W&T Wetenschap & Technologie
Een plek om te discussiëren over wetenschappelijke onderwerpen, wetenschappelijke problemen, technologische projecten en grootse uitvindingen.



Als je telkens een plaatje liet genereren door gewoon elke pixel een random kleur te geven, zou er toch ooit een foto uit moeten komen? Alle mogelijkheden bestaan, dus in principe zou je ook ooit een keer een "foto" van je tegenkomen waarbij je met een groene t-shirt op een walvis staat, samen met tweelingzussen en twee zonnen aan de hemel?
De mogelijkheden lijken wel eindeloos, maar de kans is denk ik klein dat er een "foto" uit komt. Als op een gegeven moment pc's snel genoeg zijn, kunnen we dan realistische beelden uit de massa plaatjes filteren? Bijvoorbeeld in combinatie met gezichts-herkennings algoritmes, waarbij elk random plaatje waar "iemand" op staat eruit wordt gefilterd?
Ik ben zeer benieuwd wat ons te wachten staat!!
De mogelijkheden lijken wel eindeloos, maar de kans is denk ik klein dat er een "foto" uit komt. Als op een gegeven moment pc's snel genoeg zijn, kunnen we dan realistische beelden uit de massa plaatjes filteren? Bijvoorbeeld in combinatie met gezichts-herkennings algoritmes, waarbij elk random plaatje waar "iemand" op staat eruit wordt gefilterd?
Ik ben zeer benieuwd wat ons te wachten staat!!
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Bedankt voor de positieve feedback! 
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Ik denk dat dit idee wel om hele snelle computers zou vragen, de kans dat je random zo'n plaatje genereert in een mensenleven lijkt mij op dit moment onwaarschijnlijk klein.
"No, I do not believe in patents. I believe that patents make other people dis-incentied in coming up with new thing" - Thomas Peterffy
Stel, je legt een puzzle die qua maat exact in de doos past, in losse delen in die doos.
Hoe lang je ook schud, het gaat nooit een compleet in elkaar gelegde puzzel worden.
Hoe lang je ook schud, het gaat nooit een compleet in elkaar gelegde puzzel worden.
Dat is niet waar. Als je lang genoeg schudt, valt de puzzel uiteindelijk compleet in elkaar.quote:Op woensdag 5 maart 2014 08:21 schreef DrDarwin het volgende:
Stel, je legt een puzzle die qua maat exact in de doos past, in losse delen in die doos.
Hoe lang je ook schud, het gaat nooit een compleet in elkaar gelegde puzzel worden.
Op maandag 15 mei 2023 18:39
Wellicht arrogant, maar ik weet 100% zeker dat ik meer weet van de Amerikaanse geschiedenis, vooral die van de Zuidelijke staten, dan alle fokkers bij elkaar. Durf ik mijn hand wel voor in het vuur te steken.
Wellicht arrogant, maar ik weet 100% zeker dat ik meer weet van de Amerikaanse geschiedenis, vooral die van de Zuidelijke staten, dan alle fokkers bij elkaar. Durf ik mijn hand wel voor in het vuur te steken.
Als ik waterstof, koolstof, stikstof, zuurstof, ijzer, etc, etc, etc, alle elementen waaruit een mens bestaat, in een doos stop, en ik schud lang genoeg, dan komt er een moment waarop er een complete drDarwin uit de doos stap.
Als ik maar lang genoeg schud.
Als ik maar lang genoeg schud.
Op maandag 15 mei 2023 18:39
Wellicht arrogant, maar ik weet 100% zeker dat ik meer weet van de Amerikaanse geschiedenis, vooral die van de Zuidelijke staten, dan alle fokkers bij elkaar. Durf ik mijn hand wel voor in het vuur te steken.
Wellicht arrogant, maar ik weet 100% zeker dat ik meer weet van de Amerikaanse geschiedenis, vooral die van de Zuidelijke staten, dan alle fokkers bij elkaar. Durf ik mijn hand wel voor in het vuur te steken.
Nee, die puzzel krijg je op die manier nooit compleet in elkaar.quote:
[..]
Dat is niet waar. Als je lang genoeg schudt, valt de puzzel uiteindelijk compleet in elkaar.
Door het schudden vervalt de puzzel echter tot gruis.
Als je een plaatje zou genereren van 10 bij 10 pixels met slechts 16 mogelijke kleuren is de kans dat je precies het plaatje genereert dat je wilt 1/16 tot de macht 100 (10x10 pixels)
Dat is een kans van 1 op 2,85 * 10^120. Kan je nagaan als je een fatsoenlijk formaat en meer kleuren mogelijkheden hebt. Dus nee, er zal praktisch nooit een foto uitkomen.
Dat is een kans van 1 op 2,85 * 10^120. Kan je nagaan als je een fatsoenlijk formaat en meer kleuren mogelijkheden hebt. Dus nee, er zal praktisch nooit een foto uitkomen.

Welk script, is volgens mij niet gegeven in dit topic?quote:Op woensdag 5 maart 2014 09:44 schreef Opa.Bakkebaard het volgende:
Leuk script en leuk topic dit. Na een paar keer proberen kreeg ik al dit:
Ik kan me eerlijk gezegd niet voorstellen dat dit plaatje volledig random is samengesteld, precies die lichtovergangen zijn bijzonder onwaarschijnlijk.

Toch is het echt zo. Het script is gegeven in het vorige topic: W&T / Random plaatjes generen totdat je fotos krijgtquote:
[..]
Welk script, is volgens mij niet gegeven in dit topic?
Ik kan me eerlijk gezegd niet voorstellen dat dit plaatje volledig random is samengesteld, precies die lichtovergangen zijn bijzonder onwaarschijnlijk.
Ik zie nu dat er meerdere versies zijn maar de versie waar ik naar link heb ik gebruikt.
Oh dit is een vervolg topic, sorry, niet gezien.
Maar dit plaatje is dus niet volledig random elke pixel een kleur geven, maar een aantal voorwaarden die randomized worden. Dat is wel wat anders.
Maar dit plaatje is dus niet volledig random elke pixel een kleur geven, maar een aantal voorwaarden die randomized worden. Dat is wel wat anders.
quote:
Leuk script en leuk topic dit. Na een paar keer proberen kreeg ik al dit:
[ afbeelding ]
Een soort disco eend.

No citizen has a right to be an amateur in the matter of physical training...what a disgrace it is for a man to grow old without ever seeing the beauty and strength of which his body is capable.
Gaaf!quote:
Leuk script en leuk topic dit. Na een paar keer proberen kreeg ik al dit:
[ afbeelding ]
Een soort disco eend.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Ik genereer in principe lichtgolven die een andere richting op gaan en een andere vorm/frequentie hebben. Beetje zoals licht uit de natuur de camera in valt. Als je dat niet doet heb je één en al gruis. Om iets uit het niets te maken heb je toch de basis nodig: energie golven. Je beeldscherm is het oog waar het licht in valt.quote:
Oh dit is een vervolg topic, sorry, niet gezien.
Maar dit plaatje is dus niet volledig random elke pixel een kleur geven, maar een aantal voorwaarden die randomized worden. Dat is wel wat anders.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.


Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
quote:
Leuk script en leuk topic dit. Na een paar keer proberen kreeg ik al dit:
[ afbeelding ]
Een soort disco eend.

"The only real valuable thing is intuition. The intellect has little to do on the road to discovery."






Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Ik zie een neger dat gemolesteerd wordt door een 'alien', een grey (of gray?) om exact te zijn. Klopt dat?
^DITquote:
Als je een plaatje zou genereren van 10 bij 10 pixels met slechts 16 mogelijke kleuren is de kans dat je precies het plaatje genereert dat je wilt 1/16 tot de macht 100 (10x10 pixels)
Dat is een kans van 1 op 2,85 * 10^120. Kan je nagaan als je een fatsoenlijk formaat en meer kleuren mogelijkheden hebt. Dus nee, er zal praktisch nooit een foto uitkomen.
Om te benadrukken hoe klein deze kansen zijn:
Er zitten ongeveer 10^80 atomen in ons hele universum.
Er zijn misschien eindeloos veel kansen maar je bent ook bijna een eindeloze periode bezig om dit te genereren, maakt niet uit hoe snel je computers zijn.
Maar gelukkig is het doel niet het genereren van het logo van Ajax, of de eerste foto vanaf de maan of zo. Het doel is een afbeelding met genoeg herkenbare elementen. Daar zijn er an sich al miljoenen en miljoenen van. Komt nog bij dat er ook duizenden varianten van elke afbeelding zijn die we niet of nauwelijks van elkaar kunnen onderscheiden met het blote oog. Je doet in je berekening net alsof er maar één foto bestaat.quote:
Als je een plaatje zou genereren van 10 bij 10 pixels met slechts 16 mogelijke kleuren is de kans dat je precies het plaatje genereert dat je wilt 1/16 tot de macht 100 (10x10 pixels)
Dat is een kans van 1 op 2,85 * 10^120. Kan je nagaan als je een fatsoenlijk formaat en meer kleuren mogelijkheden hebt. Dus nee, er zal praktisch nooit een foto uitkomen.

Het herkennen van beelden ligt vast in de schaduwzone van de hersenen. Pak maar een papier en een pen en ga gewoon lijnen trekken. Op den duur zul je er ''iets'' in zien. Maar valt een lijn niet binnen de marges van de schaduw zal de mens het niet erkennen.quote:
[..]
Maar gelukkig is het doel niet het genereren van het logo van Ajax, of de eerste foto vanaf de maan of zo. Het doel is een afbeelding met genoeg herkenbare elementen. Daar zijn er an sich al miljoenen en miljoenen van. Komt nog bij dat er ook duizenden varianten van elke afbeelding zijn die we niet of nauwelijks van elkaar kunnen onderscheiden met het blote oog. Je doet in je berekening net alsof er maar één foto bestaat.
Met pixels tot de macht onnozel is de kans extreem klein dat er daadwerkelijk iets zichtbaar wordt dat iedereen als hetzelfde iets zal herkennen.
Staat tegenover dat extreem klein niet gelijk is aan onmogelijk.
http://steam-cards.com/?click=a07a01
voor gratis spellen
voor gratis spellen
Dat ben ik simpelweg niet met je eens. Je redeneert weer naar één oplossing toe (namelijk een losse lijn die blijkbaar een herkenbare tekening moet maken) in plaats van alles te beschouwen. Om er maar eens wat bij te pakken:quote:
[..]
Het herkennen van beelden ligt vast in de schaduwzone van de hersenen. Pak maar een papier en een pen en ga gewoon lijnen trekken. Op den duur zul je er ''iets'' in zien. Maar valt een lijn niet binnen de marges van de schaduw zal de mens het niet erkennen.
Met pixels tot de macht onnozel is de kans extreem klein dat er daadwerkelijk iets zichtbaar wordt dat iedereen als hetzelfde iets zal herkennen.


Toegegeven, het is geen Staatsieportret van onze nieuwe Koning, maar het is opmerkelijk hoe snel een afbeelding redelijk herkenbaar wordt. Er hoeft geen perfecte replica van Van Gogh's Zonnebloemen uit te rollen voor dit topic een succes wordt. En volgens mij zitten we al relatief dicht bij iets wat de meeste mensen wel als een beest zouden herkennen.
Ik zeg trouwens doodleuk 'we', maar ik heb verder geen plaatjes gemaakt. TS is de grote baas.
Ook datquote:Staat tegenover dat extreem klein niet gelijk is aan onmogelijk.
De berekening is inderdaad gebaseerd op het precies verkrijgen van één plaatje dat je wilt. Ik bedoelde het ook meer als indicatie van de ongeloofelijke hoeveelheid mogelijkheden die al bestaan bij een heel klein plaatje met maar 16 kleuren. Er zullen ongetwijfeld een heleboel van die mogelijkheden zijn die iets herkenbaars opleveren, maar zeker niet zoveel dat dat een impact heeft op het aantal mogelijkheden. Met grotere plaatjes wordt het aantal mogelijkheden ook nog in rap tempo groter.quote:
[..]
Maar gelukkig is het doel niet het genereren van het logo van Ajax, of de eerste foto vanaf de maan of zo. Het doel is een afbeelding met genoeg herkenbare elementen. Daar zijn er an sich al miljoenen en miljoenen van. Komt nog bij dat er ook duizenden varianten van elke afbeelding zijn die we niet of nauwelijks van elkaar kunnen onderscheiden met het blote oog. Je doet in je berekening net alsof er maar één foto bestaat.
Terwijl jullie hier bezig waren met discussiëren ben ik een enorme stap dichterbij gekomen bij fotorealisme  Ik heb energie golven die meer dan 100% waren terug geduwd naar 100% en de sub golven kleiner gemaakt. Het gevolg is dat verkeerde overbelichting verwijderd is en veel meer detail. Het is bijna eng. Vanavond de screenshots!!!!!
Ik heb energie golven die meer dan 100% waren terug geduwd naar 100% en de sub golven kleiner gemaakt. Het gevolg is dat verkeerde overbelichting verwijderd is en veel meer detail. Het is bijna eng. Vanavond de screenshots!!!!!
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Sommige stukken vandaag zijn al niet van echt te onderscheiden...
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Ja zien danquote:
Sommige stukken vandaag zijn al niet van echt te onderscheiden...
Leuk! Blijft erg interessant. Mogen wij vanavond ook spelen met die nieuwe code of hou je dat liever voor jezelf?
Kan het straks posten! Alles om ons heen is denk ik ook gewoon een expressie van een energie golf. Beetje snaar theorie achtig maar dan op alle schalen bij elkaar. Eigenlijk wel logisch. Zo krijg je complexiteit uit niets op alle niveaus. Het heelal zijn de golven/snaren van het niveau erboven. Jij bent niet alleen de bomen om je heen, jij bent ook de bacterie dat aan de andere kant van de aarde zit want het zijn dezelfde golvenquote:
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Niet te hard van stapel lopen jij.quote:Op dinsdag 11 maart 2014 17:49 schreef firefly3 het volgende:
[..]
Kan het straks posten! Alles om ons heen is denk ik ook gewoon een expressie van een energie golf. Beetje snaar theorie achtig maar dan op alle schalen bij elkaar. Eigenlijk wel logisch. Zo krijg je complexiteit uit niets op alle niveaus. Het heelal zijn de golven/snaren van het niveau erboven. Jij bent niet alleen de bomen om je heen, jij bent ook de bacterie dat aan de andere kant van de aarde zit want het zijn dezelfde golvenwie weet
Naja ik ben ook al een aantal jaren bezig geweest met knutselen met cellular automatons enz, complexiteit dat ontstaat uit simpele basis regels. Het probleem ermee was altijd schaal, hoe je de gevormde complexiteit kunt gebruiken als input voor een hoger niveau van complexiteit. Energie golven overbruggen het probleem van schaal, het is geen aparte laag maar het zit overal.quote:
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.



Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Ik hou het momenteel liever voor mezelfquote:
Leuk! Blijft erg interessant. Mogen wij vanavond ook spelen met die nieuwe code of hou je dat liever voor jezelf?
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Sorry als ik je teleurstel, maar deze zijn niet wezenlijk anders dan wat er in het vorige topic al stond.quote:
[ afbeelding ]
[ afbeelding ]
[ afbeelding ]
Er is veel meer detail en het is veel scherperquote:
[..]
Sorry als ik je teleurstel, maar deze zijn niet wezenlijk anders dan wat er in het vorige topic al stond.
Dit soort patronen vind je nergens terug hoor:

Of deze scherpte

Er wordt denk ik teveel naar het totaal plaatje gekeken of het herkenbaar is in plaats van de specifieke gebieden die eruit springen met iets herkenbaars. Scherpte etc schept mogelijkheden.
[ Bericht 9% gewijzigd door firefly3 op 11-03-2014 19:33:24 ]
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Een nieuwe fout ontdekt sinds gisteren, we zien slechts 1/200ste van wat er eigenlijk is. Ik hoop het nu verder uit te kunnen werken.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
We zien nu 1/200ste van wat er daadwerkelijk gegenereerd wordt?quote:
Een nieuwe fout ontdekt sinds gisteren, we zien slechts 1/200ste van wat er eigenlijk is. Ik hoop het nu verder uit te kunnen werken.
Sommige plaatjes worden al aardig creapy trouwens, die laatste lijkt op een soort van gemuteerde baby oid.
No citizen has a right to be an amateur in the matter of physical training...what a disgrace it is for a man to grow old without ever seeing the beauty and strength of which his body is capable.
Ja, ik probeer de rest ook zichtbaar te maken.quote:
[..]
We zien nu 1/200ste van wat er daadwerkelijk gegenereerd wordt?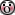
Sommige plaatjes worden al aardig creapy trouwens, die laatste lijkt op een soort van gemuteerde baby oid.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.


Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
quote:
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.


[ Bericht 34% gewijzigd door firefly3 op 01-04-2014 12:45:41 ]
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Ik heb ideeen om alles om te zetten naar een echt licht spectrum. Het gaat super veel werk worden maar het gaat spannend worden wat we te zien zullen krijgen. Ik zit nu met drie banden te spelen, vergelijkbaar met drie spotlights van rood, groen en blauw die af en toe overlappen. Hoe zou het zijn als ik niet drie golflengtes heb, maar honderden die allemaal hun eigen tint hebben? Hoe hoog zal de detail dan niet zijn?!!
Natuurlijk belichten werkt al, nu nog de detail omhoog schroeven enz:
[ Bericht 7% gewijzigd door firefly3 op 02-04-2014 14:20:13 ]
Natuurlijk belichten werkt al, nu nog de detail omhoog schroeven enz:
[ Bericht 7% gewijzigd door firefly3 op 02-04-2014 14:20:13 ]
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Ik zal later proberen om hogere resolutie plaatjes te generen, hier alvast nog meer plaatjes met "ware kleuren":




Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

[ Bericht 27% gewijzigd door firefly3 op 04-04-2014 12:32:49 ]
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Nog een wolken plaatje.

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Heb je eigenlijk al eens geprobeerd om uit een groep foto's deze waarden te halen, dus zeg maar je algorithme omkeren. Je maakt nu een aantal componenten en maakt daaruit een foto, deze componenten kun je natuurlijk ook gewoon uit een foto uitlezen. Als je de marges van de waarden die je daaruit krijgt invoert in je originele algoritme zit je denk ik op een hele goede weg.
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Ik had trouwend ook een (lastig) ideetje: is het niet een optie om met SIFT features uit bestaande fotos te halen en je gegenereerde fotos daarop te proberen te matchen? Probleem is natuurlijk foto-tekenende featuregroeperingen te vinden, maar op die manier kun je volgens mij wel veel sneller een random plaatje vinden dat op bijv. Een landschapsfoto moet lijken, of een portretfoto, etc.
Of Ipv sift iets anders dat features uit een plaatje trekt.
Of Ipv sift iets anders dat features uit een plaatje trekt.
Ipv de rgb waardes, heb ik helaas minstens het lichtspectrum waardes nodig, hoeveel lichtgolven met welke frequentie zijn binnengevallen. Van die rgb uitkomst kan ik helaas de formule niet achterhalen.quote:Op maandag 7 april 2014 13:27 schreef Bosbeetle het volgende:
Heb je eigenlijk al eens geprobeerd om uit een groep foto's deze waarden te halen, dus zeg maar je algorithme omkeren. Je maakt nu een aantal componenten en maakt daaruit een foto, deze componenten kun je natuurlijk ook gewoon uit een foto uitlezen. Als je de marges van de waarden die je daaruit krijgt invoert in je originele algoritme zit je denk ik op een hele goede weg.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Bij het zoeken naar features, "train" ik het naar een plaatje dat ik wil hebben. Dat wil ik voorkomen. Verder heeft een vlak of raster structuur een hoger score terwijl het plaatje zelf er nep uit kan zien met wat zwarte strepen op een wit achtergrond. Tot nu toe ben ik het verst gekomen door gewoon de natuurwetten te volgen.quote:
Ik had trouwend ook een (lastig) ideetje: is het niet een optie om met SIFT features uit bestaande fotos te halen en je gegenereerde fotos daarop te proberen te matchen? Probleem is natuurlijk foto-tekenende featuregroeperingen te vinden, maar op die manier kun je volgens mij wel veel sneller een random plaatje vinden dat op bijv. Een landschapsfoto moet lijken, of een portretfoto, etc.
Of Ipv sift iets anders dat features uit een plaatje trekt.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Jammer, kun je ook niet een schatting herleiden, dat zou je interessante marges moeten opleveren.quote:
[..]
Ipv de rgb waardes, heb ik helaas minstens het lichtspectrum waardes nodig, hoeveel lichtgolven met welke frequentie zijn binnengevallen. Van die rgb uitkomst kan ik helaas de formule niet achterhalen.
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Het origineel aantal zandkorrels in de bakstenen van een huis berekenen is nog makkelijker helaas.quote:
[..]
Jammer, kun je ook niet een schatting herleiden, dat zou je interessante marges moeten opleveren.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Een van de meest gebruikte bakstenen is het Waalformaat van 210 x 100 x 50mm, pak daar de inhoud, dichtheid en grootte van een gemiddeld deeltje (zo'n 2 micrometer) bij en je bent er. Nu jij.quote:
[..]
Het origineel aantal zandkorrels in de bakstenen van een huis berekenen is nog makkelijker helaas.
Dat is waarquote:Op donderdag 10 april 2014 16:28 schreef Tchock het volgende:
[..]
Een van de meest gebruikte bakstenen is het Waalformaat van 210 x 100 x 50mm, pak daar de inhoud, dichtheid en grootte van een gemiddeld deeltje (zo'n 2 micrometer) bij en je bent er. Nu jij.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Ik constateer nog steeds dat alle plaatjes uit dit algoritme op een bepaalde manier op elkaar lijken, dat het beeld erg onscherp blijft en veel minder hoogfrequente content bevat dan de meeste foto's, en dat er nog steeds geen echte features in te herkennen zijn (behalve door pareidolia). Het algoritme houdt ook geen rekening met zaken die in de meeste foto's aanwezig zijn, zoals belichting, schaduwen, perspectief, e.d. Het resultaat is dat er wel plaatjes uitkomen, maar zeker geen foto's.
Dus nog fiks werk aan de winkel, wil je dat wel voor elkaar krijgen. Ik denk zelf dat een betere approach is om (quasi-)random inhoud te voeren aan een realistische, fysisch correcte 3D renderer. Dan voldoen de plaatjes in elk geval aan de beperkingen die een foto ook heeft.
Dus nog fiks werk aan de winkel, wil je dat wel voor elkaar krijgen. Ik denk zelf dat een betere approach is om (quasi-)random inhoud te voeren aan een realistische, fysisch correcte 3D renderer. Dan voldoen de plaatjes in elk geval aan de beperkingen die een foto ook heeft.
"The only real valuable thing is intuition. The intellect has little to do on the road to discovery."
Maar het is natuurlijk wel interessant - wanneer stopt iets met pareidolia zijn, en wordt het een echt gezicht? Volgens mij is die grens maar vaag. Auto's en dieren lijken ook gelaatsuitdrukkingen te hebben die je enkel toe kunt schrijven aan dit soort menselijke herkenningsprocessen, maar dat maakt niet per se dat er niets in kan zitten.quote:
[ Bericht 0% gewijzigd door Tchock op 10-04-2014 19:29:17 ]
De grens is vaag maar ook heel breed. Neem bijvoorbeeld striptekeningen van mensen. Dat noem je ook geen pareidolia meer. Maar striptekeningen zijn ook zeker geen foto's.quote:
[..]
Maar het is natuurlijk wel interessant - wanneer stopt iets met pareidolia zijn, en wordt het een echt gezicht? Volgens mij is die grens maar vaag. Auto's en dieren lijken voor ook gelaatsuitdrukkingen te hebben die je enkel toe kunt schrijven aan dit soort menselijke herkenningsprocessen, maar dat maakt niet per dat er niets in kan zitten.
Mijn punt is: als je striptekeningen wilt, dan zal je een programma moeten maken dat de beperkingen van een striptekening kent. Als je foto's wilt, zal je de beperkingen van een foto moeten hebben (oftewel: het plaatje moet een resultaat kunnen zijn van rondkaatsend licht dat uiteindelijk in een camera valt, binnen realistische grenzen en in een realistische omgeving. Vandaar dat ik zat te denken aan 3D renderers, die dat proces uiterst goed kunnen simuleren.).
"The only real valuable thing is intuition. The intellect has little to do on the road to discovery."
Dan kan je net zo goed terragen downloaden en dan random terrain klikken en je bent er. Random terrein genereren deed ik al toen ik 16 was. Het is nu tijd om de lat hoger te zetten. De wereld van tevoren op delen in drie dimensies is valsspelen. De uitdaging is om 1 formule te houden voor alles.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Wat bedoel je daarmee dan?quote:
De uitdaging is om 1 formule te houden voor alles.
"The only real valuable thing is intuition. The intellect has little to do on the road to discovery."
1 formule dat een 2d wereld kan genereren, 3d, of wat dan ook.quote:
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Een formule die vanuit het niets leven kan genereren.quote:
[..]
1 formule dat een 2d wereld kan genereren, 3d, of wat dan ook.
Wie dit leest is gek
^^quote:Op donderdag 10 april 2014 22:20 schreef Nieuwschierig het volgende:
[..]
Een formule die vanuit het niets leven kan genereren.
Langzaam maar zeker aan de weg timmeren en kijken waar we uit komen






[ Bericht 3% gewijzigd door firefly3 op 10-04-2014 23:38:02 ]
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Ik weet niet wat er is veranderd maar dit lijkt nergens meer op. Praktisch alle kleur, diepte en scherpte is verdwenen.quote:
[..]
^^
Langzaam maar zeker aan de weg timmeren en kijken waar we uit komen
[ afbeelding ]
[ afbeelding ]
[ afbeelding ]
[ afbeelding ]
[ afbeelding ]
[ afbeelding ]
+ Meer kleurquote:Op vrijdag 11 april 2014 00:50 schreef Tchock het volgende:
[..]
Ik weet niet wat er is veranderd maar dit lijkt nergens meer op. Praktisch alle kleur, diepte en scherpte is verdwenen.
+ Meer detail
- Scherpte
- Realisme (tekening achtig)
De reden is gek genoeg een hogere frequentie. Er gebeurd teveel en er is niet 1 focus punt.
Even snel om het een beetje goed te maken

[ Bericht 18% gewijzigd door firefly3 op 11-04-2014 07:31:52 ]
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Ik had vandaag even zin om Octave (open-source variant van Matlab) te proberen.
Het leek mij wel interessant om te kijken wat er gebeurde als ik nu een plaatje genereer, waarbij elke gegenereerde pixel (van links boven tot aan rechts beneden) kijkt naar zijn buren. Het idee komt een beetje van Wolfram's Rule 30
Alleen wordt bij mij óf het gemiddelde gebruikt van de omringende pixels óf dat een pixel gewoon een random kleur krijgt. Voor dit laatste bestaat een kans van 1 op p.
code:
maar het resultaat is niet zo heel spannend nog:
en na dit plaatje weer 10x als input te hebben gebruikt:
Binnenkort even kijken wat er gebeurt als ik RGB-plaatjes probeer ipv deze simpele monochroom versies
Het leek mij wel interessant om te kijken wat er gebeurde als ik nu een plaatje genereer, waarbij elke gegenereerde pixel (van links boven tot aan rechts beneden) kijkt naar zijn buren. Het idee komt een beetje van Wolfram's Rule 30
Alleen wordt bij mij óf het gemiddelde gebruikt van de omringende pixels óf dat een pixel gewoon een random kleur krijgt. Voor dit laatste bestaat een kans van 1 op p.
code:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | n = 100; m = 100; w = ones(n, m); # define a 2D n x m matrix p = 4; # propability (1 out of p) to choose a random color for i=[2:n-1], for j=[2:m], if randi(p) == int8(p/2) w(i,j) = rand; else w(i,j) = mean( [w(i-1, j-1), w(i , j-1), w(i+1, j-1), w(i-1, j )]); end end end imshow(w) |
maar het resultaat is niet zo heel spannend nog:

en na dit plaatje weer 10x als input te hebben gebruikt:

Binnenkort even kijken wat er gebeurt als ik RGB-plaatjes probeer ipv deze simpele monochroom versies
nee, jij dan!
Hij is wel grappig, wat gebeurt er als je dit loslaat op een bekend plaatje (het lijkt erop alsof je een soort smoothing filter met random pixels hebt gemaakt)quote:
Ik had vandaag even zin om Octave (open-source variant van Matlab) te proberen.
Het leek mij wel interessant om te kijken wat er gebeurde als ik nu een plaatje genereer, waarbij elke gegenereerde pixel (van links boven tot aan rechts beneden) kijkt naar zijn buren. Het idee komt een beetje van Wolfram's Rule 30
Alleen wordt bij mij óf het gemiddelde gebruikt van de omringende pixels óf dat een pixel gewoon een random kleur krijgt. Voor dit laatste bestaat een kans van 1 op p.
code:
[ code verwijderd ]
maar het resultaat is niet zo heel spannend nog:
[ afbeelding ]
en na dit plaatje weer 10x als input te hebben gebruikt:
[ afbeelding ]
Binnenkort even kijken wat er gebeurt als ik RGB-plaatjes probeer ipv deze simpele monochroom versies
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Dat ga ik binnenkort even uitcheckenquote:
[..]
Hij is wel grappig, wat gebeurt er als je dit loslaat op een bekend plaatje (het lijkt erop alsof je een soort smoothing filter met random pixels hebt gemaakt)
nee, jij dan!
Heb niets toe te voegen, maar tof topic! Blijft leuk om te zien hoe mensen overal graag gezichten in herkennen.
Ik vecht met zwervers voor mijn plezier. Binnenkort ook op YouTube!
Gaaf om te zien dat er meer mensen bezig zijn met dit onderwerp!quote:
Ik had vandaag even zin om Octave (open-source variant van Matlab) te proberen.
Het leek mij wel interessant om te kijken wat er gebeurde als ik nu een plaatje genereer, waarbij elke gegenereerde pixel (van links boven tot aan rechts beneden) kijkt naar zijn buren. Het idee komt een beetje van Wolfram's Rule 30
Alleen wordt bij mij óf het gemiddelde gebruikt van de omringende pixels óf dat een pixel gewoon een random kleur krijgt. Voor dit laatste bestaat een kans van 1 op p.
code:
[ code verwijderd ]
maar het resultaat is niet zo heel spannend nog:
[ afbeelding ]
en na dit plaatje weer 10x als input te hebben gebruikt:
[ afbeelding ]
Binnenkort even kijken wat er gebeurt als ik RGB-plaatjes probeer ipv deze simpele monochroom versies
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Een wat vernieuwde versie van de code die ik openbaar had gemaakt (eventueel te vinden in de vorige reeks).quote:
Wat voor script/programma wordt er gebruikt om die wolkenplaatjes te maken?
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Dit zijn 100 iteraties van gehenna's algoritme alleen dan gemaakt in fiji/imagej daar kan ik wat makkelijker echte beelden in gooien. (vooralsnog mean'd hij alleen met zijn links en rechts liggen de pixels maar dat moet niet te moeilijk zijn om er een boven en onder bij te pakken
warning: lelijke code is lelijk ik moest eerst een 2d array functie maken
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | function make2DArray(m,n){ matrix = newArray((m*n)+1); matrix[0] = m; return matrix; } function fill2DArray(matrix,m,n,i){ matrix[((m%matrix[0])+(matrix[0]*n))+1] = i; return matrix; } function read2DArray(matrix,m,n){ i = matrix[((m%matrix[0])+(matrix[0]*n))+1]; return i; } function makeImagefromArray(matrix){ m=matrix[0]; n=(lengthOf(matrix)-1)/matrix[0]; newImage("Untitled", "8-bit black",m, n, 1); for(i=0; i<m; i++){ for(j=0;j<n;j++){ pixel = read2DArray(matrix,i,j); setPixel(i,j,pixel); } } } x = 100; y = 100; test = make2DArray(x,y); test2 = make2DArray(x,y); test = fill2DArray(test,8,8,255); for(j=1;j<100;j++){ for(i=2;i<lengthOf(test)-1;i++){ r=random(); rpix=random()*255; if(r < (1.2/10)){ test2[i]=rpix; } else{ test2[i]=(test[i-1]+test[i]+test[i+1])/3; } test = test2; } } makeImagefromArray(test2); |
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
hier de goede:
[ Bericht 1% gewijzigd door Bosbeetle op 16-04-2014 15:50:40 ]

[ Bericht 1% gewijzigd door Bosbeetle op 16-04-2014 15:50:40 ]
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Haha tofquote:
[ afbeelding ]
Dit zijn 100 iteraties van gehenna's algoritme alleen dan gemaakt in fiji/imagej daar kan ik wat makkelijker echte beelden in gooien. (vooralsnog mean'd hij alleen met zijn links en rechts liggen de pixels maar dat moet niet te moeilijk zijn om er een boven en onder bij te pakken
warning: lelijke code is lelijk ik moest eerst een 2d array functie maken
[ code verwijderd ]
Bij mij pakt hij ook alleen het gemiddelde van de pixel z'n linkerbuur en z'n 3 bovenburen (omdat ik linksboven begin met vullen is de rest sowieso nog wit).
nee, jij dan!
Ja ik heb een voor en na plaatjequote:
[..]
Haha tof
Bij mij pakt hij ook alleen het gemiddelde van de pixel z'n linkerbuur en z'n 3 bovenburen (omdat ik linksboven begin met vullen is de rest sowieso nog wit).
Maar het is eigenlijk gewoon een simpel filter met wat randomness
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna

+10 keer het gehenna algoritme

+100 keer het gehenna algoritme

En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Even een klein beetje aangepast, het scriptje leest nu een plaatje in:
zonder het random gedeelte, maakt hij er dit van (aanpassing in grootte zijn dankzij mijn gnuplot instellingen):
en met het random gedeelte:


| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | # n = 100; # m = 100; # w = ones(n, m); # define a 2D n x m matrix p = 4; # propability (1 out of p) to choose a random color [img, map, alpha] = imread('rb.jpg'); [n, m] = size(img); for i=[2:n-1], for j=[2:m-1], if randi(p) == int8(p/2) img(i,j) = randi(256); else img(i,j) = mean( [img(i-1, j-1), img(i , j-1), img(i+1, j-1), img(i-1, j ), img(i , j ), img(i+1, j ), img(i-1, j+1), img(i , j+1), img(i+1, j+1)] ); end end end imshow(img, map) |
zonder het random gedeelte, maakt hij er dit van (aanpassing in grootte zijn dankzij mijn gnuplot instellingen):

en met het random gedeelte:

nee, jij dan!
dit is 100 keer de bovenste
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna

wow, het is al heel duidelijk een man met een saxofoonquote:
[ afbeelding ]
+10 keer het gehenna algoritme
[ afbeelding ]
nee, jij dan!
quote:Op woensdag 16 april 2014 17:05 schreef Gehenna het volgende:
[..]
wow, het is al heel duidelijk een man met een saxofoon
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Ik heb nu wel voor het eerst in mijn leven een blur filter gemaaktquote:
Ik snap er geen fuck meer van maar leuk om te lezen en zien dit.
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Sneeuwpop, inc. wortelneus.quote:
Ik vecht met zwervers voor mijn plezier. Binnenkort ook op YouTube!
quote:
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.


Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Dat oog is wel creepy ja
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Foto vanuit een vliegtuigraampje genomen 

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Grapige rule110 variatie [01101110] maar dan op even lijnen van links naar rechts gelezen en op oneven lijnen van rechts naar links

En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna


Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Verander je je code en/of instellingen ook steeds, of zijn dit gewoon wat willekeurige try-outs?quote:
nee, jij dan!
Het is een aanpassing van de huidige versie

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.





[ Bericht 10% gewijzigd door firefly3 op 10-05-2014 14:35:05 ]
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Bedankt!quote:
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
quote:
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
quote:
Ziet er echt gaaf uit
En leuk dat je door te experimenteren een eigen blur-filter hebt gemaakt, Bosbeetle.
Bedankt allemaal! De sinussen voldeden niet om een scherper beeld te krijgen, dus moest ik ze ombuigen enz. Scherpere buigingen betekent hardere grenzen
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
wel met mijn codequote:
[..]
En leuk dat je door te experimenteren een eigen blur-filter hebt gemaakt, Bosbeetle.
nee, jij dan!
Ik ben nu weer bezig met kleur. Alweer wat verbeteringen. Het begint steeds echter te worden. Ooit kunnen we oneindig veel films bekijken die uit 1 algoritme zijn gegenereerd Met een beetje denkwerk kan er ook geluid bij, deels met hetzelfde algoritme en denkwijze. Virtual reality bril op en je zit in een andere wereld.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.


Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.



Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

[ Bericht 100% gewijzigd door firefly3 op 19-06-2014 13:18:37 ]
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
TVP
ik zal komend weekend eens een pythonscriptje trachten te schrijven en zien of ik iets kan bewerkstelligen
ik zal komend weekend eens een pythonscriptje trachten te schrijven en zien of ik iets kan bewerkstelligen
hehe dat heb ik wel eens geprobeerd te evoluerenquote:
Random muziek zou wel helemaal raar zijn ja.
MUZ / Muzikale evolutie: een experiment
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Da's wel cool ja.quote:
[..]
hehe dat heb ik wel eens geprobeerd te evolueren
MUZ / Muzikale evolutie: een experiment
Al is echte random muziek totaal niet muziek die wij mooi vinden; we houden juist van gestructureerde muziek, met bijvoorbeeld een vierkwartsmaat, in groepjes van 4 maten, met thema's en herhalingen, enzovoorts.
Maar okay, da's offtopic.
Als je gewoon in een toonladder gaat zitten maakt de maatvoering nog niet eens zo heel veel uit... en klinkt het altijd best wel okay. Ik wil ooit nog een keer een projectje in die richting doen, bij dit soort evolutie projecten is de selectie altijd het grootste probleem, het 2de probleem is een goed fenotype/genotype systeem te maken.quote:
[..]
Da's wel cool ja.
Al is echte random muziek totaal niet muziek die wij mooi vinden; we houden juist van gestructureerde muziek, met bijvoorbeeld een vierkwartsmaat, in groepjes van 4 maten, met thema's en herhalingen, enzovoorts.
Maar okay, da's offtopic.
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna

Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Dat komt omdat de gebeurtenissen onafhankelijk van elkaar moeten zijn. Het ene puzzelstukje dat op de goede plek ligt zorgt er, vanwege simpele fisieke redenen, voor dat de andere puzzelstukjes niet de juiste positie kunnen innemen. Daarom lijkt het mij sterk dat een aap een verhaal kan typen aangezien zijn hersens zo ontwikkeld zijn dat het nooit helemaal willekeurig is wat hij typt.quote:
Stel, je legt een puzzle die qua maat exact in de doos past, in losse delen in die doos.
Hoe lang je ook schud, het gaat nooit een compleet in elkaar gelegde puzzel worden.
Echter, stel dat ik een grote doos met letters heb en 1 voor 1 een letter eruit pak, dan heb ik kans dat ik de bijbel schrijf met op de laatste bladzijde Newtons calculus
We're slowly approaching inevitable death.
Kwantumcomputersquote:
[..]
^DIT
Om te benadrukken hoe klein deze kansen zijn:
Er zitten ongeveer 10^80 atomen in ons hele universum.
Er zijn misschien eindeloos veel kansen maar je bent ook bijna een eindeloze periode bezig om dit te genereren, maakt niet uit hoe snel je computers zijn.
We're slowly approaching inevitable death.
Die laatste gaat ook fout. Aangezien het aantal letters in de doos beperkt is (per definitie), is het aantal letters A ook beperkt (als het goed is 1/26e van het totaal). Als je een A pakt is de kans dat je daarna nóg een A pakt niet meer perfect willekeurig, omdat het aantal A's in de doos één lager is dan het aantal van alle andere letters.quote:
[..]
Dat komt omdat de gebeurtenissen onafhankelijk van elkaar moeten zijn. Het ene puzzelstukje dat op de goede plek ligt zorgt er, vanwege simpele fisieke redenen, voor dat de andere puzzelstukjes niet de juiste positie kunnen innemen. Daarom lijkt het mij sterk dat een aap een verhaal kan typen aangezien zijn hersens zo ontwikkeld zijn dat het nooit helemaal willekeurig is wat hij typt.
Echter, stel dat ik een grote doos met letters heb en 1 voor 1 een letter eruit pak, dan heb ik kans dat ik de bijbel schrijf met op de laatste bladzijde Newtons calculus
Daarom is het bekende beeld van de aap achter de typemachine zo aantrekkelijk: een typemachine kan een oneindige reeks karakters produceren waarbij de kans op elk karakter (in theorie) altijd even groot blijft. Maar je hebt over de intelligentie van de aap wel gelijk.
Waarom ga je er vanuit dat de letters niet op williekeuriuge wijze in de doos liggen? Zolang de letters op willekeurige wijze in de doos liggen maakt het niet uit hoe ze eruit gepakt worden.quote:
[..]
Die laatste gaat ook fout. Aangezien het aantal letters in de doos beperkt is (per definitie), is het aantal letters A ook beperkt (als het goed is 1/26e van het totaal). Als je een A pakt is de kans dat je daarna nóg een A pakt niet meer perfect willekeurig, omdat het aantal A's in de doos één lager is dan het aantal van alle andere letters.
Beperkheid maakt ook niet uit. De bijbel is beperkt
We're slowly approaching inevitable death.
*ROTSCHOP*
(omdat ik dit wel relevant vind voor dit topic)
http://tweakers.net/geek/(...)innige-plaatjes.html
(omdat ik dit wel relevant vind voor dit topic)
http://tweakers.net/geek/(...)innige-plaatjes.html
Bron van het artikel: http://googleresearch.blo(...)per-into-neural.html met gallery https://goo.gl/photos/fFcivHZ2CDhqCkZdAquote:Google legt training neurale netwerken uit met kunstzinnige plaatjes
Door Krijn Soeteman, donderdag 18 juni 2015 12:28
Google Research publiceert informatie over zijn onderzoek naar neurale netwerken. Dat doen ze aan de hand van verschillende soorten plaatjes, zowel door het netwerk te voeden met beeltenissen als andersom: een netwerk leren vormen te maken uit willekeurige ruis en al wat daartussen zit.
De achterliggende technieken voor neurale netwerken zorgen voor interessante beeltenissen. Het laat zien dat kunstliefhebbers zich in de nabije toekomst misschien moeten gaan afvragen of ze naar een door een mens vervaardigd werk kijken of naar een werk bedacht door een paar sets kunstmatige neuronen.
Een naam voor de nieuwe kunststroming is er in ieder geval al: inceptionism. De stroming bestaat uit neurale netwerken die getraind worden door miljoenen plaatjes te analyseren, waarna elke laag van het netwerk gaat bepalen wat voor eigenschappen op het plaatje te zien is om uiteindelijk bij de laatste laag te bepalen wat er te zien is. Een eerste laag kijkt bijvoorbeeld naar hoeken en randen, daaropvolgende lagen interpreteren de basisvormen, zoals een deur of een dier. De laatste lagen worden actief bij nog complexere vormen, zoals hele gebouwen. Als die procedure omgedraaid wordt door bijvoorbeeld te vragen aan het netwerk om zich een plaatje voor te stellen van een banaan vanuit willekeurige ruis, dan wordt het echt interessant.
noise to banana ruis banaan Het blijkt dat netwerken die getraind zijn om verschillende plaatjes te interpreteren heel wat informatie in zich hebben om zelf onderwerpen weer te geven, al klopt het niet altijd, zoals bij het woord 'dumbbell' waar structureel een deel van een mensen-arm bij tevoorschijn komt:
Het team heeft ook testen gehouden met interpretaties waarbij niet van te voren ingegeven wordt wat er uitgelicht moet worden, maar het netwerk zelf mag beslissen wat er te zien is. Dan wordt een willekeurig plaatje ingeladen en wordt aan een laag van het neurale netwerk gevraagd om uit te lichten wat het netwerk dan detecteert. Omdat elke laag van het neurale netwerk op een andere manier omgaat met abstractie, komen er van alleen simpele streken tot figuren en hele beelden uit. Door een feedback-loop te maken, komen er steeds beter herkenbare plaatjes uit.
Uiteindelijk doet Google dit werk natuurlijk niet voor de lol. Het is om te begrijpen en visualiseren hoe neurale netwerken leren moeilijke classificatie-taken uit te voeren, hoe netwerkarchitectuur te verbeteren is en wat het netwerk leerde tijdens de training.
Als het niet met een hamer te repareren is, is het een elektrisch probleem.
haha toen ik dat op tweakers las dacht ik ook aan dit topic
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Ik moest laatst ook al denken aan dit topique, vanwege deze uitleg over een belangrijk aspect van JPEG compressie:quote:
haha toen ik dat op tweakers las dacht ik ook aan dit topic
(er wordt dus blijkbaar gewerkt met het feit dat de waardes in een plaatje uit te drukken zijn in cosinussen en daarmee gecomprimeerd kunnen worden)

Trots lid van het 👿 Duivelse Viertal 👿
Een gedicht over Maanvis
Het ONZ / [KAMT] Kennis- en Adviescentrum Maanvis Topics , voor al je vragen over mijn topiques!
Een gedicht over Maanvis
Het ONZ / [KAMT] Kennis- en Adviescentrum Maanvis Topics , voor al je vragen over mijn topiques!
Fourier transformatie een vrij oud principe maar computers waren daar vroegah niet snel genoeg voor.quote:
[..]
Ik moest laatst ook al denken aan dit topique, vanwege deze uitleg over een belangrijk aspect van JPEG compressie:
(er wordt dus blijkbaar gewerkt met het feit dat de waardes in een plaatje uit te drukken zijn in cosinussen en daarmee gecomprimeerd kunnen worden)
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
zelfs niet met lookup tables?quote:
[..]
Fourier transformatie een vrij oud principe maar computers waren daar vroegah niet snel genoeg voor.
Trots lid van het 👿 Duivelse Viertal 👿
Een gedicht over Maanvis
Het ONZ / [KAMT] Kennis- en Adviescentrum Maanvis Topics , voor al je vragen over mijn topiques!
Een gedicht over Maanvis
Het ONZ / [KAMT] Kennis- en Adviescentrum Maanvis Topics , voor al je vragen over mijn topiques!
Nouja ze hebben op een gegeven moment het fast fourier algoritme ontwikkeld en computers zijn nu snel genoeg.... maar veel meer weet ik er ook niet van, behalve dat ik het gebruikquote:
https://en.wikipedia.org/wiki/Fast_Fourier_transform
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Maar je zou dus eigenlijk bijv. (excuses als het bullshit blijkt te zijn, zo erg zit ik er niet in) een plaatje van een boom kunnen pakken en daarvan de transformaties kunnen analyseren, en vervolgens daar een soort van 'gerandomizede' versie van kunnen maken, en op basis daarvan weer een plaatje kunnen samen stellen. En dan kijken of je iets gemaakt hebt wat op een boom lijktquote:
[..]
Nouja ze hebben op een gegeven moment het fast fourier algoritme ontwikkeld en computers zijn nu snel genoeg.... maar veel meer weet ik er ook niet van, behalve dat ik het gebruik
https://en.wikipedia.org/wiki/Fast_Fourier_transform
Trots lid van het 👿 Duivelse Viertal 👿
Een gedicht over Maanvis
Het ONZ / [KAMT] Kennis- en Adviescentrum Maanvis Topics , voor al je vragen over mijn topiques!
Een gedicht over Maanvis
Het ONZ / [KAMT] Kennis- en Adviescentrum Maanvis Topics , voor al je vragen over mijn topiques!
dat is een stuk moeilijker dan je denkt. Je moet dan namelijk ook definieren waarin "boom" anders is dan niet "boom" en daar zijn ze in dat stuk over google hierboven dus druk mee bezig.quote:
[..]
Maar je zou dus eigenlijk bijv. (excuses als het bullshit blijkt te zijn, zo erg zit ik er niet in) een plaatje van een boom kunnen pakken en daarvan de transformaties kunnen analyseren, en vervolgens daar een soort van 'gerandomizede' versie van kunnen maken, en op basis daarvan weer een plaatje kunnen samen stellen. En dan kijken of je iets gemaakt hebt wat op een boom lijkt
Hier bijvoorbeeld 2 bomen


en hier de FFT (zonder de fase plot) van de twee plaatjes


Zoals je ziet kun je er niet veel van maken, zo'n boom heeft vrij veel hoge frequenties (takken, kleine blaadjes) die zitten meer aan de buitenkant. En 1 grote frequentie de boom zelf. En dat kruis komt omdat het een vierkant plaatje is die zitten er altijd in.
Maar als ik nu een plaatje van een mens zou nemen zou de FFT er ongeveer hetzelfde uitzien.
m.a.w. je kunt er wel wat mee maar plaatjes worden er niet ineens makkelijker mee te analyseren
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Toch even voor de grap weer eens gericht een plaatje geëvolueerd
doel:
10000 iteraties evolutie
100000 iteraties evolutie
(laat mijn werkcomputer morgen er wel een avondje op doorrekenen om te kijken waar ik uitkom )
doel:

10000 iteraties evolutie

100000 iteraties evolutie

(laat mijn werkcomputer morgen er wel een avondje op doorrekenen om te kijken waar ik uitkom
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Volgens mij kom je op een gegeven moment juist uit op een effen vlak.
Als je random laat generenen, en dan neem ik aan dat je herhalingen uitsluit, dan zal je uiteindelijk als je lang genoeg doorgaat alle combinaties hebben gehad, en tot stilstand komen op een effen vlak.
Taylorreeks geloof ik,....toch ?
(Damn dat ziet er indrukwekkend uit)
Als je random laat generenen, en dan neem ik aan dat je herhalingen uitsluit, dan zal je uiteindelijk als je lang genoeg doorgaat alle combinaties hebben gehad, en tot stilstand komen op een effen vlak.
Taylorreeks geloof ik,....toch ?
(Damn dat ziet er indrukwekkend uit)
bivd kijkt met u mee.
Kun je hier iets meer over vertellen?quote:
Toch even voor de grap weer eens gericht een plaatje geëvolueerd
doel:
[ afbeelding ]
10000 iteraties evolutie
[ afbeelding ]
100000 iteraties evolutie
[ afbeelding ]
(laat mijn werkcomputer morgen er wel een avondje op doorrekenen om te kijken waar ik uitkom
Waarom evolueert het beeld richting de foto? Met welk beeld ben je begonnen?
Ik snap er gewoon echt weinig van.
Ik denk in mijn geval niet omdat ik selecteer, het is dus geen complete random.quote:
Volgens mij kom je op een gegeven moment juist uit op een effen vlak.
Als je random laat generenen, en dan neem ik aan dat je herhalingen uitsluit, dan zal je uiteindelijk als je lang genoeg doorgaat alle combinaties hebben gehad, en tot stilstand komen op een effen vlak.
Taylorreeks geloof ik,....toch ?
(Damn dat ziet er indrukwekkend uit)
Het is heel eenvoudig. Ik heb dat bovenste plaatje van jim morrison dat is mijn doel. Vervolgens maak ik tien plaatjes met 100 noise pixels bovenop mijn beginplaatje (eerst is dat gewoon een zwart vlak), random gegenereerd. Daarvan kies ik de 2 die het meest op dat plaatje van jim morrison lijken (met een eenvoudige least squares) dan neem ik het gemiddelde van die 2 plaatjes. En dat 10000 keer.quote:
[..]
Kun je hier iets meer over vertellen?
Waarom evolueert het beeld richting de foto? Met welk beeld ben je begonnen?
Ik snap er gewoon echt weinig van.
Opzich is dit geen goed model voor evolutie omdat het doel al duidelijk is en selectie plaatsvind op gelijkenis op dit doel. Wat dus betekend als je dit maar lang genoeg doet je uiteindelijk exact het Jim plaatje terug krijgt. (maar de tussenstappen kunnen er wel tof uitzien)
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
En wat is dan "precies het plaatje"? Je kan hetzelfde plaatje in talloze verschillende tinten en combinaties hebben: Negatief, gespiegeld, veller dan het orgineel, donkerder dan het orgineel, de kleuren gehusseld. Of bijna indentiek op een paar pixels na.quote:
Als je een plaatje zou genereren van 10 bij 10 pixels met slechts 16 mogelijke kleuren is de kans dat je precies het plaatje genereert dat je wilt 1/16 tot de macht 100 (10x10 pixels)
Dat is een kans van 1 op 2,85 * 10^120. Kan je nagaan als je een fatsoenlijk formaat en meer kleuren mogelijkheden hebt. Dus nee, er zal praktisch nooit een foto uitkomen.
Die som is dus wat moeilijker dan dat.
Zodra het plaatje ook maar enige grootte heeft (zeg meer dan 50x50) is het aantal mogelijkheden dat iets voorstelt, of een enigszins herkenbare foto afbeeldt, echt zó onvoorstelbaar astronomisch veel kleiner dan het aantal mogelijkheden met enkel ruis, onherkenbare smurrie, en random betekenisloze pixels. Zelfs met alle computerkracht ter wereld zou je statistisch gezien vele triljarden keren langer dan de leeftijd van het universum moeten blijven proberen tot je er ooit iets zinnigs uit krijgt.
The worst thing about censorship is ███ ███████ ██████.
Daarom moet je ook eigenlijk geen ruis genereren maar iets anders... zoals de TS ook aan het doen. Verder als je evolutie toepast op goede critereria hoef je niet zo lang te rekenen (er zijn al vele voorbeelden van)quote:
Zodra het plaatje ook maar enige grootte heeft (zeg meer dan 50x50) is het aantal mogelijkheden dat iets voorstelt, of een enigszins herkenbare foto afbeeldt, echt zó onvoorstelbaar astronomisch veel kleiner dan het aantal mogelijkheden met enkel ruis, onherkenbare smurrie, en random betekenisloze pixels. Zelfs met alle computerkracht ter wereld zou je statistisch gezien vele triljarden keren langer dan de leeftijd van het universum moeten blijven proberen tot je er ooit iets zinnigs uit krijgt.
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Er zijn inderdaad wel varianten die je ook goed zou kunnen keuren, maar we hebben het hier over 10 bij 10 pixels dan is vrijwel elke pixel die afwijkt ook wel echt opvallend. Ook zijn er maar 16 kleuren, er zijn dus niet veel kleuren die dusdanig op elkaar lijken dat een kleurverschil niet erg opvalt.quote:
[..]
En wat is dan "precies het plaatje"? Je kan hetzelfde plaatje in talloze verschillende tinten en combinaties hebben: Negatief, gespiegeld, veller dan het orgineel, donkerder dan het orgineel, de kleuren gehusseld. Of bijna indentiek op een paar pixels na.
Die som is dus wat moeilijker dan dat.
Het sommetje was vooral bedoeld om aan te geven hoe gigantisch snel het aantal mogelijkheden stijgt. En ook al stijgt het aantal mogelijkheden die iets voorstellen ook snel en zijn afwijkingen minder storend, dat haalt het nooit bij het geweldig aantal mogelijkheden die niets voorstellen.
Dat valt reuze mee. Mensen zijn zo goed in dingen herkennen. Voorbeeld:quote:
[..]
Er zijn inderdaad wel varianten die je ook goed zou kunnen keuren, maar we hebben het hier over 10 bij 10 pixels dan is vrijwel elke pixel die afwijkt ook wel echt opvallend. Ook zijn er maar 16 kleuren, er zijn dus niet veel kleuren die dusdanig op elkaar lijken dat een kleurverschil niet erg opvalt.
Het sommetje was vooral bedoeld om aan te geven hoe gigantisch snel het aantal mogelijkheden stijgt. En ook al stijgt het aantal mogelijkheden die iets voorstellen ook snel en zijn afwijkingen minder storend, dat haalt het nooit bij het geweldig aantal mogelijkheden die niets voorstellen.

Dit plaatje is ook weinig anders dan ruis met drie donkere vlakken er in. Bovendien heb je het over "het" plaatje. Terwijl in dit topic elke herkenbare vorm acceptabel is. We* werken niet naar één doel toe.
*niet dat ik daar ook iets aan heb bijgedragen op visueel vlak
Van klein naar groot:
Ik denk dat we pixels moeten blijven groeperen.
Hiernaast bestaat de wereld uit een combinatie van chaos en orde.
Ten derde perspectief.
Meer hebben we denk ik niet nodig. Stap 2 zijn formules in formules en zal al echt gaaf zijn.
Ik denk dat we pixels moeten blijven groeperen.
Hiernaast bestaat de wereld uit een combinatie van chaos en orde.
Ten derde perspectief.
Meer hebben we denk ik niet nodig. Stap 2 zijn formules in formules en zal al echt gaaf zijn.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Wat dat betreft doet google het beter dan wij
https://photos.google.com(...)VFBBZEN1d205bUdEMnhB
Dit zijn onder andere plaatjes van hun algoritmes maar ook wat de neural networks van google maken als je ze vraagt een van de onderstaande dingen te tekenen:
http://www.gizmag.com/goo(...)eptionism-art/38113/
https://photos.google.com(...)VFBBZEN1d205bUdEMnhB
Dit zijn onder andere plaatjes van hun algoritmes maar ook wat de neural networks van google maken als je ze vraagt een van de onderstaande dingen te tekenen:

http://www.gizmag.com/goo(...)eptionism-art/38113/
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Nice!quote:
Wat dat betreft doet google het beter dan wij
https://photos.google.com(...)VFBBZEN1d205bUdEMnhB
Dit zijn onder andere plaatjes van hun algoritmes maar ook wat de neural networks van google maken als je ze vraagt een van de onderstaande dingen te tekenen:
[ afbeelding ]
http://www.gizmag.com/goo(...)eptionism-art/38113/
Wel een groot verschil overigens: ze trainen naar een doel (dmv een plaatjes database) en combineren het.
In theorie zou je 1 formule kunnen hebben voor alles. Ook wat wij nog niet kennen en zonder plaatjes database.
Ze creeëren niet "iets uit het niets", maar "een combinatie uit heel veel"
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Ik vind het wel een leuk gebied van de wetenschap we kunnen neurale netwerken dingen leren, en vervolgens als dat gelukt is moeten we weer terug gaan en onderzoeken hoe (en wat) die neurale netwerken nou weer geleerd hebben. We maken dus een systeem met allemaal kleine stapjes maar kunnen zelf de combinatie van die stapjes bij elkaar niet meer begrijpen.quote:
[..]
Nice!
Wel een groot verschil overigens: ze trainen naar een doel (dmv een plaatjes database) en combineren het.
In theorie zou je 1 formule kunnen hebben voor alles. Ook wat wij nog niet kennen en zonder plaatjes database.
Ze creeëren niet "iets uit het niets", maar "een combinatie uit heel veel"
Gaat niet lang duren of we zijn computer algoritmes net zo aan het bestuderen als de natuur. (google is het eigenlijk al aan het doen)
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Het algoritme is denk ik een patroon herkenning. M.a.w. hij mixt het resultaat van de input. Hiernaast plakt hij een aantal variaties naast elkaar als eindbewerking.quote:
[..]
Ik vind het wel een leuk gebied van de wetenschap we kunnen neurale netwerken dingen leren, en vervolgens als dat gelukt is moeten we weer terug gaan en onderzoeken hoe (en wat) die neurale netwerken nou weer geleerd hebben. We maken dus een systeem met allemaal kleine stapjes maar kunnen zelf de combinatie van die stapjes bij elkaar niet meer begrijpen.
Gaat niet lang duren of we zijn computer algoritmes net zo aan het bestuderen als de natuur. (google is het eigenlijk al aan het doen)
Het gaafste is om iets te hebben zonder bepaalde data input en zonder bepaalde data output.
Zo random mogelijk met alleen basis natuurwetten als regel, in plaats van een mengeling van input data. Maarja, hoe doe je dat, echt iets uit het niets krijgen?
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Ik bied hieronder de versie aan tot hoe ver ik was gekomen.
Kopieer de code naar een tekst bestandje en maak er een .html file van. (Hernoem het naar bestandsnaam.html).
Zo werkt het:
1) Declaratie variabelen
2) Initialisatie golven en kleuren
3) Ophalen golf sterktes voor desbetreffende pixels en licht sterkte bewaren.
4) Golven belichten aan de hand van frequentie (kleur) en voorgaande golven.
5) Render
Veel plezier. Dit forceerd mij om in de toekomst er harder aan te werken.
Kopieer de code naar een tekst bestandje en maak er een .html file van. (Hernoem het naar bestandsnaam.html).
Zo werkt het:
1) Declaratie variabelen
2) Initialisatie golven en kleuren
3) Ophalen golf sterktes voor desbetreffende pixels en licht sterkte bewaren.
4) Golven belichten aan de hand van frequentie (kleur) en voorgaande golven.
5) Render
Veel plezier
SPOILEROm spoilers te kunnen lezen moet je zijn ingelogd. Je moet je daarvoor eerst gratis Registreren. Ook kun je spoilers niet lezen als je een ban hebt.Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Wat kleine aanpassingen.



Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Volg dit topic al vanaf het begin, maar had hem op dit account nog niet in MyAt.quote:
Wat kleine aanpassingen.
[ afbeelding ]
[ afbeelding ]
[ afbeelding ]
Die bovenste: groen oog met zwarte iris/pupil, links daarvan een oortje, rechtsonder een neus en een mond.
[ Bericht 1% gewijzigd door #ANONIEM op 18-09-2016 20:59:35 ]
Heeft er nog iemand nieuwe ideeen? Kort samengevat: ik simuleer willekeurige lichtgolven die in een lens worden geprojecteerd en dan terug op de "javascript canvas". Het probleem zit in het willekeurige, het blijven vage objecten maar geen steden bijvoorbeeld. Opnieuw kom je dan op hetzelfde vraagstuk terecht: iets uit het niets creëren. Complexiteit zijn algoritmes die als samenhang meer kunnen creëren (cellular automata etc). Is er een mogelijkheid om complexiteit te combineren met chaos zoals in de realiteit? Een perfect evenwicht?
Waar ik achter ben gekomen is dat complexiteit een reeks van simpele regels zijn rondom een eenvoudig object. Deze regels zijn door de bedenker ingevoerd en hebben dan al een vaststaand eindresultaat (zie wanneer een cellular automaton vastloopt: formule = afgelopen). Veel wetenschappers zeggen dat het universum ook doodvriest tot een eindstadium van totale "equilibrium" of hoe je het ook schrijft.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
M.a.w, we zijn weer terugbeland bij hetzelfde vraagstuk. A.k.a. we zijn nog bij stap 0 met ons javascriptje..
Moeten we een wereld in die wereld schapen? Een automaton bouwen die zijn eigen algoritme maakt? Buiten onze wiskunde denken waarbij 1+1=3? Ik weet niet eens wat voor input we nodig hebben in welk vorm dan ook..
Er is maar 1 manier om de loop oneindig te laten doorlopen, door een niveau van complexiteit hierover uit te laten voeren zodat de "natuurwetten veranderen".
[ Bericht 20% gewijzigd door firefly3 op 22-10-2016 00:51:02 ]
Moeten we een wereld in die wereld schapen? Een automaton bouwen die zijn eigen algoritme maakt? Buiten onze wiskunde denken waarbij 1+1=3? Ik weet niet eens wat voor input we nodig hebben in welk vorm dan ook..
Er is maar 1 manier om de loop oneindig te laten doorlopen, door een niveau van complexiteit hierover uit te laten voeren zodat de "natuurwetten veranderen".
[ Bericht 20% gewijzigd door firefly3 op 22-10-2016 00:51:02 ]
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Ik denk dat je moet gaan kijken wat er ontbreekt in jouw plaatjes. Er zitten bijvoorbeeld zelfden scherpe randen in... ze zien er allemaal vrij golvend uit. Heb al eens geprobeerd om iets meer met ruis te doen.. je gebruikt nu allemaal perfecte lichtstralen die hooguit door andere perfecte lichtstralen geintefereerd worden. Maar in het echt worden lichtstralen door allerhande dingen vervormd verstrooid etc. Dus probeer eens te werken met niet perfecte golven en iets meer ruis.quote:
M.a.w, we zijn weer terugbeland bij hetzelfde vraagstuk. A.k.a. we zijn nog bij stap 0 met ons javascriptje..
Moeten we een wereld in die wereld schapen? Een automaton bouwen die zijn eigen algoritme maakt? Buiten onze wiskunde denken waarbij 1+1=3? Ik weet niet eens wat voor input we nodig hebben in welk vorm dan ook..
Ergens 1 of 2 random scherpe randen maken gaat je ook al hele andere plaatjes opleveren.
Er is maar 1 manier om de loop oneindig te laten doorlopen, door een niveau van complexiteit hierover uit te laten voeren zodat de "natuurwetten veranderen".
Ik denk dat daar ook het grote verschil zit jij maakt random lichtstralen maar de lichtstralen die een foto maken zijn alles behalve random, je kunt namelijk prima zes keer van hetzelfde object de zelfde foto maken... en daar zitten dan wel kleine verschillen in maar geen werelden van verschil.
En mochten we vallen dan is het omhoog. - Krang (uit: Pantani)
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
My favourite music is the music I haven't yet heard - John Cage
Water: ijskoud de hardste - Gehenna
Bedankt voor je input. Momenteel weet ik nog niet hoe ik scherpe randen maak zonder dat het een cartoonachtig plaatje wordt waar je niets aan hebt. Dus dat is wel jammer.quote:
[..]
Ik denk dat je moet gaan kijken wat er ontbreekt in jouw plaatjes. Er zitten bijvoorbeeld zelfden scherpe randen in... ze zien er allemaal vrij golvend uit. Heb al eens geprobeerd om iets meer met ruis te doen.. je gebruikt nu allemaal perfecte lichtstralen die hooguit door andere perfecte lichtstralen geintefereerd worden. Maar in het echt worden lichtstralen door allerhande dingen vervormd verstrooid etc. Dus probeer eens te werken met niet perfecte golven en iets meer ruis.
Ik denk dat daar ook het grote verschil zit jij maakt random lichtstralen maar de lichtstralen die een foto maken zijn alles behalve random, je kunt namelijk prima zes keer van hetzelfde object de zelfde foto maken... en daar zitten dan wel kleine verschillen in maar geen werelden van verschil.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Wow TS, je bent wel heel fanatiek!
Misschien vind je dit praatje ook wel leuk. Het is niet precies hetzelfde als jij doet, maar gaat wel over computers die herkenbare plaatjes produceren.
Misschien vind je dit praatje ook wel leuk. Het is niet precies hetzelfde als jij doet, maar gaat wel over computers die herkenbare plaatjes produceren.

gr gr
Bedankt. Gaaf!!quote:
Wow TS, je bent wel heel fanatiek!
Misschien vind je dit praatje ook wel leuk. Het is niet precies hetzelfde als jij doet, maar gaat wel over computers die herkenbare plaatjes produceren.
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
Het algoritme een beetje bijgeschaafd!!





Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.





Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.

Vliegende blauwe donut

[ Bericht 14% gewijzigd door firefly3 op 02-04-2020 22:32:25 ]
Exponentiële deflatie van Bitcoin maakt arme mensen nog veel sneller armer dan het grote probleem van inflatie. Gematigde burning van Ethereum is de gulden middenweg.
|
|
| Forum Opties | |
|---|---|
| Forumhop: | |
| Hop naar: | |