan mij helpen?
Stel je hebt een vaas met daarin 8 ballen waarvan 5 zwart en 3 ballen wit. De ballen worden met teruglegging uit gehaald. Willekeurig worden er 3 ballen uitgehaald, hoe groot is de kans op 3 zwarte ballen? Nu weet ik alleen zo'n opgave te maken zonder teruglegging doormiddel van ncr te gebruiken.
Maar zodra er vragen kommen als '' hoe groot is de kans op minstens 1 bal'' dan weet ik niet hoe ik dit moet berekenen, en in het boek staat het niet
Wie o wie kan mij helpen?
Man is de baas, vrouw kent haar plaats.
(5/8)^3quote:
Ik heb een vraagje of permutaties en combinatoriek;
Stel je hebt een vaas met daarin 8 ballen waarvan 5 zwart en 3 ballen wit. De ballen worden met teruglegging uit gehaald. Willekeurig worden er 3 ballen uitgehaald, hoe groot is de kans op 3 zwarte ballen? Nu weet ik alleen zo'n opgave te maken zonder teruglegging doormiddel van ncr te gebruiken.
De kans op minstens 1 bal is afhankelijk van of je een bal pakt of niet.quote:Maar zodra er vragen kommen als '' hoe groot is de kans op minstens 1 bal'' dan weet ik niet hoe ik dit moet berekenen, en in het boek staat het niet
Wie o wie kan mij helpen?
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Ze pakken 3 willekeurige ballen. Hoe voer ik jou bewerking uit op een GR-machine?quote:
[..]
(5/8)^3
[..]
De kans op minstens 1 bal is afhankelijk van of je een bal pakt of niet.
Man is de baas, vrouw kent haar plaats.
Als je 3 willekeurige ballen pakt, is dat kans dat je minstens 1 bal pakt, gelijk aan 1.quote:
[..]
Ze pakken 3 willekeurige ballen. Hoe voer ik jou bewerking uit op een GR-machine?
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
En hoe doe jij die rekenkundige bewerking met GR?quote:Op maandag 18 januari 2016 20:18 schreef wimjongil het volgende:
[..]
Als je 3 willekeurige ballen pakt, is dat kans dat je minstens 1 bal pakt, gelijk aan 1.
Man is de baas, vrouw kent haar plaats.
Welke?quote:
[..]
En hoe doe jij die rekenkundige bewerking met GR?
Kijk nog eens naar wat je precies vraagt en wat je precies moet weten. Volgens mij heb je hier vergeten om de kleur van de bal te specificiëren namelijk.
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Deze opgave bijvoorbeeld.quote:
[..]
Welke?
Kijk nog eens naar wat je precies vraagt en wat je precies moet weten. Volgens mij heb je hier vergeten om de kleur van de bal te specificiëren namelijk.
De eerste kwam ik uit:

Excuus voor de slechte foto
5/8 tot de 3e macht. De tweede al niet meer 5 ncr 2 x 3 ncr 1/ 8 ncr 3. Ofwel; 30/56. Echter klopt dat antwoord niet. En hoe ik die derde opgave moet maken is mij helemaal een raadsel
Man is de baas, vrouw kent haar plaats.
Combinaties gebruiken kan alleen maar zonder teruglegging, dus bij vraag 5. 4 kan je alleen maar met kansen doen. :quote:
[..]
Deze opgave bijvoorbeeld.
5/8 tot de 3e macht. De tweede al niet meer 5 ncr 2 x 3 ncr 1/ 8 ncr 3. Ofwel; 30/56. Echter klopt dat antwoord niet. En hoe ik die derde opgave moet maken is mij helemaal een raadsel
A) (5/8)^3, maar dat wist je al
B) (5/8)^2*3/8= 75/512
C) kans op minstens 1 witte bal= 1- kans op 0 witte ballen= 1-(5/8)^3=387/512
Ok. Maar bij opgave 4 C kom ik er niet uit, ik kan alleen maar de NCR functie gebruiken op mijn GR en die is voor zonder teruglegging, hoe reken ik met teruglegging?quote:
[..]
Combinaties gebruiken kan alleen maar zonder teruglegging, dus bij vraag 5. 4 kan je alleen maar met kansen doen. :
A) (5/8)^3, maar dat wist je al
B) (5/8)^2*3/8= 75/512
C) kans op minstens 1 witte bal= 1- kans op 0 witte ballen= 1-(5/8)^3=387/512
Alvast bedankt
Man is de baas, vrouw kent haar plaats.
Je kent deze formule? P(X>=x)=1-P(X<x), X is het aantal witte ballen.quote:[..]
Ok. Maar bij opgave 4 C kom ik er niet uit, ik kan alleen maar de NCR functie gebruiken op mijn GR en die is voor zonder teruglegging, hoe reken ik met teruglegging?
Alvast bedankt
Dit geeft dus P(X>=1)= 1- P(X<1). Omdat dit een discrete stochast is, kan je ook schrijven:
1-P(X<1) <=> 1-P(x=0) => 1-(5/8)^3= 387/512
quote:
[..]
(5/8)^3
[..]
De kans op minstens 1 bal is afhankelijk van of je een bal pakt of niet.
Nee, uitgeschreven staat er (5/8)*(5/8)*(3/8), het maakt Vandale niet uit in welke volgorde je het plaatstquote:[..]
Keer 3 toch omdat het niet uitmaakt in welke beurt je de zwarte pakt
Hoezoquote:
Oke, stel jij hebt gelijk, laten we het eens uitschrijven:
Beurt 1 Beurt 2 Beurt 3
zwarte witte zwarte = (5/8)*(3/8)*(5/8)=75/512
witte zwarte zwarte = (3/8)*(5/8)*(5/8)=75/512
zwarte zwarte witte = (5/8)*(5/8)*(3/8)=75/512
Hij heeft gelijk. Je moet die drie kansen bij elkaar optellen.quote:
[..]
Hoezo
Oke, stel jij hebt gelijk, laten we het eens uitschrijven:
Beurt 1 Beurt 2 Beurt 3
zwarte witte zwarte = (5/8)*(3/8)*(5/8)=75/512
witte zwarte zwarte = (3/8)*(5/8)*(5/8)=75/512
zwarte zwarte witte = (5/8)*(5/8)*(3/8)=75/512
Op dinsdag 23 november 2010 02:22 schreef Braddie het volgende:
Haal van internet af man.
Haal van internet af man.
Och ja natuurlijk, stom , Sorry Anoonumos, T is laat in de avond, vergeef me. Ik vraag me af hoe ik hier ooit een 7 voor heb kunnen halen, als ik nu al stomme foutjes zit te maken.
Ik was eigenlijk helemaal vergeten dat ik deze post hier had geplaatst (kom hier ook niet zo vaak), vandaar deze erg late reactie. Ik wil je graag bedanken voor de moeite en excuus aanbieden voor het feit dat enige reactie van mijn kant zo lang is uitgebleven.quote:
[..]
Je bent sowieso al helemaal verkeerd bezig door een correlatiemaat te berekenen over een categorische variabele. Wiskundig gezien is het nog wel mogelijk om een correlatiemaat te berekenen aangezien je 2 variabelen hebt met verschillende waarden, maar inhoudelijk gezien is het onzinnig aangezien "Opleidingsniveau" niet van intervalniveau of hoger is... snappie? Dus dat is al fout #1.
Fout #2 die je maakt is dat je, na het gebruiken van split file, je wederom een correlatiemaat probeert te berekenen tussen variabele "Opleidingsniveau" en de andere variabele, maar dan per groep van opleidingsniveau. Maar, alle mensen in één split-groep hebben natuurlijk dezelfde score op Opleidingsniveau. Dus nu is het uitrekenen van een correlatiemaat behalve onzinnig, ook nog eens wiskundig onmogelijk geworden.
Overigens vind ik het ook raar dat je de categorieën aanduid met waardes (10, 11, 12). Niet echt fout, maar wel ongebruikelijk. Waarom niet (1, 2, 3) of (0, 1, 2)?
Anyway, door het indelen van de mensen op opleidingsniveau kun je het zien als groepen, en daarom zou je dan categorische toetsen op kunnen uitvoeren (Chi-kwadraat, ANOVA)
Hopelijk helpt dit een beetje?
Uiteindelijk heb ik de conceptversie van mijn scriptie ingeleverd met een correlatie en dit werd niet fout gerekend. De correlatiemaat die ik heb gebruikt is Kendall's Tau en volgens Field kan je die gewoon gebruiken wanneer je minimaal een ordinale variabele (ook wel 'categorale variabelen' genoemd) hebt gebruikt. Het lijkt mij dat 'Opleidingsniveau' in dit geval een ordinale variabele is (laagopgeleid, middelbaar opgeleid en hoog opgeleid?). Deze zijn samengevoegd nadat ik mijn respondenten hun hoogst genoten opleiding had gevraagd (HAVO, VWO, WO, HBO etc.) Of zie ik dit nu nog verkeerd? Dan zou het vreemd zijn, aangezien de conceptversie positief is ontvangen.
Ik ben nu aan de slag met een ANOVA voor mijn definitieve versie. Dat was mij inderdaad aangeraden, aangezien ze vonden dat ik me er met een correlatie iets te makkelijk vanaf had gemaakt (maar niet fout). Echter, volgens mij kan ik die niet uivoeren daar mijn data niet voldoet aan de aannames. Hier ga ik deze week verder mee aan de slag.
Nogmaals excuses voor de late reactie van mijn kant.
Als je data niet aan de assumpties van een ANOVA voldoet, kun je nog best veel proberen om dat te fixen.quote:
[..]
Ik was eigenlijk helemaal vergeten dat ik deze post hier had geplaatst (kom hier ook niet zo vaak), vandaar deze erg late reactie. Ik wil je graag bedanken voor de moeite en excuus aanbieden voor het feit dat enige reactie van mijn kant zo lang is uitgebleven.
Uiteindelijk heb ik de conceptversie van mijn scriptie ingeleverd met een correlatie en dit werd niet fout gerekend. De correlatiemaat die ik heb gebruikt is Kendall's Tau en volgens Field kan je die gewoon gebruiken wanneer je minimaal een ordinale variabele (ook wel 'categorale variabelen' genoemd) hebt gebruikt. Het lijkt mij dat 'Opleidingsniveau' in dit geval een ordinale variabele is (laagopgeleid, middelbaar opgeleid en hoog opgeleid?). Deze zijn samengevoegd nadat ik mijn respondenten hun hoogst genoten opleiding had gevraagd (HAVO, VWO, WO, HBO etc.) Of zie ik dit nu nog verkeerd? Dan zou het vreemd zijn, aangezien de conceptversie positief is ontvangen.
Ik ben nu aan de slag met een ANOVA voor mijn definitieve versie. Dat was mij inderdaad aangeraden, aangezien ze vonden dat ik me er met een correlatie iets te makkelijk vanaf had gemaakt (maar niet fout). Echter, volgens mij kan ik die niet uivoeren daar mijn data niet voldoet aan de aannames. Hier ga ik deze week verder mee aan de slag.
Nogmaals excuses voor de late reactie van mijn kant.
Your opinion of me is none of my business.
Ik denk dat het vooral belangrijk is dat fetX snapt wat hij aan het doen is en ook opschrijft waarom hij iets doet, niet zozeer wat nou de uitkomsten van z'n onderzoek zijn. Daar kun je punten mee scoren.
Persoonlijk alvast even een vraagje... Iemand hier ervaring met IRT en/of factoranalyse in R die ik een DMmetje mag doen als ik hier binnenkort een vraag over heb?
Your opinion of me is none of my business.
Natuurlijk, maar iets uitzoeken en vanaf niks beginnen is gewoon bar moeilijk als je er zelf geen of weinig verstand van hebt. En heel eerlijk, ik verwacht niet dat iemand die een correlatie als analyse gebruikt voor z'n scriptie echt torenhoge statistische of methodologische ambities heeft.quote:
Ik denk dat het vooral belangrijk is dat fetX snapt wat hij aan het doen is en ook opschrijft waarom hij iets doet, niet zozeer wat nou de uitkomsten van z'n onderzoek zijn. Daar kun je punten mee scoren.
Your opinion of me is none of my business.
Klopt, wel een slechte opleiding dan die fetX volgt. Verlangen dat statistische toetsen worden uitgevoerd die niet door de student worden gesnapt.quote:
[..]
Natuurlijk, maar iets uitzoeken en vanaf niks beginnen is gewoon bar moeilijk als je er zelf geen of weinig verstand van hebt. En heel eerlijk, ik verwacht niet dat iemand die een correlatie als analyse gebruikt voor z'n scriptie echt torenhoge statistische of methodologische ambities heeft.
Ik had volgens mij al gelezen dat je niet dol bent op SPSS maar Factoranalyse kun je toch heel makkelijk uitvoeren met dat programma?quote:
Persoonlijk alvast even een vraagje... Iemand hier ervaring met IRT en/of factoranalyse in R die ik een DMmetje mag doen als ik hier binnenkort een vraag over heb?
Dank voor je reactie!quote:
[..]
Als je data niet aan de assumpties van een ANOVA voldoet, kun je nog best veel proberen om dat te fixen.
Opleidingsniveau is nu een dummy variabele en mijn afhankelijke variabele is interval-niveau.
Het enige puntje is dat binnen 'Opleidingsniveau' ik (helaas) maar 18 mensen in mijn dataset heb die middelbaar zijn opgeleid (tegenover 60 laagopgeleid en 100 hoogopgeleid). Ik kan in Field echter niet vinden of dit nu een probleem is of niet. Wanneer dit geen probleem is, voldoet mijn data aan de aannames.
@MCH: Toegegeven, ik ben niet iemand die statistiek kan dromen, maar ik begrijp het wel degelijk. Heb statistiek vorig jaar met een acht afgesloten, dus ik denk niet dat je kan zeggen dat ik niets van statistiek snap. Daarnaast is mijn kwantitatieve (concept)scriptie op de Universiteit gewoon goed ontvangen, dus het is niet zo dat ik alleen maar onzin opschrijf.
Wat mij werd aangeraden is dat ik nog een ANOVA erbij zou kunnen doen, om meer uit mijn data te halen. En daar ben ik het mee eens. Helaas heb ik daar niet eerder aan gedacht. Bovendien begrijp ik prima wat voor informatie je uit een ANOVA kan halen (dwz: de interpretatie ervan). Ik zit alleen altijd te kloten met die aannames. Veel mensen vinden Field een fijn boek. Ik denk daar iets anders over. Ik vind het nogal een rommelig boek. Ik heb een jaar geleden statistiek gehad, en zodoende moet ik altijd terugkijken aan welke aannames/voorwaarden een toets precies moet voldoen.
Vind ik wel wat een heerlijk programma is het.quote:
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
3 variablen:quote:
Opleidingsniveau is nu een dummy variabele
LAAG: 1/0
MIDDEL: 1/0
HOOG: 1/0
?
Met je 18 middel zou je er misschien ook voor kunnen kiezen deze te onder te brengen bij een ander, bijv
LAAG-MIDDEL: 1/0, 78 observaties
HOOG: 100 observaties
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Klopt.quote:
[..]
3 variablen:
LAAG: 1/0
MIDDEL: 1/0
HOOG: 1/0
?
Met je 18 middel zou je er misschien ook voor kunnen kiezen deze te onder te brengen bij een ander, bijv
LAAG-MIDDEL: 1/0, 78 observaties
HOOG: 100 observaties
Dat zou inderdaad kunnen, alleen kom ik dan in de problemen met de theorie die ik heb gebruikt
In studies zie ik eigenlijk altijd het aantal studiejaren staan, niet een BSc/MSc.. kan je niet het volgende doen om een enkele variabele te creeren?
VMBO: 4 (jaar)
MBO: 7 (VMBO+3)
HAVO: 5
HBO: 9 (HAVO+4)
VWO: 6
WO: 10 (VWO + 4)
VMBO: 4 (jaar)
MBO: 7 (VMBO+3)
HAVO: 5
HBO: 9 (HAVO+4)
VWO: 6
WO: 10 (VWO + 4)
I am a Chinese college students, I have a loving father, but I can not help him, he needs to do heart bypass surgery, I can not help him, because the cost of 100,000 or so needed, please help me, lifelong You pray Thank you!
Dat rammelt natuurlijk aan alle kanten.quote:
In studies zie ik eigenlijk altijd het aantal studiejaren staan, niet een BSc/MSc.. kan je niet het volgende doen om een enkele variabele te creeren?
VMBO: 4 (jaar)
MBO: 7 (VMBO+3)
HAVO: 5
HBO: 9 (HAVO+4)
VWO: 6
WO: 10 (VWO + 4)
| Forum Opties | |
|---|---|
| Forumhop: | |
| Hop naar: | |